一种综合深度学习和医学知识的胰岛素剂量推荐系统
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及一种用于智能推荐胰岛素剂量的系统。
背景技术
根据《中国2型糖尿病防治指南(2020年版)》,CGM包括回顾性CGM系统、实时CGM系统以及扫描式CGM系统,适用情况如下:(1)T1DM。(2)需要胰岛素强化治疗的2型糖尿病(T2DM)患者。(3)在SMBG指导下使用降糖治疗的T2DM,仍出现下列情况之一,具体包括:①无法解释的严重低血糖或反复低血糖,无症状性低血糖、夜间低血糖;②无法解释的高血糖,特别是空腹高血糖;③血糖波动大;④出于对低血糖的恐惧,刻意保持高血糖状态的患者。(4)妊娠期糖尿病(GDM)或糖尿病合并妊娠。(5)患者教育。
相比于SMBG,CGM可以提供连续动态的血糖监测,记录血糖的变化趋势,具有更好指导胰岛素剂量的潜力。在1型糖尿病中,由于胰岛素为刚性需求,目前国外有些厂家已发明闭环胰岛素泵,通过CGM监测血糖、算法推荐胰岛素剂量、胰岛素泵给予连续胰岛素注射,对T1DM患者进行更方便、全面的血糖管理。而针对数量更多的2型糖尿病群体,不同的CGMS系统自带指示血糖变化的箭头,且已有少量利用CGMS箭头指导3+1方案餐时胰岛素注射的规则建议。然而,不同厂家的CGMS指示血糖变化的箭头含义各不相同,且主要反映过去15或30min的血糖变化,具有一定的时间滞后性,且其仅基于单纯的血糖数据,无法反映病人的异质性,因此具有一定的局限性。此外,现有基于血糖变化调整胰岛素的方案多适用于白种人,其餐时剂量调整较国人更为激进,目前暂无针对中国人特征和胰岛素使用习惯的基于CGM血糖的胰岛素剂量推荐系统。
发明内容
本发明的目的是:基于病史信息、CGMS血糖数据,利用神经网络模型,考虑当前血糖水平、血糖变化和对胰岛素的敏感性,构建适合中国人群的更精准的餐时胰岛素剂量推荐。
为了达到上述目的,本发明的技术方案是提供了一种综合深度学习和医学知识的胰岛素剂量推荐系统,其特征在于,包括数据采集模块、基于深度学习的神经网络模型以及胰岛素剂量推荐模块,其中:
数据采集模块进一步包括非时序信息采集单元、时序信息采集单元以及连续血糖数据采集单元:
非时序信息采集单元,用于采集非时序信息,包括病人的病史数据以及化验检验数据;
时序信息采集单元,用于采集时序信息,包括胰岛素注射记录、口服药物记录、点血糖记录信息,其中:胰岛素注射记录为七个时间点的胰岛素注射记录,包括注射胰岛素的量和对应胰岛素的胰岛素名称、胰岛素类型、起效时间、峰值时间、持续时间信息,所述七个时间点为早餐前、早餐后、午餐前、午餐后、晚餐前、晚餐后、睡前;口服药物记录按照使用日期进行处理,包括每次服药的量和对应药物的药品名称、药物类型、剂量范围、起效时间以及半衰期;点血糖记录信息为七个时间点的点血糖值;
连续血糖数据采集单元,用于基于连续血糖监测技术采集连续血糖监测数据;
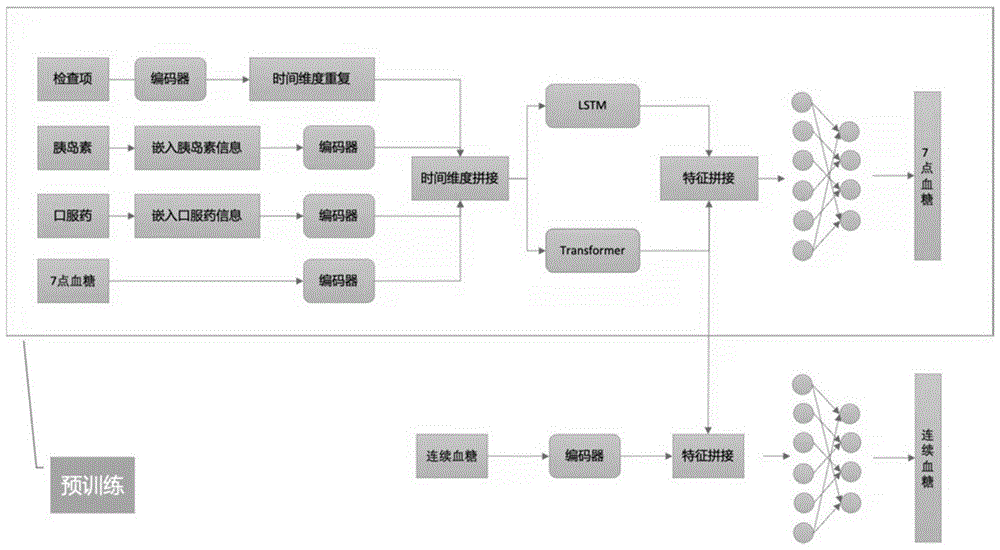
