拜占庭攻击鲁棒的联邦电子健康档案表型提取方法
文献发布时间:2024-04-18 20:01:30
技术领域
本发明属于数据处理技术领域,具体涉及一种拜占庭攻击鲁棒的联邦电子健康档案表型提取方法。
背景技术
由实体网络如医院、诊所、药房公司编织而成的现代医疗保健系统正在从具有各种医疗程序、药物、诊断和实验室测试的大量个人那里收集电子健康记录。张量分解具有良好的高维数据表示能力,为了从更高数量的关系电子健康记录中提取有意义的医学概念即表型,其被应用于表型提取中。CANDECOMP/PARAFAC或规范多元张量分解及其泛化GTF是分析张量的基本工具,然而,最基本的CP分解模型难以对大型数据集进行高效的分解,分布式张量分解方法才可处理单台机器无法处理的大张量。但是,在分布式环境中需要进行数据共享和交换,由于涉及隐私问题,这通常会受到政策的阻碍。
目前,联邦学习为不同实体之间的协作学习提供了一种隐私保护方式,联邦张量分解方法避免了共享原始张量和患者模式的相关变量,成为分布式数据在隐私保护方面更好的DTF范式,同时能够保持与之相当的计算能力和存储可扩展性。然而,联邦学习需要执行客户端和服务器之间的通信操作,在联邦计算表型分析中,由于属性的多样性,如药物的类型可能有数千种,高维张量会在每个通信周期中产生高通信成本,尽管张量分解因其表示高维数据的能力在一定程度上减少了通信成本,但仍然难以面对庞大的数据传输压力。
为了解决联邦学习中通信成本高的问题,现有技术中还存在带有高效通信的联邦张量分解方法。但是,由于联邦学习分布式的环境特性,该方法安全性较低,恶意用户采取对抗行动、亦或是硬件故障、软件错误、数据崩溃都会导致来自客户端的信息出错;计算单元固有的不可预测和潜在对抗性等性质通常被建模为拜占庭式故障。拜占庭式故障往往会导致算法难以收敛,尤其是在关乎人类身体健康的大数据医疗系统,算法模型的出错会造成难以估量的经济损失,更有甚者会严重威胁人体的生命安全。
发明内容
为了解决现有技术中存在的上述问题,本发明提供了一种拜占庭攻击鲁棒的联邦电子健康档案表型提取方法。本发明要解决的技术问题通过以下技术方案实现:
第一方面,本发明实施例提供一种拜占庭攻击鲁棒的联邦电子健康档案表型提取方法,应用于K个客户端,所述客户端包括正常客户端和拜占庭客户端;
所述表型提取方法包括:
获取电子健康记录EHR张量,并根据所述EHR张量分解成因子矩阵;所述因子矩阵包括患者因子矩阵、诊断因子矩阵和用药因子矩阵;
接收服务器发送的时间采样序列;
根据所述时间采样序列中的当前索引,判断因子矩阵是否被选中;
当选中的因子矩阵为诊断因子矩阵或用药因子矩阵时,正常客户端利用被选中的因子矩阵的随机梯度和反馈误差计算得到第一梯度后,根据服务器发送的第二梯度更新下一索引选中的因子矩阵、并根据第一梯度更新下一索引选中的因子矩阵的反馈误差;
当接收到服务器发送的第一指令时,根据被选中的诊断因子矩阵和用药因子矩阵获得电子健康档案的表型提取结果。
在本发明的一个实施例中,所述根据所述时间采样序列中的当前索引,判断因子矩阵是否被选中的步骤,包括:
根据所述时间采样序列中的当前索引,判断因子矩阵是否被选中;
