基于用户隐私数据的推荐方法及其装置、介质和系统
文献发布时间:2023-06-19 10:46:31
技术领域
本申请涉及信息安全领域,特别涉及一种基于用户隐私数据的推荐方法及其装置、介质和系统。
背景技术
近年来随着人工智能的迅速发展,人们对生活有了更强烈的智能化需求,移动终端成为现代人们集娱乐、工作和学习活动的通用设备,扮演着个人智能助理的角色。AI(Artificial Intelligence人工智能)给终端带来的最大价值在于入口本身越来越精准,越来越人性化,越来越便利。理解用户,主动服务,终生学习能够给用户带来极致的体验,也成为终端智慧化的未来。当前AI算法和终端计算能力发展迅速,各大厂商着力于充分利用各种资源优势,通过移动终端为用户提供精准、贴心的全方位个性化服务。
随着人们对个人隐私数据的重视程度日益提高,个人隐私数据不上传云端的需求越发强烈。把用户隐私数据上传云端进行分析的方式不被认可,未来也不会被应用。当前各大厂商已着力于研究用户个人隐私数据不上传云端的情况下,如何通过移动终端为用户提供精准、贴心的全方位个性化服务。
当前移动终端所提供的AI相关的推荐服务,如音乐推荐、视频推荐、应用推荐、新闻推荐、广告推荐等,均是对用户上传的非个人隐私数据进行分析与推荐的,然而,这部分数据并不能代表用户全部特征。
发明内容
本申请实施例提供了一种基于用户隐私数据的推荐方法及其装置、介质和系统。
第一方面,根据本申请一些实施例公开了一种推荐方法,包括:向云端发送用户偏好标签,其中,所述用户偏好标签包括对基于用户的隐私数据生成的第一标签进行概化后的第一概化标签;接收云端返回的基于所述用户偏好标签从资源库中搜索到的多个资源项;从所述多个资源项中选择出推荐的资源项。即在该推荐方法中,向云端发送基于用户隐私数据生成的第一标签的第一概化标签,云端可以根据第一概化标签搜索与用户的隐私数据相关的资源项,如此,在使得搜索结果更加精准智能、更具个性化的情况下,不向云端上传用户的隐私数据,保证对隐私数据的保护。可以理解,此处的第一概化标签可以是一个标签,也可以是多个标签,数量不限制。
在上述第一方面的一种实现中,所述从所述多个资源项中选择出推荐的资源项包括:基于所述用户的第一标签对所述多个资源项进行排序,生成第一排序结果;将所述第一排序结果中的前预定数目的资源项作为所述推荐的资源项。即在该实现中,根据与用户隐私数据直接相关的第一标签对云端返回的搜索结果进行排序,可以将与第一标签(可以是一个标签,也可以是多个标签,数量不限制)匹配度高的资源项排在前面。由于云端是根据概化后的第一标签或者说概化后的用户隐私数据进行搜索的,第一概化标签所表示的范围大于第一标签,故检索到内容会有冗余,将其按照第一标签或者说未概化的用户隐私数据进行排序,会将更贴近用户隐私数据的搜索结果排在前面。如此,推荐给用户的资源项更贴近所用到的用户隐私数据,用户体验更具个性化。此外,也不一定是将第一排序结果中的前预定数目的资源项作为推荐的资源项,可以设置其他的选取规则,在此不做限制,例如,将前预定数目的资源项中的奇数项作为推荐的资源项。
在上述第一方面的一种实现中,所述多个资源项包括云端基于所述第一概化标签搜索到的第一资源项;并且所述方法还包括:在所述推荐的资源项包括所述第一资源项的情况下,在屏幕上显示所述第一资源项和对应所述第一资源项的第一推荐理由,其中,所述第一推荐理由是根据检索到所述第一资源项时用到的第一概化标签所对应的第一标签生成的。即在该实现中,如果云端搜索到的资源项包括与概化的用户隐私数据相关的资源项,则根据搜索到这些资源项时概化的用户隐私数据所对应的隐私数据,为这些资源项生成推荐理由,并向用户显示或者播报推荐理由,从而使得推荐业务更加智能化。
