乳腺癌早期筛查模型的构建方法及筛查辅助系统
文献发布时间:2024-07-23 01:35:12
技术领域
本发明涉及乳腺癌早期筛查模型的构建方法及筛查辅助系统,属于医学图像处理和小样本学习领域。
背景技术
乳腺癌是世界上最常见的一种恶性肿瘤,是世界上女性发病率最高的癌症之一。由于我国的人口基数庞大,中国女性乳腺癌患者人数逐年增加,且患者的年龄也越来越年轻化。因此,如何提升乳腺癌早期筛查能力对我国防控和治疗乳腺癌变得越来越重要。
近年来,随着医学影像技术的迅速发展,对乳腺癌的早期筛查有了更灵活且精准的方式。现阶段,常用的乳腺影像技术有乳腺超声和乳腺动态对比增强磁共振成像等。出于对我国以及发展中国家的医疗水平和成本的考虑,乳腺超声检查是最符合我国及发展中国家国情的一种有效乳腺癌早期筛查方式,因为乳腺超声影像诊断相比于其他乳腺影像技术具有成本低、无创和无辐射等优势。但当前乳腺超声诊断对临床医生的要求极高,需要临床医生具备非常丰富的诊断经验和技术。此外,临床医生需要判读大量的乳腺超声影像,这很容易导致临床医生出现疲劳而产生误诊。最近,深度神经网络在乳腺超声图像诊断方面取得了巨大的成功。然后由于深度神经网络中的黑箱问题,无法通过一些有效的公式来展示网络的训练过程,而且仅通过准确度等方式展示出来的结果并不会被实际所应用,这些网络还是缺乏足够的可解释性。此外,深度神经网络算法需要大量数据来训练,以使得网络学习到充足的经验。众所周知,由于涉及病人的私密,带标签的医学图像数据是不容易采集的,而当训练数据不足时,深度神经网络算法没办法学习到足够的经验,往往会导致过拟合。因此,利用少量的乳腺超声数据构建迅速、精准的乳腺癌早期筛查辅助系统是一个具有挑战性的问题。
发明内容
为了解决上述问题,本发明提供一种了乳腺癌早期筛查模型的构建方法及筛查辅助系统,所述技术方案如下:
本发明的第一个目的在于提供一种乳腺癌早期筛查模型的构建方法,所述方法包括:
步骤1:获取乳腺超声图像和乳腺超声放射学报告;
步骤2:对所述乳腺超声图像和乳腺超声放射学报告进行预处理;
步骤3:基于预处理后的超声图像和放射学报告,构建成对的超声图像和放射学报告数据集,并划分为支持集和查询集;
步骤4:构建两个编码器,分别从成对的超声图像和放射学报告中提取形态学特征和可解释性特征,通过语义驱动的可解释性单元来实现所述形态学特征和可解释性特征的跨模态组合,得到融合特征;
步骤5:构造多任务协作策略,基于所述融合特征训练神经网络模型,得到训练好的乳腺癌早期筛查模型,所述乳腺癌早期筛查模型基于输入的融合特征,输出乳腺癌分类结果。
可选的,所述步骤4包括:
步骤41:构建乳腺超声图像编码器和乳腺超声放射学报告编码器;
步骤42:利用所述乳腺超声图像编码器对乳腺超声图像x进行编码,提取形态学特征
步骤43:利用所述乳腺超声放射学报告编码器对乳腺超声放射学报告r进行编码,提取语义特征
步骤44:生成新的形态学特征:
其中
步骤45:生成可解释性特征:
σ为sigmoid函数,
步骤46:通过语义驱动的可解释性单元来实现两个特征的跨模态组合,公式如下:
其中,
可选的,所述步骤5包括:
步骤51:构建训练集D
步骤52:训练任务Task
对训练任务Task
其中,
步骤53:给出每批任务的总大小为J,根据所有查询集任务
其中,β为外环协助训练的学习率,
步骤54:使用任务损失,临床报告驱动的可解释性模型接受单个输入,生成单个输出,任务损失用输出S和目标Q之间的误差表示,其公式为:
其中,
可选的,所述步骤2中预处理过程包括:
步骤21:将所有乳腺超声图像重新缩放到统一的像素值大小以获得统一的输入图像维数;
步骤22:将所有超声图像像素值进行归一化以获得标准的正态分布;
步骤23:去除非英语句子和错误的句子后,构建标准的放射学报告;
步骤24:使用Tokenizer技术来获取所述放射学报告中单词的特征表示。
可选的,所述步骤3包括:
步骤31:构造N-way C-shot乳腺癌早筛任务;
步骤32:给定一个训练集,将这个训练集分为支持和查询集,
