一种基于中医词典的交叉融合命名实体识别方法
文献发布时间:2024-01-17 01:28:27
技术领域
本发明属于数据处理技术领域,具体为一种基于中医词典的交叉融合命名实体识别方法。
背景技术
随着互联网技术的发展和普及,电子文本等可用信息资源得到了极大的丰富。人们迫切需要从海量非结构文本中获取有用的信息,命名实体作为一个明确的概念和研究对象,是目标文本中基本的信息元素,是正确理解目标文本的基础。中文命名实体识别是关系提取、句法分析、情感识别、智能问答等文本应用领域的重要基础工具,在自然语言处理技术中占有重要地位。
目前大多数的命名实体识别任务是基于字符特征的神经网络模型BiLSTM-CRF,其原理是把句子拆分为字符,根据Word2vec等训练模型在语料库中训练每个字符的向量,获得词嵌入作为Bi-LSTM模型的输入,通过神经网络获得隐含特征,最后通过CRF来实现序列的标注。基于词语特征的神经网络模型与基于字符嵌入的模型类似,都是基于BiLSTM-CRF结构,主要区别在于词嵌入层是把句子拆分为词语,基于语料库训练每个词语的向量获得词嵌入作为Bi-LSTM模型的输入,通过神经网络获得隐含特征,最后通过CRF来实现序列的标注。这些模型都采用单一网络结构,虽然能够完成命名实体识别任务,但是受模型网络结构单一影响,命名实体识别仍然存在准确度低的问题。
发明内容
本发明的目的在于:提供一种基于中医词典的交叉融合命名实体识别方法,以提升命名实体识别准确度和鲁棒性。
为实现上述目的,本发明采用如下技术方案:
一种基于中医词典的交叉融合命名实体识别方法,包括以下步骤:
步骤1、将给出的文档作为数据集,把数据集划分为数据子集,数据子集划分为初始训练集和待识别数据集;每个初始训练集和待识别数据集均被拆分成n个句子,再将每个句子拆分成字符序列和词汇序列;
步骤2.用初始训练集构建字符级模型、词级模型和中医词典模型;字符级模型的输入为初始训练集中的字符序列,输出为与每个字符对应的实体临时标签预测结果;词级模型的输入为词汇序列,输出为与每个词汇对应的实体临时标签预测结果;中医词典模型的输入为句子与预设的中医领域的标准化专有术语词典,输出为两者的匹配结果;
步骤3、将字符级模型和词级模型作为基本模型,结合中医词典构建融合模型;融合模型包括第一融合模型和第二融合模型,其中第一融合模型由词级模型与中医词典融合而成,第二融合模型由字符级模型与中医词典融合而成;
步骤4、用待识别数据对字符级模型、词级模型、中医词典模型、第一融合模型、第二融合模型进行多轮训练,得到标注后的待识别数据集;在多轮训练中,将字符级模型与第一融合模型看成一组,词级模型对应第二融合模型看成第二组,两组交替与中医词典模型组合训练。
步骤5、利用标注后的待识别数据,采用标注融合策略生成最终预测序列。
进一步的,所述标注融合策略生成最终预测序列的方法为:
若一个实体同时被基本模型、中医词典模型和融合模型标注,则将该实体保留在最终的预测序列中;
若两个模型均标注同一个实体,另一个模型预测另一个不同的实体,且两个实体并不冲突,则保留两个预测的实体;若两个实体冲突,则保留同时被两个模型标注的实体;
若三个模型分别标注三个不同实体:三个实体之间不存在冲突,则保留三个实体;三个实体中有两个实体冲突,保留不冲突的实体,对冲突的另外两个实体按优选级从高到低保留其中一个实体;若三个实体相互存在冲突,按优选级从高到低保留一个实体;实体保留的优先级顺序同上;优先级从高到低为:融合模型、中医词典模型、基本模型。
进一步的,所述中医词典模型采用了动态滑动窗口,对句子与预设的中医领域的标准化专有术语词典进行匹配处理;所述动态滑动窗口是指窗口长度动态改变,窗口长度初始长度为1,从1增加至外部词典中最大词汇长度;匹配时,滑动窗口头部,从句子的第一个字符开始,每次移动一个字符大小,直到窗口尾部达到语句末尾为止;每次移动窗口就匹配当前窗口在词典中出现的词汇;最后把所有的词汇收集为当前语句的集合。
