智能体装置、智能体装置的控制方法及存储介质
文献发布时间:2023-06-19 09:36:59
技术领域
本发明涉及智能体装置、智能体装置的控制方法及存储介质。
背景技术
以往,公开了一边与车辆的乘员进行对话一边提供与乘员的要求相应的与驾驶支援相关的信息、车辆的控制、其他应用程序等的智能体功能所相关的技术(例如,参照专利文献1(日本特开2006-335231号公报))。
发明内容
发明要解决的课题
然而,在以往的技术中,利用的方案是限定的。
本发明的目的之一在于,提供能够提供更具发展性的利用的方案的智能体装置、智能体装置的控制方法及存储介质。
用于解决课题的手段
本发明的智能体装置、智能体装置的控制方法及存储介质采用了以下的结构。
(1):本发明的一方案的智能体装置根据用户的讲话来提供包括基于声音的响应的服务,其中,所述智能体装置具备:检测部,其检测所述用户讲话时的说话方式;以及信息提供部,其在由所述检测部检测到在所述用户的讲话中包括规定的说话方式的情况下,向所述用户提供用于矫正所述规定的说话方式的信息。
(2):在上述(1)的方案中,所述智能体装置还具备登记由所述检测部检测到的所述用户讲话时的口头禅的口头禅登记部,所述信息提供部在由所述检测部检测到由所述口头禅登记部登记的口头禅的频率为阈值以上的情况下,向所述用户提供用于将以所述阈值以上的频率检测到的所述用户的口头禅作为所述规定的说话方式进行矫正的信息。
(3):在上述(1)或(2)的方案中,所述智能体装置还具备登记由所述检测部检测到的所述车辆的乘员的讲话时的方言的方言登记部,所述信息提供部在由所述检测部检测到由所述方言登记部登记的规定的方言的情况下,向所述用户提供用于将所述规定的方言作为所述规定的说话方式进行矫正的信息。
(4):本发明的另一方案的智能体装置根据用户的讲话来提供包括基于声音的响应的服务,其中,所述智能体装置具备:方言指定接受部,其接受所述用户对方言的指定的指示;以及信息提供部,其向所述用户提供用于以使所述用户的说话方式接近由所述方言指定接受部接受到的方言的方式进行引导的信息。
(5):在本发明的另一方案的智能体装置的控制方法中,使计算机执行以下处理:根据用户的讲话来提供包括基于声音的响应的服务;检测所述用户讲话时的说话方式;以及在检测到在所述用户的讲话中包括规定的说话方式的情况下,向所述用户提供用于矫正所述规定的说话方式的信息。
(6):本发明的另一方案的存储介质存储有程序,所述程序使计算机执行以下处理:根据用户的讲话来提供包括基于声音的响应的服务;检测所述用户讲话时的说话方式;以及在检测到在所述用户的讲话中包括规定的说话方式的情况下,向所述用户提供用于矫正所述规定的说话方式的信息。
发明效果
根据(1)~(6),能够提供更具发展性的利用的方案。
附图说明
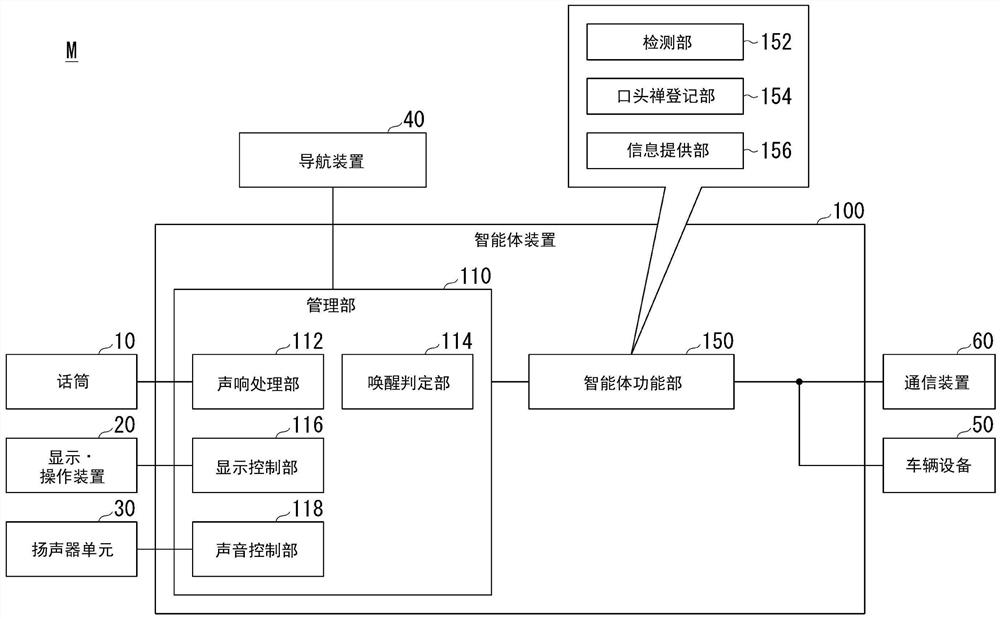
图1是示出包括智能体装置100的智能体系统1的结构的图。
图2是示出第一实施方式的智能体装置100的结构和搭载于车辆M的设备的图。
图3是示出登记于说话方式DB205的数据内容的一例的图。
图4是示出智能体服务器200的结构和智能体装置100的结构的一部分的图。
图5是用于说明第一实施方式的智能体装置100的一系列处理的流程的流程图。
图6是用于说明第一实施方式的智能体装置100的动作的图。
图7是示出第二实施方式的智能体装置100的结构和搭载于车辆M的设备的图。
图8是用于说明第二实施方式的智能体装置100的一系列处理的流程的流程图。
图9是用于说明第二实施方式的智能体装置100的动作的图。
图10是示出第三实施方式的智能体装置100的结构和搭载于车辆M的设备的图。
图11是用于说明第三实施方式的智能体装置100的一系列处理的流程的流程图。
图12是用于说明第三实施方式的智能体装置100的动作的图。
附图标记说明:
10…话筒,20…显示·操作装置,30…扬声器单元,40…导航装置,50…车辆设备,60…通信装置,100…智能体装置,110…管理部,112…声响处理部,114…唤醒判定部,116…显示控制部,118…声音控制部,150…智能体功能部,152…检测部,154…口头禅登记部,156…信息提供部,200…智能体服务器。
