学习装置和学习方法
文献发布时间:2023-06-19 09:30:39
技术领域
发明涉及一种学习装置和学习方法。
背景技术
近年来,在各个领域都尝试使用人工智能(AI)中广为人知的机器学习来用大量的数据代替人类的功能。这个领域仍在日新月异地发展,但是在当前情况下仍然存在一些问题。其代表性示例包括精度极限,该精度极限包括用于从数据中检索通用知识的概括性能,以及由于其较大的计算负荷而导致的处理速度的极限。众所周知的高性能机器学习算法有深度学习(Deep learning,DL),卷积神经网络(convolutional neural network,CNN),输入向量被限制在外围,等等。与这些方法相比,在当前情况下,梯度增强(例如,梯度提升决策树(GBDT))众所周知对于诸如图像、语音和语言之类的输入数据的准确性较差,因为它难以提取特征量,但对其他结构化数据却具有更高的性能。实际上,在Kaggle作为数据科学家的竞争中,GBDT是最标准的算法。在现实世界中,据说需要机器学习解决的问题中有70%是图像,语音和语言以外的结构化数据,因此毫无疑问,GBDT是一种重要的算法,解决现实世界中的问题。另外,近年来,已经开发出一种使用决策树从诸如图像和语音的数据中提取特征的方法。但可以为其他结构化数据提供更高的性能。实际上,在Kaggle作为数据科学家的竞争中,GBDT是最标准的算法。在现实世界中,据说需要机器学习解决的问题中有70%是图像,语音和语言以外的结构化数据,因此毫无疑问,GBDT是一种重要的算法,解决现实世界中的问题。另外,近年来,已经开发出一种使用决策树从诸如图像和语音的数据中提取特征的方法。但可以为其他结构化数据提供更高的性能。实际上,在作为数据科学家的竞赛Kaggle中,GBDT是最标准的算法。在现实世界中,需要机器学习解决的问题中有70%被认为是图像、语音和语言以外的结构化数据,因此毫无疑问,GBDT是一种解决现实世界中的问题的重要算法。另外,近年来,已经开发出一种使用决策树从诸如图像和语音的数据中提取特征的方法。
在梯度增强中,学习处理的执行速度比例如CCN的深度学习要高。然而,作为实际工作中的必需工作,在实践中进行数百次或更多次学习以用于超参数的调整和特征选择,并且为了评估泛化性能和改善性能的目的,通过组合多个模型来进行对于例如模型组合和堆叠之类的工作也是相当普遍的。因此,即使在以相对较高的速度进行处理的梯度提升中,计算时间也成为一个问题。因此,近年来,已经进行了大量以通过梯度增强来提高学习处理的处理速度的研究。
为了通过梯度增强来提高学习处理的速度,需要将学习数据划分为多个存储器要保存的片段,并且需要并行进行学习处理。假设计算出梯度信息的直方图和用于梯度增强的学习数据的特征量,则存储直方图的存储器的数量与存储学习数据的存储器的划分区块数量成比例地增加,并且电路规模也将增加。
关于上述直方图,为了提高直方图的速度,公开了一种对并行输入的值计算直方图的技术(参见专利文献1)。为了通过现场可编程门阵列(FPGA)计算定向梯度直方图(HOG)特征量作为局部特征量,公开了一种使用特定变量作为直方图的堆(bin)来对其他变量进行积分的操作(参见非专利文献1)。
发明内容
技术问题
尽管在专利文献1中公开的技术中计算了并行输入的直方图,但是所公开的仅是针对一个变量的直方图的操作,即,将变量的值作为预定堆进行计数的直方图,因此该技术如上所述,不能应用于梯度信息和特征量的直方图的创建。另外,通过非专利文献1中公开的技术,可以创建上述两个变量的直方图,但是不能并行输入两个变量以创建直方图。
本发明鉴于上述情况而做出,并且本发明提供了一种学习装置和学习方法,用于创建并行输入的特征量和梯度信息的直方图,并减小保存该直方图信息的存储器的电路规模。
解决方法
根据本发明的一个方面,学习装置被配置为通过梯度提升来进行学习。该学习装置包括多个数据存储单元、多个梯度输出单元、加法单元和直方图存储单元。多个数据存储单元被配置为存储包括至少一种类型的特征量和与梯度信息相对应的学习数据。多个梯度输出单元被设置为与多个数据存储单元相对应,并且分别被配置为从对应的多个数据存储单元中的一个接收特征量和与特征量相对应的梯度信息的输入,并通过对应于输入特征量的每个值的输出端口,输出对应于特征量的梯度信息。加法单元被配置为从多个梯度输出单元输出的多条梯度信息中的与特征量的相同值的相对应的一个或多个梯度信息相加,并输出与特征量的各个值对应的梯度信息的相加值。直方图存储单元被配置为在每个值被设置为一个堆的情况下,用于存储通过对梯度信息的相加值进行积分而得到的直方图,其中,梯度信息的相加值对应于针对每个堆从加法单元输出的特征量。
发明的有益效果
根据本发明,可以创建并行输入的特征量和梯度信息的直方图,并且减小保存直方图的信息的存储器的电路规模。
附图说明
图1是示出决策树模型的示例的示意图。
图2是示出根据第一实施例的学习和鉴别装置的模块配置的示例的示意图。
图3是示出了指针存储器的配置示例的示意图。
图4是示出学习模块的模块配置的示例的示意图。
图5是示出根据第一实施例的在初始化学习和鉴别装置时模块的操作的图。
图6是示出根据第一实施例的学习和鉴别装置的在深度0、节点0处确定节点参数时的操作的示意图。
图7是示出根据第一实施例的学习和鉴别装置在深度0,节点0处的分支时的操作的示意图。
图8是示出根据第一实施例的学习和鉴别装置的在深度1、节点0处确定节点参数时的操作的示意图。[图9]图9是示出根据第一实施例的学习和鉴别装置在深度1,节点0处的分支时的操作的示意图。
图10是示出根据第一实施例的学习和鉴别装置的在深度1、节点1处确定节点参数时的操作的示意
图11是示出根据第一实施例的学习和鉴别装置在深度1,节点1处的分支时的操作的示意图。
图12是示出根据第一实施例的学习和鉴别装置在深度1确定节点参数而没有执行分支的情况下模块的操作的示意图。
图13是示出在根据第一实施例的学习和鉴别装置完成了决策树的学习的情况下,在更新所有样本数据的状态信息时模块的操作的示意图。
图14是示出根据第一实施例的修改例的学习和鉴别装置的模型存储器的配置示例的示意图。
图15是示出根据第一实施例的修改例的学习和鉴别装置的分类模块的配置示例的示意图。
图16是示出应用了数据并行的学习和鉴别装置的模块配置的示例的示意图。
图17是示出学习模块的特定模块配置的示例的示意图。
图18是示出学习模块的梯度直方图计算模块的模块配置的示例的示意图。
图19是示出学习模块的累积梯度计算模块的模块配置的示例的示意图。
图20是示出在实现数据并行的情况下的梯度直方图计算模块的模块配置的示例的示意图。
图21是示出根据第二实施例的学习和鉴别装置的学习模块的模块配置的示例的示意图。
图22是示出根据第二实施例的学习模块的梯度直方图计算模块的模块配置的示例的示意图。
图23是示出在根据第二实施例的学习模块中假设划得分为3的情况下的梯度直方图计算模块的模块配置的示例的示意图。
图24是示出根据第二实施例的学习模块的累积梯度计算模块的模块配置的示例的示意图。
图25是示出根据第二实施例的学习和鉴别装置中在假设特征量的类型的数量为2的情况下的学习模块的模块配置的示例的示意图。
图26是示出根据第二实施例的学习模块中在假设特征量的类型的数量为2的情况下的梯度直方图计算模块的模块配置的示例的示意图。
具体实施方式
下面参考图1至图26详细描述根据本发明的学习装置和学习方法的实施例。本发明不限于以下实施例。以下实施例中的组件包括本领域技术人员容易想到的组件,基本上相同的组件以及所谓的等同物。另外,在不脱离下面描述的实施例的要旨的情况下,可以以各种方式省略、替换、修改和组合组件。
第一实施例
关于GBDT的逻辑
DL作为一种高性能机器学习算法,试图通过各种硬逻辑来实现鉴别器,且与使用图形处理单元(GPU)的处理相比,该硬逻辑被发现具有更高的功率效率。但是,GPU的架构尤其适合于DL领域的CNN,因此,从速度来看,用逻辑实现的现场可编程门阵列(FPGA)的鉴别速度并不比GPU高。另一方面,已经有通过FPGA在基于决策树的算法(例如GBDT)上实现硬逻辑的尝试,并且报道了比GPU更高速度的结果。这是因为,如后所述,基于决策树的算法由于其数据排列的特性而不适合于GPU的架构。
目前世界上关于学习的测试落后于关于鉴别的测试。关于决策树系统的现状几乎没有报道,而关于决策树系统的报道也很少。特别是,目前还没有关于GBDT学习的报告,目前可以认为这是一个尚未开发的领域。为了获得准确的鉴别模型,在学习时进行特征量的选择和设计以及学习算法的超参数的选择需要大量的试验。特别是在学习数据量大的情况下,学习处理的速度实际上会极大地影响最终模型的精度。另外,在需要跟随环境变化的实时性能(例如机器人技术,高频交易(HFT)和实时竞价(RTB))的领域中,速度与性能直接相关。因此,在其中GBDT以高精度实现高速学习处理的情况下,可以认为最终可以大大提高使用GBDT的系统的性能。
GBDT对FPGA的契合性
下面从GBDT与FPGA的契合性来看,为什么通过决策树或GPU实现GBDT处理速度不高,而通过FPGA的处理速度高。
首先,从GBDT是使用增强的算法的观点进行描述。在随机森林(Random Forest,RF)中,在决策树领域使用集成学习,树之间没有依赖关系,因此GPU可以轻松执行并行化。然而,GBDT是一种使用增强来连接大量树的方法,因此,直到获得前一棵树的结果,才可以开始学习后一棵树。因此,该处理是串行处理,并且尽可能地快速学习每棵树是非常重要的。另一方面,在RF中,即使每棵树的学习速度低,也可以通过并行增加大量树的学习速度来增加整体学习速度。因此,即使在使用GPU的情况下,可以认为动态随机存取存储器(DRAM)(下文描述)的访问延迟问题可以在一定程度上被掩盖。
接下来,从GPU设备对随机存取存储器(RAM)的访问速度的限制(特别是在随机访问中)的观点进行描述。FPGA内置的静态随机存取存储器(SRAM)可以大大增加FPGA中RAM的总线宽度,因此,例如即使在使用Xilinx公司制造的XC7k325T产品作为中档FPGA的情况下,也可以达到3.2TB/秒的速度。内置RAM的容量为16Mb。
445个BRAM×36位×100MHz×2个端口=445*36*2*100*10^6/10^12=3.2TB/秒
在使用Xilinx公司生产的VU9P产品作为高端FPGA的情况下,可以达到6.9TB/秒的速度。内置RAM的容量为270Mb。
960个URAM×36位×100MHz×2个端口=960*36*2*100*10^6/10^12=6.9TB/秒
