基于空气质量监测网络的大气污染物空间分布预测方法
文献发布时间:2024-01-17 01:26:37
技术领域
本发明涉及大气污染物浓度预测技术领域,具体涉及一种基于空气质量监测网络的大气污染物空间分布预测方法。
背景技术
城市中大气污染逐渐成为一个非常严重的问题,大气质量的不断恶化对人们的身体健康和生活环境造成了巨大的危害,大气污染物的空间分布预测对于人们的生活越来越重要。
常用的大气污染物的空间分布预测方法包括统计学方法、机器学习算法、地理信息系统插值方法和数值模拟。统计学方法包括土地利用回归、地理加权回归和广义相加模型,机器学习算法包括随机森林、神经网络、决策树和支持向量机,GIS空间插值方法包括克里金法和反距离权重法,数值模拟包括WRF/MM5-CMAQ和WRF-CHEM。
土地利用回归(LUR)由于模型构建简单,数据易获取,常应用于NO
土地利用回归包括自变量和因变量,因变量为大气污染物浓度,自变量共五类,对因变量有着直接或间接的影响。首先提取因变量,然后对自变量进行筛选,获取与因变量显著相关的自变量。之后构建预测模型,使用筛选出的自变量与因变量进行多元逐步回归,再对预测模型进行诊断和交叉验证;最后进行回归映射,将城市划分为多个网格,以网格质点为中心点,提取自变量代入预测模型中,计算出各个网格的大气污染物预测值,进而得到城市的大气污染物空间分布图。
然而土地利用回归预测模型本质上仍属线性回归,缺乏对非线性关系的拟合,且无法纳入随时间变化的特征变量,预测精度相对较低;此外每次建模只能预测固定时间段的污染物,逐日预测需要逐日建模,使用不便且效率低。
发明内容
针对现有技术中存在的问题,本发明的目的在于提供一种基于空气质量监测网络的大气污染物空间分布预测方法,同时纳入随时间变化和不随时间变化的特征变量,一次建模连续预测,拟合因变量和特征变量的非线性关系,提高预测的精度和效率。
为了达到上述目的,本发明采用以下技术方案予以实现。
本发明提供一种基于空气质量监测网络的大气污染物空间分布预测方法,空气质量监测网络包含多个空气质量监测站,包括以下步骤:
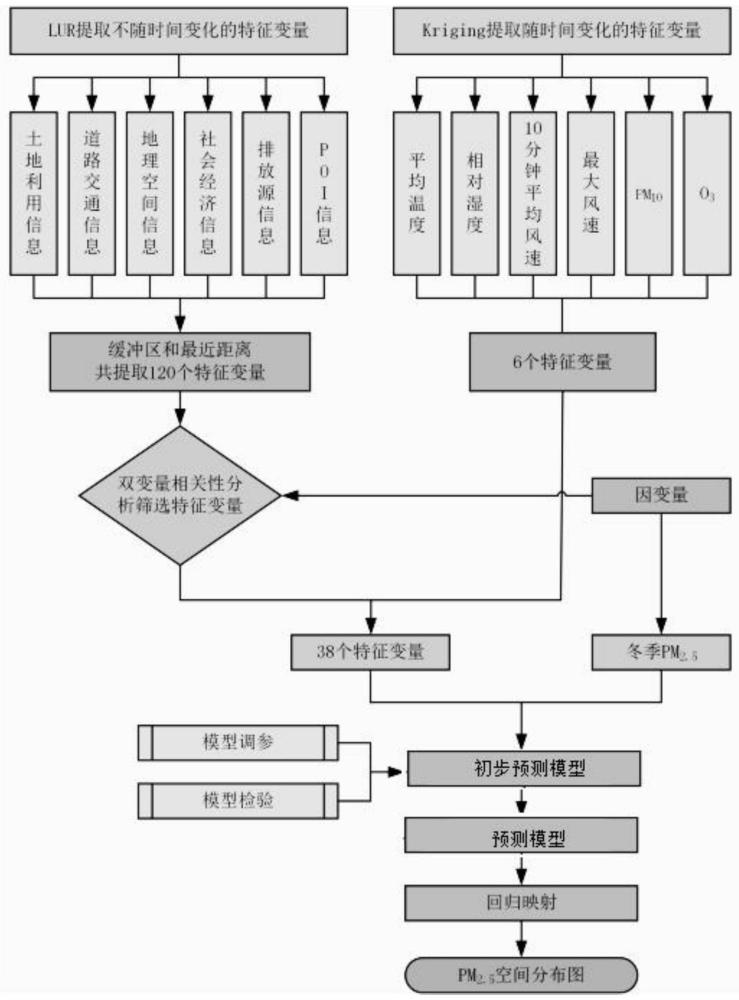
S1,分别以每个空气质量监测站为中心建立缓冲区,在每个缓冲区提取与大气污染有关的特征变量;
S2,对所述特征变量进行筛选,得到目标特征变量;
S3,建立PM
S4,建立PM
S5,将目标特征变量输入所述PM
优选的,所述特征变量包括:
1)缓冲区类特征变量,包含:
土地利用数据,包括该缓冲区内耕地、绿地、水域、工矿用地和建设用地的分布以及面积数据;
道路网络数据,包括该缓冲区所有道路、主要道路、高速公路的分布以及长度数据;
兴趣点信息,包括该缓冲区内的餐饮店、停车场、公交车站、加油站、工厂、印刷厂;
排放源信息,包括该缓冲区内的污染排放企业数量及分布;
2)距离类特征变量,包含空气质量监测站距离各种类型的用地、道路网络和兴趣点的距离数据;
3)位置特征变量,包含空气质量监测站处人口数据、GDP数据、高程数据、山脊线数据;
4)随时间变化的特征变量,包括:
污染物浓度,包括空气质量监测站采集的O
气象参数数据,包括该空气质量监测站采集的平均温度、相对湿度、平均风速和最大风速。
进一步优选的,步骤S1包括以下步骤:
S11,分别以每个空气质量监测站位置为圆心,利用GIS平台分别建立直径为100m、300m、500m、1000m、2000m、3000m、4000m和5000m的圆形缓冲区,统计各缓冲区内的道路网络信息、土地利用信息、排放源信息和兴趣点信息;
S12,使用GIS平台提取空气质量监测站的人口、GDP和高程;
S13,计算距离空气质量监测站最近的用地、道路、兴趣点的距离。
进一步优选的,提取所述随时间变化的特征变量的方法为:
首先,使用144个空气质量监测站的日平均污染物浓度/气象参数据,通过Kriging插值法,插值获得连续90天的污染物浓度/气象参的空间格栅数据;
其次,使用GIS平台的值提取至点功能提取每个空气质量监测站对应的污染物浓度/气象参数的栅格值作为特征变量。
进一步优选的,对所述特征变量进行筛选,包括以下步骤:
S21,以PM
S22,对因变量和每类缓冲区类特征变量进行斯皮尔曼相关性分析,得到每类缓冲区类特征变量的因变量-特征变量相关系数;
S23,选择因变量-特征变量相关系数最大的缓冲区类特征变量作为目标特征变量。
优选的,所述S3具体为:
收集90天内144个空气质量监测站的日平均PM
优选的,所述PM
使用Python3.6.13中的scikit-learn0.24.2包,用随机森林回归器建立PM
进一步优选的,调参训练所述PM
S41,划分训练集和验证集;
S42,利用学习曲线,确定n_estimators的范围;
S43,在确定好的n_estimators范围内,确定最佳的n_estimators;
S44,依次调max_depth参数、min_samples_leaf参数、min_samples_split参数和max_features参数,完成训练,得到PM
PM
PM
进一步优选的,对所述PM
用相同的目标特征变量和因变量分别构建多元线性回归模型、土地利用回归模型和随机森林模型;
观察多元线性回归模型、土地利用回归模型和随机森林模型的预测误差,判断PM
进一步优选的,所述步骤S6具体为:
在Arcgis10.4中使用创建渔网工具以西安市域为范围建立500m*500m的正方形网格,以网格质心为圆心画缓冲区后提取目标特征变量,将目标特征变量输入到PM
与现有技术相比,本发明的有益效果为:
本发明的预测方法纳入了随时间变化的特征变量,使得预测模型的特征变量更加全面,更准确的反映出大气污染物的影响因素,提高了预测精度,且通过一次建模即实现逐日预测,提高大气污染预测的工作效率。
附图说明
下面结合附图和具体实施例对本发明做进一步详细说明。
图1为基于空气质量监测网络的大气污染物空间分布预测方法的流程图;
图2为西安市域的土地利用图;
图3为西安市域的道路网络分布图;
图4为西安市域的加油站、工厂和印刷厂的分布图;
图5为西安市域的大气污染排放企业分布图;
图6为西安市域的高程图和山脊线图;
图7为西安市域的街街办、镇人口分布图;
图8为空气质量监测站的分布图;
图9为PM
图10为随机森林预测模型调参图;
图11为PM
图12为西安市中心城区500m*500m网格示意图;
图13为西安市域PM
具体实施方式
下面将结合实施例对本发明的实施方案进行详细描述,但是本领域的技术人员将会理解,下列实施例仅用于说明本发明,而不应视为限制本发明的范围。
