信息处理方法、装置、设备及存储介质
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及无线技术领域,尤其涉及一种信息处理方法、装置、设备及存储介质。
背景技术
目前,结构化类型数据在企业内、外部共享的场景越来越多。在数据共享的过程中,需要水印手段来保护发布方的版权以及保证共享给第三方的数据不会被第三方泄露或倒卖。目前,在结构化数据中添加水印的方式,可能会出现易被识别导致破坏问题的发生,鲁棒性较差,无法抵抗针对水印的攻击。
发明内容
有鉴于此,本发明实施例期望提供一种信息处理方法、装置、设备及存储介质。
本发明实施例的技术方案是这样实现的:
本发明的至少一个实施例提供了一种信息处理方法,所述方法包括:获取水印信息和结构化数据集;
对所述水印信息进行分割,得到N个水印分片;并对所述结构化数据集中的元组数据进行分组,得到两个第一分组;每个第一分组包含N个第二分组;N为正整数;
针对每个第一分组,生成与相应第一分组中各个第二分组对应的伪行数据,得到与相应第一分组对应的N个伪行数据;
针对每个第一分组,将所述N个水印分片分别嵌入到与相应第一分组对应的N个伪行数据中。
此外,根据本发明的至少一个实施例,所述对所述水印信息进行分割,得到N个水印分片,包括:
对水印信息进行编码,得到多个编码值;
将多个编码值转换为N个水印分片。
此外,根据本发明的至少一个实施例,所述对所述结构化数据集中的元组数据进行分组,包括:
针对所述结构化数据集中每个元组数据,利用相应元组数据对应的主键,确定第一值;
根据所述第一值,确定相应元组数据所属的第二分组;
利用相应元组数据对应的主键,确定相应元组数据所属的第二分组对应的第一分组。
此外,根据本发明的至少一个实施例,所述利用相应元组数据对应的主键,确定相应元组数据所属的第二分组对应的第一分组,包括:
在相应元组数据对应的主键为偶数的情况下,确定相应元组数据所属的第二分组属于两个第一分组中的一个分组;
在相应元组数据对应的主键为奇数的情况下,确定相应元组数据所属的第二分组属于两个第一分组中的另外一个分组。
此外,根据本发明的至少一个实施例,所述将N个水印分片分别嵌入到与相应第一分组中各个第二分组对应的N个伪行数据中,包括:
确定第i个水印分片的第二值;
确定相应第一分组中第i个第二分组中各元组数据的第一属性值,得到与第i个第二分组对应的多个第一属性值;
利用与第i个第二分组对应的多个第一属性值,以及第i个水印分片的第二值,确定与第i个第二分组对应的第i个伪行数据的第二属性值;
确定与第i个第二分组对应的第i个伪行数据的主键值;
以此类推,直至确定完相应第一分组中每个第二分组对应的伪行数据的第二属性和主键值,从而将N个水印分片分别嵌入到与相应第一分组中各个第二分组对应的N个伪行数据中;
其中,i=1,2,…,N。
本发明的至少一个实施例提供一种信息处理方法,所述方法还包括:
针对结构化数据集的两个第一分组中每个第一分组,从相应第一分组的各个第二分组中分别提取N个水印分片;
若从两个第一分组中分别提取的N个水印分片的数值均相等,则基于两个第一分组中任意一组对应的N个水印分片,得到水印信息。
此外,根据本发明的至少一个实施例,所述从相应第一分组的各个第二分组中分别提取N个水印分片,包括:
从相应第一分组的第i个第二分组中提取得到多个属性值;
基于所述多个属性值,确定与第i个第二分组对应的第i个水印分片的值;
以此类推,直至从相应第一分组的各个第二分组中分别提取N个水印分片的值;
其中,i=1,2,…,N。
本发明的至少一个实施例提供一种信息处理装置,包括:
获取单元,用于获取水印信息和结构化数据集;
第一处理单元,用于对所述水印信息进行分割,得到N个水印分片;并对所述结构化数据集中的元组数据进行分组,得到两个第一分组;每个第一分组包含N个第二分组;N为正整数;
第二处理单元,用于针对每个第一分组,生成与相应第一分组中各个第二分组对应的伪行数据,得到与相应第一分组对应的N个伪行数据;
第三处理单元,用于针对每个第一分组,将所述N个水印分片分别嵌入到与相应第一分组对应的N个伪行数据中。
本发明的至少一个实施例提供一种信息处理装置,包括:
第四处理单元,用于针对结构化数据集的两个第一分组中每个第一分组,从相应第一分组的各个第二分组中分别提取N个水印分片;
第五处理单元,用于若从两个第一分组中分别提取的N个水印分片的数值均相等,则基于两个第一分组中任意一组对应的N个水印分片,得到水印信息。
本发明的至少一个实施例提供一种第一电子设备,包括:
第一通信接口,获取水印信息和结构化数据集;
