基于神经网络的蛋白设计方法及系统
文献发布时间:2024-04-18 20:01:55
技术领域
本发明涉及蛋白质数据处理技术领域,具体涉及基于神经网络的蛋白设计方法及系统。
背景技术
蛋白质是一种重要的生物大分子,蛋白质承担并执行着身体的各项功能。传统的蛋白质设计工程一般是基于已有的蛋白进行修改,以期望能够达到人们需求的新特性。但是,并非所有蛋白质模板都能够找到,有些蛋白质模板甚至在自然进化中尚未出现,此时蛋白设计技术凸显的尤为重要。蛋白设计的过程需要遵循设计要求,设计过程中包括两个重要的环节,一是确定蛋白支链骨架,二是固定主链的氨基酸序列。
随着神经网络等机器学习方法发展,多数采用深度学习的方法学习蛋白质结构,为蛋白设计的发展提供新的方向。蛋白质的进化一般会产生特定功能的氨基酸序列,而针对氨基酸序列的设计问题在于如何在约束蛋白质可折叠的基础上同时保留其功能,传统的理性设计蛋白质分子需要进行庞大的计算,现有的计算能力几乎无法完成,因此结合机器学习的蛋白设计成为了主流。
发明内容
本发明提供基于神经网络的蛋白设计方法及系统,以解决如何在约束蛋白质可折叠的基础上同时保留其功能的问题,所采用的技术方案具体如下:
第一方面,本发明一个实施例基于神经网络的蛋白设计方法,该方法包括以下步骤:
获取蛋白质分子的图数据及氨基酸序列;
根据每个蛋白质分子的图数据及氨基酸序列获取每个蛋白质分子的氨基酸序列中每个氨基酸的近邻氨基酸集合;根据每个蛋白质分子的氨基酸序列中每个氨基酸的近邻氨基酸集合获取每个蛋白质分子的氨基酸序列中每个氨基酸的相互作用强度;利用聚类算法获取每个蛋白质分子的氨基酸序列中所有氨基酸的相互作用强度的聚类结果,根据所述聚类结果获取每个蛋白质分子的热稳定性递增序列;
根据每个蛋白质分子的热稳定性递增序列获取每个蛋白质分子对应的所有聚类簇中每个聚类簇的热稳定连续指数;根据每个蛋白质分子对应的所有聚类簇的热稳定连续指数获取每个蛋白质分子的超高热稳定性聚类簇;根据所有蛋白质分子的超高热稳定性聚类簇获取氨基酸合成序列,根据氨基酸合成序列获取目标氨基酸序列;
根据目标氨基酸序列获取模拟氨基酸序列,根据模拟氨基酸序列获取模拟生成的蛋白质分子。
优选的,所述根据每个蛋白质分子的图数据及氨基酸序列获取每个蛋白质分子的氨基酸序列中每个氨基酸的近邻氨基酸集合的方法为:
对于每个蛋白质分子的氨基酸序列,将氨基酸序列中每个氨基酸作为每个中心氨基酸,获取每个中心氨基酸在蛋白质分子的图数据中的目标节点位置,将距所述目标节点位置的空间距离最近的第一预设参数个节点所代表的氨基酸组成的集合作为每个中心氨基酸的近邻氨基酸集合。
优选的,所述根据每个蛋白质分子的氨基酸序列中每个氨基酸的近邻氨基酸集合获取每个蛋白质分子的氨基酸序列中每个氨基酸的相互作用强度的方法为:
对于每个蛋白质分子的氨基酸序列,根据氨基酸序列中每个氨基酸的近邻氨基酸集合获取每个氨基酸的结构稳定度;
对于每个蛋白质分子的氨基酸序列中每个氨基酸,将以自然常数为底数,以氨基酸的结构稳定度为指数的负映射结果与第二预设参数的乘积作为第一求和因子,将所述第一求和因子与第三预设参数的和作为氨基酸的相互作用强度。
优选的,所述根据氨基酸序列中每个氨基酸的近邻氨基酸集合获取每个氨基酸的结构稳定度的方法为:
式中,
优选的,所述利用聚类算法获取每个蛋白质分子的氨基酸序列中所有氨基酸的相互作用强度的聚类结果,根据所述聚类结果获取每个蛋白质分子的热稳定性递增序列的方法为:
对于每个蛋白质分子的氨基酸序列,将氨基酸序列中所有的氨基酸的相互作用强度组成的集合作为样本数据集,利用k-means聚类算法获取所述样本数据集的聚类结果;
