服务编排方法、基于服务编排的流程处理方法及计算设备
文献发布时间:2023-06-19 18:35:48
技术领域
本发明涉及互联网技术领域,特别涉及一种服务编排方法、基于服务编排的流程处理方法、计算设备及存储介质。
背景技术
在传统的前台-后台架构中,各个项目之间相互独立,功能可能出现重复,这使得项目本身更为繁琐,也导致开发效率变低。基于此,有必要整合出一个中间组织,为所有项目提供公共资源,这里的中间组织,即为中台。
前台通常既包括与用户直接交互的界面,也包括服务端各种实时响应用户请求的业务逻辑,后台则多指面向内部运营人员的管理系统、配置系统等,而中台,是整合某种通用能力提供给前台,包括业务中台、技术中台、数据中台、算法中台等。
业务中台是把各个项目的共通业务整合成通用的服务平台,在应用到电商业务上时,可以采取标准化的流程SOP(Standard Operating Procedure,标准作业程序)加预留扩展点方式来搭建中台架构。上述方式适合业务线较多的场景,可实现资源的高效复用,但对业务架构师的专业要求较高,由于SOP是标准流程,缺乏灵活性,导致新业务支持上存在欠缺。
为了让中台模式更好地体现,可以通过领域驱动建模抽象出电商业务中台多业务线的共性能力,并预留扩展点,然后利用服务编排对共性能力进行组合。目前,常见的服务编排方法主要有三种,第一种是使用硬编码实现服务之间的编排,但是,这不符合软件开发的开闭原则,对测试人员和产品经理不友好,且多适用于简单场景,可扩展性较差。
第二种是利用业务引擎JBMP(Java Business Process Management,Java业务流程管理)、工作流引擎Activiti等,分离任务的实现和任务的协作关系,验证了服务编排可以提升系统的柔性和灵活性。然而,JBMP和Activiti编排的大部分是人工审批任务,意味着任务流转效率和吞吐量低,而电商领域的微服务多数是程序化的自动任务,意味着任务高效流转,系统吞吐量高。此外,JBMP和Activiti的可靠性比较低,应用是单点架构、同步响应的调用模式,并且高度依赖数据库,不足以支撑电子商务的复杂场景,难以应用到电商业务中台的服务编排。
第三种则采用Netflix Conductor(一种开源微服务编排框架)实现工作流和分布式调度,性能卓越。不过,其核心代码与自身的DSL(Domain Specific Language,领域特定语言)是紧耦合,扩展能力不足,内部应用场景也较少,且由于没有中文界面,不支持可视化编排,若用作企业级的服务编排平台还存在一定差距。
因此,需要一种新的服务编排方案来优化上述处理过程。
发明内容
为此,本发明提供一种服务编排方案,以力图解决或者至少缓解上面存在的问题。
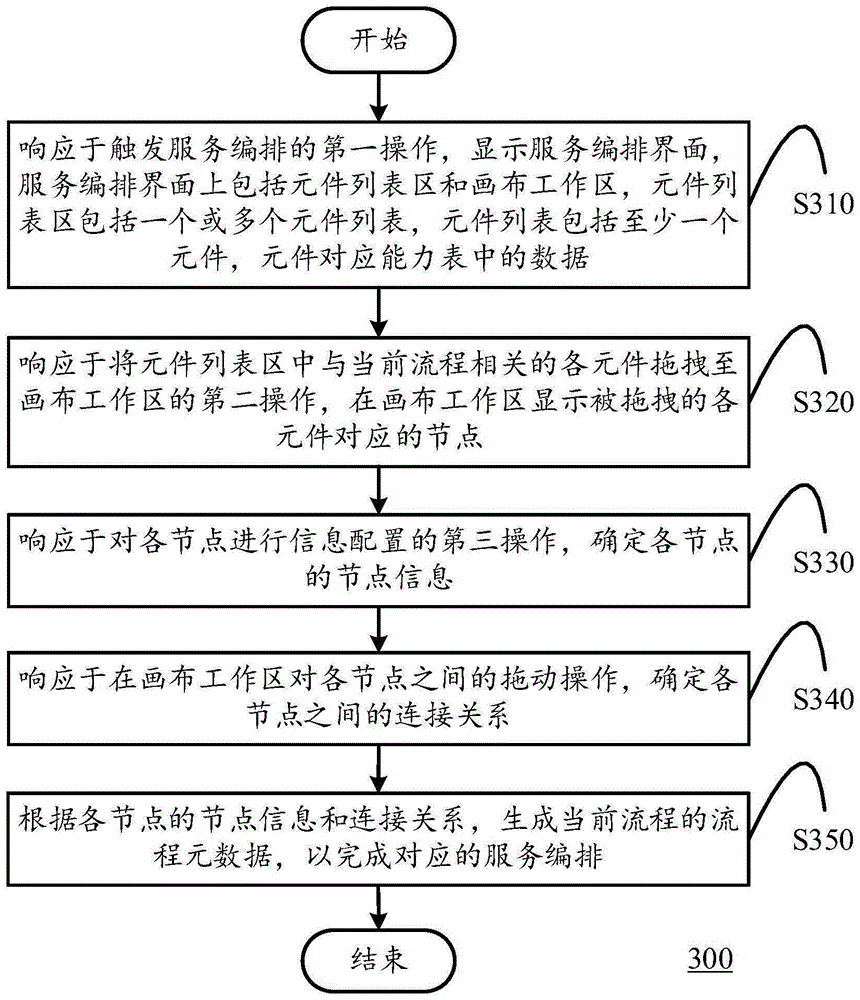
根据本发明的一个方面,提供一种服务编排方法,包括如下步骤:首先,响应于触发服务编排的第一操作,显示服务编排界面,服务编排界面上包括元件列表区和画布工作区,元件列表区包括一个或多个元件列表,元件列表包括至少一个元件,元件对应能力表中的数据;响应于将元件列表区中与当前流程相关的各元件拖拽至画布工作区的第二操作,在画布工作区显示被拖拽的各元件对应的节点;响应于对各节点进行信息配置的第三操作,确定各节点的节点信息;响应于在画布工作区对各节点之间的拖动操作,确定各节点之间的连接关系;根据各节点的节点信息和连接关系,生成当前流程的流程元数据,以完成对应的服务编排。
可选地,在根据本发明的服务编排方法中,服务编排界面上还包括基础配置区,响应于对各节点进行信息配置的第三操作,确定各节点的节点信息的步骤,包括:对任一个节点,响应于对节点的选定操作,在基础配置区显示节点对应的信息配置页面;响应于在信息配置页面对节点信息的配置操作,确定节点的节点信息。
可选地,在根据本发明的服务编排方法中,响应于在画布工作区对各节点之间的拖动操作,确定各节点之间的连接关系的步骤,包括:对任一个节点,响应于从该节点至另一节点的拖动操作,当符合预设条件时,按照拖动方向,在画布工作区显示该节点至另一节点的有向连接线;基于各节点之间的有向连接线,确定各节点之间的连接关系。
可选地,在根据本发明的服务编排方法中,服务编排界面上还包括工具栏区,工具栏区包括流程保存控件,方法还包括:响应于对流程保存控件的点击操作,将当前流程的流程元数据存储至流程表中,以保存当前流程。
可选地,在根据本发明的服务编排方法中,还包括:将当前流程与对应的业务身份进行绑定关联,并将关联信息保存至流程与业务身份关系表。
