用于过继性细胞疗法的多肽
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及一种用于过继性细胞疗法(ACT)的多肽。该多肽包含自杀部分,即,使得表达所述多肽的细胞能够被删除的表位。因此,所述多肽提供了一种为细胞提供安全开关的手段,该开关允许细胞被“关闭”或消除。本发明还提供了一种编码这种多肽的核酸、包含这种核酸的细胞以及其治疗用途。
背景技术
遵循早期期待,过继性细胞疗法(ACT)在对抗恶性和传染性疾病的临床应用中正被越来越多地使用和测试。经基因工程化以识别CD19的T细胞已被用于治疗滤泡性淋巴瘤,而使用经基因修饰以表达抗肿瘤T细胞受体的自体淋巴细胞的ACT已被用于治疗转移性黑色素瘤。ACT在黑色素瘤和EBV相关的恶性肿瘤中的成功激发了人们为重新定位效应T细胞来治疗其他肿瘤而努力,并且T细胞已经被工程化来表达具有新特异性的T细胞受体(TCR)或嵌合抗原受体(CAR)。
据报导,CAR修饰的T淋巴细胞已用于B系恶性肿瘤的免疫治疗(Kohn等(2011)Mol.Ther.19:432-438),并且抗GD2 CAR转导的T细胞已用于神经母细胞瘤的治疗(Pule等(2008)Nat.Med.14:1264-1270)。在成人淋巴瘤的CAR临床研究中也报导了显示有疗效的数据,并且用识别黑色素瘤抗原的初始T细胞受体转导的T细胞使播散性黑色素瘤得到了显著缓解。
其他类型的免疫细胞也被用于或被建议用于ACT,包括例如NK细胞,包括被工程化以表达CAR的NK细胞。最近,已经开发出了用于ACT的调节性T细胞(Treg)。Treg具有免疫抑制功能。它们的作用是控制细胞病变的免疫应答,并且对维持免疫耐受性至关重要。Treg的抑制特性可以在治疗上用于例如改善和/或预防炎症性疾病、自身免疫性疾病和移植中的免疫介导的器官损伤。
过继性免疫疗法不断提高的疗效一直与严重不良事件的报告联系在一起。已有输注工程化T细胞后的急性不良事件报导,例如细胞因子风暴。另外,已经发生了慢性不良事件,并且已通过动物模型预测到了其他不良事件。例如,由于碳酸酐酶IX(CAIX)在胆道上皮上的意外表达,重定向到CAIX(由肾癌表达的抗原)的T细胞在数名患者中产生了肝毒性。由于目标抗原在皮肤和虹膜上的表达,抗黑色素瘤的初始T细胞受体转移研究已导致患者出现白癜风和虹膜炎。在初始TCR转移后,小鼠中已有因TCR交叉配对引起的移植物抗宿主病(GvHD)样综合征的报导。在用一些含有共刺激的CAR过继转移后,动物模型中已有淋巴增生性疾病的报导。最后,载体插入突变的风险始终存在。虽然急性毒性可以通过谨慎给药来解决,但慢性毒性可能与细胞剂量无关。
由于工程化T效应细胞可以在给药后扩增并持续数年,并且鉴于患者在施用任何免疫疗法后都存在不良事件的风险,因此希望能纳入一种安全机制,以允许在面临毒性时选择性地删除过继输注的T细胞及其他免疫细胞。
自杀基因使得能够选择性删除体内转导的细胞。有两个自杀基因已接受了临床测试:HSV-TK和iCasp9。单纯疱疹病毒胸苷激酶(HSV-TK)在T细胞中的表达赋予了对更昔洛韦的易感性。HSV-TK的使用仅限于深度免疫抑制的临床环境,比如单倍体相合骨髓移植,因为这种病毒蛋白具有高度免疫原性。进一步地,它排除了使用更昔洛韦来治疗巨细胞病毒。诱导型Caspase 9(iCasp9)可以通过施用小分子药物(AP20187)来激活。iCasp9的使用取决于临床级AP20187的可用性。另外,除了基因工程细胞产物外,使用实验性小分子可能会导致监管问题。
其他自杀基因正在开发中,并且EP-2836511B已经报导了基于抗原CD20的最小表位的构建体,该构建体由裂解抗体利妥昔单抗识别。利妥昔单抗是一种针对蛋白CD20的免疫治疗嵌合单克隆抗体,蛋白CD20主要发现于B细胞表面。当利妥昔单抗与CD20结合时,会触发细胞死亡,因此利妥昔单抗可用于靶向和杀伤表达CD20的细胞。已经开发出了模仿利妥昔单抗识别的表位的肽(所谓的模拟表位),并且这些肽在EP2836511中被用作自杀-标志物联合构建体中的自杀部分,该构建体还包含CD34最小表位作为标志物部分。
具体地,EP-2836511B关注于在单个致密多肽中同时提供自杀部分和标志物部分,并为此目的开发了一种由EP-2836511的SEQ ID NO.4表示的被称为RQR8的多肽。RQR8包含两个环状肽CD20模拟表位(“R”),这些模拟表位位于具有本文SEQ ID NO.1(对应于EP-2836511B的SEQ ID NO.2)序列的特定CD34表位(“Q”)两侧,CD34表位由单克隆抗体QBEnd10识别。这很重要,因为QBEnd10抗体用于Miltenyi CliniMACS磁性细胞选择系统,该系统被广泛用于临床环境中的细胞分离。因此,将Q表位包含作为标志物使已经修饰的细胞能够表达易于使用常见选择系统选择出的该多肽。关键性地,多肽中的R表位和Q表位通过间隔序列(“S”)根据以下通式相互分离:St-R1-S1-Q-S2-R2。已讨论过组合长度需要至少10个氨基酸(其是特定构建体RQR8中的14个氨基酸)的间隔序列S1和S2与Q相结合对于保持R1和R2表位在正确距离的重要性,这样多肽不能同时与利妥昔单抗的两个抗原结合位点结合,从而确保多肽能够有效诱导细胞死亡。特别指出,R1与R2之间的距离可以超过
对用于ACT的改进或替代性自杀构建体的需求仍在继续,包括不限于使用QBEnd10CD34标志物系统的构建体,而本发明就是针对这一需求。
发明内容
特别地,在开发本发明中,本发明人已经意识到CD20表位(R表位)之间的物理距离或间距并不像EP-2836511B所认为的那样关键或重要。特别地,本发明人已经确定,防止两个R表位与同一利妥昔单抗分子结合可以通过关注于分离它们的序列的灵活性来实现,而不仅仅是物理距离(即,分离它们的序列的长度)。因此,本发明人已经表明,实际上可以产生功能性自杀多肽,在该多肽中,R表位被比EP-2836511B中所需的那些序列短得多的序列分离。进一步地,通过R表位之间不包含标志物,可以去除对多肽设计的约束,并且可以使用范围广得多的不同接头序列来将自杀多肽构建体的R表位联结在一起并使其分离。与仅限于使用Miltenyi CliniMACS系统的那些相比,这样的多肽可以在更广泛的细胞修饰方案和应用中找到实用性。特别地,本发明人发现,通过增加分离两个R表位的序列的灵活性,构建体诱导细胞裂解的能力,特别是构建体对利妥昔单抗或其生物仿制药的敏感性也增加了,并且本发明进一步包括了具有高细胞耗竭能力的改进构建体的开发。具体地,使用具有增强的利妥昔单抗敏感性的构建体可以在出现不良反应的情况下减少对患者所需施用的利妥昔单抗的量。
因此,在第一方面,本发明提供了一种多肽,该多肽包含具有下式的序列:
R1-L-R2-St
其中
R1和R2是利妥昔单抗结合表位;
St是茎序列,当该多肽在靶细胞的表面表达时,该茎序列导致R1表位和R2表位从细胞表面伸出;以及
L是将R1的C末端连接到R2的N末端的柔性接头序列,并且该柔性接头序列不包含QBEnd10结合表位,该QBEnd10结合表位包含SEQ ID NO.1所示的序列。
更具体地,L可以选自:
(i)柔性接头序列,该柔性接头序列具有不超过25个氨基酸的长度,优选不超过24个、23个、22个或21个氨基酸的长度;和/或
(ii)接头序列,该接头序列包含至少40%的甘氨酸残基或甘氨酸和丝氨酸残基;和/或
(iii)接头序列,该接头序列包含丝氨酸残基和/或甘氨酸残基,和不超过15个其他氨基酸残基,优选不超过14个、13个、12个、11个、10个、9个、8个、6个、7个、5个或4个其他氨基酸残基;和/或
(iv)接头序列,该接头序列具有氨基酸序列,其中至少80%、90%或100%的氨基酸残基为丝氨酸残基、甘氨酸残基、苏氨酸残基、丙氨酸残基、赖氨酸残基和谷氨酸残基;和/或
(v)接头序列,该接头序列具有不包含任何脯氨酸残基的氨基酸序列。
因此,替代地定义,本发明的该方面可以看作是提供了一种多肽,该多肽包含具有下式的序列:
R1-L-R2-St
其中,
R1和R2是利妥昔单抗结合表位;
St是茎序列,当该多肽在靶细胞的表面表达时,该茎序列导致R1表位和R2表位从细胞表面伸出;以及
L是将R1的C末端连接到R2的N末端的柔性接头序列,其中L选自:
(i)柔性接头,该接头不包含具有SEQ ID NO.1所示序列的QBEnd10结合表位;和/或
(i)柔性接头序列,该柔性接头序列具有不超过25个氨基酸的长度,优选不超过24个、23个、22个或21个氨基酸的长度;和/或
(ii)接头序列,该接头序列包含至少40%的甘氨酸残基或甘氨酸和丝氨酸残基;和/或
(iii)接头序列,该接头序列包含丝氨酸残基和/或甘氨酸残基,和不超过15个其他氨基酸残基,优选不超过14个、13个、12个、11个、10个、9个、8个、6个、7个、5个或4个其他氨基酸残基;和/或
(iv)接头序列,该接头序列具有氨基酸序列,其中至少80%、90%或100%的氨基酸残基为丝氨酸残基、甘氨酸残基、苏氨酸残基、丙氨酸残基、赖氨酸残基和谷氨酸残基;和/或
(v)接头序列,该接头序列具有不包含任何脯氨酸残基的氨基酸序列。
更具体地,本发明的多肽可以具有式R1-L-R2-St。
多肽可以与如编码TCR或CAR的基因等的治疗性转基因共表达。
在实施方案中,接头L不含标志物。然而,不排除多肽包含标志物。在一个实施方案中,所述多肽可以包含除在L中的标志物。在另一实施方案中,所述多肽不含标志物。在另一实施方案中,所述多肽可以与标志物共表达。
所述多肽可以包含SEQ ID NO.27所示的序列或其变体,该变体与SEQ ID NO.27所示的序列具有至少80%的同一性,并且该变体(i)与利妥昔单抗结合和(ii)当在细胞表面表达时,在利妥昔单抗存在下诱导杀伤该细胞。
在第二方面,本发明提供了一种融合蛋白,该融合蛋白包含本文定义的本发明的多肽和多肽融合配偶体,例如本文定义的任选地通过接头序列连接到多肽融合配偶体的本发明的多肽。融合配偶体可以是目标蛋白质(POI)。
POI可以是抗原受体,例如嵌合受体(比如嵌合抗原受体(CAR)或T细胞受体(TCR))、或标志物。
所述融合蛋白可以包含多肽与融合配偶体(例如目标蛋白质)之间的自剪切肽。
在一个实施方案中,本发明的多肽可以包含在多肽融合配偶体(例如POI)内。换言之,所述多肽可以在融合配偶体中融合或联结。在这方面来说,本发明的多肽可以例如包含在CAR内,例如CAR的胞外结构域内。因此,CAR可以包含胞外结构域,该胞外结构域包含抗原靶向部分,例如scFv和本发明的多肽。
在第三方面,本发明提供了一种核酸分子,该核酸分子包含能够编码如本文所定义的根据本发明的多肽或融合蛋白的核苷酸序列。
在第四方面,本发明提供了一种载体,该载体包含如本文所定义的本发明的核酸分子。
所述载体还可以包含另一编码序列或其他目标核苷酸序列。例如,其可以包含代表目标转基因的核苷酸序列,该核苷酸序列可以在一个实施方案中编码目标蛋白质,例如嵌合抗原受体或T细胞受体或标志物。
在第五方面,本发明提供了一种细胞,该细胞表达如本文所定义的本发明的多肽。
还提供了一种细胞,该细胞包含如本文所定义的核酸分子或载体。
所述细胞可以在细胞表面共表达所述多肽和POI。
所述细胞可以是免疫细胞或其前体,比如多能干细胞(PSC)、例如iPSC,特别是T细胞、NK细胞、树突状细胞或骨髓源性抑制细胞(MDSC),例如Treg细胞,该细胞包括衍生自前体的这样的细胞,以及原代细胞和细胞系。
在第六方面,本发明提供了一种用于制造根据本发明第五方面的细胞的方法,该方法包括将根据本发明第四方面的载体引入细胞(例如用该载体转导或转染细胞)的步骤。
在第七方面,本发明提供了一种用于删除根据本发明第五方面的细胞的方法,该方法包括将细胞暴露于具有利妥昔单抗的结合特异性的抗体的步骤。在一个方面,所述方法可以是一种体外方法。
替代地看,本发明的该方面可以包括具有利妥昔单抗的结合特异性的抗体用于治疗已施用了如本文所定义的本发明的细胞的受试者,以删除所述细胞。
更进一步地根据该方面,本发明提供了一种试剂盒或组合产品,该试剂盒或组合产品包含(a)如本文所定义的本发明的多核苷酸、载体或细胞和(b)具有利妥昔单抗的结合特异性的抗体。所述试剂盒或产品可以用于ACT。特别地,所述试剂盒或产品可以用于通过ACT使用所述细胞或制造供使用的本发明的细胞来治疗受试者,然后从所述受试者删除所述细胞。在施用所述细胞后(例如在一段时间后)或如果受试者表现出不想要的或有害的细胞治疗症状或效果,可以向受试者施用所述抗体。
在一个实施方案中,所述抗体可以是利妥昔单抗。
在第八方面,本发明提供了一种用于治疗受试者中疾病的方法,该方法包括向所述受试者施用根据本发明第五方面的细胞的步骤。所述受试者可以是需要治疗的受试者,而细胞可以以对受试者治疗有效的量被施用。
替代地定义,该方面可以涉及一种通过ACT治疗受试者的方法或一种受试者的ACT方法。
所述方法可以包括以下步骤:
(i)将根据本发明第四方面的载体引入细胞样本(例如,从受试者分离或从供体获得的细胞样本)中(例如,通过用所述载体转导或转染所述细胞),以及
(ii)将包含所述载体的细胞施用于所述受试者(例如,在自体细胞的情况下,将细胞返回到所述受试者)。
该方法可以包括向所述受试者施用具有利妥昔单抗的结合特异性的抗体的进一步步骤。
在第九方面,本发明提供了一种用于治疗的根据本发明第五方面的细胞。
在第十方面,本发明提供了一种用于通过过继性细胞转移来治疗的根据本发明第五方面的细胞。
所述方法或用途可以用于治疗癌症或者感染性或神经退行性疾病或用于免疫抑制。
附图说明
图1:
图2:
图3:
图4:
图5:
具体实施方式
