一种基于多模态步态参数的脑卒中关联量化评估方法
文献发布时间:2023-06-19 19:27:02
技术领域
本发明涉及脑卒中诊断技术领域,具体为一种基于多模态步态参数的脑卒中关联量化评估方法。
背景技术
传统上,判别一个人是否患有脑卒中,或给脑卒中患者严重程度进行分类时,往往由有经验的医生对病例组受试者根据美国国立卫生研究院卒中量表(NHISS)进行评分,评估卒中严重程度。
而之前的研究中孔佑琪等使用盖力步步态分析系统对卒中患者和健康对照组进行步态分析检测,发现卒中患者患侧与对照组进行比较,病例组的步幅缩短,步频及步速下降,摆动相时间、支撑相时间及双足支撑时间延长(P<0.01)。
目前临床上步态分析多用于揭示脑卒中患者的步态在很多方面存在明显差异,通过确定脑卒中患者的步态特征(步态参数),有效评价脑卒中患者康复质量效果。最初的步态分析方法是利用临床医生的经验进行主观观察,或者录像观察来进行,或者通过量表评分的方法。这种方法的优点是简单、低廉,缺点是定性、主观性大、主要依靠医生的经验、准确性不好。另外,有少量的关于脑卒中病人步态分析的智能研究,如根据步态的对称性、规律性和稳定性作为特征,对是否为脑卒中进行判别,也有对脑卒中患者的步态进行分类和评估研究,但是几乎没有基于较全面的步态时空特征(参数)。
发明内容
本发明的目的在于提供一种基于多模态步态参数的脑卒中关联量化评估方法,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:一种基于多模态步态参数的脑卒中关联量化评估方法,包括以下步骤:
S1、收集被试者的多维步态参数数据:由步态分析系统收集被试者的多维步态参数数据,并进行分析检测,得到被试者的时间参数特征和空间参数特征;
S2、数据归一化处理:采用最大最小法对数据进行归一化处理,其目的在于将所有特征都映射到(0,1)的范围内,保证不同量纲和不同数量级的特征对之后的机械学习模型的影像都相同;
S3、NIHSS量表打分和标注:医生采用临床上进行脑卒中患者严重程度评估的NIHSS量表对被试者进行打分并对相应数据进行标注;
S4、选择合适的特征:根据判别模型和分级模型选择合适的特征;
S5、选择合适的机器学习分类模型;机器学习分类模型包括判别模型和分级模型,且判别模型和分级模型的步骤相同;
S6、模型训练:模型训练包括具体以下步骤,其中判别模型和分级模型步骤相同:根据之前选定的被试归一化后的多维步态数据、不同任务下医生的标注结果、合适的特征、模型构建的算法进行模型训练和参数调优;采用交叉验证的方法进行调优参数的选择。最终我们可以得到训练后的模型A
优选的,数据归一化处理的公式为:
其中,x为被试者的时间参数特征与空间参数特征,表示最初的数据的值,x’为归一化处理后的多维步态数据,表示缩放后的值,x
优选的,NIHSS量表由11项评价指标组成,其中,每项的评分范围为0-4分,得0分表示此项评价指标功能正常,分值越高则表示功能越差,经过11项评价指标全部评价结束后,会生成NHISS总分,对于判别任务,医生要标注被试是否患有脑卒中;对于分级任务,医生要标注被试的脑卒中严重程度。
优选的,根据判别模型和分级模型选择合适的特征,其步骤相同,且包括以下步骤:
1)对于每个被试者的归一化后的多维步态数据,分别将其中单个特征与不同任务时医生的标注结果进行随机分组输入M
2)分别从每个特征重要程度综合排序中选择排名靠前的N个特征,通过交叉验证的方法,分别用M
3)选择i个不同的N(N=N
优选的,选择合适的机器学习分类模型其具体步骤如下:通过交叉验证的方法来选择模型的分类算法,具体是选择常见的M
