一种基于气流量估计的语音分离方法
文献发布时间:2024-04-18 20:01:55
技术领域
本发明属于数字音频处理技术领域,具体提供一种基于气流量估计的语音分离方法。
背景技术
在电话、视频会议中常常出现有多个讲话人同时发声的情况,语音分离的目标是从同时有多个人讲话的语音音频中分离出单个讲话人的音频,语音分离通常用于提高语音识别、情感分析等任务的性能。
目前,语音分离方法主要分为传统方法和深度学习方法,传统方法依赖于声源定位和波束形成等技术进行分离,深度学习方法分为基于频谱图的方法和基于音频时间序列的方法两类。深度学习方法较传统方法在分离效果上有了较大的提升,然而,无论是传统、还是深度学习的语音分离方法都针对讲话人正常发声的一般场景进行设计;语音分离方法均基于语音中的谐波成分进行分析和建模,在某些特殊场景,比如讲话人有意压低声音或在气喘,语音中的谐波成分偏低时,现有的方法的音频表征能力不足,分离准确性明显下降。因此,需要研究在谐波成分偏低的场景下,提高语音分离准确性的方法。
发明内容
本发明的目的在于提供一种基于气流量估计的语音分离方法,用以解决现有方法在低谐波成分场景下的分离准确度降低的问题。
为实现上述目的,本发明采用的技术方案为:
一种基于气流量估计的语音分离方法,包括:模型构建与语音分离,其特征在于:
所述模型构建包括以下步骤:
A1.构建气流量特征:设共有M个音频参与训练,每个音频均包含单个讲话人的声音,且具有相同的音频样点数K,对每一个音频作如下处理:
A1-1.估计气流量:将输入音频C输入到声门气流量估计模型中,得到该音频对应的气流量估计序列W;
A1-2.估计谐波成分:
将音频数据按固定长度划分为各音频帧,相邻帧部分重叠,得到I个音频帧;
定义长度为I的谐波成分数组H,对音频的每一个音频帧作:将音频帧i输入到基频估计算法中,得到该音频帧的基频成分;若该音频帧不存在基频成分,则置H的第i个元素H[i]为1,否则,置H的第i个元素H[i]为0,1≤i≤I;
A1-3.生成气流量特征:
定义长度为K的气流量特征数组F,计算气流量特征:
F[k]=W[k]·H[z],1≤k≤K
其中,F[k]表示第k个音频样点的气流量特征,W[k]表示第k个音频样点对应的气流量估计值,z为第k个音频样点对应的帧编号,H[z]表示谐波成分数组H的第z个元素值;
A2.生成训练样本:
A2-1.从训练音频中一次随机选择N个音频组成一组,共选择P次,形成P组音频;
A2-2.对每一组音频作如下处理:
对音频组第n个音频的数据进行归一化,得到归一化的音频数据序列c
对音频组第n个音频的气流量特征数组F的元素进行归一化,得到归一化的气流量特征数据序列f
将f
将组内所有音频的组合特征T
X
A3.训练语音分离模型:将生成的训练样本X
所述语音分离包括以下步骤:
B1.构建气流量特征:设测试音频C'为包含N个讲话人的混合声音,音频样点数为K;根据测试音频生成气流量特征:
B1-1.估计气流量:按步骤A1-1,得到测试音频C'对应的气流量估计序列W';
B1-2.估计谐波成分:按步骤A1-2,得到测试音频C'的谐波成分数组H';
B1-3.生成气流量特征:按步骤A1-3,得到测试音频C'的气流量特征数组F';
B2.生成测试样本:
B2-1.对测试音频C'的数据进行归一化,得到归一化的音频数据序列c';
B2-2.对测试音频C'的气流量特征数组F'的元素进行归一化,得到归一化的气流量特征数据序列f';
B2-3.将f'与c'拼接得到测试样本X',X'=[c'f'];
B3.语音分离:将测试样本X'输入到语音分离模型中进行分离,得到N个讲话人各自的单独语音。
基于上述技术方案,本发明的有益效果在于:
本发明提供一种基于气流量估计的语音分离方法,该方法对讲话人的声门气流量和语音谐波成分进行估计,在此基础上,以帧为单位对谐波帧的气流量进行抑制,从而生成气流量特征,弥补了低谐波成分场景下传统方法在音频表征能力上的不足,将气流量特征和原音频数据进行拼接,形成新的训练和测试样本,从而在提高非谐波语音分离准确性的同时,也保持了传统方法对正常语音的分离效果。