这些值是在使计时单位频率为100MHz的情况下获得的,但实际上,通过设计电路配置,可以在大约200至500MHz频率下进行操作,并且将限制带宽提高几倍。另一方面,连接到中央处理单元(CPU)的当前一代RAM是双数据速率4(DDR4),但是如下所述,由一个双列直插式内存模块(DIMM)生成的带宽仍然是25.6GB/sec。即使使用四个DIMM的交错配置(256位宽度),该带宽也可以达到约100GB/sec。在DDR4的芯片标准为DDR4-3200(总线宽度为64位,1个DIMM)的情况下,满足以下表达式。
200MHz×2(DDR)×64=200*10^6*2*64/10^9=25.6GB/秒
安装在GPU上的图形双数据速率5(GDDR5)的带宽大约是DDR4的带宽的四倍,但最大约为400GB/秒。
这样,FPGA中的RAM与GPU和CPU中的外部存储器之间的带宽彼此之间会有很大差异。尽管上面已经描述了顺序访问地址的情况,但是随机访问时的访问时间会更大。FPGA的内置RAM是SRAM,因此顺序访问和随机访问的访问延迟均为1个计时单位。然而,DDR4和GDDR5中的每一个RAM都是DRAM,因此在读出放大器访问不同列的情况下延迟增加。例如,典型的列地址选通延迟(CAS延迟)在DDR4的RAM中为16个计时单位,并且吞吐量被简单地计算为顺序访问的1/16。
在CNN的情况下,相邻像素的数据被连续地处理,使得随机访问的延迟不是大问题。然而,在决策树的情况下,各个分支的原始数据的地址随着分支的进行变得不连续,基本上变成了随机访问。因此,在将数据存储在DRAM中的情况下,其吞吐量造成瓶颈,使得速度大大降低。在这种情况下,GPU包括用于抑制性能降低的高速缓存,但是决策树基本上是访问整个数据的算法,因此数据访问中不存在局部性,并且几乎不表现出高速缓存的效果。在GPU的结构中,GPU包括共享内存,该共享内存包含分配给每个算术核心(SM)的SRAM,在某些情况下,可以通过使用共享内存来执行高速处理。然而,在每个SM的容量较小的情况下(如16至48kB)并且跨SM执行访问时,则会导致较大的延迟。以下是在Nvidia K80作为当前昂贵的大型GPU的情况下,对共享内存容量的测试计算。
K80=2×13SMX=26SMX=4992CUDA内核
26×48×8=9Mb
如上所述,即使在价值数十万日元的大型GPU中,共享存储器的容量也仅为9Mb,这太小了。另外,如上所述,在GPU的情况下,由于执行处理的SM不能直接访问另一SM的共享存储器,在被用于学习决策树的情况下,存在高速编码难以执行的限制。
如上所述,假设数据存储在FPGA上的SRAM中,则可以认为FPGA相比GPU可以更快地实现GBDT的学习算法。
GBDT的算法
图1是示出决策树模型示例的示意图。下面参照表达式(1)至(22)和图1描述GBDT的基本逻辑。
GBDT是一种监督学习的方法,并且监督学习是对目标函数obj(θ)进行优化的处理,该目标函数包括使用如以下表达式(1)表示的某种尺度的表示对学习数据的拟合程度的损失函数L(θ)和表示学习模型的复杂性的正则项Ω(θ)。正则化项Ω(θ)的作用是防止模型(决策树)过于复杂,即提高泛化性能。
obj(θ)=L(θ)+Ω(θ) (1)
表达式(1)的第一项的损失函数例如通过将由误差函数I计算的损失与以下表达式(2)表示的各个样本数据(学习数据)相加而获得。在这种情况下,n是样本数据的数量,i是样本编号,y是标签,并且模型的y(带上标)是预测值。
在这种情况下,例如,使用由以下表达式(3)和表达式(4)表示的平方误差函数或对数损失函数作为误差函数l。
作为表达式(1)的第二项的正则项Ω(θ),例如,使用由以下表达式(5)表示的参数θ的平方范数。在这种情况下,λ是表示正则化权重的超参数。
Ω(θ)=λ||θ||
本文考虑GBDT。首先,GBDT的第i个样本数据x
在这种情况下,K是决策树的总数,k是决策树的数目,f
对上述目标函数进行学习,但是用于神经网络的学习的随机梯度下降(SGD)之类的方法不能用于决策树模型。因此,通过使用加法训练(增强)来进行学习。在加法训练中,回合(学习的次数,决策树模型的数目)t中的预测值由以下表达式(8)表示。
从表达式(8)可以发现,决策树f
在这种情况下,在回合t中目标函数的泰勒展开式(在二阶项处被截断)由以下表达式(10)表示。
在这种情况下,在表达式(10)中,梯度信息g
当在表达式(10)中忽略常数项时,回合t中的目标函数由以下表达式(12)表示。
在表达式(12)中,回合t的目标函数由正则化项和通过对前一回合的预测值对误差函数进行一阶微分和二阶微分而获得的值表示,因此可以发现,可以在其上执行一阶微分和二阶微分的误差函数被应用。
下面考虑决策树模型。图1示出了决策树模型的示例。决策树模型包括节点和叶。在该节点上,输入在某个分支条件下输入到下一个节点或叶,并且叶具有叶权重,叶权重变为与输入相对应的输出。例如,图1示出了“叶2”的叶重量W2为“-1”的事实。
决策树模型由以下表达式(13)表示。
f
在表达式(13)中,w表示叶的重量,q表示树的结构。即,根据树的结构q将输入(样本数据x)分配给任何叶,并且输出叶的叶重量。
在这种情况下,定义决策树模型的复杂度,如以下表达式(14)所示。
在表达式(14)中,第一项表示由于叶数量而引起的复杂性,第二项表示叶重量的平方范数。γ是用于控制正则项的重要性的超参数。基于以上描述,如以下表达式(15)所示组织回合t中的目标函数。
然而,在表达式(15)中,I
根据表达式(15),回合t中的目标函数是与叶权重w有关的二次函数,并且二次函数的最小值及其条件通常由以下表达式(17)表示。
即,当确定回合t中的决策树的结构q时,目标函数及其叶权重由以下表达式(18)表示。
在这一点上,使得能够在某一回合中确定决策树的结构时计算叶权重。下面描述学习决策树的结构的过程。
学习决策树的结构的方法包括贪婪算法(Greedy Algorithm)。贪婪算法是一种算法,该算法从深度0开始启动树结构,并通过计算每个节点的分支得分(增益)来确定是否分支,从而学习决策树的结构。通过以下表达式(19)获得分支得分。
在这种情况下,G
由上述表达式(19)表示的分支得分表示以特定特征量的某个阈值进行分支时的良性,但是不能基于单个分支得分来确定最佳条件。因此,在贪婪算法中,针对所有特征量的所有阈值候选者获得分支得分,以找到分支得分最大的条件。贪婪算法是如上所述的非常简单的算法,但是其计算成本很高,因为对于所有特征量的所有阈值候选都获得了分支得分。因此,对于像XGBoost(下文将描述)之类的库,设计了一种在保持性能的同时降低计算成本的方法。
关于XGBoost
下面介绍了众所周知的作为GBDT库的XGBoost。在XGBoost的学习算法中,设计了两点,即降低候选阈值和处理缺失值。
首先,以下描述阈值候选的减少。上述的贪婪算法具有计算成本高的问题。在XGBoost中,通过加权分位数草图的方法减少了候选阈值的数量。在该方法中,左右分支的样本数据的梯度信息之和在计算分支得分(增益)时很重要,并且仅梯度信息之和以恒定比率变化的阈值是要被搜索的阈值候选。具体地,使用样本的二阶梯度h。假设特征量的维数为f,则样本量的特征量和二次梯度h的集合由下式(20)表示。
D
RANK函数r
在这种情况下,z是阈值候选。表达式(21)中的RANK函数r
|r
s
s
在这种情况下,ε是用于确定阈值候选的降低程度的参数,并且可以获得约1/ε阈值候选。
作为加权分位数草图,可以考虑两种模式,即在决策树的第一个节点上执行加权分位数草图的全局模式(在所有样本数据上共同执行),和在每个节点上执行分位数草图(每次在分配给相应节点的样本上执行)的局部模式。就泛化性能的角度而言,局部模式是合适的,因此在XGBoost中采用了局部模式。
接下来将描述缺失值的处理。不管GBDT和决策树如何,通常没有有效的方法来处理要在机器学习领域中输入的样本数据的缺失值。例如,存在用平均值、中值、协同滤波器等来对缺失值进行补充的方法,以及排除包括大量缺失值的特征量的方法,但从性能角度考虑,这些方法在许多情况下并非被很成功实现。然而,结构化数据通常包含缺失值,因此在实际使用中需要采取一些措施。
在XGBoost中,学习算法被设计为直接处理包含缺失值的样本数据。这是一种在将丢失值的所有数据分配给左节点和右节点中的任何一个节点时获得得分的方法,以获取该节点的分支得分。在执行上述加权分位数草图的情况下,可以针对排除包括缺失值的样本数据的集合获得阈值候选。
关于LightGBM
接下来,以下将描述作为GBDT的库的LightGBM。LightGBM采用一种快速算法,该算法采用特征量的量化(称为归入统计堆)进行预处理,并利用GPU计算分支得分。LightGBM的性能与XGBoost基本上相同,并且LightGBM的学习速度是XGBoost的几倍。近年来,LightGBM的用户有所增加。
首先,以下描述特征量的量化。当数据集规模较大时,需要为大量的阈值候选者计算分支得分。在LightGBM中,通过将特征量量化为学习的预处理来减少候选阈值的数量。另外,由于量化,阈值候选的值和数量对于每个节点不会像XGBoost中那样变化,因此在使用GPU的情况下,LightGBM是必不可少的处理。
已经进行了各种以分级的名义对特征量进行量化的研究。在LightGBM中,特征量被划分为k个堆,并且仅存在k个阈值候选。例如,k是255、63和15,且性能或学习速度取决于数据集。
由于特征量的量化,简化了分支得分的计算。具体地,阈值候选变为简单的量化值。因此,对于每个特征量创建一阶梯度和二阶梯度的直方图,并获得每个区间的分支得分(量化值)就足够了。这被称为特征量直方图。
接下来将描述利用GPU的分支得分的计算。由于对特征量进行了量化,因此分支得分的计算模式最大为256,但是根据数据集,样本数据的数量可能会超过数万,因此直方图的创建将占主要的学习时间。如上所述,在计算分支得分时需要获得特征量直方图。在利用GPU的情况下,多个线程需要更新相同的直方图,但是此时可以更新相同的堆位。因此,需要使用原子操作,并且当更新相同堆的比率高时,性能会下降。因此,在LightGBM中,对于创建直方图的每个线程,需要确定使用一阶梯度和二阶梯度的哪个直方图来更新值,这降低了同一个堆的更新频率。
学习和鉴别装置的配置
图2是示出根据实施例的学习和鉴别装置的模块配置的示例的示意图。图3是示出指针存储器的配置示例的示意图。图4是示出学习模块的模块配置的示例的示意图。以下,参照图2至图4,对本实施方式的学习和鉴别装置1的模块结构进行说明。
如图2所示,根据本实施例的学习和鉴别装置1包括CPU 10,学习模块20(学习单元),数据存储器30,模型存储器40和分类模块50(鉴别单元)。其中,学习模块20,数据存储器30,模型存储器40和分类模块50由FPGA构成。CPU 10可以经由总线执行与FPGA的数据通信。除了图2所示的组件之外,学习和鉴别装置1还可以包括其他组件,例如,用作CPU 10的工作区域的RAM,存储CPU 10执行的计算机程序或类似内容的只读存储器(ROM),辅助存储设备存储各种数据(计算机程序等)和与外部设备通信的通信I/F。
