用于处理数字视频的设备及方法
文献发布时间:2023-06-19 10:22:47
技术领域
本发明涉及图像数据和视频处理领域,即,分析和处理数字视频的多媒体数据的过程。更具体地,本发明涉及一种用于通过将广告图像嵌入到输入数字视频来生成输出视频的设备及相应的方法,其中,所述设备包括视频分析单元、确定单元和处理单元。
背景技术
目前,广告业是广告主和媒体公司的主要收入来源。近年来,上传到互联网和制作的电视媒体上的视频文件数量有所增加。例如,每分钟有300多个小时的视频文件上传到视频分享网站。自2011年以来,原创电视剧集数量的增长率为71%。为了增加利润,媒体公司或视频分享网站非常依赖这些媒体的广告收入(广告收益)。
用于将广告图像和/或广告视频合并到输入视频的传统设备和方法是基于将广告内容呈现给观看者,呈例如,叠加视觉图像、弹出窗口或在输入视频内显示的其他视频(例如,广告视频)等形式。然而,使用传统的设备和方法,可能会妨碍输入视频的重要内容和/或迫使观看者观看整个广告视频,这会使他们感到困扰和烦扰。此外,基于植入广告的方法需要人工编辑输入视频,费时且成本高。
正如所讨论的,媒体公司将其视频数据变现的常见方式是使用弹出式广告或横幅式广告。替代方法是将相关的广告内容自然地嵌入输入视频中。通过将广告内容(例如广告图像、广告视频等)放置到合适的位置和时间帧,广告主可以在不干扰观看者的情况下介绍自己的产品。然而,对于数千小时的视频数据,当这些任务由人工完成时,广告内容的选择和放置是困难且耗时的。这种情况下,人工广告嵌入是一项繁琐的工作,需要投入大量的资金和人力。因此,对于愿意将视频数据变现的公司来说,以舒适的方式自动插入广告是一个非常重要的问题。
此外,用于在视频中插入广告的传统设备仅限于使用静止摄像机捕获的视频。换句话说,只有当摄像机静止时才能识别插入广告的潜在位置。
在现有技术中,仅使用基于深度学习的视频内容分析对视频进行分类,且尚无多模态视频分析可用。广告并非自动选择,而是人工选择。此外,最先进技术对广告匹配问题的关注较少,一般经由广泛的视频内容分析,并且没有解决广告位置/时间帧选择与相似广告的选择和遮挡的组合问题。
尽管存在用于处理数字视频的技术,例如,将广告人工嵌入视频中等,但是通常期望改进用于处理数字视频的设备和方法。
发明内容
鉴于上述问题和缺点,本发明旨在改进用于处理数字视频的传统设备和方法。因此,本发明的目的是提供一种用于处理数字视频的设备。
本发明的目的通过所附独立权利要求中提供的解决方案来实现。本发明的有利实施方式在从属权利要求中进一步定义。
本发明的第一方面提供一种用于处理数字视频的设备,其中,所述设备包括:视频分析单元,用于将输入数字视频的多媒体数据分割为音频数据和多个视频片段,通过分析所述音频数据和所述视频片段的帧,确定每个视频片段的视频内容信息;确定单元,用于检测视频片段中的至少一个表层,基于广告图像的元数据与对应视频片段的所述确定的视频内容信息之间的语义相似度,针对所述检测到的表层从所述数据库中选择所述广告图像;处理单元,用于通过将从所述数据库中选择的所述广告图像嵌入所述检测到的表层上,生成输出视频。
从所述数据库中选择的所述广告图像可以是静止图像或视频图像。可以从所述数据库中选择一个以上广告图像以嵌入所述检测到的表层(例如广告视频)中。因此,提供所述视频的多模态分析,并基于视频内容信息选择广告图像。基于内容的广告选择将向观看者展示与他们所看视频内容相关的广告,因此,观看者极有可能在不受干扰的情况下对广告感兴趣。
