融合临床信息与磁共振图像的心肌病预后辅助预测方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及医学图像处理领域,尤其涉及一种融合临床信息与磁共振图像的心肌病预后辅助预测方法。
背景技术
扩张型心肌病是一种常见的慢性心脏病,是全世界发病率最高的一类心肌病,在心肌病中占比达90%,可导致心力衰、血栓栓塞及猝死。心脏磁共振图像的多参数、多序列成像可以从心脏形态和结构方面的变化预测扩张型心肌病患者的预后情况,根据LGE、T1mapping和ECV判断扩张型心肌病患者的心肌组织学异常,为扩张型心肌病预后提供新的影像学指标。因此,心脏MRI在扩张型心肌病预后预测和评估方面具有十分重要的作用。然而,相关研究表明扩张型心肌病患者预后与性别、年龄、纽约心脏协会(New York HeartAssociation, NYHA)心功能分级、LVEF、高血压、糖尿病等因素密切相关,这些临床指标能够为扩张型心肌病预后预测提供重要信息,辅助临床医师进行预后风险评估做出快速精确的判断。
传统的医学图像分类方法包括K近邻算法(K-Nearest Neighbor, KNN)、朴素贝叶斯分类算法(Naïve Bayes)、支持向量机(Support Vector Machine,SVM)和反向传播(BackPropagation,BP)神经网络等。近年来流行的深度学习分类方法,克服了传统方法手动选取特征、适应性弱等问题,逐渐成为医学图像分类的主流方法。
1998年,有学者提出了经典的LeNet最初用于手写数字识别与分类,准确率达98%。LeNet出现后的很长一段时间,深度卷积神经网络并未引起很大关注。直到2012年,得益于互联网及多媒体数据的大幅增长、计算机硬件性能的显著提高以及训练方法的优化,Alex等人设计了一个8层的卷积神经网络AlexNet,大幅提高分类性能并在2012年ImageNet 比赛中领先夺冠。牛津大学计算机视觉组和Google DeepMind公司提出的VGGNet取得了2014年ImageNet比赛定位项目第一名和分类项目第二名。有研究人员提出VGG16对膀胱瘤病人病理切片图像进行癌症分级预测。又有学者提出一种注意力的VGG19并用于乳腺癌增强CT图像分类。GoogleNet取得了2014年ImageNet分类项目第一名(第二名是VGGNet),网络采用了Inception结构来进行多尺度特征提取同时拓展网络宽度和深度,有学者采用了一种改进的GoogLeNet对胸部X射线图片进行正侧面的分类,准确率接近100%。国外学者将GooLeNet成功用于阿兹海默症病人的MRI图像进行多分类。当网络达到一定深度后再继续增加网路层数,网络性能不增反降。为了解决性能退化问题,微软研究院何凯明等人提出了ResNet,通过不断堆叠残差模块(residual block)成功训练了152层深度的卷积网络,后续有人采用ResNet在3D MRI上对阿兹海默症病人和正常人进行分类。吴云峰等人提出一种Inception-ResNet对肺部CT图像进行分类,有效降低模型的参数量。DenseNet拓展ResNet的跨层连接方式,在稠密连接模块中将网络中的每一层都直接与其前面层相连,实现了特征的重用并减少网络参数数量,缓解了梯度消失。随后,提出一种121层的DenseNet对胸部X射线图片进行14种疾病的分类。以及将DenseNet与CapsNet相结合对肺部X射线图进行分类诊断新冠病毒感染。
现有技术存在的不足:
1、现有模型是单模态模型,主要针对磁共振图像数据进行训练,未设计针对临床指标和磁共振图像的多源数据融合模型,忽略了临床信息的作用。
2、在特征提取中,采用不断堆叠的空洞卷积来达到高维特征提取的目的,造成训练难度高、梯度消失且计算复杂度过高。
3、在特征融合中,对原始数据不做任何特征提取直接进行融合(即数据层融合),造成冗余信息过多且模型无法实时处理。
发明内容
