一种二噁英排放浓度选择性集成预测系统及方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及城市固废焚烧技术领域,特别是涉及一种二噁英排放浓度选择性集成预测系统及方法。
背景技术
城市固体废物(Municipal solid waste,MSW)的产生量随我国经济的发展、城市化进程的加快及居民生活水平的提高迅速增加,导致很多地区出现了“垃圾围城”现象。目前,MSW的处理方法包括卫生填埋、堆肥和焚烧,其中MSW焚烧(MSW incineration,MSWI)技术在无害化、减量化和资源化等方面具有显著优势,这也是我国目前大力推行的方法。但是,运行不稳定的MSWI过程会产生二噁英类(Dioxin,DXN)有机污染物,包括多氯二苯并-对-二噁英(polychlorinated dibenzo-p-dioxins,PCDDs)和多氯二苯并呋喃(polychlorinated dibenzofurans,PCDFs),其对环境的持久性污染会对人类健康和生命产生巨大危害。实现类似MSWI过程的环保指标的优化控制,首先需要这些指标的在线实时控制。
针对DXN,当前以基于高分辨气相色谱-高分辨质谱(High-ResolutionChromatography Combined With High-Resolution Mass Spectrometry,HRGC/HRMS)为代表的离线直接检测法主要检测手段,其大时滞性、高成本、高复杂性等缺点制约了面向DXN减排的MSWI过程优化控制。另外一种检测方法是基于指示物/关联物的在线间接检测法,其核心是先检测关联物再通过构建DXN与关联物之间的映射模型实现在线预测,在实际应用过程中存在检测装置价格昂贵、复杂性高、维护困难、关联物浓度与成分存在不确定性等问题。针对上述问题,基于软测量的DXN检测方法通过易检测过程数据构建预测模型,具有稳定、快速和准确的优点。目前,数据驱动的软测量技术已经在石油、冶金和化工等领域广泛应用。
实际工业过程中,DXN排放浓度与MSWI过程的众多变量密切相关;考虑DXN真值难获取的特性,构建其软测量模型的采用小样本、高维度的数据建模,上述特性便导致基于单学习器的软测量模型难以准确预测而基于集成学习器的软测量模型泛化性能不足。相比于其他算法,集成学习在具有小样本高维特性的难以检测运行指标模型构建方面优势明显。
由上可知,面向存在大滞后性、环境复杂等特性的MSWI过程DXN排放浓度,现有SEN方法难以有效确定最优集成子模型及其权重以实现高性能建模。因此,设计一种二噁英排放浓度选择性集成预测系统及方法是十分有必要的。
发明内容
本发明的目的是提供一种二噁英排放浓度选择性集成预测系统及方法,能够实现DXN排放浓度选择性集成模型的构建,实现了DXN排放浓度的预测。
为实现上述目的,本发明提供了如下方案:
一种二噁英排放浓度选择性集成预测系统,包括:集成子模型构建模块及集成子模型加权预测模块,所述集成子模型构建模块连接所述集成子模型加权预测模块;
所述集成子模型构建模块设置有多个,所述集成子模型构建模块包括BT候选子模型构建子模块、候选子模型先验信息获取及预测子模块、候选子模型后验信息获取子模块及集成子模型选择子模块,所述BT候选子模型构建子模块连接所述候选子模型先验信息获取及预测子模块,所述候选子模型先验信息获取及预测子模块连接所述候选子模型后验信息获取子模块,所述候选子模型后验信息获取子模块连接所述集成子模型选择子模块,所述集成子模型选择子模块连接所述集成子模型加权预测模块,所述BT候选子模型构建子模块用于构建BT候选子模型集,所述候选子模型先验信息获取及预测子模块用于通过BT候选子模型集获取预测值及先验信息,所述候选子模型后验信息获取子模块用于基于先验信息确定后验信息及后验误差,所述集成子模型选择子模块用于选择集成子模型;
所述集成子模型加权预测模块用于实现集成子模型权重计算及集成模型加权预测。
