教师数据收集装置
文献发布时间:2024-04-18 19:44:28
技术领域
本发明涉及用于收集在具有使用了神经网络的机器学习功能的检查装置等的学习中使用的教师数据的教师数据收集装置。
背景技术
近年来,通过具有使用了神经网络的机器学习功能的检查装置,针对各种工业产品、部件等检查对象物,判定是正常品(合格品)还是异常品(不合格品)的验货作业的自动化技术的开发正在推进。在上述那样的检查装置中,通过读入多个被分类为合格品和不合格品的检查对象物的外观的图像数据来进行学习。而且,通过学习了分类基准的检查装置,能够将由摄像机拍摄的新的检查对象物分类为合格品和不合格品。
如上所述,在检查装置的学习中,使用合格品以及不合格品的图像数据,为了提高检查精度,合格品以及不合格品均需要大量的图像数据。但是,在工业产品等的制造现场,一般以尽可能不产生不合格品的方式进行制造,因此虽然合格品的数量多,但不合格品的数量非常少。因此,与能够比较容易地收集的合格品的图像数据(以下称为“合格品数据”)相比,难以收集不合格品的图像数据(以下称为“不合格品数据”)。
此外,不合格品数据有由熟练者或经验年数长的作业者等专家选定的数据(以下称为“专家数据”)、和由新人或经验年数短的作业者等非专家选定的数据(以下称为“非专家数据”)。作为通过学习上述那样的专家数据以及非专家数据来生成学习模型的技术,已知例如专利文献1所记载的技术。
在该专利文献1中,由知识、经验丰富的专家对“专家数据”进行标签标注,将其规定为标签标注的精度(可靠性)高的教师数据,另一方面,对“非专家数据”进行了标签标注,但将其规定为其精度(可靠性)不明确的教师数据。此外,对于非专家数据,参照专家数据来赋予可靠度。并且,通过使用专家数据和带可靠度的非专家数据进行学习,来生成作为分类模型的学习模型。
在先技术文献
专利文献
专利文献1:日本特开2009-110064号公报
发明内容
发明所要解决的课题
在上述的现有的学习模型的生成方法中,虽然对非专家数据自身的质进行了一定程度的评价,但不能说对专家数据自身的质或量进行了适当的评价。因此,在使用上述的专家数据和带可靠度的非专家数据生成的学习模型中,在专家数据自身的质或量不充分的情况下,学习模型的分类精度变低。此外,专家数据的收集通常比非专家数据的收集花费成本,因此在专家数据的量多到所需以上的情况下,会导致学习模型的生成成本的上升。
本发明为了解决上述课题而作,其目的在于提供一种教师数据收集装置,能够尽可能地减少专家数据,并且收集用于生成具有高分类精度的学习模型的教师数据。
用于解决课题的手段
为了达成上述目的,技术方案1所涉及的发明是收集检查对象物为异常品的、检查对象物的外观图像即不合格品数据作为用于给定学习模型的学习的教师数据的教师数据收集装置,其特征在于,具备:非专家不合格品数据取得单元,其通过非专家的选定来取得不合格品数据;专家不合格品数据取得单元,其通过专家的选定来取得不合格品数据;非专家数据保存部,其保存由非专家不合格品数据取得单元取得的不合格品数据作为非专家数据;专家数据保存部,其保存由专家不合格品数据取得单元取得的不合格品数据作为专家数据;第一标准偏差计算单元,其计算在非