医疗大数据的数据处理方法及智能处理系统
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及智能处理系统技术领域,具体涉及一种医疗大数据的数据处理方法及智能处理系统。
背景技术
医疗大数据的本质是数据。在医疗行业,医生的诊治是一个过程,需要将患者疾病状态或治疗过程记录下来。而每一次诊治过程,都会形成大量的医疗数据,例如:病例数据、检查检验报告数据、检查影像数据、处方数据、随访数据等。
现有技术中,医疗数据仍然缺乏有效的存档,特别是对于门诊医疗数据而言,很多偏远医疗机构的医疗数据仅有纸质存档,纸质存档的保存难度大且容易损坏,且不便于查阅。
而近年来虽然逐渐推行医疗数据的电子化存档,但是各个医疗机构的电子化医疗数据都是随着病人的就诊随机生成的,对于同一病人的医疗数据存储比较零散,缺乏统一的整理。
并且,同一病人往往会在多个不同的医疗机构就诊,在不同的医疗机构就诊时,虽然同一病人在每个医疗机构分别形成有医疗数据的记录,但是这些记录要么是纸质记录,不便于查阅,要么是单独存储于各个医疗机构内部存储终端的电子数据,不便于外部单位参考。
从而现有技术中的医疗数据都是零散而杂乱的,医疗数据存储于不同的存储地址,从而不利于提取同一病人的完整病史情况,而仅仅能通过病人自己的口述了解病人的既往病史情况。
因此,现有的医疗大数据存在的缺陷是,医疗数据不能形成一个统一和完整的记录体系,不便于医疗大数据存储过程中的数据有序存储。
发明内容
本发明的主要目的是提供一种医疗大数据的数据处理方法,旨在使医疗大数据存储过程中形成数据的有序存储。
为实现上述目的,本发明提出的一种医疗大数据的数据处理方法包括如下步骤:
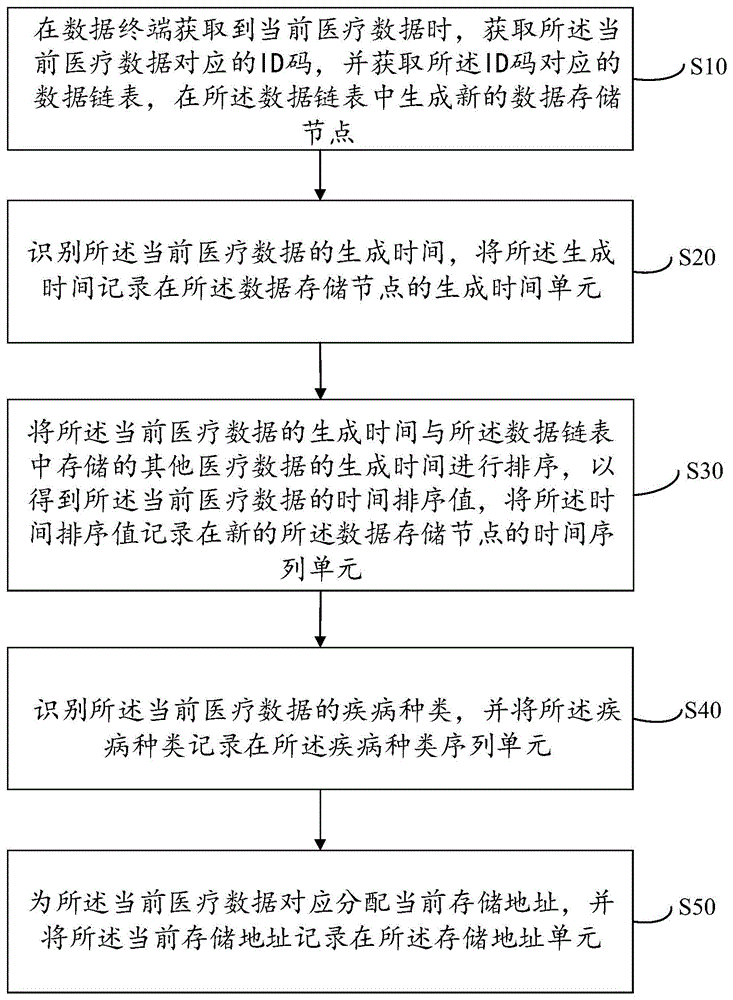
在数据终端获取到当前医疗数据时,获取所述当前医疗数据对应的ID码,并获取所述ID码对应的数据链表,在所述数据链表中生成新的数据存储节点;其中,每个所述数据存储节点包括生成时间单元、时间序列单元、疾病种类序列单元和存储地址单元;
识别所述当前医疗数据的生成时间,将所述生成时间记录在所述数据存储节点的生成时间单元;
将所述当前医疗数据的生成时间与所述数据链表中存储的其他医疗数据的生成时间进行排序,以得到所述当前医疗数据的时间排序值,将所述时间排序值记录在新的所述数据存储节点的时间序列单元;
识别所述当前医疗数据的疾病种类,并将所述疾病种类记录在所述疾病种类序列单元;
为所述当前医疗数据对应分配当前存储地址,并将所述当前存储地址记录在所述存储地址单元。
优选地,各个所述数据终端与云服务器信号连接,所述数据处理方法,还包括:
获取所述ID码对应的唯一身份信息,将所述ID码与所述唯一身份信息关联;
获取所述唯一身份信息在不同的所述数据终端分别关联的所述ID码所对应的全部数据链表,以生成用于记录所述唯一身份信息的全部医疗数据的数据链表查询树,其中,所述数据链表查询树的第一层级为唯一身份信息,第二层级为ID码,第三层级为数据链表。
优选地,所述数据处理方法,还包括:
将所述数据链表查询树存储至云服务器,且在各个与所述云服务器建立通讯的所述数据终端生成查询端口;
获取从所述查询端口输入的唯一身份信息和按时间查询指令;
根据所述唯一身份信息调取对应的数据链表查询树;
根据调取出的所述数据链表查询树,得到各个所述ID码分别对应的多个数据链表;
