基于多阶段卷积神经网络的纺织品无损环保定性方法
文献发布时间:2023-06-19 13:48:08
技术领域
本发明属于纺织品成分分析、材料分类技术领域,具体涉及一种基于多阶段一维卷积神经网络的纺织品无损环保定性方法。
背景技术
在经典的基于近红外光谱数据纺织品成分分析方法中,当前方法大多使用基于统计学习的方法中,首先对近红外光谱数据的预处理提取有效特征,然后通过随机森林、偏最小二乘、逻辑回归等方法获得定性或定量结果。当前已有方法基于浅层机器学习方法难以捕获纺织纤维成分细微差别特征,如棉麻的近红外光谱数据的差异极其微小。本发明设计的深度学习框架可以更好捕获高层抽象特征,用于区分具有细微差异的纺织品成分。另外,在混纺织物的多组分的类别分布存在极大不平衡(即长尾效应)特性,本发明设计了一种多阶段分类模型,通过多任务学习,对尾部数据及存在细微差异的数据进行更好的优化来提升混纺多组分的定性分析的准确性和鲁棒性。
上述现有技术中存在的缺陷:
(1)对于传统近红外光谱数据纺织品成分分析方法,其解决方案中往往依赖于光谱数据预处理、对数据纯净度要求很高,在工业应用场景下由于其检测性能较低已远无法满足当前检测需求。并且没有针对定性分析任务对近红外光谱数据设计有效的深度分类模型;
(2)对于同类深度学习方法而言,第一,没有考虑到纷繁复杂的纺织品近红外光谱数据的样本分布的不平衡问题,使得模型在预测样本数量较少的类别时效果较差。第二,在多成分,多组分定性分析任务中没有考虑到多阶段模型在训练过程中通过多任务损失函数间的相互促进可以使得模型学习更好的特征表示。
发明内容
本发明的目的在于提出一种基于近红外光谱数据的纺织品多阶段定性分类方法。
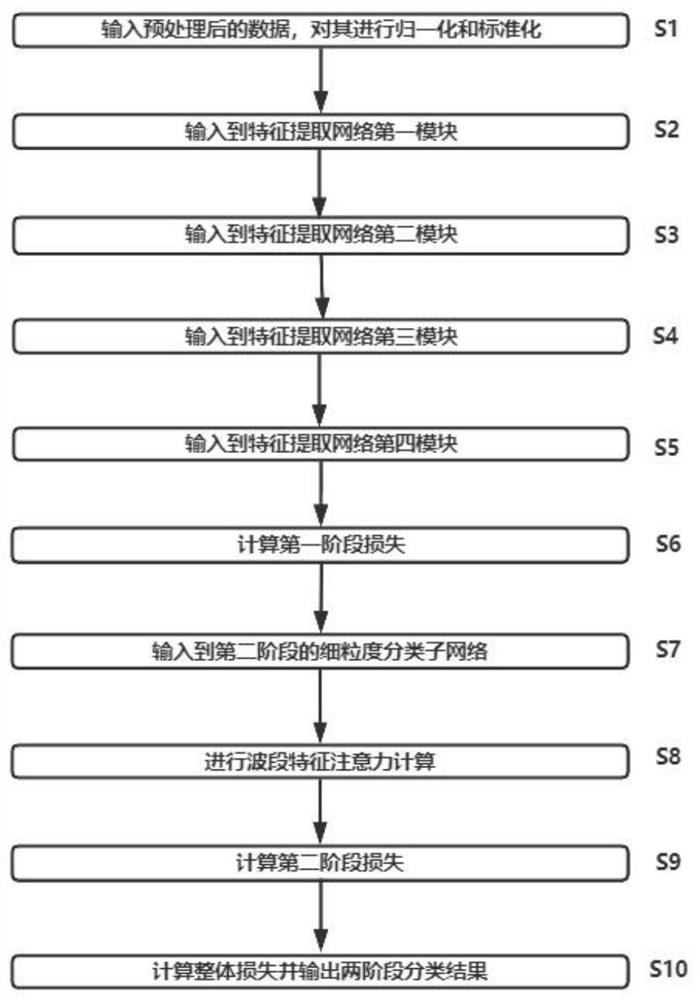
本发明提出的基于一种基于近红外光谱数据的纺织品多阶段定性分类方法设计了一个基于一维卷积网络的多阶段分类模型进行纺织品成分的定性分析。首先根据近红外光谱数据的特点设计了具有四个阶段的深度特征提取模块,获得一维的深度特征向量,并通过该特征进行第一阶段的分类,将纤维成分在特征空间中距离相近的组分进行初步分类。然后将获得的特征分别输入到第二阶段的多个子模型中,在第二阶段子模型中包含卷积层和波段注意力机制,通过对不同波段特征进行注意力计算,增强了模型对相近纤维材质的分类能力。
本发明提出的多阶段定性分类网络包括如下步骤:
(1):给定输入光谱数据,对其进行归一化和标准化,每次输入的采样数据维度为p*1,其中p是近红外光谱数据维度。将一维卷积模块串行组合,设计一个具有四个特征提取模块的一维卷积神经网络,将采样数据输入到特征提取网络;
(2):将采样特征输x输入到特征提取网络第一模块中,首先通过7*1卷积核对x进行卷积,通道个数为64,步长为2,获得一个维度为a*64维度的向量,然后将该向量进行经过两层3*1卷积层,步长为1,通道个数为64,每次卷积后通过Relu激活函数进行激活并进行标准化,得到输出向量x1,维度为a*64,其中a是经过一维卷积后的向量维度。
(3):将特征提取网络模块一的输出向量x1输入到特征提取第二模块中,将该向量进行经过两层3*1卷积层,步长为1,通道个数为128,每次卷积后通过Relu激活函数进行激活并进行标准化,得到输出向量x2,维度为b*128,其中b是经过一维卷积后的向量维度。
(4):将特征提取网络模块一的输出向量x2输入到特征提取第三模块中,将该向量进行经过两层3*1卷积层,步长为1,通道个数为256,每次卷积后通过Relu激活函数进行激活并进行标准化,得到输出向量x3,维度为c*256,其中c是经过一维卷积后的向量维度。
(5):将特征提取网络模块一的输出向量x3输入到特征提取第四模块中,首先将该向量进行经过两层3*1卷积层,步长为1,通道个数为512,每次卷积后通过Relu激活函数进行激活并进行标准化,得到输出向量x4,维度为d*512,其中d是经过一维卷积后的向量维度x4维度。