此外,所述广告在不干扰所述观看者的情况下在恰当的位置以恰当的时间间隔得以显示,例如,通过选择与所述视频内容信息语义相关的广告,并将它们无缝嵌入所述视频中。本发明还具有所述观看者无需等待广告间歇的优点。此外,由于是基于所述视频内容信息等来选择所述广告图像,因此所述观看者不会看到无关广告。广告将自然地嵌入视频中,如同在视频录制时广告就已经存在一样。此外,可以自动选择最佳的广告位置(即所述检测到的表层)和时间帧,避免干扰所述观看者。
在所述第一方面的一种实现方式中,基于遮挡处理机制生成所述输出视频,其中,所述遮挡处理机制包括:通过识别所述视频片段的场景背景、所述视频片段的场景前景和所述视频片段中的至少一个运动对象,确定所述视频片段中的至少一个遮挡物。
这是有益的,因为可以以舒适的方式将所述广告图像无缝嵌入所述输入视频中。此外,它确保对所述广告图像与所述视频中的其他对象之间出现的遮挡进行处理。例如,如果所述检测到的表层(即,将嵌入广告的表层)被另一对象遮挡(例如,当该对象移动到所述检测到的表层前方时),所述遮挡处理机制确保所述对象始终显示在所述广告图像前方,如同在录制视频时所述广告图像物理上就已经存在一样。所述遮挡物和遮挡区域通过前景/背景分割确定。因此,如果没有遮挡,不需要所述处理遮挡机制就可以将广告嵌入视频中。
在所述第一方面的一种实现方式中,分割所述输入数字视频的多媒体数据还包括对视觉信息的语义分析。
这是有益的,因为可以基于语义相似度从所述数据库中为视频片段选择最佳广告。
在所述第一方面的一种实现方式中,分割所述输入数字视频的多媒体数据还包括以下各项中的至少一项:视频片段类别检测、视频片段对象检测、视频片段对象识别、视频片段图像字幕、视频片段显著性区域检测、视频片段脸部检测、视频片段文本检测和视频片段运动检测。
这是有益的,因为每个视频片段都是通过多个子模块以不同的方式进行分析的。所述视频片段类别检测确保检测视频片段类别,用于选择语义相似的广告图像。所述视频片段对象检测和所述视频片段对象识别能够检测所述视频片段中的对象位置并进一步识别所述对象。此外,它们还确保理解视频片段的构成,并选择语义上相似的广告图像。所述视频片段图像字幕确保生成所述视频片段中图像的自然语言描述。所述视频片段显著性区域检测确保降低破坏性,并提升用户的观看体验。该模块旨在找到最低显著性区域,并将所述广告图像嵌入该区域中。因此,广告图像不会遮挡帧内任何有意义的区域,从而提高了用户的观看质量。所述视频片段脸部检测和所述视频片段文本检测能够从所述视频片段的每一帧中搜索并查找脸部和文本,并提供不将所述广告图像嵌入检测到的区域中这一反馈。所述视频片段运动检测有益于遮挡处理。例如,如果对象遮挡了所述嵌入的广告图像,则所述设备通过估计运动活动和防止缺陷来确定这种情况。所述输出视频可以具有自然场景,例如在录制视频时广告图像就存在等。
在所述第一方面的一种实现方式中,分析所述音频数据包括语音识别和文本分析。
这是有益的,因为音频信息处理会检测所述视频片段中的语音,然后使用已知方法查找最重要的词语,从而能够理解所述视频片段的构成,然后更有效地确定所述视频片段的视频内容信息。
在所述第一方面的一种实现方式中,通过将所述视频片段的所述帧划分为多个网格,并通过采用显著性检测算法、对象识别算法、脸部检测算法、文本检测算法和边缘检测算法中的至少一项对每个网格进行评分,对所述表层进行检测。