第一处理器,用于对所述水印信息进行分割,得到N个水印分片;并对所述结构化数据集中的元组数据进行分组,得到两个第一分组;每个第一分组包含N个第二分组;N为正整数;针对每个第一分组,生成与相应第一分组中各个第二分组对应的伪行数据,得到与相应第一分组对应的N个伪行数据;针对每个第一分组,将所述N个水印分片分别嵌入到与相应第一分组对应的N个伪行数据中。
本发明的至少一个实施例提供一种第二电子设备,包括:
第二通信接口,
第二处理器,用于针对结构化数据集的两个第一分组中每个第一分组,从相应第一分组的各个第二分组中分别提取N个水印分片;
若从两个第一分组中分别提取的N个水印分片的数值均相等,则基于两个第一分组中任意一组对应的N个水印分片,得到水印信息。
本发明的至少一个实施例提供一种第一电子设备,包括第一处理器和用于存储能够在第一处理器上运行的计算机程序的第一存储器,
其中,所述第一处理器用于运行所述计算机程序时,执行上述第一电子设备侧任一方法的步骤。
本发明的至少一个实施例提供一种第二电子设备,包括第二处理器和用于存储能够在第二处理器上运行的计算机程序的第二存储器,
其中,所述第二处理器用于运行所述计算机程序时,执行上述第二电子设备侧任一方法的步骤。
本发明的至少一个实施例提供一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述任一方法的步骤。
本发明实施例提供的信息处理方法、装置、设备及存储介质,获取水印信息和结构化数据集;对所述水印信息进行分割,得到N个水印分片;并对所述结构化数据集中的元组数据进行分组,得到两个第一分组;每个第一分组包含N个第二分组;N为正整数;针对每个第一分组,生成与相应第一分组中各个第二分组对应的伪行数据,得到与相应第一分组对应的N个伪行数据;针对每个第一分组,将所述N个水印分片分别嵌入到与相应第一分组对应的N个伪行数据中。采用本发明实施例提供的技术方案,将水印信息以伪行数据的形式插入到结构化数据集中,由于插入的伪行均不相同,因此不容易被识别破坏,具有较强的鲁棒性,能够抵抗针对水印的攻击。
附图说明
图1是本发明实施例信息处理方法的实现流程示意图一;
图2是本发明实施例信息处理方法的具体实现流程示意图;
图3是本发明实施例对结构化数据集中的元素数据进行分组的示意图;
图4是本发明实施例信息处理方法的实现流程示意图二;
图5是本发明实施例信息处理装置的组成结构示意图一;
图6是本发明实施例信息处理装置的组成结构示意图二;
图7是本发明实施例第一电子设备的组成结构示意图;
图8是本发明实施例第二电子设备的组成结构示意图。
具体实施方式
在对本发明实施例的技术方案进行介绍之前,先对相关技术进行说明。
相关技术中,数字水印是进行版权保护的一种技术手段,针对图片、视频、音频等类型的数据,业界已经有了很成熟的水印方案,而针对结构化数据的水印方案相对较少。随着数据成为企业的一种资产形式,为了更好的发挥数据价值,避免出现数据孤岛问题,结构化类型数据在企业内、外部共享的场景越来越多。在数据共享的过程中,需要水印手段来保护发布方的版权以及保证共享给第三方的数据不会被第三方泄露或倒卖。
发明名称为一种数值型关系数据库水印的嵌入及提取验证方法、公开号为CN104866735A的专利,公开了:对数值型关系数据库的模式和数据分析,数字水印生成及嵌入,以及数字水印的检测方法。本发明针对数值型关系数据库的特点,能够高效动态的对数据均匀的注入数字水印信息,并且在不需要源数据的情况下,提取出数字水印信息。所述的方法采用了密钥加密和抗重排序等技术,能够有效的抵抗各类去水印攻击,能够保证在低于50%的行修改情况下不会丢失水印。
发明名称为一种基于伪行伪列的水印处理和数据溯源方法、公开号为CN107992726A)的专利,公开了:数据库初始化步骤:根据发现规则对数据进行自动发现,抽取指定的数据集合,生成数据子集;对生成的数据子集进行水印处理步骤:添加伪行数据、伪列数据并根据字段规则特征实现数据水印的嵌入,生成带有水印标记的数据。本发明设计合理,能够提高数据共享过程中的安全防护能力,实现数据水印的嵌入和泄露数据的溯源,具有安全性能高、数据损失小且不容易被破坏等特点,因此在数据库安全领域具有广泛的应用场景。
发明名称为一种鲁棒性的基于分组的数字水印方法的专利,公开了:S1、水印预处理阶段,基于无监督学习方法的数据集分组,完成数据预处理和水印预处理;S2、水印嵌入阶段,将水印嵌入到数据库中的特定位置;S3、水印提取阶段,将水印从数据库中提取出来。
