一种基于多模态分析的精神疾病辅助诊断系统
文献发布时间:2024-04-18 19:58:21
技术领域
本发明涉及人工智能技术领域,尤其涉及一种基于多模态分析的精神疾病辅助诊断系统。
背景技术
在精神疾病医学的发展过程中,对于抑郁症、双相情感障碍、焦虑症等精神疾病的诊断,现在惯用的方式是通过精神检查由医生的经验进行判断,并通过量表对程度进行辅助量化。其中精神检查受限于医生的主观经验,并且对医生时间精力消耗大,量表测评需要参与人主观意愿的配合,在非配合情况下欺骗性高,降低了精神疾病诊断和大规模筛查的有效性。现有的相关分析系统中,基本都是基于量表,并在此基础上做表情分析进行判定,过程中对量表或问卷的每个问题对应的部分进行分析得出对应分值,并最终累加。
例如申请号为202011336311.7(公开号CN112614583A)的抑郁等级测试系统,通过让参与做问卷,计算问卷分数,对每个问题的视频段分析包括各个表情类别时间比、眼球凝视方向时间比、眨眼次数等,对问卷分数和两个时间比、眨眼次数作为特征集,进而进行判断。申请号为202011176044.1(公开号CN112168189A)的一种抑郁症程度量化的评估系统,也是通过分析表情进行抑郁判断,通过让参与者做问卷,通过表情抽象化形成抽象图与与抽象画表情背景图对比、并根据瞳孔位置得出评分A,与问卷输出的评分B加权得到最终评分C进行判定。申请号为201510746466.0(公开号CN105279380A)的一种基于表情分析的抑郁程度自动评估系统,通过分析参与做HAMD17问卷的视频,需要针对视频段分析,对每个视频段进行打分,以综合得分作为抑郁程度判定的依据,特征集也使用了AU的时间域特征和AU组合特征。申请号为202010326394.5(公开号CN111540440A)的基于人工智能的心理体检方法、装置、设备和介质,对普通量表的分数是一部分,对视频量表的回答中记录的视频、音频从情绪的角度进行分析是另一部分,对两部分进行加权完成心理体检。
人的表情,尤其微表情,一定程度上是人内心世界的真实反应,受人潜意识控制,可欺骗程度低,人出现心理活动的同时,脸上会不由自主地出现相应的变化。心理学家PaulEkman和研究伙伴Wallace V.Friesen根据人脸解剖学的特点和人脸肌肉的动作,定义了根据人脸面部变化划分的相互独立的面部动作单元(Facial Action Unit),以AU简称,并以此定义了面部行为编码系统FACS(Facial Action Coding System),而AU就是构成人表情和微表情的基本单元。表情分为愤怒、厌恶、害怕、开心、伤心、惊讶、正常等七种,种类比较概括,而AU是根据人脸面部肌肉分布定义,更近一步地,微表情可以看做持续时间比较短的AU,且AU的种类多达近百种,是更为细粒度的评价标准。
目前针对人脸动作单元AU的检测是技术难点,参与者面对摄像头的角度会影响AU检测的准确程度,在访谈过程中参与者的头部动作会带来影响面对摄像头的角度,而自然对话过程中头部动作不可避免。因此,现有技术的分析方法具有一定的局限性,此外,刺激源单一、获取特征不够全面细致,影响诊断结果的准确性。
发明内容
本发明针对现有技术的不足,目的在于提供一种基于多模态分析的精神疾病辅助诊断系统,通过分析视频,使用面部动作单元检测等人工智能技术,对视觉信息、语音信息、文字信息等进行多模态分析从而对精神疾病进行辅助诊断。
为了实现上述目的,本发明提供如下技术方案:
本发明提供了一种基于多模态分析的精神疾病辅助诊断系统,包括以下模块:
多刺激量表选择模块,根据使用者所选择的刺激形式的种类和每种刺激形式对应的题目数量,从预先定义的量表库中选择相应的专用量表,刺激形式的种类包括但不限于传统量表、问题作答、图片描述和视频观感;
数据采集模块,用于录入使用者的个人信息,依次向使用者展示不同刺激形式的量表内容,并分别以视频形式记录使用者在每道题目下的静态和动态过程,其中静态定义为使用者观看、阅读等非表达状态,动态定义为使用者表达状态;
特征提取模块,用于对静态数据、动态数据中的图像信号、语音信号和文字信号进行特征提取,并输出图像模态、语音模态和文字模态的静态特征和动态特征;特征提取模块包括以下分析模块:
静态图像分析模块,用于对输入的静态数据所包含的视频依次做图像提取,并根据预先定义的特征集,进行静态图像模态特征提取,输出图像模态静态特征;
静态语音分析模块,用于对输入的静态数据所包含的视频依次做语音提取,并根据预先定义的特征集,进行静态语音模态特征提取,输出语音静态特征;
静态文字分析模块,用于对输入的静态数据所包含的视频依次做文字提取,并根据预先定义的特征集,进行静态文字模态特征提取,输出文字静态特征;
动态图像分析模块,用于对输入的动态数据所包含的视频依次做图像提取,并根据预先定义的特征集,进行动态图像模态特征提取,输出图像动态特征;
