一种线粒体变异位点数据库及其建立方法和应用
文献发布时间:2023-06-19 11:14:36
技术领域
本发明涉及生物信息技术领域,特别是涉及一种线粒体变异位点数据库及其建立方法和应用。
背景技术
线粒体是真核细胞内关键的细胞器,线粒体通过氧化磷酸化或其它功能在细胞ATP产生中发挥重要作用。线粒体中包含独立的基因组,即线粒体DNA(mtDNA)。mtDNA的突变可以导致许多人类疾病,例如:A3273G突变(即线粒体基因组第3273号碱基由A变成了G)可导致MELAS等多种疾病。大约每5000人中有1人检出线粒体疾病。
mtDNA在单一细胞中的拷贝数量有几百份。同质性指的是细胞或个体中mtDNA的拷贝都是相同的;而异质性则指的是细胞或个体中包含有其他类型的mtDNA,例如包含突变的mtDNA。异质性比例(heteroplasmic fraction)是指mtDNA的突变比例,其数值可以在0-100%之间变化。大多数mtDNA突变仅在异质性比例超过特定阈值时才引起疾病症状,在此阈值以下,个体无症状,主要是因为有足够的功能正常的线粒体来维持正常代谢。异质性比例是mtDNA突变的重要特征,具有极大的研究意义。
因此,开发制作人群中的线粒体变异位点数据库具有很大的价值,可以使研究者了解所测得的变异是否为新发突变,并且看到已有的突变在人群中的分布情况及相应的异质性比例。然而,相比于常染色体变异位点种类繁多的数据库和庞大的收集量,线粒体的变异位点收录的量很少,现有比较知名的数据库只有MITOMAP,MITOMAP数据库里面的线粒体变异位点情况全部是收集不同研究机构发表的学术论文而来的(如图1所示)。数据库中线粒体的来源人群、测序方法、测序深度、数据质控、参考基因组、变异位点的分析方法,都不统一,无法保证信息的可靠性和一致性,限制了该数据库的应用价值。
发明内容
基于此,有必要针对上述问题,提供一种线粒体变异位点数据库的建立方法,使用统一的数据质控和变异位点检测流程,获得的数据质量统一、可靠,建立得到的数据库包括每个变异位点的异质性分数,对研究mtDNA突变和疾病的联系具有重要意义。
一种线粒体变异位点数据库的建立方法,包括以下步骤:
1)获取线粒体DNA序列数据;
2)将上述线粒体DNA序列与线粒体参考基因组进行比对,得到比对结果,根据预设条件抓取线粒体变异位点信息;
3)对每个线粒体变异位点信息进行同异质性分析,将异质性比例为0.01-0.98的变异位点定义为异质性变异,否则定义为同质性变异;
4)整合变异位点信息,汇总得到线粒体变异位点数据库。
上述数据库建立方法,使用统一的数据质控和变异位点检测流程,获得的数据质量统一、可靠,建立得到的数据库包括每个变异位点的异质性分数,对研究mtDNA突变和疾病的联系具有重要意义。
在其中一个实施例中,所述步骤1)中,采用DNA聚合酶和引物序列对线粒体DNA进行PCR扩增,得到线粒体DNA序列数据;
所述引物序列为:
F-16426:CCGCACAAGAGTGCTACTCTCCTC(SEQ ID No.1),
R-16425:GATATTGATTTCACGGAGGATGGTG(SEQ ID No.2)。
在其中一个实施例中,所述步骤1)中,抽取个体的外周血,使用Qiagen试剂盒提取线粒体DNA。