按照各个不同的所述数据链表中的每个所述数据存储节点中的生成时间单元中记录的生成时间,对所有的数据存储节点重新进行时间排序,得到每个数据存储节点的整体时间排序值,并将整体时间排序值更新在每个所述数据存储节点中的所述时间序列单元中;
根据各个数据存储节点中的所述时间序列单元中更新的整体时间排序值,将各个数据存储节点进行重新排序,以得到按照时间排序的第一结果链表,以通过第一结果链表记录所述唯一身份信息随着生成时间而排列的医疗数据信息。
优选地,所述数据处理方法,还包括:
获取从所述查询端口输入的唯一身份信息和疾病种类查询指令;
根据所述唯一身份信息调取对应的数据链表查询树;
根据调取出的所述数据链表查询树,得到各个所述ID码分别对应的多个数据链表;
按照各个不同的所述数据链表中的每个所述数据存储节点中的疾病种类序列单元中记录的疾病种类,提取不同的所述数据链表中符合查询疾病种类的数据存储节点;
将从不同的所述数据链表中提取出的数据存储节点按照生成时间单元中记录的生成时间进行重新排序,并将重新排序的结果记录在提取出的数据存储节点的时间序列单元中;
根据提取出的各个所述数据存储节点中的所述时间序列单元的排序值,将提取出的各个数据存储节点进行重新排序,以得到按照时间排序的第二结果链表,以通过第二结果链表记录所述唯一身份信息关于查询的疾病种类随着生成时间而排列的医疗数据信息。
优选地,所述为所述当前医疗数据对应分配当前存储地址的步骤,包括:
获取所述当前医疗数据需要的存储空间;
获取所述当前医疗数据对应的数据链表中,各个所述数据存储节点中所述存储地址单元中记录的存储地址;
获取各个所述存储地址在所述数据存储节点中出现的次数排序;
按照次数排序从多到少的顺序,依次查询每个存储地址的剩余存储空间;
当被查询的存储地址的剩余存储空间大于需要的存储空间时,将被查询的所述存储地址分配给所述当前医疗数据以作为当前存储地址。
优选地,所述为所述当前医疗数据对应分配当前存储地址,并将所述当前存储地址记录在所述存储地址单元的步骤之前,还包括:
在当前医疗数据为ID码的第一条医疗数据时,根据当前医疗数据计算ID码的预估存储空间,其中计算ID码的预估存储空间参照如下步骤进行:
从当前医疗数据中获取存储空间影响指标,以组成存储空间影响指标序列:
Y=[y
其中,Y为存储空间影响指标序列,M为存储空间影响指标总数,y
获取每一存储空间影响指标预计占用的存储空间大小,以及第一条医疗数据对应的疾病种类预计的随访时间和随访周期:
其中,X为预估存储空间,B
优选地,所述获取所述当前医疗数据对应的数据链表中,各个所述数据存储节点中所述存储地址单元中记录的存储地址的步骤之前,还包括:
在当前医疗数据对应的ID码没有对应设置数据链表时,从所述当前医疗数据提取数据特征;
将所述当前医疗数据的特征作为输入数据输入数据分析模型,以从所述数据分析模型输出所述当前医疗数据的冷热程度评级;
根据所述冷热程度评级,从各个可用的所述存储地址中为所述当前医疗数据分配所述当前存储地址。
优选地,通过以下步骤输出所述当前医疗数据的冷热程度评级:
遍历所述当前医疗数据,以从所述当前医疗数据中提取冷热特征,形成特征数组:
A=[a
其中,A为特征数组,n为特征总数,a
获取每个特征对应的特征值,根据所述特征值对各个特征评分,以形成评分数组:
F=[f
其中,F为评分数组,f
根据所述特征数组,确定每个特征对应的特征种类,并根据特征种类确定权重系数数组:
Q=[q
其中,Q为权重系数数组,q
根据所述特征数组、所述评分数组和所述权重系数数组,得到所述当前医疗数据的冷热程度评分:
其中,W为冷热程度评分;
W
优选地,所述数据处理方法,还包括:
获取数据链表在近期预设时间段内的查询次数,与最近一次查询时间;
当查询次数少于预设次数,且最近一次查询时间距离当前时间超过预设时长时,将所述数据链表对应的各个医疗数据从原存储地址转存至同一蓝光光盘进行离线存储;
将转存储蓝光光盘存储的各个医疗数据对应的数据存储节点中的存储地址单元修改为所述蓝光光盘。
此外,为实现上述目的,本发明还提出一种智能处理系统,应用如上述任一项所述的医疗大数据的数据处理方法。
本发明的技术方案中,只要在数据终端获取到当前医疗数据时,根据当前医疗数据对应的ID码,就查询到对应的数据链表,如果当前医疗数据属于ID码对应的第一项医疗数据,则获取到的数据链表为空链表,根据当前医疗数据新生成的数据存储节点为数据链表的第一个节点。每当该ID码又获取到新的医疗数据时,则为新的医疗数据又生成新的数据存储节点,从而,各个数据存储节点根据获取到的医疗数据的时间,在数据链表中依次排列。将同一ID码对应的所有医疗数据通过数据链表的形式组织起来,使得医疗大数据存储过程的数据实现有序管理。进一步的,每个数据存储节点都能体现该项医疗数据的顺序。例如,通过数据存储节点本身的排序可以记录各个医疗数据在数据终端的获取时间;通过数据存储节点的生成时间单元可以记录医疗数据的生成时间,通过时间序列单元可以体现该数据链表中所有医疗数据的生成时间排序;通过疾病种类序列单元可以体现该数据链表中所有医疗数据对应的不同疾病种类,而通过存储地址单元则可以确定数据链表中所有的医疗数据对应的存储地址。因此,通过数据链表的形式将同一ID码的医疗数据全部串联起来,且能通过生成时间单元、时间序列单元、疾病种类序列单元和存储地址单元体现各个医疗数据的关键序列信息。本发明中的数据处理方法,使得医疗大数据存储过程中按照独特的数据链表结构进行存储,数据链表记载了多方面的序列信息,有助于实现医疗大数据的有序存储。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图示出的结构获得其他的附图。
图1为本发明医疗大数据的数据处理方法一实施例的流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明,本发明实施例中所有方向性指示(诸如上、下、左、右、前、后……)仅用于解释在某一特定姿态(如附图所示)下各部件之间的相对位置关系、运动情况等,如果该特定姿态发生改变时,则该方向性指示也相应地随之改变。
另外,在本发明中如涉及“第一”、“第二”等的描述仅用于描述目的,而不能理解为指示或暗示其相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。在本发明的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。
在本发明中,除非另有明确的规定和限定,术语“连接”、“固定”等应做广义理解,例如,“固定”可以是固定连接,也可以是可拆卸连接,或成一体;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通或两个元件的相互作用关系,除非另有明确的限定。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本发明中的具体含义。
