人工智能处理器及其执行神经网络运算的方法
文献发布时间:2023-06-19 09:26:02
技术领域
本公开涉及图像处理,并且更具体地,涉及一种用于执行图像处理的人工智能(AI)处理器和使用该AI处理器的图像处理。
背景技术
由于人们对人工智能(AI)技术的兴趣日益增加,因此人们尝试将AI技术以嵌入式的方式应用于诸如终端设备(例如,电视(TV)和智能电话)之类的产品,并且在设备上(on-device)环境中操作该产品。
特别地,AI技术已被广泛地应用于图像处理,并且已连续开发了使用具有多层结构的人工神经网络来执行图像处理的技术。例如,已开发了用于执行各种图像处理操作的技术,例如使用人工神经网络来提高图像质量、扩大图像的大小、或者预测和重构图像缺失的区域。
当在图像处理领域中使用人工神经网络时,使用人工神经网络的图像处理需要大量的计算。特别地,当图像的大小逐渐增大或需要实时处理图像时,用于处理图像的硬件的资源和功耗会进一步增加。另外,当在除服务器以外的终端设备的设备上环境中执行图像处理时,用于减少终端设备的硬件的资源和功耗的技术变得更加重要。
发明内容
本公开的实施例提供了一种用于减少图像处理所需的终端设备的硬件的资源或功耗的人工智能(AI)处理器及其执行神经网络运算的方法。
另外,本公开的实施例提供了一种相对于各种图像大小能够自适应地进行操作的AI处理器、一种执行神经网络运算的方法以及一种神经网络运算平台。
附加方面部分地将在下面的描述中进行阐述,部分地将根据该描述而变得清楚。
根据本公开的示例实施例,一种人工智能(AI)处理器包括:至少一个存储器;多个神经网络运算器,包括被配置为处理图像的电路;以及控制器,包括被配置为控制至少一个存储器和多个神经网络运算器的电路。控制器可以被配置为控制将输入的图像数据存储在至少一个存储器中,并且控制多个神经网络运算器中的至少一个神经网络运算器对基于图像的大小和多个神经网络运算器的数据处理能力分割而成的图像数据执行神经网络运算,并且输出放大的图像数据。
根据本公开的另一示例实施例,一种由AI处理器执行的用于执行神经网络运算的方法,包括:接收图像的输入的图像数据,并且将该输入的图像数据存储在至少一个存储器中;基于图像的大小和多个神经网络运算器的数据处理能力对存储在至少一个存储器中的输入的图像数据进行分割;通过多个神经网络运算器中的至少一个神经网络运算器对分割而成的图像数据执行神经网络运算;以及输出放大的图像数据作为通过至少一个神经网络运算器执行神经网络运算的结果。
附图说明
根据结合附图的以下详细描述,本公开的某些实施例的上述和其它方面、特征和优点将更清楚明白,在附图中:
图1是示出了根据本公开的实施例的示例人工智能(AI)编码过程和示例AI解码过程的图;
图2是示出了根据本公开的实施例的AI解码装置的示例配置的框图;
图3是示出了根据本公开的实施例的显示设备的示例配置的框图;
图4是示出了根据本公开的实施例的AI处理器的示例配置的框图;
图5是示出了根据本公开的实施例的包括多个神经网络运算器的AI处理器的示例配置的框图;
图6是示出了根据本公开的实施例的示例神经网络运算的图;
图7是示出了根据本公开的实施例的基于图像的大小来执行神经网络运算的示例过程的图;
图8是示出了根据本公开的实施例的用于基于图像的大小来执行神经网络运算的示例AI处理器的框图;
图9是示出了根据本公开的实施例的多个神经网络运算器处理图像数据的示例过程的图;
图10是示出了根据本公开的另一实施例的多个神经网络运算器处理图像数据的示例过程的图;
图11是示出了根据本公开的另一实施例的多个神经网络运算器处理图像数据的示例过程的图;以及
图12是示出了根据本公开的实施例的由AI处理器执行的用于执行神经网络运算的示例方法的流程图。
具体实施方式
本公开允许本公开的各种改变和众多示例实施例。本公开的各种示例实施例将在附图中示出并在下面更详细地进行描述。然而,这并非旨在将本公开限制为本公开的任何特定实施例,并且应当理解,本公开涵盖不脱离本公开的精神和技术范围的所有改变、等同和/或替代方式。
在本公开中,当认为相关技术的某些详细说明可能会不必要地模糊本公开的主旨时,可以对其进行省略。另外,在本公开的描述中使用的编号(例如,第一、第二等)仅仅是用于将一个组件与另一个组件区分开的标识符号。
另外,当在本文中提到一个组件“连接”或“耦接”到另一个组件时,尽管该一个组件可以直接连接或直接耦接到该另一个组件,但是应理解的是,除非另外具体说明,否则该一个组件可以通过他们之间的另外一个组件连接或耦接到该另一个组件。
另外,关于本文中以“...器/件(单元)”、“模块”等表示的组件,可以将两个或更多个组件组合为一个组件,或者可以针对每个细分功能将一个组件划分为两个或更多个组件。另外,下面要描述的每个组件除每个组件的主要功能之外还可以附加地执行其他组件的一些或全部功能,并且每个组件的主要功能中的一些功能可以由其他组件执行。
贯穿本公开,表述“a、b或c中的至少一个”表示仅a、仅b、仅c、a和b两者、a和c两者、b和c两者、a、b和c的全部、或其变体。
另外,在本公开中,“图像”可以例如但不限于表示视频的静止图像(或者图像帧)、包括多个连续的静止图像的运动图像、视频等。
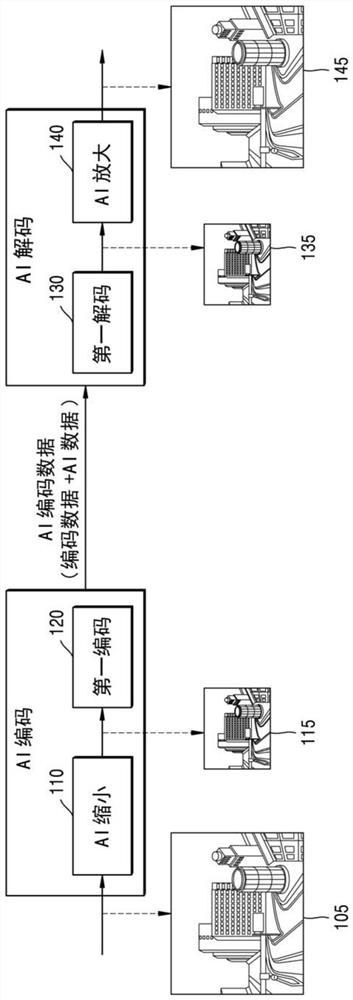
图1是示出了根据本公开的实施例的示例人工智能(AI)编码过程和AI解码过程的图。
如图1中所示,根据本公开的实施例,高分辨率的原始图像105(例如,8K图像)可以被AI缩小(downscaled)110,并且可以生成第一图像115(例如,4K图像)。在该示例中,因为对相对较低的分辨率的第一图像115执行第一编码120和第一解码130,因此与对原始图像105执行第一编码120和第一解码130的情况相比,可以大大降低处理的比特率。
在图1的AI编码过程中,原始图像105可以被AI缩小110以生成第一图像115,并且对所生成的第一图像115执行第一编码120。在AI解码过程中,可以接收作为AI编码的结果而生成的包括AI数据在内的AI编码数据和图像数据,并且可以通过第一解码130生成第二图像135(例如,4K图像),第二图像135可以被AI放大(upscaled)140由此可以生成第三图像145(例如,8K图像)。
