一种基于大规模音频理解模型的异常音检测方法
文献发布时间:2024-07-23 01:35:21
技术领域
本发明涉及音频领域,尤其涉及一种基于大规模音频理解模型的异常音检测方法。
背景技术
近些年来大语言(Large Language Model,LLM)模型发展迅速。大语言模型往往会在互联网级别的大数据上进行训练。因此,模型中存储了大量的各种各样的知识。研究者发现,大语言模型可以被用在翻译、论文写作、代码撰写、广义知识问答等各个领域。很多研究者认为大语言模型是弱人工智能迈向通用人工智能重大的一步。此外,由于大语言模型在极其大规模的数据上训练过,即使被用在新的任务上,往往也会有非常好的泛化效果。即使大语言模型无法直接泛化,我们也可以利用大语言模型的上下文学习能力(In ContextLearning,ICT),在不继续更新模型的情况下,来教会模型新的任务。
如上图所示,现在我们定义一个模板“评论:xxx情感:xxx”,在第一个空白的位置填入对食物的评价,在第二个空白位置根据评价,给出评价人的情感。在这里我们给出了三个示例,然后给了一个新的询问,新的询问我们没有给出情感。然后,我们会把示例对应的文字和新的询问对应的文字都输入到大语言模型中,大语言模型就可以根据三个示例,学到一定的规则,并得知后面应该输出“开心”。这种能力,就叫做大语言模型的上下文学习能力,也就是说大语言模型可以利用上下问的一些新知识来帮助自己预测接下来的输出。
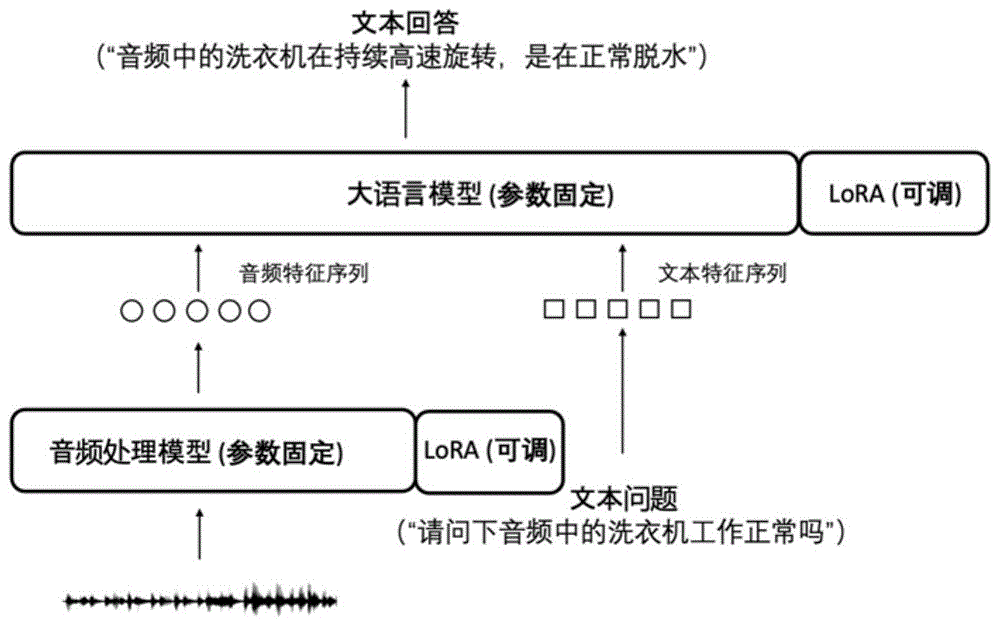
大规模语言模型在文本处理任务上展现出了极强的能力,最近很多人将大语言模型拓展到了其他的模态。比如图像和音频。这样,我们可以输入多种模态的信息和大语言模型进行交互。最近,很多研究者提出了大规模音频理解模型。如图二所示,大规模音频理解模型是一个可以同时接受音频和文本的模型。这个模型首先使用在大规模音频数据上训练的音频处理模型将音频序列转到一个帧率更低的音频特征序列。同时音频处理模型需要保证音频特征序列与文本特征序列在同一个空间内。这样,我们就可以把音频信息和文本信息同时输入到大语言模型中。在图二的例子中,我们输入了一个鸟叫的声音,和一个问题,这个问题的内容是“请描述一下这个音频的内容”,然后模型的输出是“这段音频中有一只鸟在叫”。可以看出大语言模型真正理解了音频,并能通过文本信息与使用者进行交互。
然而现有技术需要对每一种存在的机器训练一个异常音检测模型,数据收集代价大。另外,机器声音往往是重复性的信号,信息含量较低,用信息量较少的数据很难训练得到一个好的深度学习模型。
如果想让大规模音频理解模型在特定的任务上有着更优的表现,我们往往需要在特定任务的数据上进行进一步的微调。
发明内容
有鉴于现有技术的上述缺陷,本发明所要解决的技术问题是如何用信息量较少的数据训练得到一个好的深度学习模型。
为实现上述目的,本发明提供了一种基于大规模音频理解模型的异常音检测方法,其特征在于,利用大规模音频理解模型首先收集少部分异常音相关的数据,并对模型在任务上进行微调。
进一步地,所述微调过程,并不会更新原本的大语言模型和音频处理模型的参数,而是会对这两个模型分别加入一个低秩自适应模块LoRA。
进一步地,所述LoRA有两个变化矩阵,分别是dxr的矩阵和rxd的矩阵。
进一步地,所述rxd的矩阵中,r比d小,是一个低秩的变换。
进一步地,所述大规模音频理解模型训练好之后,把所述LoRA模块合并到原来dxd的权重。
进一步地,利用大语言模型的上下文学习能力,给出一些其他机器的不同声音作为例子,让所述大规模音频理解模型能够对目标机器检测异常音。
进一步地,利用大语言模型的上下文学习能力时,不需要做特定数据的自适应。
进一步地,所述大规模音频理解模型的中的大语言模型,本身就具有很强的推理能力,在结合音频处理模块之后,便能够推理出可能的异常音来源。
进一步地,所述方法包括以下几步:
步骤一:给出三个例子,每个例子有两个音频,第一段是参考音频,第二段是一个新的音频;
步骤二:在第一段音频后面,用文字指出这是来自什么机器的声音;
步骤三:在第二段音频后面,给出第二段音频和第一段音频的比较结果;
步骤四:模型可以理解对于同一种机器,在不同工作状态情况下,声音是如何变化的。
进一步地,所述检测方法在真正使用时,会使用更多示例。
本发明具有如下技术效果:
1、对于目标机器声音数据收集的要求降低,或者不需要收集对应数据。同时,以大规模音频理解模型作为基座进行微调,异常音检测效果会更好。
