基于数值模拟的神经网络预测炉膛氧气浓度系统及方法
文献发布时间:2023-06-19 09:24:30
技术领域
本发明是基于数值模拟的神经网络预测炉膛氧气浓度系统及方法,尤其涉及神经网络学习机预测炉膛氧气浓度,属于神经网络应用领域。
背景技术
燃煤锅炉在运动中产生含有CO
目前对锅炉氧浓度测量大部分停留在对烟气的氧含量测量上,导致无法准确得知炉膛内部氧含量的具体分布,无法准确对送引凤量与角度进行控制。
为了保证锅炉稳定运行,锅炉炉膛内煤粉燃料的燃烧过程必须在可控范围内,这就需要对炉膛氧气浓度有准确的了解。而传统的测量方法在测量精度和效率上有待提高,且受人为因素影响较大。
CFD数值模拟技术拥有丰富的数学计算模型,能够准确的反映出流体流动、传热、燃烧等过程。但仅仅使用CFD预测,会有操作步骤多,工作量大,仿真模拟速度慢,数值分析过程耗时长、典型工况覆盖面窄等问题。而神经网络是通过机器的计算来模拟人脑,客观真实、处理信息量大、计算速度快、通过简便快捷的方式处理复杂问题、能较为精准的预测未来。因此现提出一种基于数值模拟的利用神经网络预测炉膛氧气浓度的方法,提升计算效率。
发明内容
为了解决传统氧气浓度测量方法测量精度不足和效率低的问题,本发明提出了一种基于数值模拟的神经网络预测炉膛氧气浓度系统及方法,具体方案如下:
方案一:该系统包括数值模拟仿真模块,数据处理模块,算法预测模块和实现模块,上述各模块之间呈递进逻辑关系连接;
其中数值模拟仿真模块负责建立炉膛内部的物理模型;
数据处理模块用于处理数值模拟结果;
算法预测模块负责构建双层BP神经网络模型、MLP神经网络模型和DBN神经网络模型;
实现模块负责选出最佳算法从而实现氧量分布预测。
方案二:基于数值模拟的神经网络预测炉膛氧气浓度方法,是基于权利要求1所述的系统为基础实现的,其特征在于:具体方法步骤如下:
步骤一,通过所述的数值模拟仿真模块,利用数值模拟软件建立炉膛内部的物理模型,进行仿真运算;
步骤二,利用所述的数据处理模块,将数值模拟结果进行处理;
步骤三,所述的算法预测模块建立双层BP神经网络模型、MLP神经网络模型和DBN神经网络模型并进行算法预测;
步骤四,通过所述的实现模块选择出最佳算法从而实现炉膛内氧量分布的预测。
进一步地,步骤一中的仿真过程的具体步骤为:
步骤一一,根据锅炉运行数据与设计数据,建立锅炉物理模型;
步骤一二,选取CFD计算用煤质数据、一、二次风风温及分配方式,确定数值模拟计算边界条件;
步骤一三,选择湍流、多相流、对流、辐射及煤粉的燃烧机理的模型,利用fluent软件对锅炉燃烧进行全炉膛的数值仿真,从而得到炉膛内部任意位置的氧气浓度分布数据;
步骤一四,确定研究对象为炉膛内氧量分布,通过ANSYS Fluent软件的export功能输出TXT格式实验数据,并根据现场经验与相关的资料分析氧含量有关的锅炉运行变量;
上述运行变量包括:锅炉内部各点坐标x,y,z,各点流体旋度和速度,CO,CO
进一步地,步骤二中所述的数据处理模块,数据分析和模拟结果处理过程,具体过程如下:
步骤二一,经仿真模拟后输出的数据矢量,通过数据矢量的维度和单位建立方程,将维度达到输入变量数的维数;