具体实施方式
<第一实施方式>
以下,参照附图,对本发明的智能体装置、智能体装置的控制方法及存储介质的第一实施方式进行说明。
智能体装置是实现智能体系统的一部分或全部的装置。以下,作为智能体装置的一例,对搭载于车辆(以下,记为车辆M)且具备智能体功能的智能体装置进行说明。智能体功能例如是以下功能:至少部分地利用使用了无线通信装置的网络连接,一边与车辆M的乘员进行对话,一边进行基于乘员的讲话中包含的要求(指令)的各种信息提供或者对网络服务进行中介。在智能体功能中,可以存在具有进行车辆内的设备(例如驾驶控制、车身控制所涉及的设备)的控制等的功能的智能体功能。
智能体功能例如除了识别乘员的声音的声音识别功能(将声音文本化的功能)之外还综合地利用自然语言处理功能(理解文本的构造、含义的功能)、对话管理功能、经由网络而检索其他装置或者检索本装置持有的规定的数据库的网络检索功能等而实现。这些功能的一部分或全部可以由AI(Artificial Intelligence)技术实现。另外,用于进行这些功能的结构的一部分(尤其是,声音识别功能、自然语言处理解释功能)也可以搭载于能够与车辆M的通信装置通信的智能体服务器(外部装置)。在以下的说明中,将结构的一部分搭载于智能体服务器且智能体装置和智能体服务器协同配合来实现智能体系统设为前提。另外,将智能体装置和智能体服务器协同配合而假想地出现的服务提供主体(服务实体)称作智能体。
<整体结构>
图1是包括智能体装置100的智能体系统1的结构图。智能体系统1例如具备智能体装置100和智能体服务器200。智能体服务器200是智能体系统1的提供者运营的服务器。作为提供者,例如可举出机动车厂家、网络服务运营商、电子商贸运营商、便携终端的销售者、制造者等,任意的主体(法人、团体、个人等)能够成为智能体系统1的提供者。
智能体装置100经由网络NW而与智能体服务器200通信。网络NW例如包括互联网、蜂窝网、Wi-Fi网、WAN(Wide Area Network)、LAN(Local Area Network)、公用线路、电话线路、无线基站等中的一部分或全部。在网络NW上连接有各种网页服务器300,智能体服务器200或智能体装置100能够经由网络NW而从各种网页服务器300取得网页。
智能体装置100与车辆M的乘员进行对话,将来自乘员的声音向智能体服务器200发送,将从智能体服务器200得到的回答以声音输出、图像显示的形式向乘员提示。
智能体服务器200例如具备说话方式DB205。在说话方式DB205中登记有与车辆M的乘员的说话方式相关的信息。与说话方式相关的信息是通过车辆M的乘员与智能体装置100的日常的对话而取得的信息。与说话方式相关的信息例如包括车辆M的乘员的口头禅。车辆M的乘员的口头禅是对于车辆M的乘员而言成为了习惯的措词,例如包括车辆M的乘员在讲话时频繁使用的短句等。也可以取代智能体服务器200或在其基础上,智能体装置100具备说话方式DB205。
[车辆]
图2是示出第一实施方式的智能体装置100的结构和搭载于车辆M的设备的图。在车辆M例如搭载有一个以上的话筒10、显示·操作装置20、扬声器单元30、导航装置40、车辆设备50、通信装置60及智能体装置100。这些装置通过CAN(Controller Area Network)通信线等多路通信线、串行通信线、无线通信网等而互相连接。需要说明的是,图2所示的结构只不过是一例,也可以省略结构的一部分,还可以进一步追加别的结构。
话筒10是收集在车室内发出的声音的收音部。显示·操作装置20是能够显示图像并且接受输入操作的装置(或装置群)。显示·操作装置20例如包括构成为触摸面板的显示二器装置。显示·操作装置20也可以进一步包括HUD(Head Up Display)、机械式的输入装置。扬声器单元30例如包括在车室内的互不相同的位置配设的多个扬声器(声音输出部)。显示·操作装置20也可以由智能体装置100和导航装置40共用。