例如,关于AI编码过程,当接收到原始图像105时,原始图像105可以被AI缩小110以生成预定分辨率或预定图像质量的第一图像115。可以在AI的基础上执行AI缩小110,并且可以将用于AI缩小110的AI与用于第二图像135的AI放大140的AI关联地进行训练。这是因为当可以单独训练用于AI缩小110的AI和用于AI放大140的AI时,作为AI编码目标的原始图像105与通过AI解码重构的第三图像145之间的差异增大。
为了维持AI编码过程与AI解码过程之间的这种关联关系,可以使用AI数据。通过AI编码过程生成的AI数据可以包括表示放大目标的信息。在该示例中,可以在AI解码过程中根据基于AI数据确认的放大目标对第二图像135进行AI放大140。
用于AI缩小110的AI和用于AI放大140的AI可以以神经网络模型(例如,深度神经网络(DNN))实现。因为用于AI缩小110的神经网络模型和用于AI放大140的神经网络模型是通过在预定目标下共享丢失信息被关联训练的,因此AI编码设备可以提供在关联训练期间使用的目标信息,并且AI解码设备可以基于所提供的目标信息将第二图像135AI放大140到目标分辨率。
例如,关于图1的第一编码120和第一解码130,可以通过第一编码120减少从原始图像105被AI缩小110的第一图像115的信息量。第一编码120可以包括下列过程:预测第一图像115以生成预测数据;生成与第一图像115与预测数据之间的差异相对应的残差数据;将作为空间域分量的残差数据变换为频域分量;对变换为频域分量的残差数据进行量化;对量化后的残差数据进行熵编码,等等。可以通过使用频率变换的各种图像压缩方法中的任何图像压缩方法实现第一编码120,所述频率变换例如但不限于MPEG-2、H.264、高级视频编码(AVC)、MPEG-4、高效视频编码(HEVC)、VC-1、VP8、VP9和AOMedia Video 1(AV1)等。
可以通过对图像数据进行第一解码130来重构与第一图像115相对应的第二图像135。第一解码130可以例如包括但不限于下列过程:对图像数据进行熵解码以生成量化后的残差数据;对量化后的残差数据进行去量化;将频域分量的残差数据变换为空间域分量;生成预测数据;使用预测数据和残差数据来重构第一图像135,等等。可以通过与使用频率变换的任何图像压缩方法相对应的图像重构方法实现第一解码130,所述频率变换例如但不限于MPEG-2、H.264、MPEG-4、HEVC、VC-1、VP8、VP9、AV1等。
通过AI编码过程生成的AI编码数据可以包括作为对第一图像115执行第一编码120的结果而生成的编码数据和与对原始图像105执行AI缩小110相关的AI数据。可以在第一解码130中使用编码数据,并且可以在AI放大140中使用AI数据。
编码数据可以例如以比特流的形式被发送。编码数据可以包括基于第一图像115中的像素值而生成的数据,例如作为第一图像115与第一图像115的预测数据之间的差异的残差数据。另外,编码数据可以包括在对第一图像115执行第一编码120中使用的信息。例如,编码数据可以包括用于对第一图像115执行第一编码120的模式信息(例如,预测模式信息、运动信息等)和在第一编码120中使用的量化参数相关信息等。可以根据使用频率变换的图像压缩方法之中的在第一编码120中使用的图像压缩方法的规则(例如,语法)来生成编码数据,所述频率变换例如但不限于MPEG-2、H.264 AVC、MPEG-4、HEVC、VC-1、VP8、VP9、AV1等。
可以基于神经网络运算将AI数据用于AI放大140。如上所述,因为用于AI缩小110的神经网络模型和用于AI放大140的神经网络模型是被关联训练的,因此AI数据可以包括用于能够精确地对第二图像135进行AI放大140的信息。在AI解码过程中,可以基于AI数据将第二图像135AI放大140到目标分辨率或图像质量。AI数据可以与编码数据一起以比特流的形式被发送。根据实现示例,可以以帧或分组的形式与编码数据分开地发送A1数据。可以通过同构网络或异构网络发送作为AI编码的结果而生成的编码数据和AI数据。
图2是示出了根据本公开的实施例的AI解码装置200的示例配置的框图。
参考图2,根据本公开的实施例的AI解码装置200可以包括通信器(例如,包括通信电路)212、解析器(例如,包括解析电路)214和AI解码器(例如,包括处理电路和/或可执行程序元件)220。AI解码器220可以包括第一解码器222和AI放大器224。
通信器212可以包括各种通信电路,并且通过网络接收作为AI编码的结果而生成的AI编码数据。作为AI编码的结果而生成的AI编码数据可以包括上述编码数据和AI数据。可以通过同构网络或异构网络来接收编码数据和AI数据。
解析器214可以包括各种解析电路和/或可执行程序元件,并且通过通信器212接收AI编码数据,并且对AI编码数据进行解析并将其划分为编码数据和AI数据。例如,解析器214可以读取从通信器212获得的数据的头部,以确定该数据是编码数据还是AI数据。例如,解析器214可以通过经由通信器212接收的数据的头部将该数据划分为编码数据和AI数据,并且将编码数据和AI数据分别发送到第一解码器222和AI放大器224。
在本公开的实施例中,由解析器214解析的AI编码数据可以是从存储介质获得的,并且不限于通过通信器212接收。例如,可以从数据存储介质获得AI编码数据,数据存储介质包括磁性介质(诸如,硬盘、软盘和磁带)、光学记录介质(诸如,CD-ROM和DVD)、磁光介质(诸如,软盘)等。
第一解码器222可以基于编码数据来重构与第一图像115相对应的第二图像135。可以将由第一解码器222生成的第二图像135提供给AI放大器224。根据实现示例,还可以将编码数据中包括的第一解码相关信息(例如,模式信息(例如,预测模式信息、运动信息等)、量化参数(QP)信息等)提供给AI放大器224。
接收AI数据的AI放大器224可以基于AI数据对第二图像135进行AI放大。根据实现示例,AI放大器224还可以通过使用编码数据中包括的第一解码相关信息(例如,模式信息、量化参数(QP)信息等)对第二图像135进行AI放大。
被提供给AI放大器224的AI数据可以包括用于能够对第二图像135进行AI放大的多条信息。
AI数据中包括的信息的示例可以包括原始图像105的分辨率与第一图像115的分辨率之间的差异信息或与第一图像115相关的信息中的至少一个。