与现有技术相比,本发明的有益效果是:本发明针对之前提出的脚步检测算法和步态特征(参数)计算的方法,提出了一种基于多维步态参数的脑卒中关联量化评估方法。该方法是基于机器学习的方法,训练出一个模型,进而进行步态分析。即通过已有的全部步态特征(步态参数),选择合适的步态特征(步态参数),经过临床医生的NHISS量表对脑卒中患者的标定,经过机器学习的算法,最终训练出一种可以对是否为脑卒中患者的判别模型(判别模型)和对脑卒中严重程度分级评估的模型(分级模型)。
本发明提出的基于多维步态参数的脑卒中关联量化评估方法具有较高的准确率,有望用于临床中对脑卒中后复发的预警和康复监测及评估,以辅助医生。
附图说明
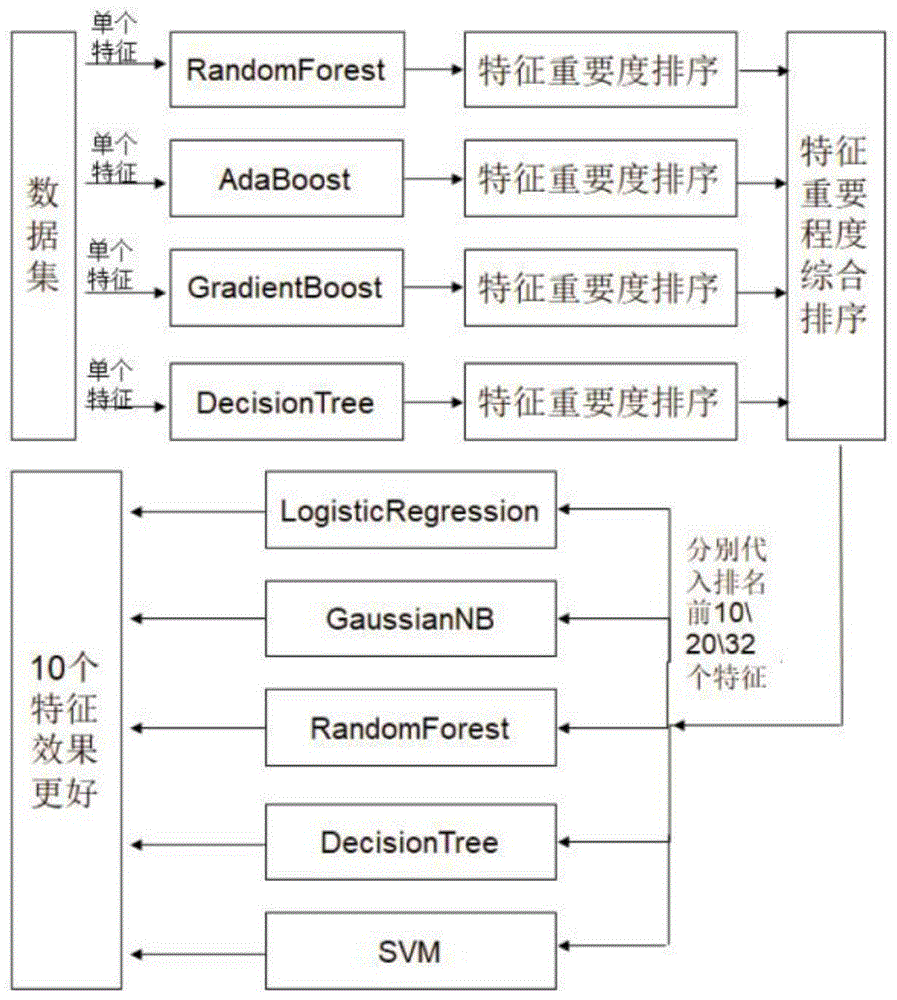
图1为本发明中选择合适的特征的步骤和流程;
图2为本发明判别模型中通过random forest、AdaBoost、GradientBoosting、DecisionTree算法选出的特征重要程度可视化排序,其中横坐标为特征相对重要度;
图3为本发明中分级模型中通过random forest、AdaBoost、GradientBoosting、DecisionTree算法选出的特征重要程度可视化排序,其中横坐标为特征相对重要度。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本部分通过北京朝阳医院(西院)神经内科采集了226例数据(包含正常健康人和脑卒中患者),对本文构建的模型分别做了实验以验证模型的有效性。实验分为两部分,第一部分(接下来称为实验一)是验证判别模型,即对正常健康人与脑卒中患者之间的判别,第二部分(接下来称为实验二)是验证分级模型,即对脑卒中患者中卒中轻重的判别。
S1、收集被试者的多维步态参数数据
本实验数据是在首都医科大学附属北京朝阳医院采集的226例数据,在实验开始之前,向受试者解释实验过程及注意事项,参加实验的受试者的详细情况如下表1(表1为实验数据信息)所示,此数据作为本专利实验一的数据集;
本专利中的步态特征采用基于可穿戴异构传感器信号融合的高精度脚步检测和提取算法和临床可信的多策略信息融合的步态参数计算方法,共计算出32个步态特征参数,按照参数类别,分类如下:
时间参数特征(8个):左摆动时间(left swing phase)、右摆动时间(right swingphase)、左支撑时间(left stance phase)、右支撑时间(right stance phase)、左单足时间(left time)、右单足时间(right time)、左双足时间(left double time)、右双足时间(right double time)。
空间参数特征(24个):左步幅(left stride)、右步幅(right stride)、左步频(left step frequency)、右步频(right step frequency)、左步速(left step speed)、右步速(right step speed)、左足偏角(left foot rotation)、右足偏角(right footrotation)、左离地角度(left off ground angle)、右离地角度(right off groundangle)、左着地角度(left ground angle)、右着地角度(right ground angle)、左矢状面最小角度(left sagittal min angle)、右矢状面最小角度(right sagittal min angle)、左矢状面最大角度(left sagittal max angle)、右矢状面最大角度(right sagittal maxangle)、左冠状面最小角度(left coronal min