导航装置40具备导航HMI(Human machine Interface)、GPS(Global PositioningSystem)等位置测定装置、存储有地图信息的存储装置及进行路径搜索等的控制装置(导航控制器)。话筒10、显示·操作装置20及扬声器单元30中的一部分或全部也可以作为导航HMI来使用。导航装置40搜索用于从由位置测定装置确定出的车辆M的位置移动至由乘员输入的目的地的路径(导航路径),以使车辆M能够沿着路径行驶的方式,使用导航HMI来输出引导信息。路径搜索功能也可以存在于能够经由网络NW而访问的导航服务器。在该情况下,导航装置40从导航服务器取得路径并输出引导信息。
车辆设备50例如包括发动机、行驶用马达等驱动力输出装置、发动机的启动马达、车门锁定装置、车门开闭装置、窗、窗的开闭装置及窗的开闭控制装置、座椅、座椅位置的控制装置、车室内后视镜及其角度位置控制装置、车辆内外的照明装置及其控制装置、刮水器、除雾器及各自的控制装置、方向指示灯及其控制装置、空调装置、行驶距离、轮胎的空气压的信息、燃料的余量信息等的车辆信息装置等。
通信装置60例如能够利用蜂窝网、Wi-Fi网来访问网络NW。通信装置60可以是车载通信装置,也可以是带入车室内的智能手机等通用通信装置。
[智能体装置]
返回图2,智能体装置100具备管理部110和智能体功能部150。管理部110例如具备声响处理部112、唤醒判定部114、显示控制部116及声音控制部118。图2所示的软件配置为了说明而简易地示出,实际上,例如能够以也可以在智能体功能部150与通信装置60之间夹设管理部110的方式任意改变。
智能体装置100的各构成要素例如通过CPU(Central Processing Unit)等硬件处理器执行程序(软件)而实现。这些构成要素中的一部分或全部也可以由LSI(Large ScaleIntegration)、ASIC(Application Specific Integrated Circuit)、FPGA(Field-Programmable Gate Array)、GPU(Graphics Processing Unit)等硬件(包括电路部:circuitry)实现,还可以通过软件与硬件的协同配合来实现。程序可以预先保存于HDD(Hard Disk Drive)、闪存器等存储装置(具备非暂时性的存储介质的存储装置),也可以保存于DVD、CD-ROM等能够装卸的存储介质(非暂时性的存储介质),并通过存储介质向驱动装置装配而安装。
管理部110通过执行OS(Operating System)、中间件等程序而发挥功能。
声响处理部112以成为适合于识别对智能体预先设定的唤醒词的状态的方式,对输入的声音进行声响处理。
唤醒判定部114从进行声响处理后的声音(声音流)识别对智能体预先设定的唤醒词。首先,唤醒判定部114基于声音流中的声音波形的振幅和零交叉来检测出声音区间。唤醒判定部114也可以根据以混合高斯分布模型(GMM;Gaussian mixture model)为基础的帧单位的声音辨识及非声音辨识来进行区间检测。
接着,唤醒判定部114将检测出的声音区间中的声音文本化,设为文字信息。然后,唤醒判定部114判定文本化的文字信息是否符合唤醒词。在判定为是唤醒词的情况下,唤醒判定部114使智能体功能部150起动。需要说明的是,相当于唤醒判定部114的功能也可以搭载于智能体服务器200。在该情况下,管理部110将由声响处理部112进行声响处理后的声音流向智能体服务器200发送,在智能体服务器200判定为是唤醒词的情况下,按照来自智能体服务器200的指示而智能体功能部150起动。需要说明的是,智能体功能部150也可以始终处于起动状态且自己进行唤醒词的判定。在该情况下,管理部110无需具备唤醒判定部114。
智能体功能部150例如具备检测部152、口头禅登记部154及信息提供部156。智能体功能部150与智能体服务器200协同配合而使智能体出现,根据车辆M的乘员的讲话来提供包括基于声音的响应的服务。智能体功能部150被赋予了控制车辆设备50的权限。另外,智能体功能部150经由通信装置60而与智能体服务器200通信。
