一种融合域特征交互的基于注意力网络学习的点击率预测方法
文献发布时间:2023-06-19 10:24:22
技术领域
本发明属于互联网广告点击率预测领域。提出一种融合域特征交互的基于注意力网络学习的点击率预测方法。
背景技术
在线广告是随着互联网的诞生与发展而衍生出的一种广告形式,即有广告发布需求的广告主通过具备广告发布能力的在线广告发布商,将具有宣传其产品或服务的广告向互联网用户发布。点击率(Click-Through-Rate,CTR)预测是根据给定的用户点击广告的历史数据以及其它辅助信息,预测出用户点击广告的概率。但是互联网中积累的大多数广告日志具有数据稀疏、特征维度大等特征,这给如何使用模型高效地从数据中提取出有效信息以提高点击率预测地准确度带来巨大的挑战。
随着数据挖掘、自然语言处理等技术的发展,在广告点击率预测方面已经有了不少成熟的研究。因子分解机(FM)模型为每个特征学习隐向量,然后在用户特征、广告特征和辅助信息特征之间进行交互,不但实现效率高,而且模型对数据中的噪声具有很好的鲁棒性,是工业界最常使用的在线广告点击率预测模型。但是FM方法仅对输入的特征之间的线性相互作用进行建模,不足以捕获现实世间数据复杂的非线性关系。深度学习能够自动探索数据间的局部依赖关系并且可建立特征之间的密集表示,使得神经网络能够在原始数据中提取出高阶特征,这种有效学习高阶隐含信息的能力也被应用到了CTR预测中。基于FM的CTR预测神经网络(DeepFM)模型由集成在并行结构中的FM部分和神经网络部分组成。FM部分用于对特征的一阶信息和特征之间的二阶交互信息进行建模,神经网络部分用于捕获非线性的高阶特征交互信息。这两部分共享相同的嵌入空间,并且将它们的输出汇总为最终预测。DeepFM模型可以有效的提高CTR预测的准确率,并且不会产生巨大的模型参数,具有很好的扩展性,被广泛应用于工业界中。
但是DeepFM忽略了特征交互的深度,在FM部分,使用简单的内积操作作为特征交互规则,不能很好的挖掘出特征之间的深层联系,同时随着用户历史数据量的急剧增加,DeepFM在特征交互部分所花费的时间也在急剧加大,导致模型整体的时间复杂度越来越大。因此建立更加有效的交互规则,捕获特征之间的深层联系是至关重要性。同时,在建立预测模型的过程中,考虑模型的时间复杂度,保证在低时间复杂度的情况下,还能够得到更好的预测结果,对工业上的实际应用是十分重要的。
发明内容
本发明的目的是在降低模型复杂度的情况下还可以得到更好的CTR预测结果,提出一种融合域特征交互的基于注意力网络学习的点击率预测方法。
本发明提供的融合域特征交互的基于注意力网络学习的点击率预测方法,方法包括:
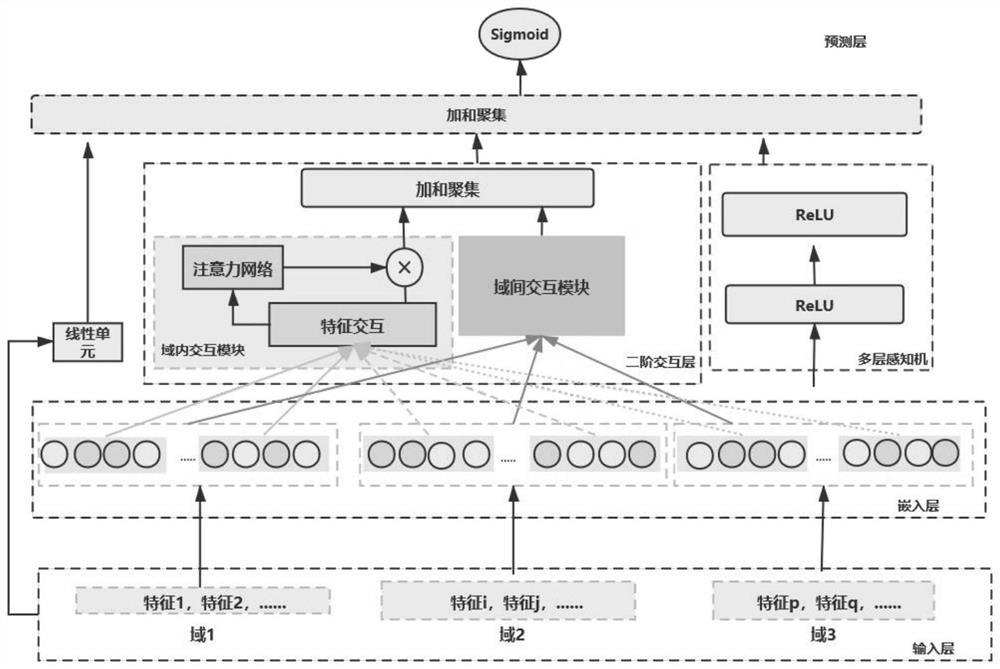
1)利用特征与标记之间的相关性,将特征划分在不同的域中。在点击率预测领域,输入空间中的特征多数是非数值型的离散数据,本发明使用信息增益率探索用户特征、物品特征和其它辅助信息特征与标记之间的相关性。根据相关性将输入空间中的特征进行分组化,把特征平均划分在若干个不同的域中,每个特征都有唯一的所属域。本发明随机初始化域的个数,通过模型的学习能力,不断优化域的大小和个数。
2)特征嵌入向量表达。独热编码(one-hot)可以提高模型的运算效率,并且更加适用于非数值型的离散数据。模型输入过程中,每个输入样本的特征经过one-hot编码后,得到对应的输入向量。但是因为巨大的数据量,导致特征输入向量会变得高维且高稀疏,不利于实际应用。本发明采用嵌入技术,将高维且高稀疏的特征输入向量转变为低维且稠密的特征嵌入向量。
3)特征二阶交互。在得到域的划分结果和每个特征的嵌入向量表达之后,本发明提出特征域内和域间的独立交互过程。对于域间交互,某个域包含若干个特征,每个特征有唯一的所属域,将属于该域的特征嵌入向量进行加和,作为该域的嵌入向量表达,然后使用哈达玛积(Hadamard)作为域间交互的方法。对于域内交互,本发明提出一个新的交互方法,从特征嵌入向量维度的层次进行内积操作,增加域内特征交互深度,并且使用注意力网络自动学习域内特征交互的重要性,提高域内特征交互效果。通过实验对比,本发明提出的新的交互方法优于目前常用的Hadamard积交互。
