针对不平衡样本数据的数据处理方法及装置
文献发布时间:2023-06-19 11:26:00
技术领域
本发明涉及样本数据处理技术领域,具体而言,涉及一种针对不平衡样本数据的数据处理方法及装置。
背景技术
在一些业务场景中,如果用于建模的样本数据存在严重的不平衡,例如,正类样本远少于负类样本,预测得出的结论往往也是有偏的。样本量少的分类所包含的特征过少,并很难从中提取规律,算法会过多地关注多数类,即分类结果会偏向于较多观测的类,容易产生过度依赖与有限的数据样本而导致过拟合问题,导致模型的泛化能力较弱。当模型应用到新的数据上时,模型的准确性会很差。
发明内容
为了改善上述问题,本发明提供了一种针对不平衡样本数据的数据处理方法及装置。
本发明实施例提供了一种针对不平衡样本数据的数据处理方法,应用于电子设备,所述方法包括以下步骤:
获取建模样本集;其中,所述建模样本集中包括多个原始样本,每个原始样本携带一个样本标签,所述样本标签为第一样本标签或第二样本标签;
对所述建模样本进行切分,得到待处理样本集和跨时间验证样本集;确定所述待处理样本集中携带第一样本标签的第一目标样本,根据所述第一目标样本构造第二目标样本,并将所述第一目标样本和所述第二目标样本进行整合得到采样样本集;
对所述采样样本集进行切分,得到训练样本集和测试样本集;通过所述训练样本集进行建模得到第一预测模型,基于所述测试样本集确定所述第一预测模型的第一模型性能分布;
通过所述采样样本集进行建模得到第二预测模型,基于所述采样样本集确定第一预测模型的第二模型性能分布;
根据所述第一模型性能分布、所述第二模型性能分布以及所述跨时间验证样本集确定所述采样样本集是否满足设定条件。
可选地,根据所述第一模型性能分布、所述第二模型性能分布以及所述跨时间验证样本集确定所述采样样本集是否满足设定条件,包括:
判断所述第一模型性能分布和所述第二模型性能分布是否满足预设模型性能指标;
在所述第一模型性能分布和所述第二模型性能分布满足所述预设模型性能指标时,基于所述跨时间验证样本集确定所述第一预测模型的第三模型性能分布以及所述第二预测模型的第四模型性能分布;
判断所述第三模型性能分布和所述第四模型性能分布是否满足预设模型性能指标;
在所述第三模型性能分布和所述第四模型性能分布满足所述预设模型性能指标时,判定所述采样样本集满足建模条件。
可选地,根据所述第一目标样本构造第二目标样本,包括:
计算每个所述第一目标样本的K个近邻;其中,K为正整数;
从所述K个近邻中挑选出N个近邻样本;其中,N为正整数;
对所述N个近邻样本进行随机线性插值,得到多个第二目标样本。
可选地,通过所述采样样本集进行建模得到第二预测模型,基于所述采样样本集确定第二预测模型的第二模型性能分布,包括:
通过对所述采样样本集进行分层采样,得到设定数量个互斥子集;
重复执行以下步骤直至得到设定数量个第二模型性能分布:将所述设定数量个互斥子集中的其中一个互斥子集作为测试子集,将所述设定数量个互斥子集中除所述测试子集之外的剩余互斥子集求并集以作为训练子集;通过所述训练子集进行建模得到第二预测模型,基于所述测试样本子集确定所述第二预测模型的第二模型性能分布。
可选地,对所述建模样本进行切分,得到待处理样本集和跨时间验证样本集,包括:
按照第一设定比例对所述建模样本进行切分,得到待处理样本集和跨时间验证样本集。
可选地,对所述采样样本集进行切分,得到训练样本集和测试样本集,包括:
按照第二设定比例对所述采样样本集进行切分,得到训练样本集和测试样本集。
可选地,判断所述第一模型性能分布和所述第二模型性能分布是否满足预设模型性能指标,包括:
确定第一模型性能分布对应的第一性能属性关联列表,确定第二模型性能分布对应的第二性能属性关联列表,以及统计所述第一性能属性关联列表和所述第二性能属性关联列表中分别包括的多个具有不同属性标签识别度的属性关联元素;
提取所述第一模型性能分布在所述第一性能属性关联列表的任一属性关联元素的初始元素描述数据,并将所述第二性能属性关联列表中具有最小属性标签识别度的属性关联元素确定为目标属性关联元素;
依据所述第一模型性能分布和所述第二模型性能分布的性能分布融合结果,将所述初始元素描述数据映射到所述目标属性关联元素,在所述目标属性关联元素中得到初始元素映射数据;在得到所述初始元素映射数据之后,基于所述初始元素描述数据以及所述初始元素映射数据,生成所述第一模型性能分布和所述第二模型性能分布之间的性能指标融合清单;
以所述初始元素映射数据为基准数据在所述目标属性关联元素中获取性能指向数据,根据所述性能指标融合清单对应的指标融合路径列表,将所述性能指向数据映射到所述初始元素描述数据所在属性关联元素,在所述初始元素描述数据所在属性关联元素中得到所述性能指向数据对应的性能评价数据,并确定所述性能评价数据的指标评价数据;
获取所述初始元素描述数据映射到所述目标属性关联元素中的数据映射路径;根据所述性能评价数据与所述数据映射路径上的多个待处理路径节点对应的路径封装数据之间的相关性系数,在所述第二性能属性关联列表中逐层依次获取所述指标评价数据对应的性能指标描述值,直至获取到的所述性能指标描述值所在属性关联元素的元素热度值与所述指标评价数据在所述第一性能属性关联列表中的元素热度值一致时,停止获取下一属性关联元素中的性能指标描述值,并建立所述指标评价数据与最后一次获取到的性能指标描述值之间的描述值队列;计算所述描述值队列的第一指标系数;判读所述第一指标系数是否达到所述预设模型性能指标对应的第二指标系数;在所述第一指标系数达到所述预设模型性能指标对应的第二指标系数的前提下,判定所述第一模型性能分布和所述第二模型性能分布满足所述预设模型性能指标;在所述第一指标系数未达到所述预设模型性能指标对应的第二指标系数的前提下,判定所述第一模型性能分布和所述第二模型性能分布不满足所述预设模型性能指标。
本发明实施例还提供了一种针对不平衡样本数据的数据处理装置,应用于电子设备,所述装置包括以下模块:
样本获取模块,用于获取建模样本集;其中,所述建模样本集中包括多个原始样本,每个原始样本携带一个样本标签,所述样本标签为第一样本标签或第二样本标签;
样本切分模块,用于对所述建模样本进行切分,得到待处理样本集和跨时间验证样本集;确定所述待处理样本集中携带第一样本标签的第一目标样本,根据所述第一目标样本构造第二目标样本,并将所述第一目标样本和所述第二目标样本进行整合得到采样样本集;
性能确定模块,用于对所述采样样本集进行切分,得到训练样本集和测试样本集;通过所述训练样本集进行建模得到第一预测模型,基于所述测试样本集确定所述第一预测模型的第一模型性能分布;通过所述采样样本集进行建模得到第二预测模型,基于所述采样样本集确定第一预测模型的第二模型性能分布;
样本判断模块,用于根据所述第一模型性能分布、所述第二模型性能分布以及所述跨时间验证样本集确定所述采样样本集是否满足设定条件。
可选地,所述样本判断模块,具体用于:
判断所述第一模型性能分布和所述第二模型性能分布是否满足预设模型性能指标;
在所述第一模型性能分布和所述第二模型性能分布满足所述预设模型性能指标时,基于所述跨时间验证样本集确定所述第一预测模型的第三模型性能分布以及所述第二预测模型的第四模型性能分布;
