眼底医学影像中视杯视盘的联合分割方法
文献发布时间:2023-06-19 10:27:30
技术领域
本发明涉及医学影像处理技术领域,具体涉及一种眼底医学影像中视杯视盘的联合分割方法。
背景技术
医学影像,是指为了医疗或医学研究目的,对人体或人体某部分以非侵入方式取得内部组织器官影像的技术与处理过程,根据其实现步骤不同,医学影像包括医学成像技术和医学处理技术,借助医学影像技术,医疗人员可以更清晰地了解人体特定的组织器官状况进而给出更为精准和合理的诊疗方案。而医学图像分割是现代医学影像处理中的关键技术,它是正常组织和病变组织的三维重建、定量分析等后续操作的基础。
在眼底医学彩照图像中,视杯和视盘的分割是后续垂直杯盘比等定量分析的基础,但眼底彩照图像中视杯和视盘存在对比度低、边界模糊和血管遮挡严重等问题,因此视盘和视杯的分割仍然存在着很大的挑战性。
针对眼底彩照图像的视杯、视盘分割技术,主要分为基于传统图像处理方法的分割方法和基于深度学习的分割方法。
传统图像分割方法,需要人工设计特征,利用视杯、视盘的亮度或者定位血管在杯沿处弯折点来确定视杯、视盘的轮廓,例如基于阈值的眼底彩照图像视杯分割方法,利用视杯的亮度特征,在获取感兴趣的区域后采用大津阈值法提取视盘,在获取视盘的基础上根据阈值采用水平集模型对彩照图像的蓝色通道图像进行分割,再经过椭圆拟合得到视杯。上述传统图像分割方法存在分割精度低、计算复杂度高和鲁棒性低等缺点。
深度学习图像分割方法是在多个公共数据集的多种场景图像中精确地分割出多种分割目标,相较于传统图像分割方法,其具有高准确度和高泛化性的优点,鉴于深度学习图像分割方法的上述优点,U-Net作为一种典型的深度学习图像分割网络,被广泛应用在医学图像分割领域。U-Net采用了编码器和解码器结构,并结合跳跃连接,在医学图像分割精度上有了很大提高,但是该分割网络对于图像的上下文信息的提取仍旧不够充分,这会导致网络对于图像的多尺度信息提取不够,容易丢失细节特征信息;另外其跳跃连接只是将编码器端的特征信息传递到解码器端,忽略了对全局信息的利用,从而导致网络对具有边界模糊和对比度低等特点的目标进行分割时,容易出现误分割。
因此,现有的医学图像分割方法,存在着对眼底彩照图像全局上下文信息和多尺度上下文信息提取不充分等缺点,影响了分割效果,无法满足眼底医学影像中视杯视盘的分割需求。
发明内容
本发明要解决的技术问题是提供一种眼底医学影像中视杯视盘的联合分割方法,能够对眼底医学影像中全局上下文信息和多尺度上下文信息进行充分提取,利于提升了眼底医学影像中视杯视盘的联合分割效果。
为了解决上述技术问题,本发明提供的技术方案如下:
一种眼底医学影像中视杯视盘的联合分割方法,包括以下步骤:
S1)构建基于U-Net网络的联合分割网络;
所述U-Net网络包括编码网络和解码网络,所述编码网络包括多个编码器,所述解码网络包括多个解码器,所述编码器和所述解码器一一对应,每个所述编码器和对应的解码器形成一层编解码层,至少一层编解码层的所述编码器和解码器之间设置有全局信息提取模块,所述全局信息提取模块用于将所在编解码层的编码器的输出特征图和其他至少一层编解码层的编码器的输出特征图进行融合得到初步融合特征图,并对所述初步融合特征图进行全局上下文信息提取处理后输出至相应的解码器;
