原发性胆汁性胆管炎临床检验数据分析方法和装置
文献发布时间:2023-06-19 19:28:50
技术领域
本发明实施例涉及临床数据处理技术领域,尤其涉及原发性胆汁性胆管炎临床检验数据分析方法和装置。
背景技术
原发性胆汁性胆管炎(primary biliary cholangitis,PBC)是一种原因不明的自身免疫性肝脏疾病。PBC发病人群主要是中老年女性,且发病不受地区和种族限制。在对PBC患者进行临床检验中相关指标项数值会出现异常,例如,血清碱性磷酸酶(ALP)升高、天门冬氨酸转氨酶(AST)和丙氨酸转氨酶(ALT)升高、血清免疫球蛋白升高,主要是免疫球蛋白M(ImmunoglobulinM,IgM)升高和血清抗线粒体抗体(antimitochondrial antibodies,AMAs)阳性等。其中,AMAs是PBC血清学诊断的标志性抗体,而且可通过间接免疫荧光法在血清中检测到抗核抗体(antinuclear antibody,ANA),这些临床数据可能会具有诊断和预后价值。若能够确定PBC患者病情及预后的多样性,准确预测或评估PBC患者预后对于临床进一步的治疗随访具有重要意义。然而,目前除了PBC临床分期及病理分期外,尚没有一种简便有效的方法可以对PBC患者进行临床特征的区分及准确判断预后。
发明内容
本发明提供了一种原发性胆汁性胆管炎临床检验数据分析方法、装置、设备和介质,可以实现对PBC患者临床数据的充分挖掘与分析,为PBC患者的临床表现分类及预后判断提供数据支撑。
根据本发明的一方面,提供了一种原发性胆汁性胆管炎临床检验数据分析方法,该方法包括:
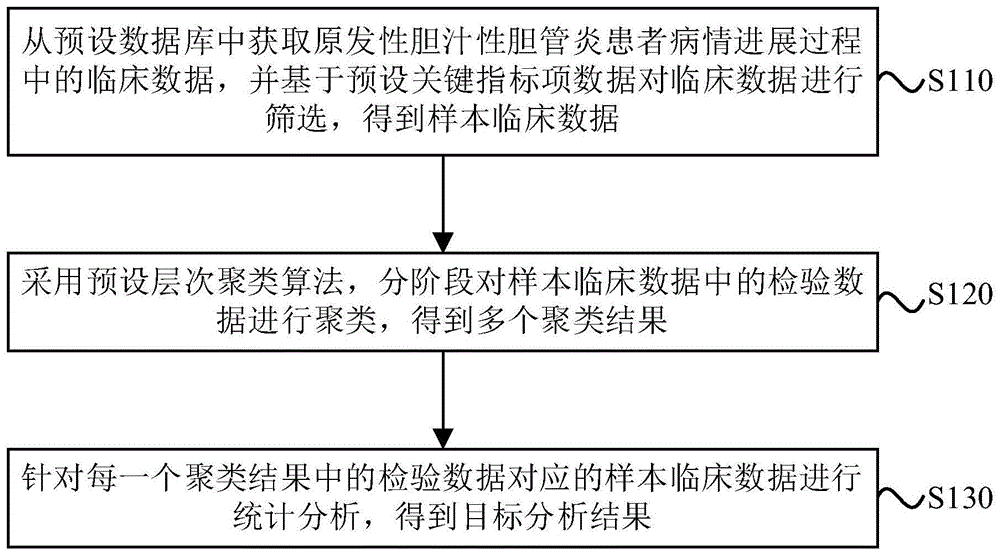
从预设数据库中获取原发性胆汁性胆管炎患者病情进展过程中的临床数据,并基于预设关键指标项数据对临床数据进行筛选,得到样本临床数据;
采用预设层次聚类算法,分阶段对样本临床数据中的检验数据进行聚类,得到多个聚类结果;
针对每一个聚类结果中的检验数据对应的样本临床数据进行统计分析,得到目标分析结果。
根据本发明的另一方面,提供了一种原发性胆汁性胆管炎临床检验数据分析装置,该装置包括:
样本数据获取模块,用于从预设数据库中获取原发性胆汁性胆管炎患者病情进展过程中的临床数据,并基于预设关键指标项数据对临床数据进行筛选,得到样本临床数据;
样本数据聚类模块,用于采用预设层次聚类算法,分阶段对样本临床数据中的检验数据进行聚类,得到多个聚类结果;
样本数据分析模块,用于针对每一个聚类结果中的检验数据对应的样本临床数据进行统计分析,得到目标分析结果。
根据本发明的另一方面,提供了一种电子设备,该电子设备包括:
至少一个处理器;以及
与至少一个处理器通信连接的存储器;其中,
存储器存储有可被至少一个处理器执行的计算机程序,计算机程序被至少一个处理器执行,以使至少一个处理器能够执行本发明任一实施例的原发性胆汁性胆管炎临床检验数据分析方法。
根据本发明的另一方面,提供了一种计算机可读存储介质,该计算机可读存储介质存储有计算机指令,计算机指令用于使处理器执行时实现本发明任一实施例的原发性胆汁性胆管炎临床检验数据分析方法。
本发明实施例的技术方案,通过从预设数据库中获取PBC患者病情进展过程中的临床数据,并基于预设关键指标项数据对临床数据进行筛选,得到样本临床数据;采用预设层次聚类算法,分阶段对样本临床数据中的检验数据进行聚类,得到多个聚类结果;针对每一个聚类结果中的检验数据对应的样本临床数据进行统计分析,得到目标分析结果。本发明实施例的技术方案,解决了对PBC患者临床数据分析应用较少且不够深入的问题,可以实现对PBC患者临床数据的充分挖掘与分析,为PBC患者的临床表现分类及预后判断提供数据支撑。
应当理解,本部分所描述的内容并非旨在标识本发明的实施例的关键或重要特征,也不用于限制本发明的范围。本发明的其它特征将通过以下的说明书而变得容易理解。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明实施例提供的一种原发性胆汁性胆管炎临床检验数据分析方法的流程图;