综上所述,第一个专利中,水印信息插入在数据属性的最低有效位,如果最低有效位被删除,则水印会失效,且水印的插入需要修改原数据属性值,在一定程度上会对业务产生影响。第二个专利中,水印值根据候选字段的特征定义,是随机的,未进行水印编码,不够直观。并且需要记录生成的随机水印,用于水印提取时的对比,易用性较差。另外,插入的多个伪行都是相同的,水印易被识别破坏。第三个专利,同样插入在数据属性的最低有效位,对原始数据存在改动,造成数据失真,影响数据可用性。同时,如果最低有效位被删除,则水印会失效。
另外,调研发现,普遍存在的水印添加方式是为不同的水印信息生成不同的伪行伪列信息,并通过一定方式记录水印信息与伪行伪列的映射关系,在提取水印阶段,通过比对伪行伪列,识别对应的水印信息。
相关技术中,在结构化数据中添加水印的方式,可能会出现易被识别导致破坏问题的发生,鲁棒性较差,无法抵抗针对水印的攻击。
基于此,本发明实施例中,获取水印信息和结构化数据集;对所述水印信息进行分割,得到N个水印分片;并对所述结构化数据集中的元组数据进行分组,得到两个第一分组;每个第一分组包含N个第二分组;N为正整数;针对每个第一分组,生成与相应第一分组中各个第二分组对应的伪行数据,得到与相应第一分组对应的N个伪行数据;针对每个第一分组,将所述N个水印分片分别嵌入到与相应第一分组对应的N个伪行数据中。
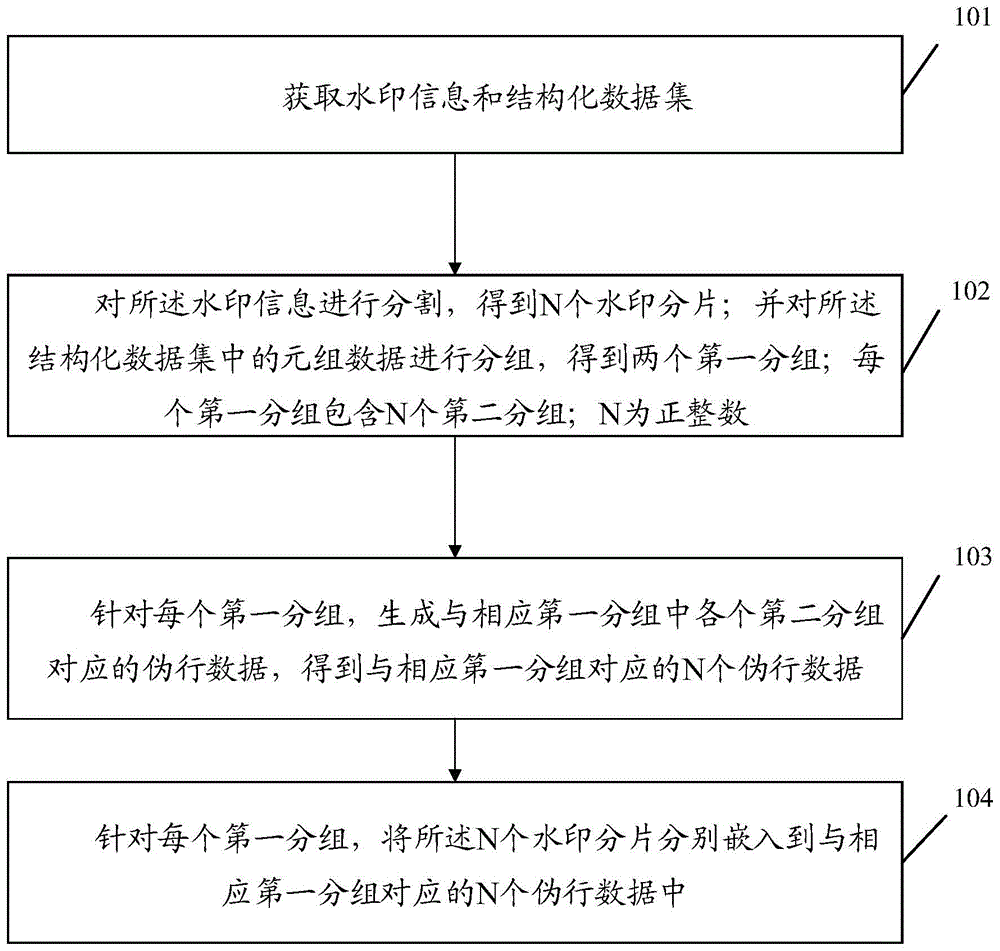
图1是本发明实施例信息处理方法的实现流程示意图,如图1所示,所述方法包括步骤101至步骤104:
步骤101:获取水印信息和结构化数据集。
可以理解的是,所述水印信息可以是指由数字、字母、特殊字符构成的多个字符。
举例来说,所述水印信息可以为:cmri、中国,等。
可以理解的是,所述结构化数据集可以是指包含结构化数据的集合。所述结构化数据可以是指以固定格式存在的数据。
可以理解的是,所述获取水印信息,可以是指从本地存储的多个水印信息中随机选取一个水印信息。
步骤102:对所述水印信息进行分割,得到N个水印分片;并对所述结构化数据集中的元组数据进行分组,得到两个第一分组;每个第一分组包含N个第二分组;N为正整数。
可以理解的是,所述元组数据可以是指所述结构化数据集中的一行结构化数据。
可以理解的是,所述第一分组可以是指大组,所述第二分组可以是指小组。
也就是说,将所述结构化数据集中的元组数据划分为两个大组,每个大组中包含N个小组。
在一实施例中,所述获取水印信息和结构化数据集,并对所述水印信息进行分割,得到N个水印分片,包括:
对水印信息进行编码,得到多个编码值;
将多个编码值转换为N个水印分片。
可以理解的是,所述对所述水印信息进行编码,得到多个编码值,具体可以是指:针对所述水印信息中每个字符,对相应字符进行编码,得到对应的编码值,从而得到多个编码值。其中,所述编码值可以为数值型数据,且取值范围可以为0到255。
进一步地,可以采用公开的编码规则或自定义的编码规则对所述水印信息中每个字符进行编码。例如,采用所述ASCII编码对每个字符进行编码。
可以理解的是,可以使用门限秘密分享算法,将多个编码值转换为N个水印分片。其中,所述门限秘密分享算法包括不限于shamir秘密分享方案、基于中国剩余定理的秘密分享方案等。
实际应用时,考虑到每个元组数据的主键不同,因此,可以基于每个元组数据的主键,来区分每个元组数据对应的小组。另外,考虑到每个元组数据的主键可以是偶数或者可以是奇数,因此,可以根据每个元组数据的主键的奇偶性,来确定每个元组数据对应的小组所属的大组。
基于此,在一实施例中,所述对所述结构化数据集中的元组数据进行分组,包括:
针对所述结构化数据集中每个元组数据,利用相应元组数据对应的主键,确定第一值;
根据所述第一值,确定相应元组数据所属的第二分组;
利用相应元组数据对应的主键,确定相应元组数据所属的第二分组对应的第一分组。
可以理解的是,所述利用相应元组数据对应的主键,确定相应元组数据所属的第二分组对应的第一分组,具体可以包括:
在相应元组数据对应的主键为偶数的情况下,确定相应元组数据所属第二分组属于两个第一分组中的一个分组;
在相应元组数据对应的主键为奇数的情况下,确定相应元组数据所属第二分组属于两个第一分组中的另外一个分组。
步骤103:针对每个第一分组,生成与相应第一分组中各个第二分组对应的伪行数据,得到与相应第一分组对应的N个伪行数据。
可以理解的是,所述伪行数据可以是指不记录实际数据的数据。
举例来说,假设N等于10,两个第一分组均包含10个第二分组,则得到20个伪行数据的过程,具体可以包括:
针对第一个第一分组中的10个第二分组,分别生成与10个第二分组对应的伪行数据,得到10个伪行数据。
针对第二个第一分组的10个第二分组,分别生成与10个第二分组对应的伪行数据,得到10个伪行数据。