若是,则根据第一目标函数计算被选中的因子矩阵的随机梯度。
在本发明的一个实施例中,若因子矩阵被选中,所述根据第一目标函数计算被选中的因子矩阵的随机梯度的步骤之后,还包括:
当被选中的因子矩阵为患者因子矩阵时,所述客户端按照如下公式更新下一索引选中的因子矩阵:
式中,A
在本发明的一个实施例中,当选中的因子矩阵为诊断因子矩阵或用药因子矩阵时,所述正常客户端利用被选中的因子矩阵的随机梯度和反馈误差计算得到第一梯度后,根据服务器发送的第二梯度更新下一索引选中的因子矩阵、并根据第一梯度更新下一索引选中的因子矩阵的反馈误差的步骤,包括:
正常客户端利用被选中的因子矩阵的随机梯度和反馈误差计算第一梯度,拜占庭客户端生成任意值;
将所述第一梯度和所述任意值发送至服务器,以使所述服务器按照非降序对所述第一梯度和所述任意值进行排序后,根据从排序结果中选取的预设数量个数据计算得到第二梯度,并将所述第二梯度广播至所述客户端;
正常客户端根据所述第二梯度更新下一索引选中的因子矩阵,并根据所述第一梯度更新下一索引选中的因子矩阵的反馈误差。
在本发明的一个实施例中,正常客户端按照如下公式更新下一索引选中的因子矩阵:
A
式中,Δ表示第二梯度,d表示因子矩阵的索引,A
在本发明的一个实施例中,正常客户端按照如下公式更新下一索引选中的因子矩阵的反馈误差:
式中,k表示客户端的索引,
在本发明的一个实施例中,所述当接收到服务器发送的第一指令时,根据被选中的诊断因子矩阵和用药因子矩阵获得电子健康档案的表型提取结果的步骤之前,还包括:
判断是否接受到服务器发送的第一指令;
当选中的因子矩阵为诊断因子矩阵或用药因子矩阵时,正常客户端利用被选中的因子矩阵的随机梯度和反馈误差计算得到第一梯度后,根据服务器发送的第二梯度更新下一索引选中的因子矩阵、并根据第一梯度更新下一索引选中的因子矩阵的反馈误差的步骤之后,还包括:
当未接收到服务器发送的第一指令时,将下一索引作为当前索引,并返回所述根据所述时间采样序列中的当前索引,判断因子矩阵是否被选中的步骤。
第二方面,本发明提供一种拜占庭攻击鲁棒的联邦电子健康档案表型提取方法,应用于服务器,包括:
随机生成时间采样序列;
将所述时间采样序列分别发送至K个客户端,以使各客户端在获取EHR张量后,根据HER张量分解成患者因子矩阵、诊断因子矩阵和用药因子矩阵,并根据所述时间采样序列中的当前索引,判断因子矩阵是否被选中,在选中的因子矩阵为诊断因子矩阵或用药因子矩阵时,使K个客户端中的正常客户端利用反馈误差和被选中的因子矩阵的随机梯度计算第一梯度,并使拜占庭客户端随机生成任意值;
接收所述正常客户端发送的第一梯度及所述拜占庭客户端发送的任意值,并按照非降序对所述第一梯度和所述任意值进行排序;
从排序结果中选取预设数量个数据,并计算得到第二梯度;
将所述第二梯度广播至所述客户端,以使所述客户端根据所述第二梯度更新下一索引选中的因子矩阵、并根据第一梯度更新下一索引选中的因子矩阵的反馈误差;
当第二目标函数收敛或达到预设迭代次数时,发送第一指令至所述客户端,以使所述客户端根据更新后的诊断因子矩阵和用药因子矩阵获得电子健康档案的表型提取结果。
