基于多资源的语音点播歌曲方法及装置
文献发布时间:2023-06-19 09:29:07
技术领域
本发明涉及歌曲点播技术领域,特别是涉及一种基于多资源的语音点播歌曲方法、装置及存储介质。
背景技术
语音识别技术,也被称为自动语音识别、电脑语音识别或是语音转文本识别,其目标是以电脑自动将人类的语音内容转换为相应的文字。与说话人识别及说话人确认不同,后者尝试识别或确认发出语音的说话人而非其中所包含的词汇内容。
目前语音识别技术的应用已较为成熟,应用于很多方面,例如语音拨号、语音导航、室内设备控制、语音文档检索、简单的听写数据录入等。而随着人们生活水平的提高,对娱乐生活的追求,以及“解放双手”的极致追求,语音点播成了语音识别的一大重点领域。
与触屏点播歌曲相比,语音点播歌曲摆脱了界面的束缚,可以让用户完全根据个人习惯完成歌曲的检索播放,但由于人类语言交流的复杂性,大大增加了点播歌曲的难度,通过自然语言点播的方式要更加灵活和广泛,才能满足各种用户不同的语言模式和点歌习惯。
公开号为CN107247768A的中国专利申请公开了一种语音点歌方法、装置、终端及存储介质,其方法如下:接收用户输入的语音信息;对语音信息进行语音识别,得到语音识别结果;将语音识别结果与预设的维度数据库进行比对,获取该语音识别结果中的维度数据及其对应的维度类别,其中维度数据库用于存储各音乐资源在不同维度类别下的维度数据;根据维度数据及其对应的维度类别检索并输出对应的音乐资源,该专利申请通过维度数据库存储各音乐资源对应于不同维度类别的维度数据,支持多维度语音点歌,提高语音点歌方式的灵活度,满足用户多维度的点歌需求,然而,在该专利申请中,资源库使用自带的数据库,而实际应用中,歌曲的版权已经被腾讯和网易等大公司所购买,本地很难也无法存储大量歌曲数据,因此,该方案只适用于本身拥有了很多资源库的企业或团体,不具有普遍适用性。
发明内容
为克服上述现有技术存在的不足,本发明之目的在于提供一种基于多资源的语音点播歌曲方法及装置,以实现基于本地资源库和网路开放平台的语音下载播放,实现根据用户语音数据,自动选择本地资源库和网络开放平台的数据进行播放,同时对本地资源自动淘汰更新,提高资源利用率。
为达上述及其它目的,本发明提出一种基于多资源的语音点播歌曲方法,包括如下步骤:
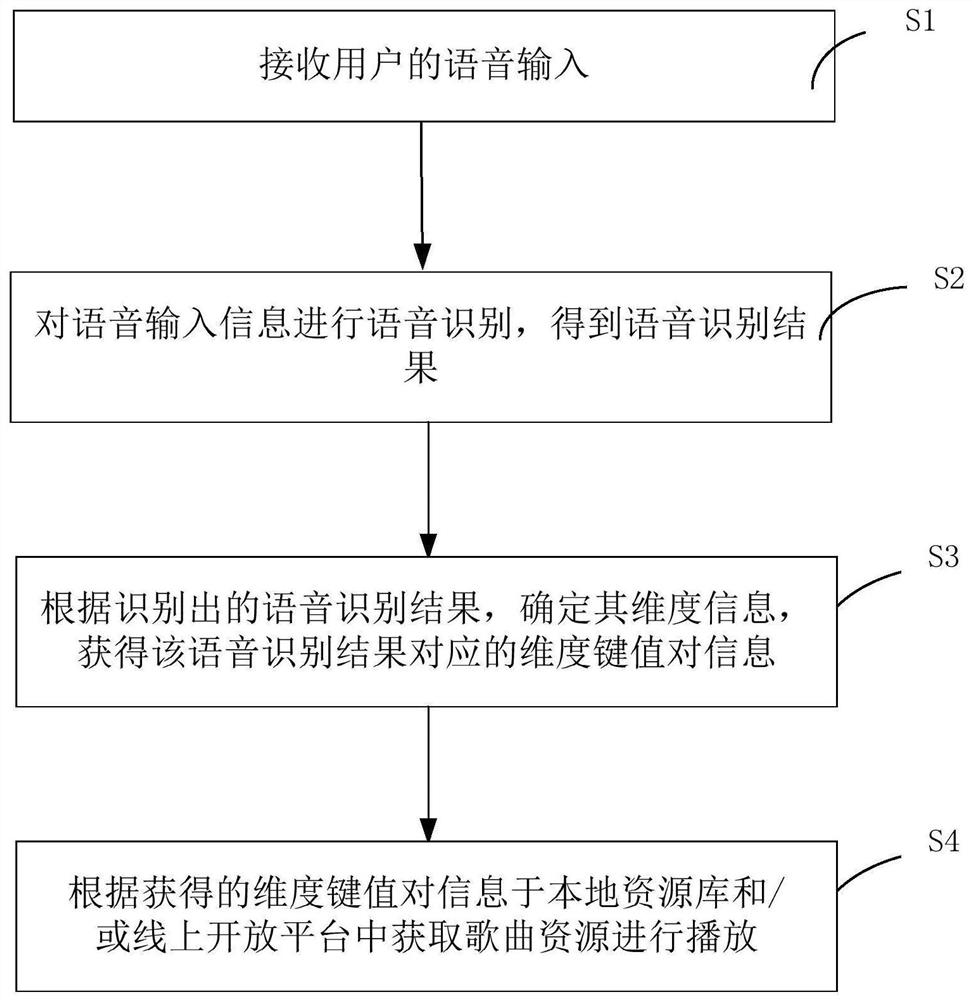
步骤S1,接收用户的语音输入;
步骤S2,对语音输入信息进行语音识别,得到语音识别结果;
步骤S3,根据识别出的语音识别结果,确定其维度信息,获得该语音识别结果对应的维度键值对信息;
步骤S4,根据获得的维度键值对信息于本地资源库和/或线上开放平台中获取歌曲资源进行播放。
优选地,步骤S4进一步包括:
步骤S400,将得到的维度键值对与本地资源库中各歌曲的维度信息进行一一对比,以于所述本地资源库获取对应的歌曲资源;
步骤S401,当于所述本地资源库中未找到符合要求的数据,则将所述维度键值对进行解析,将其自动嵌入各开放平台的API请求URL中,并对其返回结果进行解析,根据返回的结果数据中的资源下载链接将歌曲数据下载至本地,同时存储相应歌曲数据的维度信息,设定其用户播放次数。
优选地,于步骤S400中,在本地资源库中进行维度信息比对时,根据预设的维度信息比对顺序进行比对。
优选地,于步骤S400中,当比对搜索出符合要求的结果有多个,则根据结果中各歌曲的播放次数进行降序排列,获取第一条歌曲作为获得的歌曲资源进行播放,同时将该条歌曲记录的用户播放次数加一,并更新访问时间。