步骤104:针对每个第一分组,将所述N个水印分片分别嵌入到与相应第一分组对应的N个伪行数据中。
举例来说,假设N等于3,两个第一分组均包含3个第二分组,则在两个第一分组中分别嵌入3个水印分片的过程,具体可以包括:
针对第一个第一分组中的3个第二分组,分别生成与3个第二分组对应的伪行数据,得到3个伪行数据;并将分割得到的3个水印分片分别嵌入到这3个伪行数据中。
针对第二个第一分组中的3个第二分组,分别生成与3个第二分组对应的伪行数据,得到3个伪行数据;并将分割得到的3个水印分片分别嵌入到这3个伪行数据中。
本发明实施例中,将分割得到的N个水印分片分别嵌入到两个第一分组对应的N个伪行数据中,具备以下优点:
(1)将水印信息以伪行数据的形式插入到结构化数据集中,由于插入的伪行均不相同,因此不容易被识别破坏或删除,具有较强的鲁棒性,能够抵抗针对水印的攻击。
(2)利用门限秘密分享算法,将水印信息进行分片,即使丢失一些水印行,只要有效行数达到设定好的阈值,可以提取出水印信息。
(3)根据公开的编码规则,对水印编码后插入数据集中,提取出的水印可根据公开规则还原为有意义的水印信息,易于提取识别,且不需要记录随机生成的水印。
图2是本发明实施例信息处理方法的具体实现流程示意图,如图2所示,所述方法包括步骤201至步骤205:
步骤201:获取水印信息和结构化数据集。
步骤202:对所述水印信息进行分割,得到N个水印分片;N为正整数。
步骤203:针对所述结构化数据集中每个元组数据,利用相应元组数据对应的主键,确定第一值;根据所述第一值,确定相应元组数据所属的第二分组;利用相应元组数据对应的主键,确定相应元组数据所属的第二分组对应的第一分组。
图3是对结构化数据集中的元素数据进行分组的示意图,如图3所示,假设结构化数据集D由m个元组数据即d1,d2,…,dm组成,则按照下面公式(1)计算第一值d:
其中,di表示d1,d2,…,dm中任意一个元组数据;P表示元组数据di的主键;key表示密钥,N表示水印分片数。
如此,根据计算的d,可以确定元组数据di所属的第二分组的组号。
进一步地,
如果元组数据di的主键P为偶数,则该元组数据di对应的第二分组属于两个第一分组中的一个第一分组,用0.0组表示。
如果元组数据di的主键P为奇数,则该元组数据di对应的第二分组属于两个第一分组中的另外一个第一分组,用0.1组表示。
表1是对结构化数据集中的元组数据进行分组的示意,如表1所示,假设机构化数据集包括元组数据d1、元组数据d2、元组数据d3、元组数据d4,元组数据d1属于0.0组下的i=1组;元组数据d2属于0.0组下的i=4组;元组数据d3属于0.1组下的i=1组;元组数据d4属于0.1组下的i=4组。
表1
步骤204:针对每个第一分组,生成与相应第一分组中各个第二分组对应的伪行数据,得到与相应第一分组对应的N个伪行数据。
步骤205:针对每个第一分组,将所述N个水印分片分别嵌入到与相应第一分组对应的N个伪行数据中。
可以理解的是,所述将N个水印分片分别嵌入到与相应第一分组中各个第二分组对应的N个伪行数据中,具体可以包括:
确定第i个水印分片的第二值;
确定相应第一分组中第i个第二分组中各元组数据的第一属性值,得到与第i个第二分组对应的多个第一属性值;
利用与第i个第二分组对应的多个第一属性值,以及第i个水印分片的第二值,确定与第i个第二分组对应的第i个伪行数据的第二属性值;
确定与第i个第二分组对应的第i个伪行数据的主键值;
以此类推,直至确定完相应第一分组中每个第二分组对应的伪行数据的第二属性和主键值,从而将N个水印分片分别嵌入到与相应第一分组中各个第二分组对应的N个伪行数据中;
其中,i=1,2,…,N。
举例来说,两个第一分组中的一个第一分组,用0.0组表示,另外一个第一分组,用0.1组表示。
下面以第0.0组为例,描述将所述N个水印分片分别嵌入到与第0.0组对应的N个伪行数据中的过程。
假设第0.0组中第i个第二分组中各元组数据的第一属性值,用A表示,A的值具体为n1,n2,…,nj,即与第i个第二分组对应的多个第一属性值。其中,i=1,2,…,N。
按照下面公式(2)计算与第i个第二分组对应的第i个伪行数据的第二属性值:
(n1+n2+…+nj+x)mod M=Ni(2)
其中,x表示与第i个第二分组对应的第i个伪行数据的第二属性值;n1,n2,…,nj表示与第i个第二分组对应的多个第一属性值;M表示一个较大正整数,可根据结构化数据集D的数据大小进行选择;Ni表示第i个水印分片的值。
按照下面公式(3)确定与第i个第二分组对应的第i个伪行数据的主键值:
其中,d.P表示与第i个第二分组对应的第i个伪行数据的主键值,且该主键值需要满足是偶数;key表示密钥;N表示水印分片数;i表示第二个分组的编号。