基于深度学习的神经网络模型,用于根据数据采集模块采集的数据输出连续血糖预测值,包括用于处理非时序信息的编码器一、用于处理胰岛素注射记录的编码器二、用于处理口服药物记录的编码器三、用于处理点血糖记录信息的编码器四、用于处理连续血糖监测数据的编码器五、LSTM层和Transformer层;对于非时序信息,编码器一对其进行编码后得到对应的高纬度特征后,再利用时间维度重复单元,将同一高纬度特征复制至早餐前、早餐后、午餐前、午餐后、晚餐前、晚餐后、睡前这七个时间点,获得非时序信息的最终编码结果;神经网络模型将通过编码器二、编码器三以及编码器四得到编码后的时序信息与非时序信息的最终编码结果在时间维度进行拼接,得到T×M维的特征向量,其中,T=天数×7,M为特征数;T×M维的特征向量同时输入LSTM层和Transformer层,LSTM层和Transformer层的输出以及编码器五输出的高纬度特征同时输入多层堆叠的全连接和非线性映射层后,得到连续血糖预测值;
胰岛素剂量推荐模块,用于根据基于深度学习的神经网络模型输出的连续血糖预测值,结合基于医学知识胰岛素推荐规则,获得胰岛素推荐剂量。
优选地,还包括模型训练模块,用于对基于深度学习的神经网络模型进行训练,包括预训练数据集采集单元以及训练数据集采集单元;模型训练模块利用预训练数据集采集单元采集的预训练数据集对基于深度学习的神经网络模型中除编码器五外的部分进行预训练,再利用训练数据集采集单元采集的训练数据集对预训练后的基于深度学习的神经网络模型进行训练,其中:
预训练数据集采集单元从糖尿病住院病人采集非时序信息以及时序信息构成预训练数据集,预训练数据集中的样本标签为未来的早餐前、早餐后、午餐前、午餐后、晚餐前、晚餐后、睡前的点血糖值;
训练数据集采集单元从糖尿病住院病人采集非时序信息、时序信息以及连续血糖监测数据构成训练数据集,训练数据集中的样本标签为未来的连续血糖监测数据。
优选地,预训练数据集采集单元在采集非时序信息时,对于缺失的数据,使用固定的缺失编码和平均值编码的方式来进行填充。
优选地,所述胰岛素类型包括预混胰岛素、短效胰岛素和基础胰岛素。
优选地,所述时序信息采集单元在采集胰岛素注射记录时,对精确的胰岛素注射进行离散化处理,使其固定到对应的预先设定的特定时间点后,得到七个时间点的采集胰岛素注射记录;
所述时序信息采集单元在采集点血糖记录信息时,对精确的血糖值记录时间进行离散化处理,使其固定到对应的预先设定的特定时间点后,得到七个时间点的点血糖值。
优选地,所述非时序信息包括葡萄糖、体重、糖化血红蛋白、空腹血糖、葡萄糖(急)、餐后2h血糖、餐后血糖、胰岛素空腹、C肽空腹、C肽6分钟、胰岛素2分钟、胰岛素4分钟、2min血糖、4min血糖、C肽2分钟、C肽4分钟、胰岛素6分钟、6min血糖、糖化白蛋白、胰岛素、C肽1、C肽120分钟、胰岛素120分钟、C肽30分钟、胰岛素30分钟、30min血糖、C肽180分钟、C肽60分钟、胰岛素180分钟、胰岛素60分钟、120min血糖、180min血糖、60min血糖、C肽、C肽240分钟、C肽300分钟、胰岛素240分钟、胰岛素300分钟、240min血糖、300min血糖、酮体、皮质醇、皮质醇1、胰高血糖素、估算肾小球滤过率、肌酐、胆红素、尿白蛋白、尿白蛋白/肌肝、β-羟丁酸、24小时尿肌酐、24小时尿白蛋白、总胆红素、直/总比、直接胆红素、门冬氨酸氨基转移酶、丙草比、低密度脂蛋白胆固醇、游离脂肪酸、低密度脂蛋白胆固醇1、总胆固醇1、甘油三酯1、总胆红素(急)、结合胆红素(急)、门冬氨酸氨基转移酶(急)、氨基末端利钠肽前体、乳酸、舒张压、抗谷氨酸脱羧酶抗体、抗胰岛素自身抗体、抗胰岛细胞抗体、胰岛素样生长因子、尿液葡萄糖定量、24小时尿糖、丙氨酸氨基转移酶、身高、年龄、性别。