判断所述第三模型性能分布和所述第四模型性能分布是否满足预设模型性能指标;
在所述第三模型性能分布和所述第四模型性能分布满足所述预设模型性能指标时,判定所述采样样本集满足建模条件。
可选地,所述样本判断模块,进一步用于:
确定第一模型性能分布对应的第一性能属性关联列表,确定第二模型性能分布对应的第二性能属性关联列表,以及统计所述第一性能属性关联列表和所述第二性能属性关联列表中分别包括的多个具有不同属性标签识别度的属性关联元素;
提取所述第一模型性能分布在所述第一性能属性关联列表的任一属性关联元素的初始元素描述数据,并将所述第二性能属性关联列表中具有最小属性标签识别度的属性关联元素确定为目标属性关联元素;
依据所述第一模型性能分布和所述第二模型性能分布的性能分布融合结果,将所述初始元素描述数据映射到所述目标属性关联元素,在所述目标属性关联元素中得到初始元素映射数据;在得到所述初始元素映射数据之后,基于所述初始元素描述数据以及所述初始元素映射数据,生成所述第一模型性能分布和所述第二模型性能分布之间的性能指标融合清单;
以所述初始元素映射数据为基准数据在所述目标属性关联元素中获取性能指向数据,根据所述性能指标融合清单对应的指标融合路径列表,将所述性能指向数据映射到所述初始元素描述数据所在属性关联元素,在所述初始元素描述数据所在属性关联元素中得到所述性能指向数据对应的性能评价数据,并确定所述性能评价数据的指标评价数据;
获取所述初始元素描述数据映射到所述目标属性关联元素中的数据映射路径;根据所述性能评价数据与所述数据映射路径上的多个待处理路径节点对应的路径封装数据之间的相关性系数,在所述第二性能属性关联列表中逐层依次获取所述指标评价数据对应的性能指标描述值,直至获取到的所述性能指标描述值所在属性关联元素的元素热度值与所述指标评价数据在所述第一性能属性关联列表中的元素热度值一致时,停止获取下一属性关联元素中的性能指标描述值,并建立所述指标评价数据与最后一次获取到的性能指标描述值之间的描述值队列;计算所述描述值队列的第一指标系数;判读所述第一指标系数是否达到所述预设模型性能指标对应的第二指标系数;在所述第一指标系数达到所述预设模型性能指标对应的第二指标系数的前提下,判定所述第一模型性能分布和所述第二模型性能分布满足所述预设模型性能指标;在所述第一指标系数未达到所述预设模型性能指标对应的第二指标系数的前提下,判定所述第一模型性能分布和所述第二模型性能分布不满足所述预设模型性能指标
本发明所提供的针对不平衡样本数据的数据处理方法及装置,能够基于第一目标样本构造第二目标样本,并将第一目标样本和第二目标样本进行整合得到采样样本集,本方案的扩充样本的方法避免了简单的欠采样技术导致的信息丢失的问题,在样本较少的情况下,也不会加剧少样本的问题。此外,本方案的扩充样本的方法也不会产生如简单的过采样技术一样的由于生成重复样本而出现的过拟合的问题。如此,能够实现对不平衡样本的处理,使得两类不同样本的数量处于一个合理的比例。在利用上述方案确定得到的采样样本集进行建模并应用到业务场景时,能够避免样本过拟合问题,提高模型的泛化能力,从而提高对业务分类处理的准确性。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
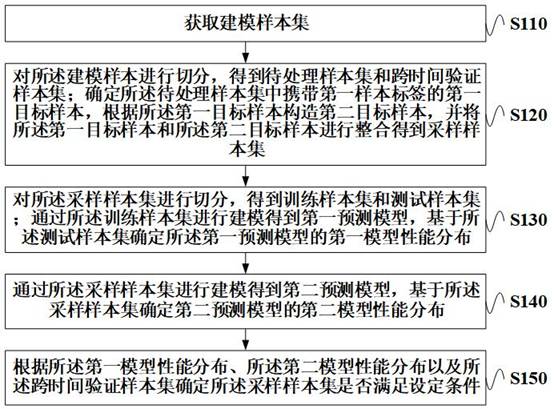
图1为本发明实施例所提供的一种针对不平衡样本数据的数据处理方法的流程图。
图2为本发明实施例所提供的一种针对不平衡样本数据的数据处理装置的模块框图。
具体实施方式