差异信息可以被表示为关于第一图像115与原始图像105相比的分辨率转换程度的信息(例如,分辨率转换率信息)。另外,因为通过重构的第二图像135的分辨率知道第一图像115的分辨率,并且可以通过第一图像115的分辨率确认分辨率转换程度,因此差异信息可以由原始图像105的分辨率信息表示。在这点上,可以以图像的水平/垂直大小表示分辨率信息,或者可以以一个轴的比例(16∶9、4∶3等)和大小表示分辨率信息。另外,当存在预先设置的分辨率信息时,可以以索引或标志的形式表示分辨率信息。
与第一图像115相关的信息可以包括以下至少一项:作为对第一图像115执行第一编码的结果而生成的编码数据的比特率、在对第一图像115执行第一编码中使用的编解码器类型、或AI放大器224的开/关标志信息。
差异信息和与第一图像115相关的信息可以作为一个AI数据进行发送,或者可以根据需要分开发送和处理。
AI放大器224可以基于AI数据中包括的差异信息或与第一图像115相关的信息中的至少一个来确定第二图像135的放大目标。放大目标可以指示例如第二图像135需要被放大到的分辨率的程度。当确定了放大目标时,AI放大器224可以使用神经网络运算对第二图像135进行AI放大以生成与放大目标相对应的第三图像145。
在本公开的实施例中,通信器212、解析器214和AI解码器220被描述为分开的设备,但是它们可以通过一个处理器来实现。在这种情况下,通信器212、解析器214和AI解码器220可以被实现为专用处理器,或者可以通过通用处理器(例如,应用处理器(AP)、中央处理单元(CPU)、图形处理单元(GPU))与软件的组合来实现。另外,通信器212、解析器214和AI解码器220可以被配置为一个或多个处理器。在这种情况下,通信器212、解析器214和AI解码器220可以被实现为专用处理器的组合,或者可以通过多个通用处理器(例如,AP、CPU和GPU)与软件的组合来实现。类似地,AI放大器224和第一解码器222可以通过一个处理器来实现,或者可以以不同的处理器来实现。
图3是示出了根据本公开的实施例的显示设备300的示例配置的框图。
根据本公开的实施例,上述图2的AI解码装置200可以是图3的显示设备300。显示设备300可以从图像供应设备100接收图像。图像供应设备100可以包括例如各种服务器,诸如广播站、媒体服务提供商、服务公司、系统集成商(SI)公司、应用市场、网站等。由图像供应设备100供应的图像的类型可以包括例如广播内容、媒体内容、应用等。在本公开的实施例中,可以根据通过网络进行的语音点播(VOD)服务的形式的实时流传输,以文件的形式将媒体内容作为视频流进行提供。
显示设备300可以对从图像供应设备100接收的AI编码数据进行解码以显示重构的图像。例如,显示设备300可以是处理从广播站的发送设备接收的广播信号、广播信息或广播数据中的至少一个的电视(TV)。
显示设备300可以包括控制处理器(例如,包括处理电路)310、视频处理器(例如,包括视频处理电路)320、显示器330、通信器(例如,包括通信电路)340、用户输入接口(例如,包括用户输入接口电路)350和存储器360,但是显示设备300的配置不限于所示的配置。
控制处理器310可以包括各种处理电路,并且执行控制以用于操作显示设备300的所有组件。控制处理器310可以包括至少一个通用处理器,该至少一个通用处理器从其中安装有控制程序的非易失性存储器加载该控制程序的至少一部分到易失性存储器中,并执行所加载的控制程序。例如,控制处理器310可以例如但不限于被实现为CPU、AP、微处理器等。控制处理器310可以安装有一个或多个核(包括单核、双核、四核或它们的倍数)。控制处理器310可以包括多个处理器。例如,控制处理器310可以包括主处理器和以睡眠模式(例如,仅待机电力被供应给显示设备300且显示设备300不用作显示设备的模式)操作的子处理器。
视频处理器320可以包括各种视频处理电路,并且对图像数据执行各种预设的图像处理操作。视频处理器320可以将通过执行这样的图像处理而生成或组合的输出信号输出到显示器330,使得与图像数据相对应的图像被显示在显示器330上。
视频处理器320可以包括第一解码器222和AI放大器224。第一解码器222和AI放大器224可以分别对应于图2的第一解码器222和AI放大器224。
另外,视频处理器320可以包括例如用于执行各种图像处理操作的包括电路和/或可执行程序元件的至少一个模块,各种图像处理操作例如为用于将交织的广播信号改变为渐进(progressive)的广播信号的去交织、用于提高图像质量的降噪、细节增强、帧刷新率转换、行扫描等。
视频处理器320可以被实现为诸如GPU的专用处理器,或者可以通过通用处理器(例如,CPU或AP)与软件的组合来实现。另外,第一解码器222和AI放大器224可以被实现为不同的处理器。当AI放大器224被实现为专用处理器时,该专用处理器可以被实现为作为基于设备上的AI(on-device based AI)进行操作。在下文中,将执行AI放大器224的功能的专用处理器称为AI处理器。稍后将参考图4详细地描述AI处理器的配置。
可以将由视频处理器320处理的图像信号输出到显示器330。显示器330可以显示与从视频处理器320接收的图像信号相对应的图像。
实现显示器330的方法不受限制,并且可以使用各种显示方法来实现显示器330,例如但不限于液晶、等离子体、发光二极管、有机发光二极管、表面传导电子发射体、碳纳米管、纳米晶体等。在本公开的实施例中,显示器330可以包括用于显示图像的显示面板,并且根据其实现方法还可以包括附加配置(例如,驱动器)。
通信器340可以包括各种通信电路,并且使用有线或无线通信方法与至少一个外部设备通信。通信器340可以被实现为包括与预定通信协议相对应的有线和/或无线通信模块(软件模块、芯片等)的通信电路。例如,通信器340可以包括调谐器342、连接器344和网络单元346。
通信器340可以从外部接收图像信号。例如,通信器340可以接收与图2的AI编码数据相对应的图像信号。可以以与显示设备300的实现形式相对应的各种方式来配置所接收的图像信号的规格。
例如,通信器340可以无线地接收从广播站发送的RF信号。在该示例中,通信器340可以包括调谐器342,调谐器342用于对针对每个信道从广播站发送的广播信号进行调谐。调谐器342可以包括解调器,该解调器用于对特定信道的调谐后的广播信号进行解调,并以传输流的形式将解调后的广播信号输出为信号。调谐器342和解调器可以被设计为集成的单个芯片或两个分离的芯片。