所述个体包括所有的国籍或人种的个体,当需要研究某个特定群体的线粒体DNA时,可仅纳入该群体的个体。例如,MITOMAP数据库主要是收录外国人群的线粒体变异情况,而线粒体是母系遗传,外国人群与中国人群在线粒体群体差异很大,MITOMAP收集的信息对中国人群的参考价值较低,那么就可以采用本发明的方法选取来自中国的个体,构建对应的数据库。
对测试个体进行编号,便于后续查询和溯源。
在其中一个实施例中,所述步骤1)中,采用DNA聚合酶和引物序列对线粒体DNA进行长片段PCR扩增,得到线粒体DNA序列数据。
优选地,所述DNA聚合酶为诺唯赞Vazyme公司的DNA聚合酶
优选地,所述引物序列为:
F-16426:CCGCACAAGAGTGCTACTCTCCTC(SEQ ID No.1),
R-16425:GATATTGATTTCACGGAGGATGGTG(SEQ ID No.2)。
该引物序列为人组织器官均可用的引物,为本领域公认的通用引物。
在其中一个实施例中,所述步骤1)中,得到PCR产物后,使用Bioo Scientific公司的NEXTflex试剂盒构建测序文库,使用Illumina Novaseq测序平台进行测序。
使用二代测序仪,测序快速、通量大、深度高,可以检测到低频的变异。
在其中一个实施例中,所述步骤2)中,先过滤掉平均测序深度低于200×的线粒体DNA,所得序列再与线粒体参考基因组进行比对,得到bam文件。
在其中一个实施例中,所述步骤2)中,所述线粒体参考基因组为NC_012920.1。
在其中一个实施例中,所述步骤2)中,所述预设条件包括:如突变类型为插入或缺失突变,当插入或缺失的序列为≤5bp的重复单元,且重复次数≥5次,则舍弃该插入或缺失突变。
在其中一个实施例中,所述步骤2)中,所述预设条件包括:变异的质量分数需≥20;变异的碱基质量分数需≥20;变异的最小频率需≥0.01。
变异的质量分数表明该处变异在统计学上的确定性,计算公式如下:
Q=-10×log
其中,Q为变异的质量分数,P为假阳性的概率。Q分值越高表示该处变异的假阳性率越低,即可信度越高。Q≥20,即P≤0.01,假阳性率低于0.01。
变异的碱基质量分数指该处变异的替换碱基在测序机器上的测序质量,分数越高表示该处的替换碱基的测序正确性越高。
变异的最小频率指的是低于该频率的变异会被过滤掉,频率即该位点测得的变异数量占总数量的比例。
在其中一个实施例中,所述预设条件还包括过滤条件:当某个体样本内检测到>50个变异位点,则舍弃该样本数据。
线粒体是非常重要的细胞器,若个体检测出>50处变异,有极大可能是本身DNA提取或者检测过程中受到污染,应当舍弃。
在其中一个实施例中,所述步骤3)中,编写Perl脚本,将异质性比例为0.01-0.98的变异位点定义为异质性变异,标注Het;否则定义为同质性变异,标注为Hom。
异质性比例,即该位点变异的拷贝数占总体mtDNA拷贝数的比例。若大于0.98,表明该变异在所测的样品中所占比例超过了98%,则几乎所有的线粒体该处都发生了变异(需要考虑到任何方法都有一定误差),则认为该变异为同质性。
在其中一个实施例中,所述步骤4)中,变异位点信息包括:
1)变异位点在线粒体基因组上的碱基位置;
2)变异位点在线粒体基因组上的处于哪个基因的区域内;
3)原本参考基因组该位置的碱基;
4)变异情况的替换碱基;
5)突变是异质性还是同质性;