构建所述联合分割网络时,在所述编码网络和解码网络之间设置多路径空洞卷积模块,所述多路径空洞卷积模块采用多个不同扩张率的并行空洞卷积来从编码网络输出的特征图中获取不同尺度的上下文信息,并将获取的不同尺度的上下文信息和编码网络输出的特征图进行融合后输出至解码网络。
S2)将待处理的眼底医学影像输入至所述联合分割网络中进行视杯视盘的联合分割。
在其中一个实施方式中,所述步骤S1)中,所述全局信息提取模块对所述初步融合特征图进行全局上下文信息提取处理的方法为:所述全局信息提取模块对所述初步融合特征图进行深度可分离卷积和全局上下文信息提取的并行处理,然后将进行深度可分离卷积处理后的初步融合特征图和进行全局上下文信息提取处理后的初步融合特征图进行最终融合。
在其中一个实施方式中,所述全局信息提取模块对所述初步融合特征图进行深度可分离卷积的方法为:所述全局信息提取模块采用多个并行的且具有不同扩张率的分离卷积对所述初步融合特征图进行卷积处理。
在其中一个实施方式中,所述解码器用于对输入该解码器的特征图进行上采样解码,所述上采样解码采用双线性插值上采样解码。
在其中一个实施方式中,所述编码网络采用残差网络。
在其中一个实施方式中,所述残差网络采用ResNet34网络。
在其中一个实施方式中,至少一个所述编码器的输出端设置有通道注意力模块,至少一个所述解码器的输出端设置有通道注意力模块,所述通道注意力模块用于对分割任务响应大的特征通道增大权重,而对分割任务响应小的特征通道减小权重。
在其中一个实施方式中,相邻两个编码器之间均设置有所述通道注意力模块,相邻两个解码器之间均设置有所述通道注意力模块。
本发明具有以下有益效果:本发明的眼底医学影像中视杯视盘的联合分割方法,改进了现有的U-Net分割网络,能够对眼底医学影像中全局上下文信息和多尺度上下文信息进行充分提取,大大提升了眼底医学影像中视杯视盘的联合分割效率和质量。
附图说明
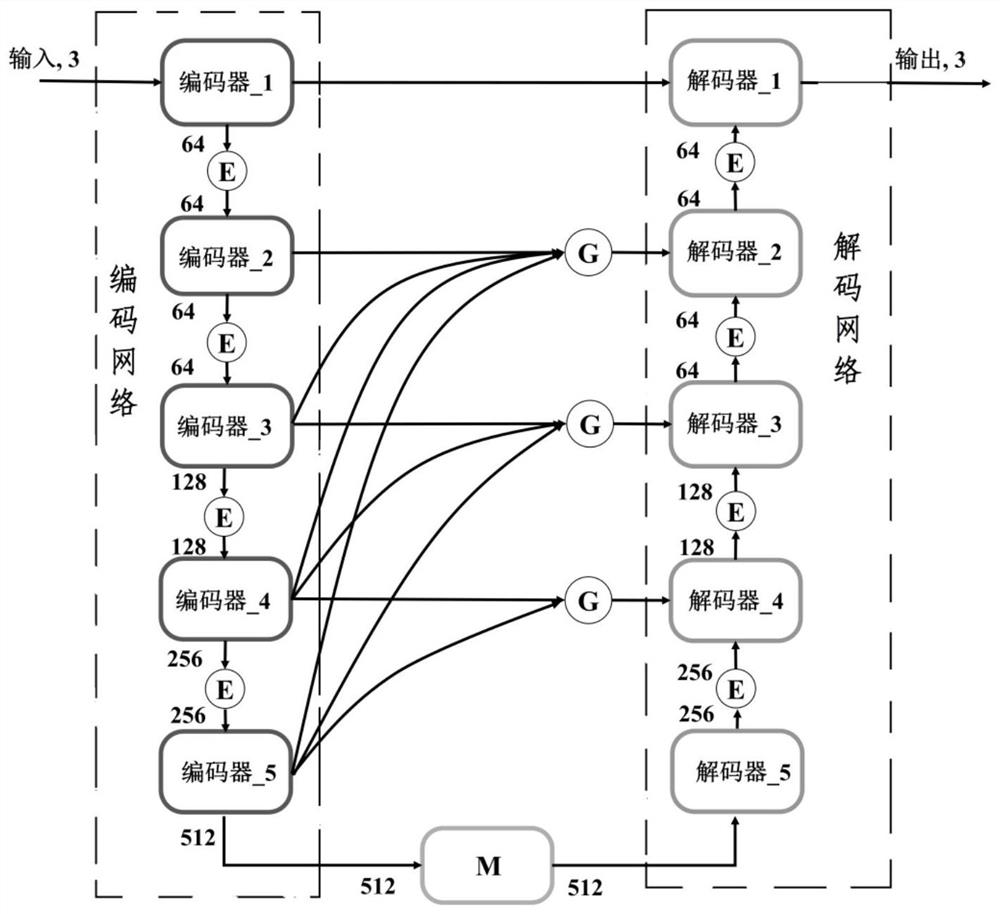
图1是本发明的眼底医学影像中视杯视盘的联合分割方法的结构示意图;
图2是图1中编码器的结构示意图;
图3是图1中解码器的结构示意图;
图4是图1中全局信息提取模块(GCE模块)的结构示意图;
图5是图1中多路径空洞卷积模块(MAC模块)的结构示意图;
图6是不同分割网络的视杯视盘的联合分割结果图;
具体实施方式
下面结合附图和具体实施例对本发明作进一步说明,以使本领域的技术人员可以更好地理解本发明并能予以实施,但所举实施例不作为对本发明的限定。
参阅图1-图3,图1中
S1)构建基于U-Net网络的联合分割网络;
U-Net网络包括编码网络和解码网络,编码网络包括多个编码器,解码网络包括多个解码器,编码器和解码器一一对应,每个编码器和对应的解码器形成一层编解码层,至少一层编解码层的编码器和解码器之间设置有全局信息提取模块-GCE模块,全局信息提取模块(GCE模块)用于将所在编解码层的编码器的输出特征图和其他至少一层编解码层的编码器的输出特征图进行融合得到初步融合特征图,并对初步融合特征图进行全局上下文信息提取处理后输出至上述全局信息提取模块(GCE模块)所在编解码层的解码器,例如,参阅图1,编码器4和解码器4所形成的第四层编解码层来说,该层的全局信息提取模块(GCE模块)用于将编码器4的输出特征图和第五层编码层中的编码器5的输出特征图进行融合并进行全局上下文信息提取处理后输出至解码器4;对于编码器2和解码器2所形成的第二层编解码层来说,该层的全局信息提取模块(GCE模块)用于将编码器2的输出特征图和第三、四、五层编码层中的编码器3、编码器4、编码器5的输出特征图进行综合融合并进行全局上下文信息提取处理后输出至解码器2;