本发明提供了一种多肽,当在细胞表面表达时,该多肽可以用作自杀构建体。这可以用作安全机制或安全开关,其允许在需要出现时,或者实际上更一般地,根据期望或需要,例如一旦细胞已经执行或完成其治疗效果(例如,一旦治疗性转基因被表达),就删除施用的细胞。
该多肽包含自杀部分。自杀部分具有导致细胞死亡的诱导能力。自杀部分的实例是由自杀基因编码的自杀蛋白,该自杀基因可以包含在用于表达所需转基因的载体中,当表达时,其允许细胞被删除以关闭转基因的表达。
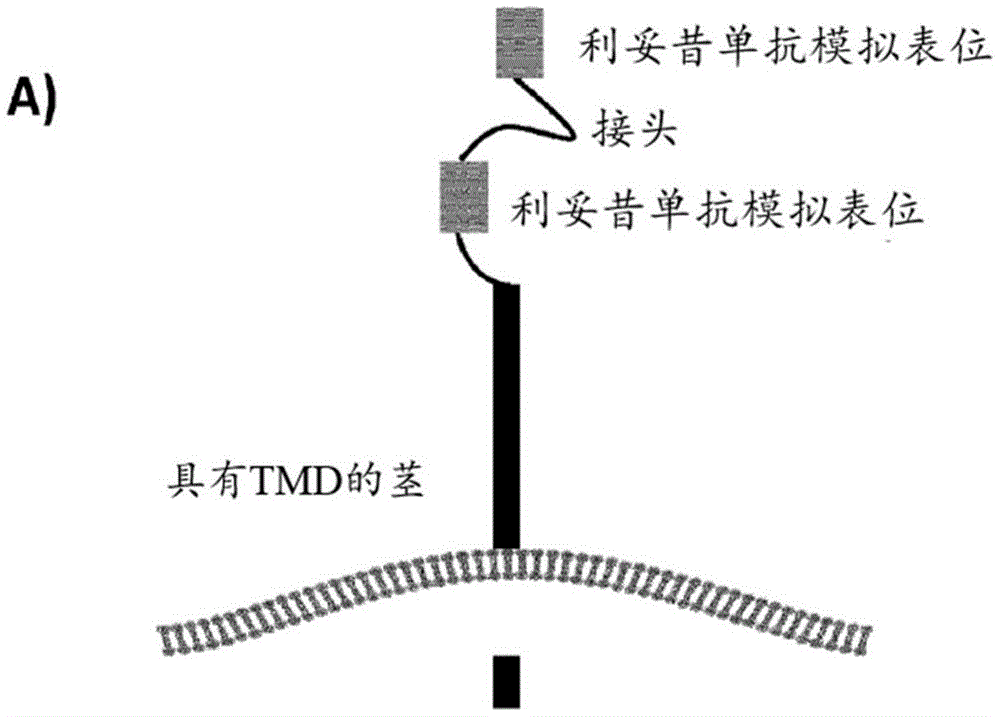
在所述多肽中,自杀部分包含基于由抗体利妥昔单抗识别的CD20的表位的最小表位。更具体地,该多肽包含由柔性接头L隔开的两个CD20表位R1和R2。
表达包含该序列的多肽的细胞可以使用抗体利妥昔单抗或具有利妥昔单抗的结合特异性的抗体选择性地杀伤。在例如逆转录病毒转导自杀多肽的编码序列后,自杀多肽在细胞表面上稳定表达。当表达的多肽暴露于或接触利妥昔单抗或具有相同结合特异性的抗体时,细胞死亡随之发生。
逆转录病毒转导是将核酸引入哺乳动物细胞中的一种常见方式,特别是用于治疗。然而,逆转录病毒载体有包装限制,并且一般需要保持引入的核酸的大小尽可能小。虽然可以使用单独的载体来将自杀基因和所需的转基因引入细胞中,但是在同一载体中引入转基因和自杀基因两者可能是需要的或方便的。通过提供包含连接两个R表位的柔性接头的多肽,多肽的长度可以变化,并且可以提供短的但柔性的接头。这可以允许将与多肽共表达的转基因的大小有更大的自由度。
根据一个方面或在一个实施方案中,本发明的多肽的接头序列L不包含QBEnd10结合表位,该表位包含SEQ ID NO.1所示的氨基酸序列。可替代地定义,本发明的多肽的接头序列L不包含QBEnd10结合表位,该表位包含SEQ ID NO.1所示的氨基酸序列或其变体,该变体保留QBEnd10结合活性。在其他实施方案中,所述多肽不包含QBEnd10结合表位,该表位包含SEQ ID NO.1所示的氨基酸序列或其变体,该变体保留QBEnd10结合活性。
SEQ ID NO.1具有16个氨基酸序列:ELPTQGTFSNVSTNVS。抗体QBEnd10可以从各种来源获得,包括Abcam、ThermoFisher、Santa Cruz Biotechnology和Bio-Rad。该抗体的详细信息可从EP3243838A1和Chia-Yu Fan等(Biochem Biophys Rep,2017年3月,9:51-60)获得。
进一步地,在一个实施方案中,所述多肽或其接头序列L不包括或包含衍生自CD34的表位。在另一个实施方案中,所述多肽或其接头序列L不包括或包含最小CD34表位。
变体QBEnd10结合表位可以包含对SEQ ID NO.1的序列进行序列修饰,只要修饰后的序列保留至少80%的序列同一性。只要保留表位的QBEnd10结合活性,就可以基于残基的极性、电荷、溶解度、疏水性、亲水性和/或两亲性的相似性进行有意的氨基酸取代。例如,带负电的氨基酸包括天冬氨酸和谷氨酸;带正电的氨基酸包括赖氨酸和精氨酸;具有相似亲水性值的不带电极性头基的氨基酸包括亮氨酸、异亮氨酸、缬氨酸、甘氨酸、丙氨酸、天冬酰胺、谷氨酰胺、丝氨酸、苏氨酸、苯丙氨酸和酪氨酸。一般地,可以进行保守取代。与SEQ IDNO.1所示的序列相比,QBEnd10结合表位可以例如包含5个或更少、4个或更少、3个或更少、2个或更少或1个氨基酸突变。QBEnd10结合表位可以由SEQ ID NO.1所示的序列或其变体组成,该变体保留QBEnd10结合活性。
本发明的多肽的接头序列是柔性接头序列。柔性接头是本领域中公知和描述的一类接头序列。接头序列一般被称为序列,其可以用来连接蛋白质或蛋白质结构域或者将蛋白质或蛋白质结构域连在一起,以产生例如融合蛋白或嵌合蛋白、或多功能蛋白或多肽。它们可以具有不同的特性,并且例如可以是柔性的、刚性的或可剪切的。例如,Chen等(2013,Advanced Drug Delivery Reviews 65,1357-1369)对蛋白接头进行了综述,该综述比较了柔性接头的类别与刚性和可剪切接头的类别。Klein等(2014,Protein EngineeringDesign and Selection,27(10),325-330)、van Rosmalen等(2017,Biochemistry,56,6565-6574)以及Chichili等(2013,Protein Science,22,153-167)也对柔性接头进行了描述。
柔性接头是允许连接的结构域或成分之间有一定程度移动的接头。柔性接头一般由小的非极性氨基酸残基(例如,甘氨酸)或极性氨基酸残基(例如,丝氨酸或苏氨酸)组成。氨基酸的小尺寸提供了灵活性,并且允许连接部分(结构域或成分)的活动性。极性氨基酸的掺入可以通过与水分子形成氢键来维持接头在水相环境中的稳定性。
最常用的柔性接头具有主要由丝氨酸残基和甘氨酸残基组成的序列(所谓的“GS接头”)。然而,许多其他柔性接头也被描述过(例如,参见Chen等,2013,同前),这些接头可以包含额外的氨基酸,比如苏氨酸和/或丙氨酸,和/或可以提高溶解度的赖氨酸和/或谷氨酸。可以使用本领域中已知和报导过的任何柔性接头。
虽然接头的长度并不是关键的,但在一些实施方案中,可能希望具有较短的接头序列。例如,接头序列可以具有不超过25个氨基酸的长度,优选不超过24个、23个、22个或21个氨基酸的长度。
在其他实施方案中,可能需要更长的接头序列,例如由GS结构域的多个重复组成或包含GS结构域的多个重复的接头序列。
在一些实施方案中,所述接头的长度可以是2个、3个、4个、5个或6个氨基酸中的任何一个至24个、23个、22个或21个氨基酸中的任何一个。在其他实施方案中,所述接头的长度可以是2个、3个、4个、5个或6个氨基酸中的任何一个至21个、20个、19个、18个、17个、16个或15个氨基酸中的任何一个。在其他实施方案中,所述接头的长度可以介于这些范围之间,例如,6-21、6-20、7-20、8-20、9-20、10-20、8-18、9-18、10-18、9-17、10-17、9-16、10-16等。因此,所述接头的长度可以在由上文列出的任何整数组成的范围内。
使用GS接头或者更具体地接头中的GS(“甘氨酸-丝氨酸”)结构域可以允许通过改变GS结构域重复的数量来容易地改变接头的长度,因此,这样的接头代表根据本发明的一类优选的接头。然而,柔性接头不限于基于“GS”重复的接头,并且已报导过(包括在Chen等,同前)分散在整个接头序列中的包含丝氨酸残基和甘氨酸残基的其他接头。
因此,在一个实施方案中,所述接头序列可以包含至少40%的甘氨酸残基或甘氨酸和丝氨酸残基。
在另一实施方案中,所述接头序列可以包含丝氨酸残基和/或甘氨酸残基,和不超过15个其他氨基酸残基,优选不超过14个、13个、12个、11个、10个、9个、8个、6个、7个、5个或4个其他氨基酸残基。应当理解“其他”氨基酸残基可以是任何不是丝氨酸或甘氨酸的氨基酸。
接头中的脯氨酸残基往往会赋予刚性,因此在一个实施方案中,所述接头序列不包含任何脯氨酸残基。然而,这不是绝对的,因为根据序列背景,柔性接头序列可以包含一个或多个脯氨酸残基。
在一个优选的实施方案中,所述接头序列包含至少一个仅由丝氨酸残基和甘氨酸残基组成的甘氨酸-丝氨酸结构域。在这样的实施方案中,所述接头可以包含不超过15个其他氨基酸残基,优选不超过14个、13个、12个、11个、10个、9个、8个、6个、7个、5个或4个其他氨基酸残基。
甘氨酸-丝氨酸结构域可以具有下式:
(S)q-[(G)m-(S)m]n-(G)p
其中q是0或1;m是1到8的整数;n是至少为1(例如1-8或更具体地1-6)的整数;p是0或者1到3的整数。
更具体地,甘氨酸-丝氨酸结构域可以具有下式:
(i)S-[(G)m-S]n;
(ii)[(G)m-S]n;或
(iii)[(G)m-S]n-(G)p,
其中m是2到8(例如3到4)的整数;n是至少为1(例如1-8或更具体地1-6)的整数;并且p是0或者1到3的整数。
在一个代表性实例中,甘氨酸-丝氨酸结构域可以具有下式:
S-[G-G-G-G-S]n
其中n是至少为1(优选地1-8、或1-6、1-5、1-4、或1-3)的整数。在上式中,序列GGGGS是SEQ ID NO.31。
接头序列可以仅由上文所描述或定义的一个或多个甘氨酸-丝氨酸结构域构成或由上文所描述或定义的一个或多个甘氨酸-丝氨酸结构域组成。然而,如上文提到的,在另一实施方案中,接头序列可以包含一个或多个甘氨酸-丝氨酸结构域和额外的氨基酸。这些额外的氨基酸可以在甘氨酸-丝氨酸结构域的一端或两端,或者在一段重复的甘氨酸-丝氨酸结构域的一端或两端。因此,可以是其他氨基酸的额外的氨基酸可以位于接头序列的一端或两端,例如这些氨基酸可以位于甘氨酸-丝氨酸结构域的两侧。在其他实施方案中,额外的氨基酸可以位于甘氨酸-丝氨酸结构域之间。例如,两个甘氨酸-丝氨酸结构域可以位于接头序列中一段其他氨基酸的两侧。进一步地,还是如上文提到的,在其他接头中,GS结构域不需要重复,并且G残基和/或S残基或者如GS等的短结构域可以简单地沿(例如如下面的SEQ ID NO.41所示的)长度或序列分布。
下面列出了代表性的示例性接头序列:
ETSGGGGSRL(SEQ ID NO.32)
SGGGGSGGGGSGGGGS(SEQ ID NO.33)
S(GGGGS)
(GGGGS)
S(GGGS)
(GGGS)
S(GGGGGS)
(GGGGGS)
S(GGGGGGS)
(GGGGGGS)
G
G
KESGSVSSEQLAQFRSLD(SEQ ID NO.39)
EGKSSGSGSESKST(SEQ ID NO.40)
GSAGSAAGSGEF(SEQ ID NO.41)
SGGGGSAGSAAGSGEF(SEQ ID NO.42)
SGGGLLLLLLLLGGGS(SEQ ID NO.43)
SGGGAAAAAAAAGGGS(SEQ ID NO.44)
SGGGAAAAAAAAAAAAAAAAGGGS(SEQ ID NO.45)
SGALGGLALAGLLLAGLGLGAAGS(SEQ ID NO.46)
SLSLSPGGGGGPAR(SEQ ID NO.47)
SLSLSPGGGGGPARSLSLSPGGGGG(SEQ ID NO.48)
GSSGSS(SEQ ID NO.49)
GSSSSSS(SEQ ID NO.50)
GGSSSS(SEQ ID NO.51)
GSSSSS(SEQ ID NO.52)
SGGGGS(SEQ ID NO.53。
在多肽中,接头的功能是将R1连接到R2。接头直接连接R1和R2,即将R1的C末端连接到R2的N末端。除接头序列L外,多肽在R1和R2之间不包含任何其他成分或序列。应当理解,由于多肽要表达在细胞表面上,并且由于R1连接到R2,所以R1和R2都要表达在细胞表面上,因此接头L不是可剪切接头。
在一个实施方案中,所述接头不执行任何其他功能,也不包含任何其他功能性成分或序列。例如,所述接头序列不具有或者不包含具有生物活性的任何序列。在一个实施方案中,所述接头不包含标志物序列。
尽管如上文所定义的本发明的多肽的接头序列是柔性序列,但是本公开还包含其他多肽,包括包含非柔性接头的多肽和/或不符合上文所列的定义和要求的多肽。
因此,在其他方面,提供了具有下式的多肽:
R1-L-R2-St
其中
R1和R2是利妥昔单抗结合表位;
St是茎序列,当该多肽在靶细胞的表面表达时,该茎序列导致R1表位和R2表位从细胞表面伸出;以及
L是将R1的C末端连接到R2的N末端的接头序列,并且该接头序列(i)不包含QBEnd10结合表位,该QBEnd10结合表位包含SEQ ID NO.1所示的序列和/或(ii)具有不超过25个氨基酸的长度,优选不超过24个、23个、22个或21个氨基酸的长度。
R1、R2和St可以如本文其他地方所定义和描述的。接头L可以是任何接头序列,即具有受上文约束条件(i)和(ii)约束的任何氨基酸序列的接头序列(并且该接头序列是不可剪切的)。
这样的接头序列的实例包括:
SGGGSNVSTNVSPAKPTTTA(SEQ ID NO.64)
SGGGSELPTQGTFSNVSTNA(SEQ ID NO.65)
EAAAKEAAAKEAAAKEAAAK(SEQ ID NO.66)
GGGGSEAAAKEAAAKSGGGS(SEQ ID NO.67)
EAAAKEAAAKEAAAK(SEQ ID NO.68)
GGLKNKAQQAAFYIGG(SEQ ID NO.69)
LCKNKAQQAAFYCI(SEQ ID NO.70)
KCLNDAQAAAEECI(SEQ ID NO.71)
GGGLKNKAQQAAFYIGGG(SEQ ID NO.72)
EAAAKEAAAKEAAAKEAAAEAAAKE(SEQ ID NO.73)
GGGSEAAAKEAAAKEAAAKEGGGS(SEQ ID NO.74)。
利妥昔单抗结合表位是与抗体利妥昔单抗或具有利妥昔单抗的结合特异性的抗体(换言之,是与利妥昔单抗一样结合相同的天然表位的抗体)结合的氨基酸序列。利妥昔单抗是一种与人CD20结合的嵌合小鼠/人单克隆κIgG1抗体。来自CD20的利妥昔单抗结合表位序列是CEPANPSEKNSPSTQYC(SEQ ID NO.29)。
利妥昔单抗在EP0669836(杂交瘤)中被首次描述,而重链序列和轻链序列在EP2000149中给出(另见参见Wang等,Analyst,2013年,138,3058,在其图1中给出了重链序列和轻链序列以及利妥昔单抗——CAS 17422-31-7,目录号:B0084-061043,BOCSciences)。也可以参考US 2009/0285795 A1、EP 1633398 A2和WO 2005/000898。利妥昔单抗及其生物仿制药是从世界各地的各种商业来源可广泛获得的。