这是有益的,因为可以确定干扰最小或侵扰最小的区域。例如,可以将视频片段的每个图像划分为多个网格,每个网格可以使用这些算法进行评分。可以使用所述网格的分数,也可以确定候选位置(即,与所述检测到的表层对应),将所述广告图像嵌入分数最高的位置。此外,通过应用一种或多种上述算法,确定最合适的候选区域(即,与所述检测到的表层对应)以嵌入所述广告图像。这些算法是所述显著性检测算法、所述对象识别算法、所述脸部检测算法、所述文本检测算法和所述边缘检测算法。
在所述第一方面的一种实现方式中,所述显著性检测算法包括检测最低显著性区域以及进一步检测所述检测到的最低显著性区域中的表层。
这是有益的,因为通过检测所述最低显著性区域以及进一步检测所述检测到的最低显著性区域中的所述表层,可以将所述广告图像嵌入视频流的视频片段中最平滑的部分,这进一步降低困扰。
在所述第一方面的一种实现方式中,所述确定单元还用于确定所述检测到的表层的3D形状,其中,所述处理单元还用于基于所述确定的所述检测到的表层的3D形状和所述遮挡处理机制,生成所述输出视频。
这是有益的,因为它确保了通过将嵌入了所述广告图像的表层的3D姿态考虑在内以及通过对遮挡进行处理,将多媒体广告(即,所述至少一个广告图像,特别是一个或多个广告静止图像和/或广告视频)嵌入视频中。
在所述第一方面的一种实现方式中,所述确定单元还用于检测视频片段中的运动对象,其中,所述处理单元还用于通过如下方式生成所述输出视频:嵌入所述选择的广告图像,从而将所述选择的广告图像嵌入所述检测到的运动对象后面以及所述检测到的表层前面。
这是有益的,因为它确保对视频片段中的运动对象和/或记录视频的摄像机的运动进行检测。此外,它还能够将所述广告图像嵌入所述检测到的表层中,并通过遮挡处理机制将所述广告图像保持在此位置,即使所述视频中的所述对象移动和/或摄像机移动等。
在所述第一方面的一种实现方式中,所述确定单元还用于在确定的时间间隔内检测所述视频片段中的所述至少一个表层;所述处理单元还用于在所述确定的时间间隔内,将从所述数据库中选择的所述广告图像嵌入所述检测到的所述输出视频中的表层上。
这是有益的,因为它能够自动将所述广告图像嵌入所述视频片段中。此外,可以在某个时间或某个时段,和/或在整个视频片段期间嵌入所述广告图像。此外,它还确保将在所述视频片段的所述时间间隔内恰当嵌入所述广告图像。
在所述第一方面的一种实现方式中,所述确定单元还用于跟踪所述检测到的表层的运动;所述处理单元还用于将从所述数据库中选择的所述广告图像嵌入所述检测到的表层上,使得所述选择的广告图像维持在所述输出视频中的所述检测到的表层上。
这是有益的,因为对所述检测到的表层进行了跟踪。此外,它还确保将所述广告图像维持在所述检测到的表层上,即使所述视频片段中的所述对象移动和/或记录视频的摄像机移动等。
综上所述,所述第一方面的所述设备提供了一种用于通过如下方式嵌入最相关的广告图像的新方法:分析视频片段及其音频内容,并结合视频内容信息为所述视频片段中的广告图像选择最佳位置和时间帧。
本发明的第二方面提供一种用于处理数字视频的方法,其中,所述方法包括以下步骤:将输入数字视频的多媒体数据分割为音频数据和多个视频片段,通过分析所述音频数据和所述视频片段的帧,确定每个视频片段的视频内容信息;检测视频片段中的至少一个表层,基于广告图像的元数据与对应视频片段的所述确定的视频内容信息之间的语义相似度,针对所述检测到的表层从所述数据库中选择所述广告图像;通过将从所述数据库中选择的所述广告图像嵌入所述检测到的表层上,生成输出视频。
