一种数据映射关系建立方法
文献发布时间:2023-06-19 09:36:59
技术领域
本发明涉及矿山设备主数据与业务系统数据映射技术领域,特别涉及一种 数据映射关系建立方法。
背景技术
在三山岛金矿大数据项目规划建设过程中,一个主要目的就是能够沿三山 岛金矿矿石流和主业务流打通信息链和数据流,提升数据质量,实现数据“清 洁”,以支撑运营效率提升和经营结果的真实呈现,实现智慧数据驱动有效增长, 充分实现数据资产价值。在这个过程中主数据的识别管理和数据标准的制定建 立显得尤为重要。
在三山岛金矿识别出的众多主数据中,设备主数据的管理应用存在一个典 型的问题:标准设备主数据和其它源业务系统数据映射问题。
基于三山岛信息化建设现状,很多已经运行多年的业务系统存在改造困难 性,所以对于数据打通只能选择建立映射关系。现有技术主要通过手工建立设 备主数据与其它源业务系统数据之间的映射关系,存在工作量大和后期维护困 难的问题。
发明内容
本发明的目的在于提供一种数据映射关系建立方法,以解决现有技术中建 立映射关系工作量大、后期维护困难的问题。
为解决上述技术问题,本发明的实施例提供如下方案:
一种数据映射关系建立方法,包括以下步骤:
提取矿山设备主数据的特征信息;
提取待映射业务系统数据的特征信息;
利用人工智能算法对所述矿山设备主数据的特征信息及所述待映射业务系 统数据的特征信息进行深度匹配;
判断两者的匹配度是否达到预设标准;
若匹配度达到所述预设标准,则建立所述矿山设备主数据与所述待映射业 务系统数据之间的映射关系。
优选地,所述待映射业务系统数据为设备集中采购系统数据,所述数据映 射关系建立方法具体包括:
根据所述矿山设备主数据中的设备名称、规格型号、技术参数提取所述矿 山设备主数据的特征信息;
根据所述设备集中采购系统数据中的设备名称、规格型号、技术参数提取 所述设备集中采购系统数据的特征信息;
利用人工智能算法对所述矿山设备主数据的特征信息及所述设备集中采购 系统数据的特征信息进行深度匹配;
判断两者的匹配度是否达到预设标准;
若匹配度达到所述预设标准,则建立所述矿山设备主数据与所述设备集中 采购系统数据之间的映射关系。
优选地,所述待映射业务系统数据为物流及车间现场物资系统数据,所述 数据映射关系建立方法具体包括:
根据所述矿山设备主数据中的设备名称、规格型号、技术参数提取所述矿 山设备主数据的特征信息;
根据所述物流及车间现场物资系统数据中的班组名称、设备名称、规格型 号、物资备件领用参数提取所述物流及车间现场物资系统数据的特征信息;
利用人工智能算法对所述矿山设备主数据的特征信息及所述物流及车间现 场物资系统数据的特征信息进行深度匹配;
判断两者的匹配度是否达到预设标准;
若匹配度达到所述预设标准,则建立所述矿山设备主数据与所述物流及车 间现场物资系统数据之间的映射关系。
优选地,所述待映射业务系统数据为生产管理及生产考核系统数据,所述 数据映射关系建立方法具体包括:
根据所述矿山设备主数据中的设备名称、规格型号、技术参数提取所述矿 山设备主数据的特征信息;
根据所述生产管理及生产考核系统数据中的设备名称、规格型号提取所述 生产管理及生产考核系统数据的特征信息;
利用人工智能算法对所述矿山设备主数据的特征信息及所述生产管理及生 产考核系统数据的特征信息进行深度匹配;
判断两者的匹配度是否达到预设标准;
若匹配度达到所述预设标准,则建立所述矿山设备主数据与所述生产管理 及生产考核系统数据之间的映射关系。
优选地,所述待映射业务系统数据为集成化安全生产系统数据,所述数据 映射关系建立方法具体包括:
根据所述矿山设备主数据中的设备名称、规格型号、技术参数提取所述矿 山设备主数据的特征信息;