本发明提供一种基于空气质量监测网络的大气污染物空间分布预测方法,基于西安市的空气质量监测网络对西安市的PM
S1,分别以每个空气质量监测站为中心建立缓冲区,在每个缓冲区提取与大气污染有关的特征变量;
分别以每个空气质量监测站位置为圆心,利用GIS平台分别建立直径为100m、300m、500m、1000m、2000m、3000m、4000m和5000m的圆形缓冲区,在每个缓冲区提取与PM
缓冲区类特征变量包含土地利用数据、道路网络数据和设施数据;
将缓冲区内的土地按照利用类型划分为耕地、绿地、水域、工矿用地和建设用地五种,土地利用数据为缓冲区内上述五种用地类型的分布及面积。
土地利用数据来源于由中国科学院制作的中国土地利用现状遥感监测数据,是以LandsatTM/ETM/OLI遥感影像为主要数据源,经过影像融合、几何校正、图像增强与拼接等处理后,通过人机交互目视解译的方法,依据中国建立的土地利用/覆被分类体系进行分类的数据产品。西安市域土地利用图如图2所示。
道路网络数据,包括该缓冲区所有道路、主要道路、高速公路的分布以及长度数据。道路网络数据来源于OpenStreetMap(OSM),OSM是一款开源地图,图层包括高速公路、铁路、水系、水域、建筑、边界、建筑物等。本发明根据西安市现状进行分类后有三个特征变量,分别是所有道路、主要道路和高速公路,其分布见图3。
设施数据包括缓冲区内的兴趣点信息和排放源信息。
兴趣点信息,包括该缓冲区内的餐饮店、停车场、公交车站、加油站、工厂、印刷厂分布及数量。兴趣点在地理信息系统中是一种点矢量数据,本发明的使用的兴趣点来源于高德地图,其中加油站、工厂和印刷厂的分布见图4。
排放源信息,包括该缓冲区内的污染排放企业数量及分布;来源于陕西省重点排污企业监测信息发布平台和西安市生态环保局公布的重点排污单位名录,共有83家大气污染排放企业,其分布见图5。
距离类特征变量,包含空气质量监测站距离各种类型的用地、道路网络和兴趣点的距离。各个空气质量监测站距离各种类型的用地、道路网络和兴趣点的距离使用Arcgis10.4生成邻近表后汇总统计数据获得。
位置特征变量,包含空气质量监测站处人口数据、GDP数据、高程数据和山脊线数据;其中高程数据和山脊线数据来源于中国科学院制作的30mDEM数据,见图6。GDP数据来源于中科院制作的中国GDP空间分布公里网格数据集,每个栅格代表该网格范围(1平方公里)内的GDP总产值,单位为万元/平方千米,本发明在Arcgis10.4软件中提取每个空气质量监测站所在的网格的GDP值作为特征变量。人口数据来源于第六次全国人口普查,分别计算空气质量监测站所在街办或镇的人口总数,人口分布见图7。
随时间变化的特征变量,包括:
污染物浓度,包括空气质量监测站采集的O
气象参数数据,包括该空气质量监测站采集的平均温度、相对湿度、平均风速和最大风速。
提取随时间变化的特征变量的方法为:
首先,使用144个空气质量监测站的日平均污染物浓度/气象参数据,通过Kriging插值法,插值获得连续90天的污染物浓度/气象参的空间格栅数据;空气质量监测站的分布如图8所示。
其次,使用GIS平台的值提取至点功能提取每个空气质量监测站对应的污染物浓度/气象参数的栅格值作为特征变量。GIS平台选用Arcgis10.4软件,得到O