图2是本发明实施例提供的另一种原发性胆汁性胆管炎临床检验数据分析方法的流程图;
图3是本发明实施例提供的又一种原发性胆汁性胆管炎临床检验数据分析方法的流程图;
图4是本发明实施例提供的一种具体的原发性胆汁性胆管炎临床检验数据分析方法的流程图;
图5是本发明实施例提供的一种具体的原发性胆汁性胆管炎临床数据统计分析方法的示意图;
图6是本发明实施例提供的一种原发性胆汁性胆管炎临床检验数据分析装置的结构框图;
图7是本发明实施例提供的一种电子设备的结构框图。
具体实施方式
为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分的实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
需要说明的是,本发明的说明书和权利要求书及上述附图中的术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
本发明实施例的技术方案中,所涉及的用户个人信息的采集、收集、更新、分析、处理、使用、传输、存储等方面,均符合相关法律法规的规定,被用于合法的用途,且不违背公序良俗。对用户个人信息采取必要措施,防止对用户个人信息数据的非法访问,维护用户个人信息安全、网络安全和国家安全。
图1是本发明实施例提供的一种原发性胆汁性胆管炎临床检验数据分析方法的流程图,本实施例可适用于PBC临床检验数据分析的场景中,更适用于基于临床数据和病情进展实现PBC临床检验数据分析的情况。该方法可以由原发性胆汁性胆管炎临床检验数据分析装置来执行,该原发性胆汁性胆管炎临床检验数据分析装置可以采用硬件和/或软件的形式实现,也可以配置于电子设备中。
如图1所示,原发性胆汁性胆管炎临床检验数据分析方法包括以下步骤:
S110、从预设数据库中获取原发性胆汁性胆管炎患者病情进展过程中的临床数据,并基于预设关键指标项数据对临床数据进行筛选,得到样本临床数据。
其中,预设数据库用于存储在医疗活动各阶段产生的数据。预设数据库可以与医院信息系统(Hospital Information System,HIS)和/或实验室(检验科)信息系统(Laboratory Information System,LIS)关联,对在医疗活动各阶段产生的数据进行采集、存储、处理、提取、传输和汇总等操作,从而为医院的整体运行提供全面的自动化管理及各种服务。临床数据包括临床症状描述数据、患者特征属性数据以及检验数据。
检验数据包括PBC患者各病程进展过程中临床检验结果,例如,可以是自身抗体等的检验结果。自身抗体是针对自身组织,器官、细胞及细胞成分的抗体,PBC相关的自身抗体包括ANA、AMA和/或AMA-M2、ACA和/或抗CENP-B抗体、抗gp210抗体、抗sp100抗体、抗Ro52抗体、抗SSA抗体、抗SSB抗体等。自身抗体的检测结果包括定性结果(阳性或阴性)和由抗体滴度或浓度换算的半定量或定量数值。
其中,预设关键指标项包括对PBC诊断和预后有关联的多个预设类别的抗核抗体。具体的,预设关键指标项为抗核抗体(ANA)、抗线粒体抗体(AMA)和/或抗AMA-M2抗体、抗着丝点抗体(Anti-centromere antibody,ACA)和/或抗着点蛋白B(Centromere protein B,CENP-B)抗体、抗Ro52抗体、抗SSA抗体、抗SSB抗体(抗单核抗体)、抗Smith(Sm)抗体、抗核糖核蛋白(nuclearribonucleoprotein,nRNP)抗体、抗双链DNA(dsDNA)抗体、抗核糖体P蛋白(Rib)抗体、抗组蛋白(His)抗体、抗Nuk抗体、抗Scl-70抗体)、抗Jol抗体、抗gp210抗体、抗sp100抗体、抗可溶性肝抗原(SLA)抗体、抗肝肾微粒体1型抗体(LKM-1)抗体和抗肝细胞胞质1型(Lc1)抗体,共计19种自身抗体。抗核抗体是以真核细胞的各种成分为靶抗原的自身抗体的总称,是通过间接免疫荧光法检测到的总ANA。ANA有多种靶抗原,每种靶抗原都与不同的自身抗体对应,形成抗核抗体谱。抗核抗体谱从属于抗核抗体总抗体,ANA阳性不代表现有抗核抗体谱中一定有阳性的抗体。ANA、AMA和ACA通过间接免疫荧光法检测,其余抗体通过免疫印迹法和酶联免疫吸附剂测定(enzyme linked immunosorbent assay,ELISA)法检测。
