用存储器内列式查询处理启用和集成存储器内半结构化数据和文本文档搜索的技术
文献发布时间:2023-06-19 10:14:56
技术领域
本发明涉及数据库系统,并且更具体而言,涉及存储在数据库系统的列中的半结构化数据的存储器内高速缓存。
背景技术
显著改善对象-关系数据库系统中查询的计算的一种方式是将数据库表预加载并保留在派生的高速缓存中。在派生的高速缓存中,以持久形式存储的数据库表的至少一部分的存储器内版本可以以列为主的格式(column-major format)镜像到数据库服务器的较低时延随机存取存储器(RAM)中。在列为主的格式中,列的列值中的一部分的表示存储在列向量中,该列向量在RAM中占据连续的地址范围。
出于若干原因,可以对列的存储器内列向量更快地执行涉及列的查询操作,诸如在列上的谓词评估和汇总。首先,列向量维持在较低时延的存储器中,在那里可以被更快地访问。第二,查询操作对其操作的列值的运行连续存储在存储器中列向量中。此外,列向量被压缩以减少存储列所需的存储器。字典压缩常常被用于压缩列向量。
字典压缩还可以被压缩列式算法利用,该压缩列式算法被优化以用于对压缩列向量执行查询操作,以进一步提高对列执行这种查询操作的速度。其它形式的压缩也可以被压缩列式算法利用。
例如,由Jesse Kamp等人于2014年7月21日提交并于2016年3月22日作为美国专利No.9,292,564发布的美国申请No.14/337,179“Mirroring,In Memory,Data From Disk ToImprove Query Performance”(“Mirroring申请”)中描述了派生的高速缓存的示例,其全部内容通过引用并入本文。
对于包含标量值(诸如整数和字符串)的列,实现压缩列式算法的益处。但是,包含半结构化数据(诸如XML(扩展标记语言)和JSON(JavaScript对象表示法))的列可能无法用压缩列式算法可以利用的方式以列为主的形式(column-major form)存储。
半结构化数据通常以持久形式存储在大型二进制对象(LOB)列中。在LOB列内,半结构化数据可以以各种半结构化数据格式存储,包括作为标记文本的主体,或者以为可压缩性和快速访问而结构化的专有格式存储。遗憾的是,对于标量列强有力地工作的压缩列式算法对这些半结构化数据格式无效。
此外,存在特定于半结构化数据的查询操作,诸如基于路径的查询操作。基于路径的操作不适合针对存储在列向量中的半结构化数据进行优化。
支持半结构化数据的数据库管理系统(DBMS)通常也将数据库数据存储在标量列中。由此类DBMS处理的查询可以引用半结构化和标量数据库数据两者。此类查询在本文中被称为混合格式查询。尽管混合格式查询要求对半结构化数据的访问,但是混合格式查询仍然受益于派生的列式高速缓存,因为执行查询的工作中的至少部分可以将派生的列式高速缓存用于标量列。对于要求访问半结构化数据的工作的一部分,这些DBMS使用对持久形式数据(PF数据)进行操作的传统查询操作。
能够存储和高效地访问半结构化数据变得越来越重要。本文描述的是用于在派生的高速缓存中维护半结构化数据以提高执行查询(包括混合格式查询)的速度的技术。
本部分中描述的方法是可以采用的方法,但不一定是先前已经设想或采用的方法。因此,除非另有指示,否则不应当仅由于将本节中所述的任何方法包括在本节中而将其假设为现有技术。
附图说明
在附图中:
图1是根据实施例的数据库系统的图,该数据库系统并发地在易失性存储器中维护镜像格式数据并在持久存储装置上维护持久格式数据。
图2A是根据实施例的用于示例的表的图。
图2B是根据实施例的用于表的存储数据的持久形式的图。
图3是示出根据实施例的混合派生的高速缓存的图。
图4A是根据实施例的表示XML片段的节点树。
图4B是根据实施例的表示JSON对象的节点树。
图5A是描绘根据实施例的以持久形式存储在列中的JSON对象的图。
图5B是图示根据实施例的标志和标志位置的图。
图6A是根据实施例的将标志映射到分层数据对象中的标志位置的发布索引。
图6B描绘了根据实施例的序列化的散列表形式的发布索引。
图6C描绘了根据实施例的序列化的散列表形式的发布索引的展开图。
图7描绘了根据实施例的在针对发布索引评估谓词时执行的过程。
图8描绘了根据实施例的对象级发布列表。
图9A描绘了根据实施例的当以序列化的散列表形式递增地更新发布索引时执行的过程。
图9B描绘了根据实施例的增量发布索引。
图10是根据实施例的可以被用于实现本文描述的技术的计算机系统的图。
图11是根据实施例的可以被用于控制计算系统的操作的软件系统的图。
具体实施方式
在下面的描述中,出于解释的目的,阐述了许多具体细节以便提供对本发明的透彻理解。但是,将显而易见的是,可以在没有这些具体细节的情况下实践本发明。在其它情况下,以框图形式示出了众所周知的结构和设备,以避免不必要地使本发明模糊。
总体概述
本文描述了用于以持久形式在持久存储装置中并且以称为半结构化数据存储器内形式(SSDM形式)的另一种形式在派生的高速缓存中维护半结构化数据的技术。以持久格式存储的半结构化数据在本文中被称为PF半结构化数据。以SSDM形式存储的半结构化数据在本文中被称为SSDM数据。
根据实施例,“混合派生的高速缓存”以SSDM形式存储半结构化数据并以另一种形式(诸如列为主的格式)存储列。本文引用的存储在派生的高速缓存中的数据具有镜像形式数据(MF数据)。混合派生的高速缓存可以以列为主的格式高速缓存标量类型列,并且以SSDM形式在列中高速缓存半结构化数据。SSDM形式的结构使得能够访问和/或增强访问,以执行基于路径和/或基于文本的查询操作。
混合派生的高速缓存改善了用于执行查询操作的高速缓存包含。高速缓存包含是指将对执行查询操作所需的数据库数据的访问限制到混合派生的高速缓存内的访问。一般而言,执行查询的高速缓存包含程度越高,混合派生的高速缓存的益处就越大,这将导致查询(包括混合格式查询)的执行更快。
混合格式查询还可以包括访问非结构化文本数据的查询。非结构化文本数据可以存储在例如LOB中。本文描述的技术可以被用于以持久格式将非结构化文本数据存储在持久存储装置上,并且以存储器内形式存储在派生的高速缓存中,所述存储器内形式在各个方面可能都比SSDM形式更不复杂。
一般体系架构
根据实施例,使用存储器内数据库体系架构在DBMS内实现派生的高速缓存,该存储器内数据库体系架构使PF数据和MF数据在事务上保持一致。在Mirroring申请中详细描述了这种存储器内数据库体系架构。Mirroring申请除其它事项外尤其描述了维护相同数据项的多个副本,其中一个副本以持久形式维护,而另一个副本以镜像形式在易失性存储器中维护。
图1是根据实施例的数据库系统的框图。参考图1,DBMS 100包括RAM 102和持久存储装置110。RAM 102一般表示由DBMS使用的RAM,并且可以由任意数量的存储器设备(包括易失性和非易失性存储器设备及其组合)实现。
持久性存储装置110一般表示任何数量的持久块模式存储设备,诸如磁盘、闪存、固态驱动器,或可通过块模式接口访问以读取或写入存储在其上的数据块的非易失性RAM。
在DBMS 100内,数据库服务器120执行由一个或多个数据库应用(未示出)提交给数据库服务器的数据库语句。由那些应用使用的数据被示为PF数据112。PF数据112驻留在PF数据结构108中的持久存储装置110中。PF数据结构108可以是例如行为主的数据块。虽然出于说明的目的而使用行为主的数据块,但PF结构可以采用任何形式,诸如列为主的数据块、混合压缩单元等。