在本发明的一个实施例中,所述从排序结果中选取预设数量个数据,并计算得到第二梯度的步骤,包括:
从排序结果中选取预设数量个数据并计算平均值,得到第二梯度。
与现有技术相比,本发明的有益效果在于:
本发明提供一种拜占庭攻击鲁棒的联邦电子健康档案表型提取方法,利用梯度阈值方法实现了涉及多医院分布式电子病历数据的安全与隐私的协同表型提取,并且可用于拜占庭攻击与隐私攻击的对抗环境下,有效保证了计算的安全与隐私,具有高通信效率及高可用性。
以下将结合附图及实施例对本发明做进一步详细说明。
附图说明
图1是本发明实施例提供的拜占庭攻击鲁棒的联邦电子健康档案表型提取方法的一种流程图;
图2是本发明实施例提供的拜占庭攻击鲁棒的联邦电子健康档案表型提取方法的另一种流程图;
图3a是本发明实施例提供的表型提取方法的一种收敛时间开销对比图;
图3b是本发明实施例提供的表型提取方法的另一种收敛时间开销对比图;
图4a是本发明实施例提供的表型提取方法的一种通信开销对比图;
图4b是本发明实施例提供的表型提取方法的另一种通信开销对比图。
具体实施方式
下面结合具体实施例对本发明做进一步详细的描述,但本发明的实施方式不限于此。
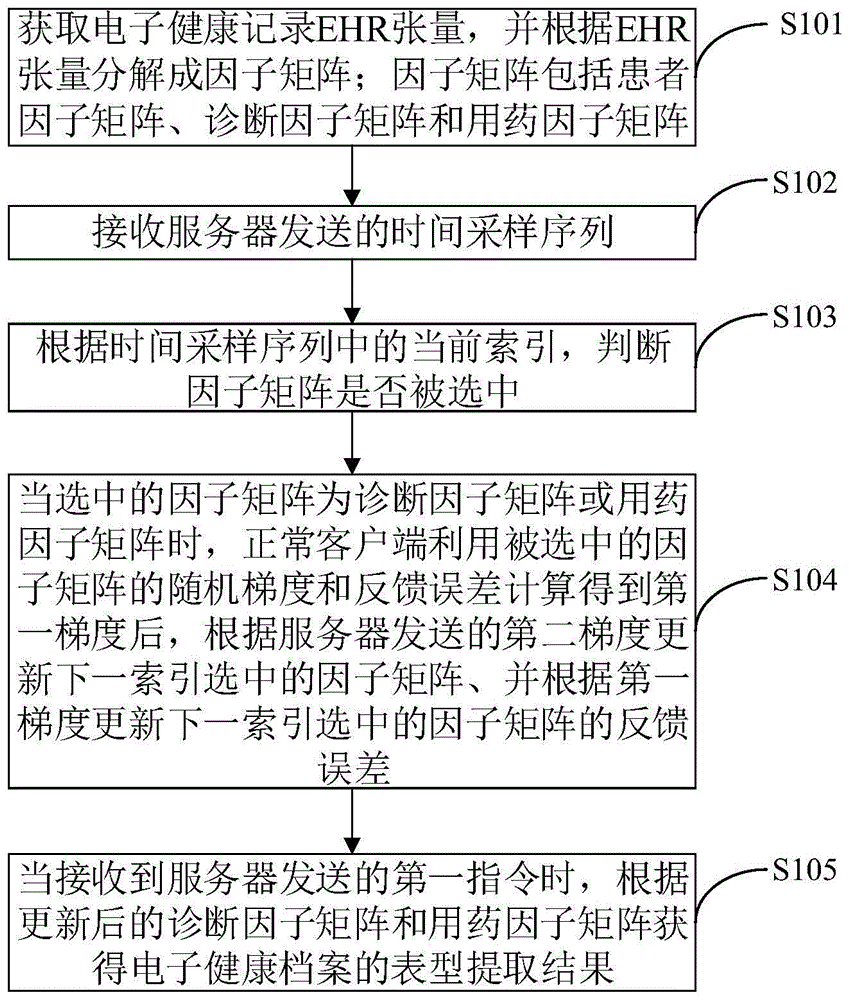
图1是本发明实施例提供的拜占庭攻击鲁棒的联邦电子健康档案表型提取方法的一种流程图。如图1所示,本发明实施例提供一种拜占庭攻击鲁棒的联邦电子健康档案表型提取方法,应用于K个客户端,客户端包括正常客户端和拜占庭客户端;
上述表型提取方法包括:
S101、获取电子健康记录EHR张量,并根据EHR张量分解成因子矩阵;因子矩阵包括患者因子矩阵、诊断因子矩阵和用药因子矩阵;
S102、接收服务器发送的时间采样序列;
S103、根据时间采样序列中的当前索引,判断因子矩阵是否被选中;
S104、当选中的因子矩阵为诊断因子矩阵或用药因子矩阵时,正常客户端利用被选中的因子矩阵的随机梯度和反馈误差计算得到第一梯度后,根据服务器发送的第二梯度更新下一索引选中的因子矩阵、并根据第一梯度更新下一索引选中的因子矩阵的反馈误差;
S105、当接收到服务器发送的第一指令时,根据更新后的诊断因子矩阵和用药因子矩阵获得电子健康档案的表型提取结果。
本实施例中,对于EHR三阶张量
需要说明的是,上述表型提取方法适用的联邦环境包括一个服务器和K个客户端,该客户端包括正常客户端和拜占庭客户端,例如K个客户端包含10%的拜占庭客户端和90%的正常客户端。
EHR三阶张量
可选地,上述步骤S103中,根据时间采样序列中的当前索引,判断因子矩阵是否被选中的步骤,包括:
根据时间采样序列中的当前索引,判断因子矩阵是否被选中;
若是,则根据第一目标函数计算被选中的因子矩阵的随机梯度。
本实施例中,第一目标函数为:
可选地,若因子矩阵被选中,根据第一目标函数计算被选中的因子矩阵的随机梯度的步骤之后,还包括:
当被选中的因子矩阵为患者因子矩阵时,所述客户端按照如下公式更新下一索引选中的因子矩阵:
式中,A
