一种基于Prophet-SVM模型的大数据采集系统的数据监控预警方法
文献发布时间:2024-04-18 20:01:55
技术领域
本发明涉及数据异常监控领域,特别是涉及一种基于Prophet-SVM模型的大数据采集系统的数据监控预警方法。
背景技术
随着大数据和物联网等技术的提出,各行各业对数据采集的发展提出了更高的要求,数据采集系统智能化是一个主要的发展趋势。数据采集系统一般通过执行代码进行自动化采集,仅仅通过代码报错来判断采集系统是否正常,往往会存在以下问题:
1、由于采集数据源网站域名更换,导致旧采集数据源停止更新,可能出现采集数量始终为0;
2、采集数据源网页结构更改,可能出现重复采集同一页面的数据;
针对上述存在的问题,在执行代码未报错的情况下,采集系统的采集数量可能与实际数据源公布情况不一致,造成数据缺失或数据重复的情况。因此,有必要对数据采集系统进行监控并能及时预警。
同时,部分数据源在特殊时间段可能会暂停公布数据或数据出现较大变动,采用传统的时间序列预测方法,难以精准捕捉这部分变化。
发明内容
基于此,有必要针对上述问题,提供一种数据采集系统监控预警的方法,同时在对数据采集系统的采集数量进行预测时,由于部分数据源在特殊时间段可能会暂停公布数据或数据出现较大变动,因此需要考虑到采集数量序列可能会受到数据公开网站发布数据周期性以及非工作日和法定节假日等因素影响。
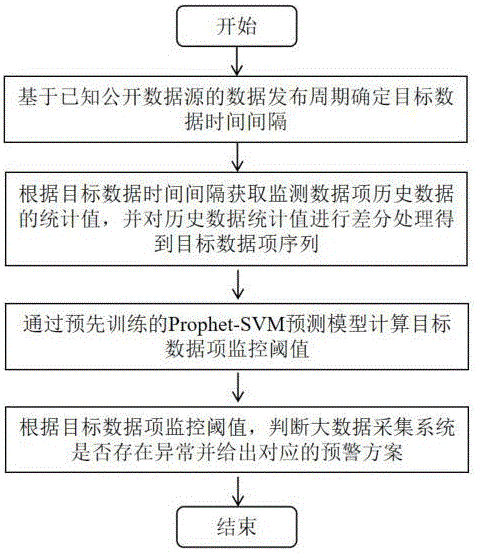
为了实现上述目的,本方法使用的技术方案是:一种基于Prophet-SVM模型的大数据采集系统的数据监控预警方法,将公开数据源的数据发布周期作为目标数据时间间隔,首先根据目标数据时间间隔获取监测数据项历史数据的统计值,并对历史数据的统计值进行差分处理得到目标数据项序列;然后通过预先训练的Prophet-SVM预测模型计算目标数据项监控阈值,最后根据目标数据项监控阈值,判断大数据采集系统是否存在异常并给出对应的预警方案。
整个方案的具体实施步骤如下:
基于已知公开数据源的数据发布周期确定目标数据时间间隔;
根据目标数据时间间隔获取监测数据项历史数据的统计值,并对历史数据统计值进行差分处理得到目标数据项序列;
通过预先训练的Prophet-SVM预测模型计算目标数据项监控阈值;
根据目标数据项监控阈值,判断大数据采集系统是否存在异常并给出对应的预警方案。
可选地,所述基于已知公开数据源的数据发布周期确定目标数据时间间隔,包括:
根据已知公开数据源的历史数据发布情况,判断目标数据更新方式为日更、周更、月更还是年更等,目标数据更新方式确定后,目标数据采集频率应与数据更新方式保持一致,从而确定目标数据采集的时间间隔。
可选地,所述根据目标数据时间间隔获取监测数据项历史数据的统计值,并对历史数据统计值进行差分处理得到目标数据项序列,包括:
基于采集到的监测数据项的历史数据,按照目标数据时间间隔统计监测数据项的数据总量,得到数据总量初始序列。由于公开数据源会不断发布新数据,因此所述数据总量初始序列会存在明显的上升趋势,通过差分处理来消除这种明显的趋势,得到公开数据源每个目标时间间隔内新增的数据量,即目标数据项序列。
可选地,通过预先训练的Prophet-SVM预测模型计算目标数据项监控阈值,包括:
将所述目标数据项序列按照80%和20%的比例分为训练集和测试集,首先建立单一Prophet模型得到所述第一预测值以及第一预测值上下限,通过计算实际值与第一预测值之间的差值得到残差序列,将所述残差序列进行归一化,对所述归一化后的残差序列建立SVM预测模型,得到第二预测值,最后通过所述第二预测值和所述第一预测值上下限的组合确定目标数据项监控阈值。
