一种数据中心资源分配方法及装置
文献发布时间:2023-06-19 09:55:50
技术领域
本发明涉及数据中心技术领域,尤其涉及一种数据中心资源分配方法及装置。
背景技术
云计算是一种基于互联网的新型信息资源服务系统,可以为用户提供包括基础设施、平台和应用在内的可定制弹性虚拟化资源服务。在技术进步、需求引领和服务模式创新等因素的共同驱动下,云计算得到了普遍认可,已经在现实生活中形成涵盖移动互联网、物联网等在内的新型创意产业,并以其低成本和无处不在的应用得到迅速发展,将从根本上改变人们生活的方方面面。
为了满足这些多元化、海量的应用资源需求,云计算必须拥有庞大的资源集群,这些资源在地理上是分布的,类型上是异构的,并且在各自的管理域中又具有不同的资源管理策略和资源使用计价准则。资源管理是云计算的核心问题之一,其目的是利用虚拟化技术屏蔽底层资源的异构性和复杂性,使得海量分布式资源形成一个统一的巨型资源池,并在此基础上,合理运用相关资源管理方法和技术,确保资源的合理、高效的分配和使用。因此,如何实现对云计算资源的有效管理是一个亟待解决的关键问题。
发明内容
本发明所要解决的技术问题在于,提出一种数据中心资源分配方法及装置,以为资源的优化合理配置提供切实有效的保障,保证云计算平台稳定运行和资源的合理使用。
为了解决上述技术问题,本发明提供一种数据中心资源分配方法,其包括:
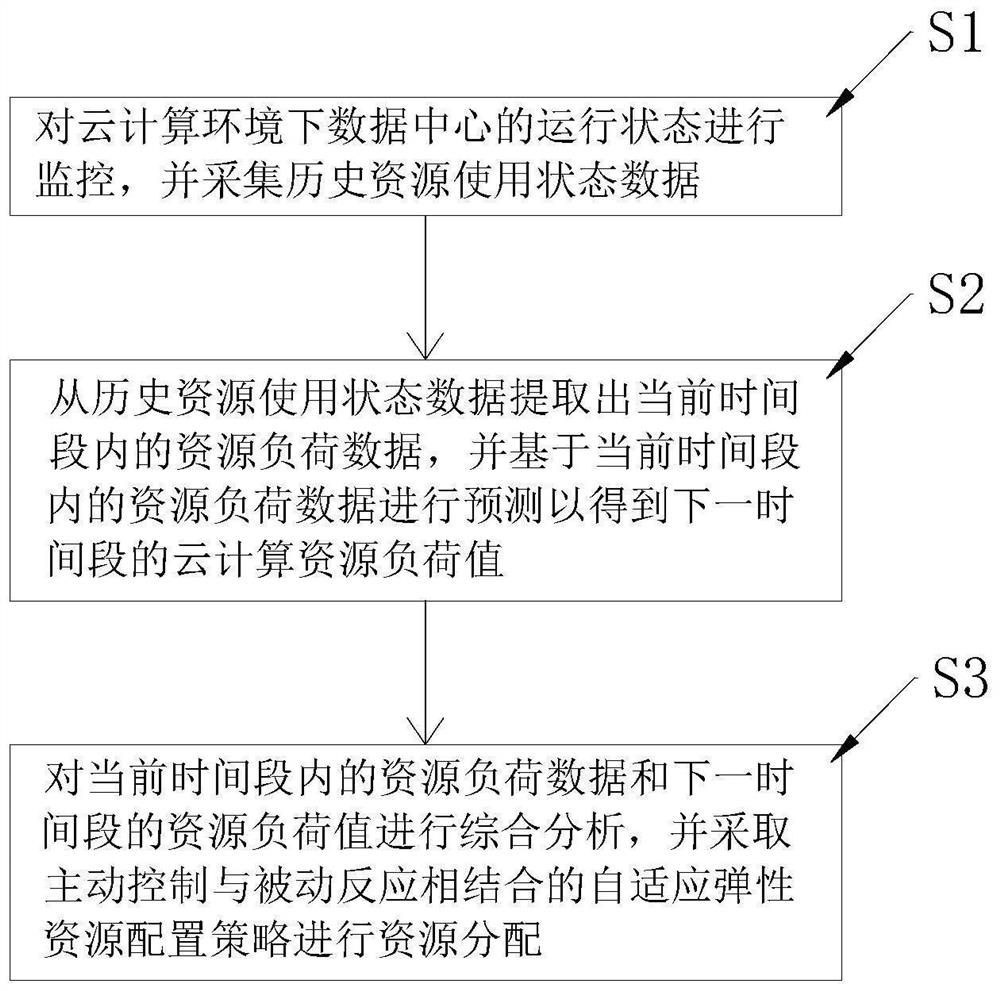
步骤S1,对云计算环境下数据中心的运行状态进行监控,并采集历史资源使用状态数据;
步骤S2,从历史资源使用状态数据提取出当前时间段内的资源负荷数据,并基于当前时间段内的资源负荷数据进行预测以得到下一时间段的云计算资源负荷值;
步骤S3,对当前时间段内的资源负荷数据和下一时间段的资源负荷值进行综合分析,并采取主动控制与被动反应相结合的自适应弹性资源配置策略进行资源分配。
进一步地,所述步骤S2具体包括:
步骤S21,利用固定尺寸重叠滑动窗口技术从历史数据集中提取当前时间段的云计算资源负荷子序列集;
步骤S22,使用KFCM聚类算法将云计算资源负荷子序列集分成若干类并放置于不同的聚类簇中;
步骤S23,给每一个聚类簇分配一个预测器,将每一个聚类簇中的云计算资源负荷子序列集输入到预测器中对其进行训练和预测;
步骤S24,挑选出具有最小预测误差的聚类簇及其所对应的预测器进行预测,获得下一时间段所需的云计算资源负荷预测值。
进一步地,所述步骤S22进一步包括:
步骤S221,设置目标函数精度ε,模糊指数p,最大迭代次数Maxiter,以及最大聚类数MaxC;
步骤S222,对云计算资源负荷子序列集X作归一化处理,选择核函数,设定相关参数,计算核矩阵K;
步骤S223,随机初始化隶属度矩阵U;
步骤S224,令t=1:Maxiter,计算目标函数J
步骤S225:输出最优隶属度矩阵U以及聚类中心v
进一步地,所述步骤S21具体为:
对于给定长度为L的云计算资源负荷时间序列,使用固定尺寸重叠滑动窗口技术将这长度为L的时间序列数据截成每段长度为d的n段子序列,得到n个d维数据点x
进一步地,当有新的资源负荷时间序列数据到来时,使用基于双时间尺度的聚类簇更新机制来放置新来的负荷数据,在短时间尺度上,计算新来数据与已有的聚类之间的相似度,并将新数据放入能够产生与其有最大相似度的聚类簇中,在长时间尺度上,将历史数据和新到数据一起进行一次聚类簇重新确定过程。
进一步地,所述步骤S23中采取基于遗传算法优化的Elman神经网络预测器。
进一步地,所述步骤S3中进行资源分配的控制实施周期T