本发明还提供了一种二噁英排放浓度选择性集成预测方法,应用于上述的二噁英排放浓度选择性集成预测系统,包括如下步骤:
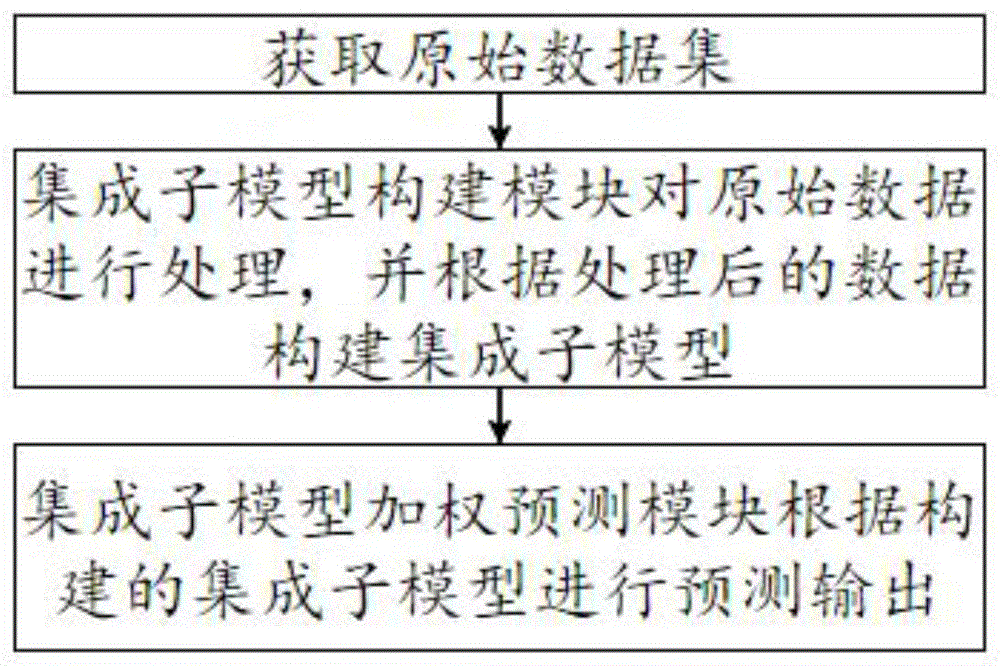
步骤1:获取原始数据集;
步骤2:集成子模型构建模块对原始数据进行处理,并根据处理后的数据构建集成子模型;
步骤3:集成子模型加权预测模块根据构建的集成子模型进行预测输出。
可选的,步骤1中,获取原始数据集,具体为:
获取原始数据集{X
可选的,步骤2中,集成子模型构建模块对原始数据集进行处理,并根据处理后的数据构建集成子模型,具体为:
集成子模型构建模块对原始数据集{X
根据数据子集通过BT候选子模型构建子模块构建BT候选子模型集;
根据BT候选子模型集通过候选子模型先验信息获取及预测子模块获取全部候选子模型的先验信息;
根据先验信息通过候选子模型后验信息获取子模块获取全部候选子模型的后验信息及对应的后验误差;
根据后验信息及对应的后验误差通过集成子模型选择子模块选择集成子模型;
重复上述过程,获取全部集成子模型及对应的后验信息。
可选的,根据数据子集通过BT候选子模型构建子模块构建BT候选子模型集,具体为:
通过BT候选子模型构建子模块构建BT候选子模型集,得到:
式中,L表示叶节点数量;I(·)表示指示函数,当预测样本属于当前叶节点的样本集时,即,x∈R
构建以平方误差为损失函数进行生长的BT模型,其损失函数Ω
式中,Ω
通过确定Ω
式中,
式中,y
循环递归上述过程,当到达叶子节点时停止递归,分裂生长结束,获得第i个候选子模型f
针对全部数据子集
得到N
可选的,根据BT候选子模型集通过候选子模型先验信息获取及预测子模块获取全部候选子模型的先验信息,具体为:
将数据子集的输入X
式中,
根据数据子集
式中,y
/>
式中,
可选的,根据先验信息通过候选子模型后验信息获取子模块获取全部候选子模型的后验信息及对应的后验误差,具体为:
计算在数据子集的输出向量
计算在原始输出向量先验信息P
得到后验信息
式中,
可选的,根据后验信息及对应的后验误差通过集成子模型选择子模块选择集成子模型,具体为:
根据全部候选子模型的后验误差
式中,
经过贝叶斯推理选择后的集成子模型记为第
式中,
可选的,步骤3中,集成子模型加权预测模块根据构建的集成子模型进行预测输出,具体为:
获取全部集成子模型及对应的后验信息为:
计算全部集成子模型的后验信息之和为:
计算第r个集成子模型的权重信息
计算全部集成子模型的权重信息为:
根据上述权重信息得到预测输出为:
式中,X
根据本发明提供的具体实施例,本发明公开了以下技术效果:本发明提供的二噁英排放浓度选择性集成预测系统及方法,该系统及方法能够解决现有DXN排放浓度预测模型存在的可解释性弱、模型复杂度高及泛化性能差等问题,首先,利用Bagging采样获得具有差异性的数据子集并构建基于二叉树的候选子模型,计算候选子模型叶子节点和预测值的先验信息,采用贝叶斯推理计算后验信息对候选子模型的适应度进行表征,依据后验误差选择最佳子模型作为集成子模型,重复上述两个过程以获得全部集成子模型及其对应的后验信息,然后,通过上述集成子模型的后验信息确定合并权重,进而实现DXN排放浓度选择性集成模型的构建,最后,在DXN数据集验证了所提方法的有效性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为城市固废焚烧过程流程示意图;
图2为本发明实施例二噁英排放浓度选择性集成预测系统结构示意图;
图3为本发明实施例二噁英排放浓度选择性集成预测方法流程示意图;
图4为DXN数据集候选子模型预测结果图;
图5为候选子模型预测结果图;
图6为DXN数据集集成子模型后验信息图;
图7a为DXN训练集的预测拟合曲线图;
图7b为DXN验证集的预测拟合曲线图;
