一种堆叠千克组砝码识别与关键部位分割方法
文献发布时间:2023-06-19 09:33:52
技术领域
本发明涉及机器学习实例分割技术领域,尤其涉及一种堆叠千克组砝码识别与关键部位分割方法。
背景技术
堆叠砝码与砝码之间、砝码抓手的识别是典型的遮挡对象低对比度低饱和度图像检测问题。低对比度图像具有邻近像素的空间相关性高、灰度变化不明显的特点,图像中的目标、细节、特征等信息都包含在一个较窄的灰度范围内而难以区分,从而给目标的识别与分割带来困难。传统的目标识别方法多基于对轮廓片段等局部特征的模板匹配,记录匹配得分的情况实现对遮挡目标的识别。基于模板匹配的传统识别方法对遮挡物体的识别需要在特定的条件下才可以较准确的识别,在面对低对比度低饱和度遮挡物体时准确率不佳、定位误差较大。本发明提出的一种堆叠千克组砝码识别与关键部位分割方法,这个算法利用了目前先进的深度神经网络,具有很好的图像理解能力,再加上合理的图像增强及数据增强,解决了识别堆叠千克组砝码的问题。
发明内容
为解决上述技术问题,本发明的目的是提供一种堆叠千克组砝码识别与关键部位分割方法。
本发明的目的通过以下的技术方案来实现:
一种堆叠千克组砝码识别与关键部位分割方法,包括:
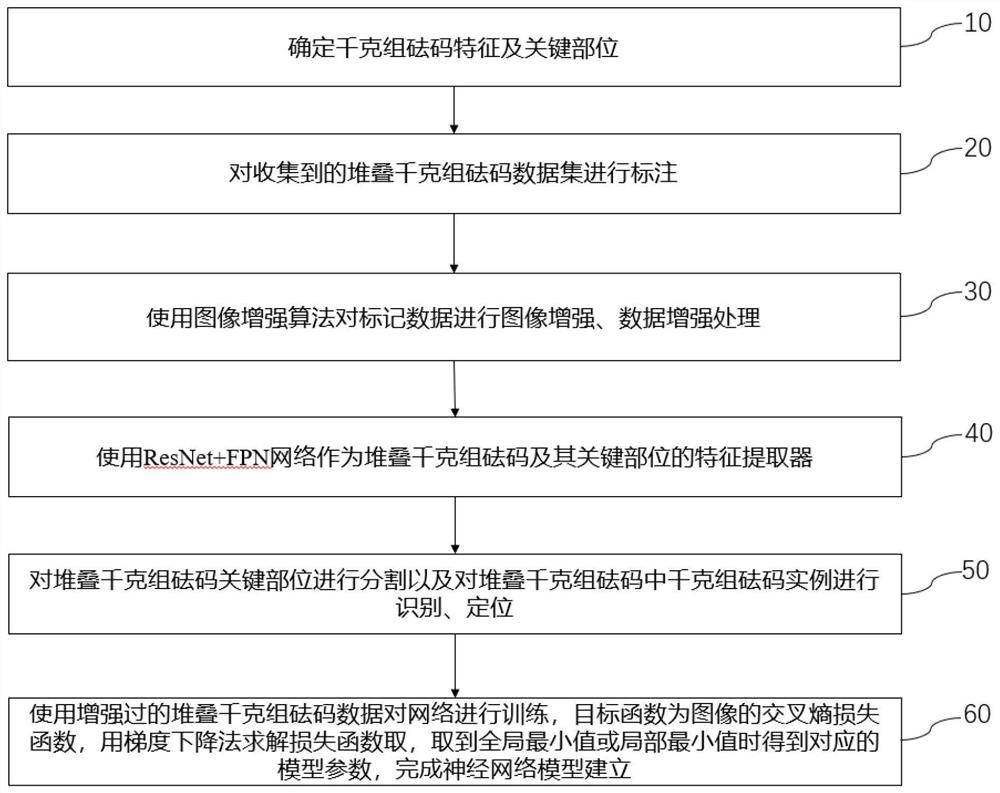
A确定千克组砝码特征及关键部位;
B对收集到的堆叠千克组砝码数据集进行标注;
C使用图像增强算法对标记数据进行图像增强、数据增强处理;
D使用ResNet+FPN网络作为堆叠千克组砝码及其关键部位的特征提取器;
E对堆叠千克组砝码关键部位进行分割以及对堆叠千克组砝码中千克组砝码实例进行识别、定位;
F使用增强过的堆叠千克组砝码数据对网络进行训练,目标函数为图像的交叉熵损失函数,用梯度下降法求解损失函数取,取到全局最小值或局部最小值时得到对应的模型参数,完成神经网络模型建立。
与现有技术相比,本发明的一个或多个实施例可以具有如下优点:
可以快速精准地识别、分割堆叠千克组砝码及其关键部位,可适用于部分遮挡的低对比度物体识别与分割。为千克组砝码智能化检定过程的自动化抓取扫除了识别的技术障碍,为复杂环境下堆叠物体识别分割提供了相关技术。
附图说明
图1是堆叠千克组砝码识别与关键部位分割方法流程框图;
图2是改进Mask R-CNN网络的基础结构图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合实施例及附图对本发明作进一步详细的描述。
本实施例提供了一种堆叠千克组砝码识别与关键部位分割方法,该方法是先将图片输入骨干网络进行特征提取得到特征图,以特征图中像素点为中心,设定若干个感兴趣区域;利用滑动窗口在特征图上为每个像素点生成若干预设尺寸的锚点框(anchor),通过anchor与ground truth间IoU(intersection over union,IoU)数值判断anchor中为目标或者背景,并修正目标anchor坐标。具体通过在x、y方向上增加平移修正量tx、ty,在长、宽方向上乘以tw、th进行缩放实现去掉anchor中判断为背景的ROI区域;边界框回归之前需经全连接层实现特征全连接计算,后输出边界框(bounding box);MASK生成分支则经图像维度扩展,经全卷积网络(fully convolutional network,FCN)后完成目标像素级实例分割。再用标注、增强好的样本数据将网络训练成识别、分割堆叠千克组砝码的专用网络。此网络可以快速精准地识别、分割堆叠千克组砝码及其关键部位,可适用于部分遮挡的低对比度物体识别与分割。为千克组砝码智能化检定过程的自动化抓取扫除了识别的技术障碍,为复杂环境下堆叠物体识别分割提供了相关技术。