进一步的,基于预设关键指标项数据对临床数据进行筛选,得到样本临床数据,包括:在临床数据中,选取包含全部预设关键指标项且各预设关键指标项数据有效的数据,作为样本临床数据。
具体的,首先,从HIS和/或LIS中获取PBC患者各病情进展过程中的血常规、生物化学指标、病毒学标志物和自身抗体等的检验结果;然后,基于预设关键指标项数据,将临床数据中选取包含全部预设关键指标项且各预设关键指标项数据有效的数据,作为样本临床数据。
S120、采用预设层次聚类算法,分阶段对样本临床数据中的检验数据进行聚类,得到多个聚类结果。
其中,预设层次聚类算法为BIRCH两步聚类法。BIRCH两步聚类法是对BIRCH算法的改进,加入了自动确定簇数量的机制,用于多种属性数据集的聚类。通过计算不同类别数据点间的相似度来创建一棵有层次的嵌套聚类树,不同类别的原始数据点是树的最低层,树的顶层是一个聚类的根节点。
具体的,BIRCH两步聚类法分为两个阶段:
1、预聚类(pre-clustering)阶段。
具体的,逐个读取样本临床数据中的检验数据对应的数据点,在生成聚类特征树(Cluster Feature tree/CF tree)的同时,预先聚类密集区域的数据点,形成多个子簇(sub-cluster)。
2、聚类(pre-clustering)阶段。
根据预聚类阶段的结果,以子簇为对象,利用凝聚法(agglomerativehierarchical clustering method)合并子簇,直到达到目标簇数量。
具体的,首先,对样本临床数据进行分阶段,例如,可以按照样本临床数据间的距离、密度或连通性等对样本临床数据进行分阶段;然后将分阶段后的样本临床数据中的检验数据输入预设层次聚类算法进行聚类,得到对应阶段的检验数据的聚类结果。
S130、针对每一个聚类结果中的检验数据对应的样本临床数据进行统计分析,得到目标分析结果。
临床数据可以是与聚类结果中的样本检验数据相关的临床诊断结果,例如,可以是血常规、生物化学指标和病毒学标志物等临床数据。其中,生物化学指标包括总蛋白、白蛋白、球蛋白、白球比、总胆红素、转氨酶、直接和间接胆红素等肝功能指标,以及总胆固醇、甘油三酯、高密度脂蛋白、载脂蛋白、空腹血糖、肾功能、尿酸、乳酸脱氢酶和肌酸肌酶等血脂指标;病毒学标志物包括甲肝抗体、乙肝五项、丙肝抗体和戊肝抗体等指标。
统计分析是包括运用数学方式,建立数学模型,对数据进行数理统计和分析。统计分析方法包括:频率分析、数据探索、交叉表分析、表分析、卡方检验、T检验、方差分析、回归分析和因子分析等方法。
具体的,根据聚类结果中的检验数据对应的样本临床数据的特征,选取一种或多种统计分析方法,运用数学方式,建立数学模型,对上述数据进行数理统计和分析,得到目标分析结果,可以将临床数据和疾病特征等结合,更好的反映检验数据和临床数据之间的关系。
本发明实施例的技术方案,通过从预设数据库中获取PBC患者病情进展过程中的临床数据,并基于预设关键指标项数据对临床数据进行筛选,得到样本临床数据;采用预设层次聚类算法,分阶段对样本临床数据中的检验数据进行聚类,得到多个聚类结果;针对每一个聚类结果中的检验数据对应的样本临床数据进行统计分析,得到目标分析结果。本发明实施例的技术方案,对PBC患者临床检验数据进行充分的挖掘与分析,将有助于人们了解PBC疾病特征及异质性,从而有助于临床医生在综合分析临床检验结果的基础上快速识别患者的疾病特征,为疾病的诊断、分型、治疗和预后判断提供决策依据。
图2是本发明实施例提供的另一种原发性胆汁性胆管炎临床检验数据分析方法的流程图,本实施例与上述实施例中的原发性胆汁性胆管炎临床检验数据分析方法属于同一个发明构思,在上述实施例的基础上进一步的描述了采用预设层次聚类算法,分阶段对样本临床数据中的检验数据进行聚类,得到多个聚类结果的过程。该方法可以由原发性胆汁性胆管炎临床检验数据分析装置执行,该装置可以由软件和/或硬件的方式来实现,集成于具有应用开发功能的电子设备中。
