一种基于知识图谱的车险理赔欺诈风险识别方法和系统
文献发布时间:2023-06-19 13:49:36
技术领域
本发明涉及计算机技术领域,尤其涉及一种基于知识图谱的车险理赔欺诈风险识别方法和系统。
背景技术
目前计算机技术发展的日新月异,计算机数据库中存储了数据量越来越庞大的业务数据。不法分子在车险理赔中实施的欺诈行为产生的业务数据之间具有一定的关联性,如何从大量业务数据中及时发现其中潜在风险点对识别欺诈行为具有越来越重要的作用。传统技术中,将业务数据按照各自规范分门别类的存储于数据库中。但由于不同数据表之间独立存储,表和表之间不存在关联性,形成了一个又一个数据孤岛,难以简易、批量对比关联案件。现有技术中有提出运用图技术,在查找关联关系时在不同数据表之间跳转,极大地降低了数据关联关系获取的效率。也有使用知识图谱在金融借贷进行反欺诈风险识别。该方法应用于金融借贷业务而且部署在金融借贷业务前端,目前缺少使用知识图谱技术运用于车险业务中控制欺诈风险的系统。该技术可以增加查找效率,但不能及时、有效的推断案件是否暗含欺诈风险。
发明内容
针对现有技术的不足,本发明提出一种基于知识图谱的车险理赔欺诈风险识别方法和系统,运用基于知识图谱技术的反欺诈模型有效降低保险公司成本,对降低车险费率、新险种的设计和定价有很大的帮助。
本发明的目的通过如下的技术方案来实现:
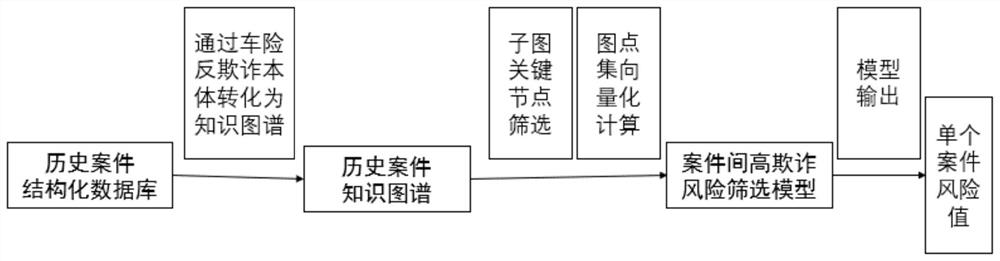
一种基于知识图谱的车险理赔欺诈风险识别方法,该方法包括如下步骤:
步骤一:将历史车险案件按照车险反欺诈本体进行分类整理,所述车险反欺诈本体包括人员本体及其属性单元、机构本体及其属性单元、保单本体及其属性单元、车辆本体及其属性单元、零部件本体及其属性单元、案件本体及其属性单元;
步骤二:根据整理后历史车险案件的数据建立知识图谱关系图;所述知识图谱关系图中包括各个实体和实体关联关系,每个实体为一个节点;
步骤三:从所述知识图谱关系图删除连接度小于预设的连接度阈值的节点,再删除那些与案件没建立连接的节点;
步骤四:以报案人和修理厂为中心,将知识图谱关系图进行划分,形成若干个关键子图,每个关键子图对应多个案件;
步骤五:根据RotatE、TransE、TransH、TransR、TransD模型将所述关键子图进行向量化,得到每个关键子图中每个案件对应的5个特征值;
步骤六:利用每个案件的对应的5个特征值和该案件在关系型数据库中存储的相关信息,以及每个车险案件是否为欺诈案件的标签,对案件间高欺诈风险筛选模型进行训练,得到训练后的案件间高欺诈风险筛选模型;
步骤七:将待识别的车险案件按照所述车险反欺诈本体进行分类整理,并将整理后的案件数据加入所述知识图谱关系图中;采用RotatE、TransE、TransH、TransR、TransD模型对待识别车险案件对应的节点和实体关联关系进行向量化,得到该案件对应的5个特征值;然后将该案件的信息和5个特征值输入训练后的案件间高欺诈风险筛选模型,模型输出待识别车险案件的风险值。
进一步地,所述案件间高欺诈风险筛选模型为XGB模型。
进一步地,输入到训练后的案件间高欺诈风险筛选模型中的信息需为布尔型或数字型特征。
进一步地,所述连接度阈值为5。
一种基于知识图谱的车险理赔欺诈风险识别系统,该系统包括:
关系型数据库,用于存储车险理赔案件相关信息;
车险反欺诈本体提取模块,用于将车险理赔案件相关信息按照车险反欺诈本体进行分类整理,并根据车险理赔案件中的各个实体和实体关联关系创建知识图谱关系图,每个实体在知识图谱关系图为一个节点;所述车险反欺诈本体包括人员本体及其属性单元、机构本体及其属性单元、保单本体及其属性单元、车辆本体及其属性单元、零部件本体及其属性单元、案件本体及其属性单元;