优选地,对本地资源库的存储定期执行淘汰机制,根据用户播放次数将超出最大保存容量的歌曲资源实行末位淘汰,若多个末位歌曲资源的访问次数都相同,则根据LRU淘汰策略,淘汰掉最近最少使用的歌曲资源。
优选地,于步骤S401中,当于所述本地资源库未找到符合要求的歌曲数据,则启动线上搜索,同时启动对多个开放平台的搜索,将解析出的键值对组合,自动嵌入每个开放平台对应的URL中,并根据匹配结果和返回的资源文件大小将返回结果排序,将排序第一的歌曲文件下载至本地资源库。
优选地,步骤S401包括:
基于开放平台URL将歌曲维度信息填充进URL中对应的字段,并对其发起请求,获取歌曲列表,将其保存至本地;
读取歌曲列表,对其解析并获取第一条歌曲数据,将其唯一歌曲ID保存至本地,将歌曲ID拼接进歌曲下载URL对开放平台发送请求,将返回值保存至本地;
对保存的歌曲链接进行解析,获得歌曲的下载链接地址,根据该下载链接地址,返回对应歌曲的歌曲数据文件,并将其文件保存于本地资源库中,存储歌曲数据的维度信息,将其用户播放次数设定为1。
优选地,于步骤401中,当存在多个开放平台均返回歌曲数据文件时,则对比输入维度键值对信息与各平台返回值的匹配程度,根据匹配程度选择歌曲资源下载到本地资源库。
优选地,当返回的歌曲数据文件维度都相同时,选择文件资源大小最小的歌曲数据文件下载到本地资源库进行保存。
为达到上述目的,本发明还提供一种基于多资源的语音点播歌曲装置,包括:
语音接收模块,用于接收用户的语音输入;
语音识别模块,用于对语音输入信息进行语音识别,得到语音识别结果;
维度分析模块,用于根据识别出的语音识别结果,确定其维度信息,获得该语音识别结果对应的维度键值对信息;
资源获取模块,用于根据获得的维度键值对信息于本地资源库和/或线上开放平台中获取歌曲资源;
播放模块,用于根据所述资源获取模块的结果,播放相应的歌曲资源。
与现有技术相比,本发明一种基于多资源的语音点播歌曲方法及装置通过利用本地资源库和多个云端资源开放平台相结合,降低了请求云端的次数和网络IO的次数,提升了用户体验,减少了资源消耗;本发明所述系统的搭载设备可为手机,平板,PC等多个设备,且可根据不同设备的系统存储等硬件情况设置不同的本地资源库所占存储区大小,实现了多平台搭建,不因系统(macOS,Windows),浏览器(Firefox,Chrome,edge等)的限制而无法使用。
附图说明
图1为本发明一种基于多资源的语音点播歌曲方法的步骤流程图;
图2为本发明一种基于多资源的语音点播歌曲装置的系统架构图;
图3为本发明实施例的流程图。
具体实施方式
以下通过特定的具体实例并结合附图说明本发明的实施方式,本领域技术人员可由本说明书所揭示的内容轻易地了解本发明的其它优点与功效。本发明亦可通过其它不同的具体实例加以施行或应用,本说明书中的各项细节亦可基于不同观点与应用,在不背离本发明的精神下进行各种修饰与变更。
图1为本发明一种基于多资源的语音点播歌曲方法的步骤流程图。如图1所示,本发明一种基于多资源的语音点播歌曲方法,包括如下步骤:
步骤S1,接收用户的语音输入。
在本发明具体实施例中,本发明之基于多资源的语音点播歌曲方法可应用于用户随身携带的移动设备,例如智能手机,可移动设备自带的麦克风或外接的耳机麦克风接收用户的语音输入,例如,用户输入语音“王力宏的心中的日月”“播放陈奕迅的浮夸”等。
步骤S2对语音输入信息进行语音识别,得到语音识别结果。