检测部152通过解析由声响处理部112进行声响处理后的声音来检测车辆M的乘员的讲话时的口头禅。口头禅是车辆M的乘员的说话方式的一例。在口头禅中,包括容易给说话对方带来好印象的积极的口头禅和容易给说话对方带来差印象的消极的口头禅。作为积极的口头禅,例如包括“幸福”、“开心”、“激动”、“有趣”等短句。作为消极的口头禅,例如包括“见鬼”、“但是”、“话虽如此”、“反正”、“算了”、“没时间”、“没钱”、“忙”、“累了”、“麻烦”等短句。
口头禅登记部154登记由检测部152检测到的车辆M的乘员的讲话时的口头禅。口头禅登记部154例如在由检测部152检测到车辆M的乘员的讲话时的口头禅的情况下,将与检测到的口头禅相关的信息通过通信装置60而向智能体服务器200发送。智能体服务器200将从口头禅登记部154接收到的与口头禅相关的信息向说话方式DB205登记。口头禅登记部154例如在由检测部152检测到车辆M的乘员的讲话时的口头禅的情况下,在检测到的口头禅已登记于智能体服务器200的说话方式DB205时,将对应的口头禅的频率相加来更新登记于说话方式DB205的与口头禅相关的信息。
图3是示出说话方式DB205的数据内容的一例的图。在说话方式DB205中登记有与车辆M的每个乘员的说话方式相关的信息。在图示的例子中,在说话方式DB205中,例如,口头禅的内容及口头禅的频率相对于乘员ID建立了对应关系。乘员ID是用于确定车辆M的乘员的辨识信息。口头禅的内容是作为车辆M的乘员的口头禅而检测到的短句。在该例子中,例如,“见鬼”、“话虽如此”、“反正”等消极的口头禅作为车辆M的乘员的口头禅而登记。口头禅的频率是检测到车辆M的乘员的口头禅的频率。
信息提供部156将用于矫正车辆M的乘员的口头禅的信息向车辆M的乘员提供。信息提供部156在由检测部152检测到口头禅的情况下,参照说话方式DB205来判定检测到由口头禅登记部154登记的口头禅的频率是否为阈值以上。信息提供部156在检测到口头禅的频率为阈值以上的情况下,将用于矫正以阈值以上的频率检测到的口头禅的信息向车辆M的乘员提供。信息提供部156例如在检测到消极的口头禅的频率为阈值以上的情况下,将用于矫正以阈值以上的频率检测到的消极的口头禅的信息向车辆M的乘员提供。信息提供部156例如在车辆M的乘员进行了包括对象的口头禅的讲话的情况下,通过使用于将在车辆M的乘员的讲话中包括对象的口头禅可视化的警告从智能体装置100向车辆M的乘员输出,来矫正车辆M的乘员的口头禅。另外,信息提供部156例如也可以在车辆M的乘员进行了包括对象的口头禅的讲话的情况下,通过将不包括对象的口头禅的讲话从智能体装置100向车辆M的乘员输出,来矫正车辆M的乘员的口头禅。
显示控制部116根据来自智能体功能部150的指示而使显示·操作装置20显示图像。显示控制部116通过一部分的智能体功能部150的控制,例如生成在车室内进行与乘员的沟通的拟人化的智能体的图像(以下,称作智能体图像),使显示·操作装置20显示生成的智能体图像。智能体图像例如是对乘员搭话的形态的图像。智能体图像例如可以包括至少由观看者(乘员)识别表情、脸部朝向的程度的脸部图像。例如,智能体图像可以在脸部区域中表示出模拟了眼睛、鼻子的部位,基于脸部区域中的部位的位置来识别表情、脸部朝向。另外,智能体图像也可以立体地感受,通过包括三维空间中的头部图像而由观看者识别智能体的脸部朝向,或者通过包括主体(躯干、手脚)的图像而识别智能体的动作、举止、姿态等。另外,智能体图像也可以是动画图像。
声音控制部118根据来自智能体功能部150的指示而使扬声器单元30中包含的扬声器中的一部分或全部输出声音。声音控制部118也可以使用多个扬声器单元30来进行使智能体声音的声像定位于与智能体图像的显示位置对应的位置的控制。与智能体图像的显示位置对应的位置例如是预测为乘员会感到智能体图像正在说出智能体声音的位置,具体而言是智能体图像的显示位置附近的位置。另外,声像定位例如是指通过调节向乘员的左右的耳朵传递的声音的大小来确定乘员感受的声源的空间位置。