因此,R1和R2可以是与利妥昔单抗结合的,或者换言之,是能够与利妥昔单抗结合的任何肽。除了CD20背景下的天然表位外,已知并报导了与利妥昔单抗结合的各种肽,或者更具体地说,模仿该天然表位的各种肽。因此,R1和R2可以是利妥昔单抗表位的模拟表位。
例如,Perosa等(2007年,Immunol,179:7967-7974)描述了这样的模拟表位,其中公开了一系列半胱氨酸约束的7-mer环状肽,该环状肽具有利妥昔单抗识别的抗原基序,但有不同的基序周围氨基酸。Perosa描述了SEQ ID NO.15至SEQ ID NO.25的11个肽,如下表1所示。在该表中,基序两侧的氨基酸以小写示出,而基序则以大写示出。已确定,可以从肽中去除首位氨基酸“a”,并且可以保留功能性表位(或模拟表位)。表1中还示出了缺失首位“a”的SEQ ID NO.4至SEQ ID NO.14的肽。
表1
可以用作根据本发明的R1和/或R2的利妥昔单抗表位的圆环状(或环状)模拟表位可以用SEQ ID NO.2的共有氨基酸序列表示:
X1-C-X2-X3-(A/S)-N-P-S-X4-C
其中X1是A或缺失,并且X2、X3和X4是任意氨基酸。
更具体地,X2可以是选自P、N、S、M、W或E的氨基酸;X3可以是选自Y、F、W、A或H的氨基酸;而X4可以是选自L、T、M或Q的氨基酸。
还开发了利妥昔单抗表位的非圆环状(或非环状)肽模拟表位。Li等(2006,CellImmunol,239:136-43)也描述了利妥昔单抗的模拟表位,包括序列为QDKLTQWPKWLE(SEQ IDNO.3)的肽。
多肽可以包含利妥昔单抗结合表位R1和R2,这些表位各自独立地包含选自由SEQID NO.2、SEQ ID NO.3或SEQ ID NO.4至SEQ ID NO.25组成的组的氨基酸序列或其保留了利妥昔单抗结合活性的变体。
这两个表位R1和R2可以是相同的或不同的。在一个实施方案中,它们是相同的。在另一实施方案中,它们是不同的。
在一个实施方案中,R1和R2各自基本上或者各自替代地由选自由SEQ ID NO.2至SEQ ID NO.25组成的组的氨基酸序列或其保留了利妥昔单抗结合活性的变体组成。
在一个代表性的实施方案中,多肽可以包含利妥昔单抗结合表位R1和R2,这些表位包含、基本上由或由SEQ ID NO.5或SEQ ID NO.16所示的氨基酸序列或其保留了利妥昔单抗结合活性的变体组成。
在一个实施方案中,R1由或基本上由SEQ ID NO.16组成,或者包含SEQ ID NO.16,并且R2由或基本上由SEQ ID NO.5组成,或者包含SEQ ID NO.5。
变体利妥昔单抗结合表位可以基于选自由SEQ ID NO.3至SEQ ID NO.25组成的组的序列,但包含一个或多个氨基酸突变(比如相对于序列的氨基酸插入、取代或删除),但前提是表位保留了利妥昔单抗结合活性。特别地,该序列可以在一个或两个末端被截短例如一个或两个氨基酸。
只要保留表位的利妥昔单抗结合活性,就可以基于残基的极性、电荷、溶解度、疏水性、亲水性和/或两亲性的相似性进行有意的氨基酸取代。例如,带负电的氨基酸包括天冬氨酸和谷氨酸;带正电的氨基酸包括赖氨酸和精氨酸;具有相似亲水性值的不带电极性头基的氨基酸包括亮氨酸、异亮氨酸、缬氨酸、甘氨酸、丙氨酸、天冬酰胺、谷氨酰胺、丝氨酸、苏氨酸、苯丙氨酸和酪氨酸。
可以进行保守取代,例如根据下表2进行取代:
表2
第二列中同一表块中的氨基酸和第三列中同一行中的氨基酸可以相互取代:
与选自由SEQ ID NO.3至SEQ ID NO.25组成的组中的序列相比,利妥昔单抗结合表位可以例如包含3个或更少、2个或更少或1个氨基酸突变。
利妥昔单抗结合表位的变体可以包含或由与SEQ ID NO.3至SEQ ID NO.25中的任何一个具有至少75%的序列同一性的氨基酸序列,更具体地,与其具有至少80%、85%、90%、95%、96%、97%、98%或99%的序列同一性的氨基酸序列组成。
若使用两个相同(或相似)的利妥昔单抗结合氨基酸序列,则使用不同的核苷酸序列来编码两个R表位可能是有利的。在许多表达系统中,同源序列会导致不期望的重组事件。利用遗传密码的简并性,替代密码子可以用于实现核苷酸序列变异而不改变蛋白质序列,从而防止同源重组事件。
多肽包含茎序列(St),当该多肽在靶细胞的表面表达时,该茎序列导致R表位和Q表位从该靶细胞表面伸出。
茎序列使R表位和Q表位与细胞表面保持足够的距离,以便于例如利妥昔单抗或等效抗体的结合。
茎序列从细胞表面提升表位。
茎序列可以是基本上线性的氨基酸序列。茎序列可以足够长,以拉开R表位和Q表位与靶细胞表面的距离,但不能太长,以免茎序列的编码序列影响载体包装和转导效率。茎序列的长度可以例如在30个到100个氨基酸之间。茎序列的长度可以约为40-50个氨基酸。
茎序列可以被高度糖基化。
茎序列可以包括一个接头序列,该接头序列将茎序列连接或连结到上述式中的表位R2。
已知有许多蛋白质,这些蛋白质在哺乳动物细胞的表面表达,并且可以用于为本文的茎序列提供基础或用作其基础。这样的表面表达的蛋白质包含能够用作茎序列或能够衍生茎序列的天然序列。例如,这种蛋白质的胞外结构域(ECD)可以用作茎序列、或胞外结构域和跨膜(TM)结构域、或具有胞内结构域(ICD)的胞外结构域和跨膜结构域(ECD和TMD),可以用作细胞内锚以将茎保持在膜中并允许茎从细胞表面伸出。
这样的蛋白质包括CD27、CD28、CD3ε、CD3z、CD45、CD4、CD5、CD8、CD9、CD16、CD18、CD22、CD33、CD37、CD64、CD80、CD86、CD134、CD137、CD152、CD154、CD278、CD279、IgG1或IgG2。
因此,茎序列St可以包含将其连接到R2的任选接头序列、胞外结构域、任选跨膜结构域和任选胞内结构域。
在一个实施方案中,茎序列可以包含将其连接到R2的接头序列、胞外结构域、跨膜结构域和胞内结构域。
茎序列或其胞外结构域可以包含以下序列或长度约等于以下序列:
PAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACD(SEQ ID NO.30),
该序列是CD8的胞外序列。
如上文提到的,茎序列可以另外包含跨膜结构域、任选地连同胞内结构域一起,其可以用作胞内锚定序列。跨膜结构域和胞内结构域可以衍生自与胞外结构域相同的蛋白质,或者它/它们可以衍生自不同的蛋白质。跨膜结构域和胞内结构域可以是可从CD8衍生的。
茎序列St可以包含衍生自CD8的胞外茎序列、跨膜结构域和胞内结构域。
包含跨膜结构域和胞内锚的CD8茎序列可以具有以下序列:
或与其具有至少75%,特别地至少80%、85%、90%、95%、96%、97%、98%或99%的序列同一性的序列。
在这个序列中,下划线部分对应于CD8a茎;中心部分对应于跨膜结构域;而粗体部分对应于胞内结构域。
茎序列中的接头序列可以是上文所描述的接头。特别地,该接头序列可以是包含或由丝氨酸(S)残基和/或甘氨酸(G)残基组成的接头序列。接头序列可以是基本线性的。在茎的背景下,接头序列可以是较短的序列。例如,接头序列可以具有以下通式:
S-(G)n-S
其中n是2与8之间的数字。
接头可以包含或由序列SGGGGS(SEQ ID NO.53)组成。
本发明多肽的代表性的示例性实施方案包括含SEQ ID NO.5和/或SEQ ID NO.16的利妥昔单抗结合表位的多肽,该多肽经由接头连接到包含衍生自CD8的胞外序列、跨膜序列和胞内序列的茎序列。特别地,茎序列可以具有SEQ ID NO.26的序列。R1与R2之间的接头L可以是上文SEQ ID NO.32至SEQ ID NO.53的任何接头或基于其的任何接头。特别地,接头L可以具有上文SEQ ID NO.32或SEQ ID NO.33中所列的序列。
茎序列可以包含连接到R2的接头序列。茎中的接头序列可以是SGGGS(SEQ IDNO.53)。
因此,本发明的多肽可以包含或由SEQ ID.NO.27、SEQ ID NO.28、SEQ ID NO.78或SEQ ID NO.79所示的氨基酸序列,或与其具有至少75%,特别地至少80%、85%、90%、95%、96%、97%、98或99%的序列同一性的序列组成。
CPYSNPSLCETSGGGGSRLCPYSNPSLCSGGGGSPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCNHRNRRRVCKCPRPVV(SEQID NO.27)
CPYSNPSLCETSGGGGSRLCPYSNPSLCSGGGGSPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCNHRNRRRVCKCPRPVV(SEQID NO.28)
ACPYSNPSLCETSGGGGSRLCPYSNPSLCSGGGGSPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCNHRNRRRVCKCPRPVV(SEQ ID NO.78)
ACPYSNPSLCSGGGGSGGGGSGGGGSCPYSNPSLCSGGGGSPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCNHRNRRRVCKCPRPVV(SEQ ID NO.79)
多肽还可以包含氨基末端的信号肽或与氨基末端的信号肽表达。本领域已知并报导了许多不同的信号序列,而选择信号肽将成为常规事项。信号肽可以例如包含或由SEQID NO.54或SEQ ID NO.80所示的序列组成。
MGTSLLCWMALCLLGADHADA(SEQ ID NO.54)
MGTSLLCWMALCLLGADHAD(SEQ ID NO.80)
包含SEQ ID NO.54的信号肽和SEQ ID NO.27的氨基酸序列的多肽由SEQ IDNO.55表示。还可以看到,SEQ ID NO.55表示包含SEQ ID NO.80的信号肽和SEQ ID NO.78的氨基酸序列的多肽。包含SEQ ID NO.54的信号肽和SEQ ID NO.28的氨基酸序列的多肽由SEQ ID NO.56表示。还可以看到,SEQ ID NO.56表示包含SEQ ID NO.80的信号肽和SEQ IDNO.79的氨基酸序列的多肽。
一旦多肽被靶细胞(即其中引入包含编码多肽的核苷酸序列的核酸分子的细胞)表达,信号肽就会被剪切掉,从而产生成熟的多肽产品。
本发明的多肽可以包含或由SEQ ID NO.27或SEQ ID NO.28或者SEQ ID NO.78或SEQ ID NO.79所示的序列的变体组成,所述变体与SEQ ID NO.27或SEQ ID NO.28或者SEQID NO.78或SEQ ID NO.79所示的序列具有至少75%(例如至少80%、85%、90%或95%)的同一性,只要该变体保留了SEQ ID NO.27或SEQ ID NO.28或者SEQ ID NO.78或SEQ IDNO.79多肽的功能活性。例如,变体序列应当(i)结合利妥昔单抗和(ii)当在细胞的表面表达时,在利妥昔单抗存在下诱导杀伤细胞。
同源性比较可以通过眼睛或用现成的序列比较程序(比如GCG WisconsinBestfit软件包)进行。
在一个实施方案中,多肽仅由上文所列的和所描述的元件R1、L、R2和St组成。在一个实施方案中,多肽不包含标志物序列。然而,在其他实施方案中,多肽可以另外包含标志物序列。然而,任何这样的标志物序列都不能作为L的额外元件位于R1与R2之间。举例来说,标志物序列可以包含在茎序列中,或者可以被引入茎与R2之间。
在其他实施方案中,多肽可以与其他部分连接或偶联。
多肽可以是融合蛋白的形式,在该融合蛋白中,多肽被融合到多肽融合配偶体或在多肽融合配偶体内融合,或与多肽融合配偶体连接或包含在多肽融合配偶体内。融合配偶体是单独的多肽或第二多肽,该多肽实质上不会与第一多肽(即本发明的多肽)的任何成分发生作用。融合配偶体可以是第二多肽,该第二多肽赋予多肽期望的特性或功能。例如,它可以是标志物,或者可以包含标志物序列。融合配偶体可以是目标蛋白质(POI)。融合配偶体可以通过接头序列与多肽连接。在这种背景下的接头序列可以是任何已知或所期望的接头序列,该接头序列适于并且具有将蛋白质与融合配偶体连接的功能。这可以包括上文讨论的任何接头序列。进一步地,接头序列可以是可剪切接头序列。
融合蛋白可以包含多肽与融合配偶体(例如目标蛋白质)之间的自剪切肽。这种自剪切肽将允许多肽和POI在靶细胞内共表达,然后再剪切,使得多肽和POI在细胞表面作为单独的蛋白质表达。例如,融合蛋白可以包含口蹄疫自剪切2A肽。自剪切肽的选项是本领域已知的。
目标蛋白质可以是用于靶细胞表面表达的分子。也就是说,它可以是期望与本发明的多肽一起在细胞表面表达的多肽。当靶细胞在体内时,POI可以发挥治疗或预防作用。
POI可以是抗原受体。例如,它可以是嵌合受体或T细胞受体(TCR)。嵌合受体可以是嵌合抗原受体(CAR)。
嵌合抗原受体是通过将抗原识别结构域(胞外域)连接到信号分子的跨膜和胞内部分(胞内域)产生的。胞外域最常衍生于抗体可变链(例如scFv),但也可以由T细胞受体可变结构域或其他分子(比如配体或其他结合分子的受体)产生。胞内域可以至少包含CD3-ζ的胞内部分。胞内域可以包含CD28-OX40-CD3ζ三细胞质结构域。各种不同的跨膜及胞内信号和共刺激结构域的组合在本领域中是已知的。
