红斑病电子病历病变分类的增量属性约简Spark方法
文献发布时间:2023-06-19 11:32:36
技术领域
本发明涉及技术领域,尤其涉及一种红斑病电子病历病变分类的增量属性约简Spark 方法。
背景技术
红斑性皮肤病是指以多形红色斑疹为特点的皮肤病。红斑病指的是临床上常见的原发性皮损,大部分炎症性皮肤病都可出现红斑,根据其不同的临床特征,可分为多种类型。红斑种类繁多,按颜色可以分为淡红色、紫红色、暗红色;按范围可呈局限性、弥漫性;按形态可呈斑状、网状、环状、地图状等。红斑病的鉴别诊断在皮肤病学中是一种常见问题,它们都具有红斑和脱屑的临床特征,差异很小,难以区分和诊断。鉴别诊断的另一个困难是,一种疾病可能在开始阶段就显示出另一种疾病的特征,而在随后的阶段可能具有其他特征。科技的发展使得计算机可以参与实际应用中对红斑病进行协助分类,便于医生对其进行诊断,具有重要的意义与价值。
但是随着医院规模的不断增大,医院新增的患者信息骤然增多,由于患者信息是动态变化的,因此需要重新计算决策系统以获得新的约简,从而消耗大量的计算时间。显然,普通的约简算法在处理动态决策系统时效率很低,而传统的增量属性约简方法在处理大规模数据时又花费时间过长。
发明内容
本发明的目的在于提供一种红斑病电子病历病变分类的增量属性约简Spark方法,该发明将基于知识粒度的动态变化数据集增量约简算法与处理大数据常用的Spark并行框架相结合,在处理复杂,大规模和动态的数据集方面有着良好的效果,有效提高处理速度,能够进一步提高电子病历属性约简的效率和精度。
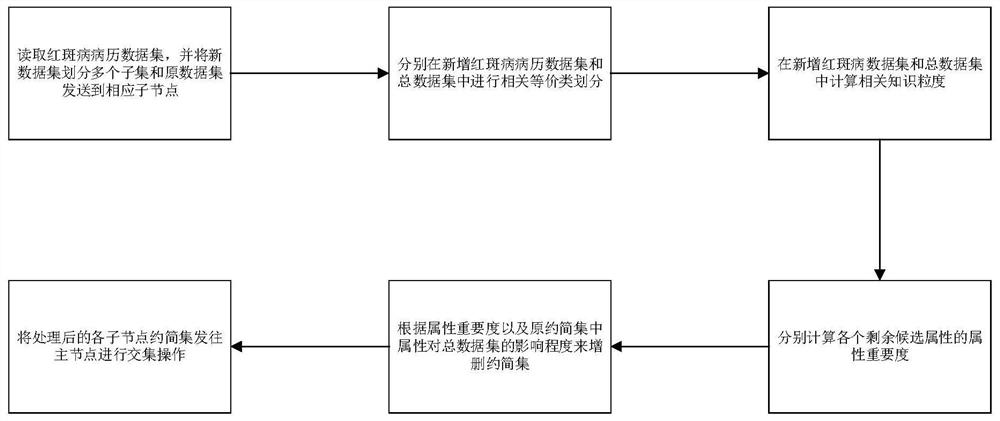
本发明的思想为:首先在Spark主控节点中读取原红斑病病历数据集和约简集以及新增红斑病数据集,并将其和原约简集分别发送到n个子节点中;其次,各个子节点上分别在新增红斑病病历数据集和总数据集中进行一系列等价类划分;接着,在新增红斑病数据集中计算相关知识粒度,并在子节点上计算剩余候选属性的属性重要度,将重要度最大的属性添加进约简集,直至总红斑病病历数据集中原约简集和条件属性集相对于决策属性的知识粒度相等,然后将约简集中对数据集无影响的属性剔除,发送到Spark主控节点;最后,将各个子节点的红斑病病历约简集进行处理,得到最终红斑病电子病历约简集。
本发明是通过如下措施实现的:红斑病电子病历病变分类的增量属性约简Spark方法,包括以下步骤:
步骤1、在Spark框架下的主控节点master中,通过Hadoop分布式文件系统HDFS读取红斑病电子病历的数据集合S,约简属性集B以及新增红斑病病历数据集S',红斑病病历信息的数据集合S和新增红斑病病历数据集S'定义如下:
S={U,CUD,V,f},其中U={x
步骤2、根据新增红斑病病历信息决策属性D的不同信息值个数,将新增红斑病病历信息集合S'划分成n个红斑病病历信息子集S'={S'
步骤3、在从节点slave
步骤4、在从节点slave
步骤5、在从节点slave
步骤6、在从节点slave
步骤7、在从节点slave
作为本发明提供的一种红斑病电子病历病变分类的增量属性约简Spark方法进一步优化方案,所述步骤5的具体步骤如下:
步骤5.1、在从节点slave
其中,
步骤5.2、在从节点slave
步骤5.3、在从节点slave
作为本发明提供的一种红斑病电子病历病变分类的增量属性约简Spark方法进一步优化方案,所述步骤6的具体步骤如下:
步骤6.1、在从节点slave
步骤6.2、在从节点slave
步骤6.3、在从节点slave
步骤6.4、在从节点slave
步骤6.5、在从节点slave
步骤6.6、在从节点slave
