一种健康评估迭代分类器模型的构建方法
文献发布时间:2023-06-19 09:30:39
技术领域
本发明属于健康评估的技术领域,具体涉及一种健康评估迭代分类器模型的构建方法。
背景技术
随着国家社会经济不断地发展,人们在衣食住行等各个方面得到了更好的供给,开始追求更好的身心健康品质。近几年,伴随国家城市化进程的加快,人们的工作、生活压力也不断增多,很多新闻播出“某员工猝死”、“某某抑郁”等等负面新闻,可以通过这些信息了解到健康对人们的重要性,为了防止出现不可挽回的局面,及时的发现健康变化,解决出现的危害是重中之重的事情。但是目前已有的健康评估方法大多数是从生物医学角度或者问卷调查方面进行的,存在较强的主观性和片面性,不能很好的对被评估者的健康状态进行评估。
目前的健康评估方法大致分为调查收集信息和生物医学各项参数检测。前者是通过大量的问卷形式对被评估者进行健康调查,问卷中的问答是由相关专家为了达到健康评估的目的设计的,但该方法过于依赖被评估者对自身健康状态的了解程度,主观性较强。后者是比较狭义的“健康”,是从生物医学角度解释健康观,健康就等于不患有任何疾病,但是广义上的健康应定义为生物医学上、精神上、社会形态上都处于完好状态,而且一个人的健康容易受到各种因素影响,比如饮食习惯、工作时间、医疗条件、生活习性等等,所以需要从各个方面对健康进行评估。
因此,急需提出一种将调查收集信息和生物医学各项参数检测相结合进行健康评估方法,从被评估者生存环境中的各个方面进行研究分析,及时发现影响健康的问题,从而快速解决这些问题,提高用户的身心健康。
发明内容
本发明的目的在于提供一种健康评估迭代分类器模型的构建方法,旨在解决上述问题,实现用户直观地了解自己的健康状况,并及时发现影响健康的问题。
本发明主要通过以下技术方案实现:
一种健康评估迭代分类器模型的构建方法,收集健康数据并确定每种影响因素的数值区间标准,然后把收集的健康数据按照数值区间标准进行划分,标记类别;采用模糊集隶属度函数确定每种因素对用户健康的影响程度,构成训练所需的训练样本集;训练迭代分类器模型,所述迭代分类器模型采用若干个弱分类器集成强分类器,所述弱分类器采用BP神经网络结构。验证迭代分类器模型精度,并选择最优的迭代分类器模型。
所述的迭代分类器采用多个弱分类器集成形成强分类器,不易在训练过程中造成过拟合情况。所述BP神经网络能对未处理过的噪声具有一定的容错能力,而且具有良好的泛化能力。本发明利用机器学习方法建立出一种能测控用户健康变化的评估模型,充分的对用户的健康进行分析,可以让用户直观地了解到自己的健康状况,及时发现影响健康的问题,从而快速解决这些问题,提高用户的身心健康。
本发明在使用过程中,收集用户的饮食习惯、工作时间、医疗条件、生活习性以及患病史等相关信息,可以通过咨询专家确定每种影响因素的数值区间标准,然后把这些信息按照数值区间标准进行划分,标记类别。
为了更好地实现本发明,进一步地,所述的数值区间标准是相关专家针对某影响健康的信息设定的区间范围,而且考虑到各种影响因素数值的不一致性,需将信息数值按相关指标进行归一化计算。
数值区间标准是由相关专家判断收集的某用户各项信息是否满足健康标准而定义的区间值。为了避免数据信息的不一致性带来的误差,需对信息进行归一化处理,如饮食方面的数值采用体质指数计算,公式如下:
公式中Kg为用户的体重,H为用户的身高。而生活习性可以采用国民幸福指数进行计算,计算公式为:
公式中II表示用户收入的递增,GC表示基尼系数,UR表示失业率,IN表示通货膨胀,可以充分的反映用户的生活质量和幸福程度。其他因素如工作时间按照一天工作时效计算,医疗条件采用医保普及率表示,患病史包含家族病史、重大疾病等生物医学信息。
为了更好地实现本发明,进一步地,所述模糊集隶属度函数通过高斯混合模型计算每个数据点的概率分布,再根据得到的概率分布赋予不同数据点重要程度不同的隶属度。