如图1所示,为堆叠千克组砝码识别与关键部位分割流程,包括千克组砝码特征确定阶段;数据标注阶段;图片预处理、数据增强阶段;特征提取网络搭建阶段;特征识别与分割网络搭建阶段和网络训练阶段;具体包括如下步骤:
步骤10确定千克组砝码特征及关键部位;
步骤20使用VGG Image Annotator图形标注工具对收集到的堆叠千克组砝码数据集进行标注;
步骤30使用图像增强算法对标记数据进行图像增强、数据增强处理;
步骤40使用ResNet+FPN网络作为堆叠千克组砝码及其关键部位的特征提取器;
步骤50使用Fully convolutional Network全卷积网络对堆叠千克组砝码关键部位进行分割,Fully Connection Network全连接网络+Classifier分类器对堆叠千克组砝码中千克组砝码实例进行识别、定位;
步骤60使用增强过的堆叠千克组砝码数据对网络进行训练,目标函数为图像的交叉熵损失函数,用梯度下降法求解损失函数取,取到全局最小值或局部最小值时得到对应的模型参数,完成神经网络模型建立。
上述步骤10具体包括:
先确定千克组砝码易于辨识的特征,包括千克组砝码标识、千克组砝码边界;然后确定不太易于辨识的关键特征,包括堆叠千克组砝码边界、千克组砝码提手。
上述步骤20是在linux/ubuntu操作系统环境下,打开VGG Image Annotator图形标注工具软件,利用软件提供的多边形标注框标记图片中感兴趣的特征并给相应实例命名,对收集到的堆叠千克组砝码数据集进行标注,并将标注数据以JSON文件格式存储,方便后续操作。
上述步骤30编写图像增强程序对数据集中图片进行对比度增强,对数据集进行数据增强,使数据集中图片大致包含实际使用中的所有情况,具体过程包括以下步骤:
(1)读取标注数据集的图片及JSON数据;
(2)对每张图片进行对比度增强及其他形式的图像变换,如翻转、旋转等;
(3)对每张图片对应的JSON坐标数据进行步骤(2)中同等变换;
(4)将增强的图像输出,将变换过后的坐标信息填入JSON文件中对应的字典内;
(5)循环遍历数据集中所有图片进行步骤(1)、步骤(2)、步骤(3)、步骤(5),生成所需大小的数据集。
上述步骤40具体包括:从网络上下载已经构建好的在COCO数据集上经过预先训练的ResNet+FPN网络作为整个算法的特征提取器;ResNet的一个基本结构,可用如下函数表示:
F=W
y=F(x,W
其中,x、y分别表示网络的输入、输出;σ表示ReLU激活函数,W
上述步骤50具体包括:使用Fully convolutiona1 Network全卷积网络对堆叠千克组砝码关键部位进行分割,得到千克组砝码在图像中的MASK掩膜0-1二值图像;使用Fully Connection Network全连接网络+Classifier分类器对堆叠千克组砝码中千克组砝码实例进行定位,得到千克组砝码在图像中的定位框信息。
上述步骤60中网络训练的内容包括:使用增强过的堆叠千克组砝码数据对网络进行训练,目标函数为图像的交叉熵损失函数。其损失函数如下:
L
式中:
L
其中:
p
t
MASK损失为二分类均值交叉熵损失,仅在其对应的第K类ROI计算时有定义,其他K-1个MASK对整个损失函数不做贡献。
网络的训练可由如下最优化公式:
其中p
虽然本发明所揭露的实施方式如上,但所述的内容只是为了便于理解本发明而采用的实施方式,并非用以限定本发明。任何本发明所属技术领域内的技术人员,在不脱离本发明所揭露的精神和范围的前提下,可以在实施的形式上及细节上作任何的修改与变化,但本发明的专利保护范围,仍须以所附的权利要求书所界定的范围为准。
- 一种堆叠千克组砝码识别与关键部位分割方法
- 一种面向千克组砝码智能化检定的标准砝码搬运装置