子图关键节点筛选模块,用于删除知识图谱关系图中连接度小于连接度阈值的节点和没有连接案件的节点,并以报案人和修理厂为中心,将知识图谱关系图划分为子图,这些子图为关键子图;
图点集向量化模块,用于根据RotatE、TransE、TransH、TransR、TransD模型将所述关键子图进行向量化,得到每个关键子图中每个案件对应的5个高风险欺诈特征值;
案件间高欺诈风险筛选模型,用于根据每个案件的5个高风险欺诈特征值以及该案件在关系型数据库中存储的相关信息,输出单个案件的风险值。
进一步地,该系统还包括关联案件返回模块,用于根据所述案件的风险值,从所述关系型数据库中调取案件,将案件的案件号和风险值返回给用户。
本发明的有益效果如下:
传统车险反欺诈模型仅单独采用知识图谱技术进行数据可视化、案件关联性进行分析;或单独运用机器学习模型,根据单个案件相关信息对案件是否欺诈进行预测。本发明综合了知识图谱技术和机器学习模型的优点,通过知识图谱技术和图点集向量化技术提取案件间的关联关系,以特征向量的形式提供给机器学习模型。通过分析不同时间、相似节点特征,串联关联案件,从而提示新提交车险案件风险等级。该方法对新提交车险案件进行欺诈风险评估,提高车险理赔业务欺诈案件治理能力。经检验,使用本发明的方法和系统可以有效提高机器学习模型预测准确度。
附图说明
图1为本发明的基于知识图谱的车险理赔欺诈风险识别方法的流程图;
图2为车险车险反欺诈本体的示意图。
具体实施方式
下面根据附图和优选实施例详细描述本发明,本发明的目的和效果将变得更加明白,应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本发明的基于知识图谱的车险理赔欺诈风险识别系统,包括关系型数据库、车险反欺诈本体提取模块、子图关键节点筛选模块、图点集向量化模块、案件间高欺诈风险筛选模型和关联案件返回模块。
1.关系型数据库
关系型数据库用于存储车险理赔案件相关信息。
2.车险反欺诈本体提取模块
将关系型数据库中数据根据业务场景的实际意义划分,即按照自定义的车险反欺诈本体进行分类整理,并根据车险理赔案件中的各个实体和实体关联关系创建知识图谱关系图,每个实体在知识图谱关系图为一个节点。
如图2所示,所述车险反欺诈本体包括:
(1)人员本体及其属性单元。具体包括身份证号、地址、住址、电话、其他代码、驾驶证号、驾驶类型、性别、姓名等属性。
(2)机构本体及其属性单元。具体包括机构代码、机构名称、修理厂类型、是否合作修理厂、修理厂经度、修理厂纬度等属性。
(3)保单本体及其属性单元。具体包括保单号、保单类型、持有者姓名、持有者身份证号、承保机构标识代码、承保二级机构标识代码、总保费、保费、起始时间、截止时间、特别条款内容、特别条款日期、修正内容、批单号码等属性。
(4)车辆本体及其属性单元。具体包括车架号、品牌标识代码、品牌名称、车型标识代码、车型名称、车辆类别、车辆类型名称、车辆使用性质、车辆所属性质、新车价格、案发时车龄、购车日期、车牌号、注册日期、发动机号等属性。
(5)零部件本体及其属性单元。具体包括零部件标识代码、零部件名称、单价、工时类型、案件工时标识代码。
(6)案件本体及其属性单元。具体包括案件号、被保险人身份证号、驾驶员身份证号、查勘员标识代码、定损员标识代码、联系人身份证号、报案人身份证号、保单号、案件节点、事故地址、省份、城市、乡镇、修理厂代码、定损地址、是否指定区域行驶、定损时间、报案时间、道路类型、报案电话、是否现场报案、案件描述、责任代码、责任名称、赔付类型、是否互碰自赔、事故原因名称、是否人伤、是否物伤、查勘时间、查勘描述、估损金额、第三者责任名称、维修零部件标识代码、维修零部件数量(和维修零部件标识代码对应)、维修零部件总价(和维修零部件标识代码对应)、是否人工、查勘地址、查勘时间。