如此,将与第i个第二分组对应的第i个伪行数据的第二属性列的值置为x,然后,将第i个伪行数据插入第i个第二分组中的随机一行,如此,第0.0组的第i个第二分组中的数据由原生的元组数据和随机插入的第i个伪行数据组成。其中,第i个伪行数据嵌入了第i个水印分片。
以此类推,在第0.0组的其他第二分组对应的伪行数据中分别嵌入对应的水印分片,从而完成将所述N个水印分片分别嵌入到与第0.0组对应的N个伪行数据中。
下面以第0.1组为例,描述将所述N个水印分片分别嵌入到与第0.0组对应的N个伪行数据中的过程。
假设第0.1组中第i个第二分组中各元组数据的第一属性值,用A表示,A的值具体为m1,m2,…,mi,即与第i个第二分组对应的多个第一属性值。其中,i=1,2,…,N。
按照下面公式(4)计算与第i个第二分组对应的第i个伪行数据的第二属性值:
(m1+m2+…+mi+x)mod M=Ni (4)
其中,x表示与第i个第二分组对应的第i个伪行数据的第二属性值;m1,m2,…,mi表示与第i个第二分组对应的多个第一属性值;M表示一个较大正整数,可根据结构化数据集D的数据大小进行选择;Ni表示第i个水印分片的值。
按照下面公式(5)确定与第i个第二分组对应的第i个伪行数据的主键值:
其中,d.P表示与第i个第二分组对应的第i个伪行数据的主键值,且该主键值需要满足是奇数;key表示密钥;N表示水印分片数;i表示第二个分组的编号。
如此,将与第i个第二分组对应的第i个伪行数据的第二属性列的值置为x,然后,将第i个伪行数据插入第i个第二分组中的随机一行,如此,第0.0组的第i个第二分组中的数据由原生的元组数据和随机插入的第i个伪行数据组成。其中,第i个伪行数据嵌入了第i个水印分片。
以此类推,在第0.1组的其他第二分组对应的伪行数据中分别嵌入对应的水印分片,从而完成将所述N个水印分片分别嵌入到与第0.1组对应的N个伪行数据中。
本示例中,将水印信息分割得到N个水印分片,将结构化数据集划分为两个第一分组,每个第一分组包含N个第二分组,具备以下优点:
(1)将数据分组以及将水印分片后,通过设计特殊的计算方法推导出二次水印信息嵌入分组,且通过伪行的方式进行水印嵌入,嵌入不会对原始数据进行改动,且采用了门限密码算法具有较好的鲁棒性。
(2)使用每片水印嵌入两次的方法,提取时仅嵌入的两片水印相同才作为待提取水印,具有良好的准确性。
图4是本发明实施例信息处理方法的实现流程示意图,如图4所示,所述方法包括步骤401至步骤402:
步骤401:针对结构化数据集的两个第一分组中每个第一分组,从相应第一分组的各个第二分组中分别提取N个水印分片。
可以理解的是,从所述结构化数据集的两个第一分组中各提取N个水印分片,可以得到2N个水印分片。
可以理解的是,所述从相应第一分组的各个第二分组中分别提取N个水印分片,具体可以包括:
从相应第一分组的第i个第二分组中提取得到多个属性值;
基于所述多个属性值,确定与第i个第二分组对应的第i个水印分片的值;
以此类推,直至从相应第一分组的各个第二分组中分别提取N个水印分片的值;
其中,i=1,2,…,N。
按照下面公式(6)计算结构数据集D中每i个元组数据对应的第二分组的组号:
其中,i表示元组数据di对应的第二分组的组号;di表示d1,d2,…,dm中任意一个元组数据;P表示元组数据di的主键;key表示密钥,N表示水印分片数。
如果元组数据di的主键P为偶数,则该元组数据di对应的第二分组属于两个第一分组中的一个第一分组,用0.0组表示。
如果元组数据di的主键P为奇数,则该元组数据di对应的第二分组属于两个第一分组中的另外一个第一分组,用0.1组表示。
下面以第0.0组为例,描述从与第0.0组对应的各个第二分组中提取N个水印分片的过程。
按照下面公式(7)计算第0.0组中第i个第二分组对应的第i个水印分片的值:
L0.0=(n1+n2+…+nj+n
其中,L0.0表示第0.0组中第i个第二分组对应的第i个水印分片的值,i=1,2,…,N;n1,n2,…,nj,n
以此类推,直到从第0.0组的各个第二分组中提取出N个水印分片的值。
下面以第0.1组为例,从与第0.0组对应的各个第二分组中提取N个水印分片的过程。
按照下面公式(8)计算第0.1组中第i个第二分组对应的第i个水印分片的值:
L0.1=(m1+m2+…+mi+m
其中,L0.1表示第0.1组中第i个第二分组对应的第i个水印分片的值,i=1,2,…,N。m1,m2,…,mi,m
以此类推,直到从第0.1组的各个第二分组中提取出N个水印分片的值。