另外,通信器340可以基于复合视频、分量视频、超级视频、SCART、HDMI、显示端口(DP)标准等通过有线方式接收信号。在这种情况下,通信器340可以包括连接器344,连接器344用于通过有线方式将显示设备300连接到外部图像源。连接器344可以通过例如HDMI电缆连接到图像源。例如,显示设备300可以通过连接器344从诸如机顶盒之类的图像源接收与内容相关的图像信号。尽管连接器344基本上从图像源接收信号,但是连接器344可以被设置为在两个方向上发送和接收信号。对于另一示例,显示设备300可以通过连接器344以有线方式连接到移动设备以及机顶盒,以接收图像信号。
通信器340可以连接到各种外围设备,以接收由通过网络(例如,互联网)接收的数据产生的图像信号。在这种情况下,通信器340可以通过网络单元346接收图像信号。网络单元346可以包括被配置为WLAN单元、无线通信模块和有线通信模块中的一个或者两个或更多个的组合的各种电路。WLAN单元可以在控制处理器310的控制下通过接入点(AP)与至少一个外部设备无线通信。WLAN单元可以包括Wi-Fi通信模块。无线通信模块可以直接在显示设备300与至少一个外部设备之间无线地执行无线通信,而无需AP。直接通信模块可以包括诸如如下项的通信模块:蓝牙、蓝牙低功耗、射频(RF)通信、Wi-Fi直连、Zigbee、超宽带(UWB)、近场通信(NFC)、红外数据协会(IrDA)等。另外,通信器340还可以包括诸如以太网之类的有线通信模块。
用户输入接口350可以包括各种用户输入接口电路并接收用户输入。用户输入接口350可以安装在显示设备300的正面、侧面或背面中的一个区域中,并且被实现为包括电源键、菜单键等的键区(或者输入面板)、触摸板、触摸屏、滚轮、拨盘、轨迹球等,以接收用户输入。备选地,用户输入接口350还可以包括:通信电路,用于从遥控设备(例如,遥控器、鼠标、键盘、安装有能够远程控制显示设备300的应用的智能电话等)接收命令/数据/信息/信号;或者语音输入接口,用于接收用户说出的语音以及声音,例如麦克风。
存储器360可以被配置为存储显示设备300的各条数据。例如,存储器360可以被设置为可写的非易失性存储器,即使当供应到显示设备300的电力被切断时,该可写的非易失性存储器也能保留数据并反映变化。存储器360可以包括硬盘(HDD)、闪存、EPROM或EEPROM中的至少一种。对于另一示例,存储器360可以被设置为易失性存储器,例如RAM。易失性存储器可以包括DRAM或SRAM,DRAM或SRAM在显示设备300的读取或写入速度方面比非易失性存储器更快。存储在存储器360中的数据可以包括例如用于驱动显示设备300的操作系统、可在操作系统上执行的各种应用、图像数据、附加数据等。另外,存储器360可以在控制处理器310的控制下存储与每个组件的操作相对应的输入/输出信号或数据。存储器360可以存储用于控制显示设备300的程序、与由制造商提供的或从外部下载的应用相关的UI、用于提供UI的图像、用户信息、文档、数据库或相关数据。在此,存储在存储器360中的应用可以包括基于先前执行的训练而操作的机器学习应用或深度学习应用。
图4是示出了根据本公开的实施例的AI处理器400的示例配置的框图。
图4示出了执行上述图3的AI放大器224的功能的AI处理器400。
AI处理器400可以例如但不限于被实现为通用处理器、数字信号处理器(DSP)、专用集成电路(ASIC)、现场可编程门阵列(FPGA)、另一可编程逻辑设备(PLD)、单独的门或晶体管逻辑、单独的硬件组件、处理器执行的软件模块等、或者它们的组合。根据本公开的实施例,AI处理器400可以被实现为芯片组形式的专用逻辑电路,例如专用ASIC、专用FPGA、专用逻辑电路和通用处理器的组合等,但不限于上述实现方法。
AI处理器400可以对通过神经网络模型输入的图像数据执行图像处理。例如,AI处理器400可以接收第二图像135的图像数据并执行神经网络运算以输出放大的第三图像145的图像数据。
AI处理器400可以包括控制器(或者,处理器控制器)410、运算器420和存储器430。控制器410可以包括各种处理电路,并且用于设置运算器420的运算所需的参数。运算器420可以包括各种处理电路和/或可执行程序元件,并且基于所设置的参数来执行神经网络运算。
例如,对于每个图像帧,神经网络运算可能需要不同的参数。“参数”可以包括在每个神经网络层的运算过程中使用的多个权重值。例如,参数可以以矩阵的形式表示。参数是作为训练结果而设置的值,并且可以根据需要通过独立的训练数据进行更新。
控制器410可以设置有表示包括多个权重值的参数的参数标识符。控制器410可以基于所设置的参数标识符来获得参数中包括的权重值。例如,控制器410可以基于参数标识符从AI处理器400外部的存储器360获得权重值,或者可以基于参数标识符从AI处理器400的存储器430获得权重值。在获得了参数时,控制器410可以将所获得的权重值寄存在与运算器420中包括的相应神经网络运算器相对应的寄存器中。例如,当一个神经网络运算器使用3×3×8滤波器卷积核(filter kernel)对图像数据执行卷积处理时,可以将3×3×8权重值寄存在与该一个神经网络运算器相对应的寄存器中。
运算器420可以包括多个神经网络运算器(例如,包括各种处理电路和/或可执行程序元件),并且可以在控制器410的控制下使用多个神经网络运算器中的至少一些神经网络运算器对图像数据执行神经网络运算。例如,一个神经网络运算器可以使用应用了寄存器中寄存的权重值的滤波器卷积核对图像数据执行卷积处理。下面将参考图5更详细地描述运算器420执行神经网络运算的过程。
存储器430可以包括多个N排存储器。N排存储器是用于在图像的水平方向上以像素列(排)为单位临时存储图像数据的存储器,并且可以被实现为例如SRAM。N排存储器可以被配置为用于临时记录一个或多个像素列的图像数据的一个或多个排存储器。
存储器430可以包括分别与运算器420中包括的多个神经网络运算器相对应的多个N排存储器,并且存储多个神经网络运算器的神经网络运算所需的运算值、运算的中间值或其最终值中的至少一个。
存储器430可以包括N排存储器,该N排存储器接收图像数据并将图像数据分发给多个神经网络运算器,或者用作用于从多个神经网络运算器收集要对其执行图像处理的图像数据的缓冲器。
在本公开的实施例中,AI处理器400的控制器410可以控制输入的图像数据存储在存储器430中。另外,控制器410可以控制多个神经网络运算器中的一些神经网络运算器对基于图像的大小和多个神经网络运算器的数据处理能力分割而成的图像数据执行神经网络运算,并且输出放大的图像数据。