图7c为DXN测试集的预测拟合曲线图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明的目的是提供一种二噁英排放浓度选择性集成预测系统及方法,能够实现DXN排放浓度选择性集成模型的构建,实现了DXN排放浓度的预测。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
城市固废焚烧过程如图1所示,面向MSWI过程的DXN软测量检测研究主要集中针对排放阶段(即烟气G3)的DXN浓度检测,本文研究重点是构建烟气G3处的软测量模型。
如图2所示,本发明实施例提供的二噁英排放浓度选择性集成预测系统,包括:集成子模型构建模块及集成子模型加权预测模块,所述集成子模型构建模块连接所述集成子模型加权预测模块;
所述集成子模型构建模块设置有多个,所述集成子模型构建模块包括BT候选子模型构建子模块、候选子模型先验信息获取及预测子模块、候选子模型后验信息获取子模块及集成子模型选择子模块,所述BT候选子模型构建子模块连接所述候选子模型先验信息获取及预测子模块,所述候选子模型先验信息获取及预测子模块连接所述候选子模型后验信息获取子模块,所述候选子模型后验信息获取子模块连接所述集成子模型选择子模块,所述集成子模型选择子模块连接所述集成子模型加权预测模块,所述BT候选子模型构建子模块用于构建BT候选子模型集,所述候选子模型先验信息获取及预测子模块用于通过BT候选子模型集获取预测值及先验信息,所述候选子模型后验信息获取子模块用于基于先验信息确定后验信息及后验误差,所述集成子模型选择子模块用于选择集成子模型;
所述集成子模型加权预测模块用于实现集成子模型权重计算及集成模型加权预测;
图2中,{X
不同模块的功能描述如下:
集成子模型构建模块:1)BT候选子模型构建子模块:对原始数据集{X
由上述子模块循环
集成子模型加权预测模块:由上述的集成子模型f
如图3所示,本发明还提供了一种二噁英排放浓度选择性集成预测方法,应用于上述的二噁英排放浓度选择性集成预测系统,包括如下步骤:
步骤1:获取原始数据集;
步骤2:集成子模型构建模块对原始数据进行处理,并根据处理后的数据构建集成子模型;
步骤3:集成子模型加权预测模块根据构建的集成子模型进行预测输出。
本发明的运行过程为:首先,利用Bagging采样获得具有差异性的数据子集并构建基于二叉树的候选子模型,计算候选子模型叶子节点和预测值的先验信息,采用贝叶斯推理计算后验信息对候选子模型的适应度进行表征,依据后验误差选择最佳子模型作为集成子模型,重复上述两个过程以获得全部集成子模型及其对应的后验信息,然后,通过上述集成子模型的后验信息确定合并权重,进而实现DXN排放浓度选择性集成模型的构建,最后,在DXN数据集验证了所提方法的有效性,具体如下:
步骤1中,获取原始数据集,具体为:
获取原始数据集{X
步骤2中,集成子模型构建模块对原始数据集进行处理,并根据处理后的数据构建集成子模型,具体为:
集成子模型构建模块对原始数据集{X
根据数据子集通过BT候选子模型构建子模块构建BT候选子模型集;
根据BT候选子模型集通过候选子模型先验信息获取及预测子模块获取全部候选子模型的先验信息;
根据先验信息通过候选子模型后验信息获取子模块获取全部候选子模型的后验信息及对应的后验误差;
根据后验信息及对应的后验误差通过集成子模型选择子模块选择集成子模型;
重复上述过程,获取全部集成子模型及对应的后验信息。
根据数据子集通过BT候选子模型构建子模块构建BT候选子模型集,具体为:
通过BT候选子模型构建子模块构建BT候选子模型集,得到:
式中,L表示叶节点数量;I(·)表示指示函数,当预测样本属于当前叶节点的样本集时,即,x∈R
构建以平方误差为损失函数进行生长的BT模型,其损失函数Ω
式中,Ω
通过确定Ω
式中,
式中,y
循环递归上述过程,当到达叶子节点时停止递归,分裂生长结束,获得第i个候选子模型f
针对全部数据子集
得到N
根据BT候选子模型集通过候选子模型先验信息获取及预测子模块获取全部候选子模型的先验信息,具体为:
将数据子集的输入X
式中,
根据数据子集
/>
式中,y
