眼底造影图像无灌注区自动识别及激光光凝区域推荐算法
文献发布时间:2023-06-19 11:27:38
技术领域
本发明属于智能医疗技术领域,具体涉及一种眼底造影图像无灌注区自动识别及激光光凝区域推荐算法。
背景技术
视网膜静脉系统中血栓形成或因炎症而造成相应静脉发生梗阻称为视网膜静脉阻塞(Retinal Vein Occlusion,RVO),它是仅次于糖尿病视网膜病变的第二大最常见的视网膜血管性疾病,也是造成视力丧失的重要原因。临床上根据阻塞发生部位不同,RVO可分为视网膜中央静脉阻塞(Central Retinal Vein Occlusion,CRVO)及视网膜分支静脉阻塞(Branch Retinal Vein Occlusion,BRVO)。
眼底荧光血管造影(fundus fluorescence angiography,FFA)可用于评估RVO血管阻塞范围、缺血程度和黄斑水肿的类型,是评估视网膜循环状态的重要工具和金标准。缺血性RVO定义,在CRVO为伴有10个视盘面积(disc areas,DA)以上的无灌注区(non-perfusion areas,NPA),BRVO为伴有5个DA以上的无灌注区。临床上明确分型的重要意义在于缺血型和非缺血型RVO在自然病程、处理方法、治疗的反应及预后方面均不同,而分型的关键在于无灌注区面积的定量分析,因此无灌注区面积的自动识别对于RVO的病情分析及治疗方案选择都是至关重要的。
人工智能简称AI(Artificial Intelligence)是计算机科学的分支,一种能够模拟人类智能行为和思维过程的系统。最早于1956年由被誉为“人工智能之父”的美国人约翰麦卡锡在达特茅斯会议上首次提出。近年来AI在生产生活各个领域的突破主要来自深度学习(Deep Learning)技术,源于人工神经网络的研究,通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示,是人工智能的核心技术。其概念由被称为“神经网络之父”的Hinton于2006年提出。2012年Hinton教授的研究团队研发的多层卷积神经网络结构,突破性的将图像识别错误率大大降低。这一革命性的技术,让神经网络深度学习飞速跃入了医疗领域。随着大数据时代的到来和计算机硬件的巨大进步,深度学习技术尤其是卷积神经网络,在图像分类、分割、检测等很多任务中相对传统模式识别方法优势显著。
AI+医学影像,是将人工智能技术具体应用在医学影像的诊断上,已报道人工智能涉及了X线、CT、MRI、病理、超声等多种医疗影像,涉及的病种也越来越广,在提高影像判读效率、提高病变诊断准确率方面有着人类无法比拟的优势。基于眼部影像学图像分析是AI在眼科领域应用的关键点。2016年顶级医学期刊JAMA报道,Google团队研发的人工智能诊断技术,根据眼底照片快速诊断糖尿病视网膜病变,灵敏度及特异度均在90%以上,诊断能力已达专家水平。其筛查糖尿病视网膜病变的能力已达专家级。其后,各国研究者基于对眼底彩照、眼前节彩照、OCT及静态视野等眼科影像学图片进行分析处理,利用AI的深度学习算法,对先天性白内障诊治方案、湿性年龄相关性黄斑变性治疗决策、青光眼、早产儿视网膜视网膜病变、孔源性视网膜脱离等方面都有文献报道。但是,目前在视网膜静脉阻塞的FFA影像方面研究未见报道。
发明内容