POI可以是受体,例如CAR或TCR,该受体对与疾病或不希望的临床病症(例如癌症、感染、神经退行性疾病)或不希望的免疫应答(例如自身免疫或过敏反应或者GvHD或移植排斥)相关的抗原具有特异性。用表达抗原受体的细胞进行的ACT可以进一步用于诱导耐受性,促进组织修复和/或组织再生,或改善慢性炎症,例如继发于代谢紊乱的慢性炎症(例如,参见WO 2020/044055)。
受体可以对肿瘤相关抗原(即在癌细胞上表达或过表达的蛋白质)具有特异性。这样的蛋白质包括在15%-20%的乳腺癌患者中过表达并且与更具侵袭性的疾病有关的ERBB2(HER-2/neu)、在大多数B细胞恶性肿瘤上表达的CD19、在肾细胞癌中经常过表达的碳酸酐酶-IX、由神经母细胞瘤细胞表达的GD2、p53、MART-1(DMF5)、gp100:154、NY-ESO-1以及CEA。
为了治疗或预防免疫紊乱或不需要的免疫应答或者诱导耐受性等,可以在Treg细胞中表达CAR,其中CAR可以例如包含胞内域,该胞内域包含如WO 2020/044055中所描述的STAT5相关基序和JAK1结合基序和/或JAK2结合基序。用于预防或治疗器官移植排斥(例如肝或肾移植排斥)的CAR可以对HLA(例如在移植供体和受体之间通常不匹配的HLA-A2)具有特异性。
本发明的第二方面涉及一种核酸分子,该核酸分子包含能够编码本发明的多肽或融合蛋白的核苷酸序列。
当由靶细胞表达时,所述核酸使得编码的多肽在靶细胞的细胞表面表达。若核酸对多肽和POI(例如作为融合蛋白)都编码,则该核酸可以使得本发明的多肽和POI在靶细胞表面表达。
所述核酸分子可以是RNA或DNA,比如cDNA。
编码SEQ ID NO.55和SEQ ID NO.56的代表性多肽的核苷酸序列分别如SEQ IDNO.57和SEQ ID NO.58所示。因此,本发明的核酸分子可以包含如SEQ ID NO.57或SEQ IDNO.58所示的核苷酸序列,或与SEQ ID NO.57或SEQ ID NO.58具有至少70%(例如至少75%、80%、85%、90%或95%)序列同一性的核苷酸序列。
本发明还提供了一种载体,该载体包含本发明的核酸分子。所述载体还可以包含目标转基因,即编码或提供目标元件的核苷酸序列。这种转基因可以是编码POI的基因。
所述载体应当能够转染或转导靶细胞(例如单独或在另一种试剂/实体存在下),使得它们表达本发明的多肽和任选的目标蛋白。
所述载体可以是非病毒载体,比如质粒。质粒可使用本领域任何公知的方法转染到细胞中,例如使用磷酸钙、脂质体或细胞穿透肽(例如两亲性细胞穿透肽)。
所述载体可以是病毒载体,比如逆转录病毒载体,例如慢病毒载体或γ逆转录病毒载体。
适于递送核酸用于在哺乳动物细胞中表达的载体在本领域是公知的,并且可以使用任何这样的载体。载体可以包含一个或多个调控元件,例如启动子。
用于将核酸引入细胞的递送系统也是本领域已知且使用的,并且递送系统不依赖于载体,包括例如基于转座子、CRISPR/TALEN递送和mRNA递送的系统。任何这样的系统都可以用来递送根据本发明的核酸分子。因此,本发明还提供了一种用于递送到细胞中的重组构建体,所述构建体包含如本文所定义和描述的本发明的核酸分子。这样的构建体可以包含另一个(例如其他或第二)核酸分子或核苷酸序列或遗传元件,其使核酸分子能够递送到细胞或促进核酸分子递送到细胞。
所述载体或重组构建体可以包含编码多肽的核酸和含POI的核酸作为单独的实体或作为单个核苷酸序列。如果它们作为单个核苷酸序列存在,则它们可以包含一个或多个内部核糖体进入位点(IRES)序列或两个编码部分之间的其他翻译偶联序列,以使下游序列能够被翻译。如2A(例如T2A或P2A)等的剪切位点可以由本发明的核酸或载体或重组构建体编码,特别是在本发明的多肽与任何POI之间。
本发明还提供了一种表达根据本发明第一方面的多肽的细胞。该细胞可以在细胞表面表达多肽或共表达多肽和POI。该细胞可以被称为靶细胞。
本发明还提供了一种细胞,该细胞包含能够编码根据本发明第一方面的多肽的核酸分子。
所述细胞可以是已经引入本文所描述的核酸分子或载体或重组构建体的细胞。所述细胞可能已经用根据本发明的载体或重组构建体转导或转染。
所述细胞可以适于过继性细胞疗法。
所述细胞可以是免疫细胞或其前体。前体细胞还可以被称为祖细胞,并且这两个术语在本文同义使用。因此,代表性免疫细胞包括T细胞,特别是细胞毒性T细胞(CTL;CD8+T细胞)、辅助性T细胞(HTL;CD4+T细胞)和调节性T细胞(Treg)。其他T细胞群也可用于本文,例如初始T细胞和记忆T细胞。其他免疫细胞包括NK细胞、NKT细胞、树突状细胞、MDSC、中性粒细胞和巨噬细胞。免疫细胞的前体包括例如诱导型PSC(iPSC)的多能干细胞或包括多能干细胞在内的更多定向祖细胞或定向于一个谱系的细胞。前体细胞可以在体内或体外被诱导分化成免疫细胞。在一个方面,前体细胞可以是能够被转分化为目标免疫细胞的体细胞。
尤其是,免疫细胞可以是NK细胞、树突状细胞、MDSC或T细胞,比如细胞毒性T淋巴细胞(CTL)或Treg细胞。
T细胞可以具有现有的特异性。例如,它可以是爱泼斯坦-巴尔病毒(EBV)特异性T细胞。替代地,T细胞可以具有重定向特异性,例如,通过引入外源TCR或异源TCR或嵌合受体,例如CAR。
在一个优选的实施方案中,免疫细胞是Treg细胞。“调节性T细胞(Treg)或T调节细胞”是具有控制细胞病变免疫应答的免疫抑制功能的免疫细胞,并且对维持免疫耐受性至关重要。如本文所用的,术语Treg是指具有免疫抑制功能的T细胞。
适当地,免疫抑制功能可以是指Treg减少或抑制免疫系统响应如病原体、同种抗原或自身抗原等的刺激而促进的多种生理和细胞效应中的一种或多种的能力。这样的效应的实例包括常规T细胞(Tconv)的增殖增强和促炎性细胞因子的分泌。任何这样的效应都可以用作免疫应答强度的指标。Tconv在Treg存在下的免疫应答相对较弱表明Treg具有抑制免疫应答的能力。例如,细胞因子分泌相对减少表明免疫应答较弱,从而表明Treg具有抑制免疫应答的能力。Treg还可以通过调节共刺激分子在如B细胞、树突状细胞和巨噬细胞等抗原呈递细胞(APC)上的表达来抑制免疫应答。CD80和CD86的表达水平可以用来评估体外共培养后活化的Treg的抑制效力。
本领域已知测定法来测量免疫应答强度的指标,从而测量Treg的抑制能力。特别地,抗原特异性Tconv细胞可以与Treg共培养,并且在共培养物中加入相应抗原的肽以刺激Tconv细胞的应答。Tconv细胞响应于添加肽的增殖程度和/或Tconv细胞响应于添加肽分泌的细胞因子IL-2的数量可以用作共培养的Treg的抑制能力的指标。同本文所描述的Treg共培养的抗原特异性Tconv细胞的增殖率可以比在没有本文所描述的Treg存在下培养的相同的Tconv细胞低5%、10%、20%、30%、40%、50%、60%、70%、90%、95%或99%。
与Treg共培养的抗原特异性Tconv细胞可以比在没有Treg存在下培养的相应Tconv细胞少表达至少10%、至少20%、至少30%、至少40%、至少50%或至少60%的效应细胞因子。所述效应细胞因子可以选自IL-2、IL-17、TNFα、GM-CSF、IFN-γ、IL-4、IL-5、IL-9、IL-10和IL-13。适当地,所述效应细胞因子可以选自IL-2、IL-17、TNFα、GM-CSF和IFN-γ。
已经确定了几种不同的Treg亚群,这些Treg亚群可以表达不同的特定标志物或不同水平的特定标志物。Treg通常是表达CD4、CD25和FOXP3(CD4
Treg还可以表达CTLA-4(细胞毒性T淋巴细胞相关分子-4)或GITR(糖皮质激素诱导的TNF受体)。
Treg可以在没有表面蛋白CD127或结合低水平表达的表面蛋白CD127(CD4
Treg可以是CD4
Treg可以具有Treg特异性去甲基化区域(TSDR)。TSDR是调节Foxp3表达的重要甲基化敏感元件(Polansky,J.K.等,2008,European journal of immunology,38(6),第1654-1663页)。
已知存在不同的Treg亚群,包括初始Treg(CD45RA
特别地,Treg可以是初始Treg。如本文中可互换使用的“初始调节性T细胞、初始T调节性细胞或初始Treg”是指表达CD45RA(特别是在细胞表面上表达CD45RA)的Treg细胞。因此,初始Treg被描述为CD45RA
特别地,初始Treg可以不表达CD45RO,并且可以被认为是CD45RO
虽然初始Treg表达如上文所述的CD25,但是根据初始Treg的来源,CD25的表达水平可能低于在记忆Treg中的表达水平。例如,对于从外周血中分离的初始Treg,CD25的表达水平可能比记忆Treg至少低10%、20%、30%、40%、50%、60%、70%、80%或90%。这样的初始Treg可以被认为是表达中等水平至低水平的CD25。然而,技术人员会明白,从脐带血中分离出来的初始Treg可能不会显示出这种差异。
典型地,如本文所定义的初始Treg可以是CD4
本文所用的CD127的低表达是指与来自同一受试者或供体的CD4
典型地,初始Treg不表达或表达低水平的CCR4、HLA-DR、CXCR3和/或CCR6。特别地,初始Treg可以表达比记忆Treg水平低(例如表达水平至少低10%、20%、30%、40%、50%、60%、70%、80%或90%)的CCR4、HLA-DR、CXCR3和CCR6。
初始Treg可以进一步表达其他标志物,包括CCR7
分离的初始Treg可以通过本领域已知的方法来识别,包括通过确定在分离的细胞的细胞表面上是否存在上文所讨论的标志物中的任何一种或多种的标志物组。例如,CD45RA、CD4、CD25和CD127
表达多肽的细胞可以来自患者,即来自要治疗的受试者。例如,可以从受试者移除细胞,然后用根据本发明的载体或其他构建体进行离体转导。替代地,所述细胞可以是用于转移给受体受试者或者来自细胞系(例如NK细胞系)的供体细胞。所述细胞可以进一步是多能细胞(例如iPSC),该多能细胞可以被分化为所期望的靶细胞类型,例如T细胞,特别是Treg。因此,所述细胞可以是待治疗受试者的自体细胞、同系细胞或异体细胞。
适于ACT的T细胞群包括:本体外周血单核细胞(PBMC)、CD8+细胞(例如,CD4耗竭的PBMC);选择性耗竭T调节性细胞(Treg)的PBMC;分离的中央记忆型(Tern)细胞;EBV特异性CTL;以及如上文所讨论的三病毒特异性CTL和Treg细胞的制剂及群。
本发明还包括细胞群,该细胞群包含根据本发明的细胞。所述细胞群可能已经用根据本发明的载体转导。细胞群中的一部分细胞可以在细胞表面表达根据本发明第一方面的多肽。细胞群中的一部分细胞可以在细胞表面共表达根据本发明第一方面的多肽和POI。所述细胞群可以是来自患者的离体细胞群。
本发明还提供了用于删除在细胞表面表达本发明的多肽的细胞的方法。所述细胞可以是包含如本文所定义或描述的核酸分子或载体或重组构建体的细胞,即核酸分子或载体或构建体已被引入其中的细胞,例如由根据本发明的载体转导的细胞。该方法包括将细胞暴露于利妥昔单抗或具有利妥昔单抗的结合特异性的抗体(即等效抗体)的步骤。
典型地,利妥昔单抗通过补体介导的细胞杀伤发挥其作用,但可能会涉及其他机制,例如ADCC。因此,在一个实施方案中,细胞可以暴露于补体和利妥昔单抗或等效抗体。
该方法包括在体外进行的删除细胞的方法,例如在培养物中。然而,主要用途是在体内删除细胞,即删除先前已被施用到受试者的细胞。
可以理解,体内这可以通过向先前施用过该细胞的受试者(换言之,先前已接受过用本发明的表达多肽的细胞进行ACT的受试者)施用利妥昔单抗或等效抗体来实现。补体可以内源性地存在于受试者中。
因此,根据本发明,可以提供利妥昔单抗或具有其结合特异性的抗体与本发明的细胞结合用于ACT。如上文提到的,细胞或用于生产细胞的核酸或载体或构建体和利妥昔单抗或等效抗体可以提供在试剂盒中,或作为组合产品提供。
当本发明的多肽在细胞表面表达时,利妥昔单抗或等效抗体与多肽的R表位结合使得细胞裂解。
如本文所用的术语“删除(delete)”与“移除(remove)”或“除去(ablate)”同义。该术语用于包括细胞杀伤或细胞增殖的抑制,使得受试者中的细胞数量可以减少。100%完全移除可能是期望的,但并不一定能实现。减少受试者体内的细胞数量或抑制其增殖可能足以产生有益的效果。
具有利妥昔单抗的结合特异性的抗体是与利妥昔单抗一样能够与相同的天然表位结合的抗体。特别地,该抗体能够与表位R1和表位R2结合。
具有利妥昔单抗的结合特异性的抗体可以包含利妥昔单抗的抗原结合结构域或来自利妥昔单抗的抗原结合结构域。更具体地,它可以包含来自利妥昔单抗的VL和VH结构域或利妥昔单抗的CDR。进一步地,只要保留了利妥昔单抗的结合特异性,就可以修饰利妥昔单抗的抗原结合结构域(例如,通过氨基酸取代、删除或插入)。
如上文提到的,利妥昔单抗的生物仿制药是可获得的,并且可以使用。本领域技术人员很容易能够使用常规方法利用可获得的其氨基酸序列来制备具有利妥昔单抗的结合特异性的抗体。
在一个实施方案中,具有利妥昔单抗的结合特异性的抗体是常规免疫球蛋白形式。也就是说它可以包含轻链和重链以及恒定区和可变区两者。抗体可以是二价的,即它可以包含两个抗原结合位点。也可以使用其他抗体形式,包括例如单链形式或单价形式。因此,抗体可以是任何类别或类型,也可以是任何形式的。
每个在细胞表面表达的多肽可以结合一个以上的利妥昔单抗分子或等效抗体分子。多肽的每个R表位都可以结合单独的利妥昔单抗分子或等效抗体分子。