所述支持集由N个乳腺癌类型组成,每种乳腺癌类型包含C个成对的乳腺超声图像和乳腺超声放射学报告;
所述查询集由N个乳腺癌类型组成,但从每种乳腺癌类型中随机选取M个成对的乳腺超声图像和乳腺超声放射学报告;
所述N-way C-shot乳腺癌早筛任务的目的是根据支持集中N类乳腺癌和其N×C个样本对查询集样本进行预测。
本发明的第二个目的在于提供一种乳腺癌早期筛查辅助系统,所述系统包括:
图像获取模块,用于获取待筛查的乳腺超声图像;
临床报告获取模块,用于获取与所述待筛查的乳腺超声图像对应的乳腺超声放射学报告;
数据预处理模块,用于对所述乳腺超声图像和乳腺超声放射学报告进行预处理;
特征提取模块,包括乳腺超声图像编码器和乳腺超声放射学报告编码器,分别用于提取形态学特征和可解释性特征,并通过语义驱动的可解释性单元来实现所述形态学特征和可解释性特征的跨模态组合,得到融合特征;
分类模块,所述分类模块为上述任一项所述方法构建的乳腺癌早期筛查模型,所述模型根据输入的所述融合特征,输出乳腺癌分类结果。
可选的,所述乳腺超声图像编码器采用多特征融合胶囊网络模型。
可选的,所述乳腺超声放射学报告编码器采用长短期记忆网络。
本发明的第三个目的在于提供一种乳腺癌早期筛查辅助装置,包括存储器和处理器;
所述存储器,用于存储计算机程序;
所述处理器,用于当执行所述计算机程序时,实现利用如上述任一项所述的乳腺癌早期筛查辅助系统得出乳腺癌分类结果。
本发明的第四个目的在于提供一种计算机可读存储介质,所述存储介质上存储有计算机程序,当所述计算机程序被处理器执行时,实现利用如上述任一项所述的乳腺癌早期筛查辅助系统得出乳腺癌分类结果。
本发明有益效果是:
(1)本发明的乳腺癌早期筛查辅助系统,将临床报告驱动的可解释性机制与多任务协作诊断策略相结合,可以实现迅速且精确的乳腺癌早期筛查,这是一种跨模态相互学习的方法,可以使用乳腺超声临床放射学报告中的临床信息来解释和强化乳腺超声图像的信息,进而提高模型的可靠性和透明度,使得模型产生的结果更容易被临床医生理解和接受。
(2)本发明模拟临床医生诊断患者的过程,发明了一种临床报告驱动的可解释性机制,该机制与临床医生诊断患者的流程相似,通过提取乳腺超声临床放射学报告中临床信息来解释乳腺超声图像的信息。
(3)本发明模仿人类学习过程互帮互助的灵感,发明了一种新的小样本学习策略,即多任务协作策略,该策略通过使模型相互协作训练,从而使模型学会去学习,进而提高模型的泛化能力。
(4)本发明使用少量成对的乳腺超声图像和乳腺超声临床放射学报告,通过结合临床报告驱动的可解释性机制与多任务协作诊断策略,不仅避免了过度拟合,实现了有竞争力的诊断结果,而且提高了诊断结果的可靠性和透明度。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
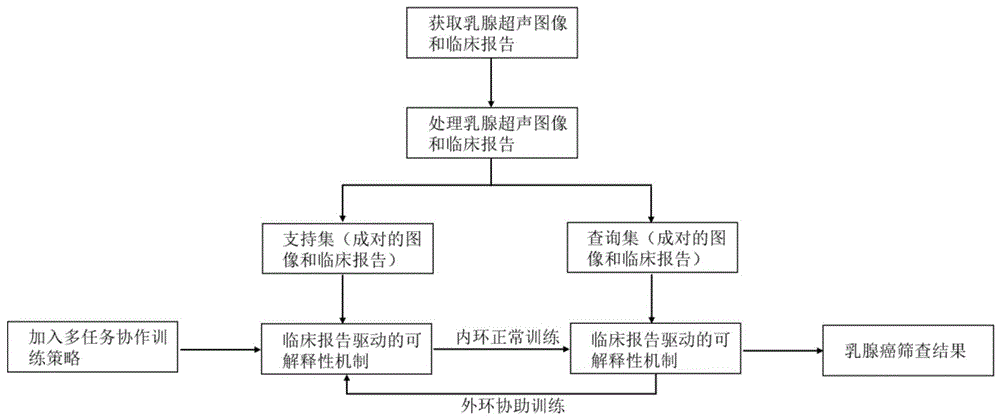
图1是本发明的乳腺癌早期筛查模型的构建方法流程图。
图2是本发明实施例二的特征提取部分的网络结构图。
图3是本发明实施例二中划分支持集和查询集示意图。
图4是本发明实施例二的临床报告驱动的可解释性机制结构(特征融合过程)图。
图5是本发明实施例二的乳腺超声编码器结构图。
图6是本发明实施例二的乳腺超声放射性报告编码器结构图。
图7是本发明实施例二的LSTM网络结构图。
图8是本发明实施例二的多任务协作训练网络结构图。
图9是本发明实施例二的乳腺癌分类结果图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方式作进一步地详细描述。
实施例一:
本实施例提供一种乳腺癌早期筛查模型的构建方法,如图1所示,方法包括:
步骤1:获取乳腺超声图像和乳腺超声放射学报告;
步骤2:对乳腺超声图像和乳腺超声放射学报告进行预处理;
步骤3:基于预处理后的超声图像和放射学报告,构建成对的超声图像和放射学报告数据集,并划分为支持集和查询集;
步骤4:构建两个编码器,分别从成对的超声图像和放射学报告中提取形态学特征和可解释性特征,通过语义驱动的可解释性单元来实现形态学特征和可解释性特征的跨模态组合,得到融合特征;