其中,K为缓冲器队列中可容纳的最大资源请求数的参数值,
进一步地,所述步骤S3中采取主动控制与被动反应相结合的自适应弹性资源配置策略进行资源分配具体为:
利用获得的数据计算资源需求变化量D(t),被动反应策略为应对当前变化所需增加或减少的资源量为:
N
其中,SR
利用预测获得的下一时刻资源需求的变化量估计值
若N
若被动反应策略决定需要增加资源供应而主动控制策略决定减少资源供应时,只执行被动反应策略,云计算将提供的资源量为:C(t)+N
其它情况,不再分配实施主动控制所需资源N
本发明还提供一种数据中心资源分配装置,包括:
监控模块,用于对云计算环境下数据中心的运行状态进行监控,并采集历史资源使用状态数据;
预测模块,用于从历史资源使用状态数据提取出当前时间段内的资源负荷数据,并基于当前时间段内的资源负荷数据进行预测以得到下一时间段的云计算资源负荷值;
资源分配模块,用于对当前时间段内的资源负荷数据和下一时间段的资源负荷值进行综合分析,并采取主动控制与被动反应相结合的自适应弹性资源配置策略进行资源分配。
进一步地,所述预测模块包括:
数据提取单元,用于利用固定尺寸重叠滑动窗口技术从历史数据集中提取当前时间段的云计算资源负荷子序列集;
分类单元,用于使用KFCM聚类算法将云计算资源负荷子序列集分成若干类并放置于不同的聚类簇中;
分配单元,用于给每一个聚类簇分配一个预测器,将每一个聚类簇中的云计算资源负荷子序列集输入到预测器中对其进行训练和预测;
选择单元,用于挑选出具有最小预测误差的聚类簇及其所对应的预测器进行预测,获得下一时间段所需的云计算资源负荷预测值。
本发明实施例的有益效果在于:将资源需求预测及混合式资源供给策略结合起来,能更好地适应云计算环境,为资源的优化合理配置提供切实有效的保障,在提供高服务质量的同时,保证云计算平台稳定运行和资源的合理使用,为云计算用户提供可靠、灵活、高效的资源供应服务。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明实施例一一种数据中心资源分配方法的流程示意图。
图2是图1所示步骤S2的具体流程示意图。
图3是本发明实施例二一种数据中心资源分配装置的模块结构示意图。
图4是图3所示预测模块的单元结构示意图。
具体实施方式
以下各实施例的说明是参考附图,用以示例本发明可以用以实施的特定实施例。
如图1所示,本发明实施例一提供一种数据中心资源分配方法,包括:
步骤S1,对云计算环境下数据中心的运行状态进行监控,并采集历史资源使用状态数据;
步骤S2,从历史资源使用状态数据提取出当前时间段内的资源负荷数据,并基于当前时间段内的资源负荷数据进行预测以得到下一时间段的云计算资源负荷值;
步骤S3,对当前时间段内的资源负荷数据和下一时间段的资源负荷值进行综合分析,并采取主动控制与被动反应相结合的自适应弹性资源配置策略进行资源分配。
可以理解,本实施例的云环境下数据中心的资源分配方法,先通过对云计算环境下数据中心的运行状态进行监控并采集历史资源使用状态数据,然后从历史资源使用状态数据提取出当前时间段内的资源负荷数据,并基于当前时间段内的资源负荷数据进行预测以得到下一时间段的云计算资源负荷值,最后基于当前时间段内的资源负荷数据和下一时间段的资源负荷值采取主动控制与被动反应相结合的自适应弹性资源配置策略进行资源分配,将资源需求预测及混合式资源供给策略结合起来,能更好地适应云计算环境,为资源的优化合理配置提供切实有效的保障,在提供高服务质量的同时,保证云计算平台稳定运行和资源的合理使用,为云计算用户提供可靠、灵活、高效的资源供应服务。