优选地,所述编码器一、编码器二、编码器三、编码器四以及编码器五的结构相同,采用MLP结构以及多头注意力编码实现,使用MLP结构预处理出的信息作为多头注意力编码的输入,再由多头注意力编码使用多头注意力机制对信息进一步处理。
优选地,所述MLP结构的实现如下式所示:
h=f(W
y=g(W
式中:x表示输入,可以分别代表非时序信息、胰岛素注射记录、口服药物记录、点血糖记录信息、连续血糖监测数据;W
多头注意力编码的实现如下式所示:
MultiHead(H)=concat(head
head
式中:H是MLP结构的输出;Q、K、V是输入的三个矩阵,用H来代替;head
优选地,在所述胰岛素剂量推荐模块中建立的基于医学知识胰岛素推荐规则如下表所示:
/>
上表中:箭头的方向表示的是根据所述神经网络模型输出的连续血糖预测值得到的血糖变化趋势,箭头数量表示的是根据所述神经网络模型输出的连续血糖预测值得到的血糖变化的幅度;+1、+2、+3、+4、+5表示胰岛素的增加用量,-1、-2、-3、-4、-5表示胰岛素的减少用量,+0表示胰岛素用量不变;胰岛素敏感性的低、中、高三个等级根据患者特征由医生进行设置。
本发明基于复旦大学附属中山医院和上海市第六人民医院住院糖尿病患者的病史、化验、用药和指尖血糖和连续血糖检测等信息,利用神经网络算法,预测2型糖尿病患者短时血糖变化情况,并结合医学知识,综合考虑当前血糖水平、血糖变化和对胰岛素的敏感性,给予胰岛素推荐剂量。本发明利用预训练的方法,可以从大量的糖尿病患者病史和化验数据中学习2型糖尿病的患者特征,利用CGM数据有助于学习到更多患者对于胰岛素的血糖反应,在预测血糖变化模型性的基础上,利用符合医学知识的胰岛素调整规则,综合考虑当前血糖、血糖变化以及患者对胰岛素的敏感性,给出了一个较合理且操作方便的胰岛素剂量调整策略,且预测表现优于既往模型。
附图说明
图1示意了本实施例公开的深度学习模型。
具体实施方式
下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所附权利要求书所限定的范围。
本实施例公开的一种综合深度学习和医学知识的胰岛素剂量推荐系统包括数据采集模块、基于深度学习的神经网络模型、胰岛素剂量推荐模块以及模型训练模块。
数据采集模块进一步包括非时序信息采集单元、时序信息采集单元以及连续血糖数据采集单元。
非时序信息采集单元用于采集非时序信息,包括病人的病史数据以及化验检验数据。病人的病史作为基本信息在入院时由医生录入。化验检验通常在病人住院期间的前1~2天完成,同样是非时序信息。下表1为本实施例中的非时序信息示例。
/>
表1
本实施例中,非时序信息采集单元所使用到的检查项目具体包括:
葡萄糖、体重、糖化血红蛋白、空腹血糖、葡萄糖(急)、餐后2h血糖、餐后血糖、胰岛素空腹、C肽空腹、C肽6分钟、胰岛素2分钟、胰岛素4分钟、2min血糖、4min血糖、C肽2分钟、C肽4分钟、胰岛素6分钟、6min血糖、糖化白蛋白、胰岛素、C肽1、C肽120分钟、胰岛素120分钟、C肽30分钟、胰岛素30分钟、30min血糖、C肽180分钟、C肽60分钟、胰岛素180分钟、胰岛素60分钟、120min血糖、180min血糖、60min血糖、C肽、C肽240分钟、C肽300分钟、胰岛素240分钟、胰岛素300分钟、240min血糖、300min血糖、酮体、皮质醇、皮质醇1、胰高血糖素、估算肾小球滤过率(根据CKD-EPI方程)、肌酐、胆红素、尿白蛋白、尿白蛋白/肌肝、β-羟丁酸、24小时尿肌酐、24小时尿白蛋白、总胆红素、直/总比、直接胆红素、门冬氨酸氨基转移酶、丙草比、低密度脂蛋白胆固醇、游离脂肪酸、低密度脂蛋白胆固醇1、总胆固醇1、甘油三酯1、总胆红素(急)、结合胆红素(急)、门冬氨酸氨基转移酶(急)、氨基末端利钠肽前体、乳酸、舒张压、抗谷氨酸脱羧酶抗体、抗胰岛素自身抗体、抗胰岛细胞抗体、胰岛素样生长因子、尿液葡萄糖定量、24小时尿糖、丙氨酸氨基转移酶、身高、年龄、性别。
