一种基于去联邦学习的医疗数据共享系统及方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及医疗共享数据领域,特别涉及一种基于去联邦学习的医疗数据共享系统及方法。
背景技术
随着大数据、移动边缘计算和机器学习等技术的飞速发展,共享经济也迅速发展。网络信息时代产生了海量的医疗数据,其共享将会产生极大的价值。然而,由于可能会带来隐私泄露等方面的安全风险,医疗机构并不愿意共享数据,这使得不同医疗机构之间难以利用对方的医疗数据进行联合分析或者建模,因此如何进行安全共享医疗数据成为本领域的研究重点。
目前医疗数据共享主要采用传统联邦学习实现,然而,现有传统联邦学习依赖于大量客户端本地数据的静态存储,在实际过程中,存在医疗数据量持续增加的情况,并且医疗数据特征可能会发生巨大变化,这会导致持续学习面临灾难性遗忘的问题。另外当某个医疗机构不再参与训练,就涉及到移除该医疗本地数据贡献的问题,移除医疗机构本地数据贡献后会降低其他医疗机构客户端的性能。
发明内容
本发明目的是为了解决现有联邦学习方法还存在医疗数据量持续增加的情况下联邦学习无法有效解决持续学习面临的灾难性遗忘的问题,同时还存在移除医疗机构数据贡献会导致其他医疗机构客户端的性能降低的问题,而提出了一种基于去联邦学习的医疗数据共享系统及方法。
一种基于去联邦学习的医疗数据共享系统,包括:初始模型获取模块、本地模型权重更新模块、本地模型权重上传模块、权重聚合及发送模块、客户端退出判断模块、退出客户端训练恢复模块;
所述初始模型获取模块用于医疗机构客户端从服务器下载全局权重θ
所述本地模型权重更新模块用于利用医疗机构客户端本地获取的医疗数据构建基于蒸馏的损失函数,利用获取的损失函数更新初始模型的权重;
所述本地模型权重上传模块用于将本地模型权重更新模块获得的权重从医疗机构客户端上传到服务器;
所述权重聚合及发送模块用于聚合服务器获取的权重,并将聚合的权重发送到医疗机构客户端作为下一轮联邦训练的初始权重;
所述客户端退出判断模块用于判断是否存在医疗机构客户端退出,若没有医疗机构客户端退出,则跳回初始模型获取模块重新获取初始模型,若存在医疗机构客户端退出则进入医疗机构客户端训练恢复模块;
所述客户端训练恢复模块用于基于遗忘学习方法恢复医疗机构客户端训练。
进一步地,所述本地模型权重更新模块用于利用医疗机构客户端本地获取的医疗数据构建基于蒸馏的损失函数,利用获取的损失函数更新初始模型的权重,包括以下步骤:
S1、获取第r-1轮联邦训练的本地模型
S2、利用教师模型和医疗机构客户端本地获取的医疗数据对初始模型进行蒸馏训练,构建医疗机构客户端k基于蒸馏的损失函数
S3、利用医疗机构客户端k基于蒸馏的损失函数
其中,η表示学习率,
进一步地,所述S2中的客户端k基于蒸馏的损失函数如下式:
其中,α和β为超参数,
所述本地旧模型为:
进一步地,所述聚合服务器获取的权重,如下式:
其中,m
进一步地,所述客户端训练恢复模型用于基于遗忘学习方法恢复客户端训练,包括以下步骤:
step1、利用聚合后的权重获取参考模型权重:
其中,N是参与联邦学习的医疗机构客户端数量;
其中,参考模型权重是除k外的其他医疗机构客户端权重的平均值;
step2、利用客户端k基于蒸馏的损失函数和参考模型权重获取遗忘学习的训练目标:
其中,v是空间,θ是本地模型训练过程中的权重,||·||