可以理解,如图2所示,所述步骤S2具体包括以下步骤:
步骤S21:利用固定尺寸重叠滑动窗口技术从历史数据集中提取当前时间段的云计算资源负荷子序列集;
步骤S22:使用KFCM聚类算法(Kernel Fuzzy C-Means,基于核的模糊C均值聚类算法)将云计算资源负荷子序列集分成若干类并放置于不同的聚类簇中;
步骤S23:给每一个聚类簇分配一个预测器,将每一个聚类簇中的云计算资源负荷子序列集输入到预测器中对其进行训练和预测;
步骤S24:挑选出具有最小预测误差的聚类簇及其所对应的预测器进行预测,获得下一时间段所需的云计算资源负荷预测值。
可以理解,在所述步骤S21中,对于给定长度为L的云计算资源负荷时间序列,使用固定尺寸重叠滑动窗口技术(Fixed Size Overlapping Sliding Window,FSOSW)将这长度为L的时间序列数据截成每段长度为d的n段子序列,则n=L/d,从而得到了n个d维数据点x
可以理解,在所述步骤S22中,令X={x
Φ:R
其中,核映射函数Φ采用径向基核函数(Radial Basis Function,RBF):
其中系数a,b,σ>0,当a=1,b=2时,RBF退化为高斯函数。
KFCM聚类算法通过将特征空间中的距离作为优化目标来将数据集分到C个聚类簇中:
使得:
其中,
特征空间中的距离
最后,利用期望最大化方法计算目标函数(1-3)的最优解,得到约束条件下的最优聚类中心v
由上所述,所述步骤S22中使用KFCM聚类算法将云计算资源负荷子序列集分成若干类并放置于不同的聚类簇中的步骤具体包括以下内容:
步骤S221:设置目标函数精度ε,模糊指数p,最大迭代次数Maxiter,以及最大聚类数MaxC;
步骤S222:对云计算资源负荷子序列集X作归一化处理,选择核函数,设定相关参数,计算核矩阵K;
步骤S223:随机初始化隶属度矩阵U;
步骤S224:令t=1:Maxiter,计算目标函数J
步骤S225:输出最优隶属度矩阵U以及聚类中心v
可以理解,所述步骤S22中采用基于核的模糊C均值聚类算法(Kernel Fuzzy C-Means,KFCM)能识别数据中非凸的聚类结构,能将样本点映射到高维特征空间,在特征空间内利用与FCM(Fuzzy C-Means,模糊C均值聚类算法)模型一致的聚类准则设计目标函数并完成聚类。由于引入了核函数,因此可实现从原始数据空间到特征空间的非线性映射,KFCM可以得到原始数据空间的非凸聚类划分,从而提升了对于高维数据的划分能力,也即增强了FCM聚类算法对于高维数据的聚类能力。
可以理解,长度为d的云计算资源负荷子序列会根据他们的负载特性通过使用相应的聚类算法被放置到不同的簇中。当有新的资源负荷时间序列数据到来时,这些新来的数据同样也会被截成若干段子序列并放置到不同的聚类簇中。在此,本实施例使用基于双时间尺度的聚类簇更新机制来合理放置新来的负荷数据,并尽可能不影响预测效果。具体地,在很短的时间尺度上(如短于6小时或12小时),我们首先计算新来数据与已有的聚类之间的相似度,并将新数据放入能够产生与其有最大相似度的聚类簇中;在较长的时间尺度上(如长于6小时或12小时),我们会将历史数据和新到数据一起进行一次聚类簇重新确定过程,即重新训练数据来获得当前情况下的最优聚类簇。这样就可以通过不断更新和再训练最新数据来适应云计算资源负荷的动态性和实时性。