构建联合分割网络时,在编码网络和解码网络之间设置多路径空洞卷积模块-MAC模块,多路径空洞卷积模块(MAC模块)采用多个不同扩张率的并行空洞卷积来从编码网络输出的特征图中获取不同尺度的上下文信息,并将获取的不同尺度的上下文信息和编码网络输出的特征图进行融合后输出至解码网络。例如,参阅图5,在MAC模块中有5个级联分支,每个级联分支的空洞卷积的膨胀率从1到1、2、4、8逐渐递增,其感受野分别为3x3、5x5、9x9、17x17、33x33,利用这五个并行空洞卷积来获取编码网络输出的特征图的不同尺度的上下文信息,最后,将不同尺度的上下文信息与编码网络输出的特征图进行相加融合,从而得到包含多尺度上下文信息的特征图,并输出至解码网络。
S2)将待处理的眼底医学影像输入至所述联合分割网络中进行视杯视盘的联合分割。
上述结构中,通过全局信息提取模块-GCE模块的设置,使得编码器高层特征图与低层特征图融合,通过跳跃连接输入到低层对应的解码器层,有效提高了网络的全局上下文信息提取能力和减少了无关噪声的产生。相较于普通卷积模块来说,多路径空洞卷积模块-MAC模块,通过组合不同的扩张率,可以提取不同感受野的特征,从而更好地融合多尺度的上下文信息,不会因为池化而损失信息,使得每个卷积的输出都能够包含更加广泛的特征信息,更利于提升图像中视杯、视盘的分割精度。
在其中一个实施方式中,如图4所示,步骤S1)中,全局信息提取模块对初步融合特征图进行全局上下文信息提取处理的方法为:全局信息提取模块对初步融合特征图进行深度可分离卷积和全局上下文信息提取的并行处理,然后将进行深度可分离卷积处理后的初步融合特征图和进行全局上下文信息提取处理后的初步融合特征图进行最终融合,最后将最终融合后的特征图输出至相应的编码器。也即,全局信息提取模块对初步融合特征图进行两路处理,一路对其进行深度可分离卷积,另一路进行全局上下文信息提取,然后再将两路结果进行融合,以有效提高全局上下文信息提取能力,实现全局上下文信息的充分提取。参阅图4,图4以第四层编解码呈为例,介绍了全局信息提取模块-GCE模块的结构。在GCE模块中,首先对输入层采用3×3卷积,提取输入层的特征图,然后将第五层得到的特征图上采样至与第四层相同尺寸大小,再对两层的特征图进行融合。
进一步地,全局信息提取模块对所述初步融合特征图进行深度可分离卷积的方法为:全局信息提取模块采用多个并行的且具有不同扩张率的分离卷积对初步融合特征图进行卷积处理。可以理解地,并行路径的数量和扩张率随着输入层数的变化而变化。例如,参阅图4,深度可分离卷积采用扩张率分别为1、2的两个并行的分离卷积对初步融合特征图进行卷积处理并融合。上述并行方法可以获得不同感受野的特征,融合后可获得更多语义信息,减少信息丢失。
在其中一个实施方式中,每一层编解码层的全局信息提取模块-GCE模块的用以下公式如下:
其中,GCE
在其中一个实施方式中,如图3所示,解码器用于对输入该解码器的特征图进行上采样解码,上采样解码采用双线性插值上采样解码。例如,解码器包括3×3卷积和双线性插值上采样两部分,解码器层以MAC模块的多尺度上下文信息特征图作为高层特征,再通过3×3卷积逐层融合跳跃连接中GCE模块输出的全局上下文信息,然后,再通过双线性插值对融合的特征图进行上采样。最后一个解码器将特征图上采样至原图大小并输出。