[智能体服务器]
图4是示出智能体服务器200的结构和智能体装置100的结构的一部分的图。以下,与智能体服务器200的结构一起,对智能体功能部150等的动作进行说明。在此,省略关于从智能体装置100到网络NW为止的物理通信的说明。
智能体服务器200具备通信部210。通信部210例如是NIC(Network InterfaceCard)等网络接口。而且,智能体服务器200例如具备声音识别部220、自然语言处理部222、对话管理部224、网络检索部226及响应文生成部228。这些构成要素例如通过CPU等硬件处理器执行程序(软件)而实现。这些构成要素中的一部分或全部也可以由LSI、ASIC、FPGA、GPU等硬件(包括电路部:circuitry)实现,还可以通过软件与硬件的协同配合来实现。程序可以预先保存于HDD、闪存器等存储装置(具备非暂时性的存储介质的存储装置),也可以保存于DVD、CD-ROM等能够装卸的存储介质(非暂时性的存储介质),并通过存储介质向驱动装置装配而安装。
智能体服务器200具备存储部250。存储部250由上述的各种存储装置实现。在存储部250中,除了说话方式DB205之外还还保存个人简介252、词典DB(数据库)254、知识库DB256、响应规则DB258等数据、程序。
在智能体装置100中,智能体功能部150将声音流或进行压缩、编码等处理后的声音流向智能体服务器200发送。智能体功能部150在识别到能够进行本地处理(不经由智能体服务器200的处理)的声音指令的情况下,可以进行由声音指令要求的处理。能够进行本地处理的声音指令是能够通过参照智能体装置100所具备的存储部(未图示)而回答的声音指令,或者是控制车辆设备50的声音指令(例如,打开空调装置的指令等)。因此,智能体功能部150也可以具有智能体服务器200所具备的功能的一部分。
当取得声音流后,声音识别部220进行声音识别并输出文本化的文字信息,自然语言处理部222对文字信息一边参照词典DB254一边进行含义解释。词典DB254是抽象化的含义信息相对于文字信息建立了对应关系的数据库。词典DB254也可以包括同义词、近义词的一览信息。声音识别部220的处理和自然语言处理部222的处理并不明确地划分阶段,可以如声音识别部220接受自然语言处理部222的处理结果而修正识别结果等这样相互影响而进行。
自然语言处理部222例如在作为识别结果而识别到“今天的天气?”、“天气如何”等含义的情况下,生成置换成了标准文字信息“今天的天气”的指令。由此,在请求的声音中存在表述差异的情况下也能够容易进行与要求相符的对话。另外,自然语言处理部222例如也可以使用利用了概率的机器学习处理等人工智能处理来识别文字信息的含义,生成基于识别结果的指令。
对话管理部224基于自然语言处理部222的处理结果(指令),一边参照个人简介252、知识库DB256、响应规则DB258一边决定相对于车辆M的乘员的讲话的内容。个人简介252包括针对每个乘员保存的乘员的个人信息、兴趣爱好、过去的对话的履历等。知识库DB256是规定了事物的关系性的信息。响应规则DB258是规定了智能体相对于指令应该进行的动作(回答、设备控制的内容等)的信息。
另外,对话管理部224也可以通过使用从声音流得到的特征信息与个人简介252进行对照来确定乘员。在该情况下,在个人简介252中,例如,个人信息与声音的特征信息建立了对应关系。声音的特征信息例如是与声音的高度、语调、节奏(声音的高低的模式)等说话方式的特征、基于梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficients)等的特征量相关的信息。声音的特征信息例如是通过在乘员的初始登记时使乘员讲出规定的单词、句子等并识别发出的声音而得到的信息。