(6):将该向量x4进行最大池化,获得一个1*512维度的深度特征,然后输入全连接网络,输出第一阶段分类向量,维度为1*K,其中K为第一阶段分类个数。计算第一阶段
损失函数loss1,具体如下:
其中N为第一阶段样本,p为模型输出类别,y为标签类别;
(7):将步骤6获得的d*512维度的向量x4作为深度特征描述子分别输入到第二阶段的六个细粒度分类子网络中,其中模型结构相同,但参数不共享。
(8):将向量x4看做512个维度为d的特征描述子,其中d是经过一维卷积后的向量维度x4的维度。首先通过一个1*1卷积层对特征进行降维,得到x5,输出的特征维度为128*d,作为特征向量H,分别输入到第二阶段分类的K个子网络中。
定义一个可学习的波段特征注意力机制,将特征向量H输入得到注意力权重向量A。具体计算方法如下:
其中tanh为激活函数,V为可学习参数,维度为u*d,其中u是隐藏层维度,d为特征x5的维度;w,维度为u*1,其中u同V的隐藏层维度。k为第二阶段子模型个数。
将得到的权重向量A与x5相乘,获得融合注意力权重的向量V。
(9):将各个子模型获得的编码层向量V输入到一层全连接网络,输出维度为L,表示第二阶段子网络分类个数。并计算第二阶段损失函数loss2,具体方法为:
其中N为第二阶段每个类别样本个数,K第一阶段输出维度,即第二阶段模型各个数,w为每个子模型损失的权重,y为子模型标签值,p为子模型输出值;
(10):将两个阶段的损失函数loss1和loss2相加得到模型最终的损失函数。模型将在预测过程中同时输出一阶段大类分类结果和二阶段细粒度分类结果。
附图说明
图1方法整体流程示意图
图2方法的主要模块示意图
具体实施方式
下面通过实施例进一步说明本发明。
实施例1:
请参看图1,给定输入光谱数据,对其进行归一化和标准化,每次输入的采样数据维度为228*1,其中228是近红外光谱数据维度。将一维卷积模块串行组合,设计一个具有四个特征提取模块的一维卷积神经网络,将采样数据输入到特征提取网络;
将采样特征输入到特征提取网络第一模块中,首先通过7*1卷积核对输入数据进行卷积,通道个数为64,步长为2,获得一个维度为102*64维度的向量,然后将该向量进行经过两层3*1卷积层,步长为1,通道个数为64,每次卷积后通过Relu激活函数进行激活并进行标准化,得到输出向量x1,维度为102*64。
将特征提取网络模块一的输出向量x1输入到特征提取第二模块中,将该向量进行经过两层3*1卷积层,步长为1,通道个数为128,每次卷积后通过Relu激活函数进行激活并进行标准化,得到输出向量x2,维度为51*128。
将特征提取网络模块一的输出向量x2输入到特征提取第三模块中,将该向量进行经过两层3*1卷积层,步长为1,通道个数为256,每次卷积后通过Relu激活函数进行激活并进行标准化,得到输出向量x3,维度为26*256。
将特征提取网络模块一的输出向量x3输入到特征提取第四模块中,首先将该向量进行经过两层3*1卷积层,步长为1,通道个数为512,每次卷积后通过Relu激活函数进行激活并进行标准化,得到输出向量x4,维度为13*512。
将该向量x4进行最大池化,获得一个1*512维度的深度特征,然后输入全连接网络,输出第一阶段分类向量,维度为6,其中6为第一阶段分类个数分别为:
1):棉、麻、人棉组成的组分
2):涤纶、尼龙组成的组分
3):腈纶、羊毛组成的组分
4):包含羊绒的组分
5):包含天丝的组分
6):包含氨纶的组分
请参看图2,在特征提取网络后计算一阶段损失函数loss1,损失函数为步骤6中所示的交叉熵损失。然后将特征输入到第二阶段的细粒度网络中,并进行注意力计算。获得第二阶段的损失并输出结果向量。
将获得的13*512维度的向量x4作为深度特征描述子分别输入到第二阶段的六个细粒度分类子网络中,其中模型结构相同,但参数不共享。