在其中一个实施方式中,编码网络采用残差网络(ResNet,Residual Network),以有效地获取输入图像的特征图,避免梯度消失,提高网络的收敛速率。
进一步地,残差网络采用ResNet34网络。如图2所示,ResNet34网络中编码器包括残差模块和下采样模块,其中,残差模块包括2个3×3卷积与残差连接,并可以去掉最后的平均池化层和全连接层,以更好地保证收敛速率和计算效率。例如,通过ResNet34作为特征提取器,获取特征编码层的特征图,分别为第一层(64x 512x 512)、第二层(64x 256x256)、第三层(128x 256x 256)、第四层(256x 128x 128)、第五层(512x 64x 64)。
在其中一个实施方式中,至少一个编码器的输出端设置有通道注意力模块,至少一个解码器的输出端设置有通道注意力模块,通道注意力模块用于对分割任务响应大的特征通道增大权重,而对分割任务响应小的特征通道减小权重,以进一步提高网络在通道上的特征提取能力,提取更多的细节特征。由于眼底彩色图像中视杯的边界较为模糊,通过通道注意力模块的添加能够提取更多的细节特征,从而提高网络对视杯的分割性能。上述通道注意力模块采用高效通道注意力模块。
进一步地,如图1所示,相邻两个编码器之间均设置有通道注意力模块,相邻两个解码器之间均设置有所述通道注意力模块,以更好地提高网络对视杯的分割性能。
在其中一个实施方式中,联合分割网络的损失函数为Dice系数损失函数和交叉熵损失函数相加之和,以克服克服数据分布不平衡带来的误差。
为了验证本实施例的分割方法的有效性和实用性,本发明采用1200张眼底彩色图像用来对设计的网络进行训练和测试,通过对比多个网络和消融实验的分割效果对本方法进行了验证:
采用包含来自两个不同设备拍摄的1200张眼底彩色图像作为数据集,为了提高网络模型的计算效率和分割精度,我们将图像进行了感兴趣区域提取,具体来讲,通过预训练的网络模型对视盘进行粗分割,然后对视盘中心定位,以视盘中心作为中心点裁剪出512×512大小的感兴趣区域。在网络训练中,采用随机左右翻转、增加亮度对比度等方法进行在线数据扩增;
在对比试验和消融实验中,将数据集随机划分为训练集(720张)、验证集(240张)和测试集(240张),采用Jaccard(Jaccard Index)指标、Dice系数指标这两个评价指标。
将本实施例的联合分割网络记为MU-Net,将采用ResNet34的基础U型网络作为MU-Net的主干网络,记为Backbone,将通道注意力模块-CA模块加入Backbone,记为“Backbone+CA”,仅将本实施例的全局信息提取模块-GCE模块加入Backbone,记为“Backbone+GCE”,仅将本实施例的多路径空洞卷积模块-MAC模块加入Backbone,记为“Backbone+MAC”。