在上述第一方面的一种实现中,所述用户标签还包括基于用户的非隐私数据生成的第二标签,其中,用户的非隐私数据为对用户进行描述的数据中除用户的隐私数据外的全部数据;并且,所述云端返回的所述多个资源项还包括云端基于所述第二标签搜索到的第二资源项。即在该实现中,同时向云端发送与用户隐私数据相关的第一概化标签和与用户非隐私数据相关的第二标签,搜索结果与用户的概化的隐私数据和非隐私数据相关。
在上述第一方面的一种实现中,所述云端搜索到的多个资源项还包括对应所述第二资源项的第二推荐理由,其中,所述第二推荐理由与搜索到所述第二资源项时所使用的第二标签相关。即云端返回的资源项中如果包括基于用户的非隐私标签(或者说非隐私数据)搜索到的资源项,则同时还返回有与该资源项对应的推荐理由。
在上述第一方面的一种实现中,所述方法还包括:在所述推荐的资源项包括所述第二资源项的情况下,在屏幕上显示所述第二资源项和所述第二推荐理由。
在上述第一方面的一种实现中,所述从所述多个资源项中选择出推荐的资源项包括:基于至少一个第二标签对所述多个资源项进行排序,生成第二排序结果。即在搜索时,资源项可能是基于一个第二标签搜索到的,而在对多个搜索到的资源项进行排序时,可以基于具有的多个第二标签对其进行排序,将同时与多个第二标签匹配的资源项排在前面。
在上述第一方面的一种实现中,所述从所述多个资源项中选择出推荐的资源项还包括:确定所述第二排序结果中是否存在重复的资源项;在确定存在重复的资源项的情况下,删除所述重复的资源项。
在上述第一方面的一种实现中,所述从所述多个资源项中选择出推荐的资源项还包括:基于所述第一标签对所述第二排序结果进行排序,生成第三排序结果;将所述第三排序结果中的前预定数目的资源项作为所述推荐的资源项。由于云端是根据概化后的第一标签或者说概化后的用户隐私数据进行搜索的,第一概化标签的所表示的范围大于第一标签,故检索到内容会有冗余,将其按照第一标签或者说未概化的用户隐私数据进行排序,会将更贴近用户隐私数据的搜索结果排在前面。如此,推荐给用户的资源项更贴近所用到的用户隐私数据,用户体验更具个性化。此外,也不一定是将第三排序结果中的前预定数目的资源项作为推荐的资源项,可以设置其他的选取规则,在此不做限制,例如,将前预定数目的资源项中的奇数项作为推荐的资源项。
第二方面,根据本申请的一些实施例,公开了一种推荐方法,包括:从终端接收用户偏好标签,其中,所述用户偏好标签包括对基于用户的隐私数据生成的第一标签进行概化后的第一概化标签;基于接收到的所述用户偏好标签,从资源库中搜索与所述用户偏好标签匹配的资源项;在搜索到与所述用户偏好标签匹配的资源项的情况下,将搜索到的所述资源项发送给所述终端。即在该推荐方法中,云端从终端接收基于用户隐私数据生成的第一标签的第一概化标签,云端可以根据第一概化标签搜索与用户的隐私数据相关的资源项,如此,在使得搜索结果更加精准智能、更具个性化的情况下,不用获取用户的隐私数据,保证对隐私数据的保护。可以理解,此处的第一概化标签可以是一个标签,也可以是多个标签,数量不限制。
在上述第二方面的一种实现中,所述用户标签还包括基于用户的非隐私数据生成的第二标签,其中,用户的非隐私数据为对用户进行描述的数据中除用户的隐私数据外的全部数据;并且所述多个资源项还包括云端基于所述第二标签搜索到的第二资源项。即在该实现中,云端同时接收与用户隐私数据相关的第一概化标签和与用户非隐私数据相关的第二标签,搜索结果与用户的概化的隐私数据和非隐私数据相关。