根据所述集成化安全生产系统数据中的作业地点、设备名称、规格型号提 取所述集成化安全生产系统数据的特征信息;
利用人工智能算法对所述矿山设备主数据的特征信息及所述集成化安全生 产系统数据的特征信息进行深度匹配;
判断两者的匹配度是否达到预设标准;
若匹配度达到所述预设标准,则建立所述矿山设备主数据与所述集成化安 全生产系统数据之间的映射关系。
优选地,所述待映射业务系统数据为自动化控制系统数据,所述数据映射 关系建立方法具体包括:
根据所述矿山设备主数据中的设备名称、规格型号、技术参数提取所述矿 山设备主数据的特征信息;
根据所述自动化控制系统数据中的由变量名标识的设备相关信息提取所述 集成化安全生产系统数据的特征信息;
利用人工智能算法对所述矿山设备主数据的特征信息及所述自动化控制系 统数据的特征信息进行深度匹配;
判断两者的匹配度是否达到预设标准;
若匹配度达到所述预设标准,则建立所述矿山设备主数据与所述自动化控 制系统数据之间的映射关系。
优选地,所述预设标准为匹配度大于等于95%。
优选地,所述人工智能算法包括聚类算法和语义识别算法。
优选地,所述数据映射关系建立方法还包括:
建立所述矿山设备主数据与所述待映射业务系统数据之间的映射关系之 后,利用互通信息进行设备单耗分析、设备监测与故障诊断、设备供应商追踪 考核。
本发明实施例提供的技术方案带来的有益效果至少包括:
本发明实施例中,通过提取矿山设备主数据和待映射业务系统数据的特征 信息,利用人工智能算法对两者提取的特征信息进行深度匹配,当匹配度达到 预设标准时,建立矿山设备主数据与待映射业务系统数据之间的映射关系,实 现了矿山设备主数据与各业务系统数据之间的互通,提升了数据质量,得到了 一致的、可靠的、有效的、可共享的各业务数据,提升了运营效率,具有广泛 的应用前景。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所 需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明 的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下, 还可以根据这些附图获得其他的附图。
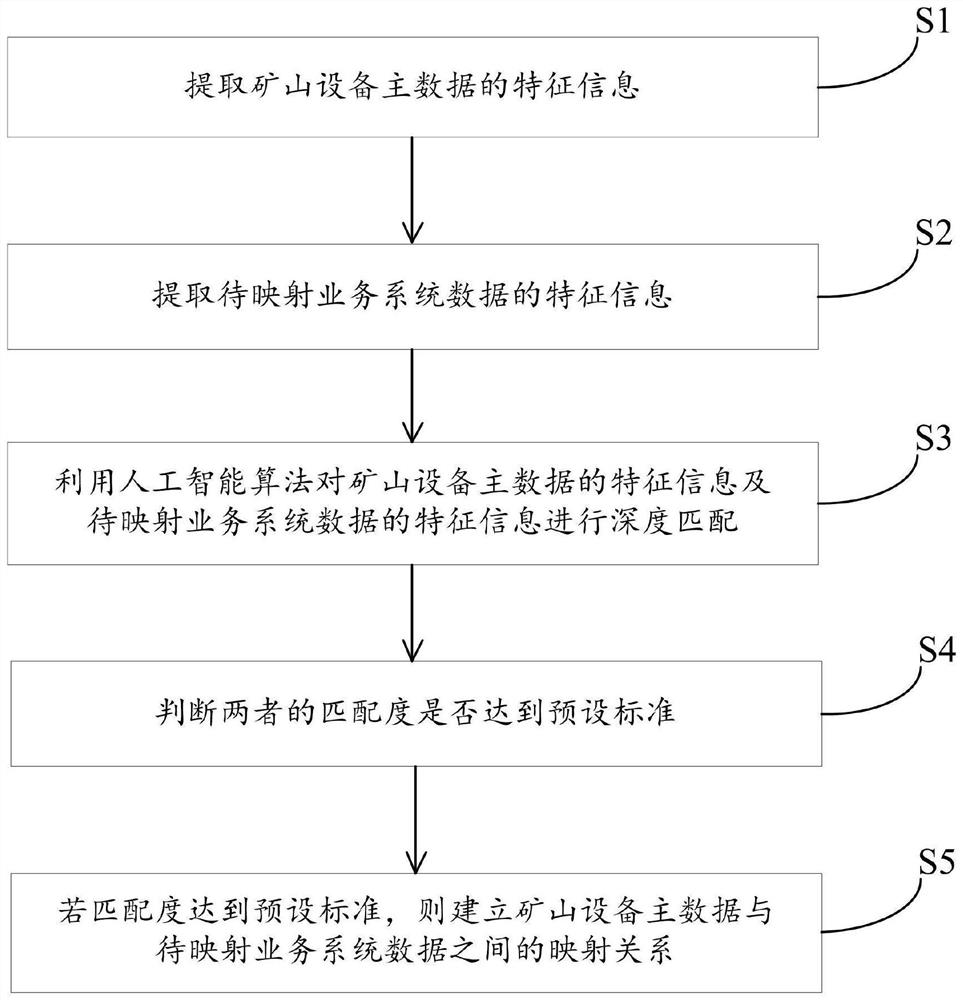
图1是本发明实施例提供的一种数据映射关系建立方法的流程图;
图2是本发明实施例中的算法模型示意图;
图3是本发明实施例中数据流转过程的示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明 实施方式作进一步地详细描述。
本发明的实施例提供了一种数据映射关系建立方法,如图1所示,该方法 包括以下步骤:
S1、提取矿山设备主数据的特征信息;
S2、提取待映射业务系统数据的特征信息;
S3、利用人工智能算法对所述矿山设备主数据的特征信息及所述待映射业 务系统数据的特征信息进行深度匹配;
S4、判断两者的匹配度是否达到预设标准;
S5、若匹配度达到所述预设标准,则建立所述矿山设备主数据与所述待映 射业务系统数据之间的映射关系。
本发明通过提取矿山设备主数据和待映射业务系统数据的特征信息,利用 人工智能算法对两者提取的特征信息进行深度匹配,当匹配度达到预设标准时, 建立矿山设备主数据与待映射业务系统数据之间的映射关系,实现了矿山设备 主数据与各业务系统数据之间的互通,提升了数据质量,得到了一致的、可靠 地、有效的、可共享的各业务数据,提升了运营效率,具有广泛的应用前景。
优选地,所述人工智能算法包括聚类算法和语义识别算法等,所述预设标 准为匹配度大于等于95%。