时序信息采集单元,用于采集时序信息,包括胰岛素注射记录、口服药物记录、点血糖记录信息。胰岛素注射记录和口服药物记录是时序信息,它们包括具体使用时间(精确到分钟)和使用剂量。
本实施例中,口服药物记录按照使用日期进行处理,包括每次服药的量和对应药物的药品名称、药物类型、剂量范围、起效时间以及半衰期。
本实施例中,胰岛素注射记录包括胰岛素注射时间、每次注射胰岛素的量和对应胰岛素的胰岛素名称、胰岛素类型、起效时间、峰值时间、持续时间信息。胰岛素注射记录较为稀疏,不同品牌的胰岛素在注射记录在时序信息出现次数不均匀,有的胰岛素出现次数很少,直接学习会造成神经网络模型有不平衡的问题。本发明将所有胰岛素按照种类分成了三大类,即胰岛素类型分为预混胰岛素、短效胰岛素和基础胰岛素。
本实施例中,点血糖记录信息包括早餐前、早餐后、午餐前、午餐后、晚餐前、晚餐后、睡前这七个时间点的七点血糖值以及七点血糖值记录时间。
实际的胰岛素注射时间以及血糖值记录时间为精确时间(例如8:24),为了统一处理,本发明将精确时间做离散化处理,将精确时间固定到对应的特定时间点(例如将8:24固定至8:30,表示早餐后)。离散化处理后,相应的血糖值记录时间就成为了点血糖值记录时间,进而获得了对应的七点血糖值。按照离散化处理后的时序,时序信息采集单元将胰岛素注射记录以及点血糖记录信息标记为早餐前、早餐后、午餐前、午餐后、晚餐前、晚餐后、睡前,时序数据示例如下表2所示。
表2
连续血糖数据采集单元,用于基于连续血糖监测技术采集连续血糖监测数据,本实施例中,连续血糖监测数据的采集周期为15分钟。
基于深度学习的神经网络模型,用于根据数据采集模块采集的数据输出连续血糖预测值。本实施例中,基于深度学习的神经网络模型的输入数据为数据采集模块采集的非时序信息、时序信息以及连续血糖监测数据,其中,时序信息为早餐前、早餐后、午餐前、午餐后、晚餐前、晚餐后、睡前这七个时间点的时序信息;基于深度学习的神经网络模型的输出为未来15min、30min、45min和60min的血糖预测值。
基于深度学习的神经网络模型的结构如图1所示,包括用于处理非时序信息的编码器一、用于处理胰岛素注射记录的编码器二、用于处理口服药物记录的编码器三、用于处理点血糖记录信息的编码器四、用于处理连续血糖监测数据的编码器五、LSTM层和Transformer层。
编码器一、编码器二、编码器三、编码器四以及编码器五的结构相同,仅初始化参数存在差异(本实施例中,初始化参数是随机的),采用MLP结构以及多头注意力编码实现,使用MLP结构预处理出的信息作为多头注意力编码的输入,再由多头注意力编码使用多头注意力机制对信息进一步处理。
MLP结构的实现如下式所示:
h=f(W
y=g(W
式中:x表示输入,可以分别代表非时序信息、胰岛素注射记录、口服药物记录、点血糖记录信息、连续血糖监测数据;W
多头注意力编码的实现如下式所示:
MultiHead(H)=concat(head
head
