基于单哈希均分布隆过滤器的重复数据删除技术实现方法
文献发布时间:2023-06-19 09:24:30
技术领域
本发明涉及计算机技术领域,具体涉及基于单哈希均分布隆过滤器的重复数据删除技术实现方法,
背景技术
现如今网络应用中经常有大量的数据排查,资格审查的需求,比如重复数据删除技术,在其中添加一个过滤器结构通常是不错的解决方案,其中布隆过滤器是最常使用的结构之一。尽管布隆过滤器在网络应用程序中有广泛的应用,但由于标准布隆过滤器(Standard Bloom filter,SBF)中对哈希函数的高要求(相互独立和良好的随机性)和有限的储存空间,导致布隆过滤器消耗的资源变多,算力下降,性价比降低。(此处可以举例)因此如何减少布隆过滤器消耗的资源,同时尽可能降低布隆过滤器的假阳性概率成为了研究的一大重点内容。
在重复数据删除技术中,有使用双重布隆过滤器结构以减小假阳性概率(张瑞,温蜜.基于Bloom Filtering检测的安全重复数据删除技术分析[J].上海电力学院学报,2017,33(04):402-406.),但使用的是标准布隆过滤器依然需要多个高要求的哈希函数消耗计算资源,还有使用技术布隆过滤器的方法(周斌,王晶奇,张莹.布隆过滤器在重复数据删除中的应用[J].电脑知识与技术,2014,10(08):1793-1795.),虽然可以实现数据的插入和删除但是依然需要使用多个高要求的哈希函数消耗计算资源,本发明提出的基于单哈希均分布隆过滤器的重复数据删除技术实现方法可以降低布隆过滤器本身需要消耗的计算资源,并且可以和双重布隆过滤器和技术布隆过滤器叠加使用。
本发明提出的基于单哈希均分布隆过滤器的重复数据删除技术实现方法,理论上假阳性概率接近标准布隆过滤器,但不需要依赖大量的高要求哈希函数,只需要选用一个同分区性能优秀的哈希函数,同时均等分区保证了单哈希均分布隆过滤器不错的稳定性。单哈希均分布隆过滤器的查询速度远快于标准布隆过滤器,且十分稳定,同时保持假阳性概率非常接近标准布隆过滤器。
事实上,单哈希均分布隆过滤器首先使用一个分区范围内高要求的哈希函数,其次依然由k个哈希函数生成k个哈希映射,但采用的k个哈希函数是计算量极低的取模运算,然后再放缩映射到大小相同的分区。取模运算虽然简单却能保证k个哈希函数的相对独立,相较于标准布隆过滤器的k个全域高要求的哈希函数,只需要选取其中的一个或分区范围内的高要求哈希函数作为母函数,这样就把计算量降低至少是标准布隆过滤器的1/k(甚至更低),虽然需要计算取模和均等分区映射的计算量,显然后续映射的计算量相较母函数而言不在同一个数量级。应用到重复数据删除技术等需要大数据过滤的情况中可以有更好的表现。
发明内容
本发明解决的技术问题是:提出一种应用于数据删除技术的基于高效率低假阳性的单哈希均分布隆过滤器方法。
本发明的目的至少通过如下技术方案之一实现。
基于单哈希均分布隆过滤器的重复数据删除技术实现方法,包括以下步骤:
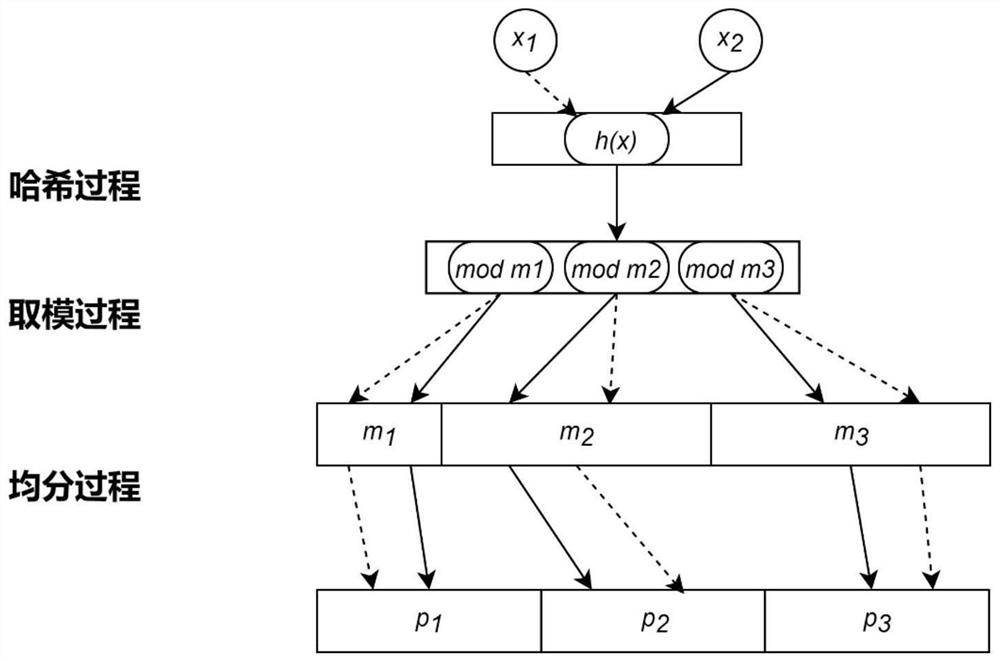
S1、确定存储区域长度,确定分区长度,确定需要存储的包括D个数据的第一数据集D1,令j=1,确定待查询的第二数据集D2;
S2、选择一个存储区域范围内的高要求哈希函数,取第一数据集D1中的第j个数据d
S3、将哈希值通过k个互相独立的取模运算计算出k个取模后的模值;
S4、将k个模值缩放映射到k个大小均分的区域,在各个分区中记录k个映射值;
S5、若j<D,则j=j+1,返回步骤S2,否则单哈希均分布隆过滤器存储信息生成完毕;
S6、根据第二数据集D2中的数据生成新的单哈希均分布隆过滤器信息,和步骤S5中已保存的存储信息进行对比检测,若未被单哈希均分布隆过滤器拒绝,则此数据为非重复数据,否则为重复数据,实现重复数据的删除。