将本实施例的主干网络Backbone、MU-Net网络与现有的U-Net、Seg-Net(A DeepConvolutional Encoder-Decoder Architecture for Image Segmentation,基于深度卷积编码-解码器结构的图像分割网络)、Attention U-Net、FCN((Fully ConvolutionalNetworks,全卷积网络)进行性能的比较;以及为验证本实施例的GCE模块、MAC模块,以及在编码器-解码器层添加高效通道注意力模块的有效性,将本实施例的网络模型与“Backbone+CA”、“Backbone+GCE”和“Backbone+MAC”也进行了比较,比较结果参阅表1,表1为本实施例的联合分割网络MU-Net与其他分割网络的对比结果表:
表1本实施例的联合分割网络与其他分割网络的对比结果表
由表1可知,在对比实验中,本实施例提出的MU-Net取得了比上述四种分割网络更好的性能指标。与FCN方法相比,本实施例提出的MU-Net网络在视盘、视杯分割的Dice系数和Jaccard指标分别取得了0.93%、1.66%、2.41%和3.69%的提升。与Backbone方法相比,本实施例提出的MU-Net网络在视盘、视杯分割的Dice系数和Jaccard指标分别取得了0.87%、1.55%、1.68%和2.68%的提升。另外,图6展示了采用不同分割网络得到的视杯、视盘分割结果,图中,白色代表视杯区域,灰色代表视盘区域。由图6可知,本实施例提出的MU-Net网络具有更好的视盘视杯联合分割效果。
有关GCE模块的消融实验,由表1可知,在主干网络Backbone的基础上加上GCE模块(Backbone+GCE)后,网络对视杯、视盘的分割性能得到明显提升,特别是Jaccard指标,与Backbone方法相比,在视杯、视盘分割上分别提升了0.96%和1.51%,这得益于GCE模块有效的提高了网络在跳跃连接阶段的全局上下文信息提取能力,并减少无关噪声的产生,也证明了本实施例提出的GCE模块能够有效的提升网络的分割性能。
有关MAC模块的消融实验。由表1所示,在主干网络Backbone的基础上加上MAC模块(Backbone+MAC)后,网络对视杯、视盘的分割性能也得到明显提升,在Jaccard指标上,与Backbone方法相比分别提升了1.05%和1.55%,说明获取多尺度上下文信息的必要性,也证明了本实施例提出的MAC模块能够有效的改进网络的分割性能。
有关在编码器-解码器层添加通道注意力模块的消融实验。由表1所示,在主干网络Backbone的基础上加入通道注意力模块(Backbone+CA)后,在视杯的分割性能上有了较为明显的提升,与Backbone方法相比,Dice系数和Jaccard指标分别提升了1.16%,1.91%,这得益于通道注意力模块提取和保留了更多的细节特征,更有助于区分视杯和视盘边界。上述消融实验证明了本实施例提出的加入通道注意力模块的方式有效地增强了分割网络对分割目标的响应,提高了分割网络模型的分割性能。
综上所述,本实施例的眼底医学影像中视杯视盘的联合分割方法,改进了现有的U-Net分割网络,通过引入全局信息提取模块(GCE模块)和多路径空洞卷积模块(MAC模块),克服了现有分割网络对眼底彩照图像中全局上下文信息和多尺度上下文信息提取不充分等缺点,大大提升了眼底医学影像中视杯视盘的联合分割效率和质量。
以上所述实施例仅是为充分说明本发明而所举的较佳的实施例,本发明的保护范围不限于此。本技术领域的技术人员在本发明基础上所作的等同替代或变换,均在本发明的保护范围之内。本发明的保护范围以权利要求书为准。
- 眼底医学影像中视杯视盘的联合分割方法
- 一种对于眼底图中视盘和视杯的语义分割方法