步骤402:若从两个第一分组中分别提取的N个水印分片的数值均相等,则基于两个第一分组中任意一组对应的N个水印分片,得到水印信息。
举例来说,假设两个第一分组分别用0.0和0.1表示,得到水印信息的过程,可以包括:
将0.0组中第i个第二分组对应的第i个水印分片的值即L0.0与0.1组中第i个第二分组对应的第i个水印分片的值即L0.1进行比较,如果L0.0=L0.1,则将L0.0或L0.1存储在预先设置的一维数组s中,i=1,2,3,…,N。
判断数组s中数据个数是否不少于N个;如果数组s中的数据个数大于或等于N个,则使用门限秘密分享算法,将数组s中的所有水印分片的值进行重组,从而得到水印信息。如果数组s中的数据个数小于N个,则丢弃提取的2N个水印分片。
本示例中,提取水印信息,具备以下优点:
使用每片水印嵌入两次的方法,提取时仅嵌入的两片水印相同才作为待提取水印,具有良好的准确性。
为实现本发明实施例信息处理方法,本发明实施例还提供一种信息处理装置,设置在第一电子设备上。图5为本发明实施例信息处理装置的组成结构示意图,如图5所示,所述装置包括:
获取单元51,用于获取水印信息和结构化数据集;
第一处理单元52,用于对所述水印信息进行分割,得到N个水印分片;并对所述结构化数据集中的元组数据进行分组,得到两个第一分组;每个第一分组包含N个第二分组;N为正整数;
第二处理单元53,用于针对每个第一分组,生成与相应第一分组中各个第二分组对应的伪行数据,得到与相应第一分组对应的N个伪行数据;
第三处理单元54,用于针对每个第一分组,将所述N个水印分片分别嵌入到与相应第一分组对应的N个伪行数据中。
在一实施例中,所述第一处理单元52,具体用于:
对水印信息进行编码,得到多个编码值;
将多个编码值转换为N个水印分片。
在一实施例中,所述第一处理单元52,具体用于:
针对所述结构化数据集中每个元组数据,利用相应元组数据对应的主键,确定第一值;
根据所述第一值,确定相应元组数据所属的第二分组;
利用相应元组数据对应的主键,确定相应元组数据所属的第二分组对应的第一分组。
在一实施例中,所述第一处理单元52,具体用于:
在相应元组数据对应的主键为偶数的情况下,确定相应元组数据所属的第二分组属于两个第一分组中的一个分组;
在相应元组数据对应的主键为奇数的情况下,确定相应元组数据所属的第二分组属于两个第一分组中的另外一个分组。
在一实施例中,所述第三处理单元54,具体用于:
确定第i个水印分片的第二值;
确定相应第一分组中第i个第二分组中各元组数据的第一属性值,得到与第i个第二分组对应的多个第一属性值;
利用与第i个第二分组对应的多个第一属性值,以及第i个水印分片的第二值,确定与第i个第二分组对应的第i个伪行数据的第二属性值;
确定与第i个第二分组对应的第i个伪行数据的主键值;
以此类推,直至确定完相应第一分组中每个第二分组对应的伪行数据的第二属性和主键值,从而将N个水印分片分别嵌入到与相应第一分组中各个第二分组对应的N个伪行数据中;
其中,i=1,2,…,N。
在一实施例中,所述第三处理单元54,还用于:
针对所述结构化数据集的两个第一分组中每个第一分组,从相应第一分组的各个第二分组中分别提取N个水印分片;
若从两个第一分组中分别提取的N个水印分片的数值均相等,则基于两个第一分组中任意一组对应的N个水印分片,得到水印信息。
在一实施例中,所述从相应第一分组的各个第二分组中分别提取N个水印分片,包括:
从相应第一分组的第i个第二分组中提取得到多个属性值;
基于所述多个属性值,确定与第i个第二分组对应的第i个水印分片的值;
以此类推,直至从相应第一分组的各个第二分组中分别提取N个水印分片的值;
其中,i=1,2,…,N。
实际应用时,所述获取单元51可以由信息处理装置中的通信接口实现;所述第一处理单元52、第二处理单元53、第三处理单元54可以由信息处理装置中的处理器实现。
需要说明的是:上述实施例提供的信息处理装置在进行信息处理时,仅以上述各程序模块的划分进行举例说明,实际应用中,可以根据需要而将上述处理分配由不同的程序模块完成,即将装置的内部结构划分成不同的程序模块,以完成以上描述的全部或者部分处理。另外,上述实施例提供的信息处理装置与信息处理方法实施例属于同一构思,其具体实现过程详见方法实施例,这里不再赘述。
为实现本发明实施例信息处理方法,本发明实施例还提供一种信息处理装置,设置在第二电子设备上。图6为本发明实施例信息处理装置的组成结构示意图,如图6所示,所述装置包括:
第四处理单元61,用于针对结构化数据集的两个第一分组中每个第一分组,从相应第一分组的各个第二分组中分别提取N个水印分片;