RAM 102还包括PF数据的缓存器高速缓存106。在缓冲器高速缓存106内,以基于数据驻留在PF数据结构108内的格式的格式存储数据。例如,如果持久格式是行为主的数据块,那么缓冲器高速缓存106可以包含行为主的数据块的高速缓存的副本。
另一方面,MF数据104具有与持久格式不同的格式。在持久格式是行为主的数据块的实施例中,镜像格式对于标量列可以是列为主,而对于保持半结构化数据的列可以是SSDM形式。因为镜像格式不同于持久格式,所以通过对PF数据执行变换来产生MF数据104。这些变换既发生在最初用MF数据104填充RAM 102时(无论是在启动时还是按需),也发生在发生故障之后重新用MF数据104填充RAM 102时。
重要的是,MF数据104的存在对于向数据库服务器提交数据库命令的数据库应用可以是透明的。已经利用仅对PF数据进行操作的DBMS的应用可以与数据库服务器进行交互而无需修改,该数据库服务器除了PF数据112之外还维护MF数据104。另外,对于那些应用来说透明的是,数据库服务器可以使用MF数据104来更高效地处理那些数据库命令中的一些或全部。
镜像格式数据
MF数据104可以镜像所有PF数据112或其子集。在一个实施例中,用户可以指定PF数据112的哪个部分是“在存储器内启用的”。可以在任何粒度级别(包括列和行范围)上进行指定。
如下面将描述的,在存储器内启用的数据被转换成镜像格式并作为MF数据104存储在RAM 102中。因此,当数据库语句需要在存储器内启用的数据时,数据库服务器可以选择从或者PF数据112或者MF数据104提供数据。转换和加载可以在起动数据库时进行,或者以懒惰或按需方式进行。MF数据104中未镜像未在存储器内启用的数据。因此,当查询要求此类数据时,数据库服务器无法选择从MF数据104获得数据。
为了解释的目的,将假设PF数据结构108包括图2A中所示的表200。表200包括四列C1、SSD C2、C3和C4,以及八行R1、R2、R3、R4、R5、R6、R7和R8。SSD C2存储半结构化数据。
持久存储装置中的行可以由行id唯一识别。在表200中,第一行与行id R1相关联,并且最后一行与行id R8相关联。行的列在本文中可以通过行id和列的级联来引用。例如,行R1的列C1用R1C1识别,并且R5的C3用R5C3识别。
图2B图示了可以如何在持久存储装置110上物理地组织驻留在表200中的数据。在本示例中,用于表200的数据存储在四个行为主的数据块202、204、206和208中。块202存储用于行R1的所有列的值,然后存储用于行R2的所有列的值。块204存储用于行R3的所有列的值,然后存储用于行R4的所有列的值。块206存储用于行R5的所有列的值,然后存储用于行R6的所有列的值。最后,块208存储用于行R7的所有列的值,然后存储用于行R8的所有列的值。
根据实施例,列SSD C2可以是由DBMS 100定义为存储半结构化数据的LOB列。对于特定行,SSD C2中的LOB可以是内联的(inline)或者外联的(out-of-line)。对于一行的内联LOB,LOB的数据物理地存储在该行的同一数据块中。对于外联LOB,将引用存储在数据块的该行中;引用是指另一个数据块集合中存储用于LOB的数据的位置。实际上,外联LOB在逻辑地但不物理地存储在包含外联的LOB的数据块中。为了阐述的目的,数据块中的行的列中的LOB在本文中可以被称为存储或包含在该数据块内,而不管LOB是内联的还是外联的。
数据块的副本可以被临时存储在缓冲器高速缓存106中。可以使用多种高速缓存管理技术中的任何一种来管理缓冲器高速缓存106。
混合派生的高速缓存和IMCU
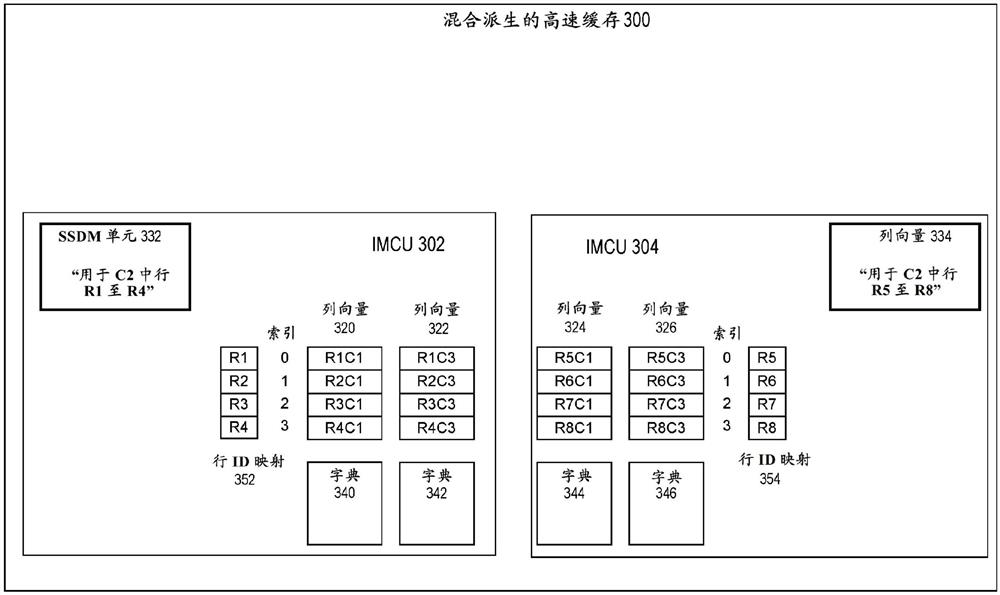
根据实施例,MF数据104被高速缓存并维持在混合派生的高速缓存内。在混合派生的高速缓存内,MF数据104以本文称为存储器内压缩单元(IMCU)的单元被存储。每个IMCU存储MF数据的不同集合。
图3描绘了混合派生的高速缓存300,根据本发明实施例的混合派生的高速缓存。如图3中所示,混合派生的高速缓存300包括IMCU 302和IMCU 304。
以与PF数据的组织对应的方式来组织IMCU。例如,在持久存储装置110上,PF数据可以被存储在(地址空间内)一系列连续的数据块中。在这些情形下,在混合派生的高速缓存300内,MF数据104存储来自一系列数据块的数据。IMCU 302保持来自行R1-R4的MF数据,而IMCU 304保持来自行R5-R8的MF数据。
IMCU 302在列向量320中保持用于行R1-R4的C1的列值并且在列向量322中保持用于行R1-R4的C3的列值。SSDM单元332以SSDM形式保持用于行R1-R4的半结构化数据。IMCU304在列向量324中保持用于行R5-R8的C1的列值并且在列向量326中保持用于行R5-R8的C3的列值。SSDM单元334以SSDM形式保持用于行R5-R8的半结构化数据。
混合派生的高速缓存300中描绘的列向量被字典压缩。在列的基于字典的压缩中,值由字典代码表示,其通常比字典代码表示的值小得多。字典将字典代码映射到值。在列的列向量中,值在列向量中的出现由列向量内的字典代码表示,该字典代码被字典映射到该值。
根据实施例,每个IMCU根据用于列向量的字典对那个列向量进行编码。列向量320和列向量322分别根据字典340和342进行编码,并且列向量324和列向量326分别根据字典344和346进行编码。
列向量中的每个字典代码被存储在列向量的相应元素内,相应元素与序数位置或索引对应。例如,在列向量324中,索引0、1、2和3分别与第一、第二、第三和第四元素对应。
当在本文中参考一个或多个列向量时使用术语“行”时,“行”是指跨列向量元素的集合的在每个列向量中具有相同的索引并且与同一行对应的一个或多个元素的集合。行的行id和与该元素集合对应的索引可以被用于识别该元素集合。例如,行R5和行0是指列向量324和326中的每一个中的第一个元素。
IMCU 302中的行id映射352和IMCU 304中的行id映射354将列向量中的行映射到行id。根据实施例,行id映射是包含行id的列向量。列向量中的行在行id映射中与该行的相同索引位置处映射到行id。列向量324和列向量326中的元素0映射到行R5,R5是行id映射354中元素0的值。
预测评估和行ID解析
常规的数据库系统可以通过首先在缓冲器高速缓存106中搜索所请求的数据来对查询做出响应,从而正常操作。如果数据在缓冲器高速缓存106中,那么从缓冲器高速缓存106访问数据。否则,将所需数据从PF数据结构108加载到缓冲器高速缓存106中,然后从缓冲器高速缓存106进行访问。但是,因为缓冲器高速缓存106和PF数据结构108中的数据都是持久格式,所以仅基于PF数据执行操作并不总是提供最佳性能。以这种方式对PF数据执行操作在本文中被称为PF侧处理。
根据实施例,数据库服务器使用混合派生的高速缓存300来执行执行数据库查询所需的数据库操作中的至少一些。此类操作包括谓词评估、预测和汇总。使用混合派生的高速缓存可以满足的查询的执行所需的数据库访问的部分越大,高速缓存包含就越大。