step3、采用梯度上升实现step2获得的训练目标,获得基于梯度上升的权重更新:
其中,Ω是围绕θ
step4、将step3获得的权重上传至服务器作为全局权重重新分发到各个客户端,将全局权重赋给医疗机构客户端的本地模型,医疗机构客户端本地执行恢复训练并上传权重参数用于聚合;
其中,恢复训练具体为:将医疗机构客户端本地获得医疗数据划分为训练集和验证集,利用训练集训练赋有全局权重的本地模型,训练过程中基于验证集判断当前赋有全局权重的本地模型准确率是否达到临界值,若达到则训练结束并将权重返回服务器,服务器再将权重发送到其他客户端执行恢复训练,最后聚合客户端权重。
一种基于去联邦学习的医疗数据共享方法,包括以下步骤:
步骤一、利用医疗机构客户端从服务器下载全局权重θ
步骤二、利用医疗机构客户端本地获取的医疗数据构建基于蒸馏的损失函数,利用获取的损失函数更新初始模型的权重;
步骤三、将步骤二获得的权重从医疗机构客户端上传到服务器;
步骤四、聚合步骤三服务器获取的权重,并将聚合的权重发送到医疗机构客户端作为下一轮联邦训练的初始权重;
步骤五、判断是否存在医疗机构客户端退出,若没有医疗机构客户端退出,则跳回步骤一重新获取初始模型,若存在医疗机构客户端退出则基于遗忘学习方法恢复医疗机构客户端训练。
进一步地,所述步骤二中的利用医疗机构客户端本地获取的医疗数据构建基于蒸馏的损失函数,利用获取的损失函数更新初始模型的权重,包括以下步骤:
步骤二一、获取第r-1轮联邦训练的本地模型
步骤二二、利用教师模型和医疗机构客户端本地获取的医疗数据对本地模型进行蒸馏训练,构建医疗机构客户端k基于蒸馏的损失函数
其中,α和β为超参数,
所述本地旧模型为:
步骤二三、利用医疗机构客户端k基于蒸馏的损失函数更新初始模型的权重
其中,η表示学习率,
进一步地,所述步骤四中的聚合步骤三服务器获取的权重,如下式:
其中,m
进一步地,所述步骤五中的若存在医疗机构客户端退出则基于遗忘学习方法恢复医疗机构客户端训练,包括以下步骤:
步骤五一、利用聚合后的权重获取参考模型权重:
其中,N是参与联邦学习的医疗机构客户端数量,参考模型权重是除k外的其他医疗机构客户端权重的平均值;
步骤五二、利用客户端k基于蒸馏的损失函数和参考模型权重获取遗忘学习的训练目标:
其中,v是空间,θ是本地模型训练过程中的权重,||·||
步骤五三、采用梯度上升实现step2获得的训练目标,获得基于梯度上升的权重更新:
其中,Ω是围绕θ
步骤五四、将步骤五三获得的权重上传至服务器作为全局权重重新分发到各个客户端,将全局权重赋给医疗机构客户端的本地模型,医疗机构客户端本地执行恢复训练并上传权重参数用于聚合。
进一步地,所述医疗机构客户端本地执行恢复训练,具体为:将医疗机构客户端本地获得医疗数据划分为训练集和验证集,利用训练集训练赋有全局权重的本地模型,训练过程中基于验证集判断当前赋有全局权重的本地模型准确率是否达到临界值,若达到则训练结束并将权重返回服务器,服务器再将权重发送到其他客户端执行恢复训练,最后聚合客户端权重。
本发明的有益效果为:
本发明提供了具有持续学习能力的客户端模型,并通过构建基于蒸馏的损失函数,有效解决持续学习面临的灾难性遗忘问题。此外针对医疗数据隐私保护所要求的模型数据遗忘问题,本发明提供了联邦学习架构中基于投影梯度上升的遗忘学习训练方法,在小幅甚至不影响模型性能的情况下,使模型能够快速遗忘特定数据,相比重新训练模型大幅降低了训练成本,保证了患者的安全隐私,同时移除医疗客户端数据贡献不会降低模型在其他医疗客户端上的性能。