式中:H是MLP结构的输出;Q、K、V是输入的三个矩阵,这里用H来代替;head
对于非时序信息,编码器一对其进行编码后得到对应的高纬度特征(128维)后,再利用时间维度重复单元,将同一高纬度特征复制至早餐前、早餐后、午餐前、午餐后、晚餐前、晚餐后、睡前这七个时间点,获得非时序信息的最终编码结果。将通过编码器二、编码器三以及编码器四得到编码后的时序信息与非时序信息的最终编码结果在时间维度进行拼接,得到T×M维的特征向量,其中,T=天数×7,M为特征数。T×M维的特征向量同时输入LSTM层和Transformer层,LSTM层和Transformer层的输出以及编码器五输出的高纬度特征同时输入多层堆叠的全连接和非线性映射层后,得到连续血糖预测值。
胰岛素剂量推荐模块,用于根据基于深度学习的神经网络模型输出的连续血糖预测值,结合基于医学知识胰岛素推荐规则,获得胰岛素推荐剂量。
基于当前血糖水平、血糖变化和对胰岛素的敏感性,我们构建了如下表3所示的餐时胰岛素推荐剂量规则。
表3
上表3中,箭头的方向表示的是血糖变化趋势,箭头数量表示的是血糖变化的幅度,如下表4所示。
表4
本实施例中,基于深度学习的神经网络模型的输出为未来15min、30min、45min和60min的血糖预测值,血糖变化趋势以及幅度主要根据未来15min的血糖预测值得到。若当前时刻血糖值为A,神经网络模型输出的未来15min的血糖预测值为B,则每分钟血糖变化C为(B-A)/15(有方向),根据C的方向确定血糖变化指示的方向是增加/减小/不变,再根据C的大小确定箭头数量,即血糖变化的幅度。
表3中,+1、+2、+3、+4、+5表示胰岛素的增加用量,-1、-2、-3、-4、-5表示胰岛素的减少用量,+0表示胰岛素用量不变。胰岛素敏感性的低、中、高三个等级根据患者特征由医生进行设置。
例如:对一个胰岛素敏感性中等的糖尿病患者,前一天他的午餐前胰岛素用量为10u,接下来需要为他推荐今日午餐前胰岛素用量,若当前他的血糖为7.0,若接下来他的血糖变化为↑,则增加2u胰岛素剂量,即今日打12u胰岛素。
模型训练模块,用于对基于深度学习的神经网络模型进行训练,包括预训练数据集采集单元以及训练数据集采集单元。模型训练模块利用预训练数据集采集单元采集的预训练数据集对基于深度学习的神经网络模型中除编码器五外的部分进行预训练,再利用训练数据集采集单元采集的训练数据集对预训练后的基于深度学习的神经网络模型进行训练。
预训练数据集采集单元从中山医院收集的糖尿病住院病人中筛选的7584名(2018年以前4479名、2019年2704名、2021年401名)有效病人采集非时序信息以及时序信息构成预训练数据集,预训练数据集中的样本标签为下一天的早餐前、早餐后、午餐前、午餐后、晚餐前、晚餐后、睡前这七个时间点的点血糖数据。对于预训练数据集中的非时序信息,经过筛选与糖尿病相关的信息,我们从病人的病史信息和化验检验中选取了共78个特征组成了非时序输入。然而,并不是每一位病人都做了详尽的检查,造成了非时序信息的缺失。对于缺失的特征,本发明使用固定的缺失编码和平均值编码的方式来进行填充。
训练数据集采集单元从中山医院收集的糖尿病住院病人中筛选出214名含有连续血糖监测数据的患者,基于这些患者的连续血糖监测数据、时序信息以及时序信息构成训练数据集。