进一步地,步骤S1中,存储区域长度是单哈希均分布隆过滤器的存储大小M,则最终各个分区的长度为M/k取整数部分,最后一块分区的长度可以小于M/k。
进一步地,步骤S2中,所述高要求哈希函数是要求该哈希函数发生哈希冲突的概率极低,包括但不仅限于MD5信息摘要算法(MD5 Message-Digest Algorithm,MD5)和循环冗余校验(Cyclic Redundancy Check,CRC)。
进一步地,步骤S3中,k个取模运算只需要满足k个取模互质,就可以保证满足k个取模运算相互独立,原理具体如下:
若哈希函数h(x)在区间[0,m
具体取值包括以下步骤:
S3.1、寻找k个最接近M/k的质数;
S3.2、利用哈希值对质数进行取模运算,得到k个取模的值。
进一步地,步骤S4中,均等分区映射可以很好的避免分区区间差距过大,将k个值缩放映射到k个大小均分的区域包括以下步骤:
S4.1、计算放缩映射f
S4.2、将对应的各个分区映射位的值设置为1,其余位置保持不变。
进一步地,步骤S6具体如下:
依次引入待查询的第二数据集D2中的数据,通过步骤S2、步骤S3和步骤S4计算出的各个分区的映射位,和步骤S5中保存的单哈希均分布隆过滤器的各个分区保存的映射位的值作比较,如果有根据带查询数据计算的任意分区对应的映射位的值为0,就代表此数据被保存的单哈希均分布隆过滤器拒绝,此带查询数据就一定是非重复数据,否则根据根据带查询数据计算的所有分区对应的映射位值都为1,则代表发现了重复数据,进而对其进行删除。
进一步地,对比不使用单哈希均分布隆过滤器有明显的提升,对比标准布隆过滤器,模运算的计算量要比高要求哈希函数运算量小,等分区映射通过的运算相对高要求哈希函数运算而言也相对简单,总体上相较于标准布隆过滤器运算量至少为其的2/k。
进一步地,在单哈希均分布隆过滤器中有两部分会发生假阳性,一种在哈希映射阶段发生,即哈希碰撞,用B表示此阶段发生假阳性。另一种是在取模和分区映射阶段产生假阳性,若哈希阶段未发生碰撞,但是取模和分区阶段发生碰撞,这样也会产生假阳性,综上,单哈希均分布隆过滤器的假阳性概率如下:
其中P(F)表示单哈希均分布隆过滤器发生假阳性的概率,P(B)的概率是哈希阶段的哈希碰撞概率,如果该过程发生假阳性,则单哈希均分布隆过滤器必然发生假阳性,P(B)和标准布隆过滤器中单个哈希函数的假阳性概率相同,即:
当H足够大,且远大于单哈希均分布隆过滤器的大小(即H>>m),则P(B)的值接近于零,可以忽略不计。取模部分的假阳性概率:
由于函数
其中m
可见p1在这个范围内取值,若m
其中
可以看出同分区后的假阳性概率不再波动而是趋于标准布隆过滤器的假阳性概率,但是同分区映射过程对部分分区产生了压缩,其中这部分造成的影响:
当m
相比于现有技术,本发明的优点在于:
本发明生成的单哈希均分布隆过滤器有高计算效率和低假阳性概率,相比较标准布隆过滤器减少了运算的消耗,提升了查询效率,理论上保证了取模过程的相互独立同时可以保证低假阳性概率,能在重复数据删除技术中进行大数据的快速过滤。
附图说明
图1是本实施例中单哈希均分布隆过滤器方法的流程示意图;
图2是本实施例中单哈希均分布隆过滤器方法中计算k个模值方法的流程示意图。
具体实施方式
下面结合附图及实施例,对本发明的具体实施作进一步的说明。
实施例:
基于单哈希均分布隆过滤器的重复数据删除技术实现方法,如图1所示,包括以下步骤:
S1、确定存储区域长度,确定分区长度,确定需要存储的包括D个数据的第一数据集D1,令j=1,确定待查询的第二数据集D2;
存储区域长度是单哈希均分布隆过滤器的存储大小M,则最终各个分区的长度为M/k取整数部分,最后一块分区的长度可以小于M/k。
本实施例中,第一数据集D1包含一个数据x
S2、选择一个存储区域范围内的高要求哈希函数,取第一数据集D1中的第j个数据d