附图说明
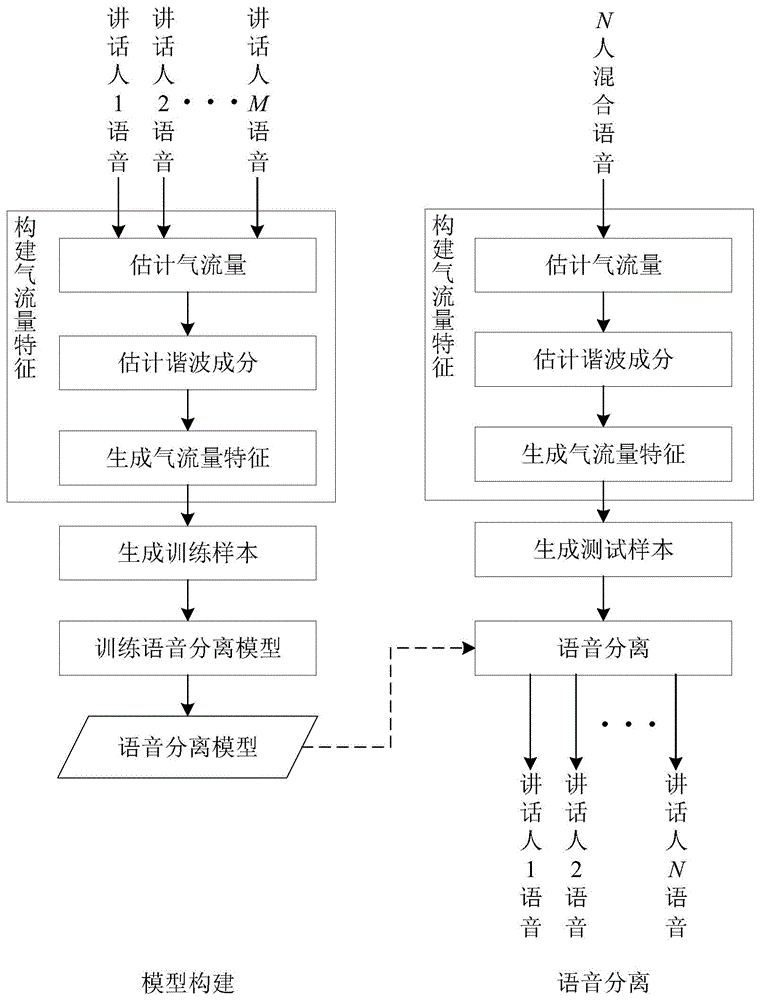
图1为本发明中基于气流量估计的语音分离方法的流程示意图,包括模型构建和语音分离两个阶段。
图2为本发明中基于气流量估计的语音分离方法的气流量估计效果图,其中,(a)为输入音频的波形图,(b)为气流量估计序列的数据图。
具体实施方式
为使本发明的目的、技术方案与有益效果更加清楚明白,下面结合附图和实施例对本发明作进一步详细说明。
本实施例提供一种基于气流量估计的语音分离方法,其流程如图1所示,该方法包含模型构建和语音分离两个阶段。
所述模型构建包括以下步骤:
A1.构建气流量特征:根据训练音频生成气流量特征,设共有M个音频参与训练,且每个音频均包含某单个讲话人的声音,具有相同的音频样点数K,对每一个音频,作如下处理:
在本实施例中,参与训练的音频共有个1332个,即M=1332,每个音频均为采样率为22500Hz的单声道音频,只包含某单个讲话人的声音,音频时长为10秒,音频样点数为225000,即K=225000;以下步骤以处理第一个女生音频为例进行说明,该音频的波形图如图2(a)所示;
A1-1.估计气流量:将输入音频C输入到现有的声门气流量估计模型中,得到该音频对应的气流量估计序列W,即C的每一个样点C[k](1≤k≤K)对应气流量估计序列W的第k个估计值W[k];
在本实施例中,将输入音频C输入到现有的声门气流量估计模型中,得到该音频对应的气流量估计序列W=[0.001,0.001,…,0.095],W共有225000个元素,对应原始音频的225000个样本点,气流量估计序列W的数据如图2(b)所示;
A1-2.估计谐波成分:
A1-2-1.将音频数据按固定长度划分为各音频帧,相邻帧帧间有重叠,得到I个音频帧;
在本实施例中,将音频数据按512个采样点的长度等分为各音频帧,相邻帧帧间有半帧长度的重叠,当前得到的音频帧总数目I=878;
A1-2-2.定义长度为I的谐波成分数组H;
A1-2-3.对音频的每一个音频帧作:将音频帧i(1≤i≤I)数据输入到现有的基频估计算法中,估计出该音频帧的基频成分;若该音频帧不存在基频成分,则置H的第i个元素H[i]为1,否则置H的第i个元素H[i]为0;
在本实施例中,将第1帧到第878帧的数据先后输入到基频估计算法YIN中,估计出每个音频帧的基频成分,从而确定谐波成分数组H的每一个元素的值;以第i=137帧为例,将第137帧音频数据输入到基频估计算法YIN中进行基频成分估计,得到该音频帧的基频成分不存在,故置H的第137个元素H[137]=1,执行该步骤后,最终得到谐波成分数组H=[1,1,…,1];
A1-3.生成气流量特征:
A1-3-1.定义长度为K的气流量特征数组F;
A1-3-2.计算气流量特征:
F[k]=W[k]·H[z],1≤k≤K,
其中,F[k]为气流量特征数组F的第k个元素,z为编号为k的音频样点对应的帧编号;
在本实施例中,以第34900个样本点为例,即k=34900,气流量估计序列W的第34900个元素W[34900]=0.632,第34900样点对应的帧编号z=137,又H[137]=1,则计算得到气流量特征数组的第34900个元素F[34900]=W[34900]·H[137]=0.632;执行该步骤后,最终得到气流量特征数组F=[0.001,0.001,…,0.095];
A2.生成训练样本:
A2-1.从训练音频中一次随机选择N个音频组成一组,共选择P次,形成P组音频;
在本实施例中,从训练音频中一次随机选择N=2个音频组成一组,共选择P=10000次,形成10000组音频;
A2-2.对每一组音频,作:
在本实施例中,以第一组为例;
A2-2-1.对满足1≤n≤N的每一个n作:
在本实施例中,N=2,故对满足1≤n≤2的每一个n,作:
A2-2-1-1.对当前音频组第n个音频的数据进行归一化,得到归一化的音频数据序列c