其中,语音识别结果可以是文字信息,具体可以使用现有的语音识别方法进行语音识别,例如,基于动态时间规整的算法、基于参数模型的隐马尔可夫法、基于非参数模型的矢量量化法、基于人工神经网络的算法等,由于语音识别已是现有的成熟技术,在此不予赘述。
步骤S3,根据识别出的语音识别结果,确定其维度信息,获得该语音识别结果对应的维度键值对信息。
在本发明具体实施例中,识别出的语音识别结果为文本信息,根据该文本信息判断其为歌曲信息中的哪一维度,具体地,首先对语音识别结果,即文字信息进行NLP(Natural Language Processing,自然语言处理)处理,由于NLP处理已经有了很成熟的技术,在此不赘述,但为了提高对音乐类文本的处理精确度,可有针对地使用歌曲文本库(如歌名文本库,歌手文本库,专辑文本库等)作为训练数据对现有的NLP模型(常见的NLP模型如Text-CNN,RNN等)训练,其主要流程包括以下步骤:
步骤1,分词:将文本信息按照语义进行分割,得到一个词数组。
步骤2,文本信息清洗:基于现有的公开的停用词库,去掉包括一些语气词在内的与维度无关的词语,例如去掉语气词,助词等停用词,一般停用词的语料库都是公开的,去掉语气词,助词等停用词,只保留句子的主干。
步骤3,命名实体识别:将词数组转化为key-value对类型的结构型数。
例如语音输入进行语音识别得到的文本数据为“给我播放一首歌叫王力宏的心中的日月”,经过分词后会分为一个词数组:
[“给我”,“播放”,“一首”,“歌”,“叫”,“王力宏”,“的”,“心中的日月”],然后对文本进行清洗后,得到:
[“王力宏”,“心中的日月”],
接下来是命名实体识别,得到维度信息:{“singer”:“王力宏”,“name”:“心中的日月”},常见的基于歌曲文本库训练的NER(命名实体识别)模型如HMM,CRF,RNN等都可以达到较好的效果。
具体地说,维度类别包括但不限于歌曲名、歌手名、歌曲风格、词曲作者、所属专辑、歌词、所属音乐榜单和所属影视娱乐节目等,由于一个语音识别结果可能包括多个维度信息,因此将确定的维度信息形成维度键值对,其中若语音识别结果的文本信息只包含一个维度信息,比如“王力宏”,则输出的维度键值对也只有一个{“singer”:”王力宏”},若输入文本为:“王力宏的心中的日月”,则输出键值对为{“singer”:“王力宏”,“name”:“心中的日月”},其他亦然。
步骤S4,根据获得的维度键值对信息于本地资源库和/或线上开放平台中获取歌曲资源。
具体地,步骤S4进一步包括:
步骤S400,将得到的维度键值对与本地资源库中各歌曲的维度信息进行一一对比,在本发明具体实施例中,进行维度信息的对比存在先后次序,即以维度“歌曲名——歌手名——歌曲风格——词曲作者——所属专辑——歌词——所属音乐榜单——所属影视娱乐节目”的顺序进行对比,例如,当维度键值对为{“singer”:“王力宏”,“name”:“心中的日月”}时,则首先会在本地资源库中搜索出“name”为“心中的日月”的歌曲子集,然后在该歌曲子集中搜索“singer”为“王力宏”的歌曲资源,当搜索出符合要求的结果有多个,则根据该歌曲的播放次数进行降序排列,获取第一条歌曲作为获得的歌曲资源通过播放模块进行播放,同时将该条歌曲记录的用户播放次数加一,并更新访问时间。
优选地,为提高资源利用率,本发明还对本地资源库的存储定期执行淘汰机制,即根据用户播放次数将超出最大保存容量的歌曲资源实行末位淘汰,即淘汰用户播放次数最少、超出最大保存容量的歌曲资源,若多个末位资源的访问次数都相同,则根据LRU淘汰策略,即淘汰掉最近最少使用的歌曲数据,以维护整个本地资源库的稳定和用户的良好体验。