另一方面,上述步骤S104中,当选中的因子矩阵为诊断因子矩阵或用药因子矩阵时,正常客户端利用被选中的因子矩阵的随机梯度和反馈误差计算得到第一梯度后,根据服务器发送的第二梯度更新下一索引选中的因子矩阵、并根据第一梯度更新下一索引选中的因子矩阵的反馈误差的步骤,包括:
S1041、正常客户端利用被选中的因子矩阵的随机梯度和反馈误差计算第一梯度,拜占庭客户端生成任意值;
S1042、将第一梯度和任意值发送至服务器,以使服务器按照非降序对第一梯度和任意值进行排序后,根据从排序结果中选取的预设数量个数据计算得到第二梯度,并将第二梯度广播至客户端;
S1043、正常客户端根据第二梯度更新下一索引选中的因子矩阵,并根据第一梯度更新下一索引选中的因子矩阵的反馈误差。
本实施例中,正常客户端首先向当前索引t选中的因子矩阵的随机梯度添加反馈误差
接着,正常客户端压缩
正常客户端将第一梯度发送至服务器、拜占庭客户端将产生的任意值也发送至服务器,服务器将接收到的第一梯度及任意值按照非降序排序,并从排序结果中选取前1-β个数据,然后通过计算1-β个数据的平均值得到第二梯度;其中,β的取值一般来说不小于拜占庭客户端在K个客户端中的数目占比,例如,拜占庭客户端数目占比为10%,则β的取值可以为0.1-0.5之间,若β的值过大,可能会导致正常客户端的信息也被过滤掉。
服务器将计算得到的第二梯度广播至客户端,进而正常客户端按照如下公式更新下一索引t+1选中的因子矩阵:
A
式中,Δ表示第二梯度,d表示因子矩阵的索引,A
进一步地,正常客户端按照如下公式更新下一索引选中的因子矩阵的反馈误差:
式中,k表示客户端的索引,
应当理解,对于当前索引t,未被选中的因子矩阵保持不变。
可选地,当接收到服务器发送的第一指令时,根据被选中的诊断因子矩阵和用药因子矩阵获得电子健康档案的表型提取结果的步骤之前,还包括:
判断是否接受到服务器发送的第一指令;
当选中的因子矩阵为诊断因子矩阵或用药因子矩阵时,正常客户端利用被选中的因子矩阵的随机梯度和反馈误差计算得到第一梯度后,根据服务器发送的第二梯度更新下一索引选中的因子矩阵、并根据第一梯度更新下一索引选中的因子矩阵的反馈误差的步骤之后,还包括:
当未接收到服务器发送的第一指令时,将下一索引作为当前索引,并返回所述根据时间采样序列中的当前索引,判断因子矩阵是否被选中的步骤。
本实施例中,当服务器检测到第二目标函数收敛或达到预设迭代次数时,发送第一指令至客户端,客户端结束迭代,并根据选中的诊断因子矩阵和用药因子矩阵获得电子健康档案的表型提取结果;反之,在第二目标函数未收敛且未达到预设迭代次数时,服务器不发送第一指令,客户端将下一索引t+1更新为当前索引,并返回上述步骤S103。
需要说明的是,提取的表型可包括患者、诊断和用药的组合,但为了保护病人的隐私,本实施例所提取的表型中不发布患者信息、只有诊断和用药的组合,二者分别对应于诊断因子矩阵和用药因子矩阵对应的列。
示例性地,提取的HER表型为:
图2是本发明实施例提供的拜占庭攻击鲁棒的联邦电子健康档案表型提取方法的另一种流程图。如图2所示,本发明实施例还提供一种拜占庭攻击鲁棒的联邦电子健康档案表型提取方法,应用于服务器,包括:
S201、随机生成时间采样序列;