将向量x4看做512个维度为13的特征描述子,其中13是经过一维卷积后的向量维度x4的维度。首先通过一个1*1卷积层对特征进行降维,得到x5,输出的特征维度为128*13,
作为特征向量H,分别输入到第二阶段分类的K个子网络中。
定义一个可学习的波段特征注意力机制,将特征向量H输入得到注意力权重向量A。具体计算方法如下:
其中V为可学习参数,维度为128*13,其中128是隐藏层维度,d为特征x5的维度,值为13;w,维度为128*1。k为第二阶段子模型个数6。
将得到的权重向量A与x5相乘,获得融合注意力权重的向量V。
将各个子模型获得的编码层向量V输入到一层全连接网络,输出第二阶段分类结果。
网络训练过程使用SGD作为优化器,输入图像尺寸为1*228,训练数据批次大小512。学习率从0.005开始,当误差趋于平稳时除以2,衰减率设置为0.0001,动量设置为0.9。
实施例2:
请参看图1,首先给定输入光谱数据,对其进行归一化和标准化,每次输入的采样数据维度为228*3,其中228是近红外光谱数据维度,并将3次采样作为一个输入数据。将一维卷积模块串行组合,设计一个具有四个特征提取模块的一维卷积神经网络,将采样数据输入到特征提取网络;
将采样特征输入到特征提取网络第一模块中,首先通过13*1卷积核对输入数据进行卷积,通道个数为32,步长为1,获得一个维度为102*32维度的向量,然后将该向量进行经过两层3*1卷积层,步长为1,通道个数为64,每次卷积后通过Relu激活函数进行激活并进行标准化,得到输出向量x1,维度为102*32。
将特征提取网络模块一的输出向量x1输入到特征提取第二模块中,将该向量进行经过两层3*1卷积层,步长为1,通道个数为64,每次卷积后通过Relu激活函数进行激活并进行标准化,得到输出向量x2,维度为51*64。
将特征提取网络模块一的输出向量x2输入到特征提取第三模块中,将该向量进行经过两层3*1卷积层,步长为1,通道个数为128,每次卷积后通过Relu激活函数进行激活并进行标准化,得到输出向量x3,维度为26*128。
将特征提取网络模块一的输出向量x3输入到特征提取第四模块中,首先将该向量进行经过两层3*1卷积层,步长为1,通道个数为256,每次卷积后通过Relu激活函数进行激活并进行标准化,得到输出向量x4,维度为13*256。
将该向量x4进行平均池化,获得一个1*256维度的深度特征,然后输入全连接网络,输出第一阶段分类向量,维度为5,其中5为第一阶段分类个数分别为:
1):棉、麻、人棉组成的组分
2):涤纶、尼龙组成的组分
3):腈纶、羊毛、羊绒组成的组分
4):包含天丝、氨纶的组分
5):其他组分
请参看图2,在特征提取网络后计算一阶段损失函数loss1,损失函数为步骤6中所示的交叉熵损失。然后将特征输入到第二阶段的细粒度网络中,并进行注意力计算。获得第二阶段的损失并输出结果向量。
将获得的13*256维度的向量x4作为深度特征描述子分别输入到第二阶段的六个细粒度分类子网络中,其中模型结构相同,但参数不共享。
将向量x4看做256个维度为13的特征描述子,其中13是经过一维卷积后的向量维度x4的维度。首先通过一个1*1卷积层对特征进行降维,得到x5,输出的特征维度为64*13,作为特征向量H,分别输入到第二阶段分类的K个子网络中。
定义一个可学习的波段特征注意力机制,将特征向量H输入得到注意力权重向量A。具体计算方法如下:
其中V为可学习参数,维度为64*13,其中64是隐藏层维度,d为特征x5的维度,值为13;w,维度为64*1。k为第二阶段子模型个数5。
将得到的权重向量A与x5相乘,获得融合注意力权重的向量V。
将各个子模型获得的编码层向量V输入到一层全连接网络,输出第二阶段分类结果。网络训练过程使用SGD作为优化器,输入图像尺寸为3*228,训练数据批次大小512。学习率从0.005开始,当误差趋于平稳时除以2,衰减率设置为0.0001,动量设置为0.9。