为了更好的理解上述技术方案,下面通过附图以及具体实施例对本发明技术方案做详细的说明,应当理解本发明实施例以及实施例中的具体特征是对本发明技术方案的详细的说明,而不是对本发明技术方案的限定,在不冲突的情况下,本发明实施例以及实施例中的技术特征可以相互组合。
发明人发现,常见的对原始样本进行采样处理方法分为两类,一类是欠采样,另一类是过采样。
欠采样是将多的那一类砍掉一部分,使得两类样本数量接近;但砍掉的数据会导致某些隐含信息的丢失,样本建模的时候只能学习到一部分的信息,如果整体样本数量较少,欠采样方法会加剧样本数量少的问题。
过采样则是将少的那一类进行有放回的抽样,通过增加较少的逾期类样本,使得两类样本保持平衡;但是有放回的抽样形成的简单复制,没有增加训练数据集的信息量,重复的样本会使得风控模型倾向于复制出来的样本具有的特征,会使模型产生过拟合。
本发明实施例的业务场景可以以信贷业务场景为例进行说明,在信贷业务场景下,简单的样本欠采样方法需要砍掉部分多数类样本数据,信贷样本数据通常包含个人身份信息、申请行为信息、消费记录信息、资产信息等多维度的信息,由于需要砍掉部分多数类样本数据,而这部分砍掉的数据可能包含这样的隐藏信息:即某些维度的信息与是否逾期会有很强的相关性;但是由于部分数据被砍掉,很可能导致这种相关性因数据的减少而降低,从而导致这种隐含信息的丢失,样本建模的时候就无法学习到这样的信息。如果整体样本数量较少,欠采样方法会加剧样本数量少的问题。本发明避免了信贷风控场景下的样本欠采样导致的信息丢失的发生,在样本较少的情况下,也不会加剧少样本的问题。
为改善上述问题,本发明提供的针对不平衡样本数据的数据处理方法及装置能够在采样的过程中尽可能保证两类样本的平衡,同时减少对样本的改变,避免对模型产生干扰。
请首先参阅图1示出了针对不平衡样本数据的数据处理方法的流程图,所述方法应用于电子设备,具体可以包括以下步骤S110步骤S150所描述的内容。
步骤S110,获取建模样本集。
例如,所述建模样本集中包括多个原始样本,每个原始样本携带一个样本标签,所述样本标签为第一样本标签或第二样本标签。
原始样本可以为信贷数据样本,第一样本标签可以指代样本具有逾期行为,即少数类样本。第二样本标签指代样本无逾期行为,即多数类样本。第一样本标签可以为“1”,第二样本标签可以为“0”。
步骤S120,对所述建模样本进行切分,得到待处理样本集和跨时间验证样本集;确定所述待处理样本集中携带第一样本标签的第一目标样本,根据所述第一目标样本构造第二目标样本,并将所述第一目标样本和所述第二目标样本进行整合得到采样样本集。
步骤S130,对所述采样样本集进行切分,得到训练样本集和测试样本集;通过所述训练样本集进行建模得到第一预测模型,基于所述测试样本集确定所述第一预测模型的第一模型性能分布。
步骤S140,通过所述采样样本集进行建模得到第二预测模型,基于所述采样样本集确定第二预测模型的第二模型性能分布。
步骤S150,根据所述第一模型性能分布、所述第二模型性能分布以及所述跨时间验证样本集确定所述采样样本集是否满足设定条件。
通过执行上述步骤S110-步骤S150,能够基于第一目标样本构造第二目标样本,并将第一目标样本和第二目标样本进行整合得到采样样本集,本方案的扩充样本的方法避免了简单的欠采样技术导致的信息丢失的问题,在样本较少的情况下,也不会加剧少样本的问题。此外,本方案的扩充样本的方法也不会产生如简单的过采样技术一样的由于生成重复样本而出现的过拟合的问题。如此,能够实现对不平衡样本的处理,使得两类不同样本的数量处于一个合理的比例。在利用上述方案确定得到的采样样本集进行建模并应用到业务场景时,能够避免样本过拟合问题,提高模型的泛化能力,从而提高对业务分类处理的准确性。