删除转移的细胞的决定可能是由于在受试者中检测到可归因于该转移的细胞的不良影响。例如,可能检测到不可接受的毒性水平。
可以通过用利妥昔单抗抗体治疗选择性地除去表达CD20的细胞。由于浆细胞中没有CD20表达,所以尽管删除了B细胞区室,但利妥昔单抗治疗后仍保留了体液免疫。
遗传修饰的免疫细胞(如T细胞)的过继转移是有吸引力的用于产生期望的免疫应答(比如抗肿瘤免疫应答)或抑制或预防不需要的免疫应答的方法。
本发明提供了一种用于治疗和/或预防受试者疾病或病症的方法,该方法包括向受试者施用根据本发明的细胞的步骤。该方法可以包括向受试者施用细胞群的步骤。
该方法可以涉及以下步骤:
(i)采集细胞样本,比如来自患者或供体的血液样本,
(ii)提取免疫细胞,例如T细胞,
(iii)将本发明的载体或构建体引入细胞中(例如用本发明的载体或构建体转导或转染细胞),所述载体或构建体包含编码多肽的核酸分子和任选的目标转基因,
(iv)离体扩增包含所述载体或构建体的细胞(即修饰后的细胞),
(v)向受试者施用细胞。
修饰的细胞可以具有所期望的治疗特性,比如增强的肿瘤特异性靶向和杀伤或免疫抑制活性。技术人员可以理解,细胞可以是待治疗受试者的异体细胞或自体细胞。
本发明的细胞可以用来治疗癌症。几乎所有肿瘤都容易使用ACT方法进行裂解,并且当遇到肿瘤抗原时,所有肿瘤都能够刺激抗肿瘤淋巴细胞释放细胞因子。
本发明的细胞可以用于例如治疗淋巴瘤、B系恶性肿瘤、转移性肾细胞癌(RCC)、转移性黑色素瘤或神经母细胞瘤。
替代地,本发明的细胞可以用来治疗或预防非癌疾病。该疾病可以是传染性疾病或与移植相关的病症,也可以是任何其他不需要或有害的免疫应答。所述细胞可以用于免疫抑制,例如用于诱导耐受性或者治疗或预防自身免疫或过敏性病症。特别地,所述细胞可以用来治疗神经退行性病症(比如阿尔茨海默病、帕金森病、运动神经元病等)、I型糖尿病、多发性硬化症、狼疮(特别是SLE)或炎症病症(比如炎症性肠病)。
本发明的细胞可以用来治疗或预防移植后淋巴增生性疾病(PTLD)或GvHD,或预防移植排斥,例如肝脏或肾脏的移植排斥。
现在将通过实施例进一步描述本发明,这些实施例是为了用来帮助本领域普通技术人员实施本发明,而不意于以任何方式限制本发明的范围。
实施例
实施例1:
不同的基于利妥昔单抗的安全开关如图1所示设计。图1呈现的序列仅用于多肽的R1-L-R2部分;茎序列和信号肽(前导)序列未示出。所描绘的RQR8、SGGGGS-CD8a、CD8a、1xSGGGGS和3xSGGGGS序列分别是SEQ ID NO.59、SEQ ID NO.60、SEQ ID NO.61、SEQ IDNO.62和SEQ ID NO.63。
开关1xSGGGGS和3xSGGGGS分别对应于SEQ ID NO.55和SEQ ID NO.56的多肽,这些多肽分别包含带有SEQ ID NO.54的信号肽(前导序列)的SEQ ID NO.27和SEQ ID NO.28的多肽。替代地,如上文提到的,SEQ ID NO.55和SEQ ID NO.56分别可以被视为分别包含带有SEQ ID NO.80的信号肽(前导序列)的SEQ ID NO.78和SEQ ID NO.79的多肽。
开关全部带有SEQ ID NO.54或SEQ ID NO.80的前导序列和带有SEQ ID NO.53的接头的SEQ ID NO.26的茎序列表达。
RQR8、SGGGGS-CD8a和CD8a的完整氨基酸序列分别如SEQ ID NO.75、SEQ ID NO.76和SEQ ID NO.77所示。
SEQ ID NO.57示出了本实施例中使用的1xSGGGGS的DNA序列,并且SEQ ID NO.58示出了本实施例中使用的3xSGGGGS的DNA序列。
确定为SGGGGS-CD8a(SEQ ID NO.60)、1xSGGGGS(SEQ ID 62)和3xSGGGGS(SEQ IDNO.63)的开关(多肽)具有根据本发明的柔性接头。EP2836511的RQR8(SEQ ID NO.59)和CD8A(SEQ ID NO.61)被包括在内用以比较。
将安全开关克隆到慢病毒表达载体中,经由2A接头序列与eGFP蛋白连接。用不同的构建体转导Jurkat细胞,并通过流式细胞仪评估eGFP表达(图2A)。在下一步中,用与Alexa-Fluor 647(克隆HU2,R&D系统)共轭的利妥昔单抗生物仿制药抗体对细胞染色。以GFP+细胞的平均荧光强度(MFI)评估染色效率(图2B)。
可以看出,所有开关都在细胞表面表达,并且看到了相当的eGFP表达水平(图2A)。与RQR8相比,开关SGGGGS-CD8a、1xSGGGGS和3xSGGGGS显示出优越的细胞表面表达,这可以从检测到的利妥昔单抗生物仿制药抗体结合的CD20表位的表达中看出。没有柔性接头的CD8A在细胞表面表现出较差的CD20表位表达。开关3xSGGGGS被表达得特别好。
实施例2:
接下来,对用不同安全开关构建体转导的细胞进行补体介导杀伤(CMC)评估。为此,在小兔补体、利妥昔单抗和小兔补体或单独的RPMI细胞培养基存在下培养细胞。培养4小时后,用流式细胞仪评估杀伤效率。此时,评估GFP阳性细胞的残留百分比。
图3示出所有开关都表现出CMC,但带有开关CD8A的CMC比其他低得多。与RQR8相比,开关SGGGGS-CD8a、1xSGGGGS和3xSGGGGS表现出提高的CMC,特别是3xSGGGGS。
实施例3:
各种安全开关的敏感性使用利妥昔单抗连续稀释液在补体依赖的细胞毒性(CDC)检测进行检查。
首先,如实施例1所描述的,比较安全开关RQR8(SEQ ID NO.75)、1xSGGGGS(也称为RR8小;SEQ ID NO.55)和3xSGGGGS(也称为RR8大;SEQ ID NO.56)的表达。
将安全开关克隆到慢病毒表达载体中,经由2A接头序列与eGFP蛋白连接。用不同的构建体转导Jurkat细胞,并通过流式细胞仪评估eGFP表达(图4)。在下一步中,用与荧光体共轭的利妥昔单抗抗体对细胞染色。以GFP+细胞的平均荧光强度(MFI)评估染色效率(图4)。
可以看出,三个开关全部都在细胞表面表达,并且看到大致相似的eGFP表达水平。(图4)。开关1xSGGGGS(RR8小)显示出略高于RQR8的表达,并且与RQR8相比,3xSGGGGS(RR8大)显示出优越的细胞表面表达,这可以从检测到的利妥昔单抗抗体结合的CD20表位的表达中看出(图4)。这证实了之前看到的结果,即开关3xSGGGGS(RR8大)被表达得特别好。
利妥昔单抗连续稀释液是在小兔补体中制备的。对用编码SEQ ID NO.75(RQR8)、SEQ ID NO.55(1xSGGGGS)或SEQ ID NO.56(3xSGGGGS)的慢病毒载体转导的Jurkat细胞(如实施例1中)进行计数并重悬于RPMI中。将细胞按每种条件一式三份或一式两份添加到96孔板(每孔100,000个Jurkat)中。在单独的培养基条件和单独的补体条件下,向96孔板的每个孔中各自加入50μL利妥昔单抗稀释液(终浓度:100μg/ml、5μg/ml、2.5μg/ml、1.25μg/ml、0.625μg/ml)(小兔补体的终体积为50%)。将孔板孵育,并且在孵育后对孔板进行活力(Live/Dead NIR试剂盒)和QBEND染色并通过FACS进行分析。
结果
如图5A所呈现的结果表明,单独的培养基和补体条件并未使得表达SEQ IDNO.75、SEQ ID NO.55或SEQ ID NO.56中的任何安全开关的Jurkat细胞显著死亡。然而,一旦加入利妥昔单抗,表达SEQ ID NO.55(RR8小)和SEQ ID NO.56(RR8大)的细胞在整个利妥昔单抗浓度范围内经历了显著的杀伤,在最高浓度的利妥昔单抗下观察到最高水平的杀伤,但即使在最低利妥昔单抗浓度下,细胞死亡水平也处于高水平(或替代地在低水平下看到的活细胞%)(图5A和图5B)。与此相反,表达SEQ ID NO.75(RQR8)的细胞对利妥昔单抗的敏感性似乎不如表达SEQ ID NO.55或SEQ ID NO.56的细胞——在所有利妥昔单抗浓度下,活的转导细胞%在利妥昔单抗治疗后对于表达SEQ ID NO.75的细胞要高得多。因此,出人意料地和有利地,具有氨基酸序列SEQ ID NO.55和SEQ ID NO.56的安全开关似乎比RQR8更有效和更敏感,可能需要更少的抗体来诱导细胞死亡。RQR8(SEQ ID NO.75)和RR8小接头(SEQ ID NO.55)具有非常相似的GFP和CD20 MFI,因此可以直接比较这些结果。从图5B可以看出,RR8小显示出了良好的剂量依赖性杀伤应答,在最高浓度的RTX下有相似甚至更好的杀伤细胞的能力。RR8大接头具有明显更高水平的CD20 MFI,并且结果也反映了这一点,即使在最低浓度下也有高水平的杀伤。
还注意到,从图5中可以看出,对于RQR8和RR8大两者,最高浓度的利妥昔单抗与接下来的较低浓度相比使得活细胞的百分比更高。这可能表明杀伤已经达到了饱和。
本发明人已设计了可以用于ACT的细胞中的新安全开关。逆转录病毒转导后,翻译的蛋白质在细胞表面稳定表达。构建体与利妥昔单抗结合,而双表位设计产生了高度有效的补体介导杀伤。由于构建体尺寸小,所以可以很容易地与典型的T细胞工程转基因(比如T细胞受体或嵌合抗原受体)以及其他转基因共表达,这些其他转基因是在面临不可接受的毒性时允许使用现成的临床级试剂/药物删除细胞的转基因。
在上文说明书中提到的所有出版物在此均通过引用并入本文。在不脱离本发明的范围和精神的情况下,本发明描述的方法和系统的各种修改和变化对于本领域技术人员而言将是显而易见的。尽管已经结合特定的优选实施方案对本发明进行了描述,但是应当理解,要求保护的本发明不应不适当地被限于这样的特定实施方案。实际上,对于细胞治疗、T细胞工程、分子生物学或相关领域技术人员显而易见的是,所描述的用于实施本发明的方法的各种修改都在所附权利要求的范围内。
序列表
<110>圭尔医疗有限公司
<120>用于过继性细胞疗法的多肽
<130>FSP1V225072ZX
<150>GB2007842.4
<151>2020-05-26
<160>80
<170>PatentIn version 3.5
<210>1
<211>16
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>QBEnd10结合表位
<400>1
Glu Leu Pro Thr Gln Gly Thr Phe Ser Asn Val Ser Thr Asn Val Ser
1 5 1015
<210>2
<211>11
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>利妥昔单抗模拟表位的共有序列
<220>
<221>misc_feature
<222>(1)..(1)
<223>Xaa可以是任何天然存在的氨基酸
<220>
<221>misc_feature
<222>(3)..(4)
<223>Xaa可以是任何天然存在的氨基酸
<220>
<221>misc_feature
<222>(10)..(10)
<223>Xaa可以是任何天然存在的氨基酸
<400>2
Xaa Cys Xaa Xaa Ala Ser Asn Pro Ser Xaa Cys
1 5 10
<210>3
<211>12
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>利妥昔单抗模拟表位
<400>3
Gln Asp Lys Leu Thr Gln Trp Pro Lys Trp Leu Glu
1 5 10
<210>4
<211>9
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>修饰后的利妥昔单抗模拟表位
<400>4
Cys Pro Tyr Ala Asn Pro Ser Leu Cys
1 5
<210>5
<211>9
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>修饰后的利妥昔单抗模拟表位
<400>5
Cys Pro Tyr Ser Asn Pro Ser Leu Cys
1 5
<210>6
<211>9
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>修饰后的利妥昔单抗模拟表位
<400>6
Cys Pro Phe Ala Asn Pro Ser Thr Cys
1 5
<210>7
<211>9
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>修饰后的利妥昔单抗模拟表位
<400>7
Cys Asn Phe Ser Asn Pro Ser Leu Cys
1 5
<210>8
<211>9
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>修饰后的利妥昔单抗模拟表位
<400>8
Cys Pro Phe Ser Asn Pro Ser Met Cys
1 5
<210>9
<211>9
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>修饰后的利妥昔单抗模拟表位
<400>9
Cys Ser Trp Ala Asn Pro Ser Gln Cys
1 5
<210>10
<211>9