可以理解,在所述步骤S23中,预测器优选采用基于遗传算法优化的Elman神经网络预测器,Elman神经网络是一种典型的动态局部递归网络,其比BP神经网络、RBF神经网络等前向型神经网络具有更强的计算能力,更注重系统的稳定性。它在前馈网络的基础上,通过存储内部状态使其具备映射动态特征的功能,从而使得系统具有适应时变特性的能力。
如图3所示,Elman神经网络一般具有4层结构,除了与其他神经网络类似的输入层、隐含层、输出层以外,它还有一个特殊的结构称为承接层,也可以称作关联层,其中输入层神经元起信号传输的作用,输出层神经元起线型加权的作用,隐含层神经元的传递函数可采用线性或非线性函数,关联层用来记忆隐含层前一时刻的输出值并返回给输入可以认为是一步延时算子,这种自连方式使其对历史状态的数据具有敏感性,内部反馈网络的加入增加网络处理动态信息的能力。
Elman神经网络的非线性状态空间表达式为:
y(k)=g(ω
x(k)=f(ω
x
其中y、x、u、xc分别表示m维输出节点向量、n维隐含层节点单元向量、r维输入向量和n维反馈状态向量,ω
f(x)=(1+e
由于Elman神经网络采取与BP网络一致的权值更新方法—梯度下降法,通过不断训练来调整网络的权值和阈值,该过程开始于输出层,然后通过隐藏层向后移动。通过应用梯度法,Elman神经网络能找到更好的权值和阈值,但很容易出现局部极小值的问题,并在其训练过程出现不稳定收敛现象。所以,本实施例借助遗传算法(Genetic Algorithm,GA)来训练优化初始权值,遗传算法是一种随机搜索方法,在搜索过程中执行全局搜索,可以在更大的空间范围内展开有效搜索,因此GA算法能帮助Elman神经网络发现更好的网络连接权值和参数,提高了Elman神经网络的预测性能。
可以理解,所述步骤S23中基于遗传算法优化的Elman神经网络预测器的工作流程如下:
步骤S231:种群初始化。个体编码方法为实数编码,每个个体均为一个实数串组成的染色体,由输入层与隐含层连接权值、隐含层阈值、关联层与隐含层连接权值、隐含层与输出层连接权值,以及输出层阈值五部分组成,GA算法将Elman神经网络的初始随机权值和阈值编码为由若干染色体组成的初始种群;
步骤S232:适应度函数设置。用训练数据训练Elman神经网络后预测系统输出,把预测输出和期望输出的均方误差(Mean Square Error,MSE)作为个体适应度值(Fitness),其计算公式为:
式中,n为网络输出节点数,y
步骤S233:选择:采用轮盘赌法(Roulette Wheel Selection)把种群中所有染色体的适应度的总和看作一个轮盘的圆周,而每个染色体按其适应度在总和中所占的比例占据轮盘的一个扇区。每次染色体的选择复制可以看作轮盘的一次随机转动,它转到哪个扇区停下来,那个扇区对应的染色体就被选中。尽管这种选择方法是随机的,但它与各染色体适应度成比例,适应度大的染色体占据轮盘扇区面积大,被选中的概率就高;
步骤S234:交叉:从种群里面随机选择两个个体再在个体字符串中随机设置一个交叉点把两个个体从这个交叉点后的部分结构进行互换从而产生新的个体;
步骤S235:变异:从种群里随机挑选若干个体,在选中的个体中随机确定变异位,然后以一定的概率对变异位进行取反运算,或者以一定概率给变异位基因加一个符合某一范围内均匀分布的随机数;
步骤S236:形成新的一代种群;
步骤S237:当达到最大后代数时算法停止;
步骤S238:产生优化后的神经网络初始权值;
步骤S239:对Elman神经网络进行学习和训练并更新权值计算网络误差观测是否达到要求;
步骤S240:当达到训练次数时流程结束。
可以理解,在所述步骤S3中,从数据中心的历史资源使用状态数据中可得:
C(t+1)=C(t)+D(t+1) (1-12)