在一些示例中,步骤S150所描述的根据所述第一模型性能分布、所述第二模型性能分布以及所述跨时间验证样本集确定所述采样样本集是否满足设定条件,可以包括以下步骤S151-步骤S154所描述的内容。
步骤S151,判断所述第一模型性能分布和所述第二模型性能分布是否满足预设模型性能指标。
步骤S152,在所述第一模型性能分布和所述第二模型性能分布满足所述预设模型性能指标时,基于所述跨时间验证样本集确定所述第一预测模型的第三模型性能分布以及所述第二预测模型的第四模型性能分布。
步骤S153,判断所述第三模型性能分布和所述第四模型性能分布是否满足预设模型性能指标。
步骤S154,在所述第三模型性能分布和所述第四模型性能分布满足所述预设模型性能指标时,判定所述采样样本集满足建模条件。
可以理解,在当采样样本集满足建模条件时,采样样本集可以用于建模,建模得到的二分类模型可以应用于多个信贷业务场景下,具有较佳的泛化能力。
在一些示例中,步骤S120所描述的根据所述第一目标样本构造第二目标样本,进一步可以包括以下步骤S121-步骤S123所描述的内容。
步骤S121,计算每个所述第一目标样本的K个近邻;其中,K为正整数。
步骤S122,从所述K个近邻中挑选出N个近邻样本;其中,N为正整数。
步骤S123,对所述N个近邻样本进行随机线性插值,得到多个第二目标样本。
例如,采用最邻近算法(通过欧式距离、曼哈顿距离或明可夫斯基距离等距离度量找出样本附近最近的一些样本),计算出每个少数类样本的K个近邻,从K个近邻中随机挑选N个样本进行随机线性插值,构造新的少数类样本,将新样本与原数据合成,产生新的样本集,也即采样样本集。
上述采样方法为smote过采样方法,该方法基于最邻近算法(通过欧式距离、曼哈顿距离或明可夫斯基距离等距离度量找出样本附近最近的一些样本),最近邻的原则上是先找出距离新点(预测点)最近的预定数量的训练样本,继而预测其所属的标签。样本数可以是用户所定义的常数(本发明使用的即为K近邻算法),或基于点的局部密度而变化的值(基于半径的近邻学习)。近邻的距离通常是可以通过任何度量方式来测量:一般使用标准欧几里得距离来判断点与点的距离。
可选地,步骤S140所描述的通过所述采样样本集进行建模得到第二预测模型,基于所述采样样本集确定第二预测模型的第二模型性能分布,进一步包括以下内容:通过对所述采样样本集进行分层采样,得到设定数量个互斥子集;重复执行以下步骤直至得到设定数量个第二模型性能分布:将所述设定数量个互斥子集中的其中一个互斥子集作为测试子集,将所述设定数量个互斥子集中除所述测试子集之外的剩余互斥子集求并集以作为训练子集;通过所述训练子集进行建模得到第二预测模型,基于所述测试样本子集确定所述第二预测模型的第二模型性能分布。其中,设定数量可以为10。
在步骤S120中,对所述建模样本进行切分,得到待处理样本集和跨时间验证样本集,包括:按照第一设定比例对所述建模样本进行切分,得到待处理样本集和跨时间验证样本集。其中,第一设定比例可以为8:2或9:1。
在步骤S120中,对所述采样样本集进行切分,得到训练样本集和测试样本集,包括:按照第二设定比例对所述采样样本集进行切分,得到训练样本集和测试样本集。其中,第二设定比例可以为7:3。
在一个可替换的实施例中,为了确保对第一模型性能分布以及第二模型性能分布的准确可靠判定,步骤S151所描述的判断所述第一模型性能分布和所述第二模型性能分布是否满足预设模型性能指标,进一步可以包括以下步骤S1511-步骤S1515所描述的内容。