在所述第二方面的一种实现方式中,所述方法还包括基于遮挡处理机制生成所述输出视频,其中,所述遮挡处理机制包括:通过识别所述视频片段的场景背景、所述视频片段的场景前景和所述视频片段中的至少一个运动对象,确定所述视频片段中的至少一个遮挡物。
在所述第二方面的一种实现方式中,分割所述输入数字视频的多媒体数据还包括对视觉信息的语义分析。
在所述第二方面的一种实现方式中,分割所述输入数字视频的多媒体数据还包括以下各项中的至少一项:视频片段类别检测、视频片段对象检测、视频片段对象识别、视频片段图像字幕、视频片段显著性区域检测、视频片段脸部检测、视频片段文本检测和视频片段运动检测。
在所述第二方面的一种实现方式中,分析所述音频数据包括语音识别和文本分析。
在所述第二方面的一种实现方式中,所述方法还包括:通过将所述视频片段的所述帧划分为多个网格,并通过采用显著性检测算法、对象识别算法、脸部检测算法、文本检测算法和边缘检测算法中的至少一项对每个网格进行评分,对所述表层进行检测。
在所述第二方面的一种实现方式中,所述显著性检测算法包括检测最低显著性区域以及进一步检测所述检测到的最低显著性区域中的表层。
在所述第二方面的一种实现方式中,所述方法还包括:确定所述检测到的表层的3D形状;基于所述确定的所述检测到的表层的3D形状和所述遮挡处理机制,生成所述输出视频。
在所述第二方面的一种实现方式中,所述方法还包括:检测视频片段中的运动对象;通过如下方式生成所述输出视频:嵌入所述选择的广告图像,从而将所述选择的广告图像嵌入所述检测到的运动对象后面以及所述检测到的表层前面。
在所述第二方面的一种实现方式中,所述方法还包括:在确定的时间间隔内检测所述视频片段中的所述至少一个表层;在所述确定的时间间隔内,将从所述数据库中选择的所述广告图像嵌入所述检测到的所述输出视频中的表层上。
在所述第二方面的一种实现方式中,所述方法还包括:跟踪所述检测到的表层的运动;将从所述数据库中选择的所述广告图像嵌入所述检测到的表层上,使得所述选择的广告图像维持在所述输出视频中的所述检测到的表层上。
本发明的第三方面提供一种计算机程序,包括程序代码,所述程序代码在计算机上执行时,使得所述计算机执行根据本发明的第二方面所述的方法。
本发明的第四方面提供一种非瞬时性计算机可读记录介质,存储计算机程序产品,所述计算机程序产品由处理器执行时,使得根据本发明的第二方面所述的方法得以执行。
应注意,本申请中所描述的所有设备、元件、单元和构件都可以在软件或硬件元件或其任何种类的组合中实施。本申请中描述的各种实体执行的所有步骤和所描述的将由各种实体执行的功能旨在表明各个实体适于或用于执行各自的步骤和功能。即使,在以下具体实施例的描述中,待由外部实体执行的特定功能或步骤未反映在执行该特定步骤或功能的该实体的具体详细元件的描述中,技术人员也应该清楚,这些方法和功能可以在相应的软件或硬件元件,或其任何种类的组合中实施。
附图说明
结合所附附图,下面具体实施例的描述将阐述上述本发明的各方面及其实现方式,其中:
图1示出了根据本发明实施例的用于处理数字视频的设备的示意图。
图2更详细地示出了根据本发明实施例的用于处理数字视频的设备的示意图。
图3示出了视频分析单元的示意图。
图4示出了包括根据本发明实施例的设备的系统的一实施例的示意图。
