基于全局风格令牌和奇异谱分析的端到端语音合成方法
文献发布时间:2024-04-18 19:58:53
技术领域
本发明属于计算机语音处理领域,尤其是一种基于GST(Global Style Tokens,全局风格令牌)和SSA(Singular Spectrum Analysis,奇异谱分析)的端到端语音合成方法。
背景技术
近年来,随着人工智能领域的快速发展,语音合成作为人机交互所必须的技术,已经成为学术研究的重点之一。语音合成(TTS,text to speech),是将文字转化为语音的过程。现在,人们的日常生活已经离不开语音合成了。
在语音合成的发展过程中,可以将语音合成技术分为传统合成方法和基于深度学习的合成方法两大类,传统方法又可分为拼接合成法和参数合成法两大类。拼接合成法是使用大规模语料库中录制好的语音片段,筛选出语料库中最佳的语音单元序列,通过规则系统的约束,根据文本序列将这些语音片段拼接起来合成一段完整语音的方法。该方法的优点是采用原始语音素材,音质较好,并且模型简单,易于调试,在自动报站、报时等场景有所应用;缺点是受语料库的语音单元驱动,过于依赖原始语音素材的规模大小与质量好坏,灵活性不足,并且合成出的语音有明显的拼接痕迹。
参数合成法是通过对文本输入进行数学建模,根据参数来预测文本的声学特征,模拟人类发声方式来合成语音的方法。该方法的优点是模块化建模,灵活性和扩展性强,并且不依赖语料的规模,在嵌入式设备中应用广泛;缺点是各个模块之间相互独立,算法相对复杂,参数众多,不利于整体系统的调整,并且合成出的语音质量相对较差,不贴近自然人声。
现在基于深度学习的语音合成主流的方法有Deep Voice,Tacotron,FastSpeech等,这些方法对比传统的语音合成方法,合成的语音更加自然、清晰,但是由于训练语料的影响,也存在一定的背景噪声,合成语音的波形带有毛刺,从而使语音质量受到影响,且合成的语音风格单一。
发明内容
为了克服现有技术的不足,本发明提供一种基于全局风格令牌和奇异谱分析的端到端语音合成方法,本发明采用奇异谱分析的方法,解决了端到端语音合成模型合成的语音波形中偶现的毛刺问题;可以一定程度上降低合成语音中存在的背景噪声,同时采用了GST结构,能合成出不同风格的语音,达到语音风格多样化的目的,声码器部分采用了MelGAN结构,提高了语音合成的速度。相较于传统的语音合成方法,本发明的方法在自然度与质量上有所提高。
为了解决上述技术问题本发明采用如下的技术方案:
一种基于全局风格令牌和奇异谱分析的端到端语音合成方法,其所述方法包括以下步骤:
S1:输入文本:在主程序中输入一段文本,作为待合成文本;
S2:文本预处理:对待合成的文本首先进行分句处理,若文本长度大于n个字符,n为预设字符数量阈值,则以n个字符为每组最大容量进行分组,若文本长度不足n个字符,则不进行分句处理;
S3:构造编码-解码器网络,过程如下:
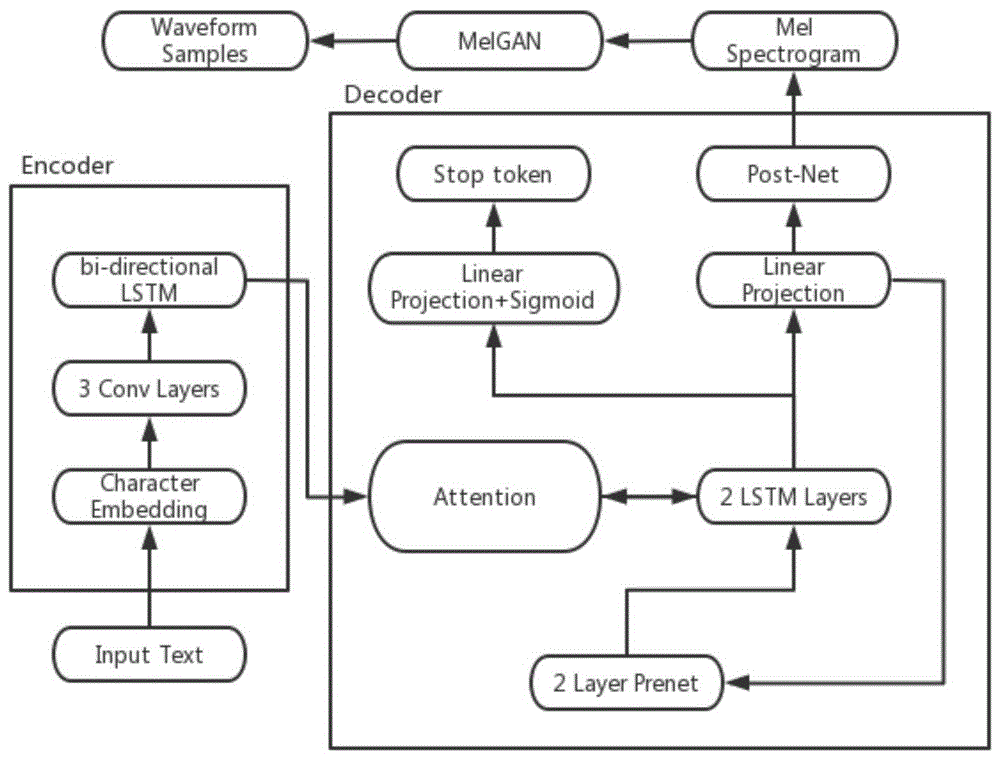
编码器模块包含一个字符嵌入层、一个3层卷积和一个双向LSTM层,编码器负责将输入的序列或句子压缩成一个固定长度的语义向量;
解码器模块包括由256个隐藏ReLU单元组成的双层全连接层,注意力机制,双层1024个单元组成的单向LSTM,线性投影层和门限层;解码器负责将编码器传输过来的向量还原成序列,其采用了一个自回归循环神经网络,从编码的输入序列预测输出声谱图,一次预测一帧;还有一个并行于频谱帧的预测,解码器LSTM的输出与注意力上下文向量拼接在一起,投影成一个标量后传递给sigmoid激活函数,来预测输出序列是否已经完成的概率;
编解码器加入了混合注意力机制,如下:
e
其中,e
其中,F表示卷积核,α
S4:训练编码-解码器网络,过程如下:
编码-解码器网络进行训练使用Adam优化器,设置学习率、批量和损失函数,最终训练出编码-解码器构成的声谱预测模型;
S5:构造MelGAN声码器,过程如下:
声码器的生成器是一个完全卷积的前馈网络,输入的频谱图为s,原始音频x为输出,使用转置的卷积层对输入序列进行上采样,每个转置的卷积层后面是带有膨胀卷积的残差块;
判别网络采用具有3个鉴别器的多尺度架构,3个鉴别器具有相同的网络结构,但在不同的音频规模上运行,鉴别器D1以原始音频的规模运行,而鉴别器D2,鉴别器D3以分别降频2倍和4倍的原始音频运行;下采样使用内核大小为4的跨步平均池执行,由于音频具有不同级别的结构,因此激励了不同比例的多个判别器;
MelGAN声码器的损失函数采用了Hinge loss:
其中,L表示计算出的铰链损失值,D
S6:构造GST模型,GST模型由参考编码器和Style Token层组成;
S7:生成梅尔谱,过程如下:
解码器的输出与使用上一个解码步输出计算而得的上下文向量做拼接,然后整个送入RNN解码器中,RNN解码器的输出用来计算新的上下文向量,最后新计算出来的上下文向量与解码器输出做拼接,送入投影层来生成预测的梅尔谱;
S8:生成时域波形,过程如下:
将梅尔谱输入到MelGAN声码器中,经过生成器中的一层Conv层后送到上采样阶段,经过两次8×后再经过两次2×,每次上采样中嵌套残差模块,最后经过一层conv层得到音频输出;
S9:通过SSA对音频进行降噪,过程如下:
通过奇异谱分析SSA先将合成的语音信号拆解成二维的轨迹矩阵,然后对轨迹矩阵做奇异值分解并按需选取最重要的前几维特征向量计算重构矩阵,最终利用重构矩阵重构信号,得到去噪后的一维信号。
进一步,所述步骤S4中,学习率设置为0.0001,批量设置为4,损失函数为均方误差函数。
再进一步,所述步骤S6中,参考编码器由卷积堆栈和RNN组成,它以对数梅尔图作为输入,首先传递到具有3×3内核,2×2步长,批量归一化和ReLU激活功能的六个二维卷积层的堆栈中,分别为6个卷积层使用32、32、64、64、128和128个输出通道,然后将生成的输出张量整形为3维,并馈送到单层128单位单向GRU,最后的GRU状态用作参考嵌入,然后将其作为输入提供给style token层,Style token层由一组Style Token Embeddings和注意模块组成,每个token嵌入为256-D,注意力模块采用基于位置的注意力机制。
更进一步,所述步骤S9中,通过奇异谱分析SSA先将合成的语音信号拆解成二维的轨迹矩阵,然后对轨迹矩阵做奇异值分解并按需选取最重要的前几维特征向量计算重构矩阵,最终利用重构矩阵重构信号,得到去噪后的一维信号,轨迹矩阵如下:
其中,原语音信号为[x
将轨迹矩阵分组如下:
其中,U是特征向量,i=1,2,...,d,d是矩阵X的秩,V
本发明的有益效果为:采用奇异谱分析的方法解决了端到端语音合成模型合成的语音波形中偶现的毛刺问题,可以一定程度上降低合成语音中存在的背景噪声。采用GST结构,能合成出不同风格的语音。相较于传统的语音合成方法,本方法在自然度与质量上有所提高。
附图说明
图1是端到端语音合成模型结构图。
图2是语音合成流程图。
具体实施方式
下面对本发明做进一步说明。
参照图1和图2,一种基于全局风格令牌和奇异谱分析的端到端语音合成方法,包括以下步骤:
S1:输入文本:在主程序中输入一段文本,作为待合成文本;
S2:文本预处理:对待合成的文本首先进行分句处理,若文本长度大于n(n取30)个字符,则以30个字符为每组最大容量进行分组,若文本长度不足30个字符,则不进行分句处理;
S3:构造编码-解码器网络,过程如下:
编码器模块包含一个字符嵌入层(Character Embedding)、一个3层卷积和一个双向LSTM层,编码器负责将输入的序列或句子压缩成一个固定长度的语义向量;