6)突变的异质性分数;
7)突变所在的个体ID。
在其中一个实施例中,所述步骤4)中,使用Linux命令整合所有个体的变异位点信息,命令为“cat*.vcf>all.vcf”;基于Linux系统的服务器,安装MySQL,新建数据库及设计表;将all.vcf导入到MySQL中,得到线粒体变异位点数据库。
在其中一个实施例中,所述步骤4)后还包括步骤5):
基于shiny平台编写服务器代码,创建UI界面,设置查询条件和过滤条件,然后连接MySQL数据库,使用shiny-server进行部署。用户可以在浏览器中访问服务器从而使用该数据库。输入要查询的起始位点及结束位点,点击search,结果以列表形式返回,并且结果列表上有筛选框,支持在结果中进行二次筛选。
使用shiny平台以及MySQL搭建数据库,数据库操作简单,响应迅速,并且可以直接在初步筛选出来的结果上进行二次筛选。
本发明一方面还提供一种采用上述方法建立得到的线粒体变异位点数据库。
现有的MITOMAP数据库,在其中搜出某一位点的某种变异情况后,不能显示该位点在人群中的异质性分数,而异质性分数对研究线粒体变异具有重要意义,缺乏这一重要信息,使得MITOMAP数据库本身的价值难以被利用。而且,MITOMAP数据库使用时速度较慢,信息冗余,需要精简,搜索出来的结果不支持二次筛选功能。图2为使用MITOMAP数据库查询第37号碱基位置突变情况的查询示例。
而本发明的数据库可以有效解决上述问题,重要信息(异质性分数等参数)突出,查询结果可靠,查询操作简单,响应迅速,支持在搜索结果中进行二次筛选。
本发明还提供一种上述线粒体变异位点数据库在制备线粒体变异位点检测设备中的应用。
本发明还提供一种线粒体变异位点查询装置,包括:
输入模块,用于输入获取的线粒体DNA序列数据;
比对模块,用于将线粒体DNA序列与线粒体参考基因组进行比对,得到比对结果,并采用预设条件抓取线粒体变异位点信息;
分析模块,用于对每个线粒体变异位点信息进行同异质性分析,将异质性比例为0.01-0.98的变异位点定义为异质性变异,否则定义为同质性变异;
整合模块,用于整合和汇总变异位点信息;
输出模块,用于输出查询结果。
与现有技术相比,本发明具有以下有益效果:
本发明的数据库建立方法,使用统一的数据质控和变异位点检测流程,获得的数据质量统一、可靠,建立得到的数据库包括每个变异位点的异质性分数,对研究mtDNA突变和疾病的联系具有重要意义。
本发明的数据库,重要信息(异质性分数等参数)突出,查询结果可靠,查询操作简单,响应迅速,支持在搜索结果中进行二次筛选。通过实验可发现,采用本发明的数据库可查询到一些变异位点,对应的个体有临床症状,而在现有的MITOMAP数据库中无报道案例,可见本发明的数据库在研究mtDNA突变和疾病的联系方面具有重要应用价值。
附图说明
图1为MITOMAP数据库收录的位点来源论文网页截图;
图2为MITOMAP数据库变异位点搜索结果示例;
图3为实施例中线粒体数据库的MySQL设计表示意图;
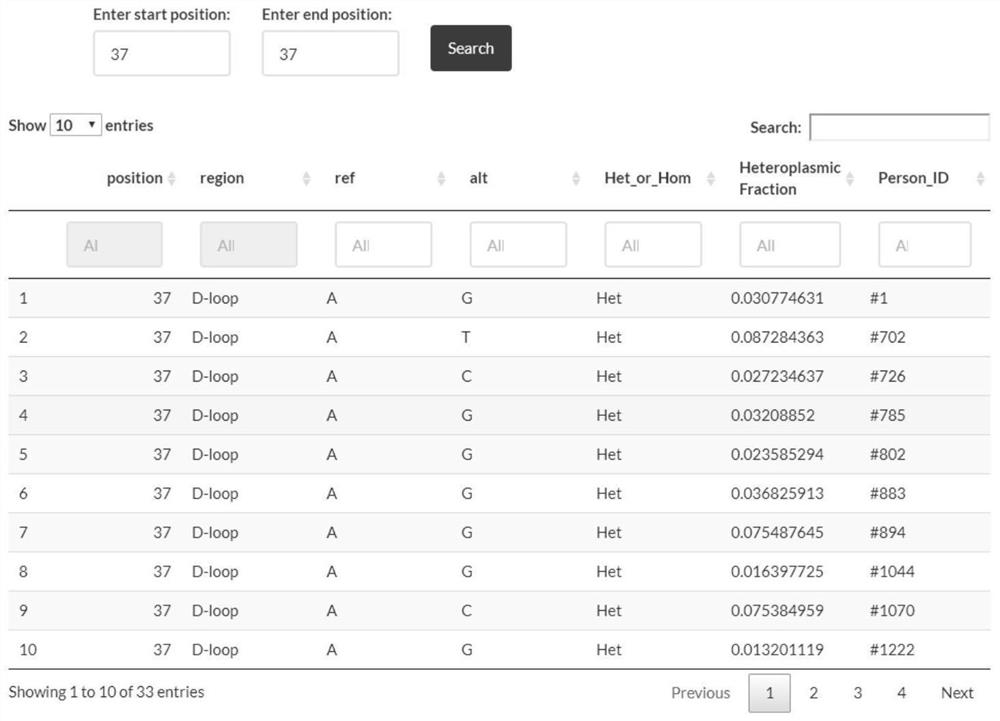
图4为实施例中数据库的测试查询结果页面截图;
图5为线粒体第3502号碱基在MITOMAP数据库中的查询结果;
图6为线粒体第3502号碱基在实施例1所建立的数据库中的查询结果;