动态语音分析模块,用于对输入的动态数据所包含的视频依次做语音提取,并根据预先定义的特征集,进行动态语音模态特征提取,输出语音动态特征;
动态文字分析模块,用于对输入的动态数据所包含的视频依次做文字提取,并根据预先定义的特征集,进行动态文字模态特征提取,输出文字动态特征;
单模态处理模块,用于对图像模态、语音模态、文字模态的静态特征和动态特征分别进行特征融合,生成图像模态、语音模态、文字模态各自的单模态特征,并对单模态特征进行分析,生成单模态辅助诊断结果,单模态辅助诊断结果,包括图像模态辅助诊断结果、语音模态辅助诊断结果、文字模态辅助诊断结果;
多模态处理模块,用于对图像模态、语音模态、文字模态的静态特征和动态特征分别进行特征融合,生成多模态静态特征和多模态动态特征,并进一步特征融合生成多模态特征,再对成多模态特征进行分析,生成多模态辅助诊断结果;
报告生成模块,对数据收集模块、各个单模态分析模块和多模态分析模块的输出进行汇总记录,根据多模态分析模型的输出结果,给出相应的意见建议,并结合数据收集模块的个人信息,生成辅助诊断报告。
进一步地,静态图像分析模块预先定义的特征集包括:面部动作单元检测特征、目光朝向检测特征和面部朝向检测特征;其中,面部朝向检测特征的提取方法为:根据预先定义的面部朝向阈值滤除无效数据,并计算空间坐标系下各个坐标维度的均值、方差、中位数绝对偏差、峰度特征并按该顺序组成向量,形成图像模态静态面部朝向特征;面部动作单元检测特征的提取方法为:对面部朝向检测滤除后的静态图像模态数据进行AU检测,并对各个AU的结果提取均值、方差统计特征,并根据预先设定的各个AU的时间长度参数计算对应AU的动作次数,将各个AU的统计特征与动作次数进行拼接形成单AU特征,将各个AU的单AU特征拼接形成图像模态静态AU特征;目光朝向检测特征的提取方法为:对双眼的目光朝向计算空间坐标系下各个坐标维度的均值、方差、中位数绝对偏差、峰度特征并按该顺序组成向量,并按左眼、右眼的次序拼接,形成图像模态静态目光朝向特征;将图像模态静态AU特征、图像模态静态目光朝向特征、图像模态静态面部朝向特征拼接形成图像模态静态特征。
进一步地,静态语音分析模块提取语音模态静态特征的方法为:语音提取MFCC特征、短时过零率、第一共振峰、第二共振峰、第三共振峰、声压级分别计算均值及方差,并按该顺序组成向量,形成语音模态静态特征。
进一步地,静态文字分析模块提取文字静态特征的方法为:文字提取通过语音自动识别完成,将所讲述的全部内容形成段落,并调用预先训练的情感分数词典计算情感分数,形成文字模态静态特征一,并调用预先训练的向量嵌入神经网络,形成文字模态静态特征二,将文字模态静态特征一与文字模态静态特征二以拼接的形式融合形成文字静态特征。
进一步地,动态图像分析模块预先定义的特征集包括:面部动作单元检测特征、目光朝向检测特征和面部朝向检测特征;其中,面部朝向检测特征的提取方法为:根据预先定义的面部朝向阈值滤除无效数据,并计算空间坐标系下各个坐标维度的均值、方差、中位数绝对偏差、峰度特征并按该顺序组成向量,形成图像模态动态面部朝向特征;面部动作单元检测特征的提取方法为:对面部朝向检测滤除后的动态图像模态数据进行AU检测,并对各个AU的结果提取均值、方差统计特征,并根据预先设定的各个AU的时间长度参数计算对应AU的动作次数,将各个AU的统计特征与动作次数进行拼接行程单AU特征,将各个AU的单AU特征拼接形成图像模态动态AU特征;目光朝向检测特征的提取方法为:对双眼的目光朝向计算空间坐标系下各个坐标维度的均值、方差、中位数绝对偏差、峰度等特征并按该顺序组成向量,并按左眼、右眼的次序拼接,形成图像模态动态目光朝向特征;将图像模态动态AU特征、图像模态动态目光朝向特征、图像模态动态面部朝向特征拼接形成图像模态动态特征。
进一步地,动态语音分析模块提取语音模态动态特征的方法为:语音提取MFCC特征、短时过零率、第一共振峰、第二共振峰、第三共振峰、声压级分别计算均值及方差,并按该顺序组成向量,形成语音模态动态特征。
进一步地,动态文字分析模块提取文字动态特征的方法为:文字提取通过语音自动识别完成,将所讲述的全部内容形成段落,并调用预先训练的情感分数词典计算情感分数,形成文字模态动态特征一,并调用预先训练的向量嵌入神经网络,形成文字模态动态特征二,将文字模态动态特征一与文字模态动态特征二以拼接的形式融合形成文字动态特征。
进一步地,单模态处理模块对静态图像分析模块输出的图像模态静态特征和动态图像分析模块输出的图像模态动态特征进行特征融合,形成图像模态特征,并对图像模态特征进行分析,生成图像模态辅助诊断结果;单模态处理模块对静态语音分析模块输出的语音模态静态特征和动态语音分析模块输出的语音模态动态特征进行特征融合,形成语音模态特征,并对语音模态特征进行分析,生成语音模态辅助诊断结果;单模态处理模块对静态文字分析模块输出的文字模态静态特征和动态文字分析模块输出的文字模态动态特征进行特征融合,形成文字模态特征,并对文字模态特征进行分析,生成文字模态辅助诊断结果。