基于目前国内外研究未利用AI技术对FFA图像进行无灌注区定量分析,本发明使用55°视野图像的眼底荧光造影机标注RVO患者视网膜无灌注区面积,结合AI强大高效的影像分析判断能力及临床大数据处理能力,追踪RVO患者的自然病程、治疗及预后,实现眼底造影图像的无灌注区面积精准定量分析,并可为激光手术提供规划,且能智能规避视盘黄斑区域。
为了达到上述目的,本发明采用了下列技术方案:
本发明提供一种眼底造影图像无灌注区自动识别及激光光凝区域推荐算法,包括以下步骤:
步骤1,采集眼底的后极部55度的眼底造影图像;
步骤2,对眼底造影图像进行脱敏预处理和数据增强;
步骤3,由专业眼科主任医生利用labelme工具对脱敏预处理和数据增强后的眼底造影图像进行标注,标注内容包括无灌注区、视盘区域、黄斑区域三部分,并通过实现json2img函数,将标注结果转换为图像格式,背景区域像素值为0,视盘区域像素值为1,黄斑区域像素值为2,无灌注区像素值为3;
步骤4,将标注后的眼底造影图像按照80%和20%的占比随机分为训练集和测试集,以文件夹的形式来区分,文件夹名字分别为train和test;
步骤5,在以TensorFlow为后端的Keras深度学习框架的基础上,利用keras框架中的layers模块构建3个标准化多流卷积神经网络模型,分别用来识别视盘区域、黄斑区域、无灌注区域;
步骤6,利用训练集图像数据对构建的多流卷积神经网络模型进行优化训练,并用测试集数据对网络模型进行验证;
步骤7,利用步骤6训练优化好的网络模型对设备实际采集数据图像进行无灌注区、视盘区域、黄斑区域的识别分割。
进一步,所述步骤2中对眼底造影图像进行脱敏预处理过程为:利用opencv-python模块下的cv2.threshold方法通过阈值分割保留眼底区域,同时剔除图像上的患者信息并将背景区域置0。
所述步骤2中对预处理后的眼底造影图像进行数据增强采用限制对比度自适应直方图均衡方法,具体为使用opencv-python模块下的createCLAHE方法创建clahe对象,clipLimit参数设置为1,titleGridSize参数设置为(8,8)。
进一步,所述步骤3中眼底造影图像标注的输出结果为json格式,存储内容为每个标注区域的标签名及区域边缘点的坐标位置信息。
进一步,所述步骤5中的构建的神经网络模型共有34层,包括输入层、下采样层、上采样层、输出层4部分,其中:
输入层要求输入图像的尺寸为768*768;
下采样层由前17层组成,功能为特征提取,第1、2层为卷积层,卷积核数量为64、卷积核大小为3×3,步长为1,padding方式为same,且在卷积层后会有一个relu激活层以提高网络模型的非线性拟合能力;第4层为最大值池化层,窗口大小为2×2,步长为2,池化层输出的特征图大小会变小;第5、6层为卷积层,为保证特征数量不减少,卷积核数量会增加变为128;第7层为池化层,参数配置与第4层相同的;第8、9层为卷积层,卷积核数量为256;第10层为最大值池化层,参数配置与第4层相同;第11、12为卷积层,卷积核数量为512;第13层为Dropout层,dropout率为0.5;第14层为最大值池化层;第15、16层为卷积层,卷积核数量为1024;第17层为Dropout层;