根据映射业务系统的不同,本发明方法可以分为以下几种情况:
当待映射业务系统数据为设备集中采购系统数据时,所述数据映射关系建 立方法具体包括:
根据矿山设备主数据中的设备名称、规格型号、技术参数提取矿山设备主 数据的特征信息;
根据设备集中采购系统数据中的设备名称、规格型号、技术参数提取设备 集中采购系统数据的特征信息;
利用人工智能算法对矿山设备主数据的特征信息及设备集中采购系统数据 的特征信息进行深度匹配;
判断两者的匹配度是否达到预设标准;
若匹配度达到预设标准,则建立矿山设备主数据与设备集中采购系统数据 之间的映射关系。
设备集中采购系统中的设备信息是事业部为了自身集采物业的开展进行编 码、维护的,与矿山设备主数据是两套信息,所以要打通这两方面的数据,需 根据矿山设备主数据中的设备名称、规格型号、技术参数和设备集中采购系统 数据中的设备名称、规格型号、技术参数,利用人工智能算法技术对比两个设 备是否是同一个设备(匹配度达到95%以上),如果是则建立映射关系。
当待映射业务系统数据为物流及车间现场物资系统数据,所述数据映射关 系建立方法具体包括:
根据矿山设备主数据中的设备名称、规格型号、技术参数提取矿山设备主 数据的特征信息;
根据物流及车间现场物资系统数据中的班组名称、设备名称、规格型号、 物资备件领用参数提取物流及车间现场物资系统数据的特征信息;
利用人工智能算法对矿山设备主数据的特征信息及物流及车间现场物资系 统数据的特征信息进行深度匹配;
判断两者的匹配度是否达到预设标准;
若匹配度达到预设标准,则建立矿山设备主数据与物流及车间现场物资系 统数据之间的映射关系。
物流及车间现场物资系统没有设备相关的基础数据,对于消耗在重点设备 上的物资、备件数据是通过班组来关联的,若要打通这两方面的数据,需要通 过班组名称、设备名称、规格型号、物资备件领用参数进行语义、聚类的深度 匹配(匹配度达到95%以上),才能建立映射关系。
当待映射业务系统数据为生产管理及生产考核系统数据,所述数据映射关 系建立方法具体包括:
根据矿山设备主数据中的设备名称、规格型号、技术参数提取矿山设备主 数据的特征信息;
根据生产管理及生产考核系统数据中的设备名称、规格型号提取生产管理 及生产考核系统数据的特征信息;
利用人工智能算法对矿山设备主数据的特征信息及生产管理及生产考核系 统数据的特征信息进行深度匹配;
判断两者的匹配度是否达到预设标准;
若匹配度达到预设标准,则建立矿山设备主数据与生产管理及生产考核系 统数据之间的映射关系。
生产管理及生产考核系统有设备相关基础信息,可以通过设备名称、规格 型号与矿山设备主数据的设备名称、规格型号等进行语义、聚类的深度匹配(匹 配度达到95%以上),才能建立映射关系。
当待映射业务系统数据为集成化安全生产系统数据,所述数据映射关系建 立方法具体包括:
根据矿山设备主数据中的设备名称、规格型号、技术参数提取矿山设备主 数据的特征信息;
根据集成化安全生产系统数据中的作业地点、设备名称、规格型号提取集 成化安全生产系统数据的特征信息;
利用人工智能算法对矿山设备主数据的特征信息及集成化安全生产系统数 据的特征信息进行深度匹配;
判断两者的匹配度是否达到预设标准;
若匹配度达到预设标准,则建立矿山设备主数据与集成化安全生产系统数 据之间的映射关系。
集成化安全生产系统也没有设备相关基础信息,对于隐患排查等作业在重 点设备上的安全管理数据是通过作业地点进行关联的,所以若要打通这两方面 数据,需要通过作业地点、设备名称、规格型号进行语义、聚类的深度匹配(匹 配度达到95%以上),才能建立映射关系。
当待映射业务系统数据为自动化控制系统数据,所述数据映射关系建立方 法具体包括:
根据矿山设备主数据中的设备名称、规格型号、技术参数提取矿山设备主 数据的特征信息;
根据自动化控制系统数据中的由变量名标识的设备相关信息提取集成化安 全生产系统数据的特征信息;
利用人工智能算法对矿山设备主数据的特征信息及自动化控制系统数据的 特征信息进行深度匹配;
判断两者的匹配度是否达到预设标准;
若匹配度达到预设标准,则建立矿山设备主数据与自动化控制系统数据之 间的映射关系。
自动化控制系统的数据是按照变量参数通过工业协议传输的,里面设备相 关信息是通过变量名标识的,因此与矿山设备主数据的关联需要通过备注描述 进行语义、聚类的深度匹配(匹配度达到95%以上),然后建立映射关系。
具体地,以三山岛金矿设备主数据的设备名称、规格型号、技术参数组合 字符和设备集中采购系统中的设备名称、规格型号、技术参数组合字符作为算 法样例数据,带入到语义识别、聚类算法中,具体算法模型如图2所示。
文本分类问题包括特征工程和分类器两部分。
特征工程在机器学习中往往是最耗时耗力的,但却极其重要。抽象来讲, 机器学习问题是把数据转换成信息再提炼到知识的过程,特征是“数据–>信息” 的过程,决定了结果的上限,而分类器是“信息–>知识”的过程,则是去逼近 这个上限。
文本分类问题所在的自然语言领域自然也有其特有的特征处理逻辑,传统 分本分类任务大部分工作也在此处。文本特征工程包括文本预处理、特征提取、 文本表示三个部分,最终目的是把文本转换成计算机可理解的格式,并封装足 够用于分类的信息,具有很强的特征表达能力。
文本分类主要按以下几步进行:
1、文本预处理
文本预处理过程是在文本中提取关键词表示文本的过程,中文文本处理中 主要包括文本分词和去停用词两个阶段。之所以进行分词,是因为很多研究表 明特征粒度为词粒度远好于字粒度,这是因为大部分分类算法不考虑词序信息, 基于字粒度显然损失了过多“n-gram”信息。
具体到中文分词,不同于英文有天然的空格间隔,需要设计复杂的分词算 法。传统算法主要有基于字符串匹配的正向/逆向/双向最大匹配;基于理解的句 法和语义分析消歧;基于统计的互信息/CRF方法。近年来随着深度学习的应用, WordEmbedding+Bi-LSTM+CRF方法逐渐成为主流。而停止词是文本中一些高 频的代词连词介词等对文本分类无意义的词,通常维护一个停用词表,特征提 取过程中删除停用表中出现的词,本质上属于特征选择的一部分。
一段描述文字经过文本分词和去停止词之后变成了以下“/”分割的一个 个关键词的形式,比如:
一班组/铲运机/编号/001
2、文本表示和特征提取
文本表示的目的是把文本预处理后的转换成计算机可理解的方式,是决定 文本分类质量最重要的部分。常用词袋模型(BOW,Bag OfWords)或向量空 间模型(VectorSpace Model)。词袋模型的示例如下:
(0,0,0,0,....,1,...0,0,0,0)
一般来说词库量至少都是百万级别,因此词袋模型有个两个最大的问题: 高纬度、高稀疏性。词袋模型是向量空间模型的基础,因此向量空间模型通过 特征项选择降低维度,通过特征权重计算增加稠密性。
向量空间模型的文本表示方法的特征提取对应特征项的选择和特征权重计 算两部分。特征选择的基本思路是根据某个评价指标独立的对原始特征项(词 项)进行评分排序,从中选择得分最高的一些特征项,过滤掉其余的特征项。
特征权重主要是经典的TF-IDF方法及其扩展方法,主要思路是一个词的重 要度与在类别内的词频成正比,与所有类别出现的次数成反比。
3、基于语义的文本表示