对于每个蛋白质分子对应的聚类结果中所有聚类簇,计算每个聚类簇内所有氨基酸的相互作用强度均值,将所有聚类簇对应的相互作用强度均值按照数值升序的顺序组成的序列作为蛋白质分子的热稳定性递增序列。
优选的,所述根据每个蛋白质分子的热稳定性递增序列获取每个蛋白质分子对应的所有聚类簇中每个聚类簇的热稳定连续指数的方法为:
式中,
优选的,所述根据每个蛋白质分子对应的所有聚类簇的热稳定连续指数获取每个蛋白质分子的超高热稳定性聚类簇的具体方法为:
对于每个蛋白质分子的对应的聚类结果中所有聚类簇的热稳定连续指数,将所述所有聚类簇的热稳定连续指数中最小值对应的聚类簇作为目标聚类簇,将相互作用强度均值高于目标聚类簇的相互作用强度均值的聚类簇作为蛋白质分子的超高热稳定性聚类簇。
优选的,所述根据所有蛋白质分子的超高热稳定性聚类簇获取氨基酸合成序列,根据氨基酸合成序列获取目标氨基酸序列的方法为:
将每个蛋白质分子对应的所有超高热稳定性聚类簇中所有元素对应的氨基酸作为待处理氨基酸,获取每个待处理氨基酸的近邻氨基酸集合,将每个待处理氨基酸与其近邻氨基酸集合中的氨基酸按照原有的氨基酸顺序组成的序列作为一个局部氨基酸序列,将所有蛋白质分子对应的所有局部氨基酸序列组成的序列作为氨基酸合成序列;
将氨基酸合成序列以及氨基酸序列数据库中的氨基酸序列作为KMP匹配算法的输入,将KMP匹配算法的输入作为目标氨基酸序列。
优选的,所述根据目标氨基酸序列获取模拟氨基酸序列,根据模拟氨基酸序列获取模拟生成的蛋白质分子的方法:
将目标氨基酸序列作为GAN生成对抗网络的输入,将GAN生成对抗网络的输出作为模拟氨基酸序列;
从现有的蛋白质主链结构数据库中获取具备热稳定性的目标蛋白质主链结构,根据模拟氨基酸序列以及目标蛋白质主链结构利用计算机模拟平台得到模拟生成的蛋白质分子。
第二方面,本发明实施例还提供了基于神经网络的蛋白设计系统,包括存储器、处理器以及存储在所述存储器中并在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述任意一项所述方法的步骤。
本发明的有益效果是:本发明根据每个蛋白质分子的图数据以及对应的氨基酸序列获取每个氨基酸的相互作用强度,利用聚类算法获取由相互作用强度组成样本数据集的聚类结果,通过构建热稳定连续指数筛选超高热稳定性聚类簇,根据超高热稳定性聚类簇获取具备一定氨基酸顺序的局部氨基酸序列,得到超高热稳定性的氨基酸合成序列以及目标氨基酸序列,利用生成对抗网络获取模拟氨基酸序列,从而利用模拟氨基酸序列设计蛋白质分子。其有益效果在于,以氨基酸分子的相互作用强度为基础,进行固定主链的氨基酸序列设计,利用热稳定性较高的局部氨基酸序列得到氨基酸合成序列,进而进行蛋白设计,在保留蛋白质的热稳定功能的基础上设计氨基酸序列,进而使得设计蛋白质更符合预期效果。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
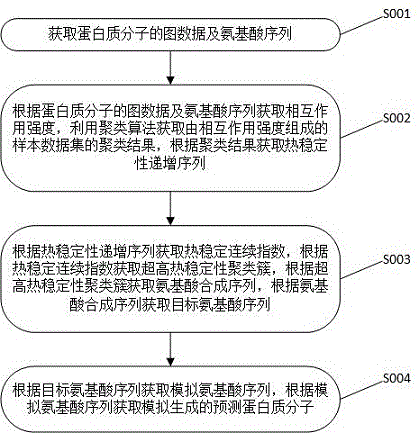
图1为本发明一个实施例所提供的基于神经网络的蛋白设计方法的流程示意图;
图2为本发明一个实施例所提供的基于神经网络的蛋白设计方法的具体实施流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1,其示出了本发明一个实施例提供的基于神经网络的蛋白设计方法流程图,该方法包括以下步骤:
步骤S001,获取蛋白质分子的图数据及氨基酸序列。