可选地,在根据本发明的服务编排方法中,还包括:响应于对当前流程的发布操作,将当前流程的流程信息写入预设的服务中间件,并按照与当前流程的流程编码对应的存储路径进行保存,流程信息包括基础信息、关联信息和流程元数据。
根据本发明的又一个方面,提供一种基于服务编排的流程处理方法,包括如下步骤:首先,启动业务系统,通过业务系统对目标注解标注的类进行扫描,以提取出相关字段并存储至能力表;基于业务系统内嵌的流程执行引擎,与预设的服务中间件建立连接;从服务中间件中读取对应存储路径下的各子节点,并创建各子节点对应流程的监听器进行流程监听;解析各子节点对应流程的流程信息并写入虚拟机内存,流程信息包括基础信息、关联信息和流程元数据。
可选地,在根据本发明的基于服务编排的流程处理方法中,目标注解包括能力注解和扩展注解,通过业务系统对目标注解标注的类进行扫描,以提取出相关字段并存储至能力表的步骤,包括:通过业务系统扫描能力注解标注的类,解析能力注解里的能力字段,并存储至能力表;通过业务系统扫描扩展注解标注的类,解析扩展注解里的扩展字段,并存储至能力表。
可选地,在根据本发明的基于服务编排的流程处理方法中,还包括:预先创建能力注解,能力注解里的能力字段包括领域编码、能力编码、能力名称、能力描述;对业务系统的代码,在抽象形成的能力类上附加能力注解,以及完善能力注解的属性信息。
可选地,在根据本发明的基于服务编排的流程处理方法中,还包括:若监听器监听到对应流程的流程信息发生变更,则从服务中间件获取变更后的流程信息;对变更后的流程信息进行解析并写入虚拟机内存。
可选地,在根据本发明的基于服务编排的流程处理方法中,还包括:从虚拟机内存读取流程元数据,将流程元数据写入流程执行引擎的上下文容器。
可选地,在根据本发明的基于服务编排的流程处理方法中,还包括:确定业务身份;调用流程执行引擎,以通过流程执行引擎,从流程与业务身份关系表中查找与业务身份对应的流程,并运行查找到的流程。
根据本发明的又一个方面,提供了一种计算设备,包括:至少一个处理器;以及存储器,存储有程序指令,其中,程序指令被配置为适于由至少一个处理器执行,程序指令包括用于执行如上所述的服务编排方法或基于服务编排的流程处理方法的指令。
根据本发明的又一个方面,提供了一种存储有程序指令的可读存储介质,当程序指令被计算设备读取并执行时,使得计算设备执行如上所述的服务编排方法或基于服务编排的流程处理方法。
根据本发明的服务编排方案,在进行服务编排时,通过服务编排界面,可以进行元件的拖拽、节点连线,提供了可视化服务编排的工作台,使得中台的能力经过编排、重组即可实现高效复用,增加了系统的可扩展性,极大提高了编排效率,降低了代码、配置文件层级编排的工作量,而且不易出错,对新手友好。在基于服务编排处理流程时,利用服务中间件创建监听器以监听流程的动态,从而解决数据库与流程执行引擎的数据一致性和可靠性问题,通过流程信息写入虚拟机内存的机制,有效减少了查询数据库的消耗,保证了读取流程信息的效率,提升了流程执行的性能。
上述技术方案,一方面提供了服务编排的工作台,另一方面提出了服务编排后的流程执行技术,使用服务编排可以将中台的流程与业务逻辑进行解耦,真正做到能力复用和灵活多变,从而有助于中台达成降本增效的目标,最终提升企业的行业竞争力。
附图说明
为了实现上述以及相关目的,本文结合下面的描述和附图来描述某些说明性方面,这些方面指示了可以实践本文所公开的原理的各种方式,并且所有方面及其等效方面旨在落入所要求保护的主题的范围内。通过结合附图阅读下面的详细描述,本公开的上述以及其它目的、特征和优势将变得更加明显。遍及本公开,相同的附图标记通常指代相同的部件或元素。
图1示出了根据本发明的一个实施例的计算设备100的结构框图;
图2示出了根据本发明的一个实施例的基于服务编排的流程处理方法200的流程图;
图3示出了根据本发明的一个实施例的服务编排方法300的流程图;以及
图4示出了根据本发明的一个实施例的服务编排界面的示意图。
具体实施方式
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
图1示出了根据本发明的一个实施例的计算设备100的结构框图。
如图1所示,在基本的配置102中,计算设备100典型地包括系统存储器106和一个或者多个处理器104。存储器总线108可以用于在处理器104和系统存储器106之间的通信。
