基于体检数据建立的人体健康模型系统
文献发布时间:2024-04-18 20:01:30
技术领域
本发明涉及物联网数据分析建模领域,具体涉及基于体检数据建立的人体健康模型系统。
背景技术
近年来,人们对健康的关注程度大幅提高。以往的体检数据,只是作为每年的健康指标,只有不出现异常,或是出现异常进行补救两种用途。但是实际上,体检数据是可以作为人体每年的基本数据,为人体的健康情况提供历史参考以及未来预测的。因此以体检数据为人体建立健康模型,就可以成为大数据建模基础上的新型健康理念。
现有的体检机构基本都是独立运行,想要调用个体完整的体检数据,需要多机构、多部门的配合,所获取的数据可能存在保存格式不同、数据录入有差异的问题;无法直接实现对人体数据的分析。
发明内容
针对上述情况,本发明的目的在于:提供一种基于体检数据建立的人体健康模型系统,基于体检数据为个体进行健康建模,通过深度学习方式实现了对纸质版体检报告的读取和整合功能;使得体检数据既有了历史数据的价值,又为个体在之后的健康情况的提供指导价值,可有效提高预测的准确性。
为实现上述目的,本发明所采取的技术方案是:提供一种基于体检数据建立的人体健康模型系统,具体如下:
步骤一:数据收集,其通过系统数据接口,调用各体检机构的体检报告数据;
步骤二:对收集数据进行预处理,具体包括数据清洗、缺失值处理及异常值处理;
步骤三:特征提取,从数据库中,选取目标特征数据,构建人体健康模型;
步骤四:特征工程,对提取的特征进行处理与转换,具体是利用标准化、归一化或特征选取方法进行处理;
步骤五:模型构建,基于机器学习或深度学习模型来构建人体健康模型;具体选用支持向量机(SVM)、随机森林或神经网络模型;
步骤六:数据模型训练,使用已准备好的特征和标签数据进行模型训练;通过调整模型参数和优化算法,使模型能够准确地预测人体健康状态;
步骤七:模型评估,使用独立的测试集评估模型的性能,具体包括:计算准确率、召回率、F1分数等指标,用以确保模型的泛化能力和预测准确性;
步骤八:健康模型应用,将训练好的健康模型应用于新的个体数据,通过输入相关特征,预测其健康状况,为个体提供一些有针对性的建议和指导;
步骤九:数据隐私和安全性,通过数据脱敏去除上一步骤的个人身份信息,加密敏感数据保证个体数据的隐私;实现的程序函数为UserPrivacy(UserHealthModelApplication),制定数据共享协议,明确后一步骤使用数据的目的、范围和权限,确保个体用户数据的安全性和合规性。实现的程序函数为UserDataSharingProtocol(UserPrivacy)。
所述步骤一中,体检报告数据包括:生理指标、血液检测结果、影像学检查的数据与图谱等。
所述步骤五中的支持向量机(SVM),适用于处理线性和非线性分类问题,可以处理高维数据,但对大规模数据集的处理效率相对较低。
所述步骤五中的随机森林(Random Forest),能够处理高维数据和特征交互关系,具有较好的泛化性能和可解释性。
所述步骤五中的深度学习,包括卷积神经网络和循环神经网络,能够处理复杂的非线性关系和大规模数据集,但需要更多的数据和计算资源。
所述特征选择和降维技术:
(1)主成分分析:通过线性变换将原始特征转换为更少的主成分,减少数据维度,保留大部分的信息,但可能会丢失一些细节信息;
(2)方差选择法:根据特征的方差选择最相关的特征,忽略方差较小的特征,可以减少特征数量,但可能会忽略一些重要特征;
(3)递归特征消除:通过递归地删除对模型预测影响较小的特征,选择最相关的特征,但可能会忽略一些次要但有用的特征。
所述模型评估的指标包括:
(1)准确率:预测结果与实际结果相符的比例;
(2)召回率:正确预测为正例样本的比例;
(3)F1分数:综合考虑准确率和召回率的平衡指标;
(4)ROC曲线和AUC:衡量二分类模型的性能。
本发明的有益效果是:基于体检数据为个体进行健康建模,通过深度学习方式实现了对纸质版体检报告的读取和整合功能;使得体检数据既有了历史数据的价值,又为个体在之后的健康情况的提供指导价值,可有效提高预测的准确性。
附图说明
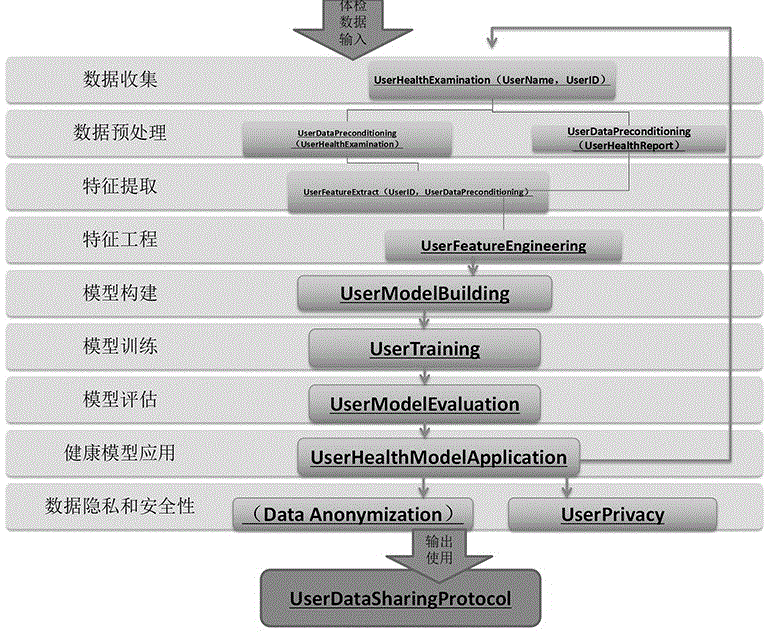
图1是基于体检数据建立的人体健康模型系统示意图;
图2是健康模型系统建立调用示意图。
实施方式
以下通过实施例对本申请进行说明。
如图1、2所示,本发明提供了一种基于体检数据建立的人体健康模型系统,系统结构包括:数据收集、数据预处理、特征提取、特征工程、模型构建、模型训练、模型评估、健康模型应用、数据隐私和安全性。