进一步地,多模态分析模块的特征融合过程为:
将静态图像分析模块输出的图像模态静态特征、静态语音分析模块输出的语音模态静态特征和静态文字分析模块输出的文字模态静态特征进行静态特征融合,生成多模态静态特征;
将动态图像分析模块输出的图像模态动态特征、动态语音分析模块输出的语音模态动态特征和动态文字分析模块输出的文字模态动态特征进行动态特征融合,生成多模态动态特征;
对多模态静态特征和多模态动态特征进行特征融合,生成多模态特征,并调用预先训练的多模态辅助诊断模型进行处理,生成多模态辅助诊断结果。
进一步地,静态特征融合或动态特征融合方法为:选取输出的单模态静态特征或动态特征中相关度高的特征项组成多模态静态特征或多模态动态特征,其中具体项的选择调用预先设置的配置文件,该文件记录预先计算好的各单模态静态特征或各单模态动态特征与精神疾病程度之间的绝对值相关性关系,且该相关性关系选取线性相关性结果与非线性相关性结果的并集。
与现有技术相比,本发明的有益效果为:
本发明的基于多模态分析的精神疾病辅助诊断系统,针对视频部分,采取静态、动态划分,其中静态定义为使用者观看、阅读等非表达状态,动态定义为使用者表达状态,并针对静态和动态数据分别进行处理,通过分析人的图像、语音、文字等各种模态信号,使用神经网络等人工智能技术对多种模态的信号进行各自单模态分析和多模态融合分析,更加客观、高效,提高准确度。此外,本发明基于多刺激形式,针对自然反应进行分析,对参与人的主观依赖程度不敏感,可欺骗性低。本发明的系统不需要人工参与,完成抑郁症、双相情感障碍、焦虑症等精神疾病的辅助诊断,大大节省人力、物力。本发明的系统可移植性高,便于部署,并且采用自助式进行,便于大范围铺开。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍。显而易见地,下面描述中的附图仅仅是本发明中记载的一些实施例,对于本领域普通技术人员来讲,还可以根据这些附图获得其他的附图。
图1为本发明实施例提供的基于多模态分析的精神疾病辅助诊断系统模块图。
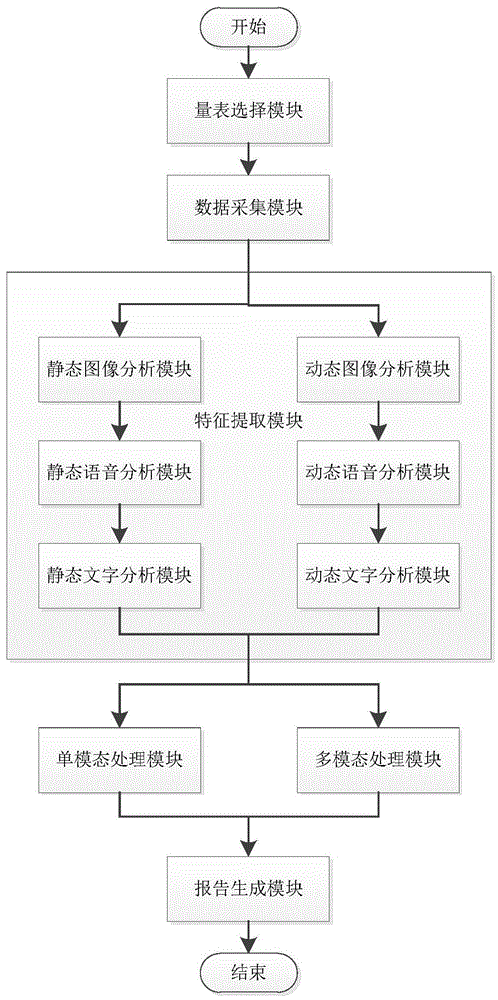
图2为本发明实施例提供的基于多模态分析的精神疾病辅助诊断系统流程图。
具体实施方式
为了更好地理解本技术方案,下面结合附图对本发明的方法做详细的说明。
本发明的基于多模态分析的精神疾病辅助诊断系统,如图1所示,包括以下模块:
多刺激量表选择模块,根据使用者所选择的刺激形式的种类和每种刺激形式对应的题目数量,从预先定义的量表库中选择相应的专用量表,刺激形式的种类包括但不限于传统量表、问题作答、图片描述和视频观感;
数据采集模块,用于录入使用者的个人信息,依次向使用者展示不同刺激形式的量表内容,并分别以视频形式记录使用者在每道题目下的静态和动态过程,其中静态定义为使用者观看、阅读等非表达状态,动态定义为使用者表达状态;
特征提取模块,用于对静态数据、动态数据中的图像信号、语音信号和文字信号进行特征提取,并输出图像模态、语音模态和文字模态的静态特征和动态特征;特征提取模块包括以下分析模块:
静态图像分析模块,用于对输入的静态数据所包含的视频依次做图像提取,并根据预先定义的特征集,进行静态图像模态特征提取,输出图像模态静态特征;
静态语音分析模块,用于对输入的静态数据所包含的视频依次做语音提取,并根据预先定义的特征集,进行静态语音模态特征提取,输出语音静态特征;
静态文字分析模块,用于对输入的静态数据所包含的视频依次做文字提取,并根据预先定义的特征集,进行静态文字模态特征提取,输出文字静态特征;
动态图像分析模块,用于对输入的动态数据所包含的视频依次做图像提取,并根据预先定义的特征集,进行动态图像模态特征提取,输出图像动态特征;
动态语音分析模块,用于对输入的动态数据所包含的视频依次做语音提取,并根据预先定义的特征集,进行动态语音模态特征提取,输出语音动态特征;
动态文字分析模块,用于对输入的动态数据所包含的视频依次做文字提取,并根据预先定义的特征集,进行动态文字模态特征提取,输出文字动态特征;
单模态处理模块,用于对图像模态、语音模态、文字模态的静态特征和动态特征分别进行特征融合,生成图像模态、语音模态、文字模态各自的单模态特征,并对单模态特征进行分析,生成单模态辅助诊断结果,单模态辅助诊断结果,包括图像模态辅助诊断结果、语音模态辅助诊断结果、文字模态辅助诊断结果;
多模态处理模块,用于对图像模态、语音模态、文字模态的静态特征和动态特征分别进行特征融合,生成多模态静态特征和多模态动态特征,并进一步特征融合生成多模态特征,再对成多模态特征进行分析,生成多模态辅助诊断结果;