CPU 10是控制GBDT整体学习的算术装置。CPU 10包括控制单元11。控制单元11控制包括学习模块20,数据存储器30,模型存储器40和分类模块50的各个模块。控制单元11由通过CPU 10执行的计算机程序实现。
学习模块20是硬件模块,其针对构成决策树的每个节点计算最佳特征量的数量(在下文中有时也称为“特征量数量”)以及阈值,并且其中节点为叶,计算要写入模型存储器40的叶权重。如图4所示,学习模块20还包括增益计算模块21_1、21_2,...和21_n(增益计算器)和最佳条件推导模块22(推导单元)。在这种情况下,n是至少等于或大于样本数据(包括学习数据和鉴别数据两者)的特征量的数量的数。在指增益计算模块21_1、21_2,...和21_n中的可选增益计算模块的情况下,或者在指全部增益计算模块21_1、21_2,...和21_n的情况下,他们被简称为“增益计算模块21”。
增益计算模块21是针对要输入的样本数据中包括的特征量中的对应特征量,使用上述表达式(19)在每个阈值处计算分支得分的模块。在这种情况下,样本数据的学习数据除了特征量之外还包括标签(真值),并且样本数据的鉴别数据包括特征量而不包括标签。每个增益计算模块21包括存储器,该存储器对一次(1个计时单位中)输入的所有特征量的各个直方图执行运算并存储直方图,并且对所有特征量并行地执行运算。基于直方图的结果,并行地计算各个特征量的增益。因此,可以一次或同时对所有特征量执行处理,从而可以显着提高学习处理的速度。这种并行读取和处理所有特征量的方法称为特征并行。为了实现此方法,数据存储器需要能够一次(在一计时单位内)读出所有特征量。因此,此方法不能在具有正常数据宽度(如32位或256位宽度)的内存中实现。使用软件时,CPU一次最多可以处理的数据位数通常最多为64位,即使一次特征量的数量为100,而每个特征量的位数为8位,那也需要8000位,因此根本无法实现该方法。因此,在相关技术中,所采用的方法是为存储器的每个地址存储不同的特征量(例如,CPU可以处理的64位宽度),并在多个地址中整体存储特征量。另一方面,本方法包括新颖的技术内容,使得所有特征量被存储在存储器的一个地址处,并且可以通过一次访问读出所有特征量。
如上所述,在GBDT中,决策树的学习无法并行化。因此,学习每个决策树的速度决定了学习处理的速度。另一方面,在用于进行整体学习的RF中,学习时的决策树之间没有依赖性,因此可以容易地并行化每个决策树的学习处理,但是其准确性通常低于GBDT。如上所述,通过将如上所述的特征并行应用于具有比RF更高的精度的GBDT的学习,可以提高决策树的学习处理的速度。
增益计算模块21将计算出的分支得分输出到最佳条件推导模块22。
最佳条件推导模块22是接收与从每个增益计算模块21输出的特征量相对应的每个分支得分的输入,并且推导阈值和分支得分最大的的特征量的数量(特征量数量)的模块。最佳条件推导模块22将推导的特征量数量和阈值作为对应节点的分支条件数据(节点的数据的示例)写入模型存储器40。
数据存储器30是存储各种数据的SRAM。数据存储器30包括指针存储器31,特征存储器32和状态存储器33。
指针存储器31是存储特征存储器32中存储的样本数据的存储目的地地址的存储器。如图3所示,指针存储器31包括库A(库区域)和库B(库区域)。稍后将参考图5至图13详细描述将区域划分为包括库A和库B的两个库,并存储样本数据的存储目的地地址的操作。指针存储器31可以有三个或更多的库。
特征存储器32是存储样本数据(包括学习数据和鉴别数据)的存储器。
状态存储器33是存储状态信息(上述w,g和h)和标签信息的存储器。
模型存储器40是SRAM,其存储针对决策树的每个节点的分支条件数据(特征量数量和阈值),指示该节点是否是叶的叶标志(标志信息,节点数据的示例),以及在节点为叶的情况下的叶权重。
分类模块50是硬件模块,其为每个节点和每个决策树分配样本数据。分类模块50计算要写入状态存储器33中的状态信息(w,g,h)。
不仅在上述学习处理中的样本数据(学习数据)的鉴别(分支)中,分类模块50也可以在样本数据(鉴别数据)的鉴别处理中以相同的模块配置来鉴别该鉴别数据。在鉴别处理时,可以通过集中读取所有特征量来对由分类模块50执行的处理进行流水线处理,并且可以提高处理速度,从而使每个计时单位能鉴别出一个样本数据。另一方面,在不能如上所述地集体地读取特征量的情况下,除非分支到相应的节点,否则无法找到需要哪一个特征量,因此,不能以每次访问相应特征量的地址的形式进行流水线处理。
假设设置了上述多个分类模块50,则可以将多个鉴别数据进行划分(并行数据)以分配给各个分类模块50,并且可以使每个分类模块50执行鉴别处理以提高鉴别处理的速度。
学习和鉴别设备的学习处理
下面参考图5至图13具体描述学习和鉴别设备1的学习处理。
初始化
图5是示出根据实施例的在初始化学习和鉴别装置时模块的操作的图。如图5所示,首先,控制单元11初始化指针存储器31。例如,如图5所示,控制单元11将指针存储器31的地址写入指针存储器31的库A中。特征存储器32中的样本数据(学习数据)的地址与学习数据的数量按顺序(例如,以地址的升序)相对应。
不一定要使用所有学习数据(不一定要写入所有存储地址),并且有可能使用基于以下内容随机选择的学习数据(只写入所选学习数据的地址)通过所谓的数据二次采样对应于预定随机数的概率。例如,在数据二次采样的结果为0.5的情况下,可以以一半的概率将学习数据的所有地址的一半对应随机数写入指针存储器31(在本例中,库A)。其中,可以使用由线性反馈移位寄存器(LFSR)创建的伪随机数来生成随机数。
用于学习的学习数据的所有特征量不是必须使用的,并且与上文所谓的特征子采样的描述类似,可以仅使用基于与随机数相对应的概率随机选择的特征量(例如,选择一半)。在这种情况下,例如,可以从特征存储器32输出常数作为从特征子采样选择的特征量以外的特征量的数据。因此,对未知数据(鉴别数据)的综合性能得到了可见的提升。
确定在深度0,节点0处的分支条件数据。
图6是示出在确定根据实施例的学习和鉴别装置在深度0,节点0处的节点参数的情况下模块的操作的图。假设决策树的层次结构的顶部是“深度0”,低于该顶部的层次结构级别依次称为“深度1”,“深度2”,…。具体的层级被称为“节点0”,并且其右侧的节点依次被称为“节点1”,“节点2“,...。
如图6所示,首先,控制单元11将起始地址和结束地址发送到学习模块20,并通过触发器使学习模块20开始处理。学习模块20基于起始地址和结束地址从指针存储器31(库A)指定目标学习数据的地址,从特征存储器32中读出学习数据(特征量),并且根据该地址从状态存储器33中读出状态信息(w,g,h)。
在这种情况下,如上所述,学习模块20的每个增益计算模块21计算对应特征量的直方图,将该直方图存储在其SRAM中,并且基于该直方图的结果计算在每个阈值处的分支得分。学习模块20的最佳条件推导模块22接收与从增益计算模块21输出的与每个特征量相对应的分支得分的输入,并且推导阈值和该分支得分最大的的特征量的数量(特征量数量)。然后,最佳条件推导模块22将推导的特征量数量和阈值作为对应节点(深度0,节点0)的分支条件数据写入模型存储器40。这一点,最佳条件推导模块22设置叶标志为“0”,以指示分支进一步从节点(深度0,节点0)执行,并将该节点的数据(这可能是部分的分支条件数据)写入模型存储器40。
学习模块20通过依次指定被写入库A的学习数据的地址并基于该地址从特征存储器32中读出各条学习数据来执行上述操作。
在深度0,节点0处的数据分支处理
图7是示出根据实施例的学习和鉴别装置的在深度0,节点0处的分支时的模块的操作的图。
如图7所示,控制单元11将起始地址和结束地址发送到分类模块50,并通过触发器使分类模块50开始处理。分类模块50基于起始地址和结束地址从指针存储器31(库A)指定目标学习数据的地址,并基于该地址从特征存储器32中读出学习数据(特征量)。分类模块50还从模型存储器40中读出对应节点(深度0,节点0)的分支条件数据(特征量数量,阈值)。分类模块50根据分支条件数据来确定使所读出的样本数据往节点(深度0,节点0)的左侧还是右侧分支,并且基于所确定的结果,分类模块50将特征存储器32中的学习数据的地址写入指针存储器31中与读出库(在本例中,库A)(用于读出的库区域)不同的其他库(写入库)(在本例中,库B)(用于写入的库)中。
此时,如图7所示,如果确定分支执行到节点的左侧,则分类模块50以地址的升序将学习数据的地址写入库B中。如果确定分支执行到该节点的右侧,则分类模块50以地址降序将学习数据的地址写入库B中。因此,在写入库(库B)中,以一种明显分离的方式,分支到节点左侧的学习数据的地址被写入为较低的地址,而分支到节点右侧的学习数据的地址被写入为较高的地址。或者,在写入库中,以分开的方式,分支到节点左侧的学习数据的地址被写入为较高的地址,而分支到节点右侧的学习数据的地址被写入为较低的地址。
如上所述,以此方式,在指针存储器31中配置了两个库,即库A和库B,并且尽管FPGA中SRAM的容量是有限的,但通过在其上交替执行读取和写入,可以有效地使用该存储器。作为一种简化方法,存在一种将特征存储器32和状态存储器33中的每一个配置为具有两个库的方法。然而,指示特征存储器32中的地址的数据通常小于样本数据,从而可以如本实施例中那样通过准备指针存储器31以间接地指定地址的方法来进一步减少存储器的使用。
如上所述,分类模块50对所有学习数据进行分支处理。然而,在分支处理结束之后,分离到节点的左侧和右侧(深度0,节点0)的各个学习数据的数量不同,因此分类模块50向控制单元11返回写入库(库B)中对应于分支到左侧的学习数据的地址和分支到右侧的学习数据的地址之间的边界的地址(中间地址)。中间地址在下一个分支处理中使用。
确定在深度1,节点0处的分支条件数据。
图8是示出在确定根据实施例的学习和鉴别设备的深度1的节点0处的节点参数的情况下模块的操作的图。该操作与图6所示的确定深度为0,节点0的分支条件数据的处理基本相同,但是目标节点的等级被改变(从深度0到深度1),从而指针存储器31中的库A和库B的作用相反。具体地,库B用作读出库,并且库A用作写入库(参考图9)。