取决于期望的配置,处理器104可以是任何类型的处理,包括但不限于:微处理器(UP)、微控制器(UC)、数字信息处理器(DSP)或者它们的任何组合。处理器104可以包括诸如一级高速缓存110和二级高速缓存112之类的一个或者多个级别的高速缓存、处理器核心114和寄存器116。示例的处理器核心114可以包括运算逻辑单元(ALU)、浮点数单元(FPU)、数字信号处理核心(DSP核心)或者它们的任何组合。示例的存储器控制器118可以与处理器104一起使用,或者在一些实现中,存储器控制器118可以是处理器104的一个内部部分。
取决于期望的配置,系统存储器106可以是任意类型的存储器,包括但不限于:易失性存储器(诸如RAM)、非易失性存储器(诸如ROM、闪存等)或者它们的任何组合。系统存储器106可以包括操作系统120、一个或者多个应用122以及程序数据124。在一些实施方式中,应用122可以布置为在操作系统上由一个或多个处理器104利用程序数据124执行指令。
计算设备100还包括储存设备132,储存设备132包括可移除储存器136和不可移除储存器138。
计算设备100还可以包括储存接口总线134。储存接口总线134实现了从储存设备132(例如,可移除储存器136和不可移除储存器138)经由总线/接口控制器130到基本配置102的通信。操作系统120、应用122以及程序数据124的至少一部分可以存储在可移除储存器136和/或不可移除储存器138上,并且在计算设备100上电或者要执行应用122时,经由储存接口总线134而加载到系统存储器106中,并由一个或者多个处理器104来执行。
计算设备100还可以包括有助于从各种接口设备(例如,输出设备142、外设接口144和通信设备146)到基本配置102经由总线/接口控制器130的通信的接口总线140。示例的输出设备142包括图形处理单元148和音频处理单元150。它们可以被配置为有助于经由一个或者多个A/V端口152与诸如显示器或者扬声器之类的各种外部设备进行通信。示例外设接口144可以包括串行接口控制器154和并行接口控制器156,它们可以被配置为有助于经由一个或者多个I/O端口158和诸如输入设备(例如,键盘、鼠标、笔、语音输入设备、触摸输入设备)或者其他外设(例如打印机、扫描仪等)之类的外部设备进行通信。示例的通信设备146可以包括网络控制器160,其可以被布置为便于经由一个或者多个通信端口164与一个或者多个其他计算设备162通过网络通信链路的通信。
网络通信链路可以是通信介质的一个示例。通信介质通常可以体现为在诸如载波或者其他传输机制之类的调制数据信号中的计算机可读指令、数据结构、程序模块,并且可以包括任何信息递送介质。“调制数据信号”可以是这样的信号,它的数据集中的一个或者多个或者它的改变可以在信号中以编码信息的方式进行。作为非限制性的示例,通信介质可以包括诸如有线网络或者专线网络之类的有线介质,以及诸如声音、射频(RF)、微波、红外(IR)或者其它无线介质在内的各种无线介质。这里使用的术语计算机可读介质可以包括存储介质和通信介质二者。
计算设备100可以实现为包括桌面计算机和笔记本计算机配置的个人计算机。当然,计算设备100也可以实现为小尺寸便携(或者移动)电子设备的一部分,这些电子设备可以是诸如蜂窝电话、数码照相机、个人数字助理(PDA)、个人媒体播放器设备、无线网络浏览设备、个人头戴设备、应用专用设备、或者可以包括上面任何功能的混合设备。甚至可以被实现为服务器,如文件服务器、数据库服务器、应用程序服务器和WEB服务器等。本发明的实施例对此均不做限制。
在根据本发明的实施例中,计算设备100被配置为执行根据本发明的基于服务编排的流程处理方法200或服务编排方法300。其中,布置在操作系统上的应用122中包含用于执行本发明的基于服务编排的流程处理方法200,或服务编排方法300的多条程序指令,这些程序指令可以指示处理器104执行本发明的基于服务编排的流程处理方法200或服务编排方法300,以便计算设备100通过执行本发明的基于服务编排的流程处理方法200处理流程,或通过执行本发明的服务编排方法300编排服务。
图2示出了根据本发明的一个实施例的基于服务编排的流程处理方法200的流程图。基于服务编排的流程处理方法200可以在计算设备(例如前述计算设备100)中执行。
如图2所示,方法200始于步骤S210。在步骤S210中,启动业务系统,通过业务系统对目标注解标注的类进行扫描,以提取出相关字段并存储至能力表。其中,目标注解包括能力注解和扩展注解。