图5示出了根据本发明实施例的用于处理数字视频的方法的示意图。
图6示出了根据本发明实施例的用于分割输入数字视频,为所述视频片段选择广告图像,将所述选择的广告图像嵌入到所述视频片段中的方法的示意图。
具体实施方式
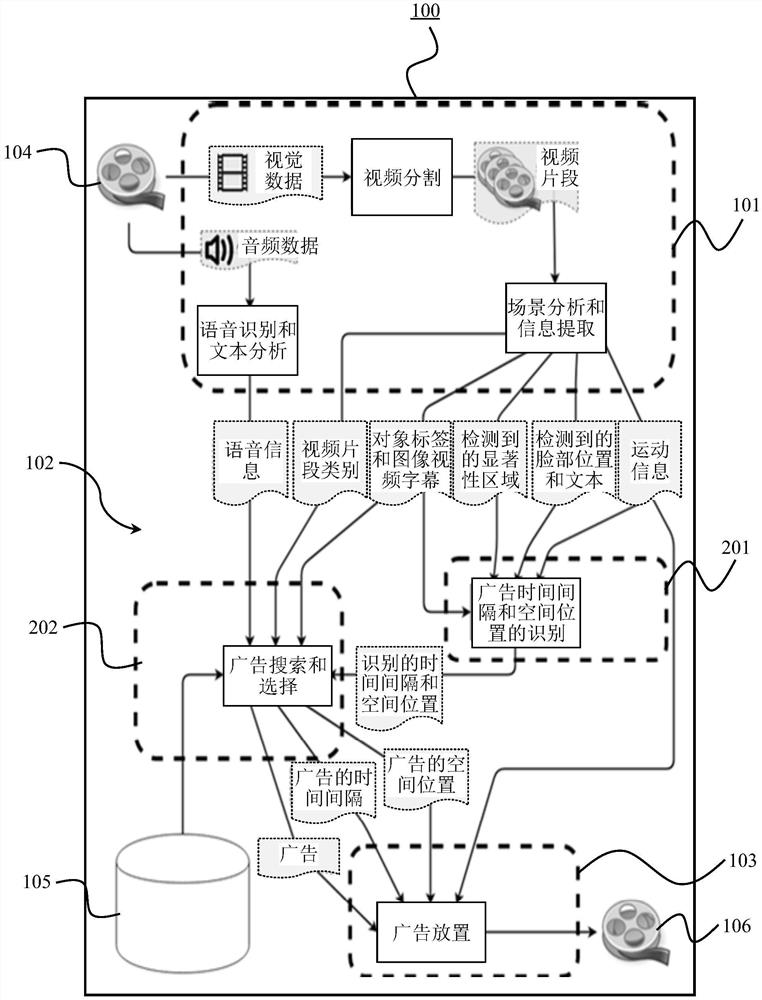
图1示出了根据本发明的实施例的设备100的示意图。设备100用于处理数字视频。设备100包括视频分析单元101、确定单元102和处理单元103。
设备100可以是电子设备,例如个人计算机、平板电脑等,可以是服务器设备/计算机、智能手机,可以位于一个设备中,可以分布在两个或更多个设备之间,可以是远程计算机(云)等,但在这方面并不限制本发明。
视频分析单元101用于将输入数字视频104的多媒体数据分割为音频数据和多个视频片段,通过分析所述音频数据和所述视频片段的帧,确定每个视频片段的视频内容信息。
换句话说,视频分析单元101用于进行基于多模态内容的视频分析。例如,视频分析单元101可以将所述输入数字视频的多媒体数据分割为音频数据和多个视频片段。
视频分析单元101还可以用于通过语音识别分析所述音频数据,例如,可以基于语音转文本程序将视频中的语音内容转换为文本,并使用自然语言处理方法分析提取的文本,以确定每个视频片段的视频内容信息。然后,使用自然语言方法(例如实体识别方法、词性标注等)分析提取的文本。
此外,视频分析单元101可以分析视频片段的帧。视频片段的帧可以使用一种或多种视觉和语义分析方法进行分析,例如视频片段对象检测、视频片段对象识别、视频片段图像字幕、视频片段脸部和文本检测以及视频片段运动分析。这些分析可以使用最先进的计算机视觉技术进行,而这些技术大多基于深度学习。对象识别将提供对视频内部内容的洞察。图像字幕提供对图像的自然语言描述。对象、脸部和文本位置用于检测不适合嵌入广告图像的重要区域。运动分析用于检测空旷静态区域、运动对象或摄像机移动。这些将用于检测用于嵌入广告图像的表层,在该表层中适当嵌入广告图像,并将该广告图像保持在该位置(即,检测到的表层),即使对象或摄像机在处理遮挡时有所移动。
因此,设备100的视频分析单元101能够将输入数字视频的多媒体数据分割为音频数据和多个视频片段,分析所述音频数据和所述视频片段的帧,确定每个视频片段的视频内容信息。
设备100还包括确定单元102,用于检测视频片段中的至少一个表层,基于广告图像的元数据与对应视频片段的所述确定的视频内容信息之间的语义相似度,针对所述检测到的表层从数据库中选择所述广告图像。
确定单元102检测用于放置广告的表层,例如,该表层可以是视频片段中的空区域。确定单元102可以使用所提取的视频内容信息,并且可以在最佳时间帧和空间位置中对表层进行检测。例如,可以对用于向观看者展示广告持续一段合理的时间,而不干扰观看者的表层进行检测。
此外,确定单元102用于针对检测到的表层从数据库105中选择广告图像。特别地,使用广告与视频内容信息的语义相似度从数据库105中选择广告图像。数据库105包括例如由广告主提供的广告元数据。可以使用视频分析单元101确定的视频内容信息在数据库105中进行搜索。广告选择可以基于语义距离、广告大小(如果是视频广告,则广告长度)等标准。
设备100还包括处理单元103,用于通过将从数据库105中选择的广告图像嵌入检测到的表层上,生成输出视频106。