数据收集:该部分是通过合作的体检机构的数据接口UserHealthExamination(UserName,UserID)收集个体的体检报告数据,包括体检报告中的基本生理数据,检测数据等。对于非合作体检机构的用户,则通过UserHealthReport(UserName,UserID,UserGraphicExtract)程序收集个体的体检报告数据,收集数据指标同上。
数据预处理:该部分对上一步所收集到的数据进行预处理,包括数据缺失值的处理,数据异常值的处理,数据的准确性和一致性通过UserDataPreconditioning(UserHealthExamination)和UserDataPreconditioning(UserHealthReport)预处理至符合下一步函数调用的要求。
特征提取:该部分用于从处理好的体检数据中,提取出关键特征,如个体的血压,血糖水平,胆固醇水平等,作为建立人体健康模型的重点数据。实现的程序函数为UserFeatureExtract(UserID,UserDataPreconditioning)。
特征工程:该部分用于对上步骤内提取的特征进行进一步的处理和转换,标准化为本专利中人体模型所需的数据类型,确保特征的可比性和有效性。实现的程序函数为UserFeatureEngineering(UserID,UserFeatureExtract)。使用的技术是特征选择和降维技术中的:主成分分析(PCA),方差选择法(Variance Thresholding),以及递归特征消除(Recursive Feature Elimination)。
模型构建:该部分同时将其他专利中包括的个体健康数据,保险数据,人存检测数据等同样进行调用进来,使用机器学习或是深度学习模型(根据不同专利中的数据特征选择使用这两种方式中的某一种)进行人体健康模型构建。实现函数为UserModelBuilding(UserID,UserFeatureEngineering)。使用技术为机器学习方法:支持向量机(SVM),随机森林(RandomForest)和深度学习(DeepLearning)中的卷积神经网络(CNN)方式和循环神经网络(RNN)方式。
模型训练:该部分使用已经准备好的特征和标签数据,结合标准科学的健康区域值和阈值,进行模型训练。通过调整模型(UserTraining(UserID,UserModelBuilding))参数和优化算法,使模型能够准确地预测人体健康状态。
模型评估:该部分属于纠错部分,使用独立的测试集评估模型的性能,包括但不限于计算准确率,召回率,F1分数等指标,确保模型UserModelEvaluation(UserID,UserTraining)的泛化能力和预测准确性。模型评估指标采用的技术主要是准确率(Accuracy),召回率(Recall),F1分数(F1 Score),ROC曲线和AUC(Area Under theCurve)。
健康模型应用:该部分将训练好的健康模型应用于新的个体数据,通过每年的体检报告,或是更新的体检数据,通过输入数值,预测其健康情况,并且可以提供一些有针对性的建议和指导,实现函数为UserHealthModelApplication(UserID,UserHealthExamination,UserHealthReport)。
数据隐私和安全性:该部分通过数据脱敏(Data Anonymization)去除上一步骤的个人身份信息,加密敏感数据等手段保证个体数据的隐私。实现的程序函数为UserPrivacy(UserHealthModelApplication),并且制定数据共享协议,明确后一步骤使用数据的目的,范围和权限,确保个体用户数据的安全性和合规性。实现的程序函数为UserDataSharingProtocol(UserPrivacy)。
需要根据具体应用场景和数据特点选择适合的技术和方法,并综合考虑模型的准确性、效率、可解释性和数据隐私等因素,由此在程序中对以上技术工具进行调用和使用。
此外,其他检测采集的数据也可连接到本系统中,提高数据库样本数量,以便提高后期预测的准确性;相关数据可以包括:结合人存检测材料中的人存数据和疾病预测数据;结合健康设计保险材料中的日常健康数据;结合日常检测的健康数据,如血糖,血氧,血压等;结合心肺检测的心率,肺部,肠部等情况的健康数据;结合血流速度检测动脉硬化的健康数据,具体实现可转化为:
(1)多源数据集成:将来自不同数据源的信息进行融合,提高模型的综合性能,如体检数据、基因组数据、生活习惯数据等;
(2)多模态学习:将不同类型的数据作为输入,进行联合建模,提供更全面的健康评估,如图像、文本、声音等。
通过数据集成,将用户个人的各种形式的整体健康信息进行融合,充实人体健康建模功能,将用户数据提升到一个动态全面的健康评估作用。