根据本发明的一个实施例,在启动业务系统之前,方法200还包括预先创建能力注解,对业务系统的代码,在抽象形成的能力类上附加能力注解,以及完善能力注解的属性信息。在该实施方式中,能力注解里的能力字段包括领域编码、能力编码、能力名称、能力描述。
例如,创建Java(一种编程语言)注解@BaseAbility作为能力注解,用来表示电商业务中台的能力,包括能力字段domainCode、code、name、desc。其中,domainCode代表领域编码,比如订单域的领域编码domainCode=order,促销域的领域编码domainCode=promotion。而code、name、desc分别代表能力编码、能力名称、能力描述,以支付成功发送短信场景来说,code=order pay success sms,name=支付成功发短信,desc=用户在支付成功之后发送的短信的处理。
完成能力注解的创建后,在抽象出来形成的电商业务中台的能力的类上附加@BaseAbility注解,这里电商业务中台的能力的类即为处理业务能力的类,一般约束为Ability结尾。例如,在支付成功发送短信的场景下,类名为PaySuccessSmsAbility,类上有注解@BaseAbility,伪代码如下:
@BaseAbility(domainCode=order,code=order_pay_success_sms,name=支付成功发短信,desc=用户在支付成功之后发送的短信的处理)
Public Class PaySuccessSmsAbility{
}
类似的类还有很多,比如扣减库存的能力类DecreaseStockAbility等。能力注解@BaseAbility的属性信息实际上就是上述能力字段domainCode、code、name、desc的信息,换言之,将字段信息处理完成即意味着完善好了属性信息。
扩展注解与能力注解不同,其为COLA(Clean Object-Oriented and LayeredArchitecture,整洁面向对象分层架构)框架的组件,而业务系统依赖于COLA框架,因此,扩展注解是不需要额外创建而可以直接引用的。扩展注解通常为@Extension,包括扩展字段useCase、bizId、scenario。
其中,useCase代表场景,在电商业务中台标识的是哪个前台商城过来的订单,比如,userCase=10代表车商城的订单,userCase=11代表积分商城的订单。而bizId代表业务线,在电商业务中台标识的是哪个业务线的订单,比如bizId=10代表厂商旗舰店的订单,bizId=11代表车品业务的订单。最后,scenario代表商品产生的订单的一个标识,是一个实物物流的订单还是一个虚拟会员卡的领券券码的订单。之所以这样区分是考虑到业务之间存在一定的交集,例如bizId=11的车品既会在积分商城里售卖,也会在车商城里售卖,但是两者的展现形式和后续的订单流程会有所差别。
@Extension注解一般会标注到扩展点的实现类,在支付成功发送短信场景下,能力类名为PaySuccessSmsAbility,依赖了扩展点类GetSmsContentExt,这个类是一个interface(接口),有多个实现类,比如发送支付成功短信实现类GetPayedSmsContentExtenion,则有伪代码如下:
@Extension(useCase=xx,bizId=xx,scenario=xx)
Public class GetPayedSmsContentExtenion implement GetSmsContentExt{
}
根据本发明的一个实施例,可采取如下方式通过业务系统对目标注解标注的类进行扫描,以提取出相关字段并存储至能力表。在该实施方式中,通过业务系统扫描能力注解标注的类,解析能力注解里的能力字段,并存储至能力表,通过业务系统扫描扩展注解标注的类,解析扩展注解里的扩展字段,并存储至能力表。
由此可知,能力表中的数据实际上就是解析能力字段和扩展字段而提取出的数据,通常能力表存储在数据库中,每一条能力表中的数据包括能力的所属领域、编码、名称、描述、能力对应的类名和方法名、创建时间、更新时间等。以下为创建能力表的示例性代码:
CREATE TABLE'trade_domain_service'(
'id'bigint(20)NOT NULL AUTO_INCREMENT COMMENT'自增id',