所述高要求哈希函数是要求该哈希函数发生哈希冲突的概率极低,包括但不仅限于MD5信息摘要算法(MD5 Message-Digest Algorithm,MD5)和循环冗余校验(CyclicRedundancy Check,CRC)。
S3、将哈希值通过k个互相独立的取模运算计算出k个取模后的模值;
如图2所示,k个取模运算只需要满足k个取模互质,就可以保证满足k个取模运算相互独立,原理具体如下:
若哈希函数h(x)在区间[0,m
具体取值包括以下步骤:
S3.1、寻找k个最接近M/k的质数;
S3.2、利用哈希值对质数进行取模运算,得到k个取模的值。
本实施例中,寻找离8最近的3个质数为5、7、11,取模m
S4、将k个模值缩放映射到k个大小均分的区域,在各个分区中记录k个映射值;
均等分区映射可以很好的避免分区区间差距过大,将k个值缩放映射到k个大小均分的区域包括以下步骤:
S4.1、计算放缩映射f
本实施例中,m
S4.2、将对应的各个分区映射位的值设置为1,其余位置保持不变。
本实施例中,把p
S5、若j<D,则j=j+1,返回步骤S2,否则单哈希均分布隆过滤器存储信息生成完毕;
S6、根据第二数据集D2中的数据生成新的单哈希均分布隆过滤器信息,和步骤S5中已保存的存储信息进行对比检测,若未被单哈希均分布隆过滤器拒绝,则此数据为非重复数据,否则为重复数据,实现重复数据的删除,具体如下:
依次引入待查询的第二数据集D2中的数据,通过步骤S2、步骤S3和步骤S4计算出的各个分区的映射位,和S5中保存的单哈希均分布隆过滤器的各个分区保存的映射位的值作比较,如果有根据带查询数据计算的任意分区对应的映射位的值为0,就代表此数据被保存的单哈希均分布隆过滤器拒绝,此带查询数据就一定是非重复数据,否则根据根据带查询数据计算的所有分区对应的映射位值都为1,则代表发现了重复数据,进而对其进行删除。
本实施例中,假设第二数据集D2中的数据x
对比不使用单哈希均分布隆过滤器有明显的提升,对比标准布隆过滤器,模运算的计算量要比高要求哈希函数运算量小,等分区映射通过的运算相对高要求哈希函数运算而言也相对简单,总体上相较于标准布隆过滤器运算量至少为其的2/k。
在单哈希均分布隆过滤器中有两部分会发生假阳性,一种在哈希映射阶段发生,即哈希碰撞,用B表示此阶段发生假阳性。另一种是在取模和分区映射阶段产生假阳性,若哈希阶段未发生碰撞,但是取模和分区阶段发生碰撞,这样也会产生假阳性,综上,单哈希均分布隆过滤器的假阳性概率如下:
其中P(F)表示单哈希均分布隆过滤器发生假阳性的概率,P(B)的概率是哈希阶段的哈希碰撞概率,如果该过程发生假阳性,则单哈希均分布隆过滤器必然发生假阳性,P(B)和标准布隆过滤器中单个哈希函数的假阳性概率相同,即:
当H足够大,且远大于单哈希均分布隆过滤器的大小(即H>>m),则P(B)的值接近于零,可以忽略不计。取模部分的假阳性概率:
由于函数
其中m
可见p1在这个范围内取值,若m
其中
可以看出同分区后的假阳性概率不再波动而是趋于标准布隆过滤器的假阳性概率,但是同分区映射过程对部分分区产生了压缩,其中这部分造成的影响:
当m
本发明可以通过高效且低假阳性的方法过滤数据,并且可以很好的应用于重复数据删除技术中,同时与标准布隆过滤器相比,拥有更好的运算效率,更低的消耗,和更低的假阳性概率,从而可以更好的应用于各种需要快速过滤数据的算法和工程中,具有良好的可行性和实用性。
上述实施例的描述较为详尽,但仅仅表达了本发明的方法和一种可行的实施方式,并非对本发明的保护范围限制。需要指出的是,本领域的科研人员和工程人员,在本发明的框架下,可以在本实例的基础上加以若干变形或改进,同时可以应用于更多的场景,但这些都在本发明的保护范围之内。本发明的保护范围应以所附权利要求为准。
- 基于单哈希均分布隆过滤器的重复数据删除技术实现方法
- 基于单次哈希布隆过滤器的Flexible IP寻址方法及装置