根据案件号依次整理相关字段。若有多个字段表示同一属性值,则需要挑选一个信息量最大的字段作为属性字段。最终整理之后形成数据库表格到具体实体属性映射文件。然后将文件中数据转化为图数据节点和图数据关系。
知识图谱关系图包含实体节点和实体关联关系。实体节点e={E,a},其中E∈ε是实体类型,ε={E
3.子图关键节点筛选模块
该模块用于删除知识图谱关系图中连接度小于连接度阈值的节点和没有连接案件的节点,并以报案人和修理厂为中心,将知识图谱关系图划分为子图,这些子图为关键子图。关键子图g={E,R},其中E是单个实体节点集合,R是实体节点集合E中实体节点相互之间的关联关系。作为其中一种实施方式,综合常规的车险理赔案件涉及的因素,将连接点阈值设置为5。所得关键子图即为高风险欺诈子图。下一步通过图点集向量化模块得到的关键子图点集向量即为高风险欺诈特征值。
4.图点集向量化模块
该模块用于根据RotatE、TransE、TransH、TransR、TransD模型将所述关键子图进行向量化,将图g′={E′,R′}中的单个实体节点根据其相关关系R″转化为向量v={V
RotatE:将每个关系定义为在复矢量空间中从源实体到目标实体的旋转。
TransE:核心思想源于word2vec训练出的词向量在向量空间中存在的平移不变性质。
TransH:认为实体在不同关系下应当拥有不同的表示,并进一步提出每个关系都对应一个超平面。
TransR:认为不同的关系拥有不同的语义空间。
TransD:为实体与关系分别设置了投影向量,并通过投影向量构建投影矩阵,既使得投影矩阵考虑到了头尾实体的影响,又控制了参数规模。
整合向量化图点集,根据不同案件属性加入索引,为案件间高欺诈风险筛选模型提供图点集向量化特征。
5.案件间高欺诈风险筛选模型
该模型可以采用二分类模型,该实施例中,优选XGB:全称是eXtreme GradientBoosting。XGB机器学习中最常用的非线性监督学习方法之一,特点是高效、灵活、轻便。这个模型包括了高效的线性模型和树学习算法,支持不同的函数,包括分类、排序和回归。它是梯度提升框架的一种高效且可扩展的实现和优化。正则化模型用于控制模型的复杂度,使学习模型更简单,避免过拟合。相比GBDT,XGB运用损失函数的二阶泰勒展开XGB的目标函数是:
其中
因此
其中Ω(f
XGB模型用泰勒展开来原来的目标函数,在优化目标函数时可以使用二阶导的信息。
把每个案件的5个特征值以及该案件在关系型数据库中存储的相关信息输入该模型中,模型输出单个案件的风险值。输入到训练后的案件间高欺诈风险筛选模型中的信息需为布尔型或数字型特征。如果在关系型数据库中存储的数据类型为类别型数据,则需要使用One-Hot编码方法将类别型数据转化为数字型特征。
6.调用关联案件返回模块
该模块用于根据案件的风险值,从关系型数据库中调取案件,将案件的案件号和风险值返回给用户。
如图1所示,本发明公开一种基于知识图谱的车险理赔欺诈风险识别方法,该方法模型训练过程和案件风险实时识别过程;
其中,训练过程包括如下步骤:
步骤一:将历史车险案件按照车险反欺诈本体进行分类整理,所述车险反欺诈本体包括人员本体及其属性单元、机构本体及其属性单元、保单本体及其属性单元、车辆本体及其属性单元、零部件本体及其属性单元、案件本体及其属性单元;
步骤二:根据整理后车险案件的数据建立知识图谱关系图;所述知识图谱关系图中包括各个实体和实体关联关系,每个实体为一个节点;
步骤三:从所述知识图谱关系图首先删除连接度小于预设的连接度阈值的节点,然后再删除那些与案件没建立连接的节点;
步骤四:以报案人和修理厂为中心,将所述历史知识图谱关系图进行划分,形成若干个关键子图,每个关键子图对应多个案件;