'domain_code'varchar(50)NOT NULL COMMENT'域编码',
'service_code'varchar(50)DEFAULT NULL COMMENT'服务编码',
'service_name'varchar(100)DEFAULT NULL COMMENT'域服务/域能力',
……
PRIMARY KEY('id'),
UNIQUE KEY'uniq_service_code'('service_code'),
KEY'idx_route_type'('route_type')
)ENGINE=InnoDB AUTO_INCREMENT=42DEFAULT CHARSET=utf8mb4
COMMENT='域信息详情表';
根据本发明的一个实施例,业务系统启动的同时,还会启动以JAR包(又称Java档案文件,英文全称为Java Archive File)方式嵌入到业务系统里的流程执行引擎。流程执行引擎可采用Apache Camel(一个基于规则的路由以及媒介引擎)实现,基于事件驱动的Apache Camel,有着良好的性能和吞吐量,目前已经拥有三百多种扩展组件,扩展机制极其方便和灵活。
在步骤S220中,基于业务系统内嵌的流程执行引擎,与预设的服务中间件建立连接。根据本发明的一个实施例,服务中间件选用ZooKeeper(一个分布式应用程序协调服务),则初始化流程执行引擎与ZooKeeper客户端之间的连接。此外,还可以注册ZooKeeper中相应存储路径的监听器,以便进行路径监听,如此一来,当有流程新增、删除的时候,通过监听路径变化的事件即可及时处理。
随后,进入步骤S230,从服务中间件中读取对应存储路径下的各子节点,并创建各子节点对应流程的监听器进行流程监听。根据本发明的一个实施例,每个子节点相当于一个流程,通过创建该流程的监听器,则当流程信息发生变更的时候就能随之更新。
由于ZooKeeper的存储结构是树形存储,在该实施方式中,假设流程P1的流程编码为flow_cancel_order,则流程P1在ZooKeeper内部的存储路径是/flow/flow_cancel_orde,进而从ZooKeeper中读取/flow/flow_cancel_orde路径下的子节点,该子节点对应的流程即为流程P1,为其创建对应的监听器以实时监听。
最后,在步骤S240中,解析各子节点对应流程的流程信息并写入虚拟机内存,流程信息包括基础信息、关联信息和流程元数据。其中,基础信息包括流程名称、流程编码(流程的唯一标识)、流程描述、版本号、触发流程的事件、流程所属领域、发布状态、编排文件信息(用于描述流程的执行过程)、创建时间、创建人、修改时间等信息。
关联信息包括从流程与业务身份关系表中,按流程编码查找出关联的业务身份集合。流程元数据一般是JSON(JavaScript Object Notation,JS对象简谱)格式,也可称为执行信息,包括流程编码、流程标识、节点信息和连接关系等信息,通常是在服务编排过程中生成的,这部分内容将在服务编排方法300的相关说明中呈现。
上述虚拟机内存可采用JVM(Java Virtual Machine,Java虚拟机)内存,将流程信息以键值对的形式存储,即写入到JVM内存。根据本发明的一个实施例,方法200还包括:从虚拟机内存读取流程元数据,将流程元数据写入流程执行引擎的上下文容器。
在该实施方式中,从JVM内存读取流程元数据,每个流程的每个节点的信息解析成作为流程执行引擎的Apache Camel的路由信息,这一解析过程是以拼接字符串的形式进行的,而后将该路由信息拼接XML(eXtensible Markup Language,可扩展标记语言)文件,再将XML文件写入Apache Camel的上下文容器Camel Context(由Apache Camel构造的运行时容器,并执行路由规则),从而完成流程的加载。
以上流程处理的过程涉及到服务编排的结果,比如当业务系统扫描目标注解标注的类并从中提取相关字段以存储到能力表中,以及启动流程执行引擎建立与服务中间件的连接之后,可以在管理后台开始服务编排,以便生成对应的流程,进而发布流程,将流程信息写入到服务中间件,如此流程执行引擎方可从服务中间件中读取到所需流程信息。
由于流程执行引擎内嵌于业务系统,则流程执行引擎与业务系统是部署于同一计算设备,而进行服务编排的管理后台显然部署于另一计算设备,数据库及服务中间件也分别运行在其他的单独的计算设备上。
