基于深监督学习的图像显著性目标检测方法
文献发布时间:2023-06-19 11:54:11
技术领域
本发明属于图像显著性目标检测领域,尤其涉及一种基于深监督学习的图像显著性目标检测方法。
背景技术
显著性目标检测的目的是用算法定位图像中最明显和最吸引眼球的区域(即人眼感兴趣区域),体现人眼中图像各区域的重视程度,识别图像的主体,减少场景的复杂度,研究人员致力于开发模拟人类注意过程的计算模型来预测图像显著性目标,它可以作为许多计算机视觉任务的预处理步骤,如场景分类,图像分割,视频压缩,信息隐藏等,在图像处理领域具有至关重要的作用。
在过去的二十年里,人们已经提出了大量的方法来检测图像中的显著目标。受人类视觉注意机制的启发,早期的经典显著对象检测模型主要利用启发式先验信息来建模或者将显著性检测定义为二元分割模型,但除了少数试图分割感兴趣对象的模型,大多数的方法都是基于低层次手工制作的特征,这些低级的特征(颜色,亮度,对比度,纹理)主要依赖于手工制作,很难捕捉到对象及周围环境的高级语义特征,因此,这些方法并不能很好地从杂乱复杂的背景中区分检测到显著性目标,而且很难适应新的场景,泛化能力较差。
近年来,全卷机神经网络(Fully Convolutional Neural Network,FCN)在显著性检测任务中表现出了很好的效果。FCN具有保存空间信息的能力,在像素级别操作,实现点对点学习和端对端训练的策略。VGG,ResNet等基于FCN的网络相继被提出用于显著性检测。VGG网络体系结构较小,参数较少,基于VGG网络的显著性目标检测模型适合作为各大视觉任务的预处理过程,可同时因为轻小的网络,VGG很难提取到深层次的语义信息;ResNet网络与VGG网络相比性能更好,但网络架构很大,过于消耗计算资源。其它的显著性检测模型大多通过依次叠加卷积层和最大池化层来生成深层特征,这些模型主要关注从最后的卷积层提取到的高级特征的非线性组合,缺乏目标边缘等低级视觉信息,在具有透明物体的场景、前景和背景之间的对比度相似,以及复杂的背景等情况下很难检测显著物体。
发明内容
本发明的目的在于针对现有技术的不足,提供一种基于深监督学习的图像显著性目标检测方法。本发明利用深度监督学习,多尺度细化显著性图像边界,多尺度监督显著性预测结果,优化图像边界信息。
本发明的目的是通过以下技术方案来实现的:一种基于深监督学习的图像显著性目标检测方法,步骤如下:
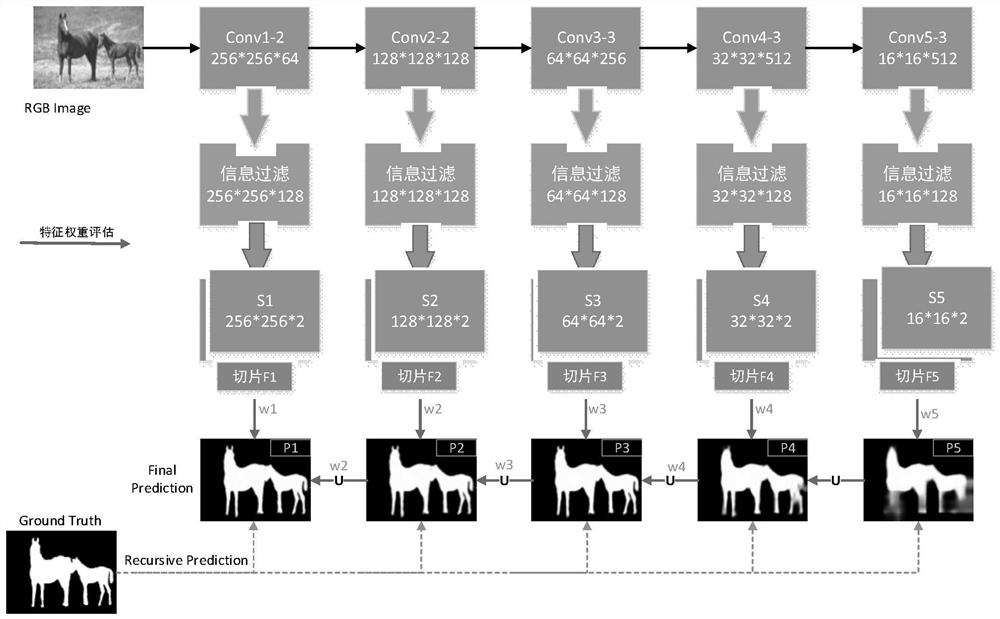
步骤1:修改VGG-16网络,去除VGG-16网络的最后一层池化层和所有的全连接层;
步骤2:将训练图像送入步骤1修改的网络,利用4个下采样层,提取5个不同尺度下的特征图像;
步骤3:递归融合步骤2得到的特征图像,预测得到多级显著性特征图像;
步骤4:将显著性特征的真值图像依次下采样到步骤3得到的多级特征同样的大小;
步骤5:利用步骤3预测的各级显著性特征图,与对应大小的步骤4得到的背景真值图之间的交叉熵损失,联合各级损失函数,得到最终的损失函数;
步骤6:利用损失函数进行端对端的训练,优化显著性图像;
步骤7:将待检测图像输入步骤6训练后的网络,经过步骤2~3的处理,得到对应的最终预测图。
进一步地,步骤1具体实现如下:
对VGG-16网络做了两处修改来适应显著性检测任务:去除VGG-16网络的最后一层池化层,以保留最后一个卷积层的特征信息;此外,去除VGG-16网络中所有的全连接层,以防止特征经过全连接层丢失特征的空间信息。