第五处理单元62,用于若从两个第一分组中分别提取的N个水印分片的数值均相等,则基于两个第一分组中任意一组对应的N个水印分片,得到水印信息。
在一实施例中,所述第四处理单元61,具体用于:
从相应第一分组的第i个第二分组中提取得到多个属性值;
基于所述多个属性值,确定与第i个第二分组对应的第i个水印分片的值;
以此类推,直至从相应第一分组的各个第二分组中分别提取N个水印分片的值;
其中,i=1,2,…,N。
实际应用时,所述第四处理单元61、第五处理单元62可以由信息处理装置中的处理器实现。
需要说明的是:上述实施例提供的信息处理装置在进行信息处理时,仅以上述各程序模块的划分进行举例说明,实际应用中,可以根据需要而将上述处理分配由不同的程序模块完成,即将装置的内部结构划分成不同的程序模块,以完成以上描述的全部或者部分处理。另外,上述实施例提供的信息处理装置与信息处理方法实施例属于同一构思,其具体实现过程详见方法实施例,这里不再赘述。
本发明实施例还提供了一种第一电子设备,如图7所示,包括:
第一通信接口71,能够与其它设备进行信息交互;
第一处理器72,与所述第一通信接口71连接,用于运行计算机程序时,执行上述第二电子设备侧一个或多个技术方案提供的方法。而所述计算机程序存储在第一存储器73上。
需要说明的是:所述第一处理器72和第一通信接口71的具体处理过程详见方法实施例,这里不再赘述。
当然,实际应用时,第一电子设备70中的各个组件通过总线系统74耦合在一起。可理解,总线系统74用于实现这些组件之间的连接通信。总线系统74除包括数据总线之外,还包括电源总线、控制总线和状态信号总线。但是为了清楚说明起见,在图7中将各种总线都标为总线系统74。
本申请实施例中的第一存储器73用于存储各种类型的数据以支持第一电子设备70的操作。这些数据的示例包括:用于在第一电子设备70上操作的任何计算机程序。
上述本申请实施例揭示的方法可以应用于所述第一处理器72中,或者由所述第一处理器72实现。所述第一处理器72可能是一种集成电路芯片,具有信号的处理能力。在实现过程中,上述方法的各步骤可以通过所述第一处理器72中的硬件的集成逻辑电路或者软件形式的指令完成。上述的所述第一处理器72可以是通用处理器、数字数据处理器(DSP,Digital Signal Processor),或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。所述第一处理器72可以实现或者执行本申请实施例中的公开的各方法、步骤及逻辑框图。通用处理器可以是微处理器或者任何常规的处理器等。结合本申请实施例所公开的方法的步骤,可以直接体现为硬件译码处理器执行完成,或者用译码处理器中的硬件及软件模块组合执行完成。软件模块可以位于存储介质中,该存储介质位于第一存储器73,所述第一处理器72读取第一存储器73中的信息,结合其硬件完成前述方法的步骤。
本发明实施例还提供了一种第二电子设备,如图8所示,包括:
第二通信接口81,能够与其它设备进行信息交互;
第二处理器82,与所述第二通信接口81连接,用于运行计算机程序时,执行上述第一电子设备侧一个或多个技术方案提供的方法。而所述计算机程序存储在第二存储器83上。
需要说明的是:所述第二处理器82和第二通信接口81的具体处理过程详见方法实施例,这里不再赘述。
当然,实际应用时,第二电子设备80中的各个组件通过总线系统84耦合在一起。可理解,总线系统84用于实现这些组件之间的连接通信。总线系统84除包括数据总线之外,还包括电源总线、控制总线和状态信号总线。但是为了清楚说明起见,在图8中将各种总线都标为总线系统84。
本申请实施例中的第二存储器83用于存储各种类型的数据以支持第二电子设备80的操作。这些数据的示例包括:用于在第二电子设备80上操作的任何计算机程序。
上述本申请实施例揭示的方法可以应用于所述第二处理器82中,或者由所述第二处理器82实现。所述第二处理器82可能是一种集成电路芯片,具有信号的处理能力。在实现过程中,上述方法的各步骤可以通过所述第二处理器82中的硬件的集成逻辑电路或者软件形式的指令完成。上述的所述第二处理器82可以是通用处理器、数字数据处理器(DSP,Digital Signal Processor),或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。所述第二处理器82可以实现或者执行本申请实施例中的公开的各方法、步骤及逻辑框图。通用处理器可以是微处理器或者任何常规的处理器等。结合本申请实施例所公开的方法的步骤,可以直接体现为硬件译码处理器执行完成,或者用译码处理器中的硬件及软件模块组合执行完成。软件模块可以位于存储介质中,该存储介质位于第二存储器83,所述第二处理器82读取第二存储器83中的信息,结合其硬件完成前述方法的步骤。
