基于脸部微表情的认知状态识别系统及方法
文献发布时间:2023-06-19 09:29:07
技术领域
本发明涉及一种基于脸部微表情的认知状态识别系统及方法。
背景技术
人的脸部可以传输信息,它是媒介,是信息传输器。脸部表情识别技术是近几十年来才逐渐发展起来的,由于面部表情的多样性和复杂性,并且涉及生理学及心理学,表情识别具有较大的难度。
微表情通常发生在一个人试图隐藏他的真实感受的时候,它是人类心理活动的真实表达,如若被有效捕捉,可以准确评估其心理和生理状态。所以近年来,微表情检测与识别工作逐渐引起了学者的关注,但由于微表情强度微弱,容易受环境因素扰动,持续时间短,发生部位区域狭小与不确定,一般传感器很难捕捉识别,所以微表情识别成为一个热门的研究领域。
发明内容
本发明提供了一种基于脸部微表情的认知状态识别系统及方法,采用如下的技术方案:
一种基于脸部微表情的认知状态识别系统,包括,数据获取模块、数据处理模块和认知分类模型;
数据获取模块用于获取用于训练的视频数据,视频数据包含认知状态正常的测试对象的视频数据和认知状态异常的测试对象的视频数据;
数据处理模块用于对视频数据进行处理,将视频数据截取为固定帧数的短视频;
认知分类模型包括:AU区域划分模块、特征提取模块、预测模块、检验模块和分类模块;
将数据处理模块处理好的短视频输入认知分类模型对其进行训练;
AU区域划分模块用于针对短视频中的每一帧图像进行面部特征点识别,将每一帧图像划分成不同的AU区域;
特征提取模块用于将每一个AU区域输入对应的CNN,得到相应AU区域的特征向量,将每一帧图像的所有AU区域的特征向量进行串联得到每一帧图像的多标签AU特征;
预测模块用于将每一帧图像的多标签AU特征输入LSTM网络进行AU预测,得到每个短视频对应的不同的AU出现的概率;
检验模块用于对预测模块的结果进行显著性检验,确定差异AU;
分类模块用于将认知状态正常和状态异常作为类别标签,将差异AU的概率作为特征标签,使用SVM进行二分类,完成认知状态评估模型训练工作;
数据获取模块还用于获取未知状态的测试对象的待识别视频数据并输入至训练好的认知分类模型;
认知分类模型输出评估结果。
进一步地,认知状态评估模型还包括预处理模块;
预处理模块用于通过VGG网络对输入至认知分类模型的短视频中的每一帧图像进行预处理后输入至AU区域划分模块。
进一步地,数据处理模块将视频数据截取为固定帧数的短视频,且相邻的短视频具有部分重叠帧数。
进一步地,数据处理模块将视频数据截取为固定帧数为n的短视频,且相邻的短视频具有部分重叠帧数为0.1n-0.4n。
一种基于脸部微表情的认知状态识别方法,包含以下步骤:
通过数据获取模块获取用于训练的视频数据,视频数据包含认知状态正常的测试对象的视频数据和认知状态异常的测试对象的视频数据;
通过数据处理模块对视频数据进行处理,将视频数据截取为固定帧数的短视频;
搭建认知状态评估模型并通过处理后的短视频对认知状态评估模型进行训练;
再通过数据获取模块获取未知状态的测试对象的待识别视频数据并输入训练好的认知状态评估模型得到评估结果;
认知状态评估模型包括:AU区域划分模块、特征提取模块、预测模块、检验模块和分类模块;
通过处理后的短视频对认知状态评估模型进行训练的具体方法为:
数据处理模块将处理后的短视频输入至认知状态评估模型;