在本公开的实施例中,当仅多个神经网络运算器中的一些神经网络运算器对分割而成的图像数据执行神经网络运算时,控制器410可以去激活不对分割而成的图像数据执行神经网络运算的一些其他神经网络运算器。
在本公开的实施例中,控制器410可以基于图像的水平大小和多个神经网络运算器的数据处理单位对图像数据进行分割。
在本公开的实施例中,控制器410可以控制多个神经网络运算器对基于图像的大小和多个神经网络运算器的数量分割而成的图像数据执行神经网络运算,并且输出放大后的图像数据。
在本公开的实施例中,控制器410可以基于图像的大小来转换多个神经网络运算器的时钟频率的速度。
在本公开的实施例中,控制器410可以基于对图像数据执行的神经网络运算所需的估计功耗,确定是基于多个神经网络运算器的数据处理能力还是基于多个神经网络运算器的数量对图像数据进行分割。在此,多个神经网络运算器的数据处理能力表示在预定时钟内每个神经网络运算器可以处理的最大数据大小。
在本公开的实施例中,控制器410可以获得与图像的帧相对应的参数,并且将该参数寄存在与多个神经网络运算器中的每一个相对应的寄存器中。
在本公开的实施例中,控制器410可以针对图像的每个帧应用不同的参数以对图像数据执行神经网络运算。
图5是示出了根据本公开的实施例的包括多个神经网络运算器(例如,包括处理电路和/或可执行程序元件)421、422、423和424的AI处理器400的示例配置的框图。
图5是AI处理器400的一部分,并且包括用于对图像数据进行神经网络运算的配置。
AI处理器400可以包括数据解包器411、多个神经网络运算器421、422、423和424、数据打包器412以及多个N排存储器431、432和433。在此,数据解包器411和数据打包器412可以包括在图4的控制器410中,并且多个神经网络运算器421、422、423和424可以包括在图4的运算器420中。
在图5中,第一N排存储器431可以例如是与数据解包器411相对应的存储器。例如,第一N排存储器431可以用作缓冲器,该缓冲器用于根据栅格(raster)方法从外部接收图像数据并将图像数据分发给多个神经网络运算器421、422、423和424。在该示例中,因为第一N排存储器431将操作所需的图像数据提供给神经网络运算器421、422、423和424并同时从外部接收图像数据,因此第一N排存储器431可以具有约为输入的图像数据的两倍的存储容量。
第二N排存储器432可以例如包括分别与多个神经网络运算器421、422、423和424相对应的多个N排存储器。第二N排存储器432可以存储神经网络运算所需的输入值、运算的中间值或其最终值中的至少一个。
第三N排存储器433可以例如是与数据打包器412相对应的存储器,并且可以用作用于收集多个神经网络运算器421、422、423和424的运算结果并将数据输出到外部的缓冲器。在该示例中,因为第三N排存储器433从神经网络运算器421、422、423和424收集运算结果并同时将经图像处理的数据提供给外部,因此第三N排存储器433可以具有约为输出的图像数据的两倍的存储容量。
第一N排存储器431、第二N排存储器432和第三N排存储器433可以分配在存储器430中。控制器410可以在存储器430中分配与第一N排存储器431、第二N排存储器432和第三N排存储器433相对应的存储空间。控制器410可以基于输入图像的大小或分割而成的图像数据的大小来确定第一N排存储器431、第二N排存储器432和第三N排存储器433中的每一个的存储空间的大小。
在描述了AI处理器400可以执行神经网络运算的特定过程之后,首先,当输入图像数据时,数据解包器411可以对输入的图像数据进行解包以对图像数据进行分割,使得可以将分割而成的图像数据分发给多个神经网络运算器421、422、423和424中的每一个。数据解包器411可以将多条子图像数据中的每一条提供给多个神经网络运算器421、422、423和424中的每一个作为分割而成的图像数据(在下文中,分割而成的图像数据可以被称为多条子图像数据)。神经网络运算器421、422、423和424中的每一个可以根据神经网络运算对所提供的子图像数据执行图像处理。数据打包器412可以收集对子图像数据中的每一个执行的图像处理的结果以输出放大的图像数据。
在本公开的实施例中,数据解包器411可以读取与一排像素相对应的图像数据并将所读取的图像数据提供给第一N排存储器431,以分割图像数据并将分割而成的图像数据提供给多个神经网络运算器421、422、423和424。
例如,当输入图像是4K图像时,数据解包器411可以读取与3840×1个像素相对应的图像数据并将所读取的图像数据记录到第一N排存储器431上,以放大作为图像帧的一排的3840×1个像素。数据解包器411可以基于图像的大小和多个神经网络运算器421、422、423和424的数据处理能力对存储在存储器430中的与3840×1个像素相对应的图像数据进行分割。例如,当多个神经网络运算器421、422、423和424中的每一个的处理单位可以是与960×1个像素相对应的图像数据时,数据解包器411可以将图像数据分割为作为(3840)/(960)的结果的四条子图像数据,并将四条子图像数据中的每一条提供给与多个神经网络运算器421、422、423和424中的每一个相对应的第二N排存储器432。
在本公开的实施例中,数据解包器411还可以考虑神经网络运算器421、422、423和424使用的滤波器卷积核的大小来获得与分割而成的图像数据的边界区域相对应的图像数据,并且将所获得的图像数据提供给与多个神经网络运算器421、422、423和424中的每一个相对应的第二N排存储器432。
多个神经网络运算器421、422、423和424中的每一个可以对存储在第二N排存储器432中的子图像数据执行放大图像处理。例如,一个神经网络运算器可以对所提供的子图像数据执行卷积运算、非线性运算和放大运算。另外,多个神经网络运算器421、422、423和424中的每一个可以对表示像素的Y、Cb和Cr中的每一个执行放大图像处理。例如,多个神经网络运算器421、422、423和424中的每一个可以对亮度分量Y执行卷积运算、非线性运算和放大运算,并且可以对色度分量Cb和Cr执行放大运算(例如,双立方缩放)。
图6是示出了根据本公开的实施例的示例神经网络运算的图。