步骤S401,当本地资源库中未找到符合要求的数据,则将该维度键值对进行解析,填入多个开放平台的API请求URL中,并对其返回结果进行解析,根据返回的结果数据中的资源下载链接下载至本地,同时存储相应歌曲数据的维度信息,设定其用户播放次数。具体地说,当本地资源库未找到符合要求的数据,则启动线上搜索,本发明会同时启动对多个开放平台的搜索,即将解析出的键值对组合,自动嵌入每个开放平台对应的URL中,并根据匹配结果和返回的资源文件大小将返回结果排序,将排序第一的歌曲文件下载至本地资源库,并通过播放模块将该歌曲资源进行播放。
例如某个开放平台的API请求URL为:
http://music.163.com/api/search/get/web?csrf_token=hlpretag=&hlposttag=&s={搜索内容}&type=1&offset=0&total=true&limit=20
“http://music.163.com/api/artist/albums/{歌手ID}?id={歌手
ID}&offset=0&total=true&limit=10”
本发明则基于开放URL将歌曲维度信息填充进URL中对应的字段,并对其发起请求,获取歌曲列表,将其保存至本地。以维度键值对为{“name”:“千年等一回”}为例,将歌曲“千年等一回”拼接到URL中的“s=”字段
设置
url=http://music.163.com/api/search/get/web?csrf_token=hlpretag=&hlposttag=&s=千年等一回&type=1&offset=0&total=true&limit=1
curl-H'Accept':'*/*'-H'Accept-Language':'en-US,en;q=0.8'-H'Cache-Control':'max-age=0'-H'User-Agent:Mozilla/5.0(X11;Linux x86_64)AppleWebKit/537.36(KHTML,like Gecko)Chrome/48.0.2564.116Safari/537.36'-H'Connection:keep-alive'-H'Referer:http://www.baidu.com/'
%url%>re.json
开放平台返回值为搜索结果列表,其列表中可能包含多个歌曲名为“千年等一回”的歌曲,然后将其返回值在本地保存为json格式,等待下一步解析。
模块继续读取本地保存的json格式的歌曲列表文件,利用jq工具(解析json的工具)解析内容并获取第一条歌曲数据,将其歌曲唯一ID保存至本地,然后将歌曲ID拼接进歌曲下载URL,本实施例中为“id=”字段,对开放平台发送请求,获得返回值,返回值中包含开放平台上该id的歌曲资源文件下载链接,将返回值保存至本地为json格式,如下所示:
set/p str= jq-win64.exe".result|.songs[0]|.id"re.json>id.txt set/p id= set link="https://api.imjad.cn/cloudmusic/?type=song&id=%id%" curl%link%>last.json 对保存的歌曲链接进行解析,获得歌曲的下载链接地址,根据该下载链接地址,返回对应歌曲的歌曲数据文件,并将其文件保存在本地的资源库中,存储歌曲数据的维度信息,将其用户播放次数设定为1,如下所示: jq-win64.exe".data[0]|.url"last.json>url.txt set/p url= set res=%url:\=% curl%res%--output%1.mp3 优选地,于步骤401中,当存在多个开放平台均返回歌曲数据文件时,则对比输入维度键值对信息与各平台返回值的匹配程度,根据匹配程度选择歌曲资源下载到本地,这里的匹配逻辑与本地资源库的匹配逻辑相同,当维度都相同时,选择文件资源大小最小的歌曲数据文件进行保存,比如QQ音乐返回的歌曲文件预览大小为3M,而网易云返回的歌曲文件预览大小为2.5M,此时则选择网易云的歌曲资源下载到本地。 图2为本发明一种基于多资源的语音点播歌曲装置的系统架构图。如图2所示,本发明一种基于多资源的语音点播歌曲装置,包括: 语音接收模块201,用于接收用户的语音输入。 在本发明具体实施例中,本发明之基于多资源的语音点播歌曲方法可应用于用户随身携带的移动设备,例如智能手机,可移动设备自带的麦克风或外接的耳机麦克风接收用户的语音输入,例如,用户输入语音“王力宏的心中的日月”“播放陈奕迅的浮夸”等,语音接收模块201接收到该语音输入信息。 语音识别模块202,用于对语音输入信息进行语音识别,得到语音识别结果。 其中,语音识别模块202的语音识别结果可以是文字信息,具体可以使用现有的语音识别方法进行语音识别,例如,基于动态时间规整的算法、基于参数模型的隐马尔可夫法、基于非参数模型的矢量量化法、基于人工神经网络的算法等,由于语音识别已是现有的成熟技术,在此不予赘述。 维度分析模块203,用于根据识别出的语音识别结果,确定其维度信息,获得该语音识别结果对应的维度键值对信息。 在本发明具体实施例中,识别出的语音识别结果为文本信息,根据该文本信息判断其为歌曲信息中的哪一维度,具体地,首先对语音识别结果,即文字信息进行NLP(Natural Language Processing,自然语言处理)处理,由于NLP处理已经有了很成熟的技术,在此不赘述,但为了提高对音乐类文本的处理精确度,可有针对地使用歌曲文本库(如歌名文本库,歌手文本库,专辑文本库等)作为训练数据对现有的NLP模型(常见的NLP模型如Text-CNN,RNN等)训练,其主要流程包括以下步骤: 步骤1,分词:将文本信息按照语义进行分割,得到一个词数组。 步骤2,文本信息清洗:基于现有的公开的停用词库,去掉包括一些语气词在内的与维度无关的词语,例如去掉语气词,助词等停用词,一般停用词的语料库都是公开的,去掉语气词,助词等停用词,只保留句子的主干。 步骤3,命名实体识别:将词数组转化为key-value对类型的结构型数。 例如语音输入进行语音识别得到的文本数据为“给我播放一首歌叫王力宏的心中的日月”,经过分词后会分为一个词数组: [“给我”,“播放”,“一首”,“歌”,“叫”,“王力宏”,“的”,“心中的日月”],然后对文本进行清洗后,得到: [“王力宏”,“心中的日月”], 接下来是命名实体识别,得到维度信息:{“singer”:“王力宏”,“name”:“心中的日月”},常见的基于歌曲文本库训练的NER(命名实体识别)模型如HMM,CRF,RNN等都可以达到较好的效果。 资源获取模块204,用于根据获得的维度键值对信息于本地资源库和/或线上开放平台中获取歌曲资源。 