如图8所示,控制单元11通过深度0的处理,基于从分类模块50接收到的中间地址,将起始地址和结束地址发送给学习模块20,并且使学习模块20开始由触发器处理。学习模块20基于起始地址和结束地址从指针存储器31(库B)指定目标学习数据的地址,基于该地址从特征存储器32中读出学习数据(特征量),并从状态存储器33中读出状态信息(w,g,h)。具体地,如图8所示,学习模块20在库B中按从左侧(下地址)到中间地址的顺序指定地址。
在这种情况下,如上所述,学习模块20的每个增益计算模块21将读出的学习数据的特征量存储在其SRAM中,并在每个阈值处计算分支得分。学习模块20的最佳条件推导模块22接收与从增益计算模块21输出的与每个特征量相对应的分支得分的输入,并且推导阈值和分支得分最大的特征量的数量(特征量数量)。然后,最佳条件推导模块22将推导的特征量数量和阈值作为对应节点(深度1,节点0)的分支条件数据写入模型存储器40。此时,最佳条件推导模块22将叶标志设置为"0",表示从节点(深度1,节点0)进一步进行分支,并将该节点的数据(这可能是分支条件数据的一部分)写入模型存储器40中。
学习模块20在库B中按从左侧(较低地址)到中间地址的顺序指定地址,并基于该地址从特征存储器32中读出各条学习数据,来执行上述操作。
在深度1的节点0处的数据分支处理。
图9是示出根据该实施例的学习和鉴别装置在深度1的节点0处分支时的模块的操作的图。
如图9所示,控制单元11基于通过深度0的处理从分类模块50接收到的中间地址,将起始地址和结束地址发送给分类模块50,并使分类模块50开始由触发器处理。分类模块50基于起始地址和结束地址从指针存储器31(库B)的左侧指定目标学习数据的地址,并根据地址从特征存储器32中读出学习数据(特征量)。分类模块50还从模型存储器40中读出对应的节点(深度1,节点0)的分支条件数据(特征量数量,阈值)。分类模块50确定是否使所读出的样本数据根据分支条件数据分支到节点(深度1,节点0)的左侧或右侧,并且基于确定的结果,分类模块50将特征存储器32中的学习数据的地址写入指针存储器31中与读出的库(在本例中,用于读取的库区域)(在本例中,库B)不同的另一库(在本例中,用于写入的库区域)(在本例中,库A)。
此时,如图9所示,如果确定分支执行到节点的左侧,则分类模块50以地址的升序将学习数据的地址写入库A中。如果确定分支执行到该节点的右侧,则分类模块50以地址降序将学习数据的地址写入库A中。因此,在写入库(库A)中,以分离的方式,分支到节点左侧的学习数据的地址被写入为较低的地址,而分支到节点右侧的学习数据的地址被写入为较高的地址。或者,在写入库中,以分离的方式,分支到节点左侧的学习数据的地址被写入为较高的地址,而分支到节点右侧的学习数据的地址被写入为较低的地址。
作为上述操作,分类模块50对所有学习数据中的,由写在库B中的中间地址左侧的地址所指定的地址所指定的学习数据进行分支处理。然而,在分支处理结束之后,分离到节点的左侧和右侧(深度1,节点0)的各个学习数据的数目不同,使得分类模块50向控制单元11返回写入库(库A)中的地址(中间地址),该地址对应于向左侧分支的学习数据的地址和向右侧分支的学习数据的地址的中间。中间地址在下一个分支处理中被使用。
在深度1的节点1处的分支条件数据的确定
图10是示出在确定根据实施例的学习和鉴别装置的深度1,节点1处的节点参数的情况下模块的操作的图。与图8的情况类似,层次级别与深度1,节点0的节点的相同,因此库B用作读出库,库A用作写入库(请参阅图11)。
如图10所示,控制单元11基于深度0的处理从分类模块50接收到的中间地址,将起始地址和结束地址发送至学习模块20,并由触发器使学习模块20开始处理。学习模块20基于起始地址和结束地址从指针存储器31(库B)指定目标学习数据的地址,基于该地址从特征存储器32中读出学习数据(特征量),并从状态存储器33中读出状态信息(w,g,h)。具体地,如图10所示,学习模块20在库B中按从右侧(较高地址)到中间地址的顺序指定地址。
如上所述,在这种情况下,学习模块20的每个增益计算模块21将读出的学习数据的每个特征量存储在其SRAM中,并在每个阈值处计算分支得分。学习模块20的最佳条件推导模块22接收与从增益计算模块21输出的与每个特征量相对应的分支得分的输入,并且推导阈值和分支得分最大的特征量的数量(特征量数量)。然后,最佳条件推导模块22将推导的特征量数量和阈值作为对应节点(深度1,节点1)的分支条件数据写入模型存储器40。此时,最佳条件推导模块22将叶标志设置为"0",表示从节点(深度1,节点1)进一步进行分支,并将该节点的数据(这可能是分支条件数据的一部分)写入模型存储器40中。
学习模块20通过从库B中的右侧(较高地址)到中间地址依次指定地址,并基于该地址从特征存储器32中读出各条学习数据,来执行上述操作。
在深度1的节点1处的数据分支处理
图11是示出根据实施例的学习和鉴别装置在深度1,节点1处分支时的模块的操作的示意图。
如图11所示,控制单元11基于深度0的处理从分类模块50接收到的中间地址,将起始地址和结束地址发送给分类模块50,并使分类模块50开始由触发器处理。分类模块50基于起始地址和结束地址从指针存储器31(库B)的右侧指定目标学习数据的地址,并根据地址从特征存储器32中读出学习数据(特征量)。分类模块50从模型存储器40中读出对应节点(深度1,节点1)的分支条件数据(特征量数量,阈值)。然后,分类模块50确定是否使读出的样本数据根据分支条件数据分支到节点(深度1,节点1)的左侧或右侧,并且基于确定结果,分类模块50将特征存储器32中的学习数据的地址写入指针存储器31中与读出的库(在此例中,用于读出的库区域)(在此例中,库B)不同的另一库(在此例中,库A)(在此例中,用于写入的库区域)。
此时,如图11所示,如果确定分支到节点的左侧,则分类模块50以地址的升序将学习数据的地址写入库A中。如果确定分支执行到该节点的右侧,则分类模块50以地址降序将学习数据的地址写入库A中。因此,在写入库(库A)中,以明显分离的方式,分支到节点左侧的学习数据的地址被写入为较低的地址,而分支到节点右侧的学习数据的地址被写入为较高的地址。或者,在写入库中,以分离的方式,分支到节点左侧的学习数据的地址被写入为较高的地址,而分支到节点右侧的学习数据的地址被写入为较低的地址。在这种情况下,需要同时执行图9中的操作。
如上所述,分类模块50对所有学习数据中的,由写在库B中的中间地址的右侧的地址所指定的地址所指定的学习数据进行分支处理。然而,在分支处理结束之后,分离到节点(深度1,节点1)的左侧和右侧的各个学习数据的数量不同,使得分类模块50向控制单元11返回写入库(库A)中的地址(中间地址),该地址对应于向左侧分支的学习数据的地址和向右侧分支的学习数据的地址的中间。该中间地址在下一个分支处理中被使用。
在确定深度1,节点1处的分支条件数据时未执行分支的情况。
图12是示出根据实施例的学习和鉴别装置确定在确定深度1,节点1处节点参数而没有执行分支的情况下模块的操作的示意图。与图8的情况类似,层次等级与深度1,节点0的节点的层次等级相同,因此库B用作读出库。
如图12所示,控制单元11基于通过在深度0的处理从分类模块50接收到的中间地址,将起始地址和结束地址发送给学习模块20,并由触发器使学习模块20开始处理。学习模块20基于起始地址和结束地址从指针存储器31(库B)指定目标学习数据的地址,基于该地址从特征存储器32中读出学习数据(特征量),并从状态存储器33中读出状态信息(w,g,h)。具体地,如图12所示,学习模块20在库B中按从右侧(较高地址)到中间的地址顺序指定地址。
如果基于所计算的分支得分等确定将不再从节点(深度1,节点1)进行分支,则学习模块20将叶标志设置为“1”,并将节点的数据(这可能是分支条件数据的一部分)写入进入模型存储器40,并将该节点的叶标志为“1”的事实发送给控制单元11。因此,可以认识到,分支不执行到比节点(深度1,节点1)更低的层次级别。在节点(深度1,节点1)的叶标志为“1”的情况下,学习模块20将叶权重(w)(可能是分支条件数据的一部分)写入模型存储器40中,以代替特征量数量和阈值。因此,与容量被单独固定在模型存储器40中的情况相比,这种情况下模型存储器40的容量可能会减少。
通过对每个等级(深度)执行图6至图12所示的上述处理,完成整个决策树(决策树完成学习)。
决策树完成学习的情况下
图13是示出在根据实施例的学习和鉴别装置完成了决策树的学习的情况下,在更新所有样本数据的状态信息时模块的操作的示意图。
在完成了对构成GBDT的一个决策树的学习的情况下,对应于每条学习数据的误差函数的一阶梯度g和二阶梯度h,以及每条学习数据的叶权重w需要被计算以用于增强(在这种情况下是梯度增强)到下一个决策树。如图13所示,控制单元11通过触发器使分类模块50开始上述计算。分类模块50对所有学习数据上的所有深度(层次级别)的节点执行分支确定的处理,并计算与每条学习数据相对应的叶权重。然后,分类模块50基于标签信息为所计算的叶权重计算状态信息(w,g,h),并将状态信息(w,g,h)写回到状态存储器33的原始地址。以这种方式,通过利用更新的状态信息来执行下一决策树的学习。
如上所述,在根据本实施例的学习和鉴别设备1中,学习模块20包括用于读取输入样本数据的各个特征量的存储器(例如,SRAM)。因此,可以通过一次访问来读取样本数据的所有特征量,并且每个增益计算模块21可以一次对所有特征量进行处理,因此加快了决策树的学习处理速度。
在根据本实施例的学习和鉴别装置1中,两个库,即库A和库B被配置在指针存储器31中,并且交替进行读取和写入。因此,可以有效地使用存储器。作为简化方法,存在一种将特征存储器32和状态存储器33中的每一个配置为具有两个库的方法。然而,指示特征存储器32中的地址的数据通常小于样本数据,从而如本实施例那样,可以通过准备指针存储器31以间接地指定地址的方法来进一步节省存储容量。如果确定分支执行到该节点的左侧,分类模块50从两个库的写入库中的低位地址开始按顺序写入学习数据的地址,并且如果确定分支被执行到节点的右侧,则分类模块50从写入库中的较高地址依次写入学习数据的地址。因此,在写入库中,以明显分离的方式,分支到节点左侧的学习数据的地址被写入为较低的地址,分支到节点右侧的学习数据的地址被写入为较高的地址。
修改例
图14是示出根据修改例的学习和鉴别装置的模型存储器的配置示例的示意图。参照图14,下面描述根据本修改例的学习和鉴别装置1的模型存储器40中的针对决策树的每个深度(层次级别)提供存储器的配置。