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>修饰后的利妥昔单抗模拟表位
<400>10
Cys Met Phe Ser Asn Pro Ser Leu Cys
1 5
<210>11
<211>9
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>修饰后的利妥昔单抗模拟表位
<400>11
Cys Pro Phe Ala Asn Pro Ser Met Cys
1 5
<210>12
<211>9
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>修饰后的利妥昔单抗模拟表位
<400>12
Cys Trp Ala Ser Asn Pro Ser Leu Cys
1 5
<210>13
<211>9
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>修饰后的利妥昔单抗模拟表位
<400>13
Cys Glu His Ser Asn Pro Ser Leu Cys
1 5
<210>14
<211>9
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>修饰后的利妥昔单抗模拟表位
<400>14
Cys Trp Ala Ala Asn Pro Ser Met Cys
1 5
<210>15
<211>10
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>利妥昔单抗模拟表位
<400>15
Ala Cys Pro Tyr Ala Asn Pro Ser Leu Cys
1 5 10
<210>16
<211>10
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>利妥昔单抗模拟表位
<400>16
Ala Cys Pro Tyr Ser Asn Pro Ser Leu Cys
1 5 10
<210>17
<211>10
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>利妥昔单抗模拟表位
<400>17
Ala Cys Pro Phe Ala Asn Pro Ser Thr Cys
1 5 10
<210>18
<211>10
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>利妥昔单抗模拟表位(R8-, R12-, R18-C)
<400>18
Ala Cys Asn Phe Ser Asn Pro Ser Leu Cys
1 5 10
<210>19
<211>10
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>利妥昔单抗模拟表位 (R14-C)
<400>19
Ala Cys Pro Phe Ser Asn Pro Ser Met Cys
1 5 10
<210>20
<211>10
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>利妥昔单抗模拟表位
<400>20
Ala Cys Ser Trp Ala Asn Pro Ser Gln Cys
1 5 10
<210>21
<211>10
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>利妥昔单抗模拟表位
<400>21
Ala Cys Met Phe Ser Asn Pro Ser Leu Cys
1 5 10
<210>22
<211>10
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>利妥昔单抗模拟表位
<400>22
Ala Cys Pro Phe Ala Asn Pro Ser Met Cys
1 5 10
<210>23
<211>10
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>利妥昔单抗模拟表位
<400>23
Ala Cys Trp Ala Ser Asn Pro Ser Leu Cys
1 5 10
<210>24
<211>10
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>利妥昔单抗模拟表位
<400>24
Ala Cys Glu His Ser Asn Pro Ser Leu Cys
1 5 10
<210>25
<211>10
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>利妥昔单抗模拟表位
<400>25
Ala Cys Trp Ala Ala Asn Pro Ser Met Cys
1 5 10
<210>26
<211>82
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>CD8茎序列
<400>26
Pro Ala Pro Arg Pro Pro Thr Pro Ala Pro Thr Ile Ala Ser Gln Pro
1 5 1015
Leu Ser Leu Arg Pro Glu Ala Cys Arg Pro Ala Ala Gly Gly Ala Val
202530
His Thr Arg Gly Leu Asp Phe Ala Cys Asp Ile Tyr Ile Trp Ala Pro
354045
Leu Ala Gly Thr Cys Gly Val Leu Leu Leu Ser Leu Val Ile Thr Leu
505560
Tyr Cys Asn His Arg Asn Arg Arg Arg Val Cys Lys Cys Pro Arg Pro
65707580
Val Val
<210>27
<211>116
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>多肽序列
<400>27
Cys Pro Tyr Ser Asn Pro Ser Leu Cys Glu Thr Ser Gly Gly Gly Gly
1 5 1015
Ser Arg Leu Cys Pro Tyr Ser Asn Pro Ser Leu Cys Ser Gly Gly Gly
202530
Gly Ser Pro Ala Pro Arg Pro Pro Thr Pro Ala Pro Thr Ile Ala Ser
354045
Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys Arg Pro Ala Ala Gly Gly
505560
Ala Val His Thr Arg Gly Leu Asp Phe Ala Cys Asp Ile Tyr Ile Trp
65707580
Ala Pro Leu Ala Gly Thr Cys Gly Val Leu Leu Leu Ser Leu Val Ile
859095
Thr Leu Tyr Cys Asn His Arg Asn Arg Arg Arg Val Cys Lys Cys Pro
100 105 110
Arg Pro Val Val
115
<210>28
<211>122
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>多肽序列
<400>28
Cys Pro Tyr Ser Asn Pro Ser Leu Cys Ser Gly Gly Gly Gly Ser Gly
1 5 1015
Gly Gly Gly Ser Gly Gly Gly Gly Ser Cys Pro Tyr Ser Asn Pro Ser
202530
Leu Cys Ser Gly Gly Gly Gly Ser Pro Ala Pro Arg Pro Pro Thr Pro
354045
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
505560
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
65707580
Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu
859095
Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Asn His Arg Asn Arg Arg
100 105 110
Arg Val Cys Lys Cys Pro Arg Pro Val Val
115 120
<210>29
<211>17
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>CD20利妥昔单抗结合表位
<400>29
Cys Glu Pro Ala Asn Pro Ser Glu Lys Asn Ser Pro Ser Thr Gln Tyr
1 5 1015
Cys
<210>30
<211>42
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>CD8胞外序列
<400>30
Pro Ala Pro Arg Pro Pro Thr Pro Ala Pro Thr Ile Ala Ser Gln Pro
1 5 1015
Leu Ser Leu Arg Pro Glu Ala Cys Arg Pro Ala Ala Gly Gly Ala Val
202530
His Thr Arg Gly Leu Asp Phe Ala Cys Asp
3540
<210>31
<211>5
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223> 代表性的示例性接头序列
<400>31
Gly Gly Gly Gly Ser
1 5
<210>32
<211>10
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>代表性的示例性接头序列
<400>32
Glu Thr Ser Gly Gly Gly Gly Ser Arg Leu
1 5 10
<210>33
<211>16
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>代表性的示例性接头序列
<400>33
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
1 5 1015
<210>34
<211>4
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>代表性的示例性接头序列
<400>34
Gly Gly Gly Ser
1
<210>35
<211>6
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>代表性的示例性接头序列
<400>35
Gly Gly Gly Gly Gly Ser
1 5
<210>36
<211>7
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>代表性的示例性接头序列
<400>36
Gly Gly Gly Gly Gly Gly Ser
1 5
<210>37
<211>6
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>代表性的示例性接头序列
<400>37
Gly Gly Gly Gly Gly Gly
1 5
<210>38
<211>8
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>代表性的示例性接头序列
<400>38
Gly Gly Gly Gly Gly Gly Gly Gly
1 5
<210>39
<211>18
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>代表性的示例性接头序列
<400>39
Lys Glu Ser Gly Ser Val Ser Ser Glu Gln Leu Ala Gln Phe Arg Ser
1 5 1015
Leu Asp
<210>40
<211>14
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>代表性的示例性接头序列
<400>40
Glu Gly Lys Ser Ser Gly Ser Gly Ser Glu Ser Lys Ser Thr
1 5 10
<210>41
<211>12
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>代表性的示例性接头序列
<400>41
Gly Ser Ala Gly Ser Ala Ala Gly Ser Gly Glu Phe
1 5 10
<210>42
<211>16
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>代表性的示例性接头序列