解码器模块包含了Prenet(由256个隐藏ReLU单元组成的双层全连接层),attention layer(注意力机制),decoder RNN(双层1024个单元组成的单向LSTM),线性投影层和门限层;解码器负责将编码器传输过来的向量还原成序列,其采用了一个自回归循环神经网络,从编码的输入序列预测输出声谱图,一次预测一帧;此外,还有一个并行于频谱帧的预测,解码器LSTM的输出与注意力上下文向量拼接在一起,投影成一个标量后传递给sigmoid激活函数,来预测输出序列是否已经完成的概率;
编解码器加入了混合注意力机制:
e
其中,e
其中,F表示卷积核,α
S4:训练编码-解码器网络,过程如下:
编码-解码器网络进行训练使用Adam优化器,学习率设置为0.0001,批量设置为4,损失函数为均方误差函数,最终训练出编码-解码器构成的声谱预测模型;
S5:构造MelGAN声码器,过程如下:
声码器的生成器是一个完全卷积的前馈网络,输入的频谱图为s,原始音频x为输出,由于梅尔频谱图的帧移采样率为256,因此使用转置的卷积层对输入序列进行上采样。每个转置的卷积层后面是带有膨胀卷积的残差块;
判别网络采用具有3个鉴别器(D1,D2,D3)的多尺度架构,这些鉴别器具有相同的网络结构,但在不同的音频规模上运行;鉴别器D1以原始音频的规模运行,而鉴别器D2,鉴别器D3以分别降频2倍和4倍的原始音频运行;下采样使用内核大小为4的跨步平均池执行。由于音频具有不同级别的结构,因此激励了不同比例的多个判别器。这种结构具有归纳偏差,每个判别器都学习不同音频频率范围的特征;
MelGAN声码器的损失函数采用了Hinge loss:
其中,L表示计算出的铰链损失值,D
S6:构造GST,过程如下:
GST模型由参考编码器和Style Token层组成,参考编码器由卷积堆栈和RNN组成,它以对数梅尔图作为输入,首先传递到具有3×3内核,2×2步长,批量归一化和ReLU激活功能的六个二维卷积层的堆栈中,分别为6个卷积层使用32、32、64、64、128和128个输出通道,然后将生成的输出张量整形为3维(保留输出时间分辨率),并馈送到单层128单位单向GRU,最后的GRU状态用作参考嵌入,然后将其作为输入提供给style token层。Style token层由一组Style Token Embeddings和注意模块组成,每个token嵌入为256-D,注意力模块采用基于位置的注意力机制;
S7:生成梅尔谱,过程如下:
解码器的输出与使用上一个解码步输出计算而得的上下文向量做拼接,然后整个送入RNN解码器中,RNN解码器的输出用来计算新的上下文向量,最后新计算出来的上下文向量与解码器输出做拼接,送入投影层来生成预测的梅尔谱;
S8:生成时域波形,过程如下:
将梅尔谱输入到MelGAN声码器中,经过生成器中的一层Conv层后送到上采样阶段,每次上采样中嵌套残差模块,最后经过一层conv层得到音频输出;
S9:通过SSA对音频进行降噪,过程如下:
通过奇异谱分析SSA先将合成的语音信号拆解成二维的轨迹矩阵,然后对轨迹矩阵做奇异值分解并按需选取最重要的前几维特征向量计算重构矩阵,最终利用重构矩阵重构信号,得到去噪后的一维信号,轨迹矩阵如下:
其中,原语音信号为[x
将轨迹矩阵分组如下:
其中,U是特征向量,i=1,2,...,d,d是矩阵X的秩,V
本实施例的基于GST和SSA的端到端语音合成方法,采用奇异谱分析的方法解决了端到端语音合成模型合成的语音波形中偶现的毛刺问题。可以一定程度上解决合成语音中存在的背景噪声。采用GST结构,能合成出不同风格的语音。相较于传统的语音合成方法,本方法在自然度与质量上有所提高。
- 一种基于端到端的音色及情感迁移的跨语言语音合成方法
- 基于多帧预测的轻量级端到端语音合成系统构建方法