通过AU区域划分模块针对短视频中的每一帧图像进行面部特征点识别,将每一帧图像划分成不同的AU区域;
通过特征提取模块将每一个AU区域输入对应的CNN,得到相应AU区域的特征向量,将每一帧图像的所有AU区域的特征向量进行串联得到每一帧图像的多标签AU特征;
通过预测模块将每一帧图像的多标签AU特征输入LSTM网络进行AU预测,得到每个短视频对应的不同的AU出现的概率;
通过检验模块对预测模块的结果进行显著性检验,确定差异AU;
将差异AU输入分类模块,将认知状态正常和状态异常作为类别标签,将差异AU的概率作为特征标签,使用SVM进行二分类,完成认知状态评估模型训练工作。
进一步地,认知状态评估模型还包括预处理模块;
在通过AU区域划分模块对图像进行划分之前,
先将短视频输入预处理模块,预处理模块通过VGG网络对短视频中的每一帧图像进行预处理。
进一步地,将视频数据截取为固定帧数的短视频的具体方法为:
将视频数据截取为固定帧数的短视频,且相邻的短视频具有部分重叠帧数。
进一步地,将视频数据截取为固定帧数的短视频的具体方法为:
将视频数据截取为固定帧数为n的短视频,且相邻的短视频具有部分重叠帧数为0.1n-0.4n。
进一步地,认知状态异常的测试对象为患有帕金森综合征的患者。
进一步地,认知状态异常的测试对象为患有阿尔茨海默症的患者。
本发明的有益之处在于所提供的基于脸部微表情的认知状态识别系统及方法,能够对测试对象的脸部视频数据进行分析处理,并自动对该测试对象的认知状态进行归类识别。
附图说明
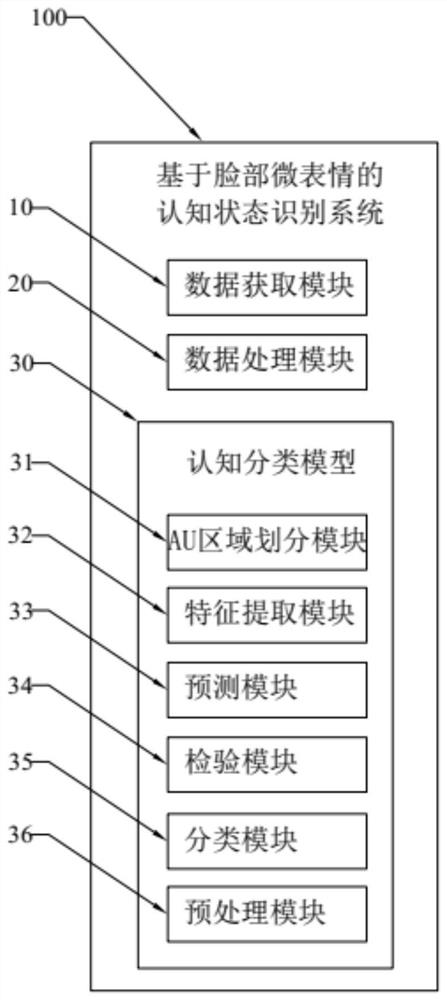
图1是本发明的基于脸部微表情的认知状态识别系统的示意图。
基于脸部微表情的认知状态识别系统100,数据获取模块10,数据处理模块20,认知分类模型30,AU区域划分模块31,特征提取模块32,预测模块33,检验模块34,分类模块35,预处理模块36。
具体实施方式
以下结合附图和具体实施例对本发明作具体的介绍。
如图1所示为本发明的一种基于脸部微表情的认知状态识别系统100,主要包括,数据获取模块10、数据处理模块20和认知分类模型30。
数据获取模块10用于获取用于训练的视频数据,视频数据包含认知状态正常的测试对象的视频数据和认知状态异常的测试对象的视频数据,视频数据包含测试对象的脸部。在本发明中,认知状态正常的测试对象为正常人,而认知状态异常的测试对象为帕金森综合征患者。可以理解的是,根据实际需要,认知状态异常的测试对象也可以是阿尔茨海默症患者。
数据处理模块20用于对视频数据进行处理,将视频数据截取为固定帧数的短视频。
具体而言,数据处理模块20将视频数据截取为固定帧数的短视频,且相邻的短视频具有部分重叠帧数。将完整的视频数据截取若干相邻的短视频,且相邻的短视频具有部分重叠的帧数。一方面可以使被分割的短视频具有更强的连贯性,另一方面也可以使分割后的短视频的数量更多,扩展了训练数据。
作为一种优选的实施方式,数据处理模块20将视频数据截取为固定帧数为n的短视频,且相邻的短视频具有部分重叠帧数为0.1n-0.4n。
认知分类模型30包括:AU区域划分模块31、特征提取模块32、预测模块33、检验模块34和分类模块35。将数据处理模块20处理好的短视频输入认知分类模型30对其进行训练。