图7为线粒体第14465号碱基在MITOMAP数据库中的查询结果;
图8为线粒体第14465号碱基在实施例1所建立的数据库中的查询结果。
具体实施方式
为了便于理解本发明,以下将给出较佳实施例对本发明进行更全面的描述。但是,本发明可以以许多不同的形式来实现,并不限于本文所描述的实施例。相反地,提供这些实施例的目的是使对本发明的公开内容的理解更加透彻全面。
除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。本文中在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本发明。
实施例1
线粒体变异位点数据库的建立,包括以下步骤:
一、获取线粒体DNA序列数据。在本实施例中,按以下步骤进行。
1、抽取个体外周血,使用Qiagen试剂盒并根据其说明提取线粒体DNA。
2、使用诺唯赞Vazyme公司的DNA聚合酶
F-16426:CCGCACAAGAGTGCTACTCTCCTC(SEQ ID No.1),
R-16425:GATATTGATTTCACGGAGGATGGTG(SEQ ID No.2)。
二、将上述线粒体DNA序列与线粒体参考基因组进行比对,得到比对结果,根据预设条件抓取线粒体变异位点信息。具体地,在本实施例中采用以下方法实现。
1、过滤掉平均测序深度低于200×的线粒体DNA,使用BWA软件将序列比对到线粒体考基因组NC_012920.1上,得到bam文件。
2、使用Pisces软件(v5.1.6.54)处理bam文件,输入参数为“-RMxNFilter 5,5-MinVQ 20-MinBQ 20-MinVF 0.01”,获得线粒体变异位点信息。
命令中各参数的意义如下:
-RMxNFilter 5,5如突变类型为插入或缺失突变,当插入或缺失的序列为≤5bp的单一重复单元,重复次数≥5次,该插入或缺失舍弃;
-MinVQ20变异的质量分数(variant quality score)需≥20;
-MinBQ 20变异的碱基质量分数(basecall quality)需≥20;
-MinVF 0.01变异的最小频率(variant frequency)需要≥0.01。
三、对每个线粒体变异位点信息进行同异质性分析,将异质性比例为0.01-0.98的变异位点定义为异质性变异,否则定义为同质性变异。
具体地,编写Perl脚本,异质性比例处于0.01-0.98的变异位点定义为异质性变异,标注Het;否则定义为同质性变异,标注为Hom。如果某个体样本内检测到>50个的变异位点,则舍弃。
四、整合变异位点信息,汇总得到线粒体变异位点数据库。
具体地,使用Linux命令整合所有个体的变异位点结果,命令为“cat*.vcf>all.vcf”。基于Linux系统的服务器,安装MySQL,新建数据库及设计表,其中设计表如图3,该表一共有7列,其意义如下:
position:整数类型,该列指明变异位点在线粒体基因组上的碱基位置;
region:文本类型,该列指明变异位点在线粒体基因组上的处于哪个基因的区域内;
ref:文本类型,该列指明原本参考基因组该位置的碱基;
alt:文本类型,该列指明该变异情况的替换碱基;
Het_or_Hom:文本类型,该列表明该突变是异质性还是同质性;