利用预训练数据集或者训练数据集对基于深度学习的神经网络模型进行预训练或训练时,按照7:0.15:0.15的比例将预训练数据集或者训练数据集进一步分成训练集、验证集和测试集。训练时,使用Adam优化器,学习率为0.001,batch_size为256,最长训练为300个epoch,并使用早停技术监测验证数据集中的loss,如果10个epoch内无更优结果,则停止训练。并根据验证集最优的原则选取最终的模型。
两次训练均使用均方根误差(Root Mean Squared Error,RMSE)损失函数,如下式所示:
在预训练中:
在第二次训练中:
RMSE用于评估预测值与真实值的差异。其中,越小的RMSE值表示预测模型的精度越高。预训练中,我们会优先选择测试集RMSE值低的模型。
上述技术方案的预测表现优于既往模型:基于高质量的患者病史、药物情况、七点血糖数据预训练,结合连续血糖监测信息,利用深度学习模型构建血糖预测模型,效果优于既往模型。下表5展示了本发明的模型与GluNet和Martinsson模型的对比。
表5
上述技术方案计划在住院或居家的2型糖尿病患者中使用,通过与HIS系统相连/患者手动输入获取患者病史、用药等基本信息,与CGM系统相连获取连续血糖监测信息,将获取数据输入模型中,模型可预测该患者未来15、30、45、60min病人的血糖,并给出血糖变化趋势的箭头指示,提供餐时胰岛素推荐剂量。最终的显示为“病人未来15/30/45/60分钟的血糖的预测值是7.8mmol/L,血糖变化趋势为:↑,推荐午餐前胰岛素剂量为10u”。
本发明所公开的技术方案综合了连续血糖监测(CGM)技术、深度学习以及综合医学知识的胰岛素决策规则。
自从CGM技术的出现以来,利用CGM数据的预测模型的开发一直是先前研究和开发工作的重点。既往大多预测模型主要集中在1型糖尿病,然而多项大型RCT研究中已证实使用CGM可以为使用胰岛素的2型糖尿病患者带来临床获益。相比于传统的七点血糖监测,CGM的采样点更为密集,能反应血糖变化趋势更好地发现临床低血糖事件,并且提供更为丰富的血糖信息,有助于指导临床降糖治疗。
深度学习(DL)是机器学习中一种基于对数据进行表征学习的方法,是一种能够模拟出人脑的神经结构的机器学习方法。其可以通过构建具有很多隐层的机器学习模型和海量的训练数据,来学习更有用的特征,从而最终提升分类或预测的准确性。利用预训练的方法,可以从大量的糖尿病患者病史和化验数据中学习2型糖尿病的患者特征,利用CGM数据有助于学习到更多患者对于胰岛素的血糖反应,从而更好地预测个体的血糖变化,进而指导临床胰岛素使用。
2型糖尿病中,基础餐时方案是一种较常见的强化治疗方案,其较好地模拟了胰岛素的生理变化(基础胰岛素模拟未进食时体内少量分泌的胰岛素,餐时胰岛素模型进餐后快速增加的胰岛素),对于糖尿病患者,已有研究发现餐后血糖高与糖尿病的不良预后相关,因此,合理的餐时胰岛素剂量调整对2型糖尿病患者至关重要。本发明中,参考了既往白种人中使用CGM箭头指示的胰岛素调整规则,并针对国人习惯做了相应调整。在当前血糖较高且血糖处于增加趋势的情况下,对胰岛素敏感性较高的病人,我们使用较保守的剂量调整策略,而对胰岛素敏感性较低的病人,我们则使用较为激进的剂量调整策略;在血糖趋向于减少的情况下,为防止低血糖,综合考虑当前血糖情况,我们会进行相应的胰岛素剂量调整。总而言之,本胰岛素推荐模型,在预测血糖变化模型性的基础上,利用符合医学知识的胰岛素调整规则,综合考虑当前血糖、血糖变化以及患者对胰岛素的敏感性,给出了一个较合理且操作方便的胰岛素剂量调整策略。