进一步地,步骤2具体实现如下:
将待测图像S送入改进后的VGG-16网络,经过卷积,信息过滤,提取到5个不同尺度和深度的特征图像,分别为S
进一步地,步骤3具体实现如下:
对多级特征图像进行进行递归融合,每一层的特征图像与上一层的特征图像融合,生成本层次的新预测图:
进一步地,步骤4具体实现如下:
根据步骤3,可以得到4个不同尺度的特定级预测图P
进一步地,步骤5具体实现如下:
利用真值图像T
其中各级损失函数分别是:
其中,l
最终,所有预测的联合损失函数为
本发明的有益效果是:本发明针对图像显著性目标检测存在的特征图像边界模糊,高亮区域不均匀等问题,采用深监督的方法,以此来改善高级特征经过层层卷积网络后丧失物体丰富低级语义信息的问题。将真值图像依次下采样到特征图像同样的大小,来自像素级的信息监督每一层的显著性图像预测,促进预测中的互补效应,联合各级损失函数,端对端训练;得到边界清晰高亮区域均匀的显著性特征图像。
附图说明
图1为算法流程图;
图2为VGG-16网络结构图;
图4为待检测图像示意图;
图5为待检测图像的显著性图像示意图;
图3为使用算法的显著性图像与未使用的对比图。
具体实施方式
下面结合附图,对本发明的具体实施方案作进一步详细描述。
本发明一种基于深监督学习的图像显著性目标检测方法,解决了市面上多尺度显著性检测存在的边界模糊等问题。首先,修改VGG-16网络以适应显著性检测任务,去除网络的最后一层池化层和所有全联接层,利用修改后的VGG-16网络来提取图像的多尺度特征信息,递归融合多尺度特征,得到显著性图像。为了加强图像的边界,将真值图像依次下采样到特征图像同样的大小,来自像素级的信息监督每一层的显著性图像预测,促进预测中的互补效应,递归指导每一层的显著性特征图像,优化边界信息,增强最后的显著性图像效果。
如图1所示,本发明具体步骤如下:
步骤1:修改VGG-16网络,去除VGG-16网络的最后一层池化层和所有的全连接层。
对VGG-16网络做了两处修改来适应显著性检测任务:去除VGG-16网络的最后一层池化层,以保留最后一个卷积层的特征信息;此外,去除VGG-16网络中所有的全连接层,以防止特征经过全连接层丢失特征的空间信息。修改后的VGG-16网络如图2所示,可用来提取5个不同尺度和深度的特征信息。
步骤2:将训练图像送入网络,利用4个下采样层,提取5个不同尺度下的特征图像。
将RGB训练图像S(本实施例中设置大小为256*256*3)送入步骤1改进后的VGG-16网络,经过卷积,信息过滤,提取到5个不同尺度和深度的特征图像,分别为S
步骤3:递归融合特征图像,得到预测的显著性特征图像。
对步骤2得到的多级特征图像S
其中,Up(P
步骤4:将真值图像依次下采样到多级特征同样的大小。
将图像S对应的显著性图像的真值图像T
步骤5:利用各级显著性特征图,与背景真值图之间的交叉熵损失,联合各级损失函数,得到最终的损失函数。
利用真值图像T
其中各级损失函数分别是:
其中,l
最终,所有预测的联合损失函数为
步骤6:利用损失函数进行端对端的训练步骤1改进后的VGG-16网络的权重参数,优化显著性特征图像;得到最后检测到的显著性特征图像与之前没有使用本发明算法的效果对比如图3所示。
步骤7:将待检测图像输入步骤6训练后的改进VGG-16网络,经过步骤2~3的处理,得到对应的最终预测图P
- 基于深监督学习的图像显著性目标检测方法
- 一种基于互补标签融合监督学习的图像显著性检测方法