4)特征高阶交互。本发明利用多层感知机(MLP)网络结构捕获所有特征嵌入向量之间的高阶交互信息。
5)预测层。本发明结合特征二阶交互和高阶交互,作为输入特征的交互结果,同时保留输入特征的线性关系,增加特征交互的宽度,最后利用Sigmoid函数,得到预测结果。
本发明的优点和积极效果:本发明提出一种融合域特征交互的基于注意力网络学习的点击率预测方法,在传统深度学习模型的框架上引入域的划分。在此基础上,本发明提出特征域内和域间的独立交互,并且设计新的交互方法来探究域内特征交互的深层联系,同时利用注意力网络自动学习域内特征交互的重要性,提高域内特征交互效果。本发明与现有技术相比,具有以下优点:
(1)引入域的划分,特征域内和域间的独立交互,可以有效降低特征在二阶交互过程中的时间消耗,从而降低模型整体的时间复杂度。
(2)提出新的交互方法,从特征嵌入向量维度的层次进行交互,增加特征交互的深度,交互过程更加细微,对比常用的Hadamard积交互方法,本发明提出的新方法可以得到更好的交互结果。
(3)使用注意力网络自动学习特征交互的重要性。通过注意力网络自动学习出特征交互的重要性,从而得到不同特征交互结果对模型预测的影响程度,提高特征交互的效果。
附图说明
图1是本发明的整体框架图。
具体实施方式
实施例1
本发明提供的融合域特征交互的基于注意力网络学习的点击率预测方法,在传统的基于深度学习的点击率预测基础上,提出域的划分,进行特征域间和域内的独立交互,同时提出新的交互方法,并利用注意力网络自动学习域内特征交互的重要性。参见附图1,本发明具体的构建过程如下。
用DFILAN表示本发明提出的融合域特征交互的基于注意力网络学习的点击率预测方法。DFILAN模型中使用到的数学符号定义如下表所示。
表1.本发明所使用到的数学符号定义
步骤一:
域的划分。首先计算出数据集中每个特征与标记之间的相关性。以电影数据集(MovieLens)为例,本发明选择其中7个特征,将数据集中的评分特征定义为样本的标记,并且将评分是1-2的定为0,3-5的定位1。通过信息增益率计算每个特征与标记之间的相关性。信息增益率的公式定义为:
Gain-rate(标记,特征)代表特征与标记之间的信息增益率,Gain(标记,特征)代表特征与标记之间的信息增益,IV(特征)代表特征不同的取值个数。得到每个特征与标记之间的相关性后,按照相关性大小将特征进行降序排列,结果如表2所示。然后随机初始化域的个数,将特征划分在不同的域里,结果如表3所示。
表2.MovieLens数据集特征与标记之间的相关性
表3.MovieLens数据集域的划分结果
步骤二:
特征嵌入向量表达。数据集经过域的划分之后,每个域包含若干个特征,每个特征有唯一的所属域,然后将数据输入到搭建好的模型框架,进行模型训练。本发明先是对特征进行独热编码(one-hot),然后使用嵌入技术,将高维、高稀疏的输入向量转变为低维、稠密的嵌入向量。假设输入数据如表4所示,每个样本有4个特征和对应的一个标记。通过one-hot编码,可以得到每个样本的输入向量表达,结果如表5所示。
表4.实例数据
表5.one-hot编码输入特征结果
通过表5可以发现,经过one-hot编码之后,真实世界的数据转变为非0即1的数值型数据,更加有利于模型的处理。但是one-hot编码会使得每个数据样本对应的输入向量变得十分的稀疏且高维,在如今海量数据面前,one-hot编码不能再直接输入到深度学习框架中。本发明使用嵌入技术将高维且稀疏的输入向量转变为低维且稠密的嵌入限量。为每个特征随机初始化一个D维的嵌入矩阵。例如,我们采用表4的输入向量结果,设D=2,嵌入向量计算过程如下所示。样本1嵌入向量表达结果如表6所示。
表6.特征嵌入向量结果
在得到域的划分结果和每个特征的嵌入向量表达之后,计算每个域的嵌入向量表达。如表3所示,movie_id,user_id特征属于M