Heteroplasmic Fraction:文本类型,该列指明突变的异质性分数;
Person_ID:文本类型,该列指明突变所在的个体ID。
再将all.vcf导入到MySQL中。
五、数据库查询。
具体地,基于shiny平台编写服务器代码,创建UI界面,设置查询条件和过滤条件,然后连接MySQL数据库,使用shiny-server进行部署。用户可以在浏览器中访问服务器从而使用该数据库。如图4,输入要查询的起始位点及结束位点,如要查询碱基37位置的突变情况,则在起始位置和结束位置都输入数字37,然后点击search,结果以列表形式返回,并且结果列表上有筛选框,支持在结果中进行二次筛选。
实施例2
分别在实施例1的线粒体变异位点数据库和MITOMAP数据库进行查询,查询线粒体的第3502号碱基变异位点。
线粒体的第3502号碱基T处于MT-ND1基因,该基因编码NADH-泛醌氧化还原酶链1蛋白。MT-ND1基因的变异与线粒体脑肌病、Leber遗传性视神经病、Leigh综合征以及成人的BMI(身体质量指数)升高都有关。
某疑似线粒体疾病患者其线粒体第3502号碱基发生突变,为查看该突变在人群中的发生情况,检索MITOMAP数据库,结果如图5,查询没有任何结果。
而使用实施例1所建立的线粒体变异位点数据库查询,可以看到第3502位点在人群中检测出有两个个体发生了突变(图6),其替换碱基皆为C,其异质性比例分别为0.017026578和0.015580532,比例接近且都很低,表明该突变虽然稀少,但可能对个体影响很大,异质性比例稍高的个体已经不存活。
实施例3
分别在实施例1的线粒体变异位点数据库和MITOMAP数据库进行查询,查询线粒体的第14465号碱基变异位点。
线粒体的第14465号碱基G处于MT-ND6基因,该基因编码NADH-泛醌氧化还原酶链6蛋白。MT-ND6基因的变异与Leber遗传性视神经病,Leigh综合征和肌张力障碍有关。
某疑似线粒体疾病患者其线粒体第14465号碱基发生突变,为查看该突变在人群中的发生情况,检索MITOMAP数据库,结果如图7,查询没有任何结果。
而使用实施例1所建立的线粒体变异位点数据库查询,可以看到第14465位点在人群中检测出有一个个体发生了突变(图8),其替换碱基为A,其异质性比例为0.025501719。
随着本发明的方法的建立,数据库可以不断地扩充样本,从而达到更广泛的代表性,为线粒体突变与疾病的相关研究提供更好的帮助。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
序列表
<110> 广州市金域转化医学研究院有限公司
<120> 一种线粒体变异位点数据库及其建立方法和应用
<160> 2
<170> SIPOSequenceListing 1.0
<210> 1
<211> 24
<212> DNA
<213> Artificial Sequence
<400> 1
ccgcacaaga gtgctactct cctc 24
<210> 2
<211> 25
<212> DNA
<213> Artificial Sequence
<400> 2
gatattgatt tcacggagga tggtg 25
- 一种线粒体变异位点数据库及其建立方法和应用
- 线粒体融合基因2的-2380位点变异及其检测方法