上采样层由15层组成,目的是还原图像细节、提取目标区域,第18层为转置卷积层,卷积核大小为2×2,该层可将特征图大小放大,该层的输出会与下采样层第13层的输出特征图进行拼接形成最终的输出,通过拼接可保留更多的图像细节,提升病灶区域分割结果的精细度;第19、20层为卷积层,随着特征图大小的放大,卷积核数量也会减少,这两层的卷积核数量为512,卷积核大小为3×3;第21层为转置卷积层,参数与第18层相同;第22层为卷积层,卷积核大小为2×2,该层的输出会与下采样层第9层的输出特征图进行拼接形成最终的输出;第23、24层为卷积层,卷积核数量为256,卷积核大小为3×3;第25层为转置卷积层,参数与第18层相同;第26层为卷积层,卷积核大小为2×2,该层的输出会与下采样层第6层的输出特征图进行拼接生成该层的输出;第27、28层为卷积层,卷积核数量为128,卷积核大小为3×3;第29层为转置卷积层,参数与第18层相同;第30层为卷积层,卷积核大小为2×2,该层的输出会与下采样层第2层的输出特征图进行拼接生成该层的输出;第31、32层为卷积层,卷积核数量为64,卷积核大小为3×3;
输出层:包括2层,目的是输出最终分割结果,第33层为卷积层,卷积核数量为2;34层为softmax层,对输出结果进行归一化,得到造影图像每个像素分别属于每个类别的概率。
进一步,所述步骤5中多流卷积神经网络模型卷积层的构建方法为layers.Conv2D,池化层的构建方法为layers.MaxPooling2D,转置卷积层的构建方法为layers.Upsampling 2D,高层特征与低层特征的拼接采用layers.concatenate方法。
进一步,所述步骤6是通过JsonGenerator类实现数据迭代器,调用JsonGenerator类下的train_generator方法获取训练集的迭代器,调用JsonGenerator类下的valid_generator方法获取测试集的迭代器。
所述步骤6中利用训练集图像数据对网络模型进行优化训练的过程为:在网络模型中分批次加载训练数据和标签,得到输出结果后,通过模型运算来计算每批数据的准确率和交叉熵损失,在训练过程中不断保存更优效果的网络模型权重文件,利用损失对模型权重进行优化,使网络模型的损失值不断降低,在训练迭代次数达到程序设定值时退出训练循环并绘制变化图,分析网络模型训练效果,通过加载不同像素值的标签分别训练3个网络模型以实现对不同区域的识别。
进一步,所述步骤7中对无灌注区、视盘区域、黄斑区域的识别分割具体为,选取大于阈值的像素点作为视盘区域候选区;所有预测概率大于0.5的像素,作为黄斑区域候选区;所有预测概率大于0.5的像素,作为无灌注区域候选区。
更进一步,所述阈值按公式p_thresh=(1-k)*p_min+k*p_max计算得到,其中,p_max和p_min分别为预测概率的最大值和最小值,k取0.8。
与现有技术相比本发明具有以下优点:
传统临床中的RVO分型均是根据医生的主观判断来进行,通过AI技术对FFA图像无灌注区的定量分析可极大提升医生的诊断能力;利用多流卷积神经网络模型可同时识别无灌注区域、视盘区域、黄斑区域,定量分析无灌注区面积,且在激光手术时可自动规避视盘区域、黄斑区域。无灌注区的定量分析可有效改善患者随访阶段的病情分析,视盘黄斑区域的识别可为激光手术提供规划,一方面可自动对无灌注区进行激光手术,另一方面可智能规避视盘区域、黄斑区域。
附图说明
图1为图像脱敏预处理过程图。
图2为图像标注示例图。
图3为多流卷积神经网络模型训练过程图。
图4为视盘中心定位示意图。
图5为视盘区域与视盘中心的定位结果图。
图6为黄斑区域及黄斑中心定位示意图。
图7为无灌注区域的定位示意图。