式中,
根据先验信息通过候选子模型后验信息获取子模块获取全部候选子模型的后验信息及对应的后验误差,具体为:
计算在数据子集的输出向量
计算在原始输出向量先验信息P
得到后验信息
式中,
根据后验信息及对应的后验误差通过集成子模型选择子模块选择集成子模型,具体为:
根据全部候选子模型的后验误差
式中,
经过贝叶斯推理选择后的集成子模型记为第
式中,
步骤3中,集成子模型加权预测模块根据构建的集成子模型进行预测输出,具体为:
获取全部集成子模型及对应的后验信息为:
计算全部集成子模型的后验信息之和为:
计算第r个集成子模型的权重信息
计算全部集成子模型的权重信息为:
根据上述权重信息得到预测输出为:
式中,X
本发明的一个实施例为:以北京某MSWI的DXN数据即进行验证,将数据集全样本分为3个部分,其中1/2作为训练样本,1/4为验证样本,1/4为测试样本,统计信息如表1所示:
表1实验数据统计结果
DXN数据其涵盖了2009-2020年的DXN建模数据141组,其输入变量为117维;
本发明选取均方根误差(Root Mean Square Error,RMSE)、平均绝对误差(MeanAbsolute Error,MAE)和解释方差(Explicable variance,EV)共四个评价指标比较不同方法的性能,计算如下:
式中,D(·)表示方差计算过程。
BBTSEN模型的建模参数设置为:子模型叶节点的最小样本数N
根据上述参数设置,本文实验过程对DXN数据集Bagging采样构建候选子模型。
基于本文所提BBTSEN算法,针对DXN数据集第
通过N
本文根据上述候选子模型构建结果,基于后验差值信息完成集成子模型选择。
针对DXN数据集,以第
由上述结果可知,针对DXN数据集第
通过上述集成子模型构建选择过程获得全部集成子模型及后验信息构建加权集成模型,其中集成子模型后验信息如图6所示。
采用本发明所提方法及上述对比方法,针对DXN数据集的预测拟合曲线如图7所示。
采用本发明所提方法与其他方法对比结果如表2所示:
表2DXN数据集算法的性能对比
由图7和表2可知:1)CART在训练集的RMSE、MAE和EV的指标结果与BPNN算法相近,二者在训练集均具有较好的效果,但在验证集和测试集上的二者性能指标均较低,表明存在过拟合现象;2)RF在训练集上的性能与本文方法接近,在测试集上的部分指标性能优于BBTSEN,但其多数低于本文所提算法;3)BBTSEN在验证集和测试集上的性能均较好,表明其具有良好的泛化性能和稳定性。
综上可知,本发明所提BBTSEN方法具有比CART、BPNN和RF拥有更好的学习能力,在测试集上的建模精度和拟合程度最佳,体现了其构建DXN软测量模型的明显优势。
本发明基于多轮重复进行Bagging和二叉树的策略构建选择性集成模型,降低模型训练消耗的同时提高模型的可解释性,采用贝叶斯推理后验信息表征候选子模型适应度,选择最佳者为每轮获取唯一集成子模型,确保最优性,基于贝叶斯和二叉树加权子模型以构建最终软测量集成模型。采用基准数据集和MSWI过程真实数据验证了所提出方法的有效性。
本发明所使用的符号说明如表3所示:
表3符号说明
/>
/>
/>
本发明提供的二噁英排放浓度选择性集成预测系统及方法,该系统及方法能够解决现有DXN排放浓度预测模型存在的可解释性弱、模型复杂度高及泛化性能差等问题,首先,利用Bagging采样获得具有差异性的数据子集并构建基于二叉树的候选子模型,计算候选子模型叶子节点和预测值的先验信息,采用贝叶斯推理计算后验信息对候选子模型的适应度进行表征,依据后验误差选择最佳子模型作为集成子模型,重复上述两个过程以获得全部集成子模型及其对应的后验信息,然后,通过上述集成子模型的后验信息确定合并权重,进而实现DXN排放浓度选择性集成模型的构建,最后,在DXN数据集验证了所提方法的有效性。
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。