针对现有技术之不足,本发明提出一种融合临床信息与磁共振图像的心肌病预后辅助预测方法,所述方法首先采用Relief特征选择算法进行临床指标的筛选,然后将筛选出的临床指标与心脏MRI图像进行特征融合,构建预测神经网络MM-Net,包括两个独立的特征提取分支:临床特征分支和图像特征分支,分别进行临床指标和心脏MRI图像的特征提取,最后将两个分支分别提取的高维特征信息进行融合处理,输出最终的心脏MRI图像分类结果,辅助预测扩张型心肌病患者是否发生严重的预后事件,具体包括:
步骤1:基于Relief特征选择算法的临床指标筛选,包括:
步骤11:采集的临床指标构成临床指标数据集,对所述临床指标数据集中的临床指标进行数据清洗和预处理,删除指标缺失程度较大的数据,补充缺失程度较小的数据,然后对非数值型数据项进行转换;
步骤12:采用Relief特征选择算法依次计算所述临床指标数据集中共18个临床指标的权重大小,通过排序得出各个指标与扩张型心肌病预后的相关程度;
步骤13:剔除掉权重为负值的临床指标,保留权重为正值的临床指标;
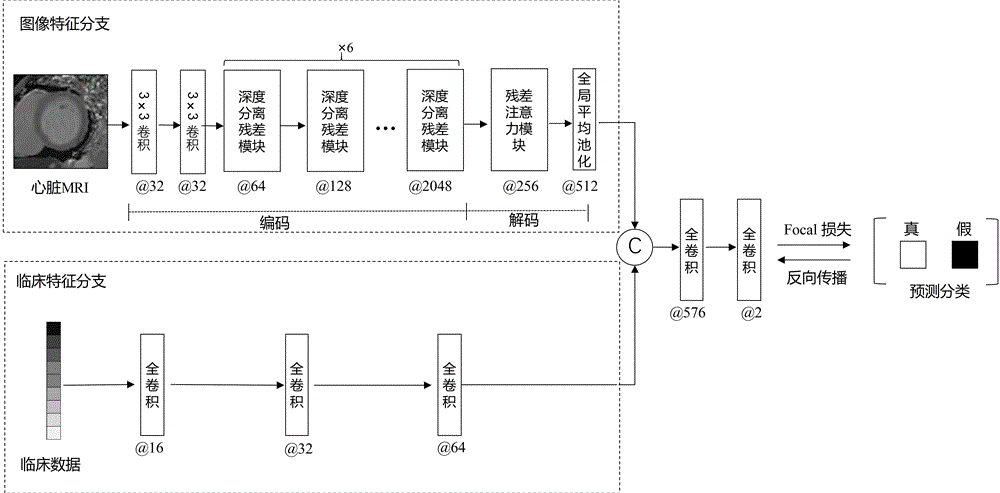
步骤2:所述临床特征分支提取临床指标高维特征,将步骤13中保留的权重为正值的临床指标送入所述临床特征分支中,所述临床特征分支包括依次级联的三个神经元个数分别为16、32和64的全连接层,经过所述临床特征分支后,得到临床指标的高维特征;
步骤3:将获取的心脏MRI图像集输入所述图像特征分支中,通过所述图像特征分支的编码器-解码器结构提取扩张型心肌病MRI图像的高维分类特征,具体包括:
步骤31:首先,对心脏MRI图像数据进行预处理,将原始图像和标注图像空间间距处理成1.0×1.0mm
步骤32:通过编码器前端级联的2层3×3大小的普通卷积进行浅层特征提取;
步骤33:编码器还包括依次级联6个深度分离残差模块SRM,构建自下而上的快速前馈扫描进行特征提取、快速增加感受野,采用残差学习策略,所述深度分离残差模块SRM采用残差连接,在每个深度分离残差模块中利用依次级联空洞率为3、5、7,卷积核大小为3×3的分离卷积层进行多尺度特征提取,将步骤32提取的浅层特征输入深度分离残差模块,得到跨任务特征;
步骤34:将所述跨任务特征输入解码器进行解码,在解码器部分引入注意力机制,采用残差注意力模块RAM进行自上而下的全局信息扩展,有针对性地提取对分类任务有重要指导作用的特征,增强有效特征的作用并抑制冗余信息;
步骤35:解码器的最后一层用池化窗口为3×3大小的全局平均池化层降低特征维度,得到心脏MRI图像的高维特征;
步骤4:采用多源信息融合策略将临床指标的高维特征与心脏MRI图像的高维特征进行融合并预测,所述融合策略为特征层融合,将所述图像特征分支和所述临床特征分支中两种模态数据的高维特征进行拼接,将拼接后的特征送入两层级联的全连接层,同时,采用Focal损失来缓解类不平衡的问题,输出最终分类结果。
与现有技术相比,本发明的有益效果在于:
1、现有技术在进行分类预测时,没有考虑到将临床信息融入其中,本发明引入Relief特征选择算法,筛选出与疾病预后预测高度相关的重要临床指标融入预后预测模型,融合了性别、年龄、心功能分级、高血压等与扩张型心肌病预后密切相关的临床因素,与心脏磁共振图像进行融合,提高了辅助预测的准确度。
2、本发明采用编码器-解码器结构和深度分离卷积模块以及残差注意力模块对图像特征进行提取,有针对性地提取对分类任务有重要指导作用的特征,增强有效特征的作用并抑制冗余信息,同时利用残差网络结构减轻网络的训练难度,有效避免梯度消失现象。
3、本发明采用特征层融合策略,能够保留两种不同数据中足够重要的信息,又能够相互补充提高分类结果,能够取得最精准的预测结果,弥补了数据层融合和决策层融合存在的不足。
附图说明
图1为本发明构建的MM-Net的网络结构图;
图2为深度分离残差模块SRM的结构示意图;
图3为残差注意力模块RAM的结构示意图;
图4为三种不同的多源信息融合策略;