首先,从现有蛋白质数据库筛选具备热稳定性较强的蛋白质,然后随机抽取20个具备较强热稳定性的蛋白质分子,获取每个蛋白质分子的氨基酸序列,同时利用图数据转化获取每个蛋白质分子的图数据,图数据转化为公知技术,不做多余赘述。所述每个蛋白质分子的图数据是由氨基酸代表的节点以及氨基酸之间的化学键代表的边构成,蛋白质分子的图数据一定程度上能够反映氨基酸之间的顺序信息,实施人员可以根据设计需求选择合适的蛋白质分子数目。
至此,得到每个蛋白质分子的图数据以及氨基酸序列。
步骤S002,根据蛋白质分子的图数据及氨基酸序列获取相互作用强度,利用聚类算法获取由相互作用强度组成的样本数据集的聚类结果,根据聚类结果获取热稳定性递增序列。
现有的蛋白设计分为两类,一种是基于模板的设计,另一种是不基于模板的设计。本发明采用基于模板的设计方式,旨在设计出一种具有超高热稳定性蛋白质。本发明的具体实施流程图如图2所示。
目前,在现有的利用MD分子动力学模拟研究蛋白质热稳定性的研究中,最后归因于蛋白质分子内部氨基酸之间形成盐桥以及氨基酸氢键的增加,而氨基酸之间的盐桥相互作用作为蛋白质热稳定性的主要原因。一般情况下,氨基酸之间盐桥相互作用的形成是由于酸性氨基酸残基侧链电离后所带的正电荷与碱性氨基酸残基侧链电离后所带的负电荷之间形成的离子键。
对于每个蛋白质分子的图数据,由于蛋白质分子的图数据一定程度上能够体现氨基酸之间的盐桥相互作用,因为氨基酸分子所含碱性氨基和酸性羧基经过“脱水缩合”与其他氨基酸分子相连,从而形成离子键,所以与氨基酸分子相连的氨基酸数目越多,氨基酸之间的盐桥相互作用能力越强。
具体地,对于每个蛋白质分子的氨基酸序列,以每个氨基酸为每个中心氨基酸,获取每个中心氨基酸在对应蛋白质分子的图数据的目标节点位置,将距目标节点位置的空间距离最近的K个节点所代表的氨基酸组成的集合作为每个中心氨基酸的近邻氨基酸集合,K的经验取值为10。
计算每个蛋白质分子的氨基酸序列中每个氨基酸的相互作用强度:
式中,
第x个蛋白质分子的氨基酸序列中第y个氨基酸的近邻氨基酸集合第i个氨基酸所代表节点的连接边的数目
氨基酸的相互作用强度一定程度上反映热稳定性的高低,氨基酸的相互作用强度越大,即局部氨基酸之间形成的氨基酸序列的热稳定性越高;氨基酸的相互作用强度越小,即局部氨基酸之间形成的氨基酸序列的热稳定性越低。因此,为了设计出具备超高热稳定性蛋白质,根据氨基酸的相互作用强度进行进一步的分析。
进一步地,对于每个蛋白质分子的氨基酸序列,将氨基酸序列中所有氨基酸的相互作用强度组成的数据集合作为样本数据集,利用k-means聚类算法,将样本数据集作为k-means聚类算法的输入,预设分类参数k取经验值为20,度量距离采用欧氏距离,将k-means聚类算法的输出作为样本数据集的聚类结果。
基于上述的分析,对于每个蛋白质分子,得到蛋白质分子的氨基酸序列对应的20个聚类簇。由于氨基酸的相互作用强度表征了局部氨基酸序列的热稳定性,不同的聚类簇一定程度上反映了不同的热稳定性水平。为了得到氨基酸序列中热稳定性较强的局部氨基酸序列,在此根据所得聚类簇进行分析。
具体地,对于每个蛋白质分子的氨基酸序列对应的20个聚类簇,计算每个聚类簇中所有氨基酸的相互作用强度均值,将20个聚类簇的相互作用强度均值按照数值升序的顺序组成的序列作为热稳定性递增序列。
至此,得到每个蛋白质分子的热稳定性递增序列。
步骤S003,根据热稳定性递增序列获取热稳定连续指数,根据热稳定连续指数获取超高热稳定性聚类簇,根据超高热稳定性聚类簇获取氨基酸合成序列,根据氨基酸合成序列获取目标氨基酸序列。
进一步地,计算每个蛋白质分子对应的样本数据集的聚类结果中每个聚类簇的热稳定连续指数:
式中,
