LncRNA预测方法、装置、计算设备及计算机可读存储介质
文献发布时间:2023-06-19 09:30:39
技术领域
本发明涉及LncRNA预测,具体的,涉及一种LncRNA预测方法、装置、计算设备及计算机可读存储介质。
背景技术
根据分子生物学的中心法则,遗传信息存储在蛋白质编码基因中。因此长期以来,非编码RNA一直被认为是描述性噪声。在过去的十年里,这种传统观点受到了挑战。越来越多的证据表明,非编码RNA在各种基本和重要的生物学过程中发挥着关键作用。此外,非蛋白质编码序列的比例随着生物体的复杂性而增加。根据转录产物长度是否超过200个核苷酸(nt),非编码RNA可进一步分为短链非编码RNA和长链非编码RNA(Long non-coding RNA,LncRNA)。
近年来,长链非编码RNA引起了研究者的极大关注,越来越多的研究结果表明,这些长链非编码RNA的突变和失调与癌症、阿尔茨海默病、心血管疾病等多种复杂人类疾病的发生发展相关。因此,准确预测LncRNA在LncRNA研究中非常重要。
利用实验技术和生物数据,已提出了多种LncRNA预测方法。例如,已发现了两种著名的LncRNA,H19和x非活性特异性转录本,这可以追溯到20世纪90年代早期的传统基因图谱。Guttman等人开发了一种功能基因组学方法,将每个大的介入LncRNA作为假定功能的信号。Cabili等人提出了一种构建大型非编码RNA间作目录的综合方法,包括基于染色质标记在24种不同的人类细胞类型和组织中构建8000多个大的中间长度。
但生物实验方法成本高、耗时长、费力,不利于大规模应用。在生物大数据时代,为了更好地利用LncRNA现有的序列资源,研究者们提出了许多基于机器学习的计算方法。
2013年,L.Wang等人实现了CPAT,这是一种潜在的蛋白质编码评估工具,包括开放阅读框架(Open Reading Frame,ORF)的特征。在分子生物学中,ORF从起始密码子开始,是DNA序列中的一个碱基序列,它编码一种蛋白质电位,并被终止密码子打断。CPAT分类模型是一个标准径向基支持向量机(Support Vector Machine,SVM)基函数核。2014年,A.M.Li等人实现了PLEK,他们使用KMER方案和滑动窗口来分析转录本。PLEK的分类模型是一个具有径向核函数的支持向量机。
2015年,Achawanantakun R.等人实施了LncRNA-ID。LncRNA-ID可根据ORF、核糖体相互作用和蛋白质保守性进行分类。随机森林(Random Forests,RF)的使用改进了LncRNA-ID的分类模型,有助于LncRNA-ID有效地处理不平衡的训练数据。
2017年,Hugo W.Schneider等人提出了一种基于SVM的LncRNAs预测方法。它使用kmer方案和来自ORF的特征来分析转录。这些特征被分为两组。第一个集合源于ORF的四个特征:1)第一个ORF长度;2)第一个ORF的相对长度;3)ORF的最长长度;4)最长的ORF相对长度。第二组基于kmer特征提取方案,其中k=2,3,4,共336个不同频率的核苷酸模式:16个二核苷酸模式频率;64个三核苷酸模式频率;256个核苷酸频率。第一ORF相对长度和PCA选择的核苷酸模式频率作为这两组特征的特征。
尽管已提出上述众多方法,但LncRNA预测仍有改进的空间。
发明内容
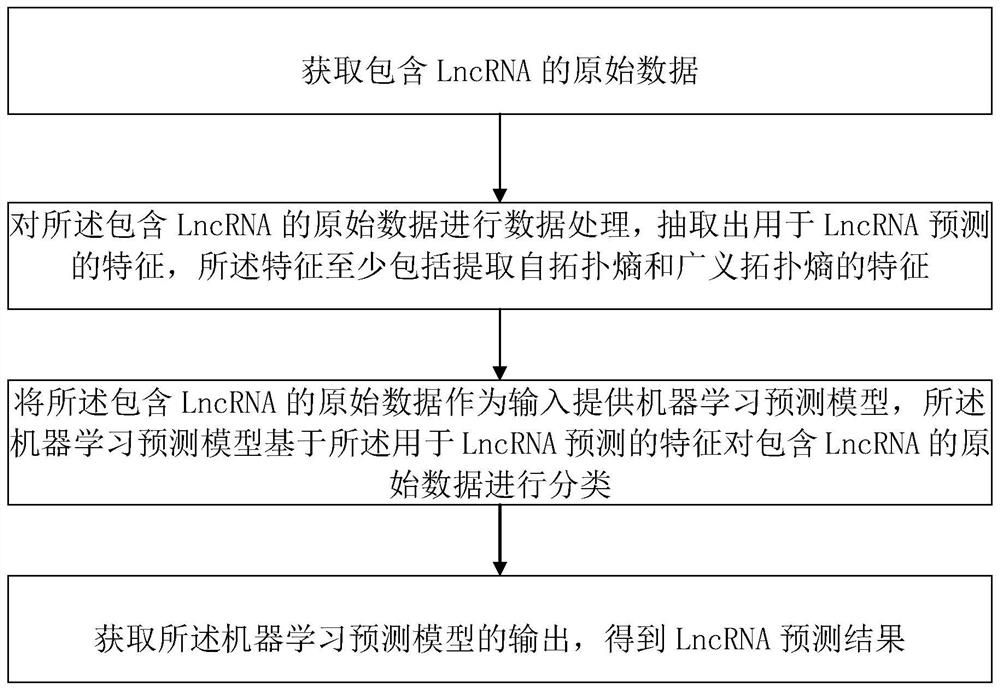
根据本发明的第一方面,提供了一种LncRNA预测方法,包括:获取包含LncRNA的原始数据;对所述包含LncRNA的原始数据进行数据处理,抽取出用于LncRNA预测的特征,所述特征至少包括提取自拓扑熵和广义拓扑熵的特征;将所述包含LncRNA的原始数据作为输入提供机器学习预测模型,所述机器学习预测模型基于所述用于LncRNA预测的特征对包含LncRNA的原始数据进行分类;获取所述机器学习预测模型的输出,得到LncRNA预测结果。
在本发明的一种实施例中,所述机器学习预测模型包括支持向量机算法模型、随机森林算法模型或极端梯度提升算法模型。
在本发明的一种实施例中,提取自拓扑熵的特征通过以下公式获得:
在本发明的一种实施例中,所述用于LncRNA预测的特征还包括:开放阅读框架特征、互信息特征、香农熵特征和Kullback-Leibler散度特征。
