一种概率密度加权的遗传代谢病筛查数据混合采样方法
文献发布时间:2023-06-19 11:35:49
技术领域
本发明属于采样方法技术领域,涉及一种混合采样方法,尤其涉及一种概率密度加权的遗传代谢病筛查数据混合采样方法。
背景技术
串联质谱技术是一种高敏感性、高选择性和高通量的血液生化物质浓度检测技术,在一次实验室检验中,串联质谱法可以同时测定几十种遗传代谢病相关代谢物的血液浓度(筛查指标),对几十种遗传代谢病做出同步诊断。随着人工智能技术的发展,近年来越来越多的学术研究和商业化产品将机器学习、数据挖掘等方法应用于医疗行业,旨在打造新一代智慧医疗模式,让机器更加精准高效地辅助医生判读和诊断疾病。然而,遗传代谢病的人群发病率较低,使得各医院或筛查中心积攒的阳性样本数量十分有限,无法满足许多机器学习特别是深度学习方法对数据量的要求,导致模型无法达到实际性能,甚至预测失败。
目前针对正负样本不均衡和阳性样本过少的问题,采样方法是一个常用的解决手段。现有的采样方法大多使用欧氏距离对正负样本点进行度量,这默认了特征空间的所有方向具有相同的重要性,但在遗传代谢病筛查数据中,病种对特征的响应各不相同,简单地使用欧式距离对数据采样反而容易产生噪音数据;另外,现有的采样方法一般随机地对数据进行采样,或者特别关注正负样本边界的情况,但在遗传代谢病筛查数据中,这些假设没有考虑人群分布规律,不符合实际情况,随机采样产生的数据将导致数据集的分布出现变化,容易对模型产生负面影响。在遗传代谢病筛查这个场景中,现有采样方法存在两个问题:特征空间的所有方向重要性相同、采样的随机性影响数据分布,导致采样生成的样本不符合数据的实际分布,影响建模的效果。
发明内容
本发明的目的在于针对现有技术的不足,提供一种概率密度加权的遗传代谢病筛查数据混合采样方法,利用基于特征惩罚的方法估计每个特征的重要性,在采样时对特征空间的各个方向进行加权;同时,估计阳性样本的分布情况,并将概率密度分布作为样本生成的依据,使得采样生成的样本与整体阳性样本分布较为一致。最终使生成的采样数据更符合人口统计学的真实情况,从而提高建模的准确度。
本发明采用的技术方案如下:
一种概率密度加权的遗传代谢病筛查数据混合采样方法,包括:首先针对一种遗传代谢病,计算历史数据库中串联质谱检测数据的阳性样本数量、阴性样本数量,并分割获得训练数据集、测试集,确定混合采样的迭代次数和每次迭代的采样数量;使用串联质谱检测数据对逻辑回归算法进行训练,基于特征惩罚的方法估计每个特征的重要性;估计阳性样本的分布情况,并将概率密度分布作为样本生成的依据,根据采样概率随机生成阳性样本,获得混合采样结果。
具体的,所述混合采样方法包括如下:
首先确定全局参数
确定混合采样的迭代次数i,确定本次采样方法所针对的一种遗传代谢病D,计算历史数据库中串联质谱检测数据的阳性样本数量
每次迭代的采样数量
对于每次迭代,重复进行以下步骤:
(1)数据特征重要性评估
对于遗传代谢病D,使用串联质谱检测数据对逻辑回归算法进行训练,并将算法的损失函数
其中J为交叉熵函数,X为训练数据集,y为数据标签,y=1表示阳性数据,y=0表示阴性数据,W为数据特征对应的权重,λ>0为惩罚系数。
上述逻辑回归算法使用随机梯度下降法作为模型优化器,该模型迭代次数由输入数据量的大小及拟合曲线决定。