根据实施例,针对多列的谓词评估可以至少部分地通过访问IMCU中的MF数据来执行。对于IMCU中高速缓存的每一列,谓词评估的结果都记录在索引对准的结果向量中。在加索引的对准的结果向量中,位向量中的每个位与列向量的索引对应,位0与第0个索引对应,位1与第一个索引对应,依此类推。在下文中,术语“结果向量”被用于指加索引的对准的位向量。对于连接谓词,可以生成多个结果向量,每个结果向量表示谓词连接词的结果,然后组合以生成“返回结果向量”,该返回结果向量表示针对IMCU中高速缓存的列的连接谓词评估的结果。
返回结果向量可以被用于执行行解析。行解析使用返回结果向量和行id映射来生成返回行列表,该返回行列表包括由返回结果向量识别出并且满足由返回结果向量表示的评估的行的行id。返回行列表可以被用于对未在混合派生的高速缓存300中高速缓存的任何列执行返回行列表中的行的进一步PF侧谓词评估,或执行其它操作(诸如未高速缓存的列的投影,或对查询中该谓词或其它谓词的其它谓词条件的评估)。
例如,由DBMS 100评估具有谓词C1=“SAN JOSE”且C3=“CA”且C4>“1400.00”的查询。DBMS 100在IMCU 304中针对C1和C3评估该谓词。为列向量324(C1)生成位向量“1110”,并为列向量326(C3)生成位向量“0110”。执行AND(与)运算生成返回向量“0110”。基于行id映射344,行R6和R7被映射到返回向量中的设置的位。DBMS 100生成包括行R6和R7的行返回列表。基于行返回列表,DBMS 100使用PF侧谓词评估针对谓词条件C4>“1400.00”来评估行R6和R7。
半结构化数据的示例
IMCU内的SSDM单元被结构化为便于对半结构化数据进行谓词评估。在描述SSDM单元之前,更详细地描述半结构化数据是有用的。半结构化数据在本文中一般是指分层数据对象的集合,其中分层结构在整个集合中的所有对象上不一定是统一的。分层数据对象常常是由分层标记语言标记的数据对象。XML和JSON是分层标记语言的示例。
使用分层标记语言结构化的数据由节点组成。节点由标记节点的定界符界定,并且可以用名称(在本文被称为标签名)加标签。一般而言,分层标记语言的语法指定标签名嵌入定界节点的定界符、与其并置或以其它方式在语法上与其相关联。
对于XML数据,节点由包括标签名的起始和结束标签界定。例如,在以下XML片段X中,
起始标签
图4A是表示上述XML片段X的节点树。参考图4A,它描述了分层数据对象401。非叶子节点用双线边界描绘,而叶子节点用单线边界描绘。在XML中,非叶子节点与元素节点对应,而叶子节点与数据节点对应。节点树中的元素节点在本文中通过节点的名称来指称,节点的名称是由节点表示的元素的名称。为了便于解释,数据节点通过数据节点表示的值来指称。
对应标签之间的数据被称为节点的内容。对于数据节点,内容可以是标量值(例如,整数、文本串、日期)。
非叶子节点(诸如元素节点)包含一个或多个其它节点。对于元素节点,内容可以是数据节点和/或一个或多个元素节点。
ZIPCODE(邮政编码)是元素节点,其包含子节点CODE(代码)、CITY(城市)和STATE(州),这些也是元素节点。数据节点95125、SAN JOSE和CA分别是元素节点CODE、CITY和STATE的数据节点。
由特定节点包含的节点在本文中被称为该特定节点的后代节点。CODE、CITY和STATE是ZIPCODE的后代节点。95125是CODE和ZIPCODE的后代节点,SAN JOSE是CITY和ZIPCODE的后代节点,CA是STATE和ZIPCODE的后代节点。
因此,非叶子节点形成具有多个级别的节点的层次结构,该非叶子节点位于最高级别。每个级别的节点链接到不同级别的一个或多个节点。最高级别之下的级别的任何给定节点都是位于该给定节点紧接着上一级别的父节点的子节点。具有相同父代的节点是兄弟节点。父节点可以有多个子节点。没有父节点链接到其的节点是根节点。没有子节点的节点是叶子节点。具有一个或多个后代节点的节点是非叶子节点。
例如,在容器节点ZIP CODE中,节点ZIP CODE是最高级别的根节点。节点95125、SAN JOSE和CA是叶子节点。
本文中使用术语“分层数据对象”来指代一个或多个非叶子节点的序列,每个非叶子节点具有子节点。XML文档是分层数据对象的示例。另一个示例是JSON对象。
JSON
JSON是轻量级分层标记语言。JSON对象包括字段的集合,每个字段是字段名/值对。字段名实际上是JSON对象中的节点的标签名。字段的名称与该字段的值之间用冒号分隔。JSON值可以是:
对象,它是用大括号“{}”括起来并用逗号分隔的字段的列表。
数组,它是用逗号分隔的JSON节点和/或用方括号“[]”括起来的值的列表。
原子,它是字符串、数字、true(真)、false(假)或null(空)。
以下JSON分层数据对象J被用于说明JSON。
分层数据对象J包含字段FIRSTNAME(名)、LASTNAME(姓)和BORN(出生)、CITY(城市)、STATE(州)和DATE(日期)。FIRSTNAME和LASTNAME分别具有原子字符串值“JACK”和“SMITH”。BORN是包含成员字段CITY、STATE和DATE的JSON对象,这些成员字段分别具有原子字符串值“SAN JOSE”、“CA”和“11/08/82”。
JSON对象中的每个字段是非叶子节点并且非叶子节点的名称是字段名。每个非空数组和非空对象都是非叶子节点,每个空数组和空对象都是叶子节点。数据节点与原子值对应。
图4B将分层数据对象J描述为包括节点的分层数据对象410,如下所述。参考图4B,有三个根节点,它们是FIRSTNAME、LASTNAME和BORN。FIRSTNAME、LASTNAME和BORN中的每一个都是字段节点。BORN具有标记为OBJECT NODE(对象节点)的后代对象节点。
OBJECT NODE在本文中被称为包含节点,因为它表示可以包含一个或多个其它值的值。在OBJECT NODE的情况下,它表示JSON对象。从OBJECT NODE开始,传下来三个后代字段节点,它们是CITY、STATE和DATE。包含节点的另一个示例是表示JSON数组的对象节点。
节点FIRSTNAME、LASTNAME、CITY和STATE具有分别表示原子字符串值“JACK”、“SMITH”、“SAN JOSE”和“CA”的原子数据节点。节点DATE具有表示日期类型值“11/08/82”的后代数据节点。
路径
路径表达式是包括“路径步骤”序列的表达式,该序列基于一个或多个节点的每个分层位置来识别分层数据对象中的一个或多个节点。“路径步骤”可以由“/”、“.”或其它定界符分隔。每个路径步骤可以是识别到分层数据对象内的节点的路径中的节点的标签名。XPath是指定用于路径表达式的路径语言的查询语言。另一种查询语言是SQL/JSON,这是Oracle和IBM与其它RDBMS供应商共同开发的SQL/JSON标准的一部分。
在SQL/JSON中,用于JSON的路径表达式的示例是“$.BORN.DATE”。步骤“DATE”指定具有节点名“DATE”的节点。步骤“BORN”指定节点“DATE”的父节点的节点名。“$”指定路径表达式的上下文,在默认情况下,它是要为其评估路径表达式的分层数据对象。