另外,本发明各个实施例之间的技术方案可以相互结合,但是必须是以本领域普通技术人员能够实现为基础,当技术方案的结合出现相互矛盾或无法实现时应当认为这种技术方案的结合不存在,也不在本发明要求的保护范围之内。
请参阅图1,在本发明的第一实施例中,该医疗大数据的数据处理方法,包括如下步骤:
步骤S10,在数据终端获取到当前医疗数据时,获取所述当前医疗数据对应的ID码,并获取所述ID码对应的数据链表,在所述数据链表中生成新的数据存储节点;其中,每个所述数据存储节点包括生成时间单元、时间序列单元、疾病种类序列单元和存储地址单元;
步骤S20,识别所述当前医疗数据的生成时间,将所述生成时间记录在所述数据存储节点的生成时间单元;
步骤S30,将所述当前医疗数据的生成时间与所述数据链表中存储的其他医疗数据的生成时间进行排序,以得到所述当前医疗数据的时间排序值,将所述时间排序值记录在新的所述数据存储节点的时间序列单元;
步骤S40,识别所述当前医疗数据的疾病种类,并将所述疾病种类记录在所述疾病种类序列单元;
步骤S50,为所述当前医疗数据对应分配当前存储地址,并将所述当前存储地址记录在所述存储地址单元。
本发明的技术方案中,只要在数据终端获取到当前医疗数据时,根据当前医疗数据对应的ID码,就查询到对应的数据链表,如果当前医疗数据属于ID码对应的第一项医疗数据,则获取到的数据链表为空链表,根据当前医疗数据新生成的数据存储节点为数据链表的第一个节点。每当该ID码又获取到新的医疗数据时,则为新的医疗数据又生成新的数据存储节点,从而,各个数据存储节点根据获取到的医疗数据的时间,在数据链表中依次排列。将同一ID码对应的所有医疗数据通过数据链表的形式组织起来,使得医疗大数据存储过程的数据实现有序管理。进一步的,每个数据存储节点都能体现该项医疗数据的顺序。例如,通过数据存储节点本身的排序可以记录各个医疗数据在数据终端的获取时间;通过数据存储节点的生成时间单元可以记录医疗数据的生成时间,通过时间序列单元可以体现该数据链表中所有医疗数据的生成时间排序;通过疾病种类序列单元可以体现该数据链表中所有医疗数据对应的不同疾病种类,而通过存储地址单元则可以确定数据链表中所有的医疗数据对应的存储地址。因此,通过数据链表的形式将同一ID码的医疗数据全部串联起来,且能通过生成时间单元、时间序列单元、疾病种类序列单元和存储地址单元体现各个医疗数据的关键序列信息。本发明中的数据处理方法,使得医疗大数据存储过程中按照独特的数据链表结构进行存储,数据链表记载了多方面的序列信息,有助于实现医疗大数据的有序存储。
数据终端可以是医疗机构的终端,或者存档机构的终端。
在本发明中,数据终端获取到当前医疗数据的时间,与当前医疗数据的生成时间,两者的概念并不相同。分为两种情况:
第一种情况,当前医疗数据是在数据终端新生成的,例如,当前医疗数据为医生在数据终端新建立的门诊病历,或者新开具的门诊处方,此时,数据终端获取当前医疗数据的时间,与当前医疗数据的生成时间相等。
第二种情况,当前医疗数据不是在数据终端新生成,只是由该数据终端作为上传的入口上传。此时,数据终端获取到当前医疗数据的时间,与当前医疗数据的生成时间不相等,例如,CT报告单在完成CT检查后的第一个工作日生成,但是可能到第三个工作日才上由数据终端上传,此时,当前医疗数据的生成时间为第一个工作日,数据终端获取到当前医疗数据的时间为第三个工作日,两者时间并不等同。此外,还有一种情况,例如,当前医疗数据可能是患者在其他医疗机构产生的,在当前的数据终端来录入。