图5为Relief特征选择算法实验结果。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明了,下面结合具体实施方式并参照附图,对本发明进一步详细说明。应该理解,这些描述只是示例性的,而并非要限制本发明的范围。此外,在以下说明中,省略了对公知结构和技术的描述,以避免不必要地混淆本发明的概念。
本发明的MM-Net网络是指:Multi-modal Network,多模态神经网络。
本发明的ROI是指:Region of Interest,感兴趣区。
本发明的LGE是指:(late gadolinium enhancement,钆剂晚期延迟强化。
本发明的T1 mapping是指:纵向弛豫时间定量成像。
下面结合附图进行详细说明。
针对现有技术存在的不足,本发明提出一种融合临床信息与磁共振图像的扩张性心肌病预后预测方法。所述方法首先采用Relief特征选择算法进行临床指标的筛选,然后将筛选出的临床指标与心脏MRI图像进行有效融合。
如图1所示,构建的预测神经网络MM-Net包括两个独立的特征提取分支:临床特征分支和图像特征分支,分别进行临床指标和心脏MRI图像的特征提取,最后将两个分支分别提取的高维特征信息进行融合处理,输出最终的心脏MRI图像分类结果,辅助预测扩张型心肌病患者是否发生严重的预后事件。
步骤11:对采集的临床指标进行数据清洗和预处理,删除指标缺失程度较大的数据,补充缺失程度较小的数据,然后对非数值型数据项进行转换,例如将性别为男性映射成1、女性映射成0,最后将各项数据归一化至[0,1]之间,减小数值差异导致的误差。
步骤12:采用Relief特征选择算法依次计算数据集中共18个临床指标的权重大小,通过排序得出各指标与扩张型心肌病预后的相关程度。
18个临床指标包括性别、年龄、身高、体重、NYHA心功能分级等。
步骤13:剔除掉权重为负值的临床指标,保留权重为正值的临床指标;
步骤2:临床特征分支提取临床指标特征,将步骤13中保留的权重为正值的临床指标送入所述临床特征分支中,所述临床特征分支包括依次级联的三个神经元个数分别为16、32和64的全连接层,经过所述临床特征分支后,得到临床数据特征。
在临床指标分支中,由于输入的临床指标是一维数据,因此采用全连接层进行特征提取,每个全连接层之后都包含一个ReLU激活函数,缓解梯度消失问题,使模型训练更加稳定和收敛。通过三个级联的全连接层,增强模型的非线性能力,逐渐提升模型的复杂度和学习能力,提取有益的临床指标特征。
步骤3:将获取的心脏MRI图像输入所述图像特征分支中,通过编码器-解码器结构提取扩张型心肌病MRI图像的分类特征,包括:
步骤31:对心脏MRI图像数据进行预处理,为了保证数据空间间距的一致性,本发明采用图像预处理方法将原始图像和标注图像空间间距处理成1.0×1.0 mm
由于在实际情况中患者发生严重的预后事件的情况较少,因此数据集负样本占大多数,LGE和T1 mapping数据正负样本比分别约为1:20和1:12。为了避免类不平衡造成过拟合的现象,本发明采用前文用过的旋转、平移等仿射变换方法,单独针对样本量较少的正类进行数据增强。LGE和T1 mapping是常用的两种磁共振图像模态,这两种磁共振图像均与扩张型心肌病预后预测相关,因此利用两种数据集来验证本方法的有效性
步骤32:在编码器部分级联2层3×3大小的普通卷积进行浅层特征提取;每个普通卷积都包含一个BN层和一个ReLU层。
步骤33:采用残差学习策略,编码器还包括依次级联6个深度分离残差模块(Separable Residual Module, SRM)构建自下而上的快速前馈扫描进行特征提取、快速增加感受野,图2为深度分离残差模块SRM结构示意图。深度分离残差模块SRM采用残差连接,在每个深度分离残差模块中利用依次级联空洞率为3、5、7,卷积核大小为3×3的分离卷积层进行多尺度特征提取,将步骤32提取的浅层特征输入深度分离残差模块,得到跨任务特征;
可分离卷积层将空间相关性和通道间相关性的学习任务完全分离,减少模型的参数量,并用1×1普通卷积代替恒等映射进行残差连接,以增强网络的表达能力,得到跨任务特征。