<400>42
Ser Gly Gly Gly Gly Ser Ala Gly Ser Ala Ala Gly Ser Gly Glu Phe
1 5 1015
<210>43
<211>16
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>代表性的示例性接头序列
<400>43
Ser Gly Gly Gly Leu Leu Leu Leu Leu Leu Leu Leu Gly Gly Gly Ser
1 5 1015
<210>44
<211>16
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>代表性的示例性接头序列
<400>44
Ser Gly Gly Gly Ala Ala Ala Ala Ala Ala Ala Ala Gly Gly Gly Ser
1 5 1015
<210>45
<211>24
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>代表性的示例性接头序列
<400>45
Ser Gly Gly Gly Ala Ala Ala Ala Ala Ala Ala Ala Ala Ala Ala Ala
1 5 1015
Ala Ala Ala Ala Gly Gly Gly Ser
20
<210>46
<211>24
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>代表性的示例性接头序列
<400>46
Ser Gly Ala Leu Gly Gly Leu Ala Leu Ala Gly Leu Leu Leu Ala Gly
1 5 1015
Leu Gly Leu Gly Ala Ala Gly Ser
20
<210>47
<211>14
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>代表性的示例性接头序列
<400>47
Ser Leu Ser Leu Ser Pro Gly Gly Gly Gly Gly Pro Ala Arg
1 5 10
<210>48
<211>25
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>代表性的示例性接头序列
<400>48
Ser Leu Ser Leu Ser Pro Gly Gly Gly Gly Gly Pro Ala Arg Ser Leu
1 5 1015
Ser Leu Ser Pro Gly Gly Gly Gly Gly
2025
<210>49
<211>6
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>代表性的示例性接头序列
<400>49
Gly Ser Ser Gly Ser Ser
1 5
<210>50
<211>7
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>代表性的示例性接头序列
<400>50
Gly Ser Ser Ser Ser Ser Ser
1 5
<210>51
<211>6
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>代表性的示例性接头序列
<400>51
Gly Gly Ser Ser Ser Ser
1 5
<210>52
<211>6
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>代表性的示例性接头序列
<400>52
Gly Ser Ser Ser Ser Ser
1 5
<210>53
<211>6
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>代表性的示例性接头序列
<400>53
Ser Gly Gly Gly Gly Ser
1 5
<210>54
<211>21
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>信号肽
<400>54
Met Gly Thr Ser Leu Leu Cys Trp Met Ala Leu Cys Leu Leu Gly Ala
1 5 1015
Asp His Ala Asp Ala
20
<210>55
<211>137
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>包含SEQ ID NO.54的信号肽和SEQ ID NO.27的氨基酸序列的多肽
<400>55
Met Gly Thr Ser Leu Leu Cys Trp Met Ala Leu Cys Leu Leu Gly Ala
1 5 1015
Asp His Ala Asp Ala Cys Pro Tyr Ser Asn Pro Ser Leu Cys Glu Thr
202530
Ser Gly Gly Gly Gly Ser Arg Leu Cys Pro Tyr Ser Asn Pro Ser Leu
354045
Cys Ser Gly Gly Gly Gly Ser Pro Ala Pro Arg Pro Pro Thr Pro Ala
505560
Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys Arg
65707580
Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala Cys
859095
Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu Leu
100 105 110
Leu Ser Leu Val Ile Thr Leu Tyr Cys Asn His Arg Asn Arg Arg Arg
115 120 125
Val Cys Lys Cys Pro Arg Pro Val Val
130 135
<210>56
<211>143
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>包含SEQ ID NO.54的信号肽和SEQ ID NO.28的氨基酸序列的多肽
<400>56
Met Gly Thr Ser Leu Leu Cys Trp Met Ala Leu Cys Leu Leu Gly Ala
1 5 1015
Asp His Ala Asp Ala Cys Pro Tyr Ser Asn Pro Ser Leu Cys Ser Gly
202530
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Cys Pro
354045
Tyr Ser Asn Pro Ser Leu Cys Ser Gly Gly Gly Gly Ser Pro Ala Pro
505560
Arg Pro Pro Thr Pro Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu
65707580
Arg Pro Glu Ala Cys Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg
859095
Gly Leu Asp Phe Ala Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly
100 105 110
Thr Cys Gly Val Leu Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Asn
115 120 125
His Arg Asn Arg Arg Arg Val Cys Lys Cys Pro Arg Pro Val Val
130 135 140
<210>57
<211>410
<212>DNA
<213>人工序列(Artificial Sequence)
<220>
<223>实施例1中使用的1xSGGGGS的DNA
<400>57
tgggcacatc tttgctttgt tggatggccc tgtgtctgct gggagccgat catgctgatg60
cctgtcctta cagcaacccc agcctgtgtg agacgagcgg tggtggcgga agccgtctct 120
gtccctactc caatcctagc ctgtgtagcg gaggtggcgg aagccctgct cctagacctc 180
ctacaccagc tcctacaatc gccagccagc ctctgtctct gaggccagaa gcttgtagac 240
ctgctgctgg cggagccgtg catacaagag gactggattt cgcctgcgac atctacatct 300
gggcccctct ggctggaaca tgtggcgttc tgctgctgag cctggtcatc accctgtact 360
gcaaccaccg gaacaggcgg agagtgtgca agtgccctag acctgtggtg410
<210>58
<211>429
<212>DNA
<213>人工序列(Artificial Sequence)
<220>
<223>实施例1中使用的3xSGGGGS的DNA
<400>58
atgggcacat ctttgctttg ttggatggcc ctgtgtctgc tgggagccga tcatgctgat60
gcctgtcctt acagcaaccc cagcctgtgt agcggcggcg gaggcagcgg tggcggaggc 120
agcggcggag gcggtagctg tccctactcc aatcctagcc tgtgtagcgg aggtggcgga 180
agccctgctc ctagacctcc tacaccagct cctacaatcg ccagccagcc tctgtctctg 240
aggccagaag cttgtagacc tgctgctggc ggagccgtgc atacaagagg actggatttc 300
gcctgcgaca tctacatctg ggcccctctg gctggaacat gtggcgttct gctgctgagc 360
ctggtcatca ccctgtactg caaccaccgg aacaggcgga gagtgtgcaa gtgccctaga 420
cctgtggtg 429
<210>59
<211>48
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>RQR8
<400>59
Cys Pro Tyr Ser Asn Pro Ser Leu Cys Ser Gly Gly Gly Gly Ser Glu
1 5 1015
Leu Pro Thr Gln Gly Thr Phe Ser Asn Val Ser Thr Asn Val Ser Pro
202530
Ala Lys Pro Thr Thr Thr Ala Cys Pro Tyr Ser Asn Pro Ser Leu Cys
354045
<210>60
<211>48
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>SGGGGS-CD8A
<400>60
Cys Pro Tyr Ser Asn Pro Ser Leu Cys Ser Gly Gly Gly Gly Ser Pro
1 5 1015
Ala Lys Pro Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro Ala Pro
202530
Thr Ile Ala Ser Gln Pro Ala Cys Pro Tyr Ser Asn Pro Ser Leu Cys
354045
<210>61
<211>34
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>CD8A
<400>61
Cys Pro Tyr Ser Asn Pro Ser Leu Cys Pro Ala Lys Pro Thr Thr Thr
1 5 1015
Pro Ala Pro Arg Pro Pro Thr Pro Ala Cys Pro Tyr Ser Asn Pro Ser
202530
Leu Cys
<210>62
<211>28
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>1x SGGGGS
<400>62
Cys Pro Tyr Ser Asn Pro Ser Leu Cys Glu Thr Ser Gly Gly Gly Gly
1 5 1015
Ser Arg Leu Cys Pro Tyr Ser Asn Pro Ser Leu Cys
2025
<210>63
<211>34
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>3x SGGGGS
<400>63