因此,数据存储节点中的生成时间单元用于记录医疗数据的生成时间,能客观体现医疗数据的实际生成时间的先后顺序,从而数据存储节点中的生成时间单元能用于体现同一患者的医疗数据生成的时间脉络。
ID码可以是用户在数据终端的唯一识别码,例如,可以是卡号等。
步骤S10中,为每一新获取的医疗数据分别对应生成有一个数据存储节点,所以同一数据链表中各个数据存储节点,按照数据终端获取医疗数据的时间先后排列。
时间序列单元用于标记同一数据链表中各个数据存储节点关于医疗数据生成时间的排序。例如,数据链表中有三个数据存储节点,表示数据终端先后获取到关于该ID码的三条医疗数据,第一条医疗数据的生成时间为2021年9月,第二条医疗数据的生成时间为2020年1月,第三条医疗数据的生成时间为2019年12月,则三个数据存储节点中,第一个数据存储节点的时间序列单元记录的时间排序值为3,第二个数据存储节点的时间序列单元记录的时间排序值为2,第三个数据存储节点的时间序列单元记录的时间排序值为1。从而,本发明中,通过各个数据存储节点在数据链表中的排序体现数据终端获取医疗数据的时间,且通过每个数据存储节点中的时间序列单元体现医疗数据的生成时间的客观顺序,实现医疗大数据的有序存储。
当查询人员选择通过时间序列对数据链表排序时,数据链表中的各个数据存储节点按照时间序列排序。
所述疾病种类序列单元不仅体现医疗数据对应的疾病种类,还体现疾病种类的序列号。例如,当前医疗数据对应的疾病种类是糖尿病,而糖尿病在疾病种类中预设的序列号为501,则所述疾病种类序列单元中记录的数据为501-糖尿病。序列号可以根据预设规则设定,例如,序列号根据疾病种类的严重程度预设排序,将严重的疾病设置更靠前的序列号,而将不严重的普通疾病的序列号设置靠后的序列号。因此,通过数据链表中的疾病种类序列单元中的序列号,可以体现出需要优先关注的疾病种类对应的医疗数据。进一步的,在对数据链表中关于各个疾病种类序列单元进行排序时,则能将严重疾病对应的医疗数据都排列在前列,引起医护人员的关注。进一步的,序列号不仅能将严重疾病排列在前列,还能将序列号相同的医疗数据排列在一起,有助于医护人员对同一疾病的所有医疗数据随时间的变化过程摸排清楚。
当查询人员选择通过疾病种类序列对数据链表排序时,数据链表中的各个数据存储节点按照疾病种类序列列排序。
数据存储节点中还具有存储地址单元,体现医疗数据的存储地址。
基于本发明的第一实施例,本发明的第二实施例中,各个所述数据终端与云服务器信号连接,所述数据处理方法,还包括:
步骤S60,获取所述ID码对应的唯一身份信息,将所述ID码与所述唯一身份信息关联;
步骤S70,获取所述唯一身份信息在不同的所述数据终端分别关联的所述ID码所对应的全部数据链表,以生成用于记录所述唯一身份信息的全部医疗数据的数据链表查询树,其中,所述数据链表查询树的第一层级为唯一身份信息,第二层级为ID码,第三层级为数据链表。
具体的,唯一身份信息用于标记患者的独一无二的身份信息,唯一身份信息可以是:身份证号码或者个人生物特征信息(例如,指纹、人脸特征、虹膜等)。
具体的,同一个唯一的身份信息可能和不同的ID码对应,例如,同一身份证号在各个医疗机构可能都有就诊记录,在各个医疗机构都注册有就诊卡号。
当各个数据终端分别和云服务器信号连接时,通过其中一个所述数据终端输入唯一身份信息(例如,通过读取身份证信息、输入身份证号码、输入指纹、通过人脸识别输入人脸信息等),即可通过输入唯一身份信息的数据终端向云服务器查询该唯一身份信息对应的所有ID码,且将数据链表查询树作为查询结果输出。