表7.域的嵌入向量表达
步骤三:
在得到每个特征的嵌入向量和每个域的嵌入向量之后,本发明进行特征域间和域内的独立交互。
(1)域间交互。本发明使用哈达玛积(Hadamard)作为域间交互的方法。以样本1为例得到域间交互结果如下:
|0.5 -0.7|⊙|1.2 -1.4|=|0.5×1.2 -0.7×(-1.4)|=|0.6 0.98|
通过实验,可以发现在域的个数比较少的情况下,模型性能达到最优。因此在设计交互层的时候,本发明主要考虑的是域内交互,对于域间交互过程,仅仅是使用Hadamard积作为交互方法。域间交互的结果如表8所示。
表8.域间交互结果
从上面的计算过程,可以发现Hadamard积交互是嵌入向量对应维度相乘,相比于传统的内积交互,Hadamard积可以得到更好的交互结果,但是它依然只是在向量对应维度上进行操作,交互程度比较浅。本发明在此基础上,提出新的交互方法,在嵌入向量维度之间的进行交互,交互程度更深,更能探索出特征之间的关系。
(2)域内交互。本发明提出一种新的交互方法,在Hadamard积的基础上,进行嵌入向量维度之间的交互。以样本1中的M
从这个交互过程中,可以看出本发明提出的新的交互方法是让域内所有特征的嵌入向量在维度上进行内积操作。例如-0.18=0.2*(-0.3)+0.3*(-0.4),它代表所有特征的嵌入向量第一维与所有特征的嵌入向量第二维进行内积。新的交互方法从特征嵌入向量出发,为了探索特征之间的深层联系,在嵌入向量维度之间进行内积操作,嵌入向量维度之间的交互,相比于常用的Hadamard积交互方法,交互程度更深,更能挖掘出特征之间的关系。
同时为了更好的说明不同的特征交互对预测结果影响程度的不同,本发明引入注意力网络自动的学习出特征交互的重要性。注意力网络的公式如下:
a′
其中I
本发明使用softmax函数将特征两两交互的重要性值映射到(0,1)之间,提高模型训练效率。softmax函数公式如下:
域内特征交互结果如表9所示。
表9.域内交互结果
域内特征交互的具体实现过程描述如下:
上述算法的中文描述:
步骤四:
本发明使用神经网络来捕获所有特征嵌入向量的高阶交互。在步骤三中,已经得到特征二阶交互的结果,挖掘出特征两两之间的深层关系。在该步骤中,本发明通过搭建多层感知机来捕获特征的高阶交互。输入是H
H
H
......
H
其中W代表MLP中每一层的权重矩阵,b代表MLP中每一层的偏置,每层的激活函数都是使用的ReLU函数。
步骤五:
在得到特征之间不同程度的交互结果后,本发明结合所有的交互结果做出最终的预测。预测层的输入如下所示:
本发明使用Sigmoid函数来预测最终的点击概率,公式如下:
在得到预测值之后,需要根据预测误差来更新模型参数,不断地训练模型,达到模型预测误差最小。本发明定义损失函数如下:
在参数更新过程中,本发明使用的是Adam优化器,使得模型训练速度更快。
实施例2
具体性能对比:
本发明将DFILAN与其它CTR预测方法在ROC曲线与坐标轴形成的面积(AUC)和对数损失(LogLoss)两个方面进行了比较,并测试了参数信息对模型性能的影响。性能测试的主要参数设置如表10所示。其它CTR预测方法包括因子分解机(FM),基于因子分解机的CTR预测神经网络(DeepFM),结合显性和隐性的特征交互(XDeepFM),利用字段进行可扩展的CTR预测(FLEN),用于用户响应预测的可感知操作的神经网络(ONN)。实验结果证明,本发明提出的融合域特征交互的基于注意力网络学习的点击率预测方法在CTR预测精准度和预测模型时间复杂度上要优于目前为止类似的最先进方法。
表10.实验参数
本发明使用了Avazu数据集,最早应用于Kaggle比赛,该数据集包含24个特征,1个标记,数据样本4千万条,本发明随机选择1百万条数据进行实验。实验中,随机选择数据样本的80%用于模型训练,20%用于模型测试。
- 一种融合域特征交互的基于注意力网络学习的点击率预测方法
- 一种基于协同注意力机制的短视频点击率预测方法