路径表达式还可以为节点应当满足的步骤指定谓词或标准。例如,下面的查询
$.born.date>TO_DATE(’1998-09-09’,‘YYYY-MM-DD’)
指定节点“born.date”大于日期值“1998-09-09”。
说明性SSD列和发布列表
根据实施例,SSDM单元包括发布索引,该发布索引将标志索引到在分层数据对象中找到的标志位置。使用图5A中描绘的分层数据对象来说明发布索引。在图6A中描绘了说明性发布索引,并且图6B描绘了在实施例中使用的散列的发布索引,该散列的发布索引是序列化的散列表形式的发布索引。
参考图5A,它以PF形式描绘了分层数据对象。参考图5A,对于R5、R6、R7和R8中的每一行,存储JSON对象。持久形式或镜像格式的JSON对象在本文中由包含JSON对象的行的行id指称。行R5包含用于说明标志的JSON对象R5。
发布索引包括从分层数据对象提取出的标志。标志可以是非叶子节点的标签名、数据节点中的词或数据节点中的另一个值、定界符,或分层数据对象的另一个特征。形成发布索引需要从分层数据对象中解析和/或提取标志。并不是在分层数据对象中找到的所有标志都必需由发布索引来加索引。
一般而言,发布索引对标志加索引,该标记是标签名或字符串值数据节点中的词。发布索引将每个标志索引到包含该标志的一个或多个分层数据对象,并索引到覆盖该标志的内容的那些分层数据对象中的字符序列。
对于JSON,标志可以是:
1)对象或数组的开始。
2)字段名。
3)原子值,在非字符串JSON值的情况下。
4)字符串原子值中的词。
发布索引可以对符合分层标记语言(诸如JSON、XML或其组合)的分层数据对象的集合加索引。使用符合JSON的分层数据对象说明了发布索引;但是,发布索引的实施例不限于JSON。
在分层数据对象内,对标志进行排序。标志的次序由在本文中被称为标志号的序数表示。
与字段名或字符串原子值中的词对应的标志被用于形成用于发布索引的键值。发布索引中的每个索引条目将标志映射到标志位置,该标志位置可以是标志号或由例如起始标志号和结束标志号定义的标志范围。
与非叶子节点的标签名对应的标志在本文中被称为标签名标志。关于JSON,标签名是字段名,并且与字段名对应的标志是标签名标志,但是在本文中也可以被称为字段标志。
标志范围根据标志的标志号指定JSON对象中与字段节点对应的区域和字段节点的内容。
图5B描绘了JSON对象R5中的标志。图5B中的每个调出(call out)标签通过标志号引用JSON对象505中的标志。标志#1是JSON对象的开头。标志#2是字段名“name(名称)”。标志#3是字段“name”的原子字符串值中的第一个词。标志#4是字段“name”的原子字符串值中的第二单词。标志#7与字段标志“friends(朋友)”对应。标志#8是与数组的开头对应的定界符,该数组是字段“friends”的JSON值。标志#9和标志#15各自是与数组内对象的开头对应的定界符。
作为数据节点的字符串值中的词的标志在本文中被称为词标志。标志#3是词标志。与数据节点的非字符串值对应的标志在本文中被称为值标志。值标志在本文未示出。
说明性发布索引和散列的发布索引
图6A描绘了发布索引601。发布索引601是将标志索引到JSON对象R5、R6、R7和R8内的标志位置的表。根据实施例,发布索引601包括列Token(标志)、Type(类型)和列PostingList(发布列表)。列Token包含与在JSON对象中找到的字段标志和词标志对应的标志。列Type包含标志类型,其可以是“tagname(标签名)”以指定作为字段标志的标志并且可以是“keyword(关键词)”以指定作为词标志的标志。
列PostingList包含发布列表。发布列表包括一个或多个对象-标志-位置列表。对象-标志-位置列表包括对诸如JSON对象之类的分层数据对象的对象引用,以及在分层数据对象内用于标志出现的一个或多个标志位置。发布索引601中的每个发布索引条目都将标志映射到发布列表,从而将标志映射到包含标志的每个JSON对象以及每个JSON对象中的一个或多个标志位置。
图6A中的发布索引601的描绘示出了为SSD列C2中的JSON对象生成的条目。参考图6A,发布索引601包含用于“name”的条目。因为该条目在列Type中包含“标签名”,所以该条目将作为字段标志的标志“name”映射到发布列表中指定的JSON对象和标志位置(0,(2-4)(10-12)(16-19))(1,(2-4))(2,(2-4))(3,(2-4))。用于标志“name”的发布索引条目包含以下项中的对象-标志-位置列表:
(0,(2-4),(10-12),(16–19))这个对象-标志-位置列表包括对象引用0,其引用包含JSON对象R5的行的索引。对象-标志-位置列表将字段标志“name”映射到JSON对象R5中由标志范围#2-#4、标志范围#10-#12和标志范围#16-#19定义的区域。
对象-标志-位置列表中的对象引用被称为索引对准的,因为对于包含分层数据对象的行,对象引用是该行在IMCU中跨列向量的索引。类似地,发布索引601及其中的发布索引条目在本文中被称为索引对准的,因为发布索引条目基于加索引的对准的对象引用将标志映射到分层数据对象。
(1,(2-4))这个对象-标志-位置列表参考列向量324和326的索引1处的JSON对象R6。对象列表将字段节点“name”映射到标志范围#2-#4定义的JSON对象R6中的区域。
发布索引601还包含用于“Helen”的条目。因为条目在Type中包含“关键词”,所以该条目将标志“Helen”作为数据节点中的词映射到发布列表(0,(11,17))(1,(3))中指定的JSON对象和区域。这个发布列表包含对象-级别列表,如下所示:
(0,(11,17))这个对象-标志-位置列表参考索引0处的JSON对象R5。对象-级别列表进一步将词“Helen”映射到由标志位置#11和#17定义的JSON对象505中的两个标志位置。
(1,(3))这个对象-标志-位置列表参考索引0处的行R6的JSON对象506。对象引用将词“Helen”映射到JSON对象506中的标志位置#3。
散列的发布索引
为了更高效的存储,将发布索引存储为SSDM单元内的序列化的散列表。散列表的每个散列桶(bucket)存储发布索引条目的一个或多个条目。
图6B示出了序列化的散列表形式的发布索引601,作为散列的发布索引651。参考图6B,散列的发布索引651包括四个散列桶HB0、HB1、HB2和HB3。图6C是散列的发布索引651的展开图,其示出了每个散列桶HB0、HB1、HB2和HB3的内容。每个散列桶可以保持一个或多个发布列表索引条目。
通过将散列函数应用于发布列表索引条目的标志来确定在其中保持发布索引条目的特定散列桶。对于标志“USA”、“citizenship”、“YAN”,散列函数评估为0;因而,标志“USA”、“citizenship”、“YAN”中的每一个的发布列表都存储在HB0中。
序列化的散列桶作为字节流存储在存储器内。在实施例中,每个散列桶以及散列桶内的组件(诸如发布列表和对象-标志-位置列表)可以由定界符界定并且可以包括头部。例如,散列桶HB0可以包括头部,该头部具有指向下一个散列桶HB1的偏移量。HB0中的每个对象-级别列表可以包括到接下来的对象列表(如果有)的偏移量。在另一个实施例中,辅助阵列可以包含到序列化的散列桶中的每个散列桶的偏移量。序列化的散列桶可以比散列桶的非序列化形式具有更少的存储器占用空间。