angle)、右冠状面最小角度(rightcoronal min angle)、左冠状面最大角度(left coronal max angle)、右冠状面最大角度(right coronal max angle)、左横断面最小角度(left cross min angle)、右横断面最小角度(right cross min angle)、左横断面最大角度(left cross max angle)、右横断面最大角度(right cross max angle)(角度参数的计算都是基于已有的惯性传感器的角度计算方法)。
S2、数据归一化处理
将S1中获取的数据,每个特征分别用归一化公式进行转换。
S3、NIHSS量表打分和标注
在表1中,39例脑卒中患者中有32例由临床医生用NIHSS量表做了评分和标定,标定的患者的分值分布在1-5分之间,即均为非严重卒中的患者,具体为下表2(表2为脑卒中患者NIHSS评分值)所示;测试时,要求患者沿着直线在平整的地面上行走,根据患者的实际情况,尽量让患者多走几次,也即不同的患者行走的次数不同,每次行走过程约涵盖2-50步;
在本专利中,我们将每名患者每次行走中每步的参数计算出来,构成本实验二的数据集,32个患者总步数为515步;考虑到样本的对称性,我们将NIHSS分值为1分的叫做卒中较轻患者,NIHSS分值在2-5分的患者归为一类叫做卒中轻度患者。实验二的具体实验数据为如表3(表3为脑卒中患者轻重判别实验数据集)所示;
S4、选择合适的特征
利用Random forest、AdaBoost、GradientBoosting、DecisionTree算法对特征进行筛选,选出最重要的N个特征。这种方法的思路是直接使用机器学习模型挑选特征,针对每个单独的特征和响应变量建议预测模型,运用交叉验证对模型进行挑选,具体步骤及流程如图1所示;
首先,通过random forest、AdaBoost、GradientBoosting、DecisionTree算法,学习被归一化后的多维步态数据中的单个特征,选出的特征重要程度的排序,取平均后获得特征重要程度综合排序。
其次,考虑到数据集中总共有32个特征参数,为了避免特征选择过多和过少带来的过拟合和欠拟合带来的问题,我们分别从按照各个重要性的排序中选择排名靠前的10个特征、20个特征和32个特征(全部特征),分别用LogisticRegression、GaussianNB、DecisionTree、RandomForest、SVM算法做交叉验证,得出它们的准确率。然后分别对比各个算法的情况下,10个特征、20个特征和32个特征(全部特征)的准确率的大小,进而综合判断最终分类器选择的特征数量。
判别模型:根据以上特征选择算法,首先选出10个特征、20个特征和32个特征分别用5种常见算法做交叉验证,得出它们对应的准确率如表4(表4为特征选择性能对比表)所示。由此表可知,选出10个特征时,分类器分类效果更好且计算量较小。图2为通过randomforest、AdaBoost、GradientBoosting、DecisionTree算法选出的特征重要程度可视化排序(横坐标为特征相对重要度)。这样的话,我们最终选择的10个特征即组成一个特征向量:右步速(right step speed)、左步速(left step speed)、右离地角度(right off groundangle)、左离地角度(left off ground angle)、右矢状面最小角度(right sagittal minangle)、左矢状面最小角度(left sagittal min angle)、右步幅(right stride)、左步幅(left stride)、右矢状面最大角度(right sagittal max angle)、左矢状面最大角度(left sagittal max angle);