步骤二二,将数据标准化处理之后,采用数据挖掘与主成分析法进行数据集划分,参数处理,整合冗余和降低维数处理;经处理后得到自动得到主成分,最终采用的数据聚类方式为k均值聚类算法。
进一步地,所述的算法预测模块建立双层BP神经网络模型、MLP神经网络模型和DBN神经网络模型三种算法预测模型,具体建立步骤如下:
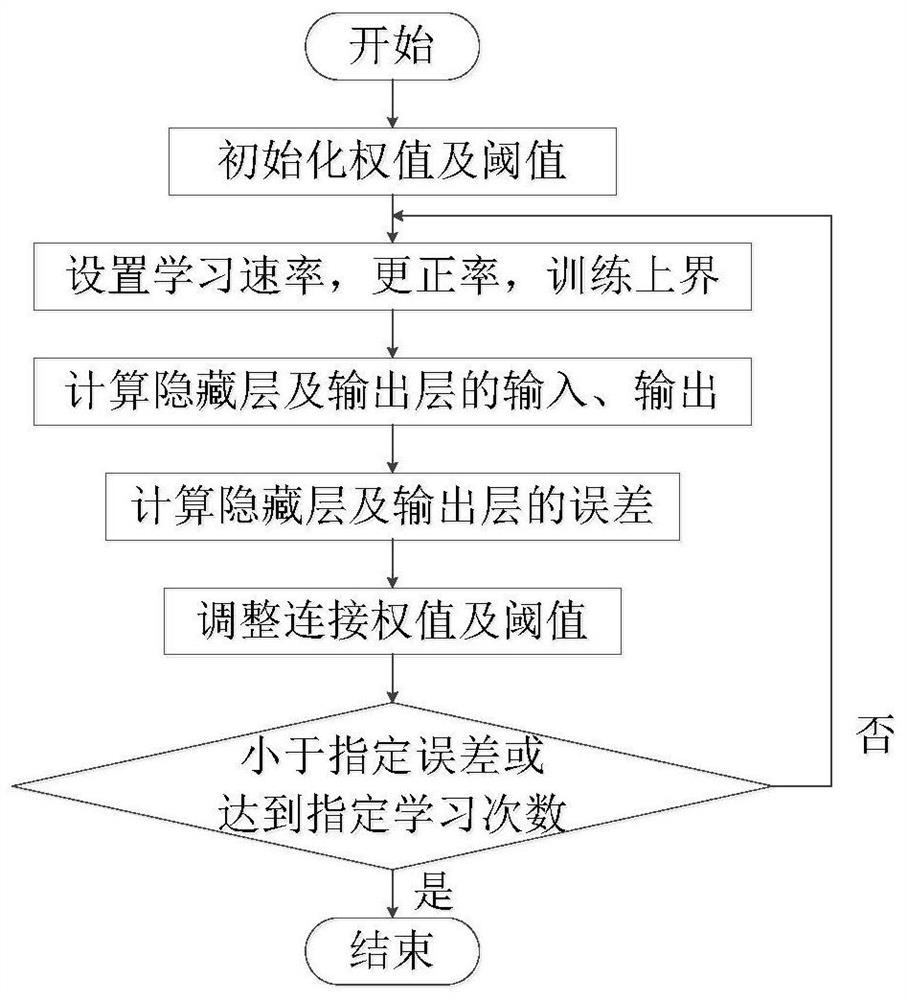
所述的步骤三中,双层BP神经网络模型预测氧量,神经网络模型中,输出层为氧含量浓度,记录每层隐含层节点个数、限定输入层节点数和迭代次数、定义输入层到隐含层权重和隐含层到输出层权重、隐含层的阈值和输出层的阈值,设置学习速率和最小误差。
循环以上过程直至误差满足精度要求或学习次数大于设定的最大次数,训练过程结束,最终对测试集输出氧浓度分布预测数据进行结果分析与评价;
所述的步骤三中,MLP神经网络模型预测氧量,将所述的数据处理模块处理后的数据分别作为训练集数据与测试集数据,从而建立MLP预测模型,确定寻优的目标函数,并转换为相应的适应值函数.经计算模型误差和反向调整后,测试不同参数于2-5层的各数量隐含层,在收敛性判定满足要求的情况下,确定参数于具有3层隐含层的MLP(S)的精确度较高且效率最高;
所述的步骤三中,DBN神经网络模型预测氧量,深度置信网络由多层RBM叠加与最后一层回归的神经网络组成,数据通过模型最底层输入,经过RBM到隐含层,低层RBM的输出作为高层RBM的输入,两层RBM组成的DBN模型,DBN的训练方法首先进行自下而上的无监督学习方法来逐层对整个DBN模型的参数进行初始化,后采取自上而下的有监督学习方法将网络参数进行微调。
进一步地,通过所述的实现模块将双层BP神经网络模型、MLP神经网络模型和DBN神经网络模型这三种算法模型集成,整合成神经网络学习机,通过此学习机预测炉膛内部氧量分布,将训练数据通过神经网络学习机训练网络,分别形成三种不同的神网络;
将验证集的输入数据分别通过这三种网络,得到预测结果,通过比对拟合程度,均方根误差等评价指标,选出结果最好的算法,为最终的预测算法;设计好要预测的工况,包括各点流体旋度和速度;CO,CO
本发明的有益效果体现在:
1.本发明基于数值模拟结果,利用fluent软件对锅炉燃烧进行全炉膛的数值仿真,从而得到炉膛内部任意位置的氧气浓度分布数据,将无法观察的炉膛内部氧气分布场,用数据进行可视化。
2.本发明将BP、MLP、DBN三种神经网络算法集成,选择预测效果最好的算法进行预测,比单纯用一种算法进行预测的准确率高,对火电机组炉膛氧气浓度进行模拟预测,以提高锅炉燃烧效率。
3.本发明基于数值模拟结果利用神经网络算法预测炉膛氧气浓度。数值模拟会有操作步骤多,工作量大,仿真模拟速度慢,数值分析过程耗时长、典型工况覆盖面窄等问题。而神经网络是通过机器的计算来模拟人脑,客观真实、处理信息量大、计算速度快、通过简便快捷的方式处理复杂问题、能较为精准的预测未来,提升计算效率。
4.基于数值模拟的利用神经网络预测炉膛内部氧量的方法,提升计算效率,省去大量数值模拟操作步骤及计算时间,准确的掌握火电机组实际运行过程中氧量的分布,进一步通过调节改善锅炉炉膛内部的燃烧情况,从而维持火电机组运行的稳定性,进一步提高机组效率。