换句话说,处理单元103可以使用一种和/或多种图像和视频处理技术将从数据库105中选择的广告嵌入检测到的表层上。此外,如果视频片段中的对象移动和/或如果摄像机移动,则处理单元103还可以使用算法将广告图像保持在相应区域,例如,输出视频106中检测到的表层。例如,处理单元103可以通过遮挡处理机制生成输出视频106,其中,如果对象出现在嵌入广告图像的区域前面,则嵌入的广告图像应停留在该对象后面。
图2更详细地示出了根据本发明的实施例的设备100的示意图。图2的设备100基于图1的设备100,因此包括其所有功能和特征。为此,相同的特征用相同的参考符号来标记。将根据图2所描述的所有特征都是设备100的可选特征。
如图2所示,设备100的确定单元102可选地还可包括广告时间间隔和空间位置识别单元201及广告搜索和选择单元202。
如图2所指示,设备100获取输入数字视频104的多媒体数据,设备100的视频分析单元101将输入数字视频104的多媒体数据分割为音频数据和视觉数据,所述视觉数据包括多个视频片段。视频分析单元101例如基于语音识别和文本分析方法进一步分析所述音频数据;确定所述输入数字视频的语音信息;将该语音信息提供给确定单元102中的广告搜索和选择单元202。
此外,视频分析单元101可以基于场景分析方法对视频片段的帧进行分析,可以提取包括视频片段类别、对象标签和图像/视频字幕的信息。视频分析单元101还检测视频片段的帧中的显著性区域、脸部和文本,并提取运动信息。此外,视频分析单元101将提取的信息提供给确定单元102。
确定单元102可选地包括广告时间和空间位置识别单元201,用于获取提取的信息,并识别用于嵌入广告图像的时间间隔和空间位置。此外,确定单元102可选地包括广告搜索选择单元202,用于从数据库105中搜索广告图像并选择广告图像。确定单元102的广告搜索和选择单元202将选择的广告、针对选择的广告图像识别的时间间隔以及识别的广告图像的空间位置提供给处理单元103。
设备100的处理单元103以识别的时间间隔将选择的广告嵌入识别的空间位置上,进一步生成输出视频106。
图3示出了包括在图1或图2所示的设备100中的视频分析单元101的示意图。视频分析单元101可以通过以下六个单元分析视频片段的帧:视频片段类别检测和识别单元301、视频片段对象检测和对象识别单元302、视频片段字幕单元303、视频片段显著性区域检测单元304、视频片段脸部和文本检测单元305、视频片段运动检测单元306。视频分析单元101可以用于通过一个或多个单元分析视频片段的帧,这些单元负责以不同的方式分析视频片段。
视频片段类别检测单元301可用于检测视频片段类别,例如足球、卡通、音乐会等。然后,可以使用该视频片段类别信息来选择语义相似的广告。
视频片段对象检测和识别单元302可用于识别每一帧中的至少一个对象,例如喜鹊、紧身衣、清真寺等。这些检测到的对象有助于理解视频片段的构成,选择语义相似的广告图像。
视频片段字幕单元303可用于创建句子(例如,英文文本),以表达视频片段的构成。该字幕包括有助于确定视频片段的构成和/或视频内容信息的信息。
视频片段显著性区域检测单元304可用于降低破坏性,提升用户的观看体验。该单元旨在找到最低显著性区域,将广告图像嵌入到该区域中。因此,嵌入的广告图像不会遮挡帧内任何有意义的信息,从而提高了用户的观看质量。
视频片段脸部和文本检测单元305可用于从视频片段的每一帧中搜索并查找一个或多个脸部和一个或多个文本,提供不在确定区域(即包括视频片段中的脸部和文本)上嵌入广告图像的反馈。视频片段脸部和文本检测单元305的目标可以与视频片段显著性区域检测模块304类似。