在本发明的一种实施例中,所述用于LncRNA预测的特征包括:1个序列长度特征,4个开放阅读框架特征,4个香农熵特征,3个拓扑熵特征,3个广义拓扑熵特征,17个互信息特征和3个Kullback-Leibler散度特征。
在本发明的一种实施例中,所述数据处理在提取特征前,包括:对原始数据进行去短操作,得到过滤后的fasta文件;使用CD-HIT包中的“cd-hit-est”程序执行重复数据删除操作,得到Cd-hit fasta文件;采用下采样法平衡数据集,得到平衡后的fasta文件。
在本发明的一种实施例中,所述数据处理还包括:对所述用于LncRNA预测的特征进行归一化处理。
根据本发明的第二方面,提供了一种LncRNA预测装置,数据获取模块,用于获取包含LncRNA的原始数据;数据处理模块,用于对所述包含LncRNA的原始数据进行数据处理,抽取出用于LncRNA预测的特征,所述特征至少包括提取自拓扑熵和广义拓扑熵的特征;分类模块,用于将所述包含LncRNA的原始数据作为输入提供机器学习预测模型,所述机器学习预测模型基于所述用于LncRNA预测的特征对包含LncRNA的原始数据进行分类;预测结果获取模块,用于获取所述机器学习预测模型的输出,得到LncRNA预测结果。
根据本发明的第三方面,提供了一种计算设备,包括存储器和处理器,所述存储器存储有程序,所述处理器执行所述程序时实现上述的LncRNA预测方法。
根据本发明的第四方面,提供了一种计算机可读存储介质,其上存储有程序,所述程序被处理器执行时实现上述的LncRNA预测方法。
本申请实现了有效的LncRNA预测,且可加快训练过程。此外,本申请不仅在LncRNA预测方面取得了良好的效果,而且对于DNA序列中其他功能元素的研究也具有可扩展性。
附图说明
图1是本发明实施例的LncRNA预测方法流程图。
图2(a)是本发明实施例的数据预处理流程图。
图2(b)是本发明实施例的基于信息熵和ORF等特征相结合的人类LncRNA预测流程图。
图3(a)和(b)是本发明实施例的基于信息熵和ORF的数据特征重要性分析,其中3(a)是人GRCh37数据的特征重要性分析,3(b)是人类GRCh38数据的特征重要性分析。
图4(a)-(f)是本发明实施例的基于GRCh37(人类物种)的实验结果,其中图4(a)是SVM算法的ROC曲线;图4(b)是RF算法的ROC曲线;图4(c)是极端梯度提升(eXtremeGradient Boosting,XGBoost)算法的ROC曲线;图4(d)是SVM算法的PR曲线;图4(e)是RF算法的PR曲线;图4(f)是XGBoost算法的PR曲线。
图5(a)-(f)是本发明实施例的基于GRCh38(人类物种)的实验结果,其中图5(a)是SVM算法的ROC曲线;图5(b)是RF算法的ROC曲线;图5(c)是XGBoost算法的ROC曲线;图5(d)是SVM算法的PR曲线;图5(e)是RF算法的PR曲线;图5(f)是XGBoost算法的PR曲线。
图6(a)-(d)分别显示了GRCh37的ROC曲线,GRCh37的PR曲线,GRCh38的ROC曲线和GRCh38的PR曲线。
图7是本发明实施例的装置结构图。
图8是本发明实施例的计算设备的内部结构图。
具体实施方式
本申请基于信息熵的特征和机器学习算法相结合,设计一种LncRNA预测方法。本申请通过计算拓扑熵和广义拓扑熵,得到了LncRNA序列的6个新特征。利用这6个特征和ORF等其他特征,应用SVM、RF和XGBoost算法来区分人类LncRNA。结果表明,该方法具有较高的曲线下面积(Area Under Curve,AUC),可达99.7905%。该方法准确、高效,具有新的信息熵特征,可推广应用于DNA序列中其他功能元素的研究。
参见图1,在本发明的一种实施例中,所述LncRNA预测方法包括:获取包含LncRNA的原始数据;对所述包含LncRNA的原始数据进行数据处理,抽取出用于LncRNA预测的特征,所述特征至少包括提取自拓扑熵和广义拓扑熵的特征;将所述包含LncRNA的原始数据作为输入提供机器学习预测模型,所述机器学习预测模型基于所述用于LncRNA预测的特征对包含LncRNA的原始数据进行分类;获取所述机器学习预测模型的输出,得到LncRNA预测结果。