专家数据保存部中保存的所有的非专家数据的特征量的标准偏差作为第一标准偏差;第二标准偏差计算单元,其计算在专家数据保存部中保存的所有的专家数据的特征量的标准偏差作为第二标准偏差;第一秩和计算单元,其计算在非专家数据保存部中保存的所有的非专家数据的特征量的秩和作为第一秩和;第二秩和计算单元,其计算在专家数据保存部中保存的所有的专家数据的特征量的秩和作为第二秩和;以及决定单元,其基于第一及第二标准偏差和第一及第二秩和来决定专家不合格品数据取得单元对不合格品数据的取得的继续以及结束。
根据该结构,在通过教师数据收集装置来收集检查对象物的不合格品数据作为教师数据的情况下,由非专家不合格品数据取得单元,通过非专家的选定来取得不合格品数据,该不合格品数据作为非专家数据被保存于非专家数据保存部中。此外,由专家不合格品数据取得单元,通过专家的选定来取得不合格品数据,该不合格品数据作为专家数据被保存于专家数据保存部中。
上述的非专家是新人、验货作业的经验年数短的作业者等,这样的非专家所选定的非专家数据是比较容易发生的不合格品图像。因此,对于所收集到的大量的非专家数据,从各不合格品图像提取特征而得到的值即在变换为特征量的情况下,成为偏在于平均值的附近的分布状态,标准偏差变小。在本发明中,将保存于非专家数据保存部中的所有的非专家数据的特征量的标准偏差计算为第一标准偏差。
另一方面,专家是熟练者、验货作业的经验年数长的作业者等,这样的专家所选定的专家数据是从比较容易发生的到几年发生一次的所有的不合格品图像。因此,在将所收集到的许多个专家数据变换为特征量的情况下,与非专家数据不同,成为整体上无遗漏地扩散的分布状态,标准偏差变大。在本发明中,将保存于专家数据保存部中的所有的专家数据的特征量的标准偏差计算为第二标准偏差。
此外,关于所收集到的大量的非专家数据,例如即使大部分的数据偏在于平均值的附近,在具有一个数据大幅脱离的离群值的情况下,标准偏差也会变大。一般地,最适于学习模型的学习的优质的教师数据优选为从平均到离群值无遗漏地分散有数据的状态。因此,对于所有的非专家数据的特征量,按照值的从小到大的顺序排序,计算该秩和作为第一秩和。另一方面,计算关于所有的专家数据的特征量的秩和作为第二秩和。
基于如以上那样计算出的第一及第二标准偏差、以及第一及第二秩和,由决定单元来决定专家不合格品数据取得单元对不合格品数据的取得的继续以及结束。具体而言,例如,在第一以及第二标准偏差的比(标准偏差比)为给定的基准值以上时,作为专家数据,可以判断为已经收集到网罗了所有的不合格品图像的教师数据。此外,在第一以及第二秩和的比(秩和比)为给定的基准值以上时,作为专家数据,可以判断为已经收集到充分包含在非专家数据中为离群值的数据的教师数据。因此,通过使用上述的标准偏差比以及秩和比,来决定由专家选定的不合格品数据的取得的继续以及结束,能够在尽可能减少专家数据的同时,收集用于生成具有高分类精度的学习模型的教师数据。
技术方案2所涉及的发明的特征在于,在技术方案1所述的教师数据收集装置中,在将第一标准偏差设为α、将第二标准偏差设为β、将第一秩和设为ξ、且将第二秩和设为θ的情况下,决定单元在通过下式(1)计算出的判定系数Vrank为给定值以上时,决定所述专家不合格品数据取得单元对所述不合格品数据的取得的结束,