如图2所示,原发性胆汁性胆管炎临床检验数据分析方法包括以下步骤:
S210、从预设数据库中获取PBC患者病情进展过程中的临床数据,并基于预设关键指标项数据对临床数据进行筛选,得到样本临床数据。
S220、采用各检验数据间的对数似然距离对样本临床数据进行预分组,得到相应的预分组结果。
假设将样本临床数据分为多个簇,其中一个簇中包括有两类检验数据,该两类检验数据间的对数似然距离的计算包括:首先,分别计算该两类检验数据合并之前的对数似然估计与合并后的对数似然估计;然后,计算合并前与合并后的对数似然估计的差,即为该两类检验数据间的对数似然距离。
具体的,计算样本临床数据中两两检验数据间的对数似然距离,基于对数似然距离对样本临床数据进行预分组,得到预分组结果。
S230、基于预分组结果,进行平衡迭代聚类得到多个聚类结果。
其中,平衡迭代聚类(Balanced Iterative Reducing and Clustering usingHierarchies,BIRCH)也叫利用层次方法的平衡迭代规约和聚类,只需扫描待进行聚类的数据集就可以进行聚类。在扫描数据集后建立一棵存放于内存中的CF tree,可以看作是数据的多层压缩。CF Tree仅存储了CF节点和对应的指针,所有的样本都在磁盘上,可以节约内存。其中,聚类特征树的每个节点都有聚类特征,包括叶子节点也有聚类特征,每一个聚类特征是一个三元组,可以用(N,LS,SS)表示。其中N代表了这个聚类特征中拥有的样本数据的数量;LS是这个聚类特征中拥有的样本数据的各个特征属性值的和;SS代表了这个聚类特征中拥有的样本数据各特征维度的平方和。聚类特征树的建立包括以下步骤:
1、定义CF Tree的参数。
具体的,定义内部节点的最大CF数B、叶子节点的最大CF数L和叶节点每个CF的最大样本半径阈值T。
2、建立CF Tree。
具体的,从预分组结果读入第一个样本临床数据,将其放入一个新的CF三元组A,这个三元组的N=1,将这个新的CF放入根节点;继续读入第二个样本临床数据,发现第二个样本临床数据和第一个样本临床数据A,在半径为T的超球体范围内,也就是说,第二个样本临床数据和第一个样本临床数据属于一个CF,我们将第二个点也加入CF三元组A,此时需要更新A的三元组的值,A的三元组中N=2;此时来了第三个节点,但是这个节点不能融入刚才前面的节点形成的超球体内,也就是说,需要一个新的CF三元组B,来容纳这个新的值,此时根节点有两个CF三元组A和B。
3、遍历预分组结果对应的样本临床数据建立CF Tree。
BIRCH算法的流程:
1、将所有的预分组结果样本临床数据依次读入,在内存中建立一颗CF Tree。
2、CF tree预处理。
具体的,设置样本数阈值,去除样本临床数据的数目小于样本数阈值的树节点;设置样本合并阈值,合并超球体距离小于样本合并阈值的元组。
3、利用聚类算法对所有的CF元组进行聚类。这样做的好处是,可以消除由于样本临床数据读入顺序导致的不合理的树结构,以及一些由于节点CF个数限制导致的树结构分裂。
4、利用3生成的CF Tree的所有CF节点的质心,作为初始质心点,对所有的样本点按距离远近进行聚类,得到聚类结果。
该方法还包括以下步骤:
S240、采用预设聚类结果评价算法对多个聚类结果进行评价,得到聚类评价结果。
聚类结果评价算法用于对聚类结果进行评价,测定聚类结果的质量。聚类结果的评价算法可以分为内部评价(internal evaluation)算法和外部评价(externalevaluation)算法。其中,外部评价算法用于在已知真实标签(ground truth)的情况下评估聚类结果,例如,通过纯度(Purity)、兰德系数(Rand Index,RI)、F值(F-score)和调整兰德系数(Adjusted Rand Index,ARI)等进行评估。内部评价算法是用于完全没有标记数据,只根据聚类结果来进行评估,例如,利用轮廓系数(Silhouette Coefficient)和Calinski-Harabasz指数(Calinski-Harabasz Index)等进行评估。