报告生成模块,对数据收集模块、各个单模态分析模块和多模态分析模块的输出进行汇总记录,根据多模态分析模型的输出结果,给出相应的意见建议,并结合数据收集模块的个人信息,生成辅助诊断报告。
在图像处理上以AU入手,本发明对表情和微表情进行刻画。在图像模态上,我们构建图像特征集,包括但不限于AU、目光朝向、面部朝向。
在语音模态上,本发明构建语音特征集,包括但不限于梅尔频率倒谱系数(MFCC)、短时过零率、多阶共振峰、多阶基音频率、声压级等。
在文字模态上,本发明构建文字特征集,包括但不限于情感分数、向量嵌入特征图等。
人在自我表达的过程中,包含着画面、声音,以及声音所转写出来的文字信息,本发明基于视觉分析、语音分析、文字分析,使用神经网络等人工智能技术,对多种模态的信号进行各自单模态分析和多模态融合分析,例如对人脸等图像信号,区别于更宽泛的表情分析,采用更细粒度的AU进行分析,完成精神疾病辅助诊断。
如图2所示,本发明提供的基于多模态分析的精神疾病辅助诊断系统流程如下:
步骤1:选择专用量表。调用量表选择模块对量表进行选择。注意:本发明的量表非传统意义上广泛使用的量表,本发明以“多刺激量表”作为特指。量表由不同刺激形式的内容构成,且每种刺激形式的内容包括多个题目。具体过程为:
1.1确定所用量表刺激形式的种类。包括但不限于传统量表、问题回答、图片描述与视频观看,但至少包含其中一种。
1.2针对每种刺激形式,确定该刺激形式下的题目数量与内容。
在一个实施例中,传统量表刺激选用PHQ-9量表,并选择其中所包含的所有题目。
在另一个实施例中,问题回答刺激由临床精神访谈中的问题总结而来并选定数量,每道题目的发问形式包括但不限于文字描述、播放医生预先录制好的该问题视频、采用虚拟动画与语音合成的形式制作并播放该问题的视频、纯语音播放该问题。
在另一个实施例中,图片描述刺激选定图片数量,并以此展示图像并同时以语音播报加文字描述的方式进行提示。
在另一个实施例中,视频观看刺激选定视频数量,包括但不限于正向、中性、负向等情感的视频,并选定播放顺序。
1.3从预先定义的量表库中,根据所选择的刺激形式的种类和每种刺激形式对应的题目数量,选择相应的专用量表。
步骤2:数据采集。本发明对辅助诊断全流程进行记录并区分记录各个问题所对应的读题、答题时间点的各个模态数据。调用数据采集模块,进行数据采集,并将采集到的数据输出给步骤3。具体过程为:
2.1个人信息录入。录入使用者的个人信息,在一个实施例中,录入的信息包括但不限于姓名、性别、年龄、受教育程度、专属病历号、病史等。
2.2展示专用量表内容并采集数据。依次向使用者展示不同刺激形式的量表内容,并分别以视频形式记录使用者在每道题目下的静态和动态过程,其中静态定义为使用者观看、阅读等非表达状态,动态定义为使用者表达状态。
在一个实施例中,针对抑郁症,以文字形式按顺序展示PHQ-9量表的每道题目。
在另一个实施例中,针对双相情感障碍,以文字形式按顺序展示BSQ量表的每道题目。
在另一个实施例中,针对焦虑症,以文字形式按顺序展示SAS量表的每道题目。
在一个实施例中,问题回答刺激的每道题目采用医生提前录制好相应视频,并按顺序播放该刺激形式下所有题目。
在一个实施例中,图片描述刺激选按顺序展示所有图片,并同时以语音播报加文字描述的方式进行提示。
在一个实施例中,视频观看刺激按正向、中性、负向的顺序播放相应的视频。
步骤3:特征提取。
3.1静态数据分析。将各个刺激形式下收集的静态数据按顺序依次输入到静态图像分析模块、静态语音分析模块、静态文字分析模块进行分析处理,包括特征提取和精神疾病辅助诊断两部分。具体过程为:
3.1.1调用静态图像分析模块,对输入的静态数据所包含的视频依次做图像提取,并根据预先定义的特征集,调用预先训练的图像模态特征提取模型进行静态图像模态特征提取,输出图像静态特征。预先训练的图像模态特征提取模型包括基于卷积神经网络(Convolutional Neural Network,CNN,下同)的预先训练的面部朝向检测模型、预先训练的AU检测模型、预先训练的目光朝向检测模型。
在一个实施例中,预先定义的特征集包括面部动作单元检测、目光朝向检测、面部朝向检测。本发明对访谈全过程的各个AU进行时间占比、次数等仅为该模态特征的一部分,对目光朝向和面部朝向进行统计分析,并就各个特征与抑郁程度进行相关性分析后,通过阈值筛选相关性高的特征作为该模态特征。
其中,在一个实施例中,面部朝向检测检测面部的朝向,并调用预先训练的基于CNN的面部朝向检测模型进行检测,其中CNN具体使用Resnet骨架结构并使用自有数据进行训练,根据预先定义的面部朝向阈值滤除无效数据,并计算空间坐标系下各个坐标维度的均值、方差、中位数绝对偏差、峰度等特征,并按该顺序组成向量,形成图像模态静态面部朝向特征。