针对机器学习预测模型,本申请使用来自Ensemble数据库的数据集进行模型训练:人类(智人)装配GRCh37(release-75)和GRCh38(release-91)。这些转录本的FASTA分类文件包含LncRNAs和蛋白编码转录本(PCTs)(见表1)。在本申请中,将LncRNAs作为正样本,PCTs作为负样本。
表1.FASTA原始文件的种类
本申请使用CD-HIT进行数据处理。CD-HIT是一种广泛用于生物序列聚类的程序,它可以减少序列冗余,提高其他序列分析的性能。CD-HIT最初用于对蛋白质序列进行聚类,以创建一个简化的参考数据库,然后扩展到支持聚类核苷酸序列和比较两个数据集。目前,CD-HIT软件包有许多程序,包括cd-hit,cd-hit-2d,cd-hit-est,cd-hit-est-2d,cd-hit-para等。在本申请中,使用cd-hit-est对核酸序列进行聚类。目的是对核酸序列进行去冗余操作,以保证机器学习训练模型的准确性。数据预处理流程如图2(a)所示。
可以看到,针对原始的Ensemble fasta文件,首先,在步骤S1,进行去短操作,即从原始文件中删除所有小于200nt的序列,得到过滤后的fasta文件。其次,在步骤S2,使用CD-HIT包中的“cd-hit-est”程序来执行重复数据删除操作,得到Cd-hit fasta文件。随后,在步骤S3,采用下采样(downsampling)法平衡数据集,得到平衡后的fasta文件。最后,在步骤S4,进行特征提取(feature extraction),获得标准数据集(standard dataset),其包括:训练集(training set)、验证集(validation set)和测试集(test set)。表2显示了数据处理后FASTA文件中核酸序列数量的变化。
表2.数据处理后的转录本FASTA文件种类
参见图2(b),针对原始数据,例如人类LncRNA,在数据处理后得到训练集和测试集,其中训练集用来训练算法模型的,而测试集用来测试算法模型的,即评估泛化误差。可以从训练集获取用于进行LncRNA预测的特征,本申请从改进的拓扑熵和广义拓扑熵中提取新的特征。拓扑熵定义如下:
有限序列的长度为ω,子序列的长度为n。其中4
广义拓扑熵是拓扑熵的完全形式,定义为:
在方程2中,n
本申请对拓扑熵和广义拓扑熵进行了修正,突出了重复子序列的特征。在本申请的计算中,去掉了外观频率较低的子序列。这意味着,这个子序列将不会被包括在熵计算,如果子序列的频率小于
信息熵特征的整合
一般的说,仅根据之前提取的6个特征进行LncRNA预测是非常困难的。优选的方式是将它们与其他常用的信息理论特征和LncRNA的ORF相关特征相结合,获得更好的性能分类器。在计算生物学和生物信息学中,人们提出了基于信息论和熵的共同特征来分析和测量转录本的结构特性。不同的复杂度计算揭示了转录本特异性的不同方面。使用了由Henkel等人提出的有用的理论信息特征。本申请使用的所有特征是35个,其包括四类特征,即ORF特征、MI(Mutual Information,互信息)特征、熵特征和Kullback-Leibler散度(KLD)特征,其具体包括:1个序列长度特征,4个ORF特征,4个香农熵(Shannon Entropy,SE)特征,3个拓扑熵(Topological Entropy,TE)特征,3个广义拓扑熵(Generalized TopologicalEntropy,GTE)特征,17个互信息(MI)特征和3个KLD特征。在本申请中,所有的样本都是由这35个特征来描述的。为了更好的说明本申请的重新搜索的优越性,选择了Kmer特征作为对比测试。在比较实验中,k分别为1、2、3时,共有84个不同频率的核苷酸模式。它们是4个单核苷酸模式频率,16个二核苷酸模式频率和64个三核苷酸模式频率。在得到整合的特征后,进行特征缩放,即归一化处理。
SVM、RF和XGBoost算法分类过程