图8为多流卷积神经网络模型预测结果图。
图9为手术激光规划图。
具体实施方式
下面结合具体实施方式对本发明作进一步的说明,但并不限制本发明的范围。
实施例1
神经网络模型的构建
在以TensorFlow为后端的Keras深度学习框架的基础上构建3个标准化Unet卷积神经网络模型,分别用来识别视盘区域、黄斑区域、无灌注区域。通过keras框架中的layers模块搭建网络模型的各种层,卷积层的搭建方法为layers.Conv2D,池化层的搭建方法为layers.MaxPooling2D,转置卷积层的搭建方法为layers.Upsampling2D,高层特征与低层特征的拼接采用layers.concatenate方法。
网络模型结构描述:网络模型共有34层,包括输入层、下采样层、上采样层、输出层4部分。
输入均为尺寸为768*768的造影图像。
下采样层由前17层组成,功能为特征提取,第1、2层为卷积层,卷积核数量为64、卷积核大小为3×3,步长为1,padding方式为same,且在卷积层后会有一个relu激活层以提高网络模型的非线性拟合能力;第4层为最大值池化层,窗口大小为2×2,步长为2,池化层输出的特征图大小会变小;第5、6层为卷积层,为保证特征数量不减少,卷积核数量会增加变为128;第7层为池化层,参数配置与第4层相同的;第8、9层为卷积层,卷积核数量为256;第10层为最大值池化层,参数配置与第4层相同;第11、12为卷积层,卷积核数量为512;第13层为Dropout层,dropout率为0.5;第14层为最大值池化层;第15、16层为卷积层,卷积核数量为1024;第17层为Dropout层。
上采样层由15层组成,目的是还原图像细节、提取目标区域,第18层为转置卷积层,卷积核大小为2×2,该层可将特征图大小放大,该层的输出会与下采样层第13层的输出特征图进行拼接形成最终的输出,通过拼接可保留更多的图像细节,提升病灶区域分割结果的精细度;第19、20层为卷积层,随着特征图大小的放大,卷积核数量也会减少,这两层的卷积核数量为512,卷积核大小为3×3;第21层为转置卷积层,参数与第18层相同;第22层为卷积层,卷积核大小为2×2,该层的输出会与下采样层第9层的输出特征图进行拼接形成最终的输出;第23、24层为卷积层,卷积核数量为256,卷积核大小为3×3;第25层为转置卷积层,参数与第18层相同;第26层为卷积层,卷积核大小为2×2,该层的输出会与下采样层第6层的输出特征图进行拼接生成该层的输出;第27、28层为卷积层,卷积核数量为128,卷积核大小为3×3;第29层为转置卷积层,参数与第18层相同;第30层为卷积层,卷积核大小为2×2,该层的输出会与下采样层第2层的输出特征图进行拼接生成该层的输出;第31、32层为卷积层,卷积核数量为64,卷积核大小为3×3。
输出层包括2层,目的是输出最终分割结果,第33层为卷积层,卷积核数量为2;34层为softmax层,对输出结果进行归一化,得到造影图像每个像素分别属于每个类别的概率。
实施例2
网络模型的优化,包括以下步骤:
步骤1:由专业医师采集眼底的后极部55度的眼底造影图像,采集设备为海德堡SPECTRALIS HRA+OCT。
步骤2:图像脱敏预处理:利用opencv-python模块下的cv2.findContours方法提取眼底区域的所有轮廓,其中轮廓面积最大的为视网膜轮廓,同时剔除图像上的患者信息并将背景区域置0。