其中,在一个实施例中,面部动作单元检测选定与人精神状态变化相关的AU4、AU12等18个面部动作单元,并调用预先训练的基于CNN的AU检测模型对面部朝向检测滤除后的静态图像模态数据进行AU检测,其中CNN具体使用ResNet骨架结构、进行多标签调整并使用自有数据进行训练,并对各个AU的结果提取均值、方差等统计特征,并根据预先设定的各个AU的时间长度参数计算对应AU的动作次数,将各个AU的统计特征与动作次数进行拼接形成单AU特征,将各个AU的单AU特征拼接形成图像模态静态AU特征。
其中,在一个实施例中,目光朝向检测检测双眼的目光朝向,并调用预先训练的基于CNN的目光朝向检测模型进行检测,其中CNN具体使用Resnet+LSTM骨架结构并使用自有数据进行训练,并对双眼的目光朝向计算空间坐标系下各个坐标维度的均值、方差、中位数绝对偏差、峰度等特征并按该顺序组成向量,并按左眼、右眼的次序拼接,形成图像模态静态目光朝向特征。
其中,在一个实施例中,将图像模态静态AU特征、图像模态静态目光朝向特征、图像模态静态面部朝向特征拼接形成图像模态静态特征。
3.1.2调用静态语音分析模块,对输入的静态数据所包含的视频依次做语音提取,并根据预先定义的特征集,进行静态语音模态特征提取,输出语音静态特征。
在一个实施例中,基于python语言和相应特征公式,对语音提取MFCC特征、短时过零率、第一共振峰、第二共振峰、第三共振峰、声压级等分别计算均值及方差,并按该顺序组成向量,形成语音模态静态特征。
3.1.3调用静态文字分析模块,对输入的静态数据所包含的视频依次做文字提取,并根据预先定义的特征集,调用预先训练的基于情感词典和CNN的文字模态特征提取模型进行静态文字模态特征提取,输出文字静态特征。
在一个实施例中,文字提取通过语音自动识别完成,将所讲述的全部内容形成段落,并调用预先训练的情感分数词典计算情感分数,形成文字模态静态特征一,其中情感词典为针对不同词语的属性、含义等对其赋给分数值,并针对抑郁症、双相情感障碍、焦虑症等具体语境进行适当调整,进而可以计算句子乃至段落的情感分数;并调用预先训练的基于CNN的向量嵌入神经网络,形成文字模态静态特征二,其中具体使用doc2vec方法进行文字特征提取,并基于Transformer骨架网络使用自有数据进行训练。将文字模态静态特征一与文字模态静态特征二以拼接的形式融合形成文字静态特征。
3.2动态数据分析。具体过程为:将各个刺激形式下收集的动态数据按顺序依次输入到图像分析模块、语音分析模块、文字分析模块进行分析处理,包括特征提取和精神疾病辅助诊断两部分。
3.2.1调用动态图像分析模块,对输入的动态数据所包含的视频依次做图像提取,并根据预先定义的特征集,调用预先训练的图像模态特征提取模型进行动态图像模态特征提取,输出图像动态特征。预先训练的图像模态特征提取模型包括基于CNN的预先训练的面部朝向检测模型、预先训练的AU检测模型、预先训练的目光朝向检测模型。
在一个实施例中,预先定义的特征集包括面部动作单元检测、目光朝向检测、面部朝向检测。本发明对访谈全过程的各个AU进行时间占比、次数等仅为该模态特征的一部分,对目光朝向和面部朝向进行统计分析,并就各个特征与抑郁程度进行相关性分析后,通过阈值筛选相关性高的特征作为该模态特征。
其中,在一个实施例中,面部朝向检测检测面部的朝向,并调用预先训练的基于CNN的面部朝向检测模型进行检测,其中CNN具体使用Resnet骨架结构并使用自有数据进行训练,根据预先定义的面部朝向阈值滤除无效数据,并计算空间坐标系下各个坐标维度的均值、方差、中位数绝对偏差、峰度等特征并按该顺序组成向量,形成图像模态动态面部朝向特征。本发明将面部朝向纳入特征集,同时根据面部朝向对视频中偏转角度过大的异常帧进行滤除,保证AU检测数据输入的合理性。
其中,在一个实施例中,面部动作单元检测选定与人精神状态变化相关的AU4、AU12等18个面部动作单元,并调用预先训练的基于CNN的AU检测模型对面部朝向检测滤除后的动态图像模态数据进行AU检测,其中CNN具体使用ResNet骨架结构、进行多标签调整并使用自有数据进行训练,并对各个AU的结果提取均值、方差等统计特征,并根据预先设定的各个AU的时间长度参数计算对应AU的动作次数,将各个AU的统计特征与动作次数进行拼接行程单AU特征,将各个AU的单AU特征拼接形成图像模态动态AU特征。
本发明使用深度学习方法,搭配高计算能力的GPU服务器完成AU检测,保证AU检测的准确性与高效性。
其中,在一个实施例中,目光朝向检测检测双眼的目光朝向,并调用预先训练的基于CNN的目光朝向检测模型进行检测,其中CNN具体使用Resnet+LSTM骨架结构并使用自有数据进行训练,并对双眼的目光朝向计算空间坐标系下各个坐标维度的均值、方差、中位数绝对偏差、峰度等特征并按该顺序组成向量,并按左眼、右眼的次序拼接,形成图像模态动态目光朝向特征。