如图14所示,根据本修改例的学习和鉴别装置1的模型存储器40包括用于深度0的存储器41_1,用于深度1的存储器41_2,...,以及用于深度(m-1)的存储器41_m,用于存储学习的决策树的模型数据的每个深度(层次级别)的数据(具体地,分支条件数据)。在这种情况下,m是至少等于或大于决策树的模型的深度(层次级别)的数量的数。即,模型存储器40包括用于针对每个深度(层次级别)同时提取数据(深度0节点数据,深度1节点数据,...,深度(m-1)节点数据)的独立端口。学习的决策树的模型数据。因此,分类模块50可以基于决策树的第一节点处的分支结果并行地在所有深度(层次级别)上读出与下一个节点相对应的数据(分支条件数据),并且可以在各个节点处执行分支处理。在不使用存储器的情况下,在一个计时单位数据(鉴别数据)中同时在一个计时单位(管道处理)中同时进行多个深度(层次级别)的分析。因此,由分类模块50执行的鉴别处理仅花费与样本数据的数量相对应的时间,并且鉴别处理的速度可以显着提高。另一方面,在相关技术中,每一个节点的样本数据都被复制到一个新的存储器区域,由于存储器进行读写的时间而影响了速度,而鉴别处理所需的时间等于(样本数据的数量×深度(层次)的数量),因此,根据本修改的鉴别处理具有如上所述的巨大优势。
图15是示出修改例的学习和鉴别装置的分类模块的结构的示例的示意图。如图15所示,分类模块50包括节点0鉴别器51_1,节点1鉴别器51_2,节点2鉴别器51_3,...。每个计时单位的样本数据从特征存储器32提供作为特征量。如图15所示,特征量首先被输入到节点0鉴别器51_1,并且节点0鉴别器51_1从对应于模型存储器40深度0的对应存储器41_1接收节点的数据(深度0节点数据)(是否向右分支或向右分支的条件,以及要使用的特征量编号)。节点0鉴别器51_1根据条件鉴别对应的样本数据是向右还是向左分支。在这种情况下,每个用于深度的存储器(用于深度0的存储器41_1,用于深度1的存储器41_2,用于深度2的存储器41_3,...)的延迟被假设为1个计时单位。基于节点0鉴别器51_1获得的结果,深度1的下一存储器41_2中的地址指定样本数据是否分支且分支到哪个数目的节点,并且相应节点的数据(深度1节点数据)被提取并输入到节点1鉴别器51_2。
深度0的存储器41_1的延迟是1个计时单位,因此特征量以1个计时单位的延迟类似地输入到节点1鉴别器51_2。下一个样本数据的特征量以相同的计时单位输入到节点0鉴别器51_1。这样,通过流水线处理来进行鉴别,在存储器对每个深度同时执行输出的前提下,一棵决策树整体上能够以1个计时单位来鉴别一个样本数据。深度0的存储器41_1仅需要一个地址,因为深度0处有一个节点,深度1的存储器41_2则需要两个地址,因为深度1处有两个节点,类似地,存储器需要四个地址深度2为41_3,深度3的存储器需要8个地址(未显示)。尽管分类模块50区分整个树,但是可以在学习节点时仅使用节点0鉴别器51_1进行学习以通过使用相同电路来减小电路规模。
第二实施方式
以下将以与第一实施方式的学习和鉴别装置1的不同点为中心,对第二实施方式的学习和鉴别装置进行说明。在第一实施方式中,以存在存储样本数据的数据存储器30为前提,说明了GBDT的学习处理和鉴别处理。本实施例描述了通过将数据存储器划分为多个部分以实现用于并行处理多个样本数据的数据并行的学习处理的操作。
关于数据并行
图16是示出应用了数据并行的学习和鉴别装置的模块配置的示例的示意图。参考图16,下面描述学习和鉴别设备1a的配置作为用于实现数据并行的配置的示例。
为了对样本数据(学习数据或鉴别数据)实现数据并行,首先,如图16所示,可以将数据存储器划分为两个数据存储器30a和30b,以保持划分后的样本数据。在图16的数据存储器30b中,数据存储器30b类似于数据存储器30a还包括指针存储器31,特征存储器32和状态存储器33。然而,仅划分存储样本数据的存储器是不够的,并且需要用于对划分后的样本数据并行执行处理(学习处理,鉴别处理等)的机制。在图16所示的配置示例中,进行鉴别处理的模块数与划分后的数据存储器相同。即,学习和鉴别装置1a具有分类模块50a,50b,该分类模块50a,50b对分别存储在两个数据存储器30a,30b中的各样本数据进行鉴别处理。针对每个单独的模块,假设通过特征并行执行处理,如上所述,为了实现数据并行,几乎不改变模块的配置,从而便于其实现。
为了提高学习处理速度(即,学习模块20执行的处理)而并行的数据存在如下问题:由于将数据存储器划分为两个数据存储器30a和30b,用于保存划分的样本数据,因此电路规模增大了。以及如上所述,保存在学习处理的过程中计算出的特征量的直方图(以下有时也称为“梯度直方图”)和梯度信息的存储器(参照上述式(11))与数据存储器的划分数量成比例地增加。
使用梯度直方图计算分支得分的方法
首先,下面描述学习模块20计算分支得分的方法。在这种情况下,假设样本数据(在这种情况下,学习数据)的特征量为量化为具有一定的位宽。例如,在特征量为8位(256个图案的值)并且特征量的维数为100的情况下,学习模块20计算出256×100=25600个图案的分支得分。在这种情况下,阈值的候选数量为256。
为了计算与某个分支条件(一个阈值对应一个特征量)相对应的分支得分,需要获得特征量等于或大于阈值(对应于阈值)的学习数据的梯度信息之和(对应上述表达式(19)中的G
表1
如表1所示,特征量有3种模式,即0、1和2,因此阈值也为0、1和2,每个阈值处的梯度信息之和是一个值由以下(表2)表示,并且计算与3个模式的每个阈值相对应的分支得分。
表2
为了获得特定阈值的梯度信息之和,需要参考当前节点处的所有学习数据。如果每次都应针对所有阈值执行此处理,则将花费很长时间。例如,在特征量是8位(256个模式)的情况下,阈值也有256个模式,因此需要获得梯度信息的总和(当前学习数据的数量×256)次。这将花费非常长的时间,因此通过预先获得针对特征量的每个值的梯度信息的总和(梯度直方图)和梯度信息的总和和梯度直方图的累积和,简化了分支得分的计算处理。
在上述(表1)表示的样本数据的情况下,针对特征量的每个值的梯度信息的总和(梯度直方图)变为由以下(表3)表示的值。
表3
特征量的每个值的梯度信息的总和为0.1+0.2+0.1-0.3=0.1。在这种情况下,总和G
表4
使用这种方法,每次引用一次当前节点上的学习数据就足够了,此后,可以通过参考与阈值数量相对应的梯度直方图来获得所有分支条件的分支得分。在特征量是8位(256个模式)的情况下,执行处理(当前节点处的学习数据的数量+256)次就足够了。上述情况是特征量具有一维的情况,但是即使特征量具有两个或更多个维,也可以通过针对特征量的每个维数获得梯度直方图来并行地计算相同的处理。下面描述图17所示的学习模块20计算梯度直方图并获得分支条件数据的配置和操作,该配置基于图4说明第一实施例中通过特征并行执行学习的学习模块20的配置,并进一步描述使用数据并行配置的情况下的配置和操作。
用于使用梯度直方图获得分支条件数据的学习模块的配置示例。
图17是示出了学习模块的特定模块配置的示例的示意图。参考图17,下面更详细地描述表示上述图4所示的配置的学习模块20的配置和操作。
图17所示的学习模块20包括增益计算模块21_1、21_2,...和21_n,以及最佳条件推导模块22。在这种情况下,n是至少等于或大于样本数据的特征量类型数量(在这种情况下为学习数据)的数。在指增益计算模块21_1、21_2,...和21_n当中的可选的增益计算模块的情况下,或者在合指增益计算模块21_1、21_2,...和21_n的情况下,它们被简称为“增益计算模块21”。
增益计算模块21_1至21_1n中的每个是针对要输入的样本数据中包括的特征量中的对应特征量使用上述表达式(19)来计算每个阈值处的分支得分的模块。增益计算模块21_1包括梯度直方图计算模块61_1,累积梯度计算模块62_1和计算模块63_1。
梯度直方图计算模块61_1是使用输入的样本数据的特征量的每个值作为直方图的堆,通过对与样本数据相对应的梯度信息的值进行积分来计算梯度直方图的模块。
累积梯度计算模块62_1是通过针对特征量的每个阈值获得梯度直方图的累积和来计算梯度信息的总和(G
计算模块63_1是使用上述表达式(19)并使用由累积梯度计算模块62_1计算出的梯度信息之和来计算每个阈值处的分支得分的模块。
类似地,增益计算模块21_2包括梯度直方图计算模块61_2,累积梯度计算模块62_2和计算模块63_2,并且它们同样适用于增益计算模块21_n。在指梯度直方图计算模块61_1、61_2,...和61_n之中可选的梯度直方图计算模块的情况下,或者合指梯度直方图计算模块61_1、61_2,...和61_n的情况下,它们被简称为“梯度直方图计算模块61”。在指累积梯度计算模块62_1、62_2,...和62_n之中可选的累积梯度计算模块的情况下,或合指累积梯度计算模块62_1、62_2,...和62_n的情况下,它们被简称为“累积梯度计算模块62”。在指示计算模块63_1、63_2,...和63_n中的可选计算模块的情况下,或一起称为计算模块63_1、63_2,...和63_n的情况下,它们被简称为“计算模块63”。
最佳条件推导模块22是接收与从各个增益计算模块21输出的每个阈值和每个特征量相对应的分支得分的输入,并且推导阈值和分支得分最高的特征量的数量(特征量数量)的模块。最佳条件推导模块22将推导的特征量数量和阈值作为对应节点的分支条件数据(节点的数据的示例)写入模型存储器40。
梯度直方图计算模块的配置和操作
图18是示出学习模块的梯度直方图计算模块的模块配置的示例的示意图。参考图18,下面描述学习模块20中的梯度直方图计算模块61的配置和操作。图18示出假设特征量具有一维的情况以及梯度信息。假设包括第一阶梯度g和第二阶梯度h,在某些情况下可以将其简单地称为梯度信息g和梯度信息h。
如图18所示,梯度直方图计算模块61包括数据计数器201、加法器202、延迟器203、梯度直方图存储器204、总计存储存储器205、加法器206、延迟器207、梯度直方图存储器208和总计存储存储器209。
数据计数器201输出用于从数据存储器30中读出要进行学习处理的样本数据(特征量)以及相应的梯度信息g和h的地址。
加法器202将从梯度直方图存储器204读出的相加的梯度信息g与从数据存储器30新读出的梯度信息g相加。
延迟器203以与将由加法器202相加的梯度信息g写入梯度直方图存储器204的定时相匹配的延迟来输出从数据存储器30读出的特征量。
梯度直方图存储器204是这样的存储器,其使用特征量的值作为地址连续存储相加的梯度信息g,并且最后存储针对特征量的每个值(堆)的梯度直方图。
总计存储存储器205是存储从数据存储器30读出的梯度信息g的总和的存储器。
加法器206将从梯度直方图存储器208读出的相加的梯度信息h与从数据存储器30新读出的梯度信息h相加。