上述逻辑回归算法完成模型参数优化后,将每个特征的最优权重值W作为面向D的数据特征重要性评估。
(2)阳性样本分布估计
D的阳性样本先验分布设定为:
X
其中p表示样本X
对于先验分布
其中
(3)单个阳性样本生成方法
对于一个阳性样本X
计算该阳性样本与剩余所有阳性样本之间的距离,距离的计算方法为:
其中X
选出与X
其中标量δ的取值范围为(0,1)。
(4)阳性样本生成方法
重复执行步骤(3)
对于一个备选阳性样本X
其中F表示标准正态分布的累积分布函数。
计算所有备选阳性样本的采样概率,并根据采样概率随机选择
(5)混合采样
将步骤(4)生成的阳性样本和对应的标签(y=1)加入训练数据集X中;随机从阴性样本中删除
本发明的有益效果是:
本发明设计了一种针对遗传代谢病筛查场景的数据混合采样方法,能够根据不同疾病的特征重要性在特征空间上进行加权,同时基于分布估计方法的采样所生成的阳性样本更加符合真实的人口统计学分布情况。相比于现有采样方法,采用本发明所生成的数据进行建模,初筛阳性率能降低约0.5%左右。
附图说明
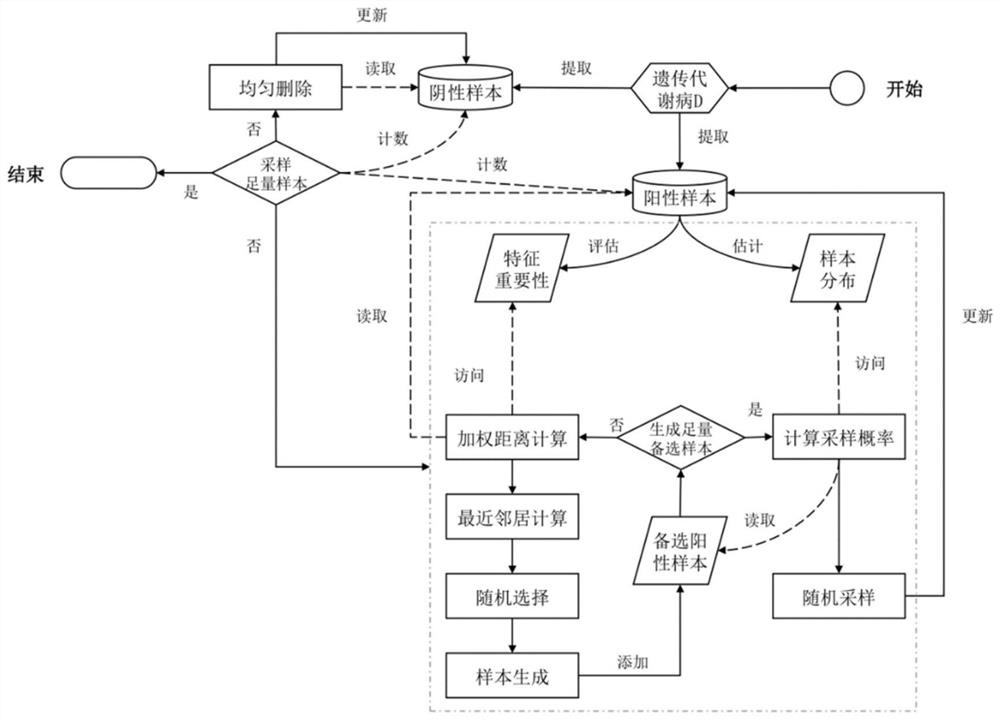
图1是本发明方法的流程示意图;
具体实施方式
下面结合附图和具体实例对本发明做进一步的说明。
本发明的一种概率密度加权的遗传代谢病筛查数据混合采样方法,利用基于特征惩罚的方法估计每个特征的重要性,在采样时对特征空间的各个方向进行加权;同时,估计阳性样本的分布情况,并将概率密度分布作为样本生成的依据,如图1所示,本发明方法具体包括如下:
一、确定全局参数
确定混合采样的迭代次数i,i越大采样方法的计算速度越慢,得到采样结果的分布越符合真实情况;i越小采样方法的计算速度越快,得到采样结果包含的噪音数据越多;(本实例中i=1000)
确定本次采样方法所针对的一种遗传代谢病D,计算历史数据库中串联质谱检测数据的阳性样本数量
每次迭代的采样数量
二、对于每次迭代,重复进行以下步骤:
(1)数据特征重要性评估
对于遗传代谢病D,使用串联质谱检测数据对逻辑回归算法进行训练,并将算法的损失函数
其中J为交叉熵函数,X为训练数据集,y为数据标签(y=1表示阳性数据,y=0表示阴性数据),W为数据特征对应的权重,λ>0为惩罚系数。(本实例中λ=0.1)
上述逻辑回归算法使用随机梯度下降法作为模型优化器,该模型迭代次数由输入数据量的大小及拟合曲线决定。
上述逻辑回归算法完成模型参数优化后,将每个特征的最优权重值W作为面向D的数据特征重要性评估。
(2)阳性样本分布估计
D的阳性样本先验分布设定为:
X
其中p表示样本X
对于先验分布
其中
(3)单个阳性样本生成方法
对于一个阳性样本X
计算该阳性样本与剩余所有阳性样本之间的距离,距离的计算方法为:
其中X
选出与X
其中标量δ的取值范围为(0,1)。(本实例中k=5)
(4)阳性样本生成方法
重复执行步骤(3)
对于一个备选阳性样本X
其中F表示标准正态分布的累积分布函数。
计算所有备选阳性样本的采样概率,并根据采样概率随机选择
(5)混合采样
将步骤(4)生成的阳性样本和对应的标签(y=1)加入训练数据集X中;随机从阴性样本中删除
采用本发明所生成的数据进行建模,初筛阳性率能降低约0.5%左右。
- 一种概率密度加权的遗传代谢病筛查数据混合采样方法
- 一种基于混合高斯概率密度加权的打分模型及系统