其中,在一个实施例中,将图像模态动态AU特征、图像模态动态目光朝向特征、图像模态动态面部朝向特征拼接形成图像模态动态特征。
3.2.2调用动态语音分析模块,对输入的动态数据所包含的视频依次做语音提取,并根据预先定义的特征集,进行动态语音模态特征提取,输出语音动态特征。
在一个实施例中,基于python语言和相应特征公式,对语音提取MFCC特征、短时过零率、第一共振峰、第二共振峰、第三共振峰、声压级等分别计算均值及方差,并按该顺序组成向量,形成语音模态动态特征。
3.2.3调用动态文字分析模块,对输入的动态数据所包含的视频依次做文字提取,并根据预先定义的特征集,调用预先训练的基于情感词典和CNN的文字模态特征提取模型进行动态文字模态特征提取,输出文字动态特征。
在一个实施例中,文字提取通过语音自动识别完成,将所讲述的全部内容形成段落,并调用预先训练的情感分数词典计算情感分数,形成文字模态动态特征一,其中情感词典为针对不同词语的属性、含义等对其赋给分数值,并针对抑郁症、双相情感障碍、焦虑症等具体语境进行适当调整,进而可以计算句子乃至段落的情感分数;并调用预先训练的向量嵌入神经网络,形成文字模态动态特征二,其中具体使用doc2vec方法进行文字特征提取,并基于Transformer骨架网络使用自有数据进行训练。将文字模态动态特征一与文字模态动态特征二以拼接的形式融合形成文字动态特征。
步骤4:单模态处理。
4.1调用图像分析模块,对3.1.1和3.2.1输出的图像模态特征进行特征融合,形成图像模态特征,调用预先训练的图像模态辅助诊断模型进行分析,生成图像模态辅助诊断结果。其中预先训练的图像模态辅助诊断模型具体为一个根据输入特征进行分类任务的分类器。
在一个实施例中,3.1.1和3.2.1输出的图像模态特征采取拼接的形式进行特征融合。
在一个实施例中,预先训练的图像模态辅助诊断模型采用一个4层的神经网络(Neural Network,NN,下同),在另一个实施例中,预先训练的图像模态辅助诊断模型采用一个高斯核的支撑向量机(Support Vector Machine,SVM,下同)。
在一个实施例中,生成针对抑郁症的辅助诊断结果,图像模态辅助诊断模型输出结果为参与者健康、轻度、中度、重度抑郁症的概率分布,概率最大者为参与者的抑郁症辅助诊断结果。
在另一个实施例中,生成针对双相情感障碍的辅助诊断结果,图像模态辅助诊断模型输出结果为参与者健康、轻度、中度、重度双相情感障碍的概率分布,概率最大者为参与者的双相情感障碍辅助诊断结果。
在另一个实施例中,生成针对焦虑症的辅助诊断结果,图像模态辅助诊断模型输出结果为参与者健康、轻度、中度、重度焦虑症的概率分布,概率最大者为参与者的焦虑症辅助诊断结果。
4.2调用语音分析模块,对3.1.2和3.2.2输出的语音模态特征进行融合,调用预先训练的基于NN的语音模态辅助诊断模型进行分析,生成语音模态辅助诊断结果。其中预先训练的语音模态辅助诊断模型具体为一个根据输入特征进行分类任务的分类器。
在一个实施例中,3.1.2和3.2.2输出语音模态特征采取拼接的形式进行特征融合。
在一个实施例中,预先训练的语音模态辅助诊断模型采用一个3层的NN,在另一个实施例中,预先训练的语音模态辅助诊断模型采用一个线性核的SVM。
在一个实施例中,生成针对抑郁症的辅助诊断结果,语音模态辅助诊断模型输出结果为参与者健康、轻度、中度、重度抑郁症的概率分布,概率最大者为参与者的抑郁症辅助诊断结果。
在另一个实施例中,生成针对双相情感障碍的辅助诊断结果,语音模态辅助诊断模型输出结果为参与者健康、轻度、中度、重度双相情感障碍的概率分布,概率最大者为参与者的双相情感障碍辅助诊断结果。
在另一个实施例中,生成针对焦虑症的辅助诊断结果,语音模态辅助诊断模型输出结果为参与者健康、轻度、中度、重度焦虑症的概率分布,概率最大者为参与者的焦虑症辅助诊断结果。
4.3调用文字分析模块,对3.1.3和3.2.3输出的文字模态特征进行特征融合,调用预先训练的文字模态辅助诊断模型进行分析,生成文字模态辅助诊断结果。其中预先训练的文字模态辅助诊断模型具体为一个根据输入特征进行分类任务的分类器。
在一个实施例中,3.1.3和3.2.3输出的文字模态特征采取拼接的形式进行特征融合。
在一个实施例中,预先训练的文字模态辅助诊断模型采用一个3层的NN,在另一个实施例中,预先训练的文字模态辅助诊断模型采用一个高斯核的SVM。
在一个实施例中,生成针对抑郁症的辅助诊断结果,文字模态辅助诊断模型输出结果为参与者健康、轻度、中度、重度抑郁症的概率分布,概率最大者为参与者的抑郁症辅助诊断结果。
在另一个实施例中,生成针对双相情感障碍的辅助诊断结果,文字模态辅助诊断模型输出结果为参与者健康、轻度、中度、重度双相情感障碍的概率分布,概率最大者为参与者的双相情感障碍辅助诊断结果。