图6示出了神经网络运算器的运算的示例。图6的处理块(例如,包括处理电路和/或可执行程序元件)612、614、616、618、620、622和624中的每一个可以对应于人工神经网络模型的至少一个层或至少一个节点。处理块612、614、616、618、620、622和624中的每一个可以对应于分配给神经网络运算器的至少一个寄存器、处理器或存储器中的至少一个、或者它们的组合。
参考图6,神经网络运算器可以将输入数据601分割为关联数据和推断数据,以对关联数据执行卷积运算、非线性运算和放大运算,并对推断数据执行放大运算。关联数据可以是来自用于基于AI的AI缩小的AI与用于基于AI的AI放大的AI之间的关联训练的数据,并且推断数据可以是未经关联训练的数据。
神经网络运算器可以将子图像数据601的关联数据输入到第一卷积层(Conv)612以执行卷积处理。例如,神经网络运算器可以使用大小为3×3的8个滤波器卷积核对子图像数据执行卷积处理。神经网络运算器可以将由8个滤波器卷积核生成的8个特征图作为卷积处理的结果输入到第一激活层614。
第一激活层614可以给每个特征图赋予非线性特性。第一激活层614可以包括sigmoid函数、tanh函数、整流线性单元(ReLU)函数等,但是不限于此。第一激活层614赋予非线性特性可以例如是指改变并输出通过第一卷积层612输出的特征图的一些样本值。可以通过应用非线性特性来执行改变。
神经网络运算器可以将第一激活层614的输出输入到第二卷积层616。神经网络运算器可以使用大小为3×3的8个滤波器卷积核对输入数据执行卷积处理。可以将第二卷积层616的输出输入到第二激活层618。第二激活层618可以给输入数据赋予非线性特性。
神经网络运算器可以通过缩放器620对第二激活层618的输出执行运算。神经网络运算器可以对双线性缩放、双立方缩放、lanczos缩放或阶梯缩放中的至少一种缩放操作的输出应用缩放器620。
神经网络运算器可以将缩放器620的输出输入到第三卷积层622以执行卷积处理,以便使用一个大小为3×3的滤波器卷积核来生成一个输出图像。第三卷积层622的输出可以被输入到第三激活层624,并且第三激活层624可以给输入数据赋予非线性特性以获得放大的关联数据。
另外,神经网络运算器可以通过缩放器(例如,包括处理电路和/或可执行程序元件)630对子图像数据601之中的推断数据执行运算,以获得放大的推断数据。神经网络运算器可以通过双线性缩放、双立方缩放、lanczos缩放或阶梯缩放中的至少一种缩放操作来执行缩放器630。
神经网络运算器可以将放大的关联数据与放大的推断数据进行组合以获得放大的子图像数据作为输出数据602。
在图6中,一个神经网络模型包括三个卷积层612、616和622、三个激活层614、618和624、以及缩放器620,但这仅是示例。卷积层和激活层的数量可以根据实现示例而变化。另外,根据实现示例,神经网络运算器不仅可以通过深度神经网络(DNN)来实现,还可以通过递归神经网络(RNN)来实现,但是本公开不限于此。
图5的数据打包器412可以从多个神经网络运算器421、422、423和424的每一个收集放大的子图像数据,并最终输出与输入的图像数据相对应的放大的图像数据。例如,数据打包器412可以输出与3840×2个像素相对应的放大的图像数据,作为对为图像帧的一排的3840×1个像素进行放大的结果。
图7是示出了根据本公开的实施例的基于图像的大小来执行神经网络运算的示例过程的图。
如图7中所示,在输入了输入图像的图像数据作为输入数据701时,AI处理器400可以确定712输入图像的大小。例如,AI处理器400可以对图像数据进行分析以确定图像的大小,或从外部接收关于图像的大小的信息。在这种情况下,关于图像的大小的信息可以包括在上面参考图1描述的AI数据或编码数据中,并且可以对其进行发送。图像的大小通常可以是一帧的水平大小,但不限于上面的示例,并且可以是图像的分辨率信息、图像的比例信息或一帧的垂直大小。
当确定了输入图像的大小时,AI处理器400可以基于图像的大小和多个神经网络运算器的数据处理能力对图像数据进行分割,以将分割而成的图像数据分配714给多个神经网络运算器。多个神经网络运算器中的每一个可以对分配的子图像数据执行神经网络运算处理716。
AI处理器400可以以排为单位收集718图像数据作为多个神经网络运算器中的每一个的神经网络运算的结果,并且输出放大的图像数据作为输出数据702。例如,AI处理器400可以对从多个神经网络运算器输出的以排为单位的图像数据进行合并,并且根据顺序扫描方法来输出合并的图像数据。
图7中的处理块712、714、716和718中的每一个可以对应于由至少一个计算机程序命令执行的软件处理单元,和/或可以对应于分配给预定操作的硬件资源(例如,处理器、寄存器、存储器等)。根据本公开的实施例,可以由控制器410执行如下操作:确定712图像的大小、分配714分割而成的图像数据、以及收集718排图像数据,并且可以通过运算器420的多个神经网络运算器执行神经网络运算处理716。
图8是示出了根据本公开的实施例的用于基于图像的大小来执行神经网络运算的示例AI处理器400的框图。
在图8中,AI处理器400可以包括输入数据控制器(例如,包括控制电路)812、多个神经网络运算器822、824和826、分别与多个神经网络运算器822、824和826对应的多个N排存储器832、834和836、以及输出数据控制器(例如,包括控制电路)842。输入数据控制器812和输出数据控制器842可以包括在图4的控制器410中。另外,输入数据控制器812可以对应于图5的数据解包器411,并且输出数据控制器842可以对应于图5的数据打包器412。
输入数据控制器812可以接收与图像的像素对应的图像数据和关于图像的大小(例如,图像的水平大小)的信息。对于另一示例,输入数据控制器812可以对图像数据进行分析以确定图像的大小。
输入数据控制器812可以基于图像的大小和多个神经网络运算器822、824和826的数据处理能力,对图像数据进行分割,并且可以同时将作为分割而成的图像数据的子图像数据中的每一个中的至少一些发送到神经网络运算器822、824和826中的至少一个。该至少一个神经网络运算器可以对所提供的图像数据执行神经网络运算,并且输出运算结果。