图3示出了根据本发明的一个实施例的服务编排方法300的流程图。服务编排方法300可以在计算设备(例如前述计算设备100)中执行,应注意的是,服务编排方法300和基于服务编排的流程处理方法200不可在同一计算设备中执行。
如图3所示,方法300始于步骤S310。在步骤S310中,响应于触发服务编排的第一操作,显示服务编排界面,服务编排界面上包括元件列表区和画布工作区,元件列表区包括一个或多个元件列表,元件列表包括至少一个元件,元件对应能力表中的数据。
根据本发明的一个实施例,第一操作通常是针对服务编排按钮的点击操作,例如,在流程管理列表中显示有多个流程,每个流程都对应有一个服务编排按钮,若选定要编排的流程,则可点击该流程的服务编排按钮,即可触发服务编排,显示对应的服务编排界面。当然,流程管理列表里的各流程,需要预先创建,比如,在管理后台新建一个流程,填写流程的基础信息,并存储到流程表里,流程表指的是数据库层面存储流程的位置。
在该实施方式中,元件列表是能力表在页面上的展示关系,是一一对应的,即一个元件对应一个能力表中的数据。例如,元件列表可以为基础域-基础能力,其中包括3个元件,分别是http服务、groovy服务和bean服务。
随后,进入步骤S320,响应于将元件列表区中与当前流程相关的各元件拖拽至画布工作区的第二操作,在画布工作区显示被拖拽的各元件对应的节点。比如,对元件列表区中与当前流程相关的各元件,点击该元件并将其拖拽到画布工作区,此时在画布工作区将显示与该元件对应的节点。
在步骤S330中,响应于对各节点进行信息配置的第三操作,确定各节点的节点信息。
根据本发明的一个实施例,服务编排界面上还包括基础配置区,可通过如下方式响应于对各节点进行信息配置的第三操作,确定各节点的节点信息。在该实施方式中,对任一个节点,响应于对节点的选定操作,在基础配置区显示节点对应的信息配置页面,响应于在信息配置页面对节点信息的配置操作,确定节点的节点信息。
信息配置页面一般包括节点类型、节点坐标等不可编辑信息,以及节点名称等可编辑信息,通过对如节点名称等可编辑信息的配置即可更新节点,进而将信息配置页面的相关信息确定为该节点的节点信息。
在步骤S340中,响应于在画布工作区对各节点之间的拖动操作,确定各节点之间的连接关系。
根据本发明的一个实施例,可以通过如下方式响应于在画布工作区对各节点之间的拖动操作,确定各节点之间的连接关系。在该实施方式中,对任一个节点,响应于从该节点至另一节点的拖动操作,当符合预设条件时,按照拖动方向,在画布工作区显示该节点至另一节点的有向连接线,基于各节点之间的有向连接线,确定各节点之间的连接关系。
例如,画布工作区有3个节点,分别是节点1、节点2和节点3,对于节点1,响应于从节点1至节点2的拖动操作,按照拖动方向显示节点1至节点2的有向连接线,并响应于从节点1至节点3的拖动操作,按照拖动方向显示节点1至节点3的有向连接线。最终,基于节点1与节点2、节点1与节点3之间的有向连接线,确定上述3个节点之间的连接关系。
最后,执行步骤S350,根据各节点的节点信息和连接关系,生成当前流程的流程元数据,以完成对应的服务编排。其中,流程元数据包括流程编码、流程标识、节点信息和连接关系。
流程编码用于唯一标识一个流程,流程标识则是相对数据库而言,由于流程在页面上操作完毕后,需要持久化存储到数据库,则在数据库层面就会生成一个标识,这个标识是利用数据库表自增生成的,也同样具有唯一性,将其记为流程标识。有了流程标识,就可以再次打开编辑对应的流程。
根据本发明的一个实施例,服务编排界面上还包括工具栏区,工具栏区包括流程保存控件,方法300还包括:响应于对流程保存控件的点击操作,将当前流程的流程元数据存储至流程表中,以保存当前流程。
图4示出了根据本发明的一个实施例的服务编排界面的示意图。如图4所示,服务编排界面包括元件列表区、画布工作区、基础配置区和工具栏区。其中,工具栏区位于服务编排界面的最上方,在工具栏区的下方位置,从左至右依次是元件列表区、画布工作区和基础配置区。
为尽量展示服务编排界面的布局和保证图示简洁明了,上述元件列表区中的各元件、画布工作区中的各节点及连接关系、基础配置区的信息配置页面、工具栏区的流程保存控件等,在图4中均未示出。
在利用服务编排界面进行服务编排时,将元件列表区中与当前流程相关的各元件拖拽至画布工作区,以在画布工作区显示被拖拽的各元件对应的节点,并在基础配置区的信息配置页面对画布工作区中的各节点进行信息配置,从而确定各节点的节点信息。而后,拖动画布工作区的各节点,以明确各节点之间的连接关系,并通过点击工具栏区的流程保存控件,保存当前流程。