可选地,通过预先训练的Prophet-SVM预测模型计算目标数据项监控阈值,还包括:
所述建立单一Prophet模型得到所述第一预测值以及第一预测值上下限的步骤为:考虑到所述目标数据项序列已经通过差分处理剔除了明显的上升趋势,因此确定单一Prophet模型的基本形式为
其中,
根据所述目标数据项序列的日期变量及对应的目标数据值,创建Prophet模型对象,并确定节假日日期数据holidays;初始化Prophet模型参数,设置周期项参数seasonality_prior_scale=10,节假日项系数holidays_prior_scale=10,置信区间interval_width=0.8,其余参数设置为默认值,基于初始Prophet模型参数,对训练集中的数据进行训练,利用训练后的模型对测试集中的数据进行Prophet拟合,得到Prophet模型预测值,通过交叉验证确定Prophet模型最优的参数,最优参数的选取标准为模型均方误差MSE最小,将最优参数下拟合得到的预测值作为所述第一预测值并输出所述第一预测值上下限。
可选地,通过预先训练的Prophet-SVM预测模型计算目标数据项监控阈值,还包括:
根据目标数据项与所述第一预测值之间的差值生成残差序列,并对所述残差序列进行归一化处理,针对所述归一化处理后的残差序列建立SVM预测模型,确定SVM预测模型中的参数,包括核函数和正则化参数C,其中核函数包括线性核函数、多项式核函数和高斯核函数,多项式核函数中还需要确定degree参数,高斯核函数中还需要确定gamma参数。通过交叉验证确定最优的核函数以及对应的最优参数,最优参数的选取标准为模型均方误差MSE最小。根据最优参数下拟合得到的SVM模型预测值作为所述第二预测值。所述残差序列归一化公式为:
其中,
可选地,通过预先训练的Prophet-SVM预测模型计算目标数据项监控阈值,还包括:
根据所述第一预测值上下限和所述第二预测值组合得到所述目标数据项监控阈值,所述监控阈值表示为
其中,
可选地,根据目标数据项监控阈值,判断大数据采集系统是否存在异常并给出对应的预警方案,包括:若目标数据项数量属于所述监控阈值内,则大数据采集系统不存在异常;若目标数据项数量不属于所述监控阈值内,则判断大数据采集系统存在异常。一般认为数据缺失比数据重复风险性更高,因此数据缺失处理优先级高于数据重复优先级,具体可表示为:目标数据项数量小于所述监控阈值下限时,发出一级报警信号,需要立即处理,目标数据项数量大于所述监控阈值上限时,发出二级报警信号,连续3个目标时间间隔发出二级报警信号需要及时进行处理。
附图说明
图1为方案具体实施流程图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例的附图,对本发明实施例的技术方案进行清楚、完整地描述。显然,所描述的实施例是本发明的一部分实施例,而不是全部的实施例。基于所描述的本发明的实施例,本领域普通技术人员在无需创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
下面将结合本申请以及图1,对整个技术方案实施步骤进行清晰完整的解释,参考以下文本,具体步骤如下:
步骤101:结合已知公开数据源的历史数据发布情况,确定公开数据源的数据发布频率,数据发布频率包括但不限于日更、周更、月更以及年更等形式,将目标数据采集时间间隔与公开数据源发布频率保持一致。如“国家企业信用信息公示系统”中每天都会更新企业的信息,即该公开数据源的数据发布频率为日更,则开发人员在采集该数据源数据时应与网站数据发布频率保持一致,即采集时间间隔为每日。