附图说明
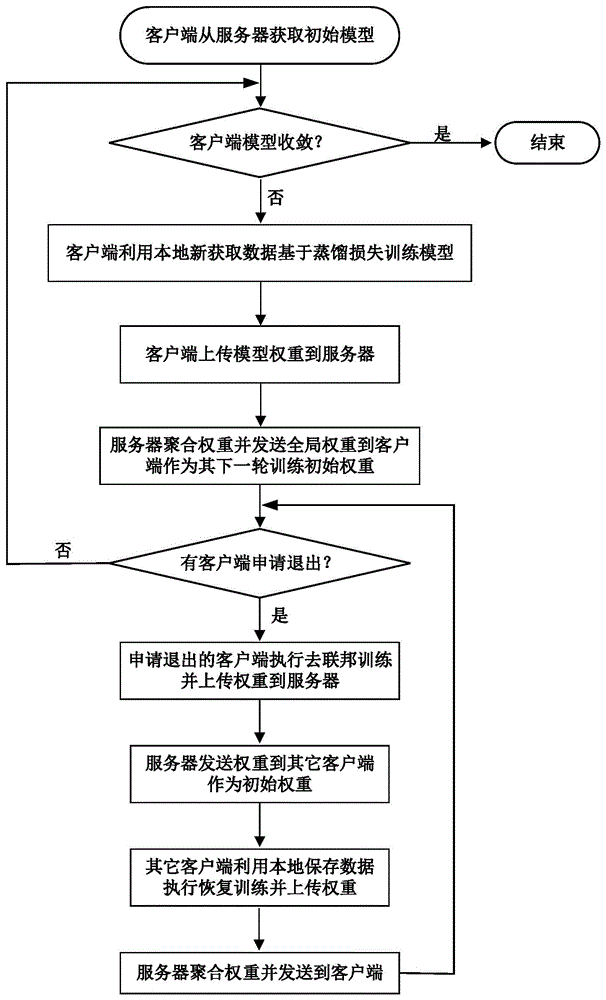
图1是本发明中基于持续学习的去联邦训练系统的整体流程图;
图2是本发明中提出持续学习的整体架构框架图;
图3是本发明中提出客户端去联邦的训练流程图。
具体实施方式
具体实施方式一:如图1-3所示,一种基于去联邦学习的医疗数据共享系统,包括:初始模型获取模块、本地模型权重更新模块、本地模型权重上传模块、权重聚合及发送模块、客户端退出判断模块、退出客户端训练恢复模块;
所述初始模型获取模块用于医疗机构客户端从服务器下载全局权重θ
所述本地模型权重更新模块用于利用医疗机构客户端本地获取的医疗数据构建基于蒸馏的损失函数,利用获取的损失函数更新初始模型的权重;
所述本地模型权重上传模块用于将本地模型的权重更新模块获得的权重从医疗机构客户端上传到服务器;
所述权重聚合及发送模块用于聚合服务器获取的权重,并将聚合的权重发送到医疗机构客户端作为下一轮联邦训练的初始权重;
所述客户端退出判断模块用于判断是否存在医疗机构客户端退出,若没有医疗机构客户端退出,则跳回初始模型获取模块重新获取初始模型,若存在医疗机构客户端退出则进入医疗机构客户端训练恢复模块;
所述退出客户端训练恢复模块用于基于遗忘学习方法恢复医疗机构客户端训练。
具体实施方式二:所述初始模型获取模块用于医疗机构客户端从服务器获取初始模型,具体为:在第r轮联邦学习训练前,客户端k从服务器中下载全局权重θ
其中,权重为
具体实施方式三:所述本地模型权重更新模块用于利用医疗机构客户端本地获取的数据构建基于蒸馏的客户端损失函数从而更新初始模型的权重,具体为:
S1、获取第r-1轮联邦训练的本地模型
S2、利用教师模型和医疗机构客户端本地获取的医疗数据对初始模型进行蒸馏训练,构建医疗机构客户端k基于蒸馏的损失函数,具体如下:
对于r=1轮训练,医疗机构客户端k没有可用的教师模型,仅用分类任务损失(softmax交叉熵)作为最终损失函数,即:
其中,D
对于r>1轮训练,医疗机构客户端k基于两个教师模型,分别为上一轮训练后保存的本地旧模型即
其中,
服务器模型蒸馏损失为:
其中,
医疗机构客户端k基于蒸馏的损失函数为:
其中,α和β为用户自定义的超参数。
S3、医疗机构客户端k基于蒸馏的损失函数
其中,η表示学习率,
具体实施方式四:所述聚合服务器获取的权重,如下式:
其中,m
具体实施方式六:所述退出客户端训练恢复模块用于基于遗忘学习方法恢复医疗机构客户端训练,具体包括以下步骤:
step1、利用聚合后的权重获取参考模型权重:
选取除k外的其他医疗机构客户端的权重平均值作为参考模型权重
其中,N是参与联邦学习的医疗机构客户端数量;
客户端的平均值有如下定义:
step2、利用客户端k基于蒸馏的损失函数和参考模型权重获取遗忘学习的训练目标:
在联邦学习模型训练期间,客户端的目标是学习将经验风险最小化的局部模型,一般基于梯度下降实现。去联邦训练则是颠倒这一过程,即通过梯度上升方式学习模型参数以最大化损失,但是通过简单的梯度上升训练难以达到目标,因为损失函数可能是无界的,经过训练后会生成一个随机模型。为了避免模型参数的任意变化,需要确保训练期间始终接近一个有效参考模型。因此遗忘学习的训练目标可以表示为:
其中,θ
其中,θ是θ
step3、基于投影梯度上升实现公式(6)的训练目标,获得基于梯度上升的权重更新:
其中,Ω是围绕θ
step4、将step3获得的权重上传至服务器作为全局权重重新分发到各个客户端,将全局权重赋给医疗机构客户端的本地模型,医疗机构客户端本地执行恢复训练并上传权重参数用于聚合;
其中恢复训练具体过程为:将医疗机构客户端本地数据划分为训练集和验证集,利用训练集训练赋有全局权重的本地模型,训练过程中基于验证集判断当前赋有全局权重的本地模型准确率是否达到临界值,若达到则训练结束并将权重返回服务器,服务器再将权重发送到其他客户端令其执行恢复训练,最后聚合客户端权重。
具体实施方式七:一种基于去联邦学习的医疗数据共享方法,包括以下步骤:
步骤一、利用医疗机构客户端从服务器下载全局权重θ
步骤二、利用医疗机构客户端本地获取的医疗数据构建基于蒸馏的损失函数从而更新初始模型的权重,包括以下步骤:
步骤二一、获取第r-1轮联邦训练的本地模型
步骤二二、利用教师模型和医疗机构客户端本地获取的医疗数据对初始模型进行蒸馏训练,构建医疗机构客户端k基于蒸馏的损失函数
/>
其中,α和β为超参数,
所述本地旧模型为:
步骤二三、利用医疗机构客户端k基于蒸馏的损失函数更新初始模型的权重
其中,η表示学习率,
步骤三、将步骤二获得的权重从医疗机构客户端上传到服务器;
步骤四、聚合步骤三服务器获取的权重,并将聚合的权重发送到医疗机构客户端作为下一轮联邦训练的初始权重;
所述聚合步骤三服务器获取的权重,如下式:
其中,m
步骤五、判断是否存在医疗机构客户端退出,若没有医疗机构客户端退出,则跳回步骤一重新获取初始模型,若存在医疗机构客户端退出则基于遗忘学习方法恢复医疗机构客户端训练,具体包括以下步骤:
步骤五一、利用聚合后的权重获取参考模型权重:
其中,N是参与联邦学习的医疗机构客户端数量;
其中,参考模型权重是除k外的其他医疗机构客户端权重的平均值;
步骤五二、利用客户端k基于蒸馏的损失函数和参考模型权重获取遗忘学习的训练目标:
其中,v是空间,θ是本地模型训练过程中的权重,||·||
步骤五三、采用梯度上升实现step2获得的训练目标,获得基于梯度上升的权重更新:
其中,Ω是围绕θ
步骤五四、将步骤五三获得的权重上传至服务器作为全局权重重新分发到各个客户端,将全局权重赋给医疗机构客户端的本地模型,医疗机构客户端本地执行恢复训练并上传权重参数用于聚合;
其中,恢复训练具体为:将客户端本地获得数据划分为训练集和验证集,利用训练集训练本地模型,训练过程中基于验证集判断当前本地模型准确率是否达到临界值,若达到则训练结束并将权重返回服务器,服务器再将权重发送到其他客户端执行恢复训练,最后聚合客户端权重。
实施例:本发明以医院病人就诊科室分类任务为例,不同医院保存有关于病人病情描述和就诊科室的数据,目的是训练一个能根据病情描述判断病人就诊科室的模型。本发明所述的搭建基于持续学习的去联邦训练系统,具体操作步骤如下:
(1)、针对医院病人就诊数据持续增加的场景和医院退出时数据遗忘请求,搭建基于持续学习的去联邦训练系统;
(2)、针对联邦持续学习中存在的灾难性遗忘问题,通过知识蒸馏的方式,构建损失函数优化模型。
(3)、在联邦学习中嵌入去联邦训练方法,当医院退出联邦学习时,通过投影梯度上升更新模型参数,以最大化训练模型局部经验损失,并经过恢复训练降低去联邦训练的影响。