一种基于机器学习的多组分晶体构型能预测方法
文献发布时间:2023-06-19 09:32:16
技术领域
本发明属于材料固有属性计算领域,具体涉及一种基于机器学习的多组分晶体构型能预测方法。
技术背景
在进行材料一些固有属性的计算时,传统的方法依然严格依赖于物理理论推导,并借助诸如第一性原理或者有着严格线性约束的物理公式进行计算,近年来机器学习工具在材料科学的研究中显著增加,机器学习在材料科学应用中的一个挑战就是识别对于一些有潜在对称问题上的固定结构和化学描述符。因此,如何从机器学习的角度解决材料固有属性的计算是一个值得研究的问题。
发明内容
鉴于以上问题,本发明提出一种基于机器学习的多组分晶体构型能预测方法,所述构型能定义为不同构型的形成能,本发明用以解决传统方法中单纯依赖于物理理论推导多组分晶体构型能而导致的预测计算不准确及不高效问题。
一种基于机器学习的多组分晶体构型能预测方法,包括以下步骤,
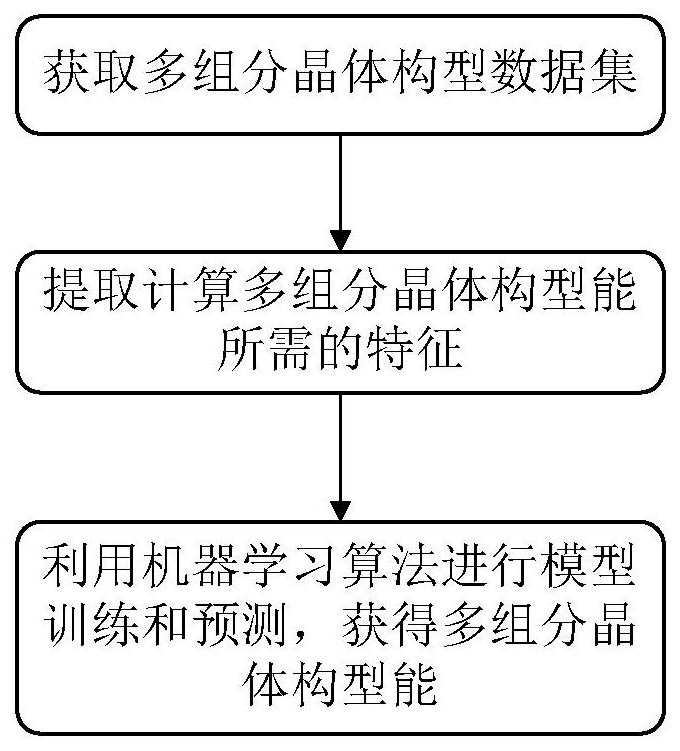
步骤一、获取多组分晶体构型数据集;
步骤二、提取计算多组分晶体构型能所需的特征;
步骤三、利用机器学习算法进行模型训练和预测,获得多组分晶体构型能。
进一步地,步骤三中利用机器学习算法进行模型训练和预测获得多组分晶体局部中心位点的能量,再将所述多组分晶体局部中心位点的能量加和,最终获得多组分晶体构型能。
进一步地,步骤二中采用团簇扩展方法进行特征提取。
进一步地,采用团簇扩展方法进行特征提取的具体步骤包括,
步骤二一、首先对多组分晶体进行不同团簇轨道划分;
步骤二二、然后对团簇类型扩展进行截断;
步骤二三、最后计算各团簇轨道上的相关函数,所述相关函数即为计算多组分晶体构型形成能所需的特征。
进一步地,步骤二二中所述截断包括对提取后的特征采用遗传算法进行特征筛选,去除对被预测属性影响不大的特征。
进一步地,所述相关函数是团簇轨道上所有对称等价团簇函数的平均值,可表示为:
其中,m
进一步地,步骤三中所述机器学习算法包括神经网络、高斯过程回归、支持向量回归、随机森林。
进一步地,步骤三中利用机器学习算法进行模型训练和预测时弱化所述相关函数的线性约束,即允许构型能对相关函数具有非线性依赖性。
进一步地,步骤三中所述多组分晶体构型能表示式为:
其中,N表示原子个数;V
本发明的有益技术效果是:
本发明提出了以团簇扩展方法计算多组分晶体的构型能,通过将多体相互作用形成的团簇函数即相关函数作为输入特征值,然后利用机器学习算法进行模型训练和预测,获得多组分晶体构型能,相比于传统的严格依赖于物理理论推导的计算方法,本发明方法预测计算结果更加准确、高效。
附图说明
本发明可以通过参考下文中结合附图所给出的描述而得到更好的理解,其中在所有附图中使用了相同或相似的附图标记来表示相同或者相似的部件。所述附图连同下面的详细说明一起包含在本说明书中并且形成本说明书的一部分,而且用来进一步举例说明本发明的优选实施例和解释本发明的原理和优点。
图1示出了根据本发明实施方式的一种基于机器学习的多组分晶体构型能预测方法的示意性流程图。
图2示出了根据本发明实施方式的一种基于机器学习的多组分晶体构型能预测方法的应用各机器学习算法的多组分晶体构型能预测结果图;其中,图(a)表示应用神经网络的构型能预测结果,图(b)表示应用随机森林的构型能预测结果,图(c)表示应用支持向量回归的构型能预测结果,图(d)表示应用高斯过程回归的构型能预测结果。
图3示出了根据本发明实施方式的一种基于机器学习的多组分晶体构型能预测方法的经过特征筛选之后应用各机器学习算法的多组分晶体构型能预测结果图;其中,图(a)表示应用神经网络的构型能预测结果,图(b)表示应用随机森林的构型能预测结果,图(c)表示应用支持向量回归的构型能预测结果,图(d)表示应用高斯过程回归的构型能预测结果。