分级模型:根据特征选择算法,首先选出10个特征、20个特征和32个特征分别用5种常见算法做交叉验证,得出它们对应的准确率如下表5(表5特征选择性能对比表)所示。由此表可知,选出10个特征时,分类器分类效果更好且计算量较小;
图3为通过random forest、AdaBoost、GradientBoosting、DecisionTree算法选出的特征重要程度可视化排序(横坐标为特征相对重要度)。这样的话,我们最终选出的10个特征即组成一个特征向量:健侧着地角度(healthy side ground angle)、患侧着地角度(affected side ground angle)、健侧离地角度(healthy side off ground angle)、患侧离地角度(affected side off gound angle)、健侧横断面最大角度(healthy side crossmax angle)、患侧横断面最大角度(affected side cross max angle)、健侧步幅(healthyside stride)、患侧双足时间(affected double time)、健侧矢状面最大角度(healthyside sagittal max angle)、患侧矢状面最大角度(affected side sagittal maxangle)。
S5、选择合适的机器学习分类模型
确定了模型训练的特征后,需要选择一个分类的算法。我们通过交叉验证的方法来选择模型的分类算法,具体是选择常见的9种分类算法,分别计算各分类算法的性能指标。每种算法进行5次交叉验证计算,计算5次的预测准确率,并由此得出该算法的预测准确率(5次的平均值),对此操作执行30次,找出峰值高的分类算法。分别对比各个算法的情况下,取得的对应准确率峰值的大小,最终选出准确率峰值较高的算法作为我们模型构建的算法。
判别模型:根据分类算法选择的确定方法,各算法及峰值如下表6(表6为判别模型的算法选择实验性能对比表)所示:
通过比较,选出以下3个算法进行分类器建模:KNN、SVM和RandomForest。
分级模型:根据分类算法选择的确定方法,各算法及峰值如下表7(表7为分级模型的算法选择实验性能对比表)所示:
通过比较,选出以下3个算法进行分类器建模:SVM、RandomForest和AdaBoost。
S6、模型训练
模型训练就是要构建一个分类器,即是根据之前选定的数据集、特征、算法进行模型训练和参数调优的过程,其输出即为构建的模型。本专利采用5折交叉验证的方法来进行参数调优选择。它的基本思想就是将原始数据集中的训练集进行分组,一部分作为训练集来训练模型,另一部分作为测试集来评价模型(即验证集)。
判别模型:如表1所示,我们选择了156名患者及正常人作为训练集来构建判别模型,针对三种不同的算法,其得到的相关参数是:KNN的参数n_neighbors=6,SVM参数C=2.1、max_iter=21、kernel=Poly,RandomForest参数n_estimators=9。
分级模型:如表3所示,我们选择了32名患者共515步作为我们的总样本,其中训练集由25名患者共457步组成,用来构建分级模型,针对三种不同的算法,其得到的相关参数是:Adaboost的参数n_estimators=7、learning_rate=1.8,SVM参数C=0.1、max_iter=7、kernel=Poly,RandomForest参数n_estimators=52。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。