在示例性实施例中,第一电子设备70、第二电子设备80可以被一个或多个应用专用集成电路(ASIC,Application Specific Integrated Circuit)、DSP、可编程逻辑器件(PLD,Programmable Logic Device)、复杂可编程逻辑器件(CPLD,Complex ProgrammableLogic Device)、现场可编程门阵列(FPGA,Field-Programmable Gate Array)、通用处理器、控制器、微控制器(MCU,Micro Controller Unit)、微处理器(Microprocessor)、或者其他电子元件实现,用于执行前述方法。
可以理解,本申请实施例的存储器(第一存储器73、第二存储器83)可以是易失性存储器或者非易失性存储器,也可包括易失性和非易失性存储器两者。其中,非易失性存储器可以是只读存储器(ROM,Read Only Memory)、可编程只读存储器(PROM,ProgrammableRead-Only Memory)、可擦除可编程只读存储器(EPROM,Erasable Programmable Read-Only Memory)、电可擦除可编程只读存储器(EEPROM,Electrically ErasableProgrammable Read-Only Memory)、磁性随机存取存储器(FRAM,ferromagnetic randomaccess memory)、快闪存储器(Flash Memory)、磁表面存储器、光盘、或只读光盘(CD-ROM,Compact Disc Read-Only Memory);磁表面存储器可以是磁盘存储器或磁带存储器。易失性存储器可以是随机存取存储器(RAM,Random Access Memory),其用作外部高速缓存。通过示例性但不是限制性说明,许多形式的RAM可用,例如静态随机存取存储器(SRAM,StaticRandom Access Memory)、同步静态随机存取存储器(SSRAM,Synchronous Static RandomAccess Memory)、动态随机存取存储器(DRAM,Dynamic Random Access Memory)、同步动态随机存取存储器(SDRAM,Synchronous Dynamic Random Access Memory)、双倍数据速率同步动态随机存取存储器(DDRSDRAM,Double Data Rate Synchronous Dynamic RandomAccess Memory)、增强型同步动态随机存取存储器(ESDRAM,Enhanced SynchronousDynamic Random Access Memory)、同步连接动态随机存取存储器(SLDRAM,SyncLinkDynamic Random Access Memory)、直接内存总线随机存取存储器(DRRAM,Direct RambusRandom Access Memory)。本申请实施例描述的存储器旨在包括但不限于这些和任意其它适合类型的存储器。
在示例性实施例中,本发明实施例还提供了一种存储介质,即计算机存储介质,具体为计算机可读存储介质,例如包括存储计算机程序的存储器,上述计算机程序可由第一电子设备70的第一处理器72执行,以完成前述第一电子设备侧方法所述步骤。计算机可读存储介质可以是FRAM、ROM、PROM、EPROM、EEPROM、Flash Memory、磁表面存储器、光盘、或CD-ROM等存储器。
需要说明的是:“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。
另外,本发明实施例所记载的技术方案之间,在不冲突的情况下,可以任意组合。
以上所述,仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。
- 日志信息处理方法、装置、电子设备及可读存储介质
- 信息处理方法及装置、电子设备和存储介质
- 贷款业务信息处理方法、装置、存储介质及计算机设备
- 信息处理方法、装置、电子设备及可读存储介质
- 用户信息处理方法、装置、计算机设备及存储介质
- 信息处理系统、信息处理方法、信息处理设备、信息处理设备控制方法、信息处理终端、信息处理终端控制方法、信息存储介质以及程序
- 信息处理系统、信息处理方法、信息处理设备、信息处理设备控制方法、信息处理终端、信息处理终端控制方法、信息存储介质以及程序