步骤5:构造多任务协作策略,基于融合特征训练神经网络模型,得到训练好的乳腺癌早期筛查模型。
实施例二:
本实施例提供一种临床报告驱动的可解释性小样本学习乳腺癌早期筛查模型的构建方法,参见图1,所述方法包括:
(1)获取乳腺超声图像和超声临床报告。
(2)对获取的图像和报告进行处理。
(3)构造成对的图像和报告数据集,并将其划分为支持集和查询集。
(4)设计临床报告驱动的可解释性机制,该机制同时从成对的乳腺超声图像和乳腺超声放射学报告中学习形态学(图像)、临床(放射学报告)信息,然后将从放射学报告中获得的临床信息作为图像的可解释信息,从而促进黑箱人工智能模型的可靠性、透明度和可解释性。
(5)构造多任务协作策略,该策略通过使人工智能模型相互协作训练,从而使模型学会去学习,进而提高模型的泛化能力。
(6)通过结合临床报告驱动的可解释性机制和多任务协作策略使得该小样本学习方法可以在少量成对超声图像和乳腺超声放射学报告有效、精准地实现乳腺癌的早期筛查。
进一步地,步骤(1)获取乳腺超声图像和超声临床报告,具体包括以下步骤:
(11)采用美国GE医疗全自动乳腺超声检查仪,对995名患者进行了1128次检查,产生的3D超声数据的大小为900×1280×720,切片厚度为0.3mm,患者的一次检查包含多个扫描方向,包括左乳房的五个扫描方向:LAP、LLAT、LMED、LUOQ、LSUP,右乳房的五个扫描方向:RAP、RLAT、RMED、RUOQ、RSUP。
(12)通过检查,获取每一个患者pdf格式的检查报告,报告中描述了患者的基本信息、扫描方向、以及是否有肿瘤,如果有肿瘤的话,标记了肿瘤的大概位置,并且描述了肿瘤的位置、大小和分级(良恶性)。
进一步地,步骤(2)对获取的图像和报告进行处理,具体包括以下步骤:
(21)根据医生的标注,将所有乳腺超声图像进行裁剪,分辨率重新缩放到256×256×256像素值大小以获得统一的输入图像维数。
(22)将所有超声图像像素值从[0,255]切换到[0,1]以获得标准的正态分布。
(23)去除非英语句子和错误的句子后,构建标准的放射学报告。
(24)使用Tokenizer技术来获取放射学报告中单词的特征表示,Tokenizer技术首先删除英文标点符号,并将大写字母转换为小写字母;接着,对放射学报告中执行词频计数,并根据词频对单词进行排序;再接着,将每个单词转换为基于词频的数字序列;最后使用零填充方法用来获得需要的数字序列长度。
进一步地,步骤(3)构造成对的图像和报告数据集,并将其划分为支持集和查询集;如图3所示,具体包括以下步骤:
(31)构造N-way C-shot乳腺癌早筛任务,一共包括2-way 1-shot,2-way 2-shot,2-way 3-shot,2-way 4-shot,2-way 5-shot,2-way 6-shot早筛任务。
(32)给定一个训练集,将这个训练集分为支持集(support set)和查询集(queryset),
(33)支持集由两个乳腺癌类型组成,但每种乳腺癌类型只包含C={1,2,3,4,5,6}个成对的乳腺超声图像和乳腺超声放射学报告。
(34)查询集由也由两个乳腺癌类型组成,但从每种乳腺癌类型中随机选取M=5个成对的乳腺超声图像和乳腺超声放射学报告。
(35)N-way C-shot任务的目的是根据支持集中两类乳腺癌和其2×{1,2,3,4,5,6}个样本对查询集样本进行预测。
进一步地,步骤(4)设计临床报告驱动的可解释性机制,该机制同时从成对的乳腺超声图像和乳腺超声放射学报告中学习形态学(图像)、临床(放射学报告)信息,然后将从放射学报告中获得的临床信息作为图像的可解释信息,从而促进黑箱人工智能模型的可靠性、透明度和可解释性,如图4所示,具体包括以下步骤:
(41)构造两个编码器,乳腺超声图像编码器(Breast Ultrasound ImageEncoder,BUIE)和乳腺超声放射学报告编码器(Breast Ultrasound Radiology PeportEncoder,BURPE),编码器可利用神经网络构造,实现特征提取的功能。