其中,C(t)和C(t+1)分别为当前及下一时刻需要用于处理请求的资源量,D(t+1)为下一时刻将增加或减少的资源需求量,即下一时刻资源需求的变化量,利用预测器获得的下一时刻资源需求量预测值C(t+1),t时刻云计算总的资源负载量为L(t),则:
它由三部分构成,即t时刻新到的资源请求量A(t),t时刻正在处理的资源请求量E(t),以及t时刻存放于缓冲器中的资源请求量B(t),τ为启用整个缓冲器所需的时间。t时刻资源请求的变化量为:
D(t)=L(t)-R(t) (1-14)
其中R(t)为t时刻可用于处理请求的资源总量,则下一时刻资源需求变化量D(t+1)的估计值
其中,控制实施周期T
其中,K为缓冲器队列中可容纳的最大资源请求数的参数值。K的取值较小时,控制系统能够对资源负载变化作出迅速的调整,但容易造成系统的震荡和不稳定;K的取值偏大时,控制器对资源负载变化的反应则较为迟钝。参数τ也有类似的作用,因为它决定着缓冲器中资源请求的启用率,在控制器的反应能力和稳定性之间起到平衡作用。
可以理解,所述基于主动控制与被动反应相结合的自适应弹性资源配置策略的主要思想是提前增加所需资源,延后释放当前空闲资源。目的是为用户提供足够资源、保证服务质量的同时,降低不必要的资源消耗,维持系统的稳定运行。与目前仅仅依靠被动反应配置策略相比,提前增加所需资源能保证在下一时间段内资源需求上升后有充足的资源量,从而不出现资源短缺和资源供给滞后的情况;而延后释放当前空闲资源是考虑云计算资源需求的不确定性,因为仅仅依靠预测信息来判断资源需求的变化是不够的,并且虚拟机的再次启动需要一定时间,当资源需求出现激增情况时,延后释放的资源能起到有效地缓冲作用。
具体地,所述主动控制与被动反应相结合的自适应弹性资源配置策略主要包括以下内容:利用获得的数据计算资源需求变化量D(t),被动反应策略为应对当前变化所需增加/减少的资源量(虚拟机数量)为:
N
其中,SR
利用预测获得的下一时刻资源需求的变化量估计值
若N
若被动反应策略决定需要增加资源供应而主动控制策略决定减少资源供应时,即两者的决定相矛盾时,只执行被动反应策略,因为被动反应策略主要应对当前的资源需求状况,即云计算将提供的资源量为:C(t)+N
其它情况,系统将不再分配实施主动控制所需资源N
再请参照图4所示,相应于本发明实施例一种数据中心资源分配方法,本发明实施例二还提供一种数据中心资源分配装置,包括:
监控模块,用于对云计算环境下数据中心的运行状态进行监控,并采集历史资源使用状态数据;
预测模块,用于从历史资源使用状态数据提取出当前时间段内的资源负荷数据,并基于当前时间段内的资源负荷数据进行预测以得到下一时间段的云计算资源负荷值;
资源分配模块,用于对当前时间段内的资源负荷数据和下一时间段的资源负荷值进行综合分析,并采取主动控制与被动反应相结合的自适应弹性资源配置策略进行资源分配。
本实施例一种数据中心资源分配装置的工作原理及具体工作过程请参照本发明实施例一的说明,此处不再赘述。
通过上述说明可知,本发明实施例的有益效果在于:将资源需求预测及混合式资源供给策略结合起来,能更好地适应云计算环境,为资源的优化合理配置提供切实有效的保障,在提供高服务质量的同时,保证云计算平台稳定运行和资源的合理使用,为云计算用户提供可靠、灵活、高效的资源供应服务。
以上所揭露的仅为本发明较佳实施例而已,当然不能以此来限定本发明之权利范围,因此依本发明权利要求所作的等同变化,仍属本发明所涵盖的范围。
- 一种数据中心资源分配方法及装置
- 基于人工智能的数据中心资源分配方法及装置