S202、将时间采样序列分别发送至K个客户端,以使各客户端在获取EHR张量后,根据HER张量分解成患者因子矩阵、诊断因子矩阵和用药因子矩阵,并根据时间采样序列中的当前索引,判断因子矩阵是否被选中,在选中的因子矩阵为诊断因子矩阵或用药因子矩阵时,使K个客户端中的正常客户端利用反馈误差和被选中的因子矩阵的随机梯度计算第一梯度,并使拜占庭客户端随机生成任意值;
S203、接收正常客户端发送的第一梯度及拜占庭客户端发送的任意值,并按照非降序对第一梯度和任意值进行排序;
S204、从排序结果中选取预设数量个数据,并计算得到第二梯度;
S205、将第二梯度广播至所述客户端,以使客户端根据第二梯度更新下一索引选中的因子矩阵、并根据第一梯度更新下一索引选中的因子矩阵的反馈误差;
S206、当第二目标函数收敛或达到预设迭代次数时,发送第一指令至客户端,以使客户端根据更新后的诊断因子矩阵和用药因子矩阵获得电子健康档案的表型提取结果。
本实施例中,每次迭代过程中服务器随机生成的时间采样序列可表示为d
上述步骤S204中,从排序结果中选取预设数量个数据,并计算得到第二梯度的步骤,包括:
从排序结果中选取预设数量个数据并计算平均值,得到第二梯度。
图3a-3b是本发明实施例提供的表型提取方法的收敛时间开销对比图,图4a-4b是本发明实施例提供的表型提取方法的通信开销对比图,其中,Bz-FedGTF-EF-PC为带有拜占庭鲁棒性、高效通信、定时通信和误差反馈的联邦张量分解,Bz-FedGTF-EF为本发明提供的上述表型提取方法,即带有拜占庭鲁棒性、高效通信、误差反馈的联邦张量分解,FedGTF-EF-PC为带有高效通信、定时通信和误差反馈的联邦张量分解,FedGTF-EF为带有高效通信和误差反馈的联邦张量分解,DPFact为带有隐私保护的联邦张量分解,BrasCPD为分布式张量分解,GCP为中心化张量分解。
请结合图3a、3b、4a和4b,在伯努利损失函数上达到收敛状态时,本发明所花费的通信开销几乎是最小的,而其他分布式表型提取方法则会因为拜占庭的攻击导致而无法收敛;在最小平方损失函数上,Bz-FedGTF-EF能最快达到收敛,尽管Bz-FedGTF-EF-PC的loss值没有达到最小收敛值,但在所有没有拜占庭鲁邦的算法中仍为最小。
通过上述各实施例可知,本发明的有益效果在于:
本发明提供一种拜占庭攻击鲁棒的联邦电子健康档案表型提取方法,利用梯度阈值方法实现了涉及多医院分布式电子病历数据的安全与隐私的协同表型提取,并且可用于拜占庭攻击与隐私攻击的对抗环境下,有效保证了计算的安全与隐私,具有高通信效率及高可用性。
在本发明的描述中,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征。在本发明的描述中,“多个”的含义是两个或两个以上,除非另有明确具体的限定。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。此外,本领域的技术人员可以将本说明书中描述的不同实施例或示例进行接合和组合。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。