使用分布索引的谓词评估
对象列表中的对象引用的索引对准启用和/或促进针对SSD C2上的谓词条件生成位向量,该位向量可与为针对列向量的谓词评估而生成的其它位向量组合以生成返回向量。例如,DBMS 100正在评估具有连接谓词“C1=“SAN JOSE”且C3=“CA”且C2包含“UK”的查询。DBMS 100在IMCU 304中针对C1和C3评估该谓词。在列向量324(C1)上为谓词连接词C1=“SAN JOSE”生成位向量“1110”并且在列向量326(C3)上为谓词连接词C3=“CA”生成位向量“0110”。
对于谓词条件,在列C2上C2包含“UK”,访问散列表以确定哪些行保持包含“UK”的JSON对象。将值“UK”应用于散列函数产生1。对散列桶HB1进行评估,以确定哪些JSON对象包含“UK”。映射到“UK”的唯一对象列表包括索引为2的对象引用。基于对象引用2,设置结果向量中的对应的第三位,从而生成位向量0010。
在为谓词生成的位向量之间执行AND运算。AND运算生成返回结果向量0010。
要求功能评估的谓词评估
当对分层数据对象执行评估时,重要的是能够指定要返回的数据的结构特征。结构特征基于分层数据对象内数据的位置。基于此类特征的评估在本文中被称为功能评估。结构特征的示例包括元素包含、字段包含、字符串接近度以及分层数据对象中基于路径的位置。发布列表索引内的标志位置可以被用于至少部分地评估结构特征。
例如,谓词条件$.CITIZENSHIP=“USA”指定JSON对象“citizenship(国籍)”内的字段“citizenship”等于字符串值“USA”。为了确定该谓词是否被满足,可以检查散列的发布索引651以找到具有标签名“citizenship”的分层数据对象,并且对于每个这样的对象,确定在标签名“citizenship”的标志位置的范围内的标志是否是等于“USA”的关键词。
具体而言,用于散列的发布索引的散列函数651被应用于生成散列值0的“citizenship”。检查散列桶HB0,以确定标签名“citizenship”包含在由索引0、1、2、3引用的分层数据对象中,这些数据对象是JSON对象R5、R6、R7和R8。对于JSON对象R6(索引1所指称的JSON对象),标签名的标志位置为(5–6)。
接下来,检查用于“USA”的发布列表。散列函数被应用于“USA”,从而生成散列值0。检查散列桶HB0,以确定关键词“USA”是在标志位置6处的关键词标志。因此,行R6中索引1处的分层数据对象满足该谓词。
类似地,对标签名“citizenship”的其它标志位置进行评估。在2014年9月26日由Zhen Hua Liu等人提交的标题为“Generic Indexing For Efficiently Supporting Ad-Hoc Query Over Hierarchical Marked-Up Data”的美国专利No.9,659,045中描述了结构特征的基于标志位置的谓词评估的示例,包括路径评估,其全部内容通过引用并入本文。
事务一致性
为了使MF数据在事务上与PF数据保持一致,提交给PF数据的事务将反映在MF数据中。根据实施例,为了反映以PF形式的半结构化数据中已提交的改变,SSDM单元本身不必改变,而是维持元数据以指示已更新在IMCU中高速缓存的哪些分层数据对象。在2014年7月21日由Vivekanandhan Raja等人提交的标题为“Multi-Version Concurrency Control OnIn-Memory Snapshot Store Of Oracle In-Memory Database”的美国专利No.9,128,972中描述了用于维护MF数据的此类元数据的机制,其内容并入本文并在本文中被称为“Concurrency Control申请”。
在实施例中,通过维持在IMCU内的“行改变的向量”来指示对IMCU中的行的改变。例如,当事务执行对行R6的更新时,通过设置与行R6对应的位来更新IMCU 304的行改变的向量。
对于要求数据项的最新版本的事务,行改变的位向量中设定的位指示行的MF数据是陈旧的,因此IMCU 304无法用来评估用于那行的谓词或从那行返回数据。代替地,使用PF侧评估来评估用于那行的谓词。
但是,并非所有事务都要求数据项的最新版本。例如,在许多DBMS中,为事务指派快照时间,并返回反映那个快照时间时数据库状态的数据。具体而言,如果为事务指派了快照时间T3,那么必须为该事务提供数据项的各版本,所述版本包括T3之前提交的所有改变并且不包括T3时未提交的改变(除事务自己所做的改变之外)。对于此类事务,行改变的位向量中设定的位不一定指示IMCU 304不能用于对应的行。
在实施例中,为了解释读取在IMCU 304中镜像的值的事务的快照时间,为试图从IMCU读取数据的每个事务创建快照无效向量。快照无效向量是特定于快照时间的,因为快照无效向量中的位仅针对在与为其构造快照无效向量的事务相关联的快照时间之前被修改的行设置。Concurrency Control申请中进一步详细描述了生成和处理快照无效向量。
利用事务一致性的谓词评估
为了利用关于查询的快照时间的事务一致性来评估针对列SSD C2的谓词条件,散列的发布索引651可以被用于相应快照无效向量指定有效的任何行,即,用于未为其设置快照无效向量中对应位的任何行。对于快照无效向量指定无效的任何行,执行PF侧评估。
图7是描述用于针对查询和快照时间评估谓词条件的过程的流程图。使用IMCU304、以下谓词C1=“SAN JOSE”且JSON_EXISTS($.CITIZENSHIP=”USA”)以及快照无效向量“0100”来说明该过程。快照无效向量指定行R6无效。
该过程选择性地对SSD C2执行谓词评估,以更高效地不仅针对SSD C2而且还针对用于另一个列的列向量评估谓词。具体而言,与基于散列的发布索引651的谓词条件相比,可以更高效地评估基于标量列向量的相等谓词条件。对于连接谓词,一旦确定行不满足该连接谓词的谓词连接词,该行就无法满足该谓词,而不管评估该行上该谓词的另一个谓词连接词的结果如何。因此,可以跳过在被先前评估的谓词连接词认为不合格的行上对另一个谓词连接词的评估,以便确定谓词的评估结果,从而减少评估连接谓词所需的处理。
参考图7,在705处,生成快照无效向量“0100”。快照无效向量指定R6行无效。
在710处,针对列向量324评估谓词条件C1=“SAN JOSE”。因而,针对行R5、R7和R8评估谓词连接词,产生结果向量1110。在实施例中,对于通过谓词评估的行,结果向量中的位设置为1。因此,当结果向量或返回向量中的位被设置为0时,指定相应的行已被认为不合格。
在715处,针对散列的发布索引651评估谓词条件JSON_EXISTS($.CITIZENSHIP=”USA”)。类似于在“基于结构特征的谓词评估”一节中描述的示例来评估谓词。但是,用于无效行或不合格行的对象-标志-位置列表可以被忽略。行R8被认为不合格,因为行R8不满足先前评估的谓词连接词。因而,使用散列的分布索引651对行R5和R7评估谓词。生成的结果向量等于1100。
在720处,在AND运算中组合所生成的结果向量以生成返回向量。生成的返回向量是1100。