在另一个实施例中,生成针对焦虑症的辅助诊断结果,文字模态辅助诊断模型输出结果为参与者健康、轻度、中度、重度焦虑症的概率分布,概率最大者为参与者的焦虑症辅助诊断结果。
步骤5:多模态处理。具体过程为:调用多模态分析模块进行综合分析处理,对各个模态的静态、动态特征分别进行特征融合生成多模态静态特征、多模态动态特征,并调用预先训练的多模态辅助诊断模型进行处理,生成多模态辅助诊断结果。其中预先训练的多模态辅助诊断模型具体为一个根据输入特征进行分类任务的分类器。
5.1对3.1.1~3.1.3输出的单模态静态特征进行静态特征融合,生成多模态静态特征。
在一个实施例中,采取拼接的方式生成多模态静态特征。
在另一个实施例中,选取3.1.1~3.1.3输出的单模态静态特征中相关度高的特征项组成多模态静态特征,其中具体项的选择调用预先设置的配置文件,该文件记录预先计算好的各单模态静态特征与精神疾病程度之间的绝对值相关性关系,且该关系选取线性相关性结果与非线性相关性结果的并集,其中线性相关采用pearson相关系数,非线性相关采用spearman相关系数。预先设置的相关性配置文件中涉及的相关性计算过程为,分别采用根据自有样本所提取的特征与自有样本中抑郁症、双相情感障碍、焦虑症等精神疾病的实际诊断结果,分别根据对应的数学公式基于python语言进行相关性计算并预先保存相关性高于阈值的特征项,其中设定抑郁症、双相情感障碍、焦虑症阈值分别为相关性绝对值高于0.3、0.34、0.3。
5.2对3.2.1~3.2.3输出的单模态动态特征进行动态特征融合,生成多模态动态特征。
在一个实施例中,采取拼接的方式生成多模态动态特征。
在另一个实施例中,选取3.2.1~3.2.3输出的单模态动态特征中相关度高的特征项组成多模态动态特征,其中具体项的选择调用预先设置的配置文件,该文件记录预先计算好的各单模态动态特征与精神疾病程度之间的绝对值相关性关系,且该关系选取线性相关性结果与非线性相关性结果的并集,其中线性相关采用pearson相关系数,非线性相关采用kendall相关系数。预先设置的相关性配置文件中涉及的相关性计算过程为,分别采用根据自有样本所提取的特征与自有样本中抑郁症、双相情感障碍、焦虑症等精神疾病的实际诊断结果,分别根据对应的数学公式基于python语言进行相关性计算并预先保存相关性高于阈值的特征项,其中设定抑郁症、双相情感障碍、焦虑症阈值分别为相关性绝对值高于0.3、0.34、0.3。
5.3对多模态静态特征和多模态动态特征进行特征融合,生成多模态特征,并调用预先训练的多模态辅助诊断模型进行处理,生成多模态辅助诊断结果。其中预先训练的多模态辅助诊断模型具体为一个根据输入特征进行分类任务的分类器。
在一个实施例中,采取拼接的形式进行特征融合。
在一个实施例中,预先训练的多模态辅助诊断模型采用一个4层的NN,在另一个实施例中,预先训练的多模态辅助诊断模型采用一个线性核的SVM。
在一个实施例中,生成针对抑郁症的辅助诊断结果,多模态辅助诊断模型输出结果为参与者健康、轻度、中度、重度抑郁症的概率分布,概率最大者为参与者的抑郁症辅助诊断结果。
在另一个实施例中,生成针对双相情感障碍的辅助诊断结果,多模态辅助诊断模型输出结果为参与者健康、轻度、中度、重度双相情感障碍的概率分布,概率最大者为参与者的双相情感障碍辅助诊断结果。
在另一个实施例中,生成针对焦虑症的辅助诊断结果,多模态辅助诊断模型输出结果为参与者健康、轻度、中度、重度焦虑症的概率分布,概率最大者为参与者的焦虑症辅助诊断结果。
步骤6:报告生成。过程为:调用报告生成模块,生成多模态辅助诊断报告。具体地,对数据收集模块、各个单模态分析模块和多模态分析模块的输出进行汇总记录,根据多模态分析模型的输出结果,调用意见建议模块,给出相应的意见建议,并结合数据收集模块的个人信息,生成辅助诊断报告。
在一个实施例中,生成的辅助诊断报告内容包括以下各项:
内容一:个人信息项,包括姓名、性别、年龄、教育程度、个人专用ID、病史。
内容二:单模态辅助诊断结果,包括图像模态辅助诊断结果、语音模态辅助诊断结果、文字模态辅助诊断结果,每个模态的辅助诊断结果均以判断的精神疾病程度结果以及各个程度概率的形式给出,抑郁症则包含步骤4.1~4.3输出的各个模态下的抑郁症辅助诊断结果,双相情感障碍则包含步骤4.1~4.3输出的各个模态下的双相情感障碍辅助诊断结果,焦虑症则包含步骤4.1~4.3输出的各个模态下的焦虑症辅助诊断结果。
内容三:多模态辅助诊断结果,以判断的精神疾病程度结果以及各个程度概率的形式给出,抑郁症则包含步骤5.3输出的各个模态下的抑郁症辅助诊断结果,双相情感障碍则包含步骤5.3输出的各个模态下的双相情感障碍辅助诊断结果,焦虑症则包含5.3输出的各个模态下的焦虑症辅助诊断结果。