根据本发明的一个实施例,方法300还包括:将当前流程与对应的业务身份进行绑定关联,并将关联信息保存至流程与业务身份关系表。
在该实施方式中,可以在业务身份绑定界面进行流程与业务身份之间的一系列操作,包括绑定、解绑等。如果选择进行绑定,则会将对应的业务身份和当前流程的流程编码关联,并生成关联信息存储到流程与业务身份关系表。如果要对已绑定的流程与业务身份来解绑,则选定解绑后,会将流程与业务身份关系表中对应业务身份、流程编码的关联信息进行删除。
根据本发明的一个实施例,方法300还包括:响应于对当前流程的发布操作,将当前流程的流程信息写入预设的服务中间件,并按照与当前流程的流程编码对应的存储路径进行保存,流程信息包括基础信息、关联信息和流程元数据。
在该实施方式中,服务中间件采用ZooKeeper,则在流程管理列表选择当前流程并点击对应的流程发布按钮,将流程信息写入到ZooKeeper里的存储路径下,存储路径的格式为/flow/流程编码,即当流程编码为flow_cancel_order时,其对应的流程的流程信息将存储到ZooKeeper中/flow/flow_cancel_order路径下。
在管理后台完成当前流程的服务编排并发布流程后,流程执行引擎之前建立的ZooKeeper监听将会收到变更信息。基于此,根据本发明的一个实施例,方法200还包括:若监听器监听到对应流程的流程信息发生变更,则从服务中间件获取变更后的流程信息,对变更后的流程信息进行解析并写入虚拟机内存。当然,后续还是要从虚拟机内存读取变更后的流程信息中的流程元数据,将其写入流程执行引擎的上下文容器,时刻保持流程信息的一致性。
当流程加载完成之后,业务系统就可以调用流程了。根据本发明的又一个实施例,方法200还包括:确定业务身份,调用流程执行引擎,以通过流程执行引擎,从流程与业务身份关系表中查找与业务身份对应的流程,并运行查找到的流程。
在该实施方式中,可以根据当前的订单号查询数据库,确定对应订单的业务身份,调用流程执行引擎的执行接口,传入领域事件、业务身份。流程执行引擎会根据领域事件、业务身份查找流程与业务身份关系表,以获取对应的流程,并运行该流程,若没有找到流程则直接报错。
根据本发明实施例的服务编排方案,在进行服务编排时,通过服务编排界面,可以进行元件的拖拽、节点连线,提供了可视化服务编排的工作台,使得中台的能力经过编排、重组即可实现高效复用,增加了系统的可扩展性,极大提高了编排效率,降低了代码、配置文件层级编排的工作量,而且不易出错,对新手友好。在基于服务编排处理流程时,利用服务中间件创建监听器以监听流程的动态,从而解决数据库与流程执行引擎的数据一致性和可靠性问题,通过流程信息写入虚拟机内存的机制,有效减少了查询数据库的消耗,保证了读取流程信息的效率,提升了流程执行的性能。
A5、如A1-A4中任一项所述的方法,还包括:
将所述当前流程与对应的业务身份进行绑定关联,并将关联信息保存至流程与业务身份关系表。
A6、如A1-A5中任一项所述的方法,还包括:
响应于对所述当前流程的发布操作,将所述当前流程的流程信息写入预设的服务中间件,并按照与所述当前流程的流程编码对应的存储路径进行保存,所述流程信息包括基础信息、关联信息和流程元数据。
B11、如B7-B10中任一项所述的方法,还包括:
从所述虚拟机内存读取所述流程元数据,将所述流程元数据写入所述流程执行引擎的上下文容器。
B12、如B7-B11中任一项所述的方法,还包括:
确定业务身份;
调用所述流程执行引擎,以通过所述流程执行引擎,从流程与业务身份关系表中查找与所述业务身份对应的流程,并运行查找到的流程。
上述技术方案,一方面提供了服务编排的工作台,另一方面提出了服务编排后的流程执行技术,将中台的流程与业务逻辑进行解耦,实现了业务的隔离,真正做到能力复用和灵活多变。在实际应用中,使用可视化的管理后台进行服务编排,以Apache Camel充当流程执行引擎的角色,处理服务编排后的流程,不仅提高了业务中台的共享复用能力和研发测试的迭代效率,也保障了交易业务的正常运行,快速响应业务需求,从而有助于中台达成降本增效的目标,最终提升企业的行业竞争力。
这里描述的各种技术可结合硬件或软件,或者它们的组合一起实现。从而,本发明的方法和设备,或者本发明的方法和设备的某些方面或部分可采取嵌入有形媒介,例如可移动硬盘、U盘、软盘、CD-ROM或者其它任意机器可读的存储介质中的程序代码(即指令)的形式,其中当程序被载入诸如计算机之类的机器,并被所述机器执行时,所述机器变成实践本发明的设备。
