一种适用于民族弦乐乐器的声音识别算法及装置
文献发布时间:2023-06-19 18:27:32
技术领域
本发明涉及声音识别技术领域,具体为一种适用于民族弦乐乐器的声音识别算法及装置。
背景技术
随着互联网带宽的增长和移动设备的普及,音乐作为数字形式的存储和检索越来越普遍。为了满足用户对音乐风格和乐器学习的需求,基于内容的音乐检索研究受到了广泛关注。古筝古琴等民族弦乐在音乐结构和旋律不同于西洋乐器,拥有强烈的民族特点。因此,如何准确识别民族弦乐在不同演奏技法下的音符,已成为数字语音处理和数字音乐教学领域的重点研究方向。民族弦乐乐音自动识别技术在编配、歌曲流派分类、歌曲情感分析等音乐领域均具有重要的应用价值。
音乐是由大量信息在不同层次上叠加而成的,因此,对于发展中的人工智能来说,音乐信号的特征分离是一项比较困难的任务。随着信息时代的来临和交叉学科研究的不断深入,智能音乐信号处理有了快速的发展,人们对音乐结构的理解大大加深,也开发了许多用于分析和处理音乐的工具。使用机器代替人类进行传统音乐的创作,成为人们追求的目标。音乐识别技术的目的是提高机器对乐曲的感知能力,让机器准确的“听懂”音乐内容,从而使机器能够理解音乐的情感等。使用深度学习和机器学习等方法来训练人工智能,针对乐理知识研究出数字信号处理的算法,用于辅助甚至代替音乐专业人员完成相关工作。
针对传统西洋乐器如钢琴、吉他等的音符的特征进行识别,其模型的输入输出和算法设计均未考虑民族弦乐如古筝、古琴的特殊指法和技法所形成的音乐音符特征,无法直接应用于古筝、古琴的音符声音的准确识别,为此,我们提出一种实用性更高的适用于民族弦乐乐器的声音识别算法及装置。
发明内容
本发明的目的在于提供一种适用于民族弦乐乐器的声音识别算法及装置,解决了现有的问题。
为实现上述目的,本发明提供如下技术方案:一种适用于民族弦乐乐器的声音识别算法,包括以下步骤:
S1、对所训练的数据集的每种音符语料进行时频域综合特征提取,将提取到的时频域综合特征作为区分音符的特征;
S2、将提取的时频域特征输入到多特征分类器中进行训练,从而得到N种音符特征分类模型;
S3、提取音符测试集的融合特征,将融合特征数据作为SVM的输入特征;
S4、将提取到的音符融合特征与训练得到的音符模型进行综合判决,从而得到相应的音符种类并输出音符识别结果。
一种适用于民族弦乐乐器的声音识别装置,包括:
音频数据输入模块,用于将存储的音频文件或通过设备采集到的音频流作为输入内容输入;
分帧加窗模块,用于对音频数据进行特征提取之前的数据预处理阶段,进行分帧与加窗操作以方便后续时频域特征提取并提高处理效率;
融合特征提取模块,用于在音符识别中,使用最多的特征是在短时傅里叶变换基础上变化的音级轮廓图PCP;
音符多特征分类器训练识别模块,采用SVM模型作为分类识别算法解决乐器特定音符特征的二分类问题
综合判决模块以及结果输出模块,用于将提取到的融合特征数据与训练得到的基于SVM的音符多特征识别模型进行综合判决。
与现有技术相比,本发明的有益效果如下:
本发明针对民族弦乐如古筝、古琴的特殊弹奏技法和指法,设计时频域多种特征提取方法,结合支持向量机和综合判决模块,对民族弦乐的音符进行准确识别。
本发明在音乐理论、信号分析处理和机器学习的基础之上,提出了基于民族弦乐乐器的融合特征和支持向量机模型的音符识别方法,使得到的弦乐音符特征更加平稳的同时削弱了大而稀疏的噪声,再通过基于支持向量机的音符识别模型对音符进行分类。实验结果表明,本发明提出的融合特征有效地提高了音符识别的抗噪性,采用的支持向量机模型能够有效避免过拟合,同时具备较高的识别准确率。
附图说明