Cys Pro Tyr Ser Asn Pro Ser Leu Cys Ser Gly Gly Gly Gly Ser Gly
1 5 1015
Gly Gly Gly Ser Gly Gly Gly Gly Ser Cys Pro Tyr Ser Asn Pro Ser
202530
Leu Cys
<210>64
<211>20
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>接头序列
<400>64
Ser Gly Gly Gly Ser Asn Val Ser Thr Asn Val Ser Pro Ala Lys Pro
1 5 1015
Thr Thr Thr Ala
20
<210>65
<211>20
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>接头序列
<400>65
Ser Gly Gly Gly Ser Glu Leu Pro Thr Gln Gly Thr Phe Ser Asn Val
1 5 1015
Ser Thr Asn Ala
20
<210>66
<211>20
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>接头序列
<400>66
Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Glu
1 5 1015
Ala Ala Ala Lys
20
<210>67
<211>20
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>接头序列
<400>67
Gly Gly Gly Gly Ser Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Ser
1 5 1015
Gly Gly Gly Ser
20
<210>68
<211>15
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>接头序列
<400>68
Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys
1 5 1015
<210>69
<211>16
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>接头序列
<400>69
Gly Gly Leu Lys Asn Lys Ala Gln Gln Ala Ala Phe Tyr Ile Gly Gly
1 5 1015
<210>70
<211>14
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>接头序列
<400>70
Leu Cys Lys Asn Lys Ala Gln Gln Ala Ala Phe Tyr Cys Ile
1 5 10
<210>71
<211>14
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>接头序列
<400>71
Lys Cys Leu Asn Asp Ala Gln Ala Ala Ala Glu Glu Cys Ile
1 5 10
<210>72
<211>18
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>接头序列
<400>72
Gly Gly Gly Leu Lys Asn Lys Ala Gln Gln Ala Ala Phe Tyr Ile Gly
1 5 1015
Gly Gly
<210>73
<211>25
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>接头序列
<400>73
Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Glu
1 5 1015
Ala Ala Ala Glu Ala Ala Ala Lys Glu
2025
<210>74
<211>24
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>接头序列
<400>74
Gly Gly Gly Ser Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Glu Ala
1 5 1015
Ala Ala Lys Glu Gly Gly Gly Ser
20
<210>75
<211>157
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>实施例1中使用的RQR8
<400>75
Met Gly Thr Ser Leu Leu Cys Trp Met Ala Leu Cys Leu Leu Gly Ala
1 5 1015
Asp His Ala Asp Ala Cys Pro Tyr Ser Asn Pro Ser Leu Cys Ser Gly
202530
Gly Gly Gly Ser Glu Leu Pro Thr Gln Gly Thr Phe Ser Asn Val Ser
354045
Thr Asn Val Ser Pro Ala Lys Pro Thr Thr Thr Ala Cys Pro Tyr Ser
505560
Asn Pro Ser Leu Cys Ser Gly Gly Gly Gly Ser Pro Ala Pro Arg Pro
65707580
Pro Thr Pro Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro
859095
Glu Ala Cys Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu
100 105 110
Asp Phe Ala Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys
115 120 125
Gly Val Leu Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Asn His Arg
130 135 140
Asn Arg Arg Arg Val Cys Lys Cys Pro Arg Pro Val Val
145 150 155
<210>76
<211>141
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>实施例1中使用的SGGGGS-CD8A
<400>76
Met Gly Thr Ser Leu Leu Cys Trp Met Ala Leu Cys Leu Leu Gly Ala
1 5 1015
Asp His Ala Asp Ala Cys Pro Tyr Ser Asn Pro Ser Leu Cys Ser Gly
202530
Gly Gly Gly Ser Pro Ala Lys Pro Thr Thr Thr Pro Ala Pro Arg Pro
354045
Pro Thr Pro Ala Pro Thr Ile Ala Ser Gln Pro Ala Cys Pro Tyr Ser
505560
Asn Pro Ser Leu Cys Ser Gly Gly Gly Gly Ser Leu Ser Leu Arg Pro
65707580
Glu Ala Cys Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu
859095
Asp Phe Ala Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys
100 105 110
Gly Val Leu Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Asn His Arg
115 120 125
Asn Arg Arg Arg Val Cys Lys Cys Pro Arg Pro Val Val
130 135 140
<210>77
<211>134
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>实施例1中使用的CD8A
<400>77
Met Gly Thr Ser Leu Leu Cys Trp Met Ala Leu Cys Leu Leu Gly Ala
1 5 1015
Asp His Ala Asp Ala Cys Pro Tyr Ser Asn Pro Ser Leu Cys Pro Ala
202530
Lys Pro Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro Ala Cys Pro
354045
Tyr Ser Asn Pro Ser Leu Cys Ser Gly Gly Gly Gly Ser Pro Thr Ile
505560
Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys Arg Pro Ala Ala
65707580
Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala Cys Asp Ile Tyr
859095
Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu Leu Leu Ser Leu
100 105 110
Val Ile Thr Leu Tyr Cys Asn His Arg Asn Arg Arg Arg Val Cys Lys
115 120 125
Cys Pro Arg Pro Val Val
130
<210>78
<211>117
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>多肽序列
<400>78
Ala Cys Pro Tyr Ser Asn Pro Ser Leu Cys Glu Thr Ser Gly Gly Gly
1 5 1015
Gly Ser Arg Leu Cys Pro Tyr Ser Asn Pro Ser Leu Cys Ser Gly Gly
202530
Gly Gly Ser Pro Ala Pro Arg Pro Pro Thr Pro Ala Pro Thr Ile Ala
354045
Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys Arg Pro Ala Ala Gly
505560
Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala Cys Asp Ile Tyr Ile
65707580
Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu Leu Leu Ser Leu Val
859095
Ile Thr Leu Tyr Cys Asn His Arg Asn Arg Arg Arg Val Cys Lys Cys
100 105 110
Pro Arg Pro Val Val
115
<210>79
<211>123
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>多肽序列
<400>79
Ala Cys Pro Tyr Ser Asn Pro Ser Leu Cys Ser Gly Gly Gly Gly Ser
1 5 1015
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Cys Pro Tyr Ser Asn Pro
202530
Ser Leu Cys Ser Gly Gly Gly Gly Ser Pro Ala Pro Arg Pro Pro Thr
354045
Pro Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala
505560
Cys Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe
65707580
Ala Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val
859095
Leu Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Asn His Arg Asn Arg
100 105 110
Arg Arg Val Cys Lys Cys Pro Arg Pro Val Val
115 120
<210>80
<211>20
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>信号肽
<400>80
Met Gly Thr Ser Leu Leu Cys Trp Met Ala Leu Cys Leu Leu Gly Ala
1 5 1015
Asp His Ala Asp
20