具体地,资源获取模块204进一步包括: 本地资源获取单元,用于将得到的维度键值对与本地资源库中各歌曲的维度信息进行一一对比,在本发明具体实施例中,进行维度信息的对比存在先后次序,即以维度“歌曲名——歌手名——歌曲风格——词曲作者——所属专辑——歌词——所属音乐榜单——所属影视娱乐节目”的顺序进行对比,例如,当维度键值对为{“singer”:“王力宏”,“name”:“心中的日月”}时,则首先会在本地资源库中搜索出“name”为“心中的日月”的歌曲子集,然后在该歌曲子集中搜索“singer”为“王力宏”的歌曲资源,当搜索出符合要求的结果有多个,则根据该歌曲的播放次数进行降序排列,获取第一条歌曲作为获得的歌曲资源通过播放模块进行播放,同时将该条歌曲记录的用户播放次数加一,并更新访问时间。 优选地,为提高资源利用率,本地资源获取单元还对本地资源库的存储定期执行淘汰机制,即根据用户播放次数将超出最大保存容量的歌曲资源实行末位淘汰,即淘汰用户播放次数最少、超出最大保存容量的歌曲资源,若多个末位资源的访问次数都相同,则根据LRU淘汰策略,即淘汰掉最近最少使用的歌曲数据,以维护整个本地资源库的稳定和用户的良好体验。 线上资源获取单元,用于当本地资源库中未找到符合要求的数据,则将该维度键值对进行解析,填入多个开放平台的API请求URL中,并对其返回结果进行解析,根据返回的结果数据中的资源下载链接下载至本地,同时存储相应歌曲数据的维度信息,设定其用户播放次数。具体地说,当本地资源库未找到符合要求的数据,则启动线上搜索,本发明会同时启动对多个开放平台的搜索,即将解析出的键值对组合,自动嵌入每个开放平台对应的URL中,并根据匹配结果和返回的资源文件大小将返回结果排序,将排序第一的歌曲文件下载至本地资源库,并通过播放模块将该歌曲资源进行播放。 也就是说,本发明基于开放URL将歌曲维度信息填充进URL中对应的字段,并对其发起请求,获取歌曲列表,将其保存至本地。以维度键值对为{“name”:“千年等一回”}为例,将歌曲“千年等一回”拼接到URL中的“s=”字段 设置 url=http://music.163.com/api/search/get/web?csrf_token=hlpretag=&hlposttag=&s=千年等一回&type=1&offset=0&total=true&limit=1 curl-H'Accept':'*/*'-H'Accept-Language':'en-US,en;q=0.8'-H'Cache-Control':'max-age=0'-H'User-Agent:Mozilla/5.0(X11;Linux x86_64)AppleWebKit/537.36(KHTML,like Gecko)Chrome/48.0.2564.116Safari/537.36'-H'Connection:keep-alive'-H'Referer:http://www.baidu.com/' %url%>re.json 开放平台返回值为搜索结果列表,其列表中可能包含多个歌曲名为“千年等一回”的歌曲,然后将其返回值在本地保存为json格式,等待下一步解析。 模块继续读取本地保存的json格式的歌曲列表文件,利用jq工具(解析json的工具)解析内容并获取第一条歌曲数据,将其歌曲唯一ID保存至本地,然后将歌曲ID拼接进歌曲下载URL,本实施例中为“id=”字段,对开放平台发送请求,获得返回值,返回值中包含开放平台上该id的歌曲资源文件下载链接,将返回值保存至本地为json格式,如下所示: set/p str= jq-win64.exe".result|.songs[0]|.id"re.json>id.txt set/p id= set