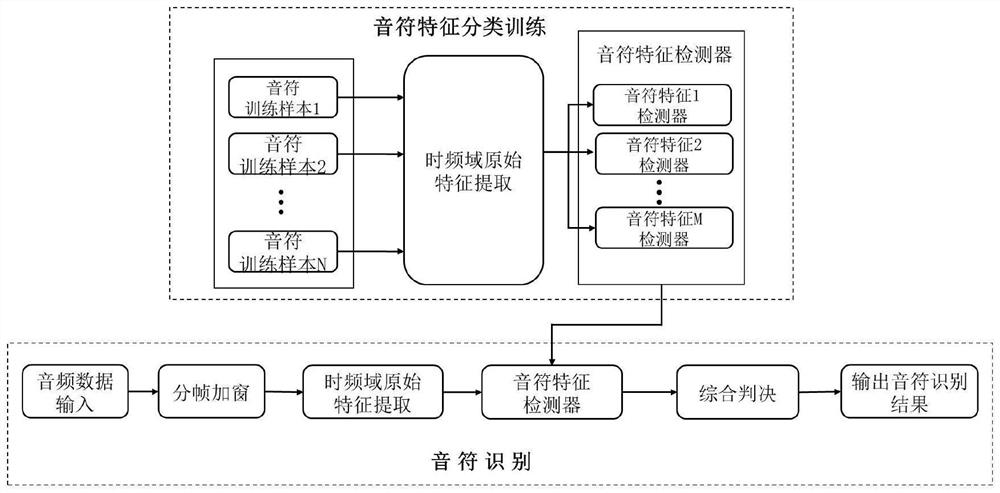
图1为本发明古筝、古琴音符乐音识别示意图;
图2为本发明分帧处理示意示意图;
图3为本发明频域频谱示意图;
图4为本发明音高频谱示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
如图1所示,一种适用于民族弦乐乐器的声音识别算法,包括以下步骤:
S1、对所训练的数据集的每种音符语料进行时频域综合特征提取,将提取到的时频域综合特征作为区分音符的特征;
S2、将提取的时频域特征输入到多特征分类器中进行训练,从而得到N种音符特征分类模型;
S3、提取音符测试集的融合特征,将融合特征数据作为SVM的输入特征;
S4、将提取到的音符融合特征与训练得到的音符模型进行综合判决,从而得到相应的音符种类并输出音符识别结果。
实施案例一
一种适用于民族弦乐乐器的声音识别装置,主要包括:音频数据输入模块、分帧加窗模块、融合特征提取模块、音符多特征分类器训练识别模块、综合判决模块以及结果输出模块,具体包括:
音频数据输入模块
将存储的音频文件或通过设备采集到的音频流作为输入内容输入。
分帧加窗模块
在对音频数据进行特征提取之前的数据预处理阶段,需要进行分帧与加窗操作以方便后续时频域特征提取并提高处理效率。
a.分帧处理
由于音频数据的短时平稳特性,在识别前对其按帧分割;本发明采用交叠分段的分割方式,可以使得分割后的帧间隔信号仍然具有连续性和平滑性,同时在帧与帧之间也作出局部计算。
帧分割数据预处理源文件的标准是采样率为44.1kHz的主旋律音频数据,格式为WAV;同时将处理的音频信号进行降采样处理使其频率降至11025Hz以便归一化;帧长选择512个采样点数,帧移长度设置为512个采样点以保护信号信息的完整性和连续性。
进行上述方法得到重叠的帧信息,再进行后续处理。分帧处理示意图2如下所示:
b.加窗处理
加窗处理可解决分帧处理后每一帧的起始段和末尾端会出现不连续的地方、且分帧越多与原始信号的误差越大这一问题,使信号变得连续。
本发明技术方案选取汉明窗函数作为滑动窗函数,在分帧后的数据段进行汉明窗滑动采样;汉明窗函数如下式所示:
窗函数长度与分帧后的长度一致,都为512点。
融合特征提取模块
在音符识别中,使用最多的特征是在短时傅里叶变换(STFT)基础上变化的音级轮廓图PCP(色度向量的一种);本发明主要使用STFT和PCP特征序列作为音符特征检测器输入,以检测各类音符特征。
a.STFT特征提取
STFT的计算方法如下:
设音频信号以函数表达为x(n),分析窗的函数长度为N,则可得到如下所示的STFT变换,其中0≤k≤N-1表示频率索引数,N点处的汉宁窗记为w(m),短时窗的中心记为n:
由此得到的音乐信号在频域上的频谱图如图3所示。
b.PCP特征提取
PCP色度图是以连续的时间变化为变量的色度向量,在表示音乐内容上有着良好的性质和表现,在获得STFT频谱特征后,其计算步骤如下:
(1)音高频谱图
使用下式将STFT频率带映射到音高域中:
将一组频率索引值分配给一个音高p∈[1:128],其关系如下:
P(p)={k:f
由此得到的音乐信号在音高上的频谱图如下图4所示。
(2)PCP映射
从频域上来看,将每个频率的分量映射到各自PCP的音符索引值记作
式中采样率记作F
(3)归一化
将映射到音名的频谱做归一化处理以避免整个音频幅度变化引起PCP幅值变化,并将同一类高音对应的频带幅度相加得到对应的PCP元素值。归一化公式如下所示:
c.特征融合
为了构造更有效的音符特征参数,将STFT和PCP融合,既表征了音符线性频谱信息,又结合了音符频谱非线性的特征。