延迟器207以与将由加法器206相加的梯度信息h写入梯度直方图存储器208的定时相匹配的延迟来输出从数据存储器30读出的特征量。
梯度直方图存储器208是使用特征量的值作为地址连续存储相加的梯度信息h的存储器,并且最后存储针对特征量的每个值(堆)的梯度直方图。
总计存储存储器209是存储从数据存储器30读出的梯度信息h的总和的存储器。
下面简单描述梯度直方图计算模块61计算梯度直方图的操作过程。首先,梯度直方图计算模块61读出存储在其中的当前节点的一条学习数据(特征量,梯度信息)。使用从数据计数器201输出的地址将数据存储在数据存储器30中。加法器202使用从数据存储器30中读出的特征量作为地址从梯度直方图存储器204中读出梯度信息g(相加的梯度信息g)。然后,加法器202将从梯度直方图存储器204中读出的梯度信息g(相加后的梯度信息g)与从数据存储器30中读出的梯度信息g相加,然后,使用从数据存储器30读出的特征量作为地址,将相加的梯度信息g写入(更新)到梯度直方图存储器204中。总计存储存储器205每当从数据存储器30中读出梯度信息g时,将多条梯度信息g相加,并存储梯度信息g的总和。由加法器206、延迟器207、梯度直方图存储器208和总计存储存储器209执行的关于梯度信息h的处理也相同。对当前节点的所有学习数据重复执行上述操作。
累积梯度计算模块的配置和操作
图19是示出学习模块的累积梯度计算模块的模块配置的示例的示意图。参考图19,下面描述学习模块20中的累积梯度计算模块62的配置和操作。图19示出的情况中,特征量被假设是一维的,梯度信息被假设包括一阶梯度g和二阶梯度h。
如图19所示,累积梯度计算模块62包括阈值计数器210、累加器211、延迟器212,差计算器213、累加器214、延迟器215和差计算器216。
阈值计数器210输出阈值,该阈值是用于从梯度直方图存储器204和208中读出针对特征量的每个值相加的梯度信息(g,h),即特征数量的每个值的梯度直方图。
累加器211从梯度直方图存储器204中读出与从阈值计数器210输出的阈值(地址)相对应的梯度信息g的梯度直方图,并进一步将梯度直方图累积在当前存储的梯度直方图的累加和上,并保存为梯度直方图的新累积和。
延迟器212将从梯度累加器211读出的梯度信息g的梯度直方图的累积和作为梯度信息g的和G
差计算器213通过从从总计存储存储器205中读出的梯度信息g的总和中减去梯度信息g的梯度直方图的累积总和(即从累加器211读出的梯度信息g的和G
累加器214从梯度直方图存储器208中读出与从阈值计数器210输出的阈值(地址)相对应的梯度信息h的梯度直方图,进一步将梯度直方图累积在当前存储的梯度直方图的累加和上,并保存为梯度直方图的新累积和。
延迟器215将从累加器214读出的梯度信息h的梯度直方图的累积和作为梯度信息h的和H
延迟器215将从梯度累加器214读出的梯度信息h的梯度直方图的累积和作为梯度信息h的和H
下面简单描述由累积梯度计算模块62执行的计算梯度信息和(G
首先,累积梯度计算模块62使用阈值作为从阈值计数器210输出的地址来读取存储在梯度直方图存储器204中的梯度信息g的梯度直方图。累加器211从梯度直方图存储器204中读出与从阈值计数器210输出的阈值相对应的梯度信息g的梯度直方图,将梯度直方图累积在当前存储的梯度直方图的累积和上,并且将其存储为梯度直方图的新的累积和。差计算器213通过从从总计存储存储器205中读出的梯度信息g的总和中减去从累加器211中读出的梯度信息g的梯度直方图的累积总和(即梯度信息g的总和G
在实现数据并行的情况下的梯度直方图计算模块。
图20是示出在实现数据并行的情况下的梯度直方图计算模块的模块配置的示例的示意图。参考图20,下面描述在实现数据并行的情况下梯度直方图计算模块61的配置和操作。图20示出了以下情况:数据并行的划分数被假设为2,特征量被假设为具有一维,并且梯度信息被假设为仅包括一阶梯度g。
如图20所示,为了实现划分数为2的数据并行,配置了作为分开的数据存储器的数据存储器30a和30b以代替图18所示的数据存储器30,梯度存储器直方图计算模块61a和61b被配置以代替梯度直方图计算模块61。
如图20所示,梯度直方图计算模块61a包括数据计数器201a、加法器202a、延迟器203a、梯度直方图存储器204a和总计存储存储器205a。梯度直方图计算模块61b包括数据计数器201b、加法器202b、延迟器203b、梯度直方图存储器204b和总计存储存储器205b。数据计数器201a和201b、加法器202a和202b、延迟器203a和203b、梯度直方图存储器204a和204b以及总计存储存储器205a和205b的功能与上面参考图18描述的相应功能相同。
如图20所示,在简单地配置数据并行的情况下,与数据存储器30类似,要布置的梯度直方图计算模块61的数目可以与划分数目相同。在这种情况下,梯度直方图存储器的数量等于(特征量的维数×划分数)。在图20所示的示例中,特征量具有一维,并且划分数为2,因此布置了两个梯度直方图存储器204a和204b。另外,在将一阶梯度g和二阶梯度h的各个梯度直方图存储器考虑为梯度信息的情况下,梯度直方图存储器所需的总容量等于(一个存储器的容量(堆数×位宽度)×2(一阶梯度g,二阶梯度h)×特征量的维数×的数量)。在大规模数据集中,特征量的维数在很多情况下可能是几百到几千,也就是说,当增加划分数时需要大量的存储器。因此,存储器的容量成为瓶颈,并且电路规模增大。例如,在特征量是8位(256个模式)并且具有2000个维数的情况下,梯度信息包括两个梯度,即一阶梯度g和二阶梯度h,且梯度直方图的位宽度为12位,要建立12位×256=3072位,因此一个梯度直方图存储器的存储容量需要满足3072位。通常基于2的幂来准备存储器,因此,在这种情况下,存储器容量为4096位(4kbit)。因此,在一个划分(或无划分)的情况下,梯度直方图存储器的总容量表示如下。
4千位×2(一阶梯度g,二阶梯度h)×2000维数=16兆位
即,每1个划分(无划分)需要16Mbit的存储容量,并且在划分存储器的情况下,需要(分区数×16Mbit)的存储容量。
例如,以下考虑Xilinx公司生产的名为virtex UltrScale+VU9P的芯片作为高端FPGA的情况。可以用于梯度直方图存储器的电路包括分布式RAM和块RAM。在VU9P中,分布式RAM的最大值为36.1Mbit,而块RAM的最大值为75.9Mbit。因此,在将分布式RAM用作梯度直方图存储器的情况下,两分区是极限,而在使用块RAM的情况下,四分区是极限。除了保持梯度直方图的目的之外,还需要将分布式RAM和块RAM用于其他目的,以使得划分次数的上限小于上述数目。因此,在特征量和梯度信息的集合被并行输入的情况下,与上述参照图17-图20的学习模块20的配置相比较,需要一个可以计算和存储配置小规模电路的梯度直方图的配置。以下描述了根据本实施例参照图21至图26的学习模块的配置和操作。
根据第二实施例的学习模块的配置。
图21是示出根据第二实施例的学习和鉴别装置的学习模块的模块配置的示例的示意图。参考图21,下面描述根据本实施例的学习和鉴别设备(学习装置的示例)的学习模块20a的配置和操作。在图21中,数据并行的划分数被假设为2,并且特征量被假设为具有一维。
如图21所示,根据本实施例的学习模块20a包括梯度直方图计算模块71、累积梯度计算模块72(累积梯度计算器)、计算模块73(得分计算器)以及最佳条件推导模块22。
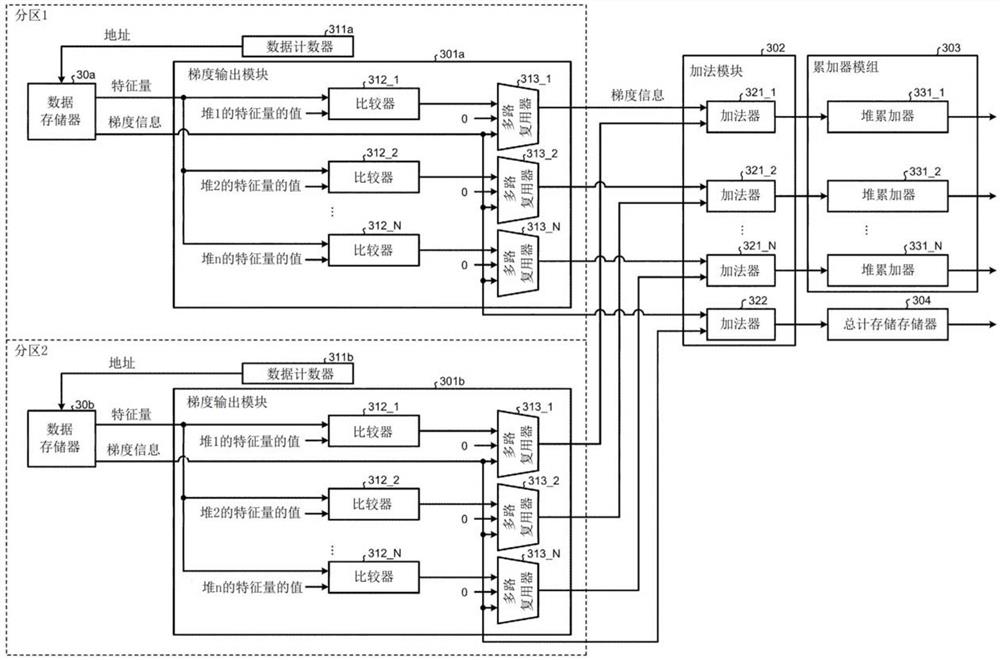
梯度直方图计算模块71是通过积分与样本数据,使用输入样本数据的特征量的每个值作为直方图的堆来计算梯度直方图(一种直方图的示例)的模块。梯度直方图计算模块71包括梯度输出模块301a和301b(梯度输出单元)、加法模块302(加法单元)、累加器模块303(直方图存储单元)以及总计存储存储器304。
梯度输出模块301a和301b中的每一个是包括与特征量的每个值相对应的输出端口的模块,该模块从数据存储器30a和30b(数据存储单元)接收特征量和梯度信息的输入,并通过输出端口输出与输入特征量的值相对应的梯度信息。
加法模块302是针对特征量的每个值(堆)将要输出的相应的梯度信息加起来的模块。
累加器模块303是将从加法模块302输入的加法梯度信息与当前针对特征量的每个值(堆)存储的加法梯度信息相加的模块,并且针对最终的每一个堆存储该梯度信息的梯度直方图。
总计存储存储器304是存储由加法模块302计算出的梯度信息的总和的存储器。
累积梯度计算模块72是通过针对特征量的每个阈值获得梯度直方图的累积和来计算梯度信息的和(G
计算模块73是使用上述表达式(19)并使用由累积梯度计算模块72计算出的梯度信息之和来计算每个阈值处的分支得分的模块。
最佳条件推导模块22是接收与从计算模块73输出的每个特征量(在图21中为一个特征量)和每个阈值相对应的分支得分的输入,并推导分支得分最大的阈值和特征量的数量(特征量数量)的模块。最佳条件推导模块22将推导的特征量数量和阈值作为对应节点的分支条件数据(节点的数据的示例)写入模型存储器40。
如图21所示,为了在划分数为2的情况下实现数据并行,将存储器划分为两个存储器,即数据存储器30a和30b,并且梯度直方图计算模块71被划分为两个模块,即前一级的梯度输出模块301a和301b。在图21中,物理划分单元被表示为“分区1”和“分区2”。
梯度直方图计算模块的配置和操作。
图22是示出根据第二实施例的学习模块的梯度直方图计算模块的模块配置的示例的示意图。参考图22,下面描述根据本实施例的学习模块20a中的梯度直方图计算模块71的配置和操作。图21示出了以下情况:假设数据并行的划分数为2,特征量被假设为具有一维,并且梯度信息被假设为仅包括一条信息(例如,一阶梯度g)。
如图21所示,梯度直方图计算模块71除了以上参考图20描述的配置之外,还包括数据计数器311a和311b。
数据计数器311a输出用于从数据存储器30a中读出要进行学习处理的样本数据(特征量)和对应的梯度信息的地址。
如图22所示,梯度输出模块301a包括比较器312_1、312_2,...和312_N(确定单元)以及多路复用器313_1、313_2,...和313_N(选择器)。在这种情况下,N是特征量可以采用的值的数量,并且是梯度直方图中的堆数。在指比较器312_1、312_2,...和312_N中的可选比较器的情况下,或合指比较器312_1、312_2,...和312_N的情况下,它们简称为“比较器312”(确定单元)。在指多路复用器313_1、313_2,...和313_N中的可选多路复用器的情况下,或合指多路复用器313_1、313_2,...和313_N的情况下,它们简称为“多路复用器313”(选择器)。