步骤S1511,确定第一模型性能分布对应的第一性能属性关联列表,确定第二模型性能分布对应的第二性能属性关联列表,以及统计所述第一性能属性关联列表和所述第二性能属性关联列表中分别包括的多个具有不同属性标签识别度的属性关联元素。
步骤S1512,提取所述第一模型性能分布在所述第一性能属性关联列表的任一属性关联元素的初始元素描述数据,并将所述第二性能属性关联列表中具有最小属性标签识别度的属性关联元素确定为目标属性关联元素。
步骤S1513,依据所述第一模型性能分布和所述第二模型性能分布的性能分布融合结果,将所述初始元素描述数据映射到所述目标属性关联元素,在所述目标属性关联元素中得到初始元素映射数据;在得到所述初始元素映射数据之后,基于所述初始元素描述数据以及所述初始元素映射数据,生成所述第一模型性能分布和所述第二模型性能分布之间的性能指标融合清单。
步骤S1514,以所述初始元素映射数据为基准数据在所述目标属性关联元素中获取性能指向数据,根据所述性能指标融合清单对应的指标融合路径列表,将所述性能指向数据映射到所述初始元素描述数据所在属性关联元素,在所述初始元素描述数据所在属性关联元素中得到所述性能指向数据对应的性能评价数据,并确定所述性能评价数据的指标评价数据。
步骤S1515,获取所述初始元素描述数据映射到所述目标属性关联元素中的数据映射路径;根据所述性能评价数据与所述数据映射路径上的多个待处理路径节点对应的路径封装数据之间的相关性系数,在所述第二性能属性关联列表中逐层依次获取所述指标评价数据对应的性能指标描述值,直至获取到的所述性能指标描述值所在属性关联元素的元素热度值与所述指标评价数据在所述第一性能属性关联列表中的元素热度值一致时,停止获取下一属性关联元素中的性能指标描述值,并建立所述指标评价数据与最后一次获取到的性能指标描述值之间的描述值队列;计算所述描述值队列的第一指标系数;判读所述第一指标系数是否达到所述预设模型性能指标对应的第二指标系数;在所述第一指标系数达到所述预设模型性能指标对应的第二指标系数的前提下,判定所述第一模型性能分布和所述第二模型性能分布满足所述预设模型性能指标;在所述第一指标系数未达到所述预设模型性能指标对应的第二指标系数的前提下,判定所述第一模型性能分布和所述第二模型性能分布不满足所述预设模型性能指标。
可以理解,通过执行上述步骤S1511-步骤S1515,确保对第一模型性能分布以及第二模型性能分布的准确可靠判定。
此外,请参阅图2,示出了一种针对不平衡样本数据的数据处理装置200,应用于电子设备,所述装置包括以下模块:
样本获取模块210,用于获取建模样本集;其中,所述建模样本集中包括多个原始样本,每个原始样本携带一个样本标签,所述样本标签为第一样本标签或第二样本标签;
样本切分模块220,用于对所述建模样本进行切分,得到待处理样本集和跨时间验证样本集;确定所述待处理样本集中携带第一样本标签的第一目标样本,根据所述第一目标样本构造第二目标样本,并将所述第一目标样本和所述第二目标样本进行整合得到采样样本集;
性能确定模块230,用于对所述采样样本集进行切分,得到训练样本集和测试样本集;通过所述训练样本集进行建模得到第一预测模型,基于所述测试样本集确定所述第一预测模型的第一模型性能分布;通过所述采样样本集进行建模得到第二预测模型,基于所述采样样本集确定第一预测模型的第二模型性能分布;
样本判断模块240,用于根据所述第一模型性能分布、所述第二模型性能分布以及所述跨时间验证样本集确定所述采样样本集是否满足设定条件。
可选的,所述样本判断模块240,具体用于:
判断所述第一模型性能分布和所述第二模型性能分布是否满足预设模型性能指标;