【数学式1】
根据该结构,使用第一标准偏差α与第二标准偏差β的标准偏差比(β/α)、以及第一秩和ξ与第二秩和θ的秩和比(ξ/θ)而计算出的判定系数Vrank随着标准偏差比以及秩和比变大,值接近1。在该判定系数Vrank为给定值以上时,能够判定作为教师数据而收集到的非专家数据以及专家数据不偏在于作为数据整体的平均附近、并且是适当分散的状态。
附图说明
图1是用于说明在学习中利用由本发明的一个实施方式的教师数据收集装置收集到的教师数据的检查系统的概要的图。
图2是表示本发明的一个实施方式的教师数据收集装置的框图。
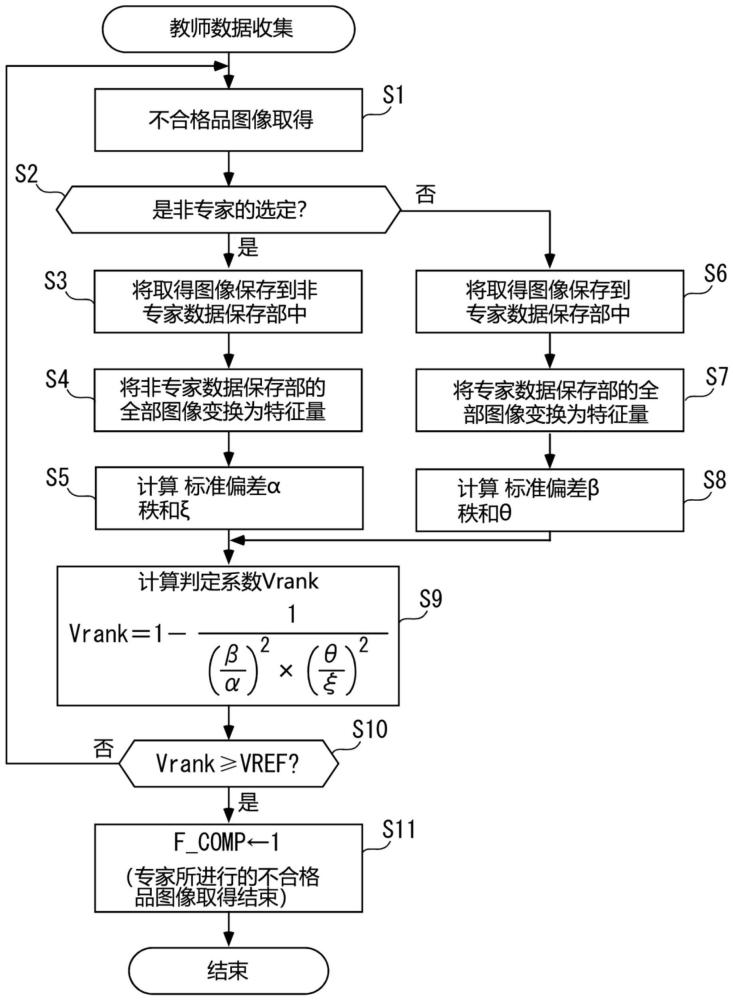
图3是表示教师数据收集装置对教师数据的收集处理的流程图。
图4是表示分类模型的生成处理的流程图。
具体实施方式
以下,参照附图对本发明的优选实施方式详细进行说明。图1示出了具备使用由后述的教师数据收集装置11收集到的许多个不合格品图像的数据(不合格品数据)、以及许多个合格品图像的数据(合格品数据)进行了学习的学习模型的检查系统。该检查系统1例如设置于车辆部件的制造工厂等,通过检查车辆部件的外观来自动地判别所制造的车辆部件(例如缸体)是正常品(合格品)还是异常品(不合格品)。以下,将要检查的车辆部件称为“检查对象物”。
如图1所示,检查系统1具备:输送机2,其沿给定方向以给定速度输送检查对象物G;以及检查装置3,其在检查对象物G到达给定的检查位置时,判定该检查对象物G是否良好。另外,虽然省略图示,但由检查装置3判定为不合格品的检查对象物G从输送机2去除,或者被输送到不合格品专用的保存场所。
检查装置3主要由计算机所构成的信息处理装置构成,具备控制部4、图像取得部5、存储部6、学习部7、输入部8、输出部9以及摄像机10。
控制部4具备CPU,控制检查装置3的上述各部5~9以及摄像机10等。图像取得部5取得由摄像机10拍摄到的检查对象物G的外观图像作为数字数据。存储部6具有ROM以及RAM,存储有在检查装置3的控制中使用的各种程序,并且存储各种数据。学习部7具有学习了用于判别检查对象物G是否良好的基准的学习模型。输入部8具有由作业者操作的键盘、鼠标,并且构成为能够从外部输入数据、信号。输出部9具有显示检查对象物G的判定结果的显示器等显示设备。
图2示出了本发明的一个实施方式的教师数据收集装置11。该教师数据收集装置11用于通过由进行检查对象物G的验货作业的作业者操作来收集不合格品数据。教师数据收集装置11与前述的检查装置3同样,由计算机所构成的信息处理装置构成,具备不合格品图像取得部12(非专家不合格品数据取得单元、专家不合格品数据取得单元)、非专家数据保存部13、专家数据保存部14、特征量变换部15、标准偏差计算部16(第一标准偏差计算单元、第二标准偏差计算单元)、秩和计算部17(第一秩和计算单元、第二秩和计算单元)、判定系数Vrank计算部18、以及不合格品图像取得的继续/结束决定部19(决定单元)。
不合格品图像取得部12针对由与前述的检查装置3的摄像机10同样的摄像机拍摄到的检查对象物G的外观图像,取得由作业者判定为不合格品的图像作为不合格品数据。