根据本公开的实施例,多个神经网络运算器822、824和826可以并行操作。此外,根据在多个N排存储器832、834和836与多个神经网络运算器822、824和826之间分配的资源,分割而成的图像数据可以在多个N排存储器832、834和836与多个神经网络运算器822、824和826之间串行或并行地发送。
图9是示出了根据本公开的实施例的多个神经网络运算器822、824和826对根据图像数据的大小分割的图像数据进行处理的示例过程的图。在图9、图10和图11中,为了易于且方便说明起见,假设AI处理器400包括数量为N(N为自然数)个的多个神经网络运算器822、824和826,多个神经网络运算器822、824和826的最大处理单位为max_width,并且多个神经网络运算器822、824和826中的每一个的处理单位为max_width/N。多个神经网络运算器822、824和826中的每一个的处理单位可以例如被定义为像素的数量、数据大小(例如,比特、字节等)。
在该示例中,输入数据控制器812可以将输入的图像数据分割为多个神经网络运算器822、824和826中的每一个的处理单位。
例如,在图9中,输入图像的图像数据的大小可以为M1,并且多个神经网络运算器822、824和826的图像数据的处理单位可以为max_width/N。
当图像数据的大小M1等于作为整个神经网络运算器822、824和826的吞吐量的max_width或具有吞吐量的倍数时,输入数据控制器812可以将图像数据分割成相同大小的M1/max_width=N。输入数据控制器812可以将N个分割而成的图像数据发送到多个神经网络运算器822、824和826中的每一个。
多个神经网络运算器822、824和826中的每一个可以对均等分割的图像数据执行神经网络运算。例如,神经网络运算器822、824和826中的每一个处理分割而成的图像数据的运算时间长度可以相同,并且神经网络运算器822、824和826中的每一个可以同时执行AI放大以输出t个放大的图像数据。
图10是示出了根据本公开的另一实施例的多个神经网络运算器822、824和826对根据图像数据的大小分割的图像数据进行处理的示例过程的图。对于另一示例,在图10中,图像数据的大小可以为M2,并且多个神经网络运算器822、824和826的图像数据的处理单位可以是max_width/N。
当图像数据的大小M2小于作为整个神经网络运算器822、824和826的图像数据吞吐量的max_widt但大于(max_width/N)*(N-1)时,输入数据控制器812可以将图像数据分割成N条。第N个图像数据的大小可以小于其他图像数据的大小。因此,处理第N个图像数据的第N神经网络运算器826的运算时间可以比其他的神经网络运算器822和824的运算时间短。在此示例中,处理第N个图像数据的第N神经网络运算器826可以首先处理分配给第N神经网络运算器826的图像数据,并且当其他的神经网络运算器822和824处理图像数据时等待或在处理图像数据之后的空闲时间期间执行其他运算。
图11是示出了根据本公开的另一实施例的多个神经网络运算器822、824和826对根据图像数据的大小分割的图像数据进行处理的示例过程的图。对于另一示例,在图11中,图像数据的大小可以为M3,并且多个神经网络运算器822、824和826的图像数据的处理单位可以是max_width/N。在该示例中,图像数据的大小M3可以小于多个神经网络运算器822、824和826之中的一些神经网络运算器822、824的图像数据处理单位。输入数据控制器812可以将图像数据分割为图像数据处理单位,以便仅使用最少数量的神经网络运算器来处理图像数据。例如,在图11中,输入数据控制器812可以将图像数据分割为两条,以便仅使用一些神经网络运算器822和824。
在图11中,输入数据控制器812可以去激活多个神经网络运算器822、824和826之中的不对图像数据执行神经网络运算处理的第N神经网络运算器826。去激活神经网络运算器可以包括:关闭神经网络运算器,使得不对其施加电力;不施加激活信号(使能信号、触发信号等);不施加时钟频率;或者将神经网络运算器转换为待机状态或睡眠模式。当不处理图像数据的神经网络运算器被去激活时,AI处理二器400的功耗可以大大降低。
返回参考图8,当由多个神经网络运算器822、824和826中的至少一个神经网络运算器执行神经网络运算时,输出数据控制器842可以从执行神经网络运算的每个神经网络运算器收集作为运算结果的放大的分割数据。当收集了放大的分割数据时,输出数据控制器842可以将放大的图像数据作为输出数据802进行输出。
在本公开的另一实施例中,输入数据控制器812可以基于图像的大小和神经网络运算器822、824和826的数量对图像数据进行分割。输入数据控制器812可以将作为分割而成的图像数据的子图像数据中的每一个发送到多个神经网络运算器822、824和826中的每一个。例如,当输入图像的图像数据的大小为M4且神经网络运算器822、824和826的数量为N时,输入数据控制器812可以将输入图像的图像数据分割为相同大小的M4/N的N个子图像数据。输入数据控制器812可以分别将N个分割而成的图像数据发送到多个神经网络运算器822、824和826。多个神经网络运算器822、824和826中的每一个可以对相同大小的图像数据执行神经网络运算。多个神经网络运算器822、824和826中的每一个可以对分割而成的图像数据执行AI放大处理,以输出放大的图像数据。
在本公开的另一实施例中,AI处理器400可以基于作为AI处理器400的操作速度的时钟频率进行操作。AI处理器400通常可以相对于构成AI处理器400的每个模块使用特定的时钟频率,或者可以针对每个模块使用不同的时钟频率。时钟频率可以是例如100MHz与800MHz之间的一个或多个值,但是不限于上述范围。
在这种情况下,AI处理器400可以基于图像的大小来转换多个神经网络运算器822、824和826的时钟频率的速度。例如,当图像的大小较小时,多个神经网络运算器822、824和826可以使用低速的时钟频率来执行神经网络运算。当图像的大小较大时,神经网络运算器822、824和826可以使用高速的时钟频率来执行神经网络运算。根据本公开的实施例,AI处理器400可以根据输入图像的大小来调节神经网络运算器822、824和826的时钟频率,从而当输入图像的大小较小时降低功耗。