在726处,对尚未被认为不合格的无效行执行PF侧评估。在当前图示中,快照无效向量指定行R6无效。因此,对行R6执行PF侧评估。
分层数据对象的PF侧评估
对以PF形式存储的分层数据对象的谓词评估可以要求也可以不要求功能评估。例如,SSD C2中PF形式的分层数据对象以二进制可流传输形式存储。为了针对行中的分层数据对象评估运算符CONTAINS,可以简单地流传输分层数据对象以查找该运算符所需的特定字符串。
但是,对于要求功能评估的谓词评估,功能评估要求启用功能评估和/或启用更高效的功能评估的分层数据对象的表示。根据本发明的实施例,为通过PF侧处理进行评估的分层数据对象生成对象-级别发布索引。对象-级别发布索引实际上是用于单个分层数据对象的发布索引。当执行PF侧谓词评估时,可以为IMCU中的任何无效行生成对象-级别发布索引。
图8描绘了用于行R6的SSD C2的对象-级别发布索引801。对象-级别发布索引801共享发布索引601的许多特征,但是没有对分层数据对象的对象引用,因为对象-级别发布索引801仅属于单个分层数据对象。
参考图8,在对象-级别发布索引801中,列Token包含与在JSON对象R6中找到的字段标志和关键词标志对应的标志。列Type包含每个条目的标志类型。列Token LocationList(标志位置列表)为每个条目包含一个或多个标志位置,用于标志对于该条目的出现。
刷新散列的发布索引
如在Mirroring申请中提到的,可以刷新IMCU以使其中的MF数据与作为特定时间点的PF数据保持同步。可以通过从头开始实现散列的发布索引来刷新散列的发布索引,这将要求处理和解析IMCU所有行中的JSON对象。
为了更高效地刷新散列的发布索引,可以通过修改现有的散列的发布索引来递增地刷新散列的发布索引。因为散列的发布索引是序列化的结构,所以散列的发布索引可能无法分段修改以反映对JSON对象的任何改变。代替地,通过将现有的散列的发布索引的有效部分与“增量发布索引”(仅针对已改变的行形成的发布索引)合并来形成刷新的散列的发布索引。为了执行递增刷新,对于每个现有的发布列表索引条目,在其中未改变的任何对象-级别-标签列表与增量发布索引中的对应发布列表索引中的任何对象-标志-位置列表之间执行排序合并。重要的是要注意,在发布列表索引条目内,对象-标志-位置列表基于对象标识符按次序被维护,以便于排序合并。
图9A描绘了用于生成用于散列的发布索引的递增刷新的“刷新的发布列表条目”的过程。图9B描绘了根据本发明实施例的增量发布索引。
参考图9B,其描绘了增量发布索引901,即,用于IMCU 304中已改变的JSON对象的发布列表索引。除增量发布索引901仅索引已改变的行R5和R6的JSON对象之外,增量发布索引901与发布索引601类似地被结构化。用于IMCU 304的行改变的位向量指定这些行已经改变。
对每个发布列表条目执行用于生成刷新的发布列表条目的过程。一般而言,每个散列桶中的每个现有发布列表条目都经过处理以形成刷新的散列的发布索引条目。刷新的发布索引条目被附加到正在形成的刷新的散列发布索引的当前版本。随着刷新后的发布索引条目的追加,将添加定界符和偏移量,诸如用于散列桶和散列的发布索引条目的定界符。在图9A中未绘出添加定界符和偏移量的操作。
对于每个已改变的JSON对象,增量发布索引901对整个JSON对象而不仅仅是已改变的节点加索引。关于改变,在行R5的JSON对象中,字符串JOHN已改为JACK。在行R6的JSON对象中,字符串“USA”已改为“UK”。增量发布索引801是索引对准的。因此,其中的对象引用是列向量索引。
使用散列的发布索引651和增量发布索引901以形成刷新的散列发布索引来说明图9A中描绘的过程。没有描绘刷新的散列发布索引。说明从HB0中的第一个分布索引条目(用于“USA”的分布索引条目)开始。
参考图9A,在905处,读取来自散列的发布索引651的下一个现有的对象-标志-位置列表。下一个现有的对象-标志-位置列表是(0,(6)(14)(21)),这是用于“USA”的第一个现有的对象-标志-位置列表。
在910处,确定下一个现有的对象-标志-位置列表是否有效。行改变的向量指定索引到0的行R5中的JSON对象没有改变,因此是有效的。
在915处,用于增量发布索引901中的对应发布索引条目的任何在先的增量对象-标志-位置列表被添加到形成的刷新的散列的发布索引。当前下一个现有对象-标志-位置列表的对象引用为0。增量发布索引901中的对应发布索引条目包含一个对象-标志-位置列表,该列表为(2,(6)),其具有对象引用2。因为对象引用2大于0,所以没有要添加的在先的对象-标志-位置列表。
在920处,将下一个现有的对象-标志-位置列表添加到刷新的散列的发布索引条目。在905处,读取下一个现有的对象-标志-位置列表(1,(6))。
在910处,根据行改变的向量,对象-标志-位置列表无效。对象-标志-位置列表被忽略。过程前进到905。在905处,读取下一个现有的对象-标志-位置列表(3,(6))。
在915处,将增量发布索引901中的用于对应发布索引条目的任何在先的增量对象-标志-位置列表添加到刷新的散列的发布索引条目。对应的发布索引条目包含一个对象-标志-位置列表,该列表为(2,(6)),其具有对象引用2。因为对象引用2小于3,所以对象-标志-位置列表(2,(6))被追加到刷新的散列的发布索引条目。
在920处,将下一个现有的对象-标志-位置列表追加到形成的刷新的散列的发布索引条目。在905处,读取下一个现有的对象-标志-位置列表(3,(6))。在910处,基于行改变的向量,确定对象-标志-位置列表是有效的。在920处,将下一个现有的对象-标志-位置列表追加到刷新的散列的发布索引条目。
在过程的执行的这一点上,刷新的对象-标志-位置列表是(0,(2-4)(10-12)(16,19))(2,(6))(3,(6))。现有的发布索引条目中没有更多的对象-标志-位置列表,因此执行前进到930。
在930处,来自增量发布索引901中尚未追加的对应发布索引条目的任何剩余的对象-标志-位置列表被追加到刷新的对象-标志-位置列表。因为没有,所以没有追加。
在935处,确定是否任何对象-标志-位置列表已经被追加到刷新的发布索引条目。如果不是,那么不将任何内容追加到刷新的散列的发布索引中。但是,已追加对象-标志-位置列表。因此,刷新的对象-标记-位置列表被追加到刷新的散列的发布索引。
在读取散列桶内的发布索引条目结束时,可以存在属于该散列桶但尚未追加到该散列桶的标志的发布索引条目。在前进到下一个散列桶(如果有)之前,将这些发布索引条目追加到刷新的散列的发布索引。
非结构化文本数据
本文描述的用于存储和查询SSDM的方法可以被用于非结构化文本数据。与SSDM相似,除发布列表不需要包括type属性以将标志的类型表示为关键词或标签名之外,IMCU可以存储来自发布列表中某一列的非结构化文本数据。类似地,对象-级别发布列表和散列的发布索引不包含用于标志的这种type属性。以类似的方式提供事务一致性、PF侧评估、散列的发布索引刷新。
数据库概述
本发明的实施例在数据库管理系统(DBMS)的上下文中使用。因此,提供了示例DBMS的描述。