比较器312接收从数据存储器30a读出的特征量的值和特定箱的特征量的值的输入,并且将这些值相互比较。如果这些值彼此相同,则比较器312将这些值彼此相同的事实(例如,电压电平的ON输出)输出到多路复用器313。例如,在特征从数据存储器30a读出的数据量等于箱1的特征量的值,比较器312_1将值彼此相同的事实输出到多路复用器313_1。
多路复用器313接收输入0和由比较器312从数据存储器30a中读出的与特征量(学习数据)相对应的梯度信息,并根据比较结果输出来输出输入梯度信息或0。复用器313_1从比较器312_1接收信号。例如,多路复用器313_1接收0的输入和与由比较器312_1从数据存储器30a读出的特征量相对应的梯度信息,将输入的梯度信息作为与在从比较器312_1输出的比较结果指示值彼此相同的情况下,作为对应于堆1的梯度信息输出输入梯度信息,在比较结果指示值彼此不同的情况下输出0。即,在这种机制中,与特征量相对应的梯度信息从与从数据存储器30a中读出的特征量的值相对应的多路复用器313输出,并且从另一个多路复用器313输出0。
数据存储器30b,数据计数器311b和梯度输出模块301b的功能分别与上述数据存储器30a、数据计数器311a和梯度输出模块301a的功能相同。
加法模块302针对特征量的每个值,即针对每个堆,将从多路复用器313输入的梯度信息相加,并且将相加的梯度信息输出至累加器模块303。加法模块302包括加法器321_1、321_2,...和321_N,以及加法器322。
加法器321_1、321_2,...和321_N中的每个加法器针对箱1、2,...和N中的每一个将从多路复用器313输入的梯度信息相加,并且将相加后的梯度信息输出到累加器模块303例如,加法器321_1将梯度信息作为来自与梯度输出模块301a中的箱1相对应的多路复用器313_1的输出,与梯度信息作为来自与梯度输出模块301b中的箱1相对应的多路复用器313_1的输出相加,并将相加的梯度信息输出到累加器模块303(在本例中,是后述的堆1累加器331_1)。
加法器322接收要求和的梯度信息的输入,分别由梯度输出模块301a和梯度输出模块301b从数据存储器30a和30b读出的梯度信息。然后,加法器322将相加的梯度信息输出到总计存储存储器304。
累加器模块303将从加法模块302输入的相加梯度信息与当前针对特征量的每个值(堆)保持的相加梯度信息相加,并最终存储针对每个堆的梯度信息的梯度直方图。累加器模块303包括堆1累加器331_1,堆2累加器331_2,...和堆N累加器331_N。
堆1累加器331_1,堆2累加器331_2,...和堆N累加器331_N将从各个加法器321_1、321_2,...和321_N输入的相加梯度信息加到当前的相加梯度信息上。例如,堆1累加器331_1将从加法器321_1输入的相加梯度信息与当前保持的相加梯度信息相加,并存储堆1的梯度信息的梯度直方图。
总和储存储器304将从加法器322输出的相加梯度信息与当前保持的相加梯度信息相加。即,总计存储存储器304存储与所有学习数据相对应的梯度信息的总数。
下面简单描述由根据本实施例的梯度直方图计算模块71执行的计算梯度直方图的操作过程。数据计数器311a(311b)输出用于从数据存储器30a中读出要进行学习处理的样本数据(特征量)和对应的梯度信息的地址。梯度输出模块301a(301b)的比较器312接收从数据存储器30a(30b)读出的特征量的值和特定箱的特征量的值的输入,并将这些值相互比较。如果值彼此相同,则比较器312将值彼此相同的事实输出到多路复用器313。多路复用器313接收0和与特征量(学习数据)相对应的梯度信息的输入。通过比较器312从数据存储器30a(30b)中读出“0”,并根据从比较器312输出的比较结果输出0或输入梯度信息。其中,各加法器321_1、321_2,...,321_N加法模块302对每个堆1、2,...和N从多路复用器313输入的梯度信息相加,并将相加的梯度信息输出到累加器模块303。累加器模块303的堆1累加器331_1,堆2累加器331_2,...和堆N累加器331_N分别从加法器321_1、321_2,...和321_N输入的相加梯度信息与当前保存的每个堆1,2,...和N的相加梯度信息相加,最后保存每个堆的梯度信息的梯度直方图。上述操作对当前节点上的所有学习数据重复执行。
在如上所述的根据本实施例的梯度直方图计算模块71的配置中,梯度直方图针对特征量的每个堆被存储在对应的寄存器(累加器)中,而不是如常规配置中那样被存储在存储器中。图22所示的梯度直方图计算模块71的配置可以通过寄存器的数量等于(特征量的堆数×特征量的维数(在图22中,维数为1))的寄存器来实现。即,将存储梯度直方图所需的总容量表示为(堆数×位宽度×2(一阶梯度g,二阶梯度h)×特征量的维数),也即与划分数无关。因此,与图20所示的传统配置相比,可以大大减小用于存储梯度直方图的电路容量。另外,在根据本实施例的梯度直方图计算模块71的配置中,电路规模与划分数无关,因此,只要其他模块的电路规模允许,就可以增加数据并行的划分数并提高学习处理的速度。
例如,在特征量为8位(256个模式)并且具有2000个维数的情况下,并且梯度信息包括两个梯度,即一阶梯度g和二阶梯度h,该数量所需寄存器的表示如下。
256(堆数)×2(一阶梯度g,二阶梯度h)×2000[维数]=1024000[寄存器]
在使用上述叫做VU9P的芯片的情况下,寄存器的最大数量为2364000,因此根据本实施例的直方图计算模块71,可以将保持梯度直方图所需的寄存器数量抑制为梯度配置中最大寄存器数量的一半。
图23是示出在根据第二实施例的学习模块中假设划分数为3的情况下的梯度直方图计算模块的模块配置的示例的示意图。参考图23,下面描述在假设用于数据并行的划分数为3的情况下的梯度直方图计算模块71的配置示例。图23示出一种情况,其中特征量被假设具有一维,并且假设梯度信息仅包括一条信息(例如,一阶梯度g)。
例如,在图23中,加法模块302包括加法器321_1_1,...和321_N_1,加法器321_1_2,...和321_N_2以及加法器322_1和322_2。如在图23所示的梯度直方图计算模块71中,加法模块302可以以逐步的方式积分(累加)多条梯度信息。例如,关于堆1,加法器321_1_1将从“分区1”输出的梯度信息与从“分区2”输出的梯度信息相加,以输出至加法器321_1_2。加法器321_1_2将从加法器321_1_1输出的和与从“除法3”输出的梯度信息相加,以输出至累加器模块303的堆1累加器331_1。
累积梯度计算模块的配置和操作。
图24是示出根据第二实施例的学习模块的累积梯度计算模块的模块配置的示例的示意图。参考图24,下面描述根据本实施例的学习模块20a中的累积梯度计算模块72的配置和操作。图24举例说明了以下情况:假设“数据并行”的划分数为1,假设特征量为一维,并且假设梯度信息包含两条信息(例如,一阶梯度g和二阶梯度h)。
图19所示的常规累积梯度计算模块62使用来自阈值计数器210的输出(阈值)作为地址来访问梯度直方图存储器204(208)。在图24中,寄存器(累加器)保存每个堆的梯度直方图,使得经由多路复用器从每个堆仅提取与阈值计数器的阈值相对应的值。
如图24所示,累积梯度计算模块72包括阈值计数器340、累加器341、延迟器342、差计算器343、累加器344、延迟器345、差计算器346以及多路复用器347和348。在图24中,假设对应于一阶梯度g的累加器模块303和总计存储存储器304分别是累加器模块303g和总计存储存储器304g。假设对应于二阶梯度h的累加器模块303和合计存储存储器304分别是累加器模块303h和合计存储存储器304h。
阈值计数器340输出从累加器模块303g和303h中得到的阈值,用于读出针对特征量的每个值(堆)添加的梯度信息(g,h),即,特征量的每个堆的梯度直方图。
多路复用器347从阈值计数器340接收阈值的输入,以及累加器模块303g的每个累加器(堆1累加器331_1,堆2累加器331_2,...以及堆N累加器331_N)的存储值(梯度直方图)的输入。然后,多路复用器347将与各个堆的输入梯度直方图中的与阈值计数器340相对应的堆位相对应的梯度直方图输出到累加器341。
多路复用器348从阈值计数器340接收阈值的输入,以及累加器模块303h的每个累加器(堆1累加器331_1,堆2累加器331_2,...以及堆N累加器331_N)的存储值(梯度直方图)的输入。然后,多路复用器348将与各个堆的输入梯度直方图中的与阈值计数器340相对应的堆位相对应的梯度直方图输出到累加器344。
累加器341从多路复用器347接收与从阈值计数器340输出的阈值相对应的梯度信息g的梯度直方图的输入,将输入的梯度直方图累积在当前存储的梯度直方图的累积和上,并将其保存为梯度直方图的新累积和。
延迟器342延迟从梯度累加器341读出的作为信息G
差计算器343通过从总计存储存储器304g中读出的梯度信息g的合计总和减去从梯度累加器341中读出的梯度信息g的梯度直方图的累积和(即,梯度信息g的总和G
累加器344从多路复用器348接收与从阈值计数器340输出的阈值相对应的梯度信息h的梯度直方图的输入,将输入的梯度直方图累积在当前存储的梯度直方图的累积和上,并将其保存为梯度直方图的新累积和。
延迟器345延迟从梯度累加器344读出的梯度信息h的梯度直方图的累积和作为信息H
差计算器346通过从总计存储存储器304h中读出的梯度信息h的合计总和中减去从累加器344中读出的梯度信息h的梯度直方图的累积和(即,梯度信息h的和H
下面简单描述由累积梯度计算模块72执行的计算梯度信息的总和(G
首先,多路复用器347从阈值计数器340接收阈值的输入,以及累加器模块303g的每个累加器(堆1累加器331_1,堆2累加器331_2,...,和堆N累加器331_N)的存储值(梯度直方图)的输入。复用器347将与各个堆位的输入梯度直方图中的与阈值计数器340相对应的堆位相对应的梯度直方图输出到累加器341。然后,累加器341从多路复用器347接收与从阈值计数器340输出的阈值相对应的梯度信息g的梯度直方图的输入,将输入的梯度直方图累积在当前存储的梯度直方图的累积和上,并将其保存为梯度直方图的新累积和。延迟器342延迟从梯度累加器341读出的作为信息G
由此,在梯度直方图计算模块71预先进行了梯度信息的梯度直方图的计算和存储处理之后,累积梯度计算模块72和计算模块73进行处理。因此,可以提高由学习模块20a执行的针对分支得分(增益)的计算处理的速度。