具体实施方式
在下文中将结合附图对本发明的示范性实施例进行描述。为了清楚和简明起见,在说明书中并未描述实际实施方式的所有特征。然而,应该了解,在开发任何这种实际实施例的过程中必须做出很多特定于实施方式的决定,以便实现开发人员的具体目标,例如,符合与系统及业务相关的那些限制条件,并且这些限制条件可能会随着实施方式的不同而有所改变。此外,还应该了解,虽然开发工作有可能是非常复杂和费时的,但对得益于本发明内容的本领域技术人员来说,这种开发工作仅仅是例行的任务。在此,还需要说明的一点是,为了避免因不必要的细节而模糊了本发明,在附图中仅仅示出了与根据本发明的方案密切相关的装置结构和/或处理步骤,而省略了与本发明关系不大的其他细节。
图1示出了根据本发明实施方式的一种基于机器学习的多组分晶体构型能预测方法的示意性流程图。如图1所示,该方法包括,
步骤一、获取多组分晶体构型数据集;
步骤二、提取计算多组分晶体构型能所需的特征;
进一步地,利用团簇扩展方法提取计算多组分晶体构型形成能所需的特征,该特征提取方法包括以下步骤,
步骤二一、首先对多组分晶体进行不同团簇轨道划分,例如划分为対簇、三簇、四簇;
步骤二二、然后对团簇类型扩展进行截断;
步骤二三、最后计算各团簇轨道上的相关函数,所述相关函数即为计算多组分晶体构型形成能所需的特征;其中,相关函数是所有对称等效簇函数的平均值,即将同一团簇轨道上的所有团簇函数相加,并除以团簇不同类型的个数。相关函数可表示为:
其中,m
步骤三、利用机器学习算法进行模型训练和预测,获得多组分晶体构型能;或者,利用机器学习算法进行模型训练和预测,获得多组分晶体局部中心位点的能量,再将多组分晶体局部中心位点的能量加和,获得多组分晶体构型能。
团簇扩展被公式化为线性团簇基函数乘以常数扩展系数,常数扩展系数取决于多组分固体的基本化学性质和晶体结构。团簇扩展在形式上是精确的,但实际上必须被截断。本发明以团簇扩展方法为基础,但放宽了线性约束,进行特征选取计算,允许用团簇展开的方式依据扩展系数来构建可以描述构型的函数,已广泛应用于金属和半导体合金物理性能的第一性原理计算。下面以简单的二元合金对团簇扩展方法作详细解释说明。
N个位点的元晶体组成的特定顺序可以由占位变量的展开向量来表示:
该和延伸到晶体内位点α所有的簇(例如点簇、对簇、三重态簇等),且:
团簇函数
任何两个团簇函数
由于对称相同的团簇的扩展系数是相同的,所以每个团簇函数的轨道上就仅存在一个扩展系数。这样就可以将完全松弛的形成能表示式重写,如下式所示,首先将轨道求和,然后将每个轨道内的团簇函数求和:
上式通过晶体中的原子数归一化,可重写为:
其中,m
对于二元合金,每个对称不同的团簇类型,例如最近邻对簇、次近邻对簇、最近邻三重态簇等,都有相关函数
将团簇扩展后的能量重新转换为站点能量之和是具有指导意义的。为此,定义
单个位点能量被定义为:
其中,|α|是总能量公式(6)中出现的团簇中的所有位点数量,是为了避免在计算各个位点能量和的时候重复相加。
上述单个位点能量公式(7)表明了局部中心位点相关函数被定义为:
在测量局部有序度时,上式中是含有位点i的所有对称等价团簇的加和,在被母晶的局部有序度进行群组操作允许的情况下位点i周围的方位做任何改变它都是不变的。
具体实施例一
本发明是在严格物理理论推导下,选取与将要计算的属性有相关性的输入特征,并借助机器学习算法模型,弱化线性约束,从而进行模型训练,得出一个能够方便计算的非线性机器学习算法模型。
合金的特性对母体晶体结构上不同化学物种的有序性或无序性很敏感,但是作为机器学习问题,合金受到的关注较少。在这里,从机器学习的角度解决了合金问题,并表明可以使用在晶格模型哈密顿量的背景下开发的数学工具来制定合适且稳定的构型有序度的描述符。