步骤34:将跨任务特征输入解码器进行解码,在解码器部分引入注意力机制,采用残差注意力模块RAM(Residual Attention Module, RAM)进行自上而下的全局信息扩展,有针对性地提取对分类任务有重要指导作用的特征,增强有效特征的作用并抑制冗余信息;同时利用残差网络结构减轻网络的训练难度,有效避免梯度消失现象。
残差注意力模块RAM结构示意图如图3所示。残差注意力模块(residualattention module)RAM包括主干分支trunk branch和掩模分支mask branch,主干分支由多个级联的残差卷积模块构成,对输入特征图进行特征处理,输出主干特征图T
掩模分支采用编码-解码的结构,采用自下而上和自上而下的注意力相结合的方式,学习得到一个与主干输出大小相同的注意力特征掩模M
掩模分支获得注意力特征掩模的过程为:首先在编码器部分进行自下而上的快速前馈扫描,使用三个残差单元和两个最大池化层进行特征提取、快速增加感受野;其次,在解码器部分进行自上而下的全局信息扩展,指导每个位置的输入特征,使用与编码器中最大池化层数量相同的两层线性插值进行对称的上采样,以保证输入输出特征大小相同,最后,还增加了编码器解码器结构之间的跳跃连接,以捕捉不同尺度的信息。
步骤35:解码器的最后一层用池化窗口为3×3大小的全局平均池化层降低特征维度,得到高维图像特征
步骤4:采用多源信息融合策略将临床指标特征与高维图像特征进行融合并预测,所示融合策略为特征层融合,将图像分支和临床指标分支中两种模态数据的高维特征进行拼接,将拼接后的特征送入两层级联的全连接层解决网络非线性问题,采用Focal损失来缓解类不平衡的问题,输出最终分类结果,预测患者是否发生严重的预后事件。
多源信息融合策略包含数据层融合、特征层融合以及决策层融合三类,如图4所示。数据层融合是低层次的融合,即将不同来源的原始数据直接进行融合,然后将融合后的数据进行后续的特征处理及决策,该类方法能够最大程度保存源数据中的原始信息,挖掘原始数据中的更多细节,但是计算负担较大,且无法实时处理。
特征层融合是指对不同数据源分别提取特征信息,然后将提取到的特征信息融合后进行分析和处理,为后期决策分析提供支持,该类方法保留了足够重要的信息,减少了数据处理量,增强了实时性,但是无法避免地丢失了部分细节性特征。
决策层融合是高层次的融合,首先对不同数据源进行分析处理后得出各自的初步决策,然后对采用某种规则对初步决策进行融合得到最终的决策结果,该类方法灵活且实时性最好,但是会大量丢失细节信息,且对前一级依赖较大,实现困难。
本发明采用在图像分类实验采用广泛使用的准确率(Accuracy)、灵敏度(Sensitivity,也称召回率Recall)、特异性(Specificity)和曲线下面积(Area UnderCurve, AUC)四个客观评价指标。Accuracy是分类任务中最常见的评价指标,指正确预测的样本数占所有样本数的比例,通常来说,Accuracy越高,分类器效果越好。Sensitivity表示所有正类的样本中被分对的比例,衡量了分类器对正类样本的识别能力,越高表示模型对正样本的识别能力越强。Specificity表示所有负类样本中被分对的比例,衡量了分类器对负样本的识别能力,越高表示模型对负样本的识别能力越强。AUC是指ROC(ReceiverOperating Characteristic)曲线下方的面积大小。ROC曲线横纵坐标分别为FPR(假负利率)和TPR(真正例率),FPR越小,TPR越高,则模型越好。因此ROC下面积(AUC)越大,或者曲线更接近左上角,模型分类效果越理想。
为了验证本发明提出的MM-Net对于扩张型心肌病预后辅助预测的有效性,本发明将其与VGG16、ResNet50、DenseNet121、Inception v3和Xception五种目前主流的图像分类方法进行比较。
表1展示了几种方法在T1 mapping和LGE两种数据上的分类定量评估结果,这两种数据集的数据均来自合作医院心脏科采集的数据。