维数数为2时学习模块的配置。
图25是示出在根据第二实施例的学习和鉴别装置中假设特征量的类型的数量为2的情况下的学习模块的模块配置的示例的示意图。图26是示出在根据第二实施例的学习模块中假设特征量的类型的数量为2的情况下的梯度直方图计算模块的模块配置的示例的示意图。参考图25和图26,下面描述根据本实施例的学习和鉴别设备(学习装置的示例)的学习模块20b的配置和操作。图25示出了假设数据并行的划分数为2的情况。
如图25所示,学习模块20b包括梯度直方图计算模块71,累积梯度计算模块72_1和72_2、计算模块73_1和73_2以及最佳条件推导模块22。梯度直方图计算模块71包括梯度输出。模块301a_1、301a_2、301b_1和301b_2、加法模块302_1和302_2、累加器模块303_1和303_2以及总计存储存储器304_1和304_2的总和。如图26所示,梯度直方图计算模块71除了图25所示的配置之外,还包括数据计数器311a和311b。
如图26所示,每个梯度输出模块301a_1、301a_2、301b_1和301b_2包括比较器312_1、312_2,...和312_N,以及多路复用器313_1、313_2,...和313_N。每个加法模块302_1和302_2包括加法器321_1、321_2,...和321_N,以及加法器322。每个累加器模块303_1和303_2包括堆1累加器331_1、堆2累加器331_2,...和N堆累加器331_N。
在图25和图26所示的配置中,梯度输出模块301a_1和301b_1、加法模块302_1、累加器模块303_1、总计存储存储器304_1、累积梯度计算模块72_1和计算模块73_1用于“特征量1”的处理。另一方面,梯度输出模块301a_2和301b_2、加法模块302_2、累加器模块303_2、总计存储存储器304_2、累积梯度计算模块72_2和计算模块73_2用于对应于“特征量2”的处理。每个模块的操作与上述参考图22和图24描述的操作相同。
如上所述,存储梯度直方图所需的容量表示为(二进制数×位宽度×2(一阶梯度g,二阶梯度h)×特征量的维数),因此,需要累加器模块303(在图25中,累加器模块303_1和303_2)的数量与特征量的维数相对应。但是,由于容量与划分数无关,所以尽管图25和图26示出了划分数为2的情况,只要配置两个累加器模块303就足够了。即使划分数等于或大于3,特征量的维数也为2。
如上所述,在根据本实施例的学习和鉴别装置的学习模块20a(20b)中,梯度直方图计算模块71将梯度直方图存储在针对特征量的每个堆的对应寄存器(累加器)中,而不是如在图20中所示的常规配置中那样,将梯度直方图存储在存储器中。梯度直方图计算模块71的可以配置其数量等于(特征量的堆数×特征量的维数)的寄存器。即,存储梯度直方图所需的总容量表示为(堆数×位宽度×2(一阶梯度g,二阶梯度h)×特征量的维数),与划分数无关。因此,与图20所示的常规配置相比,可以大大减小保存为特征量而创建的梯度直方图信息和并行输入的梯度信息的的存储器(累加器,寄存器)的电路规模。另外,在根据本实施例的梯度直方图计算模块71的配置中,电路规模与划分数无关,因此,只要其他模块的电路规模允许,可以增加数据并行的划分数,并且可以提高学习处理的速度。
示例
下面描述由根据上述实施例的学习和鉴别设备1执行的学习处理的速度的预测结果。
首先,对上述作为GBDT的代表性库的XGBoost和LightGBM的学习速度进行评估以进行比较。2017年12月,使用GPU的LightGBM的学习速度很高,并且对此速度进行了测量。
根据硬件配置的计时单位来计算处理时间。在这种情况下实现的硬件逻辑中,该处理主要包括三个处理,即,由学习模块20执行的学习处理,由分类模块50执行的鉴别处理(以节点为单位)以及鉴别分类模块50执行的处理(以树为单位)。
关于由学习模块执行的处理
在这种情况下,主要的处理是计算分支得分并从样本数据的每个特征量创建梯度直方图。根据样本数据的每个特征量创建梯度直方图时,需要针对每个深度(层次级别)读取所有样本数据。对某些样本数据的学习在树的浅层处结束,因此该估计是最大值。为了计算分支得分,参考了梯度直方图的所有堆,因此需要与堆数(特征量的维数)相对应的计时单位。因此,学习模块20执行的处理过程的计时单位数C
C
在这种情况下,n
关于由分类模块执行的处理(以节点为单位),
在这种情况下,执行处理以确定使用学习到的节点的结果将样本数据分配给左侧还是右侧的下级节点。对于每个深度处理的样本数据的总数是恒定的,因此计时单位C
C
关于由分类模块执行的处理(以树为单位),
在这种情况下,在结束一个决策树的学习之后,针对每个样本数据更新梯度信息以用于学习下一决策树。因此,需要使用学习的决策树对所有样本数据进行预测。在以树为单位的处理中,存在与深度相对应而导致的延迟。在这种情况下,计时单位C
C
在这种情况下,所有样本数据是指子采样之前所有学习样本数据和所有验证样本数据的总数。
因此,用于一个决策树的学习处理的计时单位C
C
GBDT包含大量决策树,因此,假设决策树的数量为n
C
上文描述的是上述特征并行情况下的测试计算。对于所谓的数据并行,在并行布置大量模块并为每个数据划分模块的情况下,基本上可以在每个模块的每个节点的数据都是平衡的情况下对应于模块的数量而提高速度。不平衡的程度取决于样本数据和为每个模块划分样本数据的方法,因此在下文中将使用实际数据来检查该耗损。根据预测,即使考虑到此耗损,也可以将效率提高50%或更高。
关于使用过的数据
从大约十万条数据中随机选择学习数据和鉴别数据(用于评估的数据)作为测试用的样本数据,以下内容代表数据集的概述。
类数:2
特征量的维数:129
学习数据的数量:63415
评估数据的数量:31707
速度的测量条件如下所示(表5)。假设处于工作状态的FPGA的计时单位频率为100[MHz](实际中,计时单位频率很有可能是更高的值)。
表5
硬件逻辑
下表(表6)表示使用上述计算速度的表达式计算上述架构的学习速度的测试计算。然而,该测试计算是在所有样本数据的最后到达分支的情况下的测试计算,并且表示最差值。
表6
包括通过CPU和GPU进行的实际测量的比较结果
下表(表7)表示通过CPU和GPU进行的实际测量结果。为了比较,其中还包括硬逻辑的测试计算结果。到目前为止,仅使用特征并行(Feature Parallel)进行了测试计算,因此添加了同时使用数据并行(Data Parallel)的情况下的测试计算结果作为参考。
表7
*1英特尔酷睿i7-5930K(6C12T 3.5GHz)
*2 GPU GTX1080Ti/CPU核心英特尔酷睿i7 7700(4C8T 3.6GHz)
*3本测试计算是在数据为15行并行,数据并行效率为75%(假设使用KC705基板)的条件下进行的
*4本测试计算是在数据为240行并行,数据并行效率为50%(假设使用AWS f1.16xlarge实例)的条件下进行的
可以发现,与使用CPU的情况相比,即使在使用GPU的情况下,当前数据的学习速度也会降低。微软公司作为LightGBM的开发者指出,在使用GPU的情况下,学习速度提高了约3到10倍,但是学习速度很大程度上取决于数据。可以发现的是,GPU无法成功提高当前数据的学习速度。该结果还表示,与CNN相比,使用GBDT的算法不容易提高GPU的学习速度。由于使用了CPU,与作为最基本库的XGBoost相比,以LightGBM为后发者的学习速度提高了约10倍。通过仅使用特征并行的硬逻辑,学习速度提高到了个人计算机(PC)中最快的CPU(LightGBM)的大约2.3倍。根据测试计算,在还使用15并行的数据并行的情况下,即使将数据并行的效率假设为75%,学习速度也会提高25倍或更多,考虑使用240并行和AWSf1.16xlarge,如果效率假设为50%,则学习速度会提高275倍或更多。然而,该测试计算是在存储带达到极限的情况下的测试计算。
FPGA的功耗预计为几W,而CPU和GPU的功耗等于或大于100W,除了速度之外,功耗之间相差两位数,因此它们之间的功率效率可能相差三位数或更多位数。
参考标号
1和1a学习和鉴别设备
10 CPU
11控制单元
20、20a和20b学习模块
21、21_1和21_2得分计算模块
22最佳条件推导模块
30、30a和30b数据存储器
31指针存储器
32特征存储器
33状态存储器
40模型存储器
41_1深度0的存储器
41_2深度1的存储器
41_3深度2的存储器
50、50a和50b鉴别模块
51_1节点0的鉴别器
51_2节点1的鉴别器
51_3节点2的鉴别器
61、61_1和61_2梯度直方图计算模块
61a和61b梯度直方图计算模块
62、62_1和62_2累积梯度计算模块
63、63_1和63_2计算模块
71梯度直方图计算模块
72、72_1和72_2累积梯度计算模块
73、73_1和73_2计算模块
201、201a和201b数据计数器
202、202a和202b加法器
203、203a和203b延迟器
204、204a和204b梯度直方图存储器
205、205a和205b总计总和存储存储器
206加法器
207延迟器
208梯度直方图存储器
209总计总和存储存储器
210阈值计数器
211累加器
212延迟器
213差计算器
214累加器
215延迟器
216差计算器
301a、301a_1和301a_2梯度输出模块
301b、301b_1和301b_2梯度输出模块
302、302_1和302_2加法模块
303、303_1和303_2累加模块
303g和303h累加模块
304、304_1和304_2总计总和存储器
304g和304h总计总和存储器
311a和311b数据计数器
312、312_1和312_2比较器
313、313_1和313_2多路复用器
321_1和321_2加法器
321_1_1和321_1_2加法器
322、322_1和322_2加法器
331_1堆1累加器
331_2堆2累加器
340阈值计数器
341累加器
342延迟器
343差计算器
344累加器
345延迟器
346差计算器
347和348多路复用器
引用列表
专利文献
专利文献1:日本特开2013-8270号公报
非专利文献
非专利文献1:Michal Drozdz和Tomasz Kryjak,“使用HOG功能和SVM分类器的多尺度面部检测的FPGA实现”。图像处理与通信21.3(2016):27-44页。
- 掩模计算装置、簇权重学习装置、掩模计算神经网络学习装置、掩模计算方法、簇权重学习方法和掩模计算神经网络学习方法
- 循环神经网络的学习方法及用于该学习方法的计算机程序、和声音识别装置