第x个蛋白质分子对应的热稳定性递增序列中第q个、第(q+1)个元素值之间的差异
进一步地,对于第x个蛋白质分子对应的样本数据集的聚类结果中所有的聚类簇的热稳定连续指数,获取热稳定连续指数的最小值,并获取热稳定连续指数的最小值所对应的聚类簇。热稳定连续指数的最小值所对应的聚类簇一定程度上反映了热稳定性平均水平较差,且连续性较差,能够作为热稳定性的衡量标准。
具体地,对于热稳定连续指数的最小值所对应的聚类簇,将所述聚类簇对应的相互作用强度均值在第x个蛋白质分子的热稳定性递增序列中的位置作为目标位置,将热稳定性递增序列中目标位置之后的每个元素所对应的聚类簇作为每个超高热稳定性聚类簇,即将相互作用强度均值高于热稳定连续指数的最小值所对应的聚类簇的相互作用强度均值的所有聚类簇作为蛋白质分子的超高热稳定性聚类簇。
进一步地,将每个蛋白质分子对应的所有超高热稳定性聚类簇中所有元素对应的氨基酸作为待处理氨基酸,获取每个待处理氨基酸的近邻氨基酸集合,将每个待处理氨基酸与其近邻氨基酸集合中的氨基酸按照原有的氨基酸顺序组成的序列作为每个局部氨基酸序列,所述原有的氨基酸顺序是指每个待处理氨基酸与其近邻氨基酸集合中的所有的氨基酸在蛋白质分子的原始氨基酸序列中顺序,将所有蛋白质分子对应的所有局部氨基酸序列组成的序列作为超高热稳定性的氨基酸合成序列。
根据超高热稳定性的氨基酸合成序列,并且获取现有的氨基酸序列数据库,利用KMP匹配算法,将氨基酸合成序列与氨基酸序列数据库中的氨基酸序列作为KMP匹配算法的输入,将KMP匹配算法的输出作为氨基酸序列数据库中与氨基酸合成序列匹配度最高的氨基酸序列,记为目标氨基酸序列,KMP匹配算法为公知技术,不做多余赘述。
步骤S004,根据目标氨基酸序列获取模拟氨基酸序列,根据模拟氨基酸序列获取模拟生成的预测蛋白质分子。
将目标氨基酸序列作为生成对抗网络GAN的输入,生成对抗网络的损失函数包括鉴别器D的损失函数以及生成器G的损失函数,其中,鉴别器的作用在于鉴别输入到鉴别器内的样本是真实样本还是生成器生成的样本,因此将鉴别器的损失函数设置为二元交叉熵函数;而生成器的作用是为了使得生成样本接近真实样本,因此生成器的损失函数采用均方差损失函数。
将上述鉴别器的损失函数与生成器的损失函数之和作为生成对抗网络的损失函数,其次以Adam算法为优化算法,将生成对抗网络的输出作为模拟氨基酸序列,其中GAN网络为监督学习,因此生成对抗网络的输出,即生成器输出的模拟氨基酸序列需要人为标注,具体的可通过专家根据目标氨基酸序列,人为设定相应的模拟氨基酸序列。
由于氨基酸合成序列具备超高热稳定性,目标氨基酸序列与氨基酸合成序列具有较高的匹配度,则目标氨基酸序列有同样的性质,即超高热稳定性。GAN生成对抗网络输出的模拟氨基酸序列与目标氨基酸较为相似,则模拟氨基酸序列具备较强的热稳定性。
从现有的蛋白质主链结构数据库中获取具备热稳定性的目标蛋白质主链结构,根据模拟氨基酸序列以及目标蛋白质主链结构,通过搭建计算机模拟平台,利用MD分子动力学模拟技术对模拟氨基酸序列与目标蛋白质主链结构进行蛋白质分子模拟,生成蛋白质分子,MD分子动力学模拟技术为公知技术,不做多余赘述。
基于与上述方法相同的发明构思,本发明实施例还提供了基于神经网络的蛋白设计系统,得到模拟氨基酸序列以及目标蛋白质主链结构后,将模拟氨基酸序列以及目标蛋白质主链结构传输至蛋白质分子生成模块,通过搭建计算机模拟平台,利用MD分子动力学模拟技术对模拟氨基酸序列与目标蛋白质主链结构进行蛋白质分子模拟,生成蛋白质分子。
本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。