非专家数据保存部13保存由非专家(新人、验货作业的经验年数短的作业者)选定的不合格品数据(非专家数据)。另一方面,专家数据保存部14保存由专家(熟练者、验货作业的经验年数长的作业者)选定的不合格品数据(专家数据)。
特征量变换部15将不合格品数据变换为给定的特征量。具体而言,例如使用SIFT(Scale-Invariant Feature Transform:尺度不变特征转换)、CNN(Convolution NeuralNetwork:卷积神经网络),将不合格品数据变换为特征量。
标准偏差计算部针对分别保存于上述的非专家数据保存部13以及专家数据保存部14中的许多个不合格品数据,计算基于特征量的标准偏差。此外,秩和计算部17针对上述的许多个不合格品数据,计算基于特征量的秩和。
如后所述,判定系数Vrank计算部18将非专家数据的标准偏差及秩和、以及专家数据的标准偏差及秩和这4个作为参数,来计算用于判定不合格品图像取得的继续或结束的判定系数Vrank。
不合格品图像取得的继续/结束决定部19根据所计算出的判定系数Vrank,来决定是否继续或者结束不合格品图像的取得。
图3示出了作为上述教师数据收集装置11的教师数据的不合格品图像的收集处理。在本处理中,首先,在步骤1(图示为“S1”。以下相同)中,取得不合格品图像。
接着,在步骤2中,判定所取得的不合格品图像是否为非专家的选定。例如,在非专家操作教师数据收集装置11时,判定为所取得的不合格品图像是非专家的选定,在专家操作教师数据收集装置11时,判定为所取得的不合格品图像是专家的选定。在上述步骤2的判定结果是“是”时,将取得图像保存到非专家数据保存部13中(步骤3)。另外,在非专家选定不合格品图像的情况下,在所选定的不合格品图像是到目前为止没有见过的不合格品图像时,设该不合格品图像为离群值,为了使与专家数据的条件一致,不保存在非专家数据保存部13中。
接着,通过特征量变换部15将非专家数据保存部13的全部图像变换为特征量(步骤4)。另外,除了本次保存在非专家数据保存部13中的不合格品图像以外的不合格品图像已经被预先变换为特征量,因此,在步骤4中,仅将本次取得的不合格品图像变换为特征量。然后,基于非专家数据保存部13所保存的全部图像的特征量,通过标准偏差计算部16以及秩和计算部17来分别计算出标准偏差α(第一标准偏差)以及秩和ξ(第一秩和)(步骤5)。
另一方面,在所述步骤2的判别结果为“否”、本次取得的不合格品图像是由专家选定的图像时,将取得图像保存到专家数据保存部14中(步骤6)。接着,与所述步骤4同样地,将专家数据保存部14的全部图像变换为特征量(步骤7)。然后,基于专家数据保存部14所保存的全部图像的特征量,通过标准偏差计算部16以及秩和计算部17来分别计算标准偏差β(第二标准偏差)以及秩和θ(第二秩和)(步骤8)。
所述步骤5或步骤8的结束后,通过判定系数Vrank计算部18,使用在步骤5以及8中计算出的4个参数即标准偏差α、标准偏差β、秩和ξ以及秩和θ,通过不合格品图像取得的继续/结束决定部19,使用下式(1),来计算判定系数Vrank,