2、能够好的利用非目标机器的语音来提升目标机器异常音检测的性能。
3、使得我们的模型不仅可以判断音频中是否有异常音,还可以判断异常音的可能来源。
以下将结合附图对本发明的构思、具体结构及产生的技术效果作进一步说明,以充分地了解本发明的目的、特征和效果。
附图说明
图1是本发明的一个较佳实施例的大规模音频理解模型到异常音检测任务的自适应方法;
图2是本发明的一个较佳实施例的LoRA模块;
图3是本发明的一个较佳实施例的基于上下文学习的异常音检测算法。
具体实施方式
以下参考说明书附图介绍本发明的多个优选实施例,使其技术内容更加清楚和便于理解。本发明可以通过许多不同形式的实施例来得以体现,本发明的保护范围并非仅限于文中提到的实施例。
在附图中,结构相同的部件以相同数字标号表示,各处结构或功能相似的组件以相似数字标号表示。附图所示的每一组件的尺寸和厚度是任意示出的,本发明并没有限定每个组件的尺寸和厚度。为了使图示更清晰,附图中有些地方适当夸大了部件的厚度。
一、基于大规模音频理解模型微调的异常音检测算法
在背景技术中,我们已经提到,目前的音频理解模型可以同时输入音频和文本的信息,从而实现模型对音频的理解。但是,如果想让大规模音频理解模型在特定的任务上有着更优的表现,我们往往需要在特定任务的数据上进行进一步的微调。为了让大规模音频理解模型能够在异常音检测任务上有着更好的标签,我们会首先收集少部分异常音相关的数据,并对模型在这个任务上进行微调。
如图1所示,在微调过程中,我们并不会更新原本的大语言模型和音频处理模型的参数。而是会对这两个模型分别加入一个低秩自适应模块(Low-RankAdaptation,LoRA)。如图2所示,对于正常的神经网络线性层,从d维的向量映射到d维的向量,往往需要一个dxd维的权重矩阵。LoRA则是图四右图所示的一个并行的分支。这个分支有两个变化矩阵,分别是dxr的矩阵和rxd的矩阵。在这里r往往会比d小很多,所以右边可以看成是一个低秩的变换。之所以可以这样做,是因为很多研究者发现,权重dxd的矩阵并不是一个满秩的矩阵,所以也没有必要使用一个满秩的自适应模块。同时,这种低秩的自适应模块也可以大大减少额外的参数量。另外,在模型训练好之后,我们可以把LoRA模块合并到原来dxd的权重,这样,在推理阶段,模型的计算量不会有任何的增加。
二、基于大语言模型上下文学习能力的异常音检测方法
虽然我们可以通过收集一定的数据,从而做到音频理解模型自适应到特定类型的异常音检测任务。但在真实场景中,我们会遇到各种情况下的异常音。比如洗衣机工作的异常音,风扇工作的异常音,等等。如果针对每一种情况,我们都收集一定量的数据,对模型进行自适应,这会使得成本变得非常的高。我们在这里提出一种不需要做特定数据的自适应,就可以实现模型在特定场景进行异常音检测的方法。在背景技术中,我们提到,大语言模型具有极强的上下文理解能力,我们同样可以把这种能力用到未知场景的异常音检测任务中。
如图3所示,假设我们的模型已经在洗衣机的音频上自适应过。那么我们的模型,就能很好的理解洗衣机的声音。另外,在现实生活中,我们会发现很多机器在不同工作状态的声音变化都是类似的。比如洗衣机和水轮机在高速运转的时候,对应的声音音调会变得更高。我们仿照大语言模型的上下文学习能力,这里我们提出基于音频和文本的双模态上下文学习,用于将音频理解模型应用到新的机器异常音检测任务上。在上下文学习的输入中,我们会给出三个例子,每个例子有两个音频,第一段是参考音频,第二段是一个新的音频。同时,在第一段音频后面,我们会用文字指出这是来自什么机器的声音。然后,在第二段音频后面,我们会给出第二段音频和第一段音频的比较结果。通过三个示例(真正使用的时候可以给出更多示例),模型可以理解对于洗衣机,在不同工作状态情况下,声音是如何变化的。另外,就像我们上面说的,水轮机本身和洗衣机具有一定的相似性,都是电机的旋转。通过大语言模型的上下文学习能力,模型可以很好的泛化到水轮机的异常音检测这个任务上。
以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术无需创造性劳动就可以根据本发明的构思作出诸多修改和变化。因此,凡本技术领域中技术人员依本发明的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在由权利要求书所确定的保护范围内。
- 一种基于生成对抗网络的音频异常检测方法
- 一种基于视频理解模型的考生回头异常行为检测方法
- 一种基于环境模型的音频异常事件检测方法