脱敏预处理结果见图1,其中图1-a为眼底区域轮廓提取结果,虚线范围即为眼底区域提取结果;图1-b为脱敏输出结果,去除了患者信息等内容;图1-c为预处理后的最终结果。
步骤3:采用限制对比度自适应直方图均衡(Contrast Limited AdaptiveHistogram Equalization,CLAHE)方法对脱敏后的图像数据进行数据增强,具体为使用opencv-python模块下的createCLAHE方法创建clahe对象,clipLimit参数设置为1,titleGridSize参数设置为(8,8)。该方法可使荧光较弱的血管得到增强。
步骤4:由专业眼科主任医生利用labelme工具对图像进行标注,标注内容包括无灌注区、视盘区域及视盘中心点位置、黄斑区域及黄斑中心凹位置。标注工具labelme输出结果为json格式,存储内容为每个区域的标签名及区域边缘点的坐标位置信息,通过实现json2img函数,将json格式的标注结果转换为图像格式,背景区域像素值为0,视盘区域像素值为1,黄斑区域像素值为2,无灌注区像素值为3。标注示例图如图2,其中图2-a为无灌注区标注示例图;2-b为视盘中心点标注示例图;2-c为黄斑中心凹标注示例图。
步骤5:由专业眼科主任医生通过labelme标注工具标注红外图像的视盘区域,红外图像可清楚查看视盘边界,由此可确定视盘面积的均值及范围。
步骤6:将标注后的眼底造影图像按照80%和20%的占比随机分为训练集和测试集,以文件夹的形式来区分,文件夹名字分别为train和test;
步骤7:网络模型的优化:神经网络代码实现的功能主要包括读取数据文件和对应的标签文件,对训练数据进行归一化预处理。通过JsonGenerator类实现数据迭代器,调用JsonGenerator类下的train_generator方法获取训练集的迭代器,调用JsonGenerator类下的valid_generator方法获取测试集的迭代器。
在网络模型中分批次加载训练数据和标签,得到输出结果后,通过模型运算来计算每批数据的准确率和交叉熵损失,由于图像中的目标分割区域面积占整体面积的比值较小并保存在日志文件中,利用损失对模型权重进行优化,通过优化函数使模型损失值不断降低。损失函数使用focal loss,优化器选择带动量的随机梯度下降算法,调用fit_generator方法实现模型参数的训练优化,并传入回调函数TensorBoard实现训练过程的绘制。在训练过程中不断保存更优效果的模型权重文件,在训练迭代次数达到程序设定值时退出训练循环并绘制变化图,分析网络模型训练效果。通过加载不同像素值的标签分别训练3个网络模型以实现对不同区域的识别。绘制结果见图3,其中图3-a为训练过程准确率变化图,图3-b为训练过程损失变化图。
训练完成后,通过分别加载3个模型权重文件来初始化模型权重,加载测试集数据对训练中的最优模型进行分析验证,验证阶段选取76张造影图像进行临床验证,最终效果显示无灌注区域识别IOU可以达到75.07%,视盘中心定位平均误差为16.37um,黄斑中心定位平均误差为43.91um。
实施例3
基于多流卷积神经网络模型的眼底造影图像的识别和分割
将采集的患者眼底造影图像加载到训练好的网络模型中,得到造影图像每个像素分别属于每个类别的概率。按下述方法对眼底造影图像进行识别分割。
1、视盘中心定位:
(1)选取所有像素预测概率的最大值p_max和最小值p_min;(2)确定分离视盘和背景的动态阈值,p_thresh=(1-k)*p_min+k*p_max,其中p_tresh表示分离视盘和背景的阈值,k取0.8;(3)选取大于阈值的像素点作为视盘候选区域,如图4-a所示;(4)对视盘区域做开运算;(5)遍历候选区域内的每个连通区域S,判断区域S是否满足条件:像素面积大于3050(视盘平均像素面积的一半);区域中心满足视盘中心的空间约束条件如图4-b所示,空间约束条件为左侧0.05×宽,右侧0.6×宽,上侧0.3×高,下侧0.3×高的范围和左侧0.6×宽,右侧0.05×宽,上侧0.3×高,下侧0.3×高的范围内为满足条件的范围;(6)选取满足上述条件的所有区域,取每个区域S内的最大概率作为其置信度,置信度最大的区域T即为视盘所在区域,如图5-a所示;(7)计算区域T的中心,即为视盘中心,如图5-b所示。
2、黄斑中心定位:
(1)选取所有预测概率大于0.5的像素,作为黄斑候选区域,如图6-a;(2)遍历候选区域内的每个连通区域S,判断区域S是否满足条件:像素面积大于10;区域中心满足黄斑中心的空间约束条件在图6-b中的虚线边框内,空间约束条件为左侧0.3×宽,右侧0.3×宽,上侧0.4×高,下侧0.3×高;(3)选取满足上述条件的所有区域,取每个区域S的面积作为其置信度,置信度最大的区域T即为黄斑所在区域;(4)计算区域T的中心,即为黄斑中心,如图6-c。
3、无灌注区定位:
(1)选取所有预测概率大于0.5的像素,作为无灌注候选区域,如图7-a;(2)遍历候选区域内的每个连通区域S,确定区域S内高危无灌注区的阈值t,t=(1-0.75)*p_min+0.75*p_max;(3)取区域S内概率大于t(高危区域)像素的平均概率作为其置信度,如图7-b。
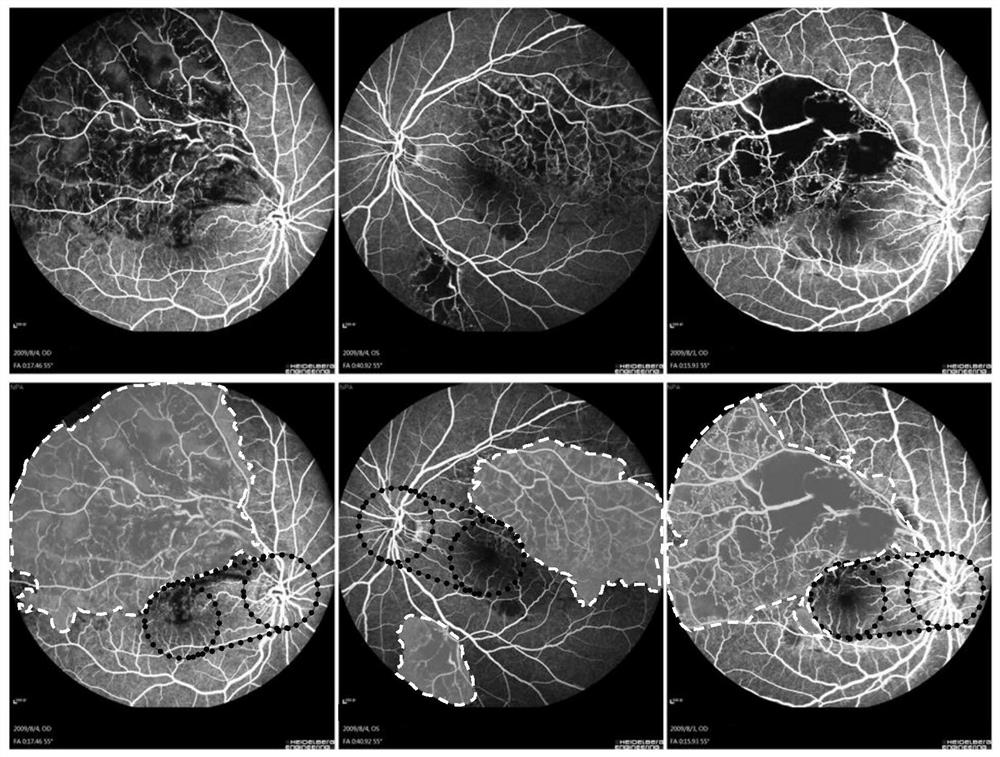
图8为网络模型的预测结果图。其中,第一列为预处理后的FFA图像,第二列为医生标注结果,第三列为网络模型预测结果,图中虚线不规则区域为无灌注区,靠近无灌注区的虚线圆圈为黄斑区域,另一个虚线圆圈为视盘区域。
实施例4
激光手术建议,见图9,其中第一行为原始的FFA图像,第二行为激光手术规划图,虚线不规则区域为建议激光手术区域,两个虚线圆圈以及与视盘、黄斑两个圆都相切的直线与圆弧围成的区域为激光禁区。
(1)由网络模型识别出眼底的无灌注区域、视盘中心、黄斑中心。本方案不考虑患者因素,故标出所有需要治疗的区域,具体激光过程由医生决定。
(2)取黄斑中心的1个视盘直径范围、视盘中心的1个视盘直径范围,作为激光禁区,如图虚线圆圈部分;
(3)取两条与视盘、黄斑两个圆都相切的直线与圆弧围成的区域,作为激光禁区,如图两虚线圆圈及其中间部分;
(4)将无灌注区域中与手术禁区重叠的部分进行排除,剩余部分即为建议手术区域,如图9第二行虚线不规则部分。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,对于本领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干变型和改进,都包含在本发明的保护范围之内。
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
- 眼底造影图像无灌注区自动识别及激光光凝区域推荐算法
- 基于深度学习的眼底荧光造影图像无灌注区自动分割方法