目前大多数模糊隶属度函数的研究都是基于样本点到类别中心点的距离构建的距离度量隶属度,离中心点距离越近隶属度越高,其设计直接影响分类器的性能。如果数据中出现离散点时,利用距离度量构建的隶属度函数会导致分类器分类方向倾向离散点,造成分类误差,降低分类精度。所以本发明设计的模糊隶属度函数不再使用距离度量为基准,而是使用聚类方法自动生成样本点的概率分布,并根据概率值赋予不同样本重要程度不同的隶属度,减弱隶属度函数对离散点、异常点的敏感度。本发明的聚类方法采用高斯混合模型,因为高斯混合模型是一种软聚类方法,可以得到样本点在高斯分布下的概率值,得到不同样本的重要程度。
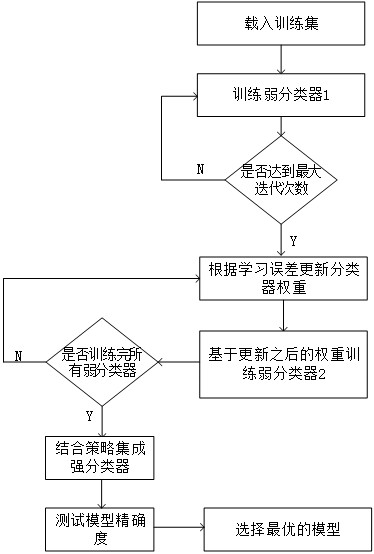
为了更好地实现本发明,进一步地,训练迭代分类器模型主要包括以下步骤:
步骤S100:载入训练样本集,初始化分类器模型权重,训练弱分类器1;
步骤S200:按照设定的迭代次数训练弱分类器,达到最大迭代次数时,计算误差率e
步骤S300:使用更新之后的权重参数训练弱分类器2;
步骤S400:重复步骤S100-S300直至训练完所有弱分类器;
步骤S500:使用结合策略将所有弱分类器集成强分类器,并对强分类器进行精度测试,选择最优的分类模型。
为了更好地实现本发明,进一步地,所述步骤S500中,首先计算t次迭代之后每个弱分类模型的平均精度均值,并将平均精度均值作为每个弱分类器的权重w;利用加权投票法将多个弱分类器集成强分类器,公式为:
其中:G
为了更好地实现本发明,进一步地,权重α
其中,R为分类器的类别数量,lr为分类器训练的学习率。所述lr设为0.001。
为了更好地实现本发明,进一步地,所述健康数据包括用户的饮食习惯、工作时间、医疗条件、生活习性以及患病史信息中的任意一种或者多种。
本发明的有益效果:
(1)本发明利用迭代分类器构造用户所处的社会公共卫生与环境和用户自身生物医学状态的健康评估模型,可以让用户直观地了解到自己的健康状况,及时发现影响健康的问题,从而快速解决这些问题,提高用户的身心健康,与现有技术相比,具有显著的进步。
(2)本发明设计的模糊隶属度函数不再使用距离度量为基准,而是使用聚类方法自动生成样本点的概率分布,并根据概率值赋予不同样本重要程度不同的隶属度,减弱隶属度函数对离散点、异常点的敏感度。
(3)本发明提出为每种影响健康的因素建立对应的隶属度,能确定各个因素对健康的影响程度,加快发现存在的问题的速度。
(4)结合策略采用改进的加权投票法,该方法能剔除分类错误的冗余弱分类器,提高分类精度和速度。
(5)所述BP神经网络能对未处理过的噪声具有一定的容错能力,而且具有良好的泛化能力。
附图说明
图1为本发明模型构建的流程图;
图2为生成样本集的流程图;
图3为迭代分类器模型训练流程图。
具体实施方式
实施例1:
一种健康评估迭代分类器模型的构建方法,如图1、图2所示,收集健康数据并确定每种影响因素的数值区间标准,然后把收集的健康数据按照数值区间标准进行划分,标记类别;采用模糊集隶属度函数确定每种因素对用户健康的影响程度,构成训练所需的训练样本集;训练迭代分类器模型,所述迭代分类器模型采用若干个弱分类器集成强分类器,所述弱分类器采用BP神经网络结构。
所述的迭代分类器采用多个弱分类器集成形成强分类器,不易在训练过程中造成过拟合情况。所述BP神经网络能对未处理过的噪声具有一定的容错能力,而且具有良好的泛化能力。本发明利用机器学习方法建立出一种能测控用户健康变化的评估模型,充分的对用户的健康进行分析,可以让用户直观地了解到自己的健康状况,及时发现影响健康的问题,从而快速解决这些问题,提高用户的身心健康。
实施例2:
本实施例是在实施例1的基础上进行优化,如图2所示,所述模糊集隶属度函数通过高斯混合模型计算每个数据点的概率分布,再根据得到的概率分布赋予不同数据点重要程度不同的隶属度。本发明提出为每种影响健康的因素建立对应的隶属度,能确定各个因素对健康的影响程度,加快发现存在的问题的速度。