缓冲区类特征变量共有三大类共15个,分别为耕地面积、绿地面积、水域面积、工矿用地面积和建设用地面积,所有道路长度、主要道路长度、高速公路长度,以及餐饮店、停车场、公交车站、加油站、工厂、印刷厂的数量和污染排放企业数量。
针对每个空气质量监测站分别提取5000m、4000m、3000m、2000m、1000m、500m、300m和100m共8个缓冲区的缓冲类特征变量,最终缓冲类特征变量120个。
距离类特征变量共14个,分别为距离所有道路、距离主要道路、距离高速公路、距离山脊线、距离停车场、距离公交车站、距离餐饮店、距离绿地、距离水域、距离耕地、距离工业用地、距离印刷厂、距离加油站、距离污染排放企业的距离数据。
站点位置提取的特征变量3个,分别是人口、GDP和高程数据。
随时间变化的特征变量包括污染物和气象参数共2类6个特征变量,分别为PM
每个空气质量监测站提取143个特征变量。
S2,对步骤S1提取的特征变量进行筛选,得到目标特征变量;
对特征变量中的缓冲区类特征变量进行筛选,具体方法如下:
以PM
因变量PM
对特征变量中的缓冲区类变量进行筛选。以工矿用地为例,提取8个缓冲区内的工矿用地面积和PM
对缓冲区类特征变量进行筛选后,加上其他类型的特征变量,得到每个空气质量监测站的38个目标特征变量,其描述性统计见表1。表1包括了目标特征变量的平均值、标准差、最小值和最大值。
表1冬季PM
S3,建立PM
用研究时段总天数90乘以监测站点数量144得到因变量数量,冬季PM
S4,建立PM
确定数据集后使用Python3.6.13中的scikit-learn0.24.2包,用随机森林回归器建立PM
如图10所示,用训练集调参训练所述PM
S41,划分训练集和验证集;
S42,利用学习曲线,确定n_estimators的范围;
S43,在确定好的n_estimators范围内,确定最佳的n_estimators;
S44,依次调max_depth参数、min_samples_leaf参数、min_samples_split参数和max_features参数,完成训练,得到PM
训练后的PM
所述PM
通过以下方法对所述PM
用相同的目标特征变量和因变量分别构建多元线性回归模型、土地利用回归模型和随机森林模型;观察多元线性回归模型、土地利用回归模型和随机森林模型的预测误差,判断PM2.5预测模型的评价结果;预测误差包括均方误差、均方根误差和平均绝对误差。
使用相同的特征变量和因变量分别构建多元线性回归模型(MLR)、土地利用回归模型(LUR)和随机森林模型(RF)。MLR和LUR模型使用R语言建立。R
表2冬季PM
S5,将目标特征变量输入所述PM
对PM
由实施例的结果可知,本发明的预测方法纳入了随时间变化的特征变量,使得预测模型的参数更加全面,更准确的反映出大气污染物的影响因素,提高了预测精度,且通过一次建模即实现逐日预测,提高大气污染预测的工作效率。
虽然,本说明书中已经用一般性说明及具体实施方案对本发明作了详尽的描述,但在本发明基础上,可以对之作一些修改或改进,这对本领域技术人员而言是显而易见的。因此,在不偏离本发明精神的基础上所做的这些修改或改进,均属于本发明要求保护的范围。