在程序代码在可编程计算机上执行的情况下,计算设备一般包括处理器、处理器可读的存储介质(包括易失性和非易失性存储器和/或存储元件),至少一个输入装置,和至少一个输出装置。其中,存储器被配置用于存储程序代码;处理器被配置用于根据该存储器中存储的所述程序代码中的指令,执行本发明的服务编排方法或基于服务编排的流程处理方法。
以示例而非限制的方式,可读介质包括可读存储介质和通信介质。可读存储介质存储诸如计算机可读指令、数据结构、程序模块或其它数据等信息。通信介质一般以诸如载波或其它传输机制等已调制数据信号来体现计算机可读指令、数据结构、程序模块或其它数据,并且包括任何信息传递介质。以上的任一种的组合也包括在可读介质的范围之内。
在此处所提供的说明书中,算法和显示不与任何特定计算机、虚拟系统或者其它设备固有相关。各种通用系统也可以与本发明的示例一起使用。根据上面的描述,构造这类系统所要求的结构是显而易见的。此外,本发明也不针对任何特定编程语言。应当明白,可以利用各种编程语言实现在此描述的本发明的内容,并且上面对特定语言所做的描述是为了披露本发明的最佳实施方式。
在此处所提供的说明书中,说明了大量具体细节。然而,能够理解,本发明的实施例可以在没有这些具体细节的情况下被实践。在一些实例中,并未详细示出公知的方法、结构和技术,以便不模糊对本说明书的理解。
类似地,应当理解,为了精简本公开并帮助理解各个发明方面中的一个或多个,在上面对本发明的示例性实施例的描述中,本发明的各个特征有时被一起分组到单个实施例、图、或者对其的描述中。然而,并不应将该公开的方法解释成反映如下意图:即所要求保护的本发明要求比在每个权利要求中所明确记载的特征更多特征。更确切地说,如下面的权利要求书所反映的那样,发明方面在于少于前面公开的单个实施例的所有特征。因此,遵循具体实施方式的权利要求书由此明确地并入该具体实施方式,其中每个权利要求本身都作为本发明的单独实施例。
本领域那些技术人员应当理解在本文所公开的示例中的设备的模块或单元或组件可以布置在如该实施例中所描述的设备中,或者可替换地可以定位在与该示例中的设备不同的一个或多个设备中。前述示例中的模块可以组合为一个模块或者此外可以分成多个子模块。
本领域那些技术人员可以理解,可以对实施例中的设备中的模块进行自适应性地改变并且把它们设置在与该实施例不同的一个或多个设备中。可以把实施例中的模块或单元或组件组合成一个模块或单元或组件,以及此外可以把它们分成多个子模块或子单元或子组件。除了这样的特征和/或过程或者单元中的至少一些是相互排斥之外,可以采用任何组合对本说明书(包括伴随的权利要求、摘要和附图)中公开的所有特征以及如此公开的任何方法或者设备的所有过程或单元进行组合。除非另外明确陈述,本说明书(包括伴随的权利要求、摘要和附图)中公开的每个特征可以由提供相同、等同或相似目的的替代特征来代替。
此外,本领域的技术人员能够理解,尽管在此所述的一些实施例包括其它实施例中所包括的某些特征而不是其它特征,但是不同实施例的特征的组合意味着处于本发明的范围之内并且形成不同的实施例。例如,在下面的权利要求书中,所要求保护的实施例的任意之一都可以以任意的组合方式来使用。
此外,所述实施例中的一些在此被描述成可以由计算机系统的处理器或者由执行所述功能的其它装置实施的方法或方法元素的组合。因此,具有用于实施所述方法或方法元素的必要指令的处理器形成用于实施该方法或方法元素的装置。此外,装置实施例的在此所述的元素是如下装置的例子:该装置用于实施由为了实施该发明的目的的元素所执行的功能。
如在此所使用的那样,除非另行规定,使用序数词“第一”、“第二”、“第三”等等来描述普通对象仅仅表示涉及类似对象的不同实例,并且并不意图暗示这样被描述的对象必须具有时间上、空间上、排序方面或者以任意其它方式的给定顺序。
尽管根据有限数量的实施例描述了本发明,但是受益于上面的描述,本技术领域内的技术人员明白,在由此描述的本发明的范围内,可以设想其它实施例。此外,应当注意,本说明书中使用的语言主要是为了可读性和教导的目的而选择的,而不是为了解释或者限定本发明的主题而选择的。因此,在不偏离所附权利要求书的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。对于本发明的范围,对本发明所做的公开是说明性的,而非限制性的,本发明的范围由所附权利要求书限定。