SVM、RF和XGBoost是广泛使用的机器学习算法,用于识别LncRNAs和PCTs。SVM算法是一种与相关学习算法相关的监督学习模型,可以分析数据,识别模式,并用于分类和回归分析。RF算法是一种集成的分类任务学习方法。它在训练数据时构造大量的决策树,并输出每棵树的类。XGBoost算法基于树结构中组织的各种规则来预测输出变量。此外,XGBoost算法的学习方法不需要线性特征或特征之间的线性交互。它是一种梯度增强算法,可以加速树的构造,并提出一种新的树搜索分布式算法。使用到这三种机器学习模型训练方法。在特征提取和数据划分后,获得35个特征的训练集、验证集和测试集。使用训练集和验证集,使用这三个模型进行机器学习模型训练,获得机器学习预测模型。使用预测模型和测试集,输出预测结果的评估报告,使用AUC值作为预测评价指标。
RF和XGBoost算法已经具备了自动选择参数的内置功能。为了更好地训练一个好的机器学习模型,本申请没有预先选择特征,而是使用上文所述的35个特征作为输入来训练分类器。然而,SVM并没有自动选择特征个数的功能。本申请选择特征是为了提高训练速度和效率。特征选择结果如图3(a)和3(b)所示。
由图3(a)和3(b)可知,前4个重要特征分别为:长度(length),广义拓扑熵的第4个(getoentropy4),最长ORF相对长度(lp),及最长ORF的长度(ll)。两个版本的人体数据在特征选择上有一定的一致性。在本申请设计的Kmer比较实验中,使用相同的方法进行特征选择。
机器学习模型训练结果比较
本申请使用具有35个特征的SVM、RF、和XGBoost算法来区分GRCh37版本的人类LncRNA,并与具有Kmer特征的LncRNA进行比较。
从图4(a)-(f)可以看出,基于信息熵的组合和ORF提取特征的本申请的方法,优于基于公里提取特征的方法,描述如下:
(1)在图4(a)(b)(c),信息熵的AUC值是99.7905%,公里的AUC值是96.3130%;
(2)对于相同的训练算法,信息熵的AUC值大于Kmer 1的AUC值。最大差值为7.0820%,平均差值为5.4766%;
(3)在图4(d)(e)(f)中,信息熵的AUPR值达到99.7792%,Kmer的AUPR值最多为96.3035%;
(4)在图4(d)(e)(f)中,信息熵的AUPR值大于Kmer值,最大差值为5.8724%,平均差值为4.8184%。
还将具有35个特征的SVM、RF、和XGBoost算法应用到GRCh38版本的LncRNA中,并与具有Kmer特征的LncRNA进行了相似的比较。
如图5(a)-(f)所示,在GRCh38版本的人类LncRNA,基于本申请信息熵和ORF相结合的方法比基于Kmer提取特征的方法更好,如下所示:
(1)在图5(a)(b)(c)中,信息熵的AUC值最大是99.7887%,公里的AUC值是97.3003%最大;
(2)在图5(a)(b)(c)中,信息熵的AUC值大于Kmer法的AUC值,最大差值为6.6198%,平均差值为4.6982%;
(3)图5(d)(e)(f)中,信息熵的AUPR值达到99.7606%,Kmer的AUPR值最多为97.3299%;
(4)在图5(d)(e)(f)中,信息熵的AUPR值大于Kmer值,最大差值为4.8293%,平均差值为3.8553%。
进一步的,图6(a)-(d)中的结果表明,XGBoost的信息熵的特征具有最佳的AUC和PR值,图6(a)-(d)中对应的值分别为99.7905%,99.7792%,99.7887%,99.7606%。PLEK方法得到的AUC和PR值比XGBoost的信息熵的特征的小,图6(a)-(d)中对应的值分别为94.9319%,96.1293%,95.7796%,96.7145%。CPAT方法得到的AUC和PR值也比XGBoost的信息熵的特征的小,图6(a)-(d)中对应的值分别为96.1223%,94.7806%,96.3012%,94.4445%。在图6(a)和(b)中,PLEK的AUC值比Kmer_RF大1.0562%,比CPAT小1.1904%。PLEK的PR值比CPAT大1.3487%。在图6(c)和(d)中,PLEK的AUC值比Kmer_RF大1.0155%,比CPAT小0.5216%。PLEK的PR值比CPAT大2.27%。值得注意的是,PLEK在这35个特征上的运行时间是9天,而其他方法的时间要短得多。