对话管理部224在指令要求能够经由网络NW而检索的信息的情况下,使网络检索部226进行检索。网络检索部226经由网络NW而访问各种网页服务器300,取得期望的信息。“能够经由网络NW而检索的信息”例如是处于车辆M的周边的餐厅的普通用户的评价结果,或者是当天的与车辆M的位置相应的天气预报。
响应文生成部228以使由对话管理部224决定的讲话的内容向车辆M的乘员传达的方式生成响应文并向智能体装置100发送。响应文生成部228在确定了乘员是登记于个人简介的乘员的情况下,也可以生成叫出乘员的名字或者设为了模仿乘员的说话方式的说话方式的响应文。
智能体功能部150当取得响应文后,指示声音控制部118进行声音合成并输出声音。另外,智能体功能部150指示显示控制部116配合声音输出而显示智能体的图像。这样,实现假想地出现的智能体对车辆M的乘员进行响应的智能体功能。
[智能体装置的处理流程]
以下,使用流程图对第一实施方式的智能体装置100的一系列处理的流程进行说明。图5所示的流程图的处理例如可以在输入了车辆M的乘员的讲话的情况下执行。
首先,检测部152通过解析从车辆M的乘员输入的讲话来检测车辆M的乘员的讲话时的口头禅(步骤S10)。口头禅登记部154将由检测部152检测到的口头禅与车辆M的乘员的乘员ID建立对应关系并向说话方式DB205登记(步骤S12)。接着,信息提供部156参照说话方式DB205来判定是否包括检测到的频率为阈值以上的口头禅(步骤S14)。信息提供部156在判定为包括检测到的频率为阈值以上的口头禅的情况下,将用于矫正检测到的频率为阈值以上的口头禅的信息向车辆M的乘员提供(步骤S16)。由此,本流程图的处理结束。另一方面,信息提供部156在判定为不包括检测到的频率为阈值以上的口头禅的情况下,不将用于矫正口头禅的信息向车辆M的乘员提供,本流程图的处理结束。
图6是用于说明第一实施方式的智能体装置100的动作的图。在该图所示的例子中,以在作为车辆M的乘员的口头禅而包括消极的口头禅的情况下将用于矫正该口头禅的信息向车辆M的乘员提供的情况为例进行说明。
智能体装置100参照说话方式DB205来对检测到的频率为阈值以上的车辆M的乘员的口头禅进行检测。在图示的例子中,智能体装置100将“见鬼”这一消极的口头禅作为检测到的频率为阈值以上的车辆M的乘员的口头禅而检测。在该情况下,智能体装置100向车辆M的乘员输出用于将“见鬼”这一消极的口头禅可视化的警告。
从车辆M的乘员向智能体装置100输入委托对所警告的口头禅的矫正的讲话。在图示的例子中,从车辆M的乘员向智能体装置100输入委托将“见鬼”这一消极的口头禅矫正为“不好”这一积极的口头禅的讲话。
智能体装置100在受理了口头禅的矫正的委托后从车辆M的乘员输入了包括消极的口头禅的讲话的情况下,将用于矫正消极的口头禅的信息向车辆M的乘员提供。在图示的例子中,从车辆M的乘员向智能体装置100输入了包括“见鬼”这一消极的口头禅的讲话。因此,智能体装置100将取代“见鬼”这一消极的口头禅而使用了“不好”这一积极的口头禅的讲话作为相对于来自车辆M的乘员的讲话的响应而输出。
根据上述说明的第一实施方式的智能体装置100,能够以更具发展性的利用的方案来矫正车辆M的乘员的口头禅。车辆M的乘员的口头禅是从与车辆M的乘员之间的日常的会话得到的信息,有时难以设置检测车辆M的乘员的口头禅的机会。因此,在第一实施方式的智能体装置100中,从车辆M的乘员与智能体装置100之间的对话检测车辆M的乘员的口头禅,将用于矫正检测到的口头禅的信息向车辆M的乘员提供。由此,能够以更具发展性的利用的方案来矫正车辆M的乘员的口头禅。
<第二实施方式>
以下,对第二实施方式进行说明。第二实施方式与第一实施方式相比,在提供用于矫正车辆M的乘员的方言的信息这一点上处理内容不同。以下,以该不同点为中心进行说明。
图7是示出第二实施方式的智能体装置100的结构和搭载于车辆M的设备的图。第二实施方式的智能体装置100的智能体功能部150A例如具备检测部152、方言登记部154A及信息提供部156。
检测部152通过解析由声响处理部112进行声响处理后的声音来检测车辆M的乘员的讲话时的方言。方言是车辆M的乘员的说话方式的一例。方言意味着每个地域的语言体系,例如包括大阪话、京都话等。方言例如由词汇、语法、语调、口音等规定。