进一步的,所述预设的中医领域的标准化专有术语词典包括《中医病证分类与代码》、《中医临床诊疗术语》,根据需求选择。
本发明提供的一种基于中医词典的交叉融合命名实体识别方法,通过构建字符级模型、词级模型、中医词典模型、融合模型,利用上述模型完成命名实体识别任务。其中融合模型是在原有字符级模型和词级模型的基础上,引入中医领域的标准化专有术语词典,并基于该术语词典衍生的两个包含外部词汇的融合模型,通融合模型的引入丰富了模型多样性。将字符级模型与第一融合模型看成一组,词级模型与对应第二融合模型看成第二组,在多轮训练时,两组模型交替与中医词典模型组合训练,完善标注结果;并融合所有标注结果来获取最终预测序列,完成命名实体识别。
与现有技术相比,本发明在融合模型与融合所有模型标注结果的协同下,提升了识别准确度和鲁棒性。
附图说明
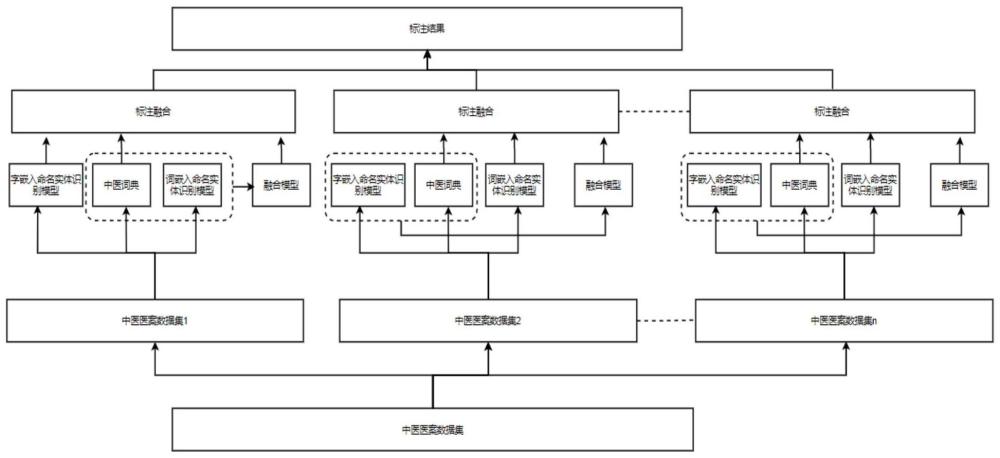
图1为为实施例整体训练模型;
图2为字符级模型表示图;
图3为词级模型表示图;
图4为第一融合模型;
图5为第二融合模型。
具体实施方式
如图1所示,本实施例提供的一种基于中医词典的交叉融合命名实体识别方法,包括以下步骤:
步骤1、将给出的文档作为数据集,并对数据集进行划分,数据集的划分方法为:
先将数据集划分为数据子集,数据子集划分为初始训练集和待识别数据集,其中初始训练集用于构建模型,待识别数据集用于训练模型。每个初始训练集和待识别数据集均被拆分成n句子,再将句子拆分成字符序列和词汇序列。
本实施例中,给出的文档集表示为:D={d
步骤2、基于字符序列构建字符级模型,基于词汇序列构建词级模型,结合句子与预设的中医领域的标准化专有术语词典构建中医词典模型。
构建字符级模型,如图2所示,字符级模型的输入为初始训练集中的字符序列,输出为与每个字符对应的实体临时标签预测结果。字符级模型包括双向LSTM网络、输出层和隐藏层,其预测过程如下:
a1、单词首先映射到一个向量,从而产生一个单词嵌入序列。将单词嵌入序列作为双向LSTM的输入,以使前向移动的和后向移动的输出层连接起来,从而创建特定于上下文的表示信息。具体方法如下:
句子s
把每个字符c
其中e
其中
a2、使用CRF条件随机场作为输出层,利用CRF条件随机场对特定于上下文的表示信息进行标注,本实施例在此过程中,将先前预测的标签设置为当前标签的预测条件。
所述隐藏层根据输出层输出的标注信息,预测每个字符的概率分数,以获得可能的目标标签,得到与每个字符对应的实体临时标签输出。
a3、通过最小化分类交叉熵优化模型:
其中,P(y
构建词级模型,词级模型的输入为拆分得到的词汇序列,输出为与每个词汇对应的实体临时标签预测结果。词级模型与字符级模型结构相同,与字符级模型不同的是,其嵌入层不同。具体实现过程如下如图3所示:
b1、词汇先映射到一个向量,从而产生一个词汇嵌入序列。将这词汇嵌入序列作为双向LSTM的输入,使前向移动和后向动的输出层连接起来,得到特定于上下文的表示信息。即:
把每个词w
其中e
隐藏层设于双向LSTM的顶部,用于检测更深级别的特征信息d
d
其中W
构建中医词典模型,中医词典模型的输入为步骤1得到的句子与预设的中医领域的标准化专有术语词典,输出为两者的匹配结果。
构建词典模型需要提供外部词典,以用于后期匹配。本实施例中采用的词典是中医领域的标准化专有术语词典,能够根据实体识别的类型匹配不同的外部词典。如做中医证型的命名实体识别,则采用国家中医药管理局颁布的《中医病证分类与代码》,作为外部词典。如做症状识别,则采用《中医临床诊疗术语》作为外部词典。
因为词典中每个词汇的大小不同,如果采用固定大小的窗口,不能匹配所有的词汇,所以采用动态滑动窗口,窗口长度动态改变,从最开始大小为1,增加到大小为词典中最大词汇长度。滑动窗口头部,从句子的第一个字符开始,每次移动一个字符大小,直到窗口尾部达到语句末尾为止。每次移动窗口就匹配窗口在词典中出现的词汇。最后把所有的词汇收集为当前语句的集合。