在上述第二方面的一种实现中,所述方法还包括:基于所述第二标签生成对应所述第二资源项的第二推荐理由。即云端搜索到的资源项中如果包括基于用户的非隐私标签(或者说非隐私数据)搜索到的资源项,则同时还生成与该资源项对应的推荐理由。
在上述第二方面的一种实现中,所述方法还包括:基于所述第二标签对向所述终端发送的资源项进行排序,生成第二排序结果;确定所述第二排序结果中是否存在重复的资源项;在确定存在重复的资源项的情况下,删除所述重复的资源项。其中,即在搜索时,资源项可能是基于一个第二标签搜索到的,而在对多个搜索到的资源项进行排序时,可以基于具有的多个第二标签对其进行排序,将同时与多个第二标签匹配的资源项排在前面。
在上述第二方面的一种实现中,所述资源项包括云端基于所述第一概化标签搜索到的第一资源项。
第三方面,根据本申请的一些实施例,公开了一种推荐装置,包括:第一发送模块,向云端发送用户偏好标签,其中,所述用户偏好标签包括对基于用户的隐私数据生成的第一标签进行概化后的第一概化标签;第一接收模块,用于接收云端返回的基于所述用户偏好标签从资源库中搜索到的多个资源项;选择模块,用于从所述多个资源项中选择出推荐的资源项。
第四方面,根据本申请的一些实施例,公开了一种推荐装置,包括:第二接收模块,用于从终端接收用户偏好标签,其中,所述用户偏好标签包括对基于用户的隐私数据生成的第一标签进行概化后的第一概化标签;搜索模块,用于基于接收到的所述用户偏好标签,从资源库中搜索与所述用户偏好标签匹配的资源项;第二发送模块,用于在搜索到与所述用户偏好标签匹配的资源项的情况下,将搜索到的所述资源项发送给所述终端。
第五方面,根据本申请的一些实施例,公开了一种机器可读介质,所述机器可读介质上存储有指令,该指令在机器上执行时使机器执行上述第一方面或者第二方面的推荐方法。
第六方面,根据本申请的一些实施例,公开了一种系统,包括:
存储器,用于存储由系统的一个或多个处理器执行的指令,以及
处理器,是系统的处理器之一,用于执行上述第一方面或者第二方面的推荐方法。
第七方面,根据本申请的实施例,公开了一种终端,该终端具有实现上述方法中终端的行为的功能。所述功能可以通过硬件实现,也可以通过硬件执行相应的软件实现。所述硬件或软件包括一个或多于一个与上述功能相对应的模块。
第八方面,根据本申请的实施例,公开了一种云端,该云端具有实现上述方法中云端的行为的功能。所述功能可以通过硬件实现,也可以通过硬件执行相应的软件实现。所述硬件或软件包括一个或多于一个与上述功能相对应的模块。
附图说明
图1根据本申请的一些实施例,示出了一种基于用户隐私数据的推荐系统的结构示意图;
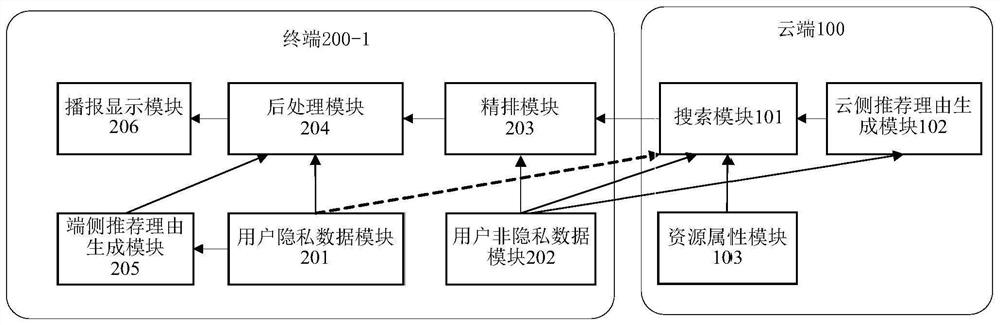
图2根据本申请的一些实施例,示出了图1所示的系统中的终端和云端的结构示意图;
图3根据本申请的一些实施例,示出了终端播报显示推荐的歌曲的示意图;
图4根据本申请的一些实施例,示出了终端播报显示推荐的歌曲的示意图;
图5根据本申请的一些实施例,示出了图1中所示的系统中的终端的一种工作流程图;
图6根据本申请的一些实施例,示出了图1所示的系统中的云端的一种工作流程图;
图7根据本申请的一些实施例,示出了一种推荐装置的结构示意图;
图8根据本申请的一些实施例,示出了一种推荐装置的结构示意图;
图9根据本申请的一些实施例,示出了一种系统的框图;
图10根据本申请的一些实施例,示出了一种片上系统(SoC)的框图。
具体实施例
本申请的说明性实施例包括但不限于基于隐私数据的推荐方法及其装置、介质和系统。