可选的,基于轮廓系数进行聚类结果评估包括:计算样本点的轮廓系数检测值S(i)。具体的,通过公式(1)计算第i个样本的对应的轮廓系数检测值S(i),假设聚类结果中,包含N个簇,其中,a(i)是第i个样本点到该样本点对应的簇内其他样本点的平均距离,b(i)是第i个样本点到其他(N-1)个簇的平均距离,样本点到簇的距离通过第i个样本点到该簇中所有样本点的平均距离,将样本点的轮廓系数检测值S(i)作为聚类评价结果。
S250、根据聚类评价结果对多个聚类结果进行修正,得到最终聚类结果。
可选的,设置评估阈值,对聚类结果进行修正。若S(i)大于评估阈值,表示该聚类结果中存在该簇;若S(i)不大于评估阈值,表示该簇不存在。将S(i)大于评估阈值的聚类结果作为最终聚类结果。
S260、针对每一个聚类结果中的检验数据对应的样本临床数据进行统计分析,得到目标分析结果。
本发明实施例的技术方案,通过从预设数据库中获取PBC患者病情进展过程中的临床数据,并基于预设关键指标项数据对临床数据进行筛选,得到样本临床数据;采用各检验数据间的对数似然距离对样本临床数据进行预分组,得到相应的预分组结果;基于预分组结果,进行平衡迭代聚类得到多个聚类结果;采用预设聚类结果评价算法对多个聚类结果进行评价,得到聚类评价结果;根据聚类评价结果对多个聚类结果进行修正,得到最终聚类结果;针对每一个聚类结果中的检验数据对应的样本临床数据进行统计分析,得到目标分析结果。本发明实施例的技术方案,通过对聚类结果进行评价,并根据聚类评价结果对聚类结果进行修正,解决了对PBC患者临床数据分析应用较少且不够深入的问题,可以实现对PBC患者的临床数据进行充分的挖掘与分析,为PBC患者的临床表现分类及预后判断的提供数据支撑。
图3是本发明实施例提供的又一种原发性胆汁性胆管炎临床检验数据分析方法的流程图,本实施例与上述实施例中的PBC临床检验数据分析方法属于同一个发明构思,在上述实施例的基础上进一步的描述了针对每一个聚类结果中的检验数据对应的样本临床数据进行统计分析的过程。该方法可以由原发性胆汁性胆管炎临床检验数据分析装置执行,该装置可以由软件和/或硬件的方式来实现,集成于具有应用开发功能的电子设备中。
如图3所示,原发性胆汁性胆管炎临床检验数据分析方法包括以下步骤:
S310、从预设数据库中获取PBC患者病情进展过程中的临床数据,并基于预设关键指标项数据对临床数据进行筛选,得到样本临床数据。
S320、采用预设层次聚类算法,分阶段对样本临床数据中的检验数据进行聚类,得到多个聚类结果。
S330、针对每一个聚类结果中的检验数据对应的样本临床数据,进行性别分布、年龄分布、临床特征、合并症、阳性抗体类别和临床终点事件中至少一个统计项进行统计分析,得到目标统计结果。
合并症是与原发疾病同时存在且相互独立的一种或多种疾病或临床状态。PBC可能并发腹水、形成门静脉高压症以及肝功能衰竭,晚期可能出现肝功能衰竭和肝硬化的相关症状等其他合并症,还可能并发肝癌。此外,PBC的合并症可能包括一种或多种的自身免疫性疾病,例如,干燥综合征、甲状腺炎、类风湿关节炎、系统性硬化病和系统性红斑狼疮等。
临床终点事件主要是指肝病相关死亡和肝硬化失代偿(腹水、上消化道出血和/或肝性脑病)、肝癌、肝移植或肝病相关死亡等。
可以理解的是,由于PBC相关临床数据的数据量大,需要通过对样本临床数据进行统计分析,达到估计总体的目的,更直观的显示出上述统计项对PBC的影响。
进一步的,该方法还包括以下步骤:
S340、获取待分析PBC临床数据。
S350、根据各聚类结果对应的目标分析结果,确定待分析PBC临床数据对应的分类结果和预后特征。
具体的,首先,获取待分析PBC临床数据;然后,根据各聚类结果与目标分析结果的对应关系,确定待分析PBC临床数据对应的分类结果;同时,根据目标统计结果中各聚类结果对应的预后特征,确定待分析PBC临床数据的预后特征。