步骤102:确定目标数据项采集时间间隔后,统计目标数据项历史数据中每个时间间隔下的数据总量,得到数据总量初始序列。如历史采集的“国家企业信用信息公示系统”中的企业信息存储在企业信息表中,通过数据采集入库时间即可计算每天企业信息表中的数据总量,得到企业数总量初始序列。由于公开数据源会不断发布新数据,而旧数据会下架,在数据采集过程中,对于下架的数据在数据库中一般会更新数据状态而不会删除该条数据,因此数据总量初始序列会存在明显的上升趋势,通过差分处理来消除这种明显的趋势,得到公开数据源每个目标时间间隔的新增的数据量,即目标数据项序列。
步骤103:得到的目标数据项序列中包括日期变量及对应的目标数据值,即某个公开数据源在采集日期下新增了多少数据量。同时还需要确定节假日日期数据,一般而言,节假日一般指非工作日以及法定节假日,针对不同的数据项还可加入特殊的节假日日期数据,如对于产品销售数据统计时,双十一时期可归入节假日日期。
步骤104:将目标数据项序列的日期变量和目标数据值作为Prophet模型的输入,由于目标数据项序列已经通过差分处理剔除了明显的趋势,因此在Prophet模型设定时只考虑周期项和节假日项。首先初始化Prophet模型参数,设置周期项参数seasonality_prior_scale=10,节假日项系数holidays_prior_scale=10,置信区间interval_width=0.8,其余参数设置为默认值,基于初始Prophet模型参数,对训练集中的数据进行训练,利用训练后的模型对测试集中的数据进行Prophet拟合,得到Prophet模型预测值。由于模型优劣需要通过相应的指标进行评估,选择均方误差MSE作为模型评价指标,并通过交叉验证确定Prophet模型中最优的参数,并以均方误差MSE最小来选取Prophet模型最优的参数,将最优参数下的模型对待预测数据项进行拟合,拟合得到的预测值作为第一预测值并输出预测值上下限。
步骤105:由于Prophet模型对于时间序列中的线性部分拟合较好,而对于非线性部分拟合较差,因此再选用SVM预测模型对非线性部分进行拟合。根据目标数据项实际值和第一预测值之间的差值生成残差序列,为了提高模型的收敛性,此处需要对残差序列进行归一化处理,针对归一化处理后的残差序列建立SVM预测模型,确定SVM预测模型中的参数,包括核函数和正则化参数C,其中核函数包括线性核函数、多项式核函数和高斯核函数,多项式核函数中还需要确定degree参数,高斯核函数中还需要确定gamma参数。通过交叉验证确定最优的核函数以及对应的最优参数,通过模型均方误差MSE最小的原则来选取SVM预测模型最优的参数。将最优参数下的SVM预测模型对待预测数据项进行拟合,拟合得到的预测值作为第二预测值。
步骤106:根据Prophet模型拟合的第一预测值上下限和SVM预测模型拟合的第二预测值进行组合,得到目标数据项的监控阈值,若当前目标数据项数量属于监控阈值内,则大数据采集系统不存在异常;若当前目标数据项数量不属于监控阈值内,则判断大数据采集系统存在异常。一般认为数据缺失比数据重复风险性更高,因此数据缺失处理优先级高于数据重复优先级,具体可表示为:目标数据项数量小于监控阈值下限时,发出一级报警信号,需要立即处理,目标数据项数量大于监控阈值上限时,发出二级报警信号,连续3个目标时间间隔发出二级报警信号需要及时进行处理。