数据链表查询树用于:将患者的所有医疗数据组织在一个树状结构数据中展示出来,使得患者的医疗数据条理清晰有序。第一层级的唯一身份信息体现医疗数据的归属,第二层级的ID码能够呈现患者的医疗数据分布点的总数量。进一步的,在第二层级中除了显示ID码之外,还可以呈现ID码对应的单位名称、地理位置,以及数据生成时间的起点至数据生成时间的终点。从而,通过数据链表查询树的第二层级,能够让查询人员区分每个数据链表对应的医疗数据的存储地点、存储单位和存储的医疗数据对应的数据生成时间阶段,从而更有针对性的去查阅第三层级的数据链表。
基于本发明的第二实施例,本发明的第三实施例中,所述数据处理方法,还包括:
步骤S80,将所述数据链表查询树存储至云服务器,且在各个与所述云服务器建立通讯的所述数据终端生成查询端口;
步骤S90,获取从所述查询端口输入的唯一身份信息和按时间查询指令;
步骤S100,根据所述唯一身份信息调取对应的数据链表查询树;
步骤S110,根据调取出的所述数据链表查询树,得到各个所述ID码分别对应的多个数据链表;
步骤S120,按照各个不同的所述数据链表中的每个所述数据存储节点中的生成时间单元中记录的生成时间,对所有的数据存储节点重新进行时间排序,得到每个数据存储节点的整体时间排序值,并将整体时间排序值更新在每个所述数据存储节点中的所述时间序列单元中;
步骤S130,根据各个数据存储节点中的所述时间序列单元中更新的整体时间排序值,将各个数据存储节点进行重新排序,以得到按照时间排序的第一结果链表,以通过第一结果链表记录所述唯一身份信息随着生成时间而排列的医疗数据信息。
具体的,每个数据终端可以根据自身获取的医疗数据生成数据链表,并将数据链表和医疗数据存储在数据终端中,还可以将数据链表和医疗数据存储在与数据终端连接的存储终端中。
在本实施例中,将所述数据链表查询树存储至云服务器,而每个数据链表对应的医疗数据可以存储在获取医疗数据的数据终端中或也可以存储在云服务器的存储空间中。
在本实施例中,根据按时间查询指令,将数据链表查询树中的所有数据存储节点按照生成时间重新排列,以得到一条第一结果链表,第一结果链表用于记录唯一身份信息随着生成时间而排列的医疗数据信息,从而,查询人员可以完整的获取到该患者随着时间推移的所有病史信息,从而梳理患者在不同时期的医疗信息。
在本实施例中可以体现:各个数据存储节点中的时间序列单元用于排列各个数据存储节点的顺序。具体的,在同一ID码对应的同一数据链表中,各个数据存储节点的时间序列单元体现的是每个数据存储节点在当前数据链表中的生成时间排序;在将唯一身份信息对应的多条数据链表整合成第一结果链表时,各个数据存储节点的时间序列单元体现的是每个数据存储节点在第一结果链表中的生成时间排序。第一结果链表有助于梳理患者随时间推移的身体状况变化情况。
进一步的,数据存储节点中还可以包括数据终端信息单元,以通过数据终端信息节点记录数据存储节点的来源属于哪个数据终端,以记载每个数据存储节点的归属。
基于本发明的第二实施例或第三实施例,本发明的第四实施例中,所述数据处理方法,还包括:
步骤S140,获取从所述查询端口输入的唯一身份信息和疾病种类查询指令;
步骤S150,根据所述唯一身份信息调取对应的数据链表查询树;
步骤S160,根据调取出的所述数据链表查询树,得到各个所述ID码分别对应的多个数据链表;