附图说明
图1是BP神经网络算法流程图;
图2是DBN网络结构图;
图3是BP预测结果示意图;
图4是MLP预测结果示意图;
图5是DBN预测结果示意图。
具体实施方式
结合附图1-5说明本实施例,具体实施过程如下:
具体实施方式一:基于数值模拟的神经网络预测炉膛氧气浓度系统,该系统包括数值模拟仿真模块,数据处理模块,算法预测模块和实现模块,上述各模块之间呈递进逻辑关系连接,其中数值模拟仿真模块负责建立炉膛内部的物理模型,数据处理模块用于处理数值模拟结果,算法预测模块负责构建双层BP神经网络模型、MLP神经网络模型和DBN神经网络模型,实现模块负责选出最佳算法从而实现氧量分布预测。
具体实施方式二:基于数值模拟的神经网络预测炉膛氧气浓度方法,针对采集的离线数据,用数值模拟软件建立炉膛的物理模型,并在ICEM中对其网格进行划分及边界设定;利用ANSYS FLUENT对划分好的模型进行求解仿真,得到数据结果;利用数据处理方法处理数值模拟结果;利用神经网络学习机进行预测,最终实现炉膛内部氧量分布的预测,为实现锅炉实际运行提供理论和实践依据,包括以下步骤:
一)、数值模拟仿真:利用数值模拟软件建立炉膛内部的物理模型,仿真运算。
二)、数据处理:处理数值模拟结果。
三)、算法预测:利用三种神经网络算法预测。
四)、结果应用:从三种神经网络选择效果最佳算法,预测指定工况下的燃烧器出口风量。
具体实施步骤如下:
(1)CFD仿真:
根据锅炉运行数据与设计数据,建立锅炉物理模型,选取CFD计算用煤质数据、一、二次风风温及分配方式,确定数值模拟计算边界条件;选择合理的湍流、多相流、对流、辐射及煤粉的燃烧机理等模型,利用fluent软件对锅炉燃烧进行全炉膛的数值仿真,从而得到炉膛内部任意位置的氧气浓度分布数据。
确定研究对象为炉膛内氧量分布,通过ANSYS Fluent软件的export功能输出TXT格式实验数据,根据现场经验与相关的资料分析氧含量有关的锅炉运行变量,从中确定18个变量,这18个变量包括:锅炉内部各点坐标x,y,z,各点流体旋度和速度,CO,CO2,N2,O2,H2O,SO2浓度,温度,压强和挥发分等。
(2)数据分析:
经仿真模拟后输出的数据矢量数量达到120W,且每组数据矢量的维度和单位都不同,维度达到18维,直接使用或直接分组使用会导致数据分析不准确,预测精度不高,预测时间加长。并且如果计算机计算能力不够,会导致无法得出结果。
为了提高锅炉运行过程中氧浓度的预测精度和速度,在将数据标准化处理之后,采用数据挖掘与主成分析法进行数据集划分,参数处理,整合冗余,降低维数。经处理后得到的6个和7个主成分。
无论的深度学习还是机器学习或者是神经网络,预测集中预测单点的速度要远远高于训练集中单点的预测速度。尤其是在高维数据组中,为了提高预测的速度并且提高预测的精度,更要在合理的范围内,尽量少的选取更具代表性的点的各个参数作为训练集的组成,因此本文选取数据聚类与分类的方式对上文中处理过的数据进行进一步的数据挖掘处理。