在所述第一模型性能分布和所述第二模型性能分布满足所述预设模型性能指标时,基于所述跨时间验证样本集确定所述第一预测模型的第三模型性能分布以及所述第二预测模型的第四模型性能分布;
判断所述第三模型性能分布和所述第四模型性能分布是否满足预设模型性能指标;
在所述第三模型性能分布和所述第四模型性能分布满足所述预设模型性能指标时,判定所述采样样本集满足建模条件。
可选的,所述样本判断模块240,进一步用于:
确定第一模型性能分布对应的第一性能属性关联列表,确定第二模型性能分布对应的第二性能属性关联列表,以及统计所述第一性能属性关联列表和所述第二性能属性关联列表中分别包括的多个具有不同属性标签识别度的属性关联元素;
提取所述第一模型性能分布在所述第一性能属性关联列表的任一属性关联元素的初始元素描述数据,并将所述第二性能属性关联列表中具有最小属性标签识别度的属性关联元素确定为目标属性关联元素;
依据所述第一模型性能分布和所述第二模型性能分布的性能分布融合结果,将所述初始元素描述数据映射到所述目标属性关联元素,在所述目标属性关联元素中得到初始元素映射数据;在得到所述初始元素映射数据之后,基于所述初始元素描述数据以及所述初始元素映射数据,生成所述第一模型性能分布和所述第二模型性能分布之间的性能指标融合清单;
以所述初始元素映射数据为基准数据在所述目标属性关联元素中获取性能指向数据,根据所述性能指标融合清单对应的指标融合路径列表,将所述性能指向数据映射到所述初始元素描述数据所在属性关联元素,在所述初始元素描述数据所在属性关联元素中得到所述性能指向数据对应的性能评价数据,并确定所述性能评价数据的指标评价数据;
获取所述初始元素描述数据映射到所述目标属性关联元素中的数据映射路径;根据所述性能评价数据与所述数据映射路径上的多个待处理路径节点对应的路径封装数据之间的相关性系数,在所述第二性能属性关联列表中逐层依次获取所述指标评价数据对应的性能指标描述值,直至获取到的所述性能指标描述值所在属性关联元素的元素热度值与所述指标评价数据在所述第一性能属性关联列表中的元素热度值一致时,停止获取下一属性关联元素中的性能指标描述值,并建立所述指标评价数据与最后一次获取到的性能指标描述值之间的描述值队列;计算所述描述值队列的第一指标系数;判读所述第一指标系数是否达到所述预设模型性能指标对应的第二指标系数;在所述第一指标系数达到所述预设模型性能指标对应的第二指标系数的前提下,判定所述第一模型性能分布和所述第二模型性能分布满足所述预设模型性能指标;在所述第一指标系数未达到所述预设模型性能指标对应的第二指标系数的前提下,判定所述第一模型性能分布和所述第二模型性能分布不满足所述预设模型性能指标。
综上,本发明所提供的针对不平衡样本数据的数据处理方法及装置,能够基于第一目标样本构造第二目标样本,并将第一目标样本和第二目标样本进行整合得到采样样本集,本方案的扩充样本的方法避免了简单的欠采样技术导致的信息丢失的问题,在样本较少的情况下,也不会加剧少样本的问题。此外,本方案的扩充样本的方法也不会产生如简单的过采样技术一样的由于生成重复样本而出现的过拟合的问题。如此,能够实现对不平衡样本的处理,使得两类不同样本的数量处于一个合理的比例。在利用上述方案确定得到的采样样本集进行建模并应用到业务场景时,能够避免样本过拟合问题,提高模型的泛化能力,从而提高对业务分类处理的准确性。
以上仅为本申请的实施例而已,并不用于限制本申请。对于本领域技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本申请的权利要求范围之内。