在本公开的另一实施例中,AI处理器400可以基于对图像数据执行神经网络运算所需的预期功耗量,确定是基于多个神经网络运算器822、824和826的数据处理能力还是基于多个神经网络运算器822、824和826的数量对图像数据进行分割。例如,神经网络运算器822、824和826消耗的功耗可以包括在施加时钟频率时消耗的动态功耗和在不施加时钟频率时消耗的静态功耗。静态功耗可以指的是即使在不施加时钟频率时由于AI处理器400用作电容而泄漏的漏功耗。
在该示例中,在基于输入图像的图像数据的大小和多个神经网络运算器822、824和826的数据处理能力处理图像数据的情形下通过关闭一些神经网络运算器来降低其静态功耗的策略与在基于图像数据的大小和多个神经网络运算器822、824和826的数量处理图像数据的情形下通过改变时钟频率来降低动态功耗的策略之间,AI处理器400可以预测究竟哪一种策略对于功耗更有效。例如,当静态功耗的贡献在功耗中较高时,AI处理器400可以选择关闭一些神经网络运算器的策略,而当静态功耗的贡献较低时,则选择通过改变时钟频率来降低动态功耗的策略。对于另一示例,AI处理器400可以当输入图像的图像数据的大小小于或等于预定大小时选择关闭一些神经网络运算器的策略,并且当图像数据的大小超过预定大小时选择改变时钟频率的策略。AI处理器400可以基于时钟频率、电压、电流、芯片单元的大小或芯片单元的特性中的至少一项来确定策略,并且当确定了对于功耗有效的策略时,可以根据所确定的策略,使用多个神经网络运算器822、824和826中的至少一个对图像数据执行神经网络运算。
图12是示出了根据本公开的实施例的由AI处理器400执行的用于执行神经网络运算的示例方法的流程图。
可以通过包括例如处理器和存储器的各种类型的电子设备并使用人工神经网络模型来执行本公开的执行神经网络运算的方法的每个操作。这里将描述本公开的实施例,其中包括根据本公开的实施例的AI处理器400的设备执行用于执行神经网络运算的方法。因此,关于AI处理器400描述的本公开的实施例可以适用于执行神经网络运算的方法的本公开的实施例,并且相反,关于执行神经网络运算的方法描述的本公开的实施例可以适用于AI处理器400的本公开的实施例。根据本公开的实施例的执行神经网络运算的方法不限于该方法由本文中公开的AI处理器400执行的本公开的实施例,并且可以由各种类型的电子设备执行。
在图12的操作1201中,A1处理器400可以接收输入图像的图像数据,并且将图像数据存储在至少一个存储器中。
在图12的操作1203中,AI处理器400可以基于图像的大小和多个神经网络运算器的数据处理能力对存储在存储器中的图像数据进行分割。例如,AI处理器400可以基于图像的水平大小和多个神经网络运算器的数据处理单位对图像数据进行分割。
在图12的操作1205中,AI处理器400可以通过多个神经网络运算器中的至少一些神经网络运算器对分割而成的图像数据执行神经网络运算。根据本公开的实施例,AI处理器400可以使用多个神经网络运算器中的一些或全部。另外,根据本公开的实施例,AI处理器400可以调节使用的神经网络运算器的数量。在这种情况下,AI处理器400可以去激活多个神经网络运算器之中的不对分割而成的图像数据执行神经网络运算处理的一些其他的神经网络运算器。
在图12的操作1207中,AI处理器400可以输出放大的图像数据,作为通过一些神经网络运算器执行神经网络运算的结果。
在本公开的另一实施例中,AI处理器400可以基于图像的大小和神经网络运算器的数量对图像数据进行分割。AI处理器400可以通过多个神经网络运算器对分割而成的图像数据执行神经网络运算。在这种情况下,AI处理器400可以基于图像的大小来转换多个神经网络运算器的时钟频率的速度。
在本公开的另一实施例中,AI处理器400可以基于对图像数据执行神经网络运算所需的预期功耗量,确定是基于多个神经网络运算器的数据处理能力还是基于多个神经网络运算器的数量对图像数据进行分割。
上面描述的本公开的各种示例实施例可以被编写为在计算机上可执行的程序或指令,并且该程序或指令可以被存储在介质中。
介质可以连续地存储非暂时性计算机可执行程序或指令或临时存储非暂时性计算机可执行程序或指令以用于执行或下载。另外,介质可以包括单个硬件或若干种硬件的组合的形式的各种记录装置或存储装置,并且不限于直接连接到任何计算机系统的介质,而是可以分布在网络上。介质的示例可以包括磁介质(诸如,硬盘、软盘和磁带)、光学记录介质(诸如,CD-ROM和DVD)、磁光介质(诸如,软盘、ROM、RAM、闪存)等,并且被配置为存储程序指令。另外,介质的其他示例可以包括由分发应用的应用商店、供应或分发各种软件的站点、服务器等管理的记录介质或存储介质。
上面描述的神经网络模型可以被实现为软件模块。当神经网络模型被实现为软件模块(例如,包括指令的程序模块)时,DNN模型可以存储在非暂时性计算机可读记录介质上。另外,神经网络模型可以以硬件芯片的形式被集成为上述AI解码装置200或显示设备300的一部分。例如,神经网络模型可以以针对AI的专用硬件芯片的形式或作为现有的通用处理器(例如,CPU或应用处理器)或图形专用处理器(例如,GPU)的一部分进行制造。
另外,可以以可下载软件的形式提供神经网络模型。计算机程序产品可以包括为通过制造商或电子市场电子分发的软件程序的形式的产品(例如,可下载的应用)。对于电子分发,软件程序的至少一部分可以存储在存储介质上,或者可以被临时生成。在这种情况下,存储介质可以是制造商或电子市场的服务器,或者可以是中继服务器的存储介质。
根据本公开的实施例的AI处理器可以根据图像的大小使用多个神经网络运算器中的一些神经网络运算器对图像数据执行神经网络运算,从而减少AI处理器的神经网络运算所需的功耗。
另外,根据本公开的实施例的AI处理器可以根据图像的大小来转换多个神经网络运算器的时钟频率,从而减少AI处理器的神经网络运算所需的功耗。
另外,除预定大小的图像之外,根据本公开的实施例的AI处理器还可以针对8K、4K、2K等自适应地操作多个神经网络运算器,由此可以针对图像的各种大小重复利用神经网络运算平台。
根据本公开的实施例的AI处理器可以实现的效果不限于上面所提到的那些,并且本领域技术人员根据以下描述可以显而易见地理解上面没有提到的其他效果。
尽管已参考各种示例实施例示出和描述了本公开,但是应理解的是,各种示例实施例旨在是说明性的而非限制性的。本领域的普通技术人员将理解的是,可以在不脱离包括所附权利要求及其等同物的本公开的真实精神和完整范围的情况下,在形式和细节上进行各种改变。
- 人工智能处理器及其执行神经网络运算的方法
- 微处理器电路以及执行神经网络运算的方法