面部动作编码系统(Facial Action Coding System,FACS)是一种通过面部外观对人类面部动作进行分类的系统,定义面部活动单元(Action Unit,AU)来描述不同的面部肌肉动作变化,因此对于微表情的检测可以转化为对于AU的检测。对每一个短视频进行AU检测,主要使用卷积神经网络(Convolutional Neural Network,CNN)和长短时记忆网络(Long Short Term Memory,LSTM)。其中CNN实现AU特征提取,LSTM完成时序特征提取。
其中,AU区域划分模块31用于针对短视频中的每一帧图像进行面部特征点识别,将每一帧图像划分成不同的AU区域。具体而言,首先要进行面部特征点识别,确定视频每一帧人脸各个器官的位置。在确定好面部特征点的前提下,要进行裁剪从而实现AU区域的划分。根据AU所在位置,选择能够表示AU显著变化特征的标志性的点作为AU的中心,该结果为AU区域划分的依据。
特征提取模块32用于将每一个AU区域输入对应的CNN,得到相应AU区域的特征向量,将每一帧图像的所有AU区域的特征向量进行串联得到每一帧图像的多标签AU特征。具体而言,对于每一个AU要单独设计局部的CNN,其滤波器针对对应的AU区域进行训练,得到特征向量来表示相应区域的AU特征,将所有AU的特征向量进行串联,就得到每一帧图像的多标签AU特征。
预测模块33用于将每一帧图像的多标签AU特征输入LSTM网络进行AU预测,得到每个短视频对应的不同的AU出现的概率。具体而言,由于AU的产生与消失是一个动态的过程,所以在提取视频里每一帧图像的AU特征的基础上,要综合分析视频的时序信息。使用LSTM网络可以融合静态的CNN特征,能够提高静态的AU检测的准确率。前面的特征提取模块32输出了每一帧图像的多标签AU特征,将该结果按照产生时间从前到后的顺序进行排列,分别输入到LSTM网络中的每一个LSTM模块中,同时前一个模块的输出结果也作为下一个模块的输入,LSTM网络的模块个数为短视频的帧数n,最后综合所有的LSTM模块的输出结果进行AU的预测,得到不同的AU出现的概率。
检验模块34用于对预测模块33的结果进行显著性检验,确定差异AU。对于认知状态正常和认知状态异常的测试者而言,二者的某些面部AU出现的概率存在着一些差异,所以分别对每一个经过预测模块33得到的AU进行显著性检验,确定出在认知状态正常和认知状态异常的测试者之间体现出明显差异的差异AU,将它们作为之后认知状态评估的依据。
分类模块35用于将认知状态正常和状态异常作为类别标签,将差异AU的概率作为特征标签,使用支持向量机(Support Vector Machine,SVM)进行二分类,完成认知状态评估模型训练工作。微表情的变化情况能够反映人的认知状态,即AU和认知状态之间存在某些隐性的关系。将认知状态正常和认知状态异常作为类别标签,将检验模块34确定的差异AU的概率作为特征标签,使用支持向量机(Support Vector Machine,SVM)进行二分类,就在AU概率和认知状态之间建立起了联系。
当完成认知分类模型30的训练后,通过数据获取模块10获取未知状态的测试对象的待识别视频数据并输入至训练好的认知分类模型30。认知分类模型30根据输入的待识别视频数据输出评估结果,即该测试对象的认知状态为正常或是异常。