步骤S170,按照各个不同的所述数据链表中的每个所述数据存储节点中的疾病种类序列单元中记录的疾病种类,提取不同的所述数据链表中符合查询疾病种类的数据存储节点;
步骤S180,将从不同的所述数据链表中提取出的数据存储节点按照生成时间单元中记录的生成时间进行重新排序,并将重新排序的结果记录在提取出的数据存储节点的时间序列单元中;
步骤S190,根据提取出的各个所述数据存储节点中的所述时间序列单元的排序值,将提取出的各个数据存储节点进行重新排序,以得到按照时间排序的第二结果链表,以通过第二结果链表记录所述唯一身份信息关于查询的疾病种类随着生成时间而排列的医疗数据信息。
每一个唯一身份信息对应的第一结果链表仅有一条,用于记录患者随着时间而推移的所有医疗数据。
而每一个唯一身份信息对应的第二结果链表可以有多条,且每一种疾病种类对应一条第二结果链表,且每一种疾病种类对应的第二结果链表中的各个数据存储节点均按照生成时间排序。因此,第二结果链表有助于查询人员梳理患者在具体疾病种类中随着时间推移而生成的医疗数据,以确定患者身体在具体疾病种类中的发展情况。
基于本发明的第一实施例至第四实施例,本发明的第五实施例中,所述步骤S50中的为所述当前医疗数据对应分配当前存储地址的步骤,包括:
步骤S51,获取所述当前医疗数据需要的存储空间;
步骤S52,获取所述当前医疗数据对应的数据链表中,各个所述数据存储节点中所述存储地址单元中记录的存储地址;
步骤S53,获取各个所述存储地址在所述数据存储节点中出现的次数排序;
步骤S54,按照次数排序从多到少的顺序,依次查询每个存储地址的剩余存储空间;
步骤S55,当被查询的存储地址的剩余存储空间大于需要的存储空间时,将被查询的所述存储地址分配给所述当前医疗数据以作为当前存储地址。
本实施例用于实现统一数据链表中各医疗数据的集中存储。
所述步骤S50之前,还包括:
在当前医疗数据为ID码的第一条医疗数据时,根据当前医疗数据计算ID码的预估存储空间,其中计算ID码的预估存储空间参照如下步骤进行:
从当前医疗数据中获取存储空间影响指标,以组成存储空间影响指标序列:
Y=[y
其中,Y为存储空间影响指标序列,M为存储空间影响指标总数,y
获取每一存储空间影响指标预计占用的存储空间大小,以及第一条医疗数据对应的疾病种类预计的随访时间和随访周期:
其中,X为预估存储空间,B
Z
进一步的,之所以要根据ID码的第一条医疗数据计算该ID码的预估存储空间,也是为了为该ID码的医疗数据预留一个专用存储区块,以便于数据的统一存储。并且同一ID码的医疗数据具有类似的冷热属性和查询规律,便于从同一存储区块中调取同一患者的医疗数据,也便于后期对同一患者的医疗数据进行整体转储、迁移或删除。
更进一步的,在计算该ID码的预估存储空间后,每当获取到该ID码的另一医疗数据,则向专用存储区块中进行存储,直至该专用存储区块中存储空间不足为止。
作为本实施例的扩展,根据该ID码的医疗数据获取规律,还可以对专用存储区块进行扩大或者缩小。例如,根据该ID码的医疗数据更新频率与标准频率的比值,校正所述专用存储区块的空间大小。
其中,X'为校正存储空间,v
所述存储空间影响指标是根据疾病信息确定的占用存储空间的指标,其可以包括:病历、处方、每一检查报告类型(例如心电、超声、影像)、检验报告类型(例如血、尿、粪)。
基于本发明的第五实施例,本发明的第六实施例中,所述步骤S52之前,还包括:
步骤S56,在当前医疗数据对应的ID码没有对应设置数据链表时,从所述当前医疗数据提取数据特征;