视频片段运动检测单元306可负责实现遮挡处理机制。例如,如果有任何类型的对象遮挡了嵌入的广告,则视频片段运动检测单元306会通过估计的运动活动识别这种情况。因此,视频片段运动检测单元306可以防止缺陷,还可以创造更多的自然场景。
除了视觉信息提取之外,视频分析器单元还可以提取音频信息(未示出),如上所述。视频分析器单元101分析音频数据并检测视频片段中的语音,然后使用已知的方法确定视频内容信息,从而发现大多数有意义的词语,如上所述。
综上所述,本发明提出了一种新方法,其目的不仅在于通过分析视频片段的帧及其音频数据来检索最相关的广告图像,而且在于将广告图像嵌入最佳位置和时间间隔中。所述设备还可以执行显著性检测和遮挡处理机制,从而允许将广告图像嵌入视频片段中最平滑的部分,同时最大可能地降低困扰。
此外,所述设备还提供了通过显著性检测进行基于内容的自动广告嵌入,并进一步使用广泛的位置分析,例如,遮挡处理机制,这相比现有技术系统具有优势。
图4示出了包括根据本发明实施例的设备100的系统400的一实施例的示意图。
图4的设备100基于图1或图2的设备100,因此包括其所有功能和特征。
系统400的设备100通过将广告图像嵌入作为输入数字视频的视频源的多媒体数据中,生成输出视频,这种嵌入考虑了广告图像放置的表层的3D姿态以及遮挡处理机制。对视频片段进行语义分析,基于视频内容信息与广告元数据之间的语义相似度选择广告图像。
设备100包括视频分析单元101,用于将作为输入数字视频的视频源的多媒体数据分割为音频数据和视频片段;分析音频数据和视频片段的帧;提取场景信息;确定视频内容信息。
视频分析单元101基于语音识别和文本分析分析视频源的音频数据,并且进一步分割视频源(即,输入数字视频),对视频片段进行分类。
此外,视频分析单元101还提取视频片段中的信息。提取的信息包括:由视频片段对象检测单元提取的对象信息;由视频片段显著性区域检测单元提取的显著性信息;由视频片段脸部和文本检测单元提取的脸部和文本信息;由视频片段运动检测单元提取的运动信息。
视频分析单元101针对视频源中所有的视频片段和/或场景对音频数据和视频片段的帧进行分析并确定视频内容信息。
此外,视频分析单元101将提取的信息提供给确定单元102中的数据库(database,DB)。确定单元102可选地包括广告选择单元,用于利用确定的视频内容信息和广告图像元数据针对视频片段和/或选择的场景,选择最相关的广告。确定单元102还可选地包括时间和位置识别单元,用于利用对象信息、显著性信息、脸部信息、文本信息和运动信息确定用于嵌入广告图像的时间和位置(即,对表层进行检测)。确定单元102使用前述信息查找最不干扰观看者的位置。
系统400还包括数据库105,用于存储广告图像及其对应的元数据,广告图像可以例如基于其内容、广告来源等进行分类,但在这方面并不限制本发明。
设备100还包括处理单元103,用于生成输出视频。处理单元103嵌入广告图像,进行遮挡处理,保存处理后的视频的多媒体数据,进一步生成输出视频。例如,处理单元103使用位置(即,检测到的表层)、时间信息(即,展示广告的间隔时间)、运动信息、遮挡信息,嵌入广告图像。