在一个具体的实施例中,图4是本发明实施例提供的一种具体的原发性胆汁性胆管炎临床检验数据分析方法的流程图,如图4所示,该原发性胆汁性胆管炎检验临床数据分析方法包括以下步骤:
S410、获取PBC患者的临床数据。
具体的,从医院医疗信息系统(HIS系统及LIS系统)中提取PBC患者的临床资料,建立回顾性研究队列,同时记录基线及随访数据,包括出院诊断、人口统计学数据、病史、体格检查结果、合并症和实验室检测结果(包括血常规、生物化学指标、病毒学标志物和自身抗体结果)等数据。。
S420、基于临床数据的自身抗体类型确定样本临床数据。
将临床数据中包含19种自身抗体检测且数据完整的PBC患者的临床数据作为样本临床数据,得到样本量为537的样本临床数据。
S430、采用对数似然距离对样本临床数据进行预分组,得到预分组结果。
为了减少所有可能性聚类之间的距离,对19种自身抗体进行预分组。具体的,计算样本点的轮廓系数检测值S(i),保留S(i)>0.5的聚类结果,作为预分组结果。
S440、基于预分组结果,通过BIRCH算法对样本临床数据进行聚类分析,得到多个聚类结果。
采用BIRCH两步聚类算法对样本量为537的样本临床数据进行聚类分析,将相应自身抗体结果转化为二分类变量阴性和阳性进行聚类分析,得到五个聚类结果(参考图5)。其中,聚类1对应的样本量为107,聚类2对应的样本量为120,聚类3对应的样本量为125,聚类4对应的样本量为101,聚类5对应的样本量为84;同时,根据聚类结果生成对应的编号,用于表示样本临床数据对应的聚类类型和其对应的患者。
S450、对每个聚类结果中的检验数据对应的样本临床数据进行统计分析,得到目标分析结果。
对五个聚类中的检验数据对应的样本临床数据的基线人口统计学、临床症状体征、合并症、实验室检测指标、随访及临床终点事件进行比较,对不同聚类进行生存分析比较,对不同自身抗体聚类的临床特征进行描述,得到各聚类对应的目标分析结果(参考图5)。
S460、根据各聚类结果对应的目标分析结果,确定待分析PBC临床数据对应的分类结果和预后特征。
具体的,根据五个聚类对应的目标分析结果,确定待分析PBC临床数据对应的分类结果和预后特征(参考图5)。
本发明实施例的技术方案,通过从预设数据库中获取PBC患者病情进展过程中的临床数据,并基于预设关键指标项数据对临床数据进行筛选,得到样本临床数据;采用预设层次聚类算法,分阶段对样本临床数据中的检验数据进行聚类,得到多个聚类结果;针对每一个聚类结果中的检验数据对应的样本临床数据,进行性别分布、年龄分布、临床特征、合并症、阳性抗体类别和临床终点事件中至少一个统计项进行统计分析,得到目标统计结果;获取待分析PBC临床数据;根据各聚类结果对应的目标分析结果,确定待分析PBC临床数据对应的分类结果和预后特征。本发明实施例的技术方案,基于聚类结果对样本临床数据和临床数据进行统计分析,可以直接得到待分析PBC临床检验数据的分类结果和预后特征,解决了对PBC患者临床数据分析应用较少且不够深入的问题,可以实现对PBC患者临床数据的充分挖掘与分析,为PBC患者的临床表现分类及预后判断提供数据支撑。
图6是本发明实施例提供的一种原发性胆汁性胆管炎临床检验数据分析装置的结构框图,本实施例可适用于PBC临床检验数据分析的场景中,更适用于基于临床数据和病情进展实现PBC临床检验数据分析的情况。该装置可以采用硬件和/或软件的形式实现,集成于具有应用开发功能的计算机设备中。
如图6所示,该原发性胆汁性胆管炎临床检验数据分析装置包括:样本数据获取模块601、样本数据聚类模块602和样本数据分析模块603。
其中,样本数据获取模块601用于从预设数据库中获取PBC患者病情进展过程中的临床数据,并基于预设关键指标项数据对临床数据进行筛选,得到样本临床数据;样本数据聚类模块602用于采用预设层次聚类算法,分阶段对样本临床数据中的检验数据进行聚类,得到多个聚类结果;样本数据分析模块603用于针对每一个聚类结果中的检验数据对应的样本临床数据进行统计分析,得到目标分析结果。