从表1中可以看到,在LGE数据上,MM-Net的准确率达到了99.4%,比VGG16、ResNet50、DenseNet121、Inception v3和Xception分别高出13.7%、1.5%、1.5%、0.7%和0.5%,并且,MM-Net的AUC指标也最高,充分说明了MM-Net在LGE数据上的预后预测效果最好。同时,MM-Net的敏感度和特异性也高于其他几种方法,分别达到了100%和99.7%,说明其能够很好地处理类别不平衡问题,避免陷入过拟合。
在T1 mapping数据上,MM-Net的准确率、敏感度和AUC均最好,分别为97.1%、91.2%和98.4%,说明了其在T1数据上也能取得最好的分类效果。而ResNet50和Xception虽然特异性分别高达99.5%和97.8%,但是其分别对应的敏感度都很低,说明这几种方法都无法较好地处理数据类别不平衡的问题,陷入了过拟合。MM-Net在T1 mapping数据上良好的分类性能进一步表明了其在不同心脏MRI数据集上均有良好的分类能力。
表 1 不同网络模型的客观评价指标对比
此外,综合对比LGE数据和T1数据的预测结果可以看出,基于LGE数据的预后预测效果比T1 mapping更加理想,因此,LGE比T1 mapping更适合来做扩张型心肌病的预后预测,印证了LGE在临床中与扩张型心肌病患者的远期预后评估有着重要的关系,LGE是扩张型心肌病预后不良的独立预测因子。
为了进一步验证本发明几个创新点的有益效果,本发明针对MM-Net模型在LGE数据上进行消融实验,以找到模型的结构和参数的最优化设置,具体涉及如下几个方面的问题:(1)临床指标对模型性能的影响;(2)不同的融合策略对模型性能的影响;(3)数据增强步骤是否有效;(4)损失函数的选择。
1、临床指标
为了验证基于Relief特征选择算法的有效性以及临床指标对预后预测网络模型的影响,实验首先采用Relief特征选择算法来计算各个临床指标的权重,通过排序得出各指标与扩张型心肌病预后的相关程度。然后,基于Relief权重按照由大到小的顺序依次加入到网络模型中进行实验,验证Relief算法的有效性。表2给出了本发明用到的临床指标中英文名称及其缩略表示。
表2 临床指标中英文名称及其缩略表示
图5给出了基于Relief算法计算的每个临床指标对应的Relief权重值(即与扩张型心肌病预后预测的相关性)以及相关性排序。从图5可以看出以下几点:
(1)按照Relief值从大到小的顺序排列,各个临床指标对于扩张型心肌病预后的重要程度依次为:hyp、DCM type、age、HB、SBP、sex、smoker、DBP、weight、his、height、NYHA、ACEIARB、new HF、diu、alcohol、β blocker、antis。
(2)hyp(高血压)这项指标的Relief权重值最高,达到了0.1以上,表明hyp是本发明实验所有指标中与扩张型心肌病预后最相关的指标,说明了高血压是扩张型心肌病预后发生不良事件重要的影响因素。
(3)DCM type、age、HB、SBP几项指标的Relief值虽然都低于hyp但都大于0.01,表明这几项指标与扩张型心肌病预后比较相关,说明了DCM的类型、年龄、血红蛋白和收缩压几个特征与扩张型心肌病发生不良预后事件有提示作用。
(4)sex、smoker、DBP、weight、his、height和NYHA几项指标的Relief值在0.01到0.1之间,表明这几项指标也与扩张型心肌病预后有关,说明了性别、吸烟、舒张压、体重、患病时长、身高和心功能分级几个特征对扩张型心肌病发生不良事件具有预后判断价值。
(5)antis、β blocker、alcohol、diu、New HF和ACEIARB六项指标的Relief值为负数,表明在本实验中这几项指标与扩张型心肌病预后不相关甚至会干扰预后预测准确性。
表3是根据相关性由大到小依次添加临床指标后的实验结果,展示了不同临床指标对预后预测模型性能的影响。从表3可以得到以下结论:
(1)随着临床指标的增加,模型的预测能力总体逐渐提升,一直到相关性最大的前12个指标添加完毕,模型预测能力达到最高,准确率、特异性和AUC三项指标分别达到了99.4%、98.7%和99.8%,充分说明基于Relief算法筛选出的临床指标确实能够辅助模型提高预测能力。
(2)当按照相关性添加到前四个指标时,模型预测能力反而略有下降,这可能是由于刚好这几个指标之间相互影响和抵消,降低了模型的预测能力。
(3)随着前12个临床指标的依次添加,模型性能提升开始变得缓慢,印证了相关指标的排序与预后预测重要程度的对应,说明Relief值能够反映指标的相关程度。
(4)当继续添加ACEIARB等Relief值为负数的指标,模型性能开始下降,说明Relief值小于0时临床指标对模型性能没有提升作用,反而会造成负面影响,进一步验证了基于Relief特征选择算法的有效性。
表3 MM-Net加入不同临床指标的实验结果
2、融合策略
本发明提出的网络MM-Net采用特征层融合策略,取得了不错的性能。为了验证不同融合策略对于多源信息融合的预后预测模型的影响,本发明基于MM-Net的基本结构和功能模块,分别针对数据层融合策略和决策层融合策略展开实验。
数据层融合策略采用数据先融合的方式,由于无需单独的分支对临床指标进行处理,因此去掉MM-Net中的临床分支,保留图像分支进行特征提取。具体地,首先将预处理过的心脏MRI图像与其对应的临床指标进行拼接,然后送入MM-Net 的心脏MRI图像数据分支进行特征提取,最后输出分类预测结果。
决策层融合策略采用后融合的方式,基于MM-Net的临床指标分支和图像分支分别对临床指标和心脏MRI图像进行分类特征提取,然后分别在两个分支最后一层全连接层后加入softmax使其分别输出各自分支的分类结果(二维特征向量),最后将两个分支的分类结果进行拼接后,通过一个全连接层输出最终的预后预测结果。
表4给出了不同融合策略下模型的预测结果,从表中可以看出,数据层融合无法充分利用多种模态数据间的互补信息,还会造成大量冗余信息。决策层融合会大量丢失细节信息且对前一层依赖较大,因此预测效果最差。特征层融合能够保留两种不同数据中足够重要的信息,又能够相互补充提高分类结果,能够取得最精准的预测结果。
表 4 不同融合策略的实验结果
3、数据增强
本发明实验在数据预处理时,为了缓解类不平衡问题,单独针对样本量较少的正类样本做了数据增强。为了验证其有效性,本发明在未做数据增强的数据集上进行实验,结果如表5所示。
表5 数据增强的实验结果
从表5中可以看到,未做数据增强的模型预测结果只有特异性略高于做了数据增强的结果,这是由于做了数据增强后,样本量大的负类样本所占的比例相对减少的缘故。但是准确率、敏感度和AUC三个指标均低于做了数据增强的模型预测结果,而其中敏感度表现最为明显,下降了12.9%,充分说明了数据增强能够提升样本量少的正类样本的分类准确性,缓解类别不平衡。
4、损失函数
本发明MM-Net使用的损失函数是Focal loss,为了验证其是否是最优选择,本发明分别采用CE loss、Dice loss和Jaccard loss三种医学图像常用的损失函数进行对比实验,结果如表6所示。
表6 损失函数的影响
从表6中可以看到,Focal loss的各项评价指标均高于CE loss、Dice loss和Jaccard loss,且敏感度和特异性分别达到了100%和99.7%,充分说明了Focal loss有助于提高难分样本的准确度,能够更好地处理类不平衡的数据。其中, CE loss的各项指标略低于或等于Focal loss的指标,Dice loss和Jaccard loss的各项指标有明显下降,说明这几个损失函数在处理类别不平衡问题的能力还有待提升。
需要注意的是,上述具体实施例是示例性的,本领域技术人员可以在本发明公开内容的启发下想出各种解决方案,而这些解决方案也都属于本发明的公开范围并落入本发明的保护范围之内。本领域技术人员应该明白,本发明说明书及其附图均为说明性而并非构成对权利要求的限制。本发明的保护范围由权利要求及其等同物限定。