与现有技术相比,本发明的有益效果为:本发明在面对新增数据集规模较大,最终类别繁多的实际问题时,能够有效利用上次计算所得结果,将其加入到本次计算中,大幅度节省了红斑病电子病历的数据处理时间,将数据以划分子集的方式分配到各个节点并行处理和计算,也提高了红斑病电子病历属性约简的效率和精度,降低了误诊几率,对于红斑病电子病历的处理及最终诊断提供了便利,在对于红斑病智能辅助分类方面具有较强的应用价值。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。
图1为本发明红斑病电子病历病变分类的增量属性约简Spark方法的总体框架图。
图2为本发明红斑病电子病历病变分类的增量属性约简Spark方法的流程图。
图3为本发明红斑病电子病历病变分类的增量属性约简Spark方法的Spark架构图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。当然,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
实施例1
参见图1至图3,本发明提供其技术方案为,红斑病电子病历病变分类的增量属性约简 Spark方法,包括以下步骤:
步骤1、在Spark框架下的主控节点master中,通过Hadoop分布式文件系统HDFS读取红斑病电子病历的数据集合S,约简属性集B以及新增红斑病病历数据集S',红斑病病历信息的数据集合S和新增红斑病病历数据集S'定义如下:
S={U,CUD,V,f},其中U={x
以如下决策表为例,表1为原红斑病数据集决策表S,原约简集B={a
通过Hadoop分布式文件系统HDFS读取数据到Spark框架下的主控节点master中。
表1
步骤2、根据新增红斑病病历信息决策属性D的不同信息值个数,将新增红斑病病历信息集合S'划分成n个红斑病病历信息子集S'={S'
表2为新增红斑病数据集决策表S'划分后的某子表S'
表2
步骤3、在从节点slave
计算可得U/B={{u
步骤4、在从节点slave
计算可得(UUU'
(UUU'
步骤5、在从节点slave
步骤6、在从节点slave
步骤7、在从节点slave
优选地,所述步骤5的具体步骤如下:
步骤5.1、在从节点slave
其中,
计算可得
步骤5.2、在从节点slave
计算可得
步骤5.3、在从节点slave
因为新增红斑病病历数据集中条件属性集相对于决策属性的知识粒度与原约简属性集相对于决策属性的知识粒度不相等,所以原约简集需要修改,进入步骤6。
优选地,所述步骤6的具体步骤如下:
步骤6.1、在从节点slave
第一轮遍历时,计算可得
第二轮遍历时,计算可得
步骤6.2、在从节点slave
第一轮遍历,将外部属性重要度最大的属性,即a
第二轮遍历,将外部属性重要度最大的属性,即a
步骤6.3、在从节点slave
第一轮遍历中,计算可得总红斑病病历数据集中条件属性集相对于决策属性的知识粒度
第二轮遍历中,计算可得总红斑病病历数据集中条件属性集相对于决策属性的知识粒度
步骤6.4、在从节点slave
计算可得,
步骤6.5、在从节点slave
计算可得
步骤6.6、在从节点slave
因为约简集中剔除属性后的相对决策属性的知识粒度
本发明的工作原理:首先在Spark主控节点中读取原红斑病病历数据集和约简集以及新增红斑病数据集,并将其和原约简集分别发送到n个子节点中;其次,各个子节点上分别在新增红斑病病历数据集和总数据集中进行一系列等价类划分;接着,在新增红斑病数据集中计算相关知识粒度,并在子节点上计算剩余候选属性的属性重要度,将重要度最大的属性添加进约简集,直至总红斑病病历数据集中原约简集和条件属性集相对于决策属性的知识粒度相等,然后将约简集中对数据集无影响的属性剔除,发送到Spark主控节点;最后,将各个子节点的红斑病病历约简集进行处理,得到最终红斑病电子病历约简集。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 红斑病电子病历病变分类的增量属性约简Spark方法
- 红斑病电子病历病变分类的增量属性约简Spark方法