max_len=max(|dicW
Set
K=Set
其中max_len表示词典中词汇的最大长度,match代表字符匹配,如果滑动窗口包裹的词汇出现在词典中,则输出。len代表滑动窗口大小,Set
步骤3、将字符级模型和词级模型作为基本模型,结合中医词典构建融合模型。融合模型包括第一融合模型和第二融合模型。如图4所示,第一融合模型由词级模型与中医词典融合而成。如图5所示,第二融合模型由字符级模型与中医词典融合而成。
相较于字符级模型,词级模型受到分词效果的影响,在通用领域标注准确度更高,然而在一些专有领域其准确度仍待提升。本实施例通过在词级模型中引入外部词典构建第一融合模型,配合在字符级模型中引入外部词典构建的第二融合模型,使其能够识别出之前未见过的专有词汇的表示形式,并获得上下文句法信息,实现了专有领域准确度的提升。
第一融合模型的输出是由单个词汇构建的联合表示,对于每个词,其特征表示由两部分构成,其中h
第二融合模型与第一融合模型类似,同样具有两个可选的特征表示,其中h
步骤4、用待识别数据对字符级模型、词级模型、中医词典模型、第一融合模型、第二融合模型进行多轮训练,得到标注后的待识别数据集;在多轮训练中,将字符级模型与第一融合模型看成一组,词级模型与对应第二融合模型看成第二组,两组交替与中医词典模型组合训练。
为了保持输出结果的多样性,本实施例在训练过程中没有采用固定结构,而是随着模型的训练过程动态地改变。即在每一批次数据训练过程中采用三种模型:第一种是基本模型,即字符级模型和词级模型,每一次只能选其中一种基本模型,并在下一批次更换为另一种基本模型。第二种是中医词典模型,通过输入待识别数据中的句子,与预设的中医领域的标准化专有术语词典进行匹配,并将匹配的所有标注结果输出。第三种是联合模型,是本轮训练没有被选中的另一个基本模型与另一个中医词典模型联合得到的融合模型。这样可以保证每一批次数据都有基本的原生的命名实体识别模型,也有改进的词典模型联合另一个原生模型,也有原生的词典匹配结果。
具体来讲:把训练过程分为n步,把待识别数据集分为n份。在第一步训练过程中,用于训练的三种模型分别是:字符级模型、中医词典模型、第一融合模型,将第一份待识别数据集分别输入上述三种模型,进行训练获得标注。在第二步训练过程中,用于训练的三种模型分别是:词级模型、中医词典模型、第二融合模型,第二份待识别数据集分别输入三种模型进行训练获得标注。如此反复,直到训练完n批次数据集为止,。
步骤5、根据标注后的待识别数据,生成最终预测序列。
本实施例将每一批次数据训练过程中的基本模型、中医词典模型、融合模型分别表示为Ma和Mb和Mc。根据标注融合策略生成最终预测序列Y的方法为:
若一个实体同时被Ma和Mb和Mc标注,则将该实体保留在最终的预测序列中。
若两个模型均标注同一个实体,另一个模型预测另一个不同的实体,且两个实体并不冲突,则保留两个预测的实体;若两个实体冲突,则保留同时被两个模型标注的实体;
若三个模型分别标注三个不同实体:三个实体之间不存在冲突,则保留三个实体;三个实体中有两个实体冲突,保留不冲突的实体,对冲突的另外两个实体按优选级从高到低保留其中一个实体;若三个实体相互存在冲突,按优选级从高到低保留一个实体;实体保留的优先级顺序同上;优先级从高到低为:融合模型、中医词典模型、基本模型。
以上所述,仅为本发明的具体实施方式,在上述内容中所述的字符级模型根据其实现方式亦可称为字嵌入识别模型,词级模型亦可称为词嵌入识别模型。需要说明的是,本说明书中所公开的任一特征,除非特别叙述,均可被其他等效或具有类似目的的替代特征加以替换;所公开的所有特征、或所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以任何方式组合。