【数学式1】
上式(1)的使用基于标准偏差α以及β的标准偏差比(β/α)、以及基于秩和ξ以及θ的秩和比(ξ/θ)计算出的判定系数Vrank随着标准偏差比以及秩和变大,值接近1。在该判定系数Vrank成为后述的给定值VREF以上时,能够判定作为教师数据而收集到的非专家数据以及专家数据不偏在于作为数据整体的平均附近、并且是适当分散的状态。
在上述步骤10中,判别判定系数Vrank是否为给定值VREF以上。在该判别结果为“否”、判定系数Vrank小于给定值VREF时,视为专家数据尚未足够齐备,而返回至步骤1,继续不合格品图像取得。
另一方面,在步骤10的判别结果为“是”、Vrank≥VREF时,视为专家数据已足够齐备,应完成专家对不合格品图像的收集,而将专家数据取得完成标志F_COMP设定为“1”(步骤11),结束教师数据收集处理。另外,通过对上述标志F_COMP设定“1”,从而在教师数据收集装置11中,通过未图示的显示部等来通知教师数据的收集已完成的情况。
图4示出了在前述的检查系统1中作为检查装置3的学习部7所搭载的学习模型的分类模型的生成处理。在本处理中,从教师数据收集装置11的专家数据保存部14输出所有的数据(专家数据)(步骤21),并且从非专家数据保存部13输出所有或者比专家数据的数量多的给定数量的数据(非专家数据)(步骤22)。接着,将所输出的专家数据与非专家数据结合(步骤23)。由此,生成用于分类模型的生成的许多个不合格品教师数据。
然后,使用所生成的许多个不合格品教师数据与已经收集到的许多个合格品数据(合格品教师数据),使分类模型学习(步骤24)。由此,能够得到分类精度高的分类模型,在检查系统1中,能够高精度地判定检查对象物G是否良好。
如以上详述的那样,根据本实施方式,通过使用基于非专家数据的特征量的标准偏差α和秩和ξ、以及基于专家数据的特征量的标准偏差β和秩和θ,来决定由专家选定的不合格品图像的取得的继续以及结束,由此能够在尽可能减少专家数据的同时,收集用于生成具有高分类精度的学习模型的教师数据。
另外,本发明并不限定于所说明的上述实施方式,能够以各种方式实施。例如,在实施方式中,使用判定系数Vrank,来决定专家对不合格品图像的收集的继续/结束,但也可以通过将第一标准偏差α与第二标准偏差比β的标准偏差比(β/α)、以及第一秩和ξ与第二秩和θ的秩和比(θ/ξ)分别与给定的基准值进行比较,来决定专家对不合格品图像的收集的继续/结束。此外,在实施方式中示出的教师数据收集装置11的细微部分的结构等仅为例示,能够在本发明的主旨的范围内适当变更。
符号说明
1检查系统
2输送机
3检查装置
4控制部
5图像取得部
6存储部
7学习部
8输入部
9输出部
10摄像机
11教师数据收集装置
12不合格品图像取得部(非专家不合格品数据取得单元、专家不合格品数据取得单元)
13非专家数据保存部
14专家数据保存部
15特征量变换部
16标准偏差计算部(第一标准偏差计算单元、第二标准偏差计算单元)
17秩和计算部(第一秩和计算单元、第二秩和计算单元)
18判定系数Vrank计算部
19不合格品图像取得的继续/结束决定部(决定单元)
G检查对象物。