步骤S57,将所述当前医疗数据的特征作为输入数据输入数据分析模型,以从所述数据分析模型输出所述当前医疗数据的冷热程度评级;
步骤S58,根据所述冷热程度评级,从各个可用的所述存储地址中为所述当前医疗数据分配所述当前存储地址。
具体的,可以根据冷热程度评级分为至少三个冷热层级:冷数据、温数据和热数据。
根据所述冷热程度评级,将冷热程度相近的医疗数据存储于同一存储介质,有助于当存储介质上的医疗数据存满后,或者当存储介质上的医疗数据达到预设的转存条件时,将该存储介质上的数据统一转存到其他的长期存储介质上。
基于本发明的第六实施例,本发明的第七实施例中,通过以下步骤输出所述当前医疗数据的冷热程度评级:
遍历所述当前医疗数据,以从所述当前医疗数据中提取冷热特征,形成特征数组:
A=[a
其中,A为特征数组,n为特征总数,a
获取每个特征对应的特征值,根据所述特征值对各个特征评分,以形成评分数组:
F=[f
其中,F为评分数组,f
根据所述特征数组,确定每个特征对应的特征种类,并根据特征种类确定权重系数数组:
Q=[q
其中,Q为权重系数数组,q
根据所述特征数组、所述评分数组和所述权重系数数组,得到所述当前医疗数据的冷热程度评分:
其中,W为冷热程度评分;
W
其中,冷热特征为影响数据被查询次数的数据,冷热特征可以为:年龄、疾病种类、疾病种类等级(例如,肺结节的等级)、检验报告指标值的异常程度、随访周期、诊疗效果、既往病史、诊疗意见。
冷热特征不以此为限,凡是可能影响到医疗数据被查询次数的数据,均可设定为冷热特征,且冷热特征可以在医疗数据的存储过程中新增,以调整预估存储空间的大小。
基于本发明的第一实施例至第七实施例,本发明的第八实施例中,所述数据处理方法,还包括:
步骤S200,获取数据链表在近期预设时间段内的查询次数,与最近一次查询时间;
步骤S210,当查询次数少于预设次数,且最近一次查询时间距离当前时间超过预设时长时,将所述数据链表对应的各个医疗数据从原存储地址转存至同一蓝光光盘进行离线存储;
步骤S220,将转存储蓝光光盘存储的各个医疗数据对应的数据存储节点中的存储地址单元修改为所述蓝光光盘。
蓝光光盘是一种光存储介质,存储寿命长、安全性高且存储能耗低。将长期不使用的医疗数据转存到蓝光光盘进行离线存储有助于清理云服务器和数据终端的存储空间,以存储更新的医疗数据。
但是,数据链表相当于是一个医疗数据信息的摘录信息,其占用存储空间小,因此,仍然存储在数据终端或者云服务器中。从而,查询人员仍然可以通过查询ID号调取对应的数据链表,或者查询唯一身份信息调取用于记录所述唯一身份信息的全部医疗数据的数据链表查询树,以通过数据链表或者数据链表查询树确定患者随着时间推移的身体状况,以及患者具体疾病类型随着时间推移的进展情况。因此,本发明的技术方案通过独特的数据链表形式记录医疗大数据的信息摘要,使得医疗大数据的存储清晰而有序,并且,数据链表采用独特的数据存储节点记录各条医疗数据之间的关联,能通过时间序列单元和疾病种类序列单元整理医疗大数据中每一患者数据的顺序。
此外,为实现上述目的,本发明还提出一种智能处理系统,应用上述任一项所述的医疗大数据的数据处理方法。
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是在本发明的构思下,利用本发明说明书及附图内容所作的等效结构变换,或直接/间接运用在其他相关的技术领域均包括在本发明的专利保护范围内。