在文本表示方面除了向量空间模型,还有基于语义的文本表示方法,比如 LDA主题模型、LSI/PLSI概率潜在语义索引等方法,这些方法得到的文本表示 可以认为文档的深层表示,而词向量(word embedding)文本分布式表示方法则 是深度学习方法的重要基础。
深度学习的图像和语音原始数据是连续和稠密的,有局部相关性。应用深 度学习解决大规模文本分类问题最重要的是解决文本表示,再利用CNN/RNN 等网络结构自动获取特征表达能力,去掉繁杂的人工特征工程,端到端的解决 问题。
文本的分布式表示:词向量(word embedding)。分布式表示(DistributedRepresentation),基本思想是将每个词表达成n维稠密、连续的实数向量,与 之相对的one-hot encoding向量空间只有一个维度是1,其余都是0。分布式表 示最大的优点是具备非常强的特征表达能力,比如n维向量每维k个值,可 以表征kn个概念。事实上,无论是神经网络的隐层,还是多个潜在变量的概 率主题模型,都是应用分布式表示。
例如,神经网络语言模型(NNLM,Neural Probabilistic Language Model) 采用的是文本分布式表示,即每个词表示为稠密的实数向量。NNLM模型的目 标是构建语言模型,词的分布式表示即词向量(word embedding)是训练语言模 型的一个附加产物。
文本的表示通过词向量的表示方式,把文本数据从高纬度高稀疏的神经网 络难处理的方式,变成了类似图像、语音的的连续稠密数据。深度学习算法本 身有很强的数据迁移性,很多之前在图像领域很适用的深度学习算法比如CNN 等也可以很好的迁移到文本领域。
词向量解决了文本表示的问题,文本分类模型利用CNN/RNN等深度学习 网络及其变体解决自动特征提取(即特征表达)的问题。自然语言处理中常用 的是递归神经网络(RNN,RecurrentNeuralNetwork),能够更好的表达上下文信 息。具体在文本分类任务中,通常使用双向LSTM网络,具体实现过程如下:
1、数据处理
数据处理部分和CharCNN是一样的,这里将输入处理成固定长度的序列。
2、模型搭建
以下代码按照LSTM(GRU)—dropout—LSTM(GRU)—dropout—全连 接层—输出层这样的结构来进行组织。要注意的是,对每层的LSTM或GRU核 中的神经元进行dropout,还有取最后时刻和最后一层的LSTM或GRU的隐状 态作为全连接层的输入。
3、模型训练、验证和测试
这一部分的代码和CharCNN类似,在验证和测试时不无需dropout,并且用 早停防止过拟合。
4、模型预测
以上给出了本发明实施例中算法的一种具体实现形式,不构成对本发明的 限制。可以理解的是,本发明方法还可以采用其他的类似人工智能算法来实现, 只要能够实现相应功能即可,此处不再赘述,
进一步地,所述数据映射关系建立方法还包括:
建立矿山设备主数据与待映射业务系统数据之间的映射关系之后,利用互 通信息进行设备单耗分析、设备监测与故障诊断、设备供应商追踪考核等。
图3是本发明实施例中数据流转过程的示意图。矿山设备主数据和各个业 务系统数据建立好映射关系后,就可以打通以设备为主线(维度)的采购信息、 物资备件领用信息、生产信息、安全信息、自动化控制信息,利用这些互通的 信息,可以进行设备单耗分析、设备监测与故障诊断、设备供应商追踪考核等 数据的深度应用,给矿山业务带来更大价值。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的 精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的 保护范围之内。
- 一种数据映射关系建立方法
- 一种映射关系建立方法、装置、用户面功能及介质