结论本申请提出了一种有效的LncRNA预测器。为了获得更准确、更真实的预测结果,本申请使用CD_HIT工具对核酸序列进行去冗余(即删除重复数据)操作。从核酸序列本身中提取特征,将拓扑熵和广义拓扑熵作为新的信息理论特征。结合35个特征来训练分类器。
使用SVM、RF和XGBoost机器学习方法进行特征选择和分类器训练。与Kmer控制实验相比,本申请减少了49个特征,加快了训练过程,使得硬件(例如存储器资源)消耗更少、处理时间更短。本申请的方法的一个优点是只使用直接从序列本身计算出来的特征。本申请不仅在LncRNA预测方面取得了良好的效果,而且对于DNA序列中其他功能元素的研究也具有可扩展性。
参考图7,本发明实施例的一种LncRNA预测装置,数据获取模块,用于获取包含LncRNA的原始数据;数据处理模块,用于对所述包含LncRNA的原始数据进行数据处理,抽取出用于LncRNA预测的特征,所述特征至少包括提取自拓扑熵和广义拓扑熵的特征;分类模块,用于将所述包含LncRNA的原始数据作为输入提供机器学习预测模型,所述机器学习预测模型基于所述用于LncRNA预测的特征对包含LncRNA的原始数据进行分类;预测结果获取模块,用于获取所述机器学习预测模型的输出,得到LncRNA预测结果。
本申请的方法可以实现在计算设备中。计算设备的一个示例性的内部结构图可以如图8所示,该计算设备可以包括通过系统总线连接的处理器、存储器、外界接口、显示器和输入装置。其中,处理器用于提供计算和控制能力。存储器包括非易失性存储介质、内存储器。该非易失性存储介质存储有操作系统,应用程序、数据库等。内存储器为非易失性存储介质中的操作系统和程序的运行提供环境。外界接口包括例如网络接口,用于与外部的终端通过网络连接通信。外界接口也可以包括USB接口等等。该计算设备的显示器可以是液晶显示屏或者电子墨水显示屏,输入装置可以是显示屏上覆盖的触摸层,也可以是例如计算设备外壳上设置的按键、轨迹球或触控板,还可以是外接的键盘、触控板或鼠标等。
计算设备中的非易失性存储介质存储的程序在被处理器执行时可以实现上述癌症生存期预测方法。另外,非易失性存储介质也可以以单独的物理形式存在,例如一U盘,当其与一处理器连接时,U盘上存储的程序被执行可以实现上述方法。本发明的方法,也可以实现为苹果或安卓应用市场中的一个APP
(应用程序),供用户下载到各自的移动终端运行。
本领域技术人员可以理解,图8中示出的结构,仅仅是与本申请方案相关的部分结构的框图,并不构成对本申请方案所应用于其上的计算设备的限定,具体的计算设备可以包括比图中所示更多或更少的部件,或者组合某些部件,或者具有不同的部件布置。
如上所述,本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一非易失性计算机可读存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。其中,本申请所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和/或易失性存储器。非易失性存储器可包括只读存储器(ROM)、可编程ROM(PROM)、电可编程ROM(EPROM)、电可擦除可编程ROM(EEPROM)或闪存。易失性存储器可包括随机存取存储器(RAM)或者外部高速缓冲存储器。作为说明而非局限,RAM以多种形式可得,诸如静态RAM(SRAM)、动态RAM(DRAM)、同步DRAM(SDRAM)、双数据率SDRAM(DDRSDRAM)、增强型SDRAM(ESDRAM)、同步链路(Synchlink)DRAM(SLDRAM)、存储器总线(Rambus)直接RAM(RDRAM)、直接存储器总线动态RAM(DRDRAM)、以及存储器总线动态RAM(RDRAM)等。
以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