在本实施例中,以第n=1个音频为例,对第1个音频C
其中,
执行该步骤后,得到归一化的音频数据序列c
A2-2-1-2.对第n个音频对应的气流量特征数组F的元素进行归一化,得到归一化的气流量特征数据序列f
在本实施例中,以第n=1个音频为例,对第1个气流量特征F
其中,F
执行该步骤后,得到归一化的气流量特征数据序列f
A2-2-1-3.将f
在本实施例中,以第n=1个音频为例,将f
A2-2-2.将组内所有音频的组合特征T
X
在本实施例中,N=2,以音频组p=1为例,将组内两音频的组合特征T
X
A3.训练语音分离模型:将生成的训练样本X
在本实施例中,将生成的训练样本X
所述语音分离包括以下步骤:
B1.构建气流量特征:根据测试音频生成气流量特征,设测试音频包含某N个讲话人的混合声音,音频样点数为K;
在本实施例中,参与测试的音频共有8000个,每个音频均为采样率为22500Hz的单声道音频,均包含某N=2个讲话人的混合声音,音频时长为10秒,音频样点数为225000,即K=225000;以下步骤以处理第一个测试音频为例进行说明;
B1-1.估计气流量:按步骤A1-1,得到测试音频C'对应的气流量估计序列W';
在本实施例中,将输入音频C'输入到现有的声门气流量估计模型中,得到该音频对应的气流量估计序列W'=[0.003,0.005,…,0.004],W'共有225000个元素,对应原始音频的225000个样本点;
B1-2.估计谐波成分:按步骤A1-2,得到测试音频C'每个音频帧对应的谐波成分数组H';
在本实施例中,按步骤A1-2,得到测试音频C'每个音频帧对应的谐波成分数组H'=[1,1,…,1];
B1-3.生成气流量特征:按步骤A1-3,得到测试音频C'对应的气流量特征数组F';
在本实施例中,按步骤A1-3,得到测试音频C'对应的气流量特征数组F'=[0.003,0.005,…,0.004];
B2.生成测试样本:
B2-1.对测试音频C'的数据进行归一化,得到归一化的音频数据序列c';
在本实施例中,对C'进行归一化,对满足1≤k≤225000的每一个k,计算归一化的音频数据序列c'的第k个元素c'[k]:
其中,C'
执行该步骤后,得到归一化的音频数据序列c'=[0.004,0.011,…,0.028];
B2-2.对测试音频C'对应的气流量特征数组F'的元素进行归一化,得到归一化的气流量特征数据序列f';
在本实施例中,对F'进行归一化,对满足1≤k≤225000的每一个k,计算归一化的气流量特征数据序列f'的第k个元素f'[k]:
其中,F'
执行该步骤后,得到归一化的气流量特征数据序列f'=[0.002,0.003,…,0.002];
B2-3.将f'的K个数据拼接到c'的K个数据之后,得到长度2K的测试样本X',即X'=[c'f'];
在本实施例中,将f'=[0.002,0.003,…,0.002]拼接到c'=[0.004,0.011,…,0.028]之后,得到长度2K的组合特征X',即X'=[0.004,0.011,…,0.002];
B3.语音分离:将测试样本X'输入到语音分离模型中进行分离,得到N个讲话人各自单独的语音;
在本实施例中,将测试样本X'输入到语音分离模型中进行分离,得到N=2个讲话人各自单独的语音。
下面将本发明方法的性能与SepFormer语音分离方法进行比较,分离效果的指标采用SI-SNR;两种方法都使用相同的实施例数据集进行训练和测试,其结果如表1所示,其中数据为测试音频的平均值;
表1
可以看到,本发明方法的SI-SNR较传统SepFormer方法有了明显的提高,表明本发明获得了更好的语音分离效果。
以上所述,仅为本发明的具体实施方式,本说明书中所公开的任一特征,除非特别叙述,均可被其他等效或具有类似目的的替代特征加以替换;所公开的所有特征、或所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以任何方式组合。