本发明实施例的技术方案,通过从预设数据库中获取PBC患者病情进展过程中的临床数据,并基于预设关键指标项数据对临床数据进行筛选,得到样本临床数据;采用预设层次聚类算法,分阶段对样本临床数据中的检验数据进行聚类,得到多个聚类结果;针对每一个聚类结果中的检验数据对应的样本临床数据进行统计分析,得到目标分析结果。本发明实施例的技术方案,解决了对PBC患者临床数据分析应用较少且不够深入的问题,可以实现对PBC患者临床数据的充分挖掘与分析,为PBC患者的临床表现分类及预后判断提供数据支撑。
可选的,样本数据获取模块601用于:在临床数据中,选取包含全部预设关键指标项且各预设关键指标项数据有效的数据,作为样本临床数据。
可选的,样本数据聚类模块602用于:
采用各样本检验数据间的对数似然距离对样本临床数据进行预分组,得到相应的预分组结果;
基于预分组结果,进行平衡迭代聚类得到多个聚类结果。
可选的,样本数据聚类模块602用于:
采用预设聚类结果评价算法对多个聚类结果进行评价,得到聚类评价结果;
根据聚类评价结果对多个聚类结果进行修正,得到最终聚类结果。
可选的,样本数据分析模块603还用于:针对每一个聚类结果中的检验数据对应的样本临床数据,进行性别分布、年龄分布、临床特征、合并症、阳性抗体类别和临床终点事件中至少一个统计项进行统计分析。
可选的,该装置还包括临床检验数据分析模块,用于:
获取待分析PBC临床数据;
根据各聚类结果对应的目标分析结果,确定待分析PBC临床数据对应的分类结果和预后特征。
本发明实施例所提供的PBC临床检验数据分析装置可执行本发明任一实施例所提供的PBC临床检验数据分析方法,具备执行方法相应的功能模块和有益效果。
图7是本发明的实施例提供的一种电子设备的结构框图。电子设备10旨在表示各种形式的数字计算机,诸如,膝上型计算机、台式计算机、工作台、个人数字助理、服务器、刀片式服务器、大型计算机或其它适合的计算机。电子设备还可以表示各种形式的移动装置,诸如,个人数字处理、蜂窝电话、智能电话、可穿戴设备(如头盔、眼镜、手表等)或其它类似的计算装置。本文所示的部件、它们的连接关系以及它们的功能仅仅作为示例,并且不意在限制本文中描述的和/或者要求的本发明的实现。
如图7所示,电子设备10包括至少一个处理器11,以及与至少一个处理器11通信连接的存储器,如只读存储器(ROM)12、随机访问存储器(RAM)13等,其中,存储器存储有可被至少一个处理器执行的计算机程序,处理器11可以根据存储在只读存储器(ROM)12中的计算机程序或者从存储单元18加载到随机访问存储器(RAM)13中的计算机程序,来执行各种适当的动作和处理。在RAM 13中,还可存储电子设备10操作所需的各种程序和数据。处理器11、ROM 12以及RAM 13通过总线14彼此相连。输入/输出(I/O)接口15也连接至总线14。
电子设备10中的多个部件连接至I/O接口15,包括:输入单元16,例如键盘或鼠标等;输出单元17,例如各种类型的显示器或扬声器等;存储单元18,例如磁盘或光盘等;以及通信单元19,例如网卡、调制解调器或无线通信收发机等。通信单元19允许电子设备10通过诸如因特网的计算机网络和/或各种电信网络与其他设备交换信息/数据。
处理器11可以是各种具有处理和计算能力的通用和/或专用处理组件。处理器11的一些示例包括但不限于中央处理单元(CPU)、图形处理单元(GPU)、各种专用的人工智能(AI)计算芯片、各种运行机器学习模型算法的处理器、数字信号处理器(DSP)、任何适当的处理器、控制器或微控制器等。处理器11执行上文所描述的各个方法和处理,例如PBC临床检验数据分析方法。
在一些实施例中,PBC临床检验数据分析方法可被实现为计算机程序,其被有形地包含于计算机可读存储介质,例如存储单元18。在一些实施例中,计算机程序的部分或者全部可以经由ROM 12和/或通信单元19而被载入和/或安装到电子设备10上。当计算机程序加载到RAM 13并由处理器11执行时,可以执行上文描述的PBC临床检验数据分析方法的一个或多个步骤。备选地,在其他实施例中,处理器11可以通过其他任何适当的方式(例如,借助于固件)而被配置为执行PBC临床检验数据分析方法。