一般而言,诸如数据库服务器之类的服务器是集成的软件组件和诸如存储器、节点以及节点上用于执行集成的软件组件的进程之类的计算资源的分配的组合,其中软件和计算资源的组合专用于代表服务器的客户端提供特定类型的功能。数据库服务器控制并促进对特定数据库的访问,处理客户端访问数据库的请求。
数据库包括存储在持久存储机制(诸如硬盘的集合)上的数据和元数据。这样的数据和元数据可以例如根据关系和/或对象关系数据库构造在逻辑上存储在数据库中。
用户通过向DBMS的数据库服务器提交使数据库服务器对存储在数据库中的数据执行操作的命令来与该数据库服务器进行交互。用户可以是在与数据库服务器交互的客户端计算机上运行的一个或多个应用。多个用户在本文中也可以被统称为用户。
数据库命令可以是数据库语句的形式。为了使数据库服务器处理数据库语句,数据库语句必须符合数据库服务器支持的数据库语言。许多数据库服务器支持的数据库语言的一个非限制性示例是SQL,包括由诸如Oracle之类的数据库服务器支持的SQL专有形式(例如,Oracle Database 11g)。将SQL数据定义语言(“DDL”)指令发布到数据库服务器以创建或配置数据库对象,诸如表、视图或复杂类型。数据操纵语言(“DML”)指令被发布给DBMS,以管理存储在数据库结构内的数据。例如,SELECT、INSERT、UPDATE和DELETE是一些SQL实施方式中常见的DML指令示例。SQL/XML是在对象-关系数据库中操纵XML数据时使用的SQL的常见扩展。
一般而言,数据被存储在一个或多个数据容器中的数据库中,每个容器包含记录,并且每个记录内的数据被组织为一个或多个字段。在关系DBMS中,数据容器通常被称为表,记录被称为行,而字段被称为列。在面向对象的数据库中,数据容器通常被称为对象类,记录被称为对象,而字段被称为属性。其它数据库体系架构可以使用其它术语。实现本发明的系统不限于任何特定类型的数据容器或数据库体系架构。但是,出于解释的目的,本文使用的示例和术语应通常与关系数据库或对象-关系数据库相关联。因此,术语“表”、“行”和“列”在本文中将分别用于指代数据容器、记录和字段。
多节点数据库管理系统由互连的节点组成,这些节点共享对同一数据库的访问。通常,节点经由网络互连,并在不同程度上共享对共享存储装置的访问,例如对一组盘驱动器和存储在其上的数据块的共享访问。多节点DBMS中的节点可以是经由网络互连的一组计算机(例如,工作站、个人计算机)的形式。可替代地,节点可以是网格的节点,该网格由与机架上的其它服务器刀片互连的服务器刀片形式的节点组成。
多节点DBMS中的每个节点都托管数据库服务器。服务器(诸如数据库服务器)是集成软件组件和计算资源(诸如存储器、节点以及节点上的用于在处理器上执行集成软件组件的进程)的分配的组合、专用于代表一个或多个客户端执行特定功能的软件和计算资源的组合。
可以分配来自多节点DBMS中多个节点的资源,以运行特定的数据库服务器的软件。软件和节点中的资源的分配的每种组合都是在本文中被称为“服务器实例”或“实例”的服务器。数据库服务器可以包括多个数据库实例,其中一些或全部在单独的计算机(包括单独的服务器刀片)上运行。
硬件概述
根据一个实施例,本文描述的技术由一个或多个专用计算设备实现。专用计算设备可以是硬连线的以执行这些技术,或者可以包括数字电子设备(诸如被持久地编程为执行这些技术的一个或多个专用集成电路(ASIC)或现场可编程门阵列(FPGA)),或者可以包括被编程为根据固件、存储器、其它存储装置或组合中的程序指令执行这些技术的一个或多个通用硬件处理器。这种专用计算设备还可以将定制的硬连线逻辑、ASIC或FPGA与定制编程相结合,以实现这些技术。专用计算设备可以是台式计算机系统、便携式计算机系统、手持设备、联网设备或者结合硬连线和/或程序逻辑以实现这些技术的任何其它设备。
例如,图10是图示可以在其上实现本发明实施例的计算机系统1000的框图。计算机系统1000包括总线1002或用于传送信息的其它通信机制,以及与总线1002耦合以处理信息的硬件处理器1004。硬件处理器1004可以是例如通用微处理器。
计算机系统1000还包括耦合到总线1002的主存储器1006,诸如随机存取存储器(RAM)或其它动态存储设备,用于存储将由处理器1004执行的信息和指令。主存储器1006还可以用于存储在执行由处理器1004执行的指令期间的临时变量或其它中间信息。当存储在处理器1004可访问的非瞬态存储介质中时,这些指令使计算机系统1000成为被定制以执行指令中指定的操作的专用机器。
计算机系统1000还包括耦合到总线1002的只读存储器(ROM)1008或其它静态存储设备,用于存储用于处理器1004的静态信息和指令。提供存储设备1010(诸如磁盘、光盘或固态驱动器)并耦合到总线1002,用于存储信息和指令。
计算机系统1000可以经由总线1002耦合到显示器1012(诸如阴极射线管(CRT)),用于向计算机用户显示信息。包括字母数字键和其它键的输入设备1014耦合到总线1002,用于将信息和命令选择传送到处理器1004。另一种类型的用户输入设备是光标控件1016(诸如鼠标、轨迹球或光标方向键),用于将方向信息和命令选择传送到处理器1004并用于控制显示器1012上的光标移动。这种输入设备通常在两个轴上具有两个自由度,第一轴(例如,x)和第二轴(例如,y),这允许设备指定平面中的位置。
计算机系统1000可以使用定制的硬连线逻辑、一个或多个ASIC或FPGA、固件和/或程序逻辑(它们与计算机系统相结合,使计算机系统1000成为或将计算机系统1000编程为专用机器)来实现本文所述的技术。根据一个实施例,响应于处理器1004执行包含在主存储器1006中的一个或多个指令的一个或多个序列,计算机系统1000执行所述的技术。这些指令可以从另一个存储介质(诸如存储设备106)读入到主存储器1006中。包含在主存储器1006中的指令序列的执行使得处理器1004执行本文所述的处理步骤。在替代实施例中,可以使用硬连线的电路系统代替软件指令或与软件指令组合。
如本文使用的术语“存储介质”是指存储使机器以特定方式操作的数据和/或指令的任何非瞬态介质。这种存储介质可以包括非易失性介质和/或易失性介质。非易失性介质包括例如光盘、磁盘或固态驱动器,诸如存储设备1010。易失性介质包括动态存储器,诸如主存储器1006。存储介质的常见形式包括例如软盘、柔性盘、硬盘、固态驱动器、磁带或任何其它磁数据存储介质、CD-ROM、任何其它光学数据存储介质、任何具有孔图案的物理介质、RAM、PROM和EPROM、FLASH-EPROM、NVRAM、任何其它存储器芯片或盒式磁带。
存储介质不同于传输介质但可以与传输介质结合使用。传输介质参与在存储介质之间传送信息。例如,传输介质包括同轴电缆、铜线和光纤,包括包含总线1002的导线。传输介质也可以采用声波或光波的形式,诸如在无线电波和红外数据通信期间生成的那些。
各种形式的介质可以参与将一个或多个指令的一个或多个序列传送到处理器1004以供执行。例如,指令最初可以在远程计算机的磁盘或固态驱动器上携带。远程计算机可以将指令加载到其动态存储器中,并使用调制解调器通过电话线发送指令。计算机系统1000本地的调制解调器可以在电话线上接收数据并使用红外发送器将数据转换成红外信号。红外检测器可以接收红外信号中携带的数据,并且适当的电路系统可以将数据放在总线1002上。总线1002将数据传送到主存储器1006,处理器1004从主存储器1006检索并执行指令。由主存储器1006接收的指令可以可选地在由处理器1004执行之前或之后存储在存储设备106上。