综合考虑到本文仿真实验数据的性质:具有维数高,数量大,比较复杂,但输入数据具有确定性,并且数据输入顺序于网格划分的顺序一致的特点,需要很高的聚类质量等特点;决定采用的数据聚类方式为k均值聚类算法(K-means)。
(3)神经网络学习机预测:
BP神经网络预测氧量
在本文采用的典型的双层BP神经网络模型中,输出层为氧含量浓度,每层隐含层节点为100个,输入层节点数分别为13;迭代次数为1000次,输入层到隐含层权重为w
循环以上过程直至误差满足精度要求或学习次数大于设定的最大次数,训练过程结束。
最终对测试集输出氧浓度分布预测数据进行结果分析与评价。
具体实施方式二:除实施方式一中所述的神经网络学习机,还可采用MLP预测氧量,实施方式如下:
将构建神经网络之前处理好的数据分别作为训练集数据与测试集数据,建立MLP预测模型,隐含层激活函数与输出层激活函数都为Sigmoid函数。标度因变量正态化为0.02。确定寻优的目标函数,并转换为相应的适应值函数.经计算模型误差和反向调整后(测试不同参数于2-5层的各数量隐含层),在收敛性判定满足要求的情况下,确定参数于具有3层隐含层的MLP(S)的精确度较高且效率最高。
输入测试集数据进行测试。对测试集输出氧浓度分布预测数据进行结果分析与评价。
具体实施方式三:除实施方式一中初所述的神经网络学习机,还可采用DBN预测氧量,深度置信网络(DBN)由多层RBM叠加与最后一层回归的神经网络组成。数据通过模型最底层输入,经过RBM到隐含层,低层RBM的输出作为高层RBM的输入,如图2所示为两层RBM组成的DBN模型。DBN的训练方法首先进行自下而上的无监督学习方法来逐层对整个DBN模型的参数进行初始化,后采取自上而下的有监督学习方法将网络参数进行微调。
编写程序将BP神经网络,多层感知机MLP,深度信念神经网络DBN这三种算法集成,整合成神经网络学习机,通过此学习机预测炉膛内部氧量分布。将训练数据通过神经网络学习机训练网络,分别形成三种不同的神网络。将验证集的输入数据分别通过这三种网络,得到预测结果。通过比对拟合程度,均方根误差等评价指标,选出结果最好的算法,为最终的预测算法。
具体实施方式四:根据上述实施例的系统构建过程,最终实现应用的结果如下:
设计好要预测的工况,包括各点流体旋度和速度;CO,CO
数据集通过BP神经网络,多层感知机MLP,深度信念神经网络DBN,这三种神经网络后,选出误差小、准确率高的算法,三者预测实际炉内氧气浓度如附图所示,采用机器学习算法预测结果,从图中可以看出,BP和DBN预测和实际有部分结果有偏差,MLP预测和实际结果大致重合。
算法评价指标有平均绝对误差MAE,均方误差MSE,均方根误差RMSE。其中MAE,MSE,RMSE越小表示误差越小,算法评价结果表所示:
从表中可以看出,MLP的MAE,MSE,RMSE最小,因此选择MLP作为最终预测算法。
以上实施例只是对本专利的示例性说明,并不限定它的保护范围,本领域技术人员还可以对其局部进行改变,只要没有超出本专利的精神实质,都在本专利的保护范围内。
- 基于数值模拟的神经网络预测炉膛氧气浓度系统及方法
- 一种基于数值模拟利用回归算法预测炉膛氧气浓度的方法