目前大多数模糊隶属度函数的研究都是基于样本点到类别中心点的距离构建的距离度量隶属度,离中心点距离越近隶属度越高,其设计直接影响分类器的性能。如果数据中出现离散点时,利用距离度量构建的隶属度函数会导致分类器分类方向倾向离散点,造成分类误差,降低分类精度。所以本发明设计的模糊隶属度函数不再使用距离度量为基准,而是使用聚类方法自动生成样本点的概率分布,并根据概率值赋予不同样本重要程度不同的隶属度,减弱隶属度函数对离散点、异常点的敏感度。本发明的聚类方法采用高斯混合模型,因为高斯混合模型是一种软聚类方法,可以得到样本点在高斯分布下的概率值,得到不同样本的重要程度。
本实施例的其他部分与实施例1相同,故不再赘述。
实施例3:
本实施例是在实施例1或2的基础上进行优化,如图3所示,训练迭代分类器模型主要包括以下步骤:
步骤S100:载入训练样本集,初始化分类器模型权重,训练弱分类器1;
步骤S200:按照设定的迭代次数训练弱分类器,达到最大迭代次数时,计算误差率e
步骤S300:使用更新之后的权重参数训练弱分类器2;
步骤S400:重复步骤S100-S300直至训练完所有弱分类器;
步骤S500:使用结合策略将所有弱分类器集成强分类器,并对强分类器进行精度测试,选择最优的分类模型。
进一步地,首先计算t次迭代之后每个弱分类模型的平均精度均值,并将平均精度均值作为每个弱分类器的权重w;利用加权投票法将多个弱分类器集成强分类器,公式为:
其中:G
所述结合策略采用改进的加权投票法,该方法能剔除分类错误的冗余弱分类器,提高分类精度和速度。
进一步地,权重α
其中,R为分类器的类别数量,lr为分类器训练的学习率,设为0.001。
本实施例的其他部分与上述实施例1或2相同,故不再赘述。
实施例4:
一种健康评估迭代分类器模型的构建方法,如图1-图3所示,主要包括以下步骤:
收集用户的饮食习惯、工作时间、医疗条件、生活习性以及患病史等相关信息;
咨询相关专家确定每种影响因素的数值区间标准,然后把这些信息按照数值区间标准进行划分,标记类别;
搭建迭代分类器模型进行分类训练,并且构造模糊集隶属度函数确定每种因素对用户健康的影响程度,构成训练所需的训练样本集;
训练迭代分类器模型,验证分类器精度,选出最优的模型。
其中,数值区间标准是由相关专家判断收集的某用户各项信息是否满足健康标准而定义的区间值。在本发明提出的方法中,为了避免数据信息的不一致性带来的误差,需对信息进行归一化处理。
本发明设计的模糊隶属度函数不再使用距离度量为基准,而是使用聚类方法自动生成样本点的概率分布,并根据概率值赋予不同样本重要程度不同的隶属度,减弱隶属度函数对离散点、异常点的敏感度。本发明的聚类方法采用高斯混合模型,因为高斯混合模型是一种软聚类方法,可以得到样本点在高斯分布下的概率值,得到不同样本的重要程度。
迭代分类器采用多个弱分类器集成形成强分类器,其中,弱分类器采用BP神经网络,BP神经网络能对未处理过的噪声具有一定的容错能力,而且具有良好的泛化能力。假设训练样本集为
1.载入训练样本集,初始化分类器模型权重,训练弱分类器1;
2.按照设定的迭代次数训练弱分类器1,达到最大迭代次数时计算误差率e
其中R为分类器的类别数量,lr为分类器训练的学习率,设为0.001。
3.使用更新之后的权重参数训练弱分类器2;
4.重复步骤2的计算方式,直至所有弱分类器得到训练,总共有10个弱分类器;
5.使用结合策略将所有弱分类器集成形成强分类器,并对强分类器进行精度测试,选出最优的模型作为最终的分类模型。
其中,结合策略采用改进的加权投票法,该方法能剔除分类错误的冗余弱分类器,提高分类精度和速度。主要做法如下:
1)计算t次迭代之后每个弱分类模型的平均精度均值(Mean Average Precision,mAP),并将平均精度均值作为每个分类器的权重w;
2)利用加权投票法将多个弱分类器集成强分类器,公式为:
公式中G
本发明在使用过程中,只需要收集用户的相关信息输入到模型中,就能直观地告诉用户健康变化情况,并且还能告诉用户影响健康的因素是什么,能让用户及时改善或解决问题,提高身心健康。
以上所述,仅是本发明的较佳实施例,并非对本发明做任何形式上的限制,凡是依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化,均落入本发明的保护范围之内。