步骤五:根据RotatE、TransE、TransH、TransR、TransD模型将所述关键子图进行向量化,得到每个关键子图中每个案件对应的5个特征值;
步骤六:将每个历史车险案件的对应的5个特征值和该案件在关系型数据库中存储的相关信息,以及每个车险案件是否为欺诈案件的标签,输入案件间高欺诈风险筛选模型中,对模型进行训练,得到优化后的案件间高欺诈风险筛选模型。所述案件间高欺诈风险筛选模型为二分类模型。
案件风险实时识别过程包括:
(1)将实时车险案件也按照车险反欺诈本体进行分类整理,然后将整理后的案件数据加入所述知识图谱关系图中,若所述知识图谱关系图中已有相同节点,则直接使用该节点,并为该节点添加新案件的实体关联关系;若所述知识图谱关系图中没有相同节点,则先创建新节点,并为新节点添加新案件的实体关联关系;
(2)采用RotatE、TransE、TransH、TransR、TransD模型对新创建的节点和/或实体关联关系进行向量化,得到新案件对应的5个特征值;
(3)将新案件对应的5个特征值以及该案件分类整理后的相关信息输入优化后的案件间高欺诈风险筛选模型中,模型输出该案件的风险值。
下面给出一个本发明的方法和系统的一个具体实施例。在该实施例中,车险数据集中有9175个案件,其中2129个案件标记为欺诈案件,案件欺诈率为23.20%。
在实际业务场景中,保险公司会使用模型评估单个案件风险值,对风险较高的案件采用人工调查的方式确定案件是否是欺诈案件。考虑到人工调查每个案件均有一定成本,保险公司希望人工参与调查的案件欺诈率越高越好,一般保险公司的案件抽调率在1%——5%之间。使用本发明的案件间高欺诈风险筛选模型(XGB模型加上图点集向量化特征)从车险数据集中的9175个案件中抽取了288个高风险案件,案件抽调率为3.14%,其中有117个被标记为欺诈的案件,案件欺诈率为40.63%,比数据集的整体案件欺诈率23.20%有显著的提高。
为了能够评价不同算法的优劣,在Precision和Recall的基础上提出了F1值的概念,来对Precision和Recall进行整体评价。F1的定义如下:
F1值=正确率*召回率*2/(正确率+召回率)
如表1所示,给出了使用单个特征值与XGB模型结合,得到的AUC值、准确率、精确率、找回率和F1值。从表1中可以看出,仅仅使用XGB模型,不使用图点集向量化特征,得到的F1值仅为0.295。而单独使用RotatE、TransE、TransH、TransR、TransD特征中的任意一个,F1值均得到提高。而同时使用RotatE、TransE、TransH、TransR、TransD特征,F1值达到0.468,提升较为明显。
为了进一步证明本发明的方法的优越性,选用不同的二分法模型,如支持向量机模型、神经网络模型分别结合RotatE、TransE、TransH、TransR、TransD单个特征或者全部特征进行计算,结果如表2和表3所示。通过对比表1~表3,发现本发明使用的XGB模型结合RotatE、TransE、TransH、TransR、TransD全部特征,F1值最高。
表1图点集向量化特征加入XGBoost模型中各项评价指标表
表2图点集向量化特征加入支持向量机模型中各项评价指标表
表3图点集向量化特征加入神经网络模型中各项评价指标表
本领域普通技术人员可以理解,以上所述仅为发明的优选实例而已,并不用于限制发明,尽管参照前述实例对发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实例记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在发明的精神和原则之内,所做的修改、等同替换等均应包含在发明的保护范围之内。
- 一种基于知识图谱的车险理赔欺诈风险识别方法和系统
- 车险理赔方法及车险理赔服务系统