方言登记部154A登记由检测部152检测到的车辆M的乘员的讲话时的方言。方言登记部154A例如在由检测部152检测到车辆M的乘员的讲话时的方言的情况下,将与检测到的方言相关的信息通过通信装置60而向智能体服务器200发送。智能体服务器200将从方言登记部154A接收到的与方言相关的信息向说话方式DB205登记。
信息提供部156将用于矫正车辆M的乘员的方言的信息向车辆M的乘员提供。信息提供部156在由检测部152检测到方言的情况下,参照说话方式DB205来判定检测到的方言是否是由方言登记部154A登记的规定的方言。信息提供部156在判定为由检测部152检测到的方言是规定的方言的情况下,将用于矫正检测到的方言的信息向车辆M的乘员提供。信息提供部156例如也可以事先登记检测到的方言中的车辆M的乘员自身在意的方言的语调、单词等特征,将用于矫正事先登记的方言的特征的信息向车辆M的乘员提供。
以下,使用流程图对第二实施方式的智能体装置100的一系列处理的流程进行说明。图8所示的流程图的处理例如可以在输入了车辆M的乘员的讲话的情况下执行。
检测部152通过解析从车辆M的乘员输入的讲话来检测车辆M的乘员的讲话时的方言(步骤S20)。检测部152例如通过解析车辆M的乘员的讲话的词汇、语法、音韵、口音等来检测车辆M的乘员的方言。另外,检测部152将在步骤S10中检测到的方言与车辆M的乘员的乘员ID建立对应关系并向说话方式DB205登记(步骤S22)。接着,信息提供部156参照说话方式DB205来判定规定的方言是否与车辆M的乘员建立对应关系并登记于说话方式DB205(步骤S24)。信息提供部156在判定为规定的方言与车辆M的乘员建立对应关系并登记于说话方式DB205的情况下,将用于矫正规定的方言的信息向车辆M的乘员提供(步骤S26)。由此,本流程图的处理结束。另一方面,信息提供部156在规定的方言未与车辆M的乘员建立对应关系并登记于说话方式DB205的情况下,不将用于矫正规定的方言的信息向车辆M的乘员提供,本流程图的处理结束。
图9是用于说明第二实施方式的智能体装置100的动作的图。在该图所示的例子中,以在车辆M的乘员的讲话中包括规定的方言的情况下将用于矫正规定的方言的信息向车辆M的乘员提供的情况为例进行说明。
智能体装置100接受从车辆M的乘员输入的讲话。在图示的例子中,智能体装置100接受从车辆M的乘员输入的包括与天气相关的话题的讲话。
智能体装置100通过解析接受到的讲话来检测车辆M的乘员的方言。在图示的例子中,智能体装置100检测为车辆M的乘员的方言是“大阪话”。在该情况下,智能体装置100向车辆M的乘员输出用于将车辆M的乘员的方言是“大阪话”的意旨可视化的警告。
从车辆M的乘员向智能体装置100输入委托对所警告的方言的矫正的讲话。在图示的例子中,从车辆M的乘员向智能体装置100输入委托将“大阪话”矫正为“东京话”的讲话。
智能体装置100在受理了方言的矫正的委托后从车辆M的乘员输入了包括成为矫正的对象的方言的讲话的情况下,将用于矫正方言的信息向车辆M的乘员提供。在图示的例子中,从车辆M的乘员向智能体装置100输入了包括“大阪话”的讲话。因此,智能体装置100将取代“大阪话”而使用了“东京话”的讲话作为相对于来自车辆M的乘员的讲话的响应而输出。
根据上述说明的第二实施方式的智能体装置100,除了起到第一实施方式的智能体装置100的效果之外,还能够以更具发展性的利用的方案来矫正车辆M的乘员的方言。车辆M的乘员的方言是从与车辆M的乘员之间的日常的会话得到的信息,有时,检测车辆M的乘员的方言伴随着困难。因此,在第二实施方式的智能体装置100中,从乘车时的车辆M的乘员与智能体装置100之间的对话检测车辆M的乘员的方言,将用于矫正检测到的方言的信息向车辆M的乘员提供。由此,能够以更具发展性的利用的方案来矫正车辆M的乘员的方言。
<第三实施方式>
以下,对第三实施方式进行说明。第三实施方式与第一实施方式相比,在提供用于以接近由车辆M的乘员指定的方言的方式进行引导的信息这一点上处理内容不同。以下,以该不同点为中心进行说明。