本发明所述的计算机,是广义上的一种能够按照事先设定或存储的指令,自动进行数值计算和/或信息处理的计算设备,其硬件可以包括至少一个存储器、至少一个处理器,以及至少一个通信总线。其中,所述通信总线用于实现这些元件之间的连接通信。处理器可以包括但不限于微处理器。计算机硬件还可以包括专用集成电路(ApplicationSpecific Integrated Circuit,ASIC)、可编程门阵列(Field-Programmable GateArray,FPGA)、数字处理器(Digital Signal Processor,DSP)、嵌入式设备等。所述计算机还可包括网络设备和/或用户设备。其中,所述网络设备包括但不限于单个网络服务器、多个网络服务器组成的服务器组或基于云计算(Cloud Computing)的由大量主机或网络服务器构成的云,其中,云计算是分布式计算的一种,由一群松散耦合的计算机集组成的一个超级虚拟计算机。
计算设备可以是,但不限于任何一种可与用户通过键盘、触摸板或声控设备等方式进行人机交互的个人电脑、服务器等终端。本文中的计算设备还可以包括移动终端,其可以是,但不限于任何一种可与用户通过键盘、触摸板或声控设备等方式进行人机交互的电子设备,例如,平板电脑、智能手机、个人数字助理(Personal Digital Assistant,PDA)、智能式穿戴式设备等终端。计算设备所处的网络包括,但不限于互联网、广域网、城域网、局域网、虚拟专用网络(Virtual Private Network,VPN)等。
所述存储器用于存储程序代码。所述存储器可以是集成电路中没有实物形式的具有存储功能的电路,如RAM(Random-Access Memory,随机存取存储器)、FIFO(First InFirst Out)等。或者,所述存储器也可以是具有实物形式的存储器,如内存条、TF卡(Trans-flash Card)、智能媒体卡(smart media card)、安全数字卡(secure digital card)、快闪存储器卡(flash card)等储存设备等等。
所述处理器可以包括一个或者多个微处理器、数字处理器。所述处理器可调用存储器中存储的程序代码以执行相关的功能。例如,图8中所述的各个模块是存储在所述存储器中的程序代码,并由所述处理器所执行,以实现上述方法。所述处理器又称中央处理器(CPU,Central Processing Unit),可以是一块超大规模的集成电路,是运算核心(Core)和控制核心(Control Unit)。
需要说明的是,对于前述的各方法实施例,为了简单描述,故将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本发明并不受所描述的动作顺序的限制,因为依据本发明,某些步骤可以采用其他顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例均属于优选实施例,所涉及的动作和模块并不一定是本发明所必须的。
在上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述的部分,可以参见其他实施例的相关描述。
在本申请所提供的几个实施例中,应该理解到,所揭露的装置,可通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或元件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性或其它的形式。
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
另外,在本发明的各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可为个人计算机、服务器或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、只读存储器(ROM,Read-Only Memory)、随机存取存储器(RAM,Random Access Memory)、移动硬盘、磁碟或者光盘等各种可以存储程序代码的介质。
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
以上所述实施例仅表达了本申请的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对申请专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本申请构思的前提下,还可以做出若干变形和改进,这些都属于本申请的保护范围。因此,本申请专利的保护范围应以所附权利要求为准。