作为一种优选的实施方式,认知状态评估模型还包括预处理模块36。预处理模块36用于通过VGG网络对输入至认知分类模型30的短视频中的每一帧图像进行预处理后输入至AU区域划分模块31。可以理解的是,由于VGG网络具有简单的结构和优良的对象分类性能,所以使用VGG对图像进行初步的处理,VGG网络一方面可以缩小的图片的尺寸,可以减小区域划分产生的误差,另一方面也能够实现AU特征的初步提取。将VGG网络的输出结果作为AU区域划分模块31的划分的对象,根据原始图像的尺寸和VGG输出图像的尺寸的比值,可以确定在输出图像里面AU中心的位置,根据该位置将人脸图像进行裁剪,每一个AU对应一个尺寸较小的局部图像。
本发明还揭示了一种基于脸部微表情的认知状态识别方法,用于上述的基于脸部微表情的认知状态识别系统100,具体的包含以下步骤:
S1:通过数据获取模块10获取用于训练的视频数据,视频数据包含认知状态正常的测试对象的视频数据和认知状态异常的测试对象的视频数据。
S2:通过数据处理模块20对视频数据进行处理,将视频数据截取为固定帧数的短视频。
S3:搭建认知状态评估模型并通过处理后的短视频对认知状态评估模型进行训练。
S4:再通过数据获取模块10获取未知状态的测试对象的待识别视频数据并输入训练好的认知状态评估模型得到评估结果。
具体而言,认知状态评估模型包括:AU区域划分模块31、特征提取模块32、预测模块33、检验模块34和分类模块35。
通过处理后的短视频对认知状态评估模型进行训练的具体方法为:
S31:数据处理模块20将处理后的短视频输入至认知状态评估模型。
S32:通过AU区域划分模块31针对短视频中的每一帧图像进行面部特征点识别,将每一帧图像划分成不同的AU区域。
S33:通过特征提取模块32将每一个AU区域输入对应的CNN,得到相应AU区域的特征向量,将每一帧图像的所有AU区域的特征向量进行串联得到每一帧图像的多标签AU特征。
S34:通过预测模块33将每一帧图像的多标签AU特征输入LSTM网络进行AU预测,得到每个短视频对应的不同的AU出现的概率。
S35:通过检验模块34对预测模块33的结果进行显著性检验,确定差异AU。
S36:将差异AU输入分类模块35,将认知状态正常和状态异常作为类别标签,将差异AU的概率作为特征标签,使用SVM进行二分类,完成认知状态评估模型训练工作。
作为一种优选的实施方式,认知状态评估模型还包括预处理模块36。
在通过AU区域划分模块31对图像进行划分之前,
通过处理后的短视频对认知状态评估模型进行训练的具体方法还包括:
S30:先将短视频输入预处理模块36,预处理模块36通过VGG网络对短视频中的每一帧图像进行预处理。
作为一种优选的实施方式,将视频数据截取为固定帧数的短视频的具体方法为:
将视频数据截取为固定帧数的短视频,且相邻的短视频具有部分重叠帧数。
作为一种优选的实施方式,将视频数据截取为固定帧数的短视频的具体方法为:
将视频数据截取为固定帧数为n的短视频,且相邻的短视频具有部分重叠帧数为0.1n-0.4n。
作为一种优选的实施方式,认知状态异常的测试对象为患有帕金森综合征的患者。
作为一种可选的实施方式,认知状态异常的测试对象为患有阿尔茨海默症的患者。
以上显示和描述了本发明的基本原理、主要特征和优点。本行业的技术人员应该了解,上述实施例不以任何形式限制本发明,凡采用等同替换或等效变换的方式所获得的技术方案,均落在本发明的保护范围内。