图10是示出第三实施方式的智能体装置100的结构和搭载于车辆M的设备的图。第三实施方式的智能体装置100的智能体功能部150B例如具备方言指定接受部154B和信息提供部156。
方言指定接受部154B接受车辆M的乘员对方言的指定的指示。方言指定接受部154B例如在车辆M的乘员操作显示·操作装置20而指定了方言的情况下,基于从显示·操作装置20输出的操作信号来接受方言的指定的指示。作为指定的方言,不限于日语,也可以是英语等当地的方言,还可以是牛津剑桥口音等在特定的地域中限定地使用的当地的方言。
信息提供部156将用于以使车辆M的乘员的方言接近由方言指定接受部154B接受到的方言的方式进行引导的信息向车辆M的乘员提供。信息提供部156例如在由方言指定接受部154B接受了方言的指定的指示的情况下,通过将包括接受到的方言的讲话从智能体装置100向车辆M的乘员输出来引导车辆M的乘员的方言。
以下,使用流程图对第三实施方式的智能体装置100的一系列处理的流程进行说明。图11所示的流程图的处理例如可以在输入了车辆M的乘员的讲话的情况下执行。
方言指定接受部154B判定是否由车辆M的乘员指定了方言(步骤S30)。信息提供部156在判定为由方言指定接受部154B指定了方言的情况下,将用于以接近指定的方言的方式进行引导的信息向车辆M的乘员提供(步骤S32)。由此,本流程图的处理结束。另一方面,信息提供部156在判定为未由方言指定接受部154B指定方言的情况下,不引导车辆M的乘员的方言,本流程图的处理结束。
图12是用于说明第三实施方式的智能体装置100的动作的图。在该图所示的例子中,以在由车辆M的乘员指定了规定的方言的情况下将用于以接近指定的方言的方式进行引导的信息向车辆M的乘员提供的情况为例进行说明。
智能体装置100接受从车辆M的乘员输入的委托方言的矫正的讲话。在图示的例子中,智能体装置100委托将车辆M的乘员的方言以接近“东京话”的方式进行引导。
智能体装置100在受理了方言的引导的委托后从车辆M的乘员输入了包括规定的方言的讲话的情况下,将以接近指定的方言的方式进行引导的信息向车辆M的乘员提供。在图示的例子中,从车辆M的乘员向智能体装置100输入了包括“大阪话”的讲话。因此,智能体装置100对使用了“大阪话”的来自车辆M的乘员的讲话输出使用了“东京话”的响应。
根据上述说明的第三实施方式的智能体装置100,除了起到第一或第二实施方式的智能体装置100的效果之外,还能够配合车辆M的乘员的意图而引导车辆M的乘员的方言。车辆M的乘员的方言是习惯性地进行的,其引导有时伴随着困难。因此,在第三实施方式的智能体装置100中,将用于以接近由车辆M的乘员指定的方言的方式进行引导的信息向车辆M的乘员提供。由此,能够配合车辆M的乘员的意图而引导车辆M的乘员的方言。
[实施方式的变形例]
在上述第一或第二实施方式中,智能体装置100在车辆M的乘员的讲话中包括口头禅或方言的情况下,也可以不对乘员的讲话进行响应而是忽视,由此催促乘员的讲话的矫正。
在上述各实施方式中,智能体装置100例如也可以将政治家的不适当发言的新闻等成为了车辆M的乘员的感情容易高涨的场景作为触发条件而开始乘员的讲话的矫正。
在上述各实施方式中,智能体装置100例如也可以通过与车辆M的乘员之间的会话或拍摄了车室内的图像等来推定乘员的人数、乘员彼此的关系性,基于该推定结果来判定是否开始乘员的讲话的矫正。智能体装置100例如可以在乘员在车室内为独自1人的情况下开始讲话的矫正,也可以在乘员仅由家人构成的情况下开始讲话的矫正。
在上述各实施方式中,智能体装置100例如也可以设置于便携信息终端。在该情况下,便携信息终端也可以在与用户的对话中矫正用户的说话方式。
以上使用实施方式说明了本发明的具体实施方式,但本发明丝毫不被这样的实施方式限定,在不脱离本发明的主旨的范围内能够施加各种变形及替换。
- 智能体装置、智能体系统、服务器装置、智能体装置的控制方法及存储介质
- 智能体装置、智能体装置的控制方法及存储介质