(42)乳腺超声图像编码器采用多特征融合胶囊网络模型,如图5所示,模型第一步对胶囊的输入向量u
(43)乳腺超声放射学报告编码器采用长短期记忆网络(Long Short-TermMemory,LSTM),如图6所示,网络使用三个门,输入门(input gate)、遗忘门(forget gate)、和输出门(output gate),以此来控制信息的去留,每个门的公式为:
i
f
o
其中W
g
c
h
其中⊙为矩阵点乘,c
(44)使用BUIE对乳腺超声图像x进行编码,提取形态学(图片)特征
(45)利用BURPE对乳腺超声放射学报告r进行编码,输出临床(可解释性)特征
(46)生成新的形态学特征利用如下公式:
为全连接层的权重,b
(47)生成可解释性特征利用如下公式:
σ为sigmoid函数,
(48)当得到了形态学特征和语义特征后,通过语义驱动的可解释性单元来实现这两个特征的跨模态组合,公式如下:
其中,f
临床报告驱动的可解释性机制是现实生活中临床医生的诊断患者过程,乳腺超声图像的编码过程可以看作是临床医生解读图像的过程,乳腺超声放射学报告的编码过程可以看作是临床医生解读患者病理报告的过程。
进一步地,步骤(5)构造多任务协作策略,该策略通过使人工智能模型相互协作训练,从而使模型学会去学习,进而提高模型的泛化能力,如图8所示,具体包括以下步骤:
(51)给出数据集D由乳腺超声图像和相关乳腺放射学报告组成。
(52)将数据集D分成两部分:训练集(D
(53)从D
(54)在训练任务Task
其中,
(55)给出每批任务的总大小为J,接下来根据所有查询集任务
β为外环协助训练的学习率,
(56)使用任务损失,临床报告驱动的可解释性模型接受单个输入,生成单个输出,任务损失用输出S和目标Q之间的误差表示,其公式为:
是任务损失,S
(57)多任务协作诊断策略在内环中,使用支持集任务用于正常训练临床报告驱动的可解释性模型,然后通过外环中的查询集任务优化模型。具体来讲,多协作训练利用从内环中训练支持集任务获得的经验来指导外环中查询集任务的分类;随后,进一步利用外环中训练查询集任务获得经验来优化内环中训练支持集任务获得的经验。通过这种不断循环优化训练的方式,使得不同的支持集任务和查询集任务相互协作训练和学习。因此,在经过一系列训练后,提出的临床报告驱动的可解释性模型可以学会协作学习,学会快速学习,学会自己学习,即临床报告驱动的可解释性模型自己学习如何从少量数据中快速学习。
模型训练好之后,可以用于乳腺癌的早期筛查,筛查过程为:
医生通过超声检查获取到患者的乳腺超声图像和乳腺超声放射学报告,而后将乳腺超声图像和乳腺超声放射学报告输入乳腺癌早筛系统中,乳腺癌早筛系统使用乳腺超声图像编码器BUIE和乳腺超声放射学报告编码器BURPE,分别提取乳腺超声图像的形态学特征和乳腺超声放射学报告的可解释性特征,进一步得到融合特征,将融合特征输入训练好的分类神经网络F
实施例三:
本实施例提供一种乳腺癌早期筛查辅助系统,包括:
图像获取模块,用于获取待筛查的乳腺超声图像;
临床报告获取模块,用于获取与待筛查的乳腺超声图像对应的乳腺超声放射学报告;
数据预处理模块,用于对乳腺超声图像和乳腺超声放射学报告进行预处理;
特征提取模块,包括乳腺超声图像编码器和乳腺超声放射学报告编码器,分别用于提取形态学特征和可解释性特征,并通过语义驱动的可解释性单元来实现形态学特征和可解释性特征的跨模态组合,得到融合特征;
分类模块,分类模块为实施例一或实施例二方法构建的乳腺癌早期筛查模型,乳腺癌早期筛查模型为训练好的神经网络,可以根据输入的融合特征,输出乳腺癌分类结果。
本发明实施例中的部分步骤,可以利用软件实现,相应的软件程序可以存储在可读取的存储介质中,如光盘或硬盘等。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种基于尿液进行前列腺癌早期筛查模型的构建方法、筛查模型及试剂盒
- 一种基于尿液进行前列腺癌早期筛查模型的构建方法、筛查模型及试剂盒