计算机系统1000还包括耦合到总线1002的通信接口1018。通信接口1018提供耦合到网络链路1020的双向数据通信,其中网络链路1020连接到本地网络1022。例如,通信接口1018可以是集成服务数字网(ISDN)卡、电缆调制解调器、卫星调制解调器或者提供与对应类型的电话线的数据通信连接的调制解调器。作为另一个示例,通信接口1018可以是局域网(LAN)卡,以提供与兼容LAN的数据通信连接。还可以实现无线链路。在任何此类实现中,通信接口1018都发送和接收携带表示各种类型信息的数字数据流的电信号、电磁信号或光信号。
网络链路1020通常通过一个或多个网络向其它数据设备提供数据通信。例如,网络链路1020可以提供通过本地网络1022到主计算机1024或到由互联网服务提供商(ISP)1026操作的数据设备的连接。ISP 1026进而通过全球分组数据通信网络(现在通常称为“互联网”1028)提供数据通信服务。本地网络1022和互联网1028都使用携带数字数据流的电信号、电磁信号或光信号。通过各种网络的信号以及网络链路1020上并通过通信接口1018的信号(其将数字数据携带到计算机系统1000和从计算机系统1000携带数字数据)是传输介质的示例形式。
计算机系统1000可以通过(一个或多个)网络、网络链路1020和通信接口1018发送消息和接收数据,包括程序代码。在互联网示例中,服务器1030可以通过互联网1028、ISP1026、本地网络1022和通信接口1018发送对应用程序的请求代码。
接收到的代码可以在被接收到时由处理器1004执行,和/或存储在存储设备106或其它非易失性存储器中以供稍后执行。
在前面的说明书中,已经参考众多具体细节描述了本发明的实施例,这些细节可以从实现到实现有所变化。因而,说明书和附图应被视为说明性而非限制性的。本发明范围的唯一和排他性指示,以及申请人意图作为本发明范围的内容,是以发布这种权利要求书的具体形式从本申请发布的权利要求书集合的字面和等同范围,包括任何后续更正。
软件概述
图11是可以用于控制计算机系统1000的操作的基本软件系统1100的框图。软件系统1100及其组件,包括它们的连接、关系和功能,仅仅是示例性的,并且不意味着限制(一个或多个)示例实施例的实现。适于实现(一个或多个)示例实施例的其它软件系统可以具有不同的组件,包括具有不同的连接、关系和功能的组件。
提供软件系统1100用于指导计算机系统1000的操作。可以存储在系统存储器(RAM)1006和固定存储装置(例如,硬盘或闪存)1010上的软件系统1100包括内核或操作系统(OS)1110。
OS 1110管理计算机操作的低级方面,包括管理进程的执行、存储器分配、文件输入和输出(I/O)以及设备I/O。表示为1102A、1102B、1102C...1102N的一个或多个应用可以被“加载”(例如,从固定存储装置1010传送到存储器1006中)以供系统1100执行。意图在计算机系统1000上使用的应用或其它软件也可以被存储为可下载的计算机可执行指令集,例如,用于从互联网位置(例如,Web服务器、app商店或其它在线服务)下载和安装。
软件系统1100包括图形用户界面(GUI)1115,用于以图形(例如,“点击”或“触摸手势”)方式接收用户命令和数据。进而,这些输入可以由系统1100根据来自操作系统1110和/或(一个或多个)应用1102的指令来操作。GUI 1115还用于显示来自OS 1110和(一个或多个)应用1102的操作结果,用户可以提供附加的输入或终止会话(例如,注销)。
OS 1110可以直接在计算机系统1000的裸硬件1120(例如,(一个或多个)处理器1004)上执行。可替代地,管理程序或虚拟机监视器(VMM)1130可以插入在裸硬件1120和OS1110之间。在这个配置中,VMM 1130充当OS 1110与计算机系统1000的裸硬件1120之间的软件“缓冲”或虚拟化层。
VMM 1130实例化并运行一个或多个虚拟机实例(“客人机”)。每个客人机包括“客人”操作系统(诸如OS 1110),以及被设计为在客人操作系统上执行的一个或多个应用(诸如(一个或多个)应用1102)。VMM 1130向客人操作系统呈现虚拟操作平台并管理客人操作系统的执行。
在一些实例中,VMM 1130可以允许客人操作系统如同其直接在计算机系统1000的裸硬件1120上运行一样运行。在这些实例中,被配置为直接在裸硬件1120上执行的客人操作系统的相同版本也可以在VMM 1130上执行而无需修改或重新配置。换句话说,VMM 1130可以在一些情况下向客人操作系统提供完全硬件和CPU虚拟化。
在其它实例中,客人操作系统可以被专门设计或配置为在VMM 1130上执行以提高效率。在这些实例中,客人操作系统“意识到”它在虚拟机监视器上执行。换句话说,VMM1130可以在某些情况下向客户操作系统提供半虚拟化。
计算机系统进程包括硬件处理器时间的分配,以及存储器的分配(物理和/或虚拟)、用于存储由硬件处理器执行的指令的存储器的分配,用于存储由硬件处理器执行指令所生成的数据,和/或用于当计算机系统进程未运行时在硬件处理器时间的分配之间存储硬件处理器状态(例如,寄存器的内容)。计算机系统进程在操作系统的控制下运行,并且可以在计算机系统上执行的其它程序的控制下运行。
云计算
本文一般地使用术语“云计算”来描述计算模型,该计算模型使得能够按需访问计算资源的共享池,诸如计算机网络、服务器、软件应用和服务,并且允许以最少的管理工作或服务提供商交互来快速提供和释放资源。
云计算环境(有时称为云环境或云)可以以各种不同方式实现,以最好地适应不同要求。例如,在公共云环境中,底层计算基础设施由组织拥有,该组织使其云服务可供其它组织或公众使用。相反,私有云环境一般仅供单个组织使用或在单个组织内使用。社区云旨在由社区内的若干组织共享;而混合云包括通过数据和应用可移植性绑定在一起的两种或更多种类型的云(例如,私有、社区或公共)。
一般而言,云计算模型使得先前可能由组织自己的信息技术部门提供的那些职责中的一些代替地作为云环境内的服务层来输送,以供(根据云的公共/私人性质,在组织内部或外部)消费者使用。取决于特定实现,由每个云服务层提供或在每个云服务层内提供的组件或特征的精确定义可以有所不同,但常见示例包括:软件即服务(SaaS),其中消费者使用在云基础设施上运行的软件应用,同时SaaS提供者管理或控制底层云基础设施和应用。平台即服务(PaaS),其中消费者可以使用由PaaS的供应者支持的软件编程语言和开发工具,以开发、部署和以其它方式控制它们自己的应用,同时PaaS提供者管理或控制云环境的其它方面(即,运行时执行环境下的一切)。基础设施即服务(IaaS),其中消费者可以部署和运行任意软件应用,和/或提供进程、存储装置、网络和其它基础计算资源,同时IaaS提供者管理或控制底层物理云基础设施(即,操作系统层下面的一切)。数据库即服务(DBaaS),其中消费者使用在云基础设施上运行的数据库服务器或数据库管理系统,同时DbaaS提供者管理或控制底层云基础设施、应用和服务器,包括一个或多个数据库服务器。
- 用存储器内列式查询处理启用和集成存储器内半结构化数据和文本文档搜索的技术
- 存储器内数据搜索技术