在此,以团簇扩展方法为基础,但放宽了线性约束,并利用高级的机器学习工具(例如神经网络和高斯过程回归)来表示依赖于合金构型的晶体特性(取决于对称性的不变的顺序描述符)。作为描述符,使用相关函数,即由团簇基函数计算而得的机器学习模型所需训练输入特征,通过对氧化锆ZrO进行不同构型的形成能进行建模来说明该方法。
首先建立CASM所需唯一输入文件prim.json,该文件为计算的晶体材料的晶格常数、晶格矢量、基元形式、原子坐标模式、晶格描述(fcc,bcc,hcp等)、晶体名称;在Linux系统下将输入文件输入进行项目初始化,选择合成轴,然后执行;设置截止扩大体积倍数,然后生成描述该晶体不同构型的文件;
然后利用VASP等第一性原理计算软件给出上述该晶体相关构型的形成能,用作后续进行机器学习算法模型训练的训练集和测试集;
然后设置合适的化学参考参数,指定团簇基函数和轨道参数,生成团簇基集文件,用于后续训练机器学习模型所需的输入特征,特征提取方法可采用软件CASM(一种基于统计力学的团簇方法(GitHub上开源软件))进行特征提取;一个晶体的构型能可以表示为:
其中,N表示原子个数;V
其中,
进一步地,将相关函数和能量之间的线性约束放宽,得到上述训练所需标签和输入特征之后,训练机器学习模型来寻找他们之间的关系,选择的机器学习算法包括神经网络、高斯过程回归(GPR)、支持向量回归(SVR)、随机森林(RF)等。
该晶体相关构型形成能数据集包括336种构型,且每个标签中含有74个相关函数(corr)作为特征,数据集中的75%作为训练集,25%作为测试集;测试时采用bootstrap方法进行随机选取测试集,用MSE(均方误差)和R2(决定系数)用来评估预测值与真实值的拟合程度,其中,MSE越小表示拟合越好,R2越大表示拟合越好,图2和表1示出了构型能预测结果,其中,图2中(a)表示应用神经网络的构型能预测结果,(b)表示应用随机森林的构型能预测结果,(c)表示应用支持向量回归的构型能预测结果,(d)表示应用高斯过程回归的构型能预测结果。从中可以看出,综合各种机器学习算法运用之后来看MSE和R2表现,通过本发明预测方法获得的预测值与真实值拟合度很高,均方误差较小;综合以上几种算法来看,神经网络表现最优秀,支持向量回归表现稍差。
表1
在输入特征的选择上可以用遗传算法等进行筛选,选择相关性更强且对被预测属性影响更大的特征,去掉冗余特征,提高准确度和效率。每一个索引(index)中的二进制数字为74个,即特征筛选之前共截断到74个团簇轨道,每个团簇轨道上都是等价对称团簇,所用的特征由此给出,index值越小,表示筛选出的特征组合越优越;其中标志置为1的特征组合中对应编号的团簇轨道被选中,获得对应的相关函数作为机器学习模型训练的输入特征,再次重复上面训练预测操作,图3和表2示出了经过特征筛选后的构型能预测结果,其中,图3中(a)表示应用神经网络的构型能预测结果,(b)表示应用随机森林的构型能预测结果,(c)表示应用支持向量回归的构型能预测结果,(d)表示应用高斯过程回归的构型能预测结果。从中可以看出,进行特征筛选之后的预测结果要比筛选之前更加精准,误差更低,拟合度更好。
表2
尽管根据有限数量的实施例描述了本发明,但是受益于上面的描述,本技术领域内的技术人员明白,在由此描述的本发明的范围内,可以设想其它实施例。此外,应当注意,本说明书中使用的语言主要是为了可读性和教导的目的而选择的,而不是为了解释或者限定本发明的主题而选择的。因此,在不偏离所附权利要求书的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。对于本发明的范围,对本发明所做的公开是说明性的,而非限制性的,本发明的范围由所附权利要求书限定。