因此,设备100能够将广告图像和/或广告视频嵌入输入数字视频中。首先,将输入数字视频分割成视频片段和/或视频场景。对每个视频片段和/或场景进行分析,选择最佳的可用位置和时间帧。使用从视频片段和/或场景中提取的语义信息,从数据库中选择合适的广告图像,在处理遮挡时将其嵌入所选位置和时间帧中。该系统的输出是检测到的表层上嵌入的广告的输出视频。
图5示出了根据本发明实施例的用于处理数字视频的方法500的示意图。
方法500包括第一步骤:将输入数字视频的多媒体数据分割501为音频数据和多个视频片段,通过分析所述音频数据和所述视频片段的帧,确定(例如提取)501每个视频片段的视频内容信息。
该方法还包括第二步骤:检测502视频片段中的至少一个表层,基于广告图像的元数据与对应视频片段的确定的(例如提取的)视频内容信息之间的语义相似度,针对检测到的表层从数据库中选择502广告图像。
该方法还包括第三步骤:通过将从数据库中选择的广告图像嵌入检测到的表层上,生成503输出视频。
图6示出了根据本发明实施例的用于处理数字视频的方法600的示意图。
在601中,设备100获取视频源作为输入数字视频。
在602中,设备100将视频可视化地分割成多个视频片段。视频分析单元101利用视频的视觉信息分割该视频。视觉信息表示每一帧的结构信息、颜色直方图、边缘信息等。视频分割操作可以减少为视频片段选择广告图像的计算操作的次数等。
在603中,设备100中的视频分析单元分析视频片段的帧。
在604中,视频分析单元101确定视频片段特征,并进一步确定视频片段的视频内容信息。
在605中,确定单元102基于广告图像的元数据与对应视频片段的确定的视频内容信息之间的语义相似度,从广告数据库中选择广告图像。
在606中,设备100的处理单元103将选择的广告图像嵌入视频片段的检测到的表层上并执行遮挡处理机制。
此外,当确定执行遮挡处理机制和广告图像的嵌入时,处理单元转到步骤607,生成输出视频。然而,当确定没有嵌入广告图像且没有执行遮挡处理机制时,则所述方法转到步骤603,视频分析单元101重新分析视频片段并确定(例如,提取)视频内容信息。
除了视频内容信息和视觉相似度外,所述设备还可以考虑视频片段与广告图像之间的语义相似度,例如,可以以不同的方式提取视频片段中每一帧的几种信息,确定单元可以考虑提取的信息以选择广告图像。
所述设备可以将多媒体广告(例如,广告图像、广告视频等)自动嵌入输入数字视频中。例如,所述设备旨在基于遮挡处理机制和显著性区域分析,将虚拟广告嵌入语义相似的视频片段中。语义相似度表示视频片段与广告图像之间的关系,例如,对于任何与车辆相关的视频片段,所述设备可以不嵌入清洗材料的广告。此外,可以应用遮挡处理机制,使得如果任何对象移动到嵌入广告图像的前面,则嵌入广告图像应停留在该对象后面和检测到的表层的前面。
已经结合作为实例的不同实施例以及实施方式描述了本发明。然而,根据对附图、本发明和独立权利要求的研究,本领域技术人员在实践所要求保护的发明时,能够理解和实现其他变化。在权利要求书以及说明书中,词语“包括”不排除其他元件或步骤,且不定冠词“一”或者“一个”不排除多个。单个元件或其他单元可满足权利要求书中所叙述的若干实体或项目的功能。仅仅在相互不同的从属权利要求中叙述某些措施这一事实并不意味着这些措施的组合不能在有利的实施方式中使用。
- 用于录制并传输数字视频图像的图像录制系统、用于接收并处理数字图像数据的图像数据处理系统、用于生成无抖动数字视频图像的图像稳定系统和方法
- 用于时分多路复用处理多个数字视频节目的方法和设备