可以理解,如本文所使用的,术语“模块””可以指代或者包括专用集成电路(ASIC)、电子电路、执行一个或多个软件或固件程序的处理器(共享、专用、或群组)和/或存储器、组合逻辑电路、和/或提供所描述的功能的其他适当硬件组件,或者可以作为这些硬件组件的一部分。
下面将结合附图对本申请的实施例作进一步地详细描述。
根据本申请的一些实施例公开了一种基于用户隐私数据的推荐系统10。图1示出了该推荐系统10的结构示意图。如图1所示,该系统10包括云端100和请求云端100搜索要推荐给用户的资源项的多个终端,例如,终端200-1至终端200-n。云端100用于基于用户的隐私概化标签(即第一概化标签)和非隐私标签(即第二标签)从资源库中为终端搜索相关资源项,在一些实施例中,云端100可以搜索自身拥有的资源库,例如音乐库、新闻库、应用库等等。在另一些实施例中,云端100还可以搜索其他设备存储等资源库。云端100可以是具有搜索功能等任意的计算设备,包括但不限于手机、平板电脑、膝上型计算机、台式计算机、可穿戴设备、头戴式显示器、移动电子邮件设备、便携式游戏机、便携式音乐播放器、阅读器设备、个人数字助理、虚拟现实或者增强现实设备、其中嵌入或耦接有一个或多个处理器的电视机等电子设备。
本申请的终端200-1至200-n可以通过向云端100发送隐私概化标签从云端100获取跟用户隐私数据相关的搜索结果,同时,通过基于隐私标签(即第一标签)对云端100返回的搜索结果中的资源项进行排序,更加智能化地为用户提供个性化推荐服务,此外,终端200-1至200-n还可以基于用户隐私标签,生成对应推荐的资源项的推荐理由,并在向用户显示推荐的资源项时显示相关的推荐理由。200-1至200-n可以是面向用户的各种计算设备,包括但不限于手机、平板电脑、膝上型计算机、台式计算机、可穿戴设备、头戴式显示器、移动电子邮件设备、便携式游戏机、便携式音乐播放器、阅读器设备、个人数字助理、虚拟现实或者增强现实设备、其中嵌入或耦接有一个或多个处理器的电视机等电子设备。
下面以图2所示的终端200-1和云端100的结构为例,详细说明本申请的技术方案。可以理解,本申请的技术方案适用于各种结构的终端和云端设备,并不限于图2所示的结构。
具体地,如图2所示,云端100包括搜索模块101、云侧推荐理由生成模块102、以及资源属性模块103。其中,搜索模块101可以根据终端200-1上传的用户的非隐私标签及隐私概化标签,从资源属性模块103(可以包括云端100的音乐库100-1、新闻库100-2、应用库100-3等)中选择与非隐私标签及隐私概化标签相匹配的资源项,然后将资源项id和对应的标签详情以及为搜索到的资源项生成的推荐理由下发给终端200-1。
云侧推荐理由生成模块102可以根据终端200-1上传的非隐私标签,为从资源属性模块103搜索到的资源项生成推荐理由,例如,为从音乐库100-1中搜索到的歌曲进行推荐理由生成,比如歌曲《忘情水》对应的年代标签为“80后”,则云侧推荐理由生成模块102对其生成的推荐理由为“搜索理由–年代–80后”。
资源属性模块103可以是一个云侧的资源库,例如,可以包括音乐库、新闻库、应用库等等中的一个或者多个。该模块中的每个资源或者说每个资源项都有相应的资源属性标签,如音乐《忘情水》的标签有“歌名–忘情水”,“歌手–刘德华”,“年代-80后”,“风格–抒情”等。如游戏应用A的标签有“类别-游戏”、“画面-中国风”、“历史背景-战国”等。该模块根据搜索模块101输入的隐私概化标签或者非隐私标签选择对应的音乐返回。
如图2所示,终端200-1包括用户隐私数据模块201、用户非隐私数据模块202、精排模块203、后处理模块204、端侧推荐理由生成模块205以及播报显示模块206。