本文中以上描述的系统和技术的各种实施方式可以在数字电子电路系统、集成电路系统、场可编程门阵列(FPGA)、专用集成电路(ASIC)、专用标准产品(ASSP)、芯片上系统的系统(SOC)、负载可编程逻辑设备(CPLD)、计算机硬件、固件、软件和/或它们的组合中实现。这些各种实施方式可以包括:实施在一个或者多个计算机程序中,该一个或者多个计算机程序可在包括至少一个可编程处理器的可编程系统上执行和/或解释,该可编程处理器可以是专用或者通用可编程处理器,可以从存储系统、至少一个输入装置和至少一个输出装置接收数据和指令,并且将数据和指令传输至该存储系统、该至少一个输入装置和该至少一个输出装置。
用于实施本发明的方法的计算机程序可以采用一个或多个编程语言的任何组合来编写。这些计算机程序可以提供给通用计算机、专用计算机或其他可编程数据处理装置的处理器,使得计算机程序当由处理器执行时使流程图和/或框图中所规定的功能/操作被实施。计算机程序可以完全在机器上执行或部分地在机器上执行,作为独立软件包部分地在机器上执行且部分地在远程机器上执行或完全在远程机器或服务器上执行。
在本发明的上下文中,计算机可读存储介质可以是有形的介质,其可以包含或存储以供指令执行系统、装置或设备使用或与指令执行系统、装置或设备结合地使用的计算机程序。计算机可读存储介质可以包括但不限于电子的、磁性的、光学的、电磁的、红外的或半导体系统、装置或设备,或者上述内容的任何合适组合。备选地,计算机可读存储介质可以是机器可读信号介质。机器可读存储介质的更具体示例会包括基于一个或多个线的电气连接、便携式计算机盘、硬盘、随机存取存储器(RAM)、只读存储器(ROM)、可擦除可编程只读存储器(EPROM或快闪存储器)、光纤、便捷式紧凑盘只读存储器(CD-ROM)、光学储存设备、磁储存设备或上述内容的任何合适组合。
为了提供与用户的交互,可以在电子设备上实施此处描述的系统和技术,该电子设备具有:用于向用户显示信息的显示装置(例如,CRT(Cathode Ray Tube,阴极射线管)或者LCD(Liquid Crystal Display,液晶显示器)监视器);以及键盘和指向装置(例如,鼠标或者轨迹球),用户可以通过该键盘和该指向装置来将输入提供给电子设备。其它种类的装置还可以用于提供与用户的交互;例如,提供给用户的反馈可以是任何形式的传感反馈(例如,视觉反馈、听觉反馈或者触觉反馈);并且可以用任何形式(包括声输入、语音输入或者触觉输入)来接收来自用户的输入。
可以将此处描述的系统和技术实施在包括后台部件的计算系统(例如,作为数据服务器)、或者包括中间件部件的计算系统(例如,应用服务器)、或者包括前端部件的计算系统(例如,具有图形用户界面或者网络浏览器的用户计算机,用户可以通过该图形用户界面或者该网络浏览器来与此处描述的系统和技术的实施方式交互)或者包括这种后台部件、中间件部件、或者前端部件的任何组合的计算系统中。可以通过任何形式或者介质的数字数据通信(例如,通信网络)来将系统的部件相互连接。通信网络的示例包括:局域网(LAN)、广域网(WAN)、区块链网络和互联网。
计算系统可以包括客户端和服务器。客户端和服务器一般远离彼此并且通常通过通信网络进行交互。通过在相应的计算机上运行并且彼此具有客户端-服务器关系的计算机程序来产生客户端和服务器的关系。服务器可以是云服务器,又称为云计算服务器或云主机,是云计算服务体系中的一项主机产品,以解决了传统物理主机与VPS服务中,存在的管理难度大,业务扩展性弱的缺陷。
应该理解,可以使用上面所示的各种形式的流程,重新排序、增加或删除步骤。例如,本发明中记载的各步骤可以并行地执行也可以顺序地执行也可以不同的次序执行,只要能够实现本发明的技术方案所期望的结果,本文在此不进行限制。
上述具体实施方式,并不构成对本发明保护范围的限制。本领域技术人员应该明白的是,根据设计要求和其他因素,可以进行各种修改、组合、子组合和替代。任何在本发明的精神和原则之内所作的修改、等同替换和改进等,均应包含在本发明保护范围之内。