首先提取第i帧的y
之后融合每帧y
Y=[y
最后将融合特征参数作为SVM的输入训练识别。
音符多特征分类器训练识别模块
本发明技术方案采用SVM模型作为分类识别算法解决乐器特定音符特征的二分类问题。
其中特定音符特征检测器负责以下几类特征检测,输出0或1,表示检测到该特征或没有:
-单弦震动
-间隔1根弦的双弦震动
-间隔5根弦的双弦震动
-尾音频率上移
-尾音频率下移
-尾音频率抖动
-单弦震动强弱反复
-连续多根弦响应
对于SVM分类器,选择RBF(RadialBasisFunction)作为核函数,按照经验选取惩罚函数c和核函数参数g,并使用网格搜索法对其进行优化以提高分类结果准确率,使用“一对一”方法进行多类分类。
类假设使用径向基函数(RBF)核;径向基函数的两个参数内核C和γ通过参数搜索确定。本发明使用网格搜索的方法来获得C和γ参数。C和γ参数设置完成后即可将SVM扩展到输出概率估计和预测分类标签。
综合判决模块以及结果输出模块
将提取到的融合特征数据与训练得到的基于SVM的音符多特征识别模型进行综合判决,根据下表,得到相应的音符种类判别结果并输出。
具体实施案例二
实验环境及语料选取
采用采集的古筝曲目《渔舟唱晚》《高山流水》《雪山春晓》《云裳诉》等作为数据集,总共包含一百二十首曲目,对这些曲目进行手动标记后得到的标签文件进行训练和判别。
数据集综合古筝曲目合集的流派类型与技法难度进行分类,从而保持公平性;训练集包括三个样本,每个样本包含三十首曲目;测试集包含一个样本,包含三十首曲目,随机从测试集中选取三首曲目进行测试。
在MATLAB2019R环境上进行仿真,电脑配置为win10,运行内存8GB,处理器为intel-i7-4710MQ。
本文采用识别正确率作为性能评价指标,定义如下:
其中,P
实验设计及运行结果
a.音符特征识别正确率检测
设计多组实验进行音符识别验证,比较不同特征提取效果的差异,验证出最适合音符识别的特征,并进行分析。
实验1:提取MFCC特征作为音符特征输入到SVM进行音符识别;
实验2:提取PCP特征作为音符特征输入到SVM进行音符识别;
实验3:提取PCP、MFCC及一维Teager能量倒谱系数特征作为音符特征输入到SVM进行音符识别。
实验结果如下表1所示:
表1不同音符特征在SVM模型下的识别正确率
通过对比实验1、实验2和实验3可以得出,融合一维MFCC、PCP特征之后,相对于分别提取MFCC或PCP特征时识别性能有所提升,这主要是由于PCP特征具有一定的抗噪性能,并反映不同音符之间的非线性能量变化,STFT代表线性频谱特征;融合了MFCC和PCP特征的算法识别率提高了1.91%。
b.鲁棒性验证
为了验证本文方法的鲁棒性,将测试语料分成5等份,分别和白噪声一起构建形成SNR=[5,10,15,20,25]dB的带噪音符;测试集分别与白噪声构建形成SNR=[0,5,10,15]dB的测试音符库;通过训练带噪的音符从而模拟现实环境,在不同的噪声环境下再次进行音符识别测试。
实验1:提取MFCC特征作为音符特征输入到SVM进行音符识别;
实验2:提取PCP特征作为音符特征输入到SVM进行音符识别;
实验3:提取PCP、MFCC合并特征作为音符特征输入到SVM进行音符识别。
实验结果如下表2所示:
表2不同信噪比下的和弦识别正确率
通过对比实验1、实验2和实验3可以得出,本文提出的PCP+MFCC合并特征的识别效果最优,而且随着信噪比的降低,识别率影响相对于其他两种特征并不是很大,在0dB依然可以保持70.61%的识别正确率。
- 一种民族拉弦乐器的降噪装置
- 一种云南民族弦乐器的琴弦自动上蜡装置