内容四:意见建议,与多模态辅助诊断结果相匹配的意见建议,如针对抑郁症的轻度辅助诊断结果,给出“抑郁症轻度,建议放松心情,规范作息,适度运动,尝试自我调节。如出现连续15天及以上情绪低落、体重明显下降、兴趣减退、睡眠质量下降等,建议去医院做相关检查,寻求医生的帮助。
在一个实施例中,生成针对抑郁症的辅助诊断报告。
在一个实施例中,生成针对双相情感障碍的辅助诊断报告。
在另一个实施例中,生成针对焦虑症的辅助诊断报告。
相应于上述本发明实施例提供的系统,本发明实施例还提供了一种电子设备,包括:处理器、通信接口、存储器和通信总线,其中,处理器、通信接口、存储器通过通信总线完成相互间的通信;
存储器,用于存放计算机程序;
处理器,用于执行存储器上所存放的程序时,实现上述本发明实施例提供的系统流程。
上述控制设备设备中提到的通信总线可以是外设部件互连标准(PeripheralComponent Interconnect,PCI)总线或扩展工业标准结构(Extended Industry StandardArchitecture,EISA)总线等。该通信总线可以分为地址总线、数据总线、控制总线等。为便于表示,图中仅用一条粗线表示,但并不表示仅有一根总线或一种类型的总线。
通信接口用于上述电子设备与其他设备之间的通信。
存储器可以包括随机存取存储器(Random Access Memory,RAM),也可以包括非易失性存储器(Non-Volatile Memory,NVM),例如至少一个磁盘存储器。可选的,存储器还可以是至少一个位于远离前述处理器的存储装置。
上述的处理器可以是通用处理器,包括中央处理器(Central Processing Unit,CPU)、网络处理器(Network Processor,NP)等;还可以是数字信号处理器(Digital SignalProcessing,DSP)、专用集成电路(Application Specific Integrated Circuit,ASIC)、现场可编程门阵列(Field-Programmable Gate Array,FPGA)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。
在本发明提供的又一实施例中,还提供了一种计算机可读存储介质,该计算机可读存储介质内存储有计算机程序,所述计算机程序被处理器执行时实现上述本发明实施例提供的任一方法的步骤。
在本发明提供的又一实施例中,还提供了一种包含指令的计算机程序产品,当其在计算机上运行时,使得计算机执行上述本发明实施例提供的任一方法的步骤。
在上述实施例中,可以全部或部分地通过软件、硬件、固件或者其任意组合来实现。当使用软件实现时,可以全部或部分地以计算机程序产品的形式实现。所述计算机程序产品包括一个或多个计算机指令。在计算机上加载和执行所述计算机程序指令时,全部或部分地产生按照本发明实施例所述的流程或功能。所述计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。所述计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一个计算机可读存储介质传输,例如,所述计算机指令可以从一个网站站点、计算机、服务器或数据中心通过有线(例如同轴电缆、光纤、数字终端设备线(DSL))或无线(例如红外、无线、微波等)方式向另一个网站站点、计算机、服务器或数据中心进行传输。所述计算机可读存储介质可以是计算机能够存取的任何可用介质或者是包含一个或多个可用介质集成的服务器、数据中心等数据存储设备。所述可用介质可以是磁性介质,(例如,软盘、硬盘、磁带)、光介质(例如,DVD)、或者半导体介质(例如固态硬盘Solid State Disk(SSD))等。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
本说明书中的各个实施例均采用相关的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于装置实施例、电子设备实施例、计算机可读存储介质实施例和计算机程序产品实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
以上所述仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内所作的任何修改、等同替换、改进等,均包含在本发明的保护范围内。
- 一种多模态图像辅助诊断系统及其搭建方法
- 基于多模态信息的自闭症辅助诊断系统、设备及介质
- 一种基于视觉模态分析的避雷器故障诊断系统及诊断方法
- 一种基于视频分析的多模态癫痫诊断系统和方法