link="https://api.imjad.cn/cloudmusic/?type=song&id=%id%" curl%link%>last.json 对保存的歌曲链接进行解析,获得歌曲的下载链接地址,根据该下载链接地址,返回对应歌曲的歌曲数据文件,并将其文件保存在本地的资源库中,存储歌曲数据的维度信息,将其用户播放次数设定为1,如下所示: jq-win64.exe".data[0]|.url"last.json>url.txt set/p url= set res=%url:\=% curl%res%--output%1.mp3 优选地,当存在多个开放平台均返回歌曲数据文件时,线上资源获取单元还对比输入维度键值对信息与各平台返回值的匹配程度,根据匹配程度选择歌曲资源下载到本地,这里的匹配逻辑与本地资源库的匹配逻辑相同,当维度都相同时,选择文件资源大小最小的歌曲数据文件进行保存,比如QQ音乐返回的歌曲文件预览大小为3M,而网易云返回的歌曲文件预览大小为2.5M,此时则选择网易云的歌曲资源下载到本地。 播放模块205,用于根据资源获取模块204的结果,播放相应的歌曲资源,具体地,播放模块205可利用移动设备自带的音乐播放器或下载的第三方播放器软件进行歌曲播放。也就是说,若本地资源库存在相应的歌曲资源则资源获取模块204直接将歌曲资源推送至播放模块205,若本地资源库不存在相应的歌曲资源则从多个开放平台获取歌曲资源,并保存至本地资源库,然后将该歌曲资源推送至播放模块205。
在本实施例中,假设用户语音输入“播放陈奕迅的浮夸”,如图3所示,本发明之基于多资源的语音点播歌曲步骤如下: 1、用户通过手机麦克风输入“播放陈奕迅的浮夸”; 2、语音识别模块将用户的语音输入转化为文本信息“播放陈奕迅的浮夸”,并输入至维度分析模块; 3、维度分析模块将输入文本转化为{“singer”:“陈奕迅”,“name”:“浮夸”}的维度键值对信息,并输入至资源获取模块; 4、资源获取模块根据该维度键值对信息,首先从本地资源库中进行对比,若有匹配结果,则将匹配得到的歌曲资源推送至播放模块,同时该将该条数据的最后使用时间和使用次数进行更新;若无匹配结果,则启动线上搜索,同时启动对多个开放平台的搜索,将解析出的键值对组合,并自动嵌入每个开放平台对应的URL中,然后根据匹配结果和返回的资源文件大小将返回结果排序,将排序第一的歌曲文件下载至本地资源库,然后将该歌曲资源推送至播放模块; 5.播放模块,例如移动设备,如智能手机的默认播放器,通过扬声器或者外接耳机播放相应的歌曲。 与现有技术相比,本发明具有如下优点: 1、本发明结合了本地资源库和多个线上开放平台的资源的多歌曲资源,增加曲库资源的同时避免了每次都请求网络,避免播放延迟。 2、本发明维度分析模块使用歌曲的多个维度信息进行资源的匹配,同时结合资源使用次数,在精确匹配资源的同时考虑了用户行为,匹配效果更稳定; 3、本发明中,本地资源库采用使用次数和最后使用时间双维度淘汰机制,保证了有限的本地资源库空间存储了用户播放次数最多的歌曲资源。 4、本发明通过线上资源请求多个开放平台资源,并根据匹配程度和资源文件大小进行排序选择,在保证了用户体验的同时减少了本地资源库和网络传输的消耗。 上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何本领域技术人员均可在不违背本发明的精神及范畴下,对上述实施例进行修饰与改变。因此,本发明的权利保护范围,应如权利要求书所列。
- 基于多资源的语音点播歌曲方法及装置
- 基于语音识别的歌曲推送的方法和装置