1)用户隐私数据模块201基于获取到的用户隐私数据,生成用户的隐私标签和隐私概化标签。隐私标签可以用于端侧后处理模块204及端侧推荐理由生成模块205。
可以理解,本申请的用户隐私数据可以是能够将用户与其他用户区分开的用户数据,例如,用户的运动状态、用户的当前位置、住所位置、用户年龄、手机号码、身份证号码等,这些用户隐私数据如果公开,会对用户的人身安全、信息安全、财产安全等产生风险。此外,隐私数据还可以是用户不愿意公开的个人数据,如就医记录、体检报告、家庭成员信息等。
可以理解,隐私标签可以是基于用户隐私数据生成的关键词,例如,如果用户年龄为18,则其隐私标签可以是“00后”,如果用户居所为成都,则其隐私标签可以是成都,如果用户隐私数据表示用户是学生,则其隐私标签可以是学生,如果用户当前的状态为正在跑步,则其隐私标签可以是跑步,……。而隐私概化标签可以是隐私标签的上位概念,比隐私标签所表示的范围更广,隐私概化标签可以包括多个不同的隐私标签。例如,隐私概化标签可以是隐私标签所属的至少一个类别,对于空间位置、时间等,隐私概化标签可以具有比隐私标签所表示的空间范围或者时间范围更大的范围。例如,隐私标签为跑步,则其隐私概化标签可以是运动,同时运动可以是游泳、乘车等隐私标签的隐私概化标签。再例如,隐私标签为睡觉,则其隐私概化标签可以是作息时间,此外,作息时间还可以是起床、午休等的隐私概化标签。
2)用户非隐私数据模块202可以用于获取用户在相关推荐业务上产生的行为日志,如音乐应用中用户一周内最喜欢听的歌曲、歌手、年代、风格等,新闻应用中用户一个月内频繁浏览的新闻所属的板块,用户近期内搜索下载的应用所属的类别等。然后基于获取到的这些对用户进行描述的特征数据,生成非隐私标签。例如,用户最近喜欢听摇滚歌曲,则可以生成非隐私标签摇滚,用户最近喜欢看军事新闻,则可以生成非隐私标签军事。这些非隐私数据除了可以来自用户的行为日志,还可以是请求用户输入或者请求用户选择的,能够上传云端100的用户数据,例如,相关应用可以列出一些标签供用户选择,用户选择的这些标签可以作为用户的非隐私标签。这些数据不是某一个或者少数用户特有的数据,不具有很强的独特性。
该模块输出的非隐私标签分别用于云端100的搜索模块101、云侧推荐理由生成模块102以及精排模块203。
3)精排模块203可以对云端100的搜索模块101搜索到的资源项的列表进行排序,得到排序后的资源项列表(即第二排序结果),排序依据为终端200-1上存储的用户非隐私标签的内容,可以将与非隐私标签匹配度高的资源项排在前面。如用户只有一个隐私标签为“歌手–周杰伦”,则精排模块203的输出会把歌手为周杰伦的歌曲排在最前面。
此外,可以理解,精排模块203也可以基于非隐私标签,对资源项列表进行综合分析后进行排序,不限制为根据与非隐私标签的匹配度进行排序,例如,可以结合用户偏好和歌曲偏好作为输入,利用机器学习中的CTR(Click-Through-Rate,点击通过率)预估/LTR(LearningToRank,学习排序)方法进行排序。
可以理解,精排模块203在对资源项列表进行排序时,所用到的非隐私标签可以比搜索到资源项列表中的资源项时用到的非隐私标签多,即精排模块203是一个综合排序模块。例如,资源项列表中的歌曲A和歌曲B在搜索时用到的非隐私标签是“80”后,在排序的时候,如果非隐私标签除了“80”后,还有歌手C,而只有歌曲A的资源属性标签标明其是由歌手C演唱的,则将歌曲A排在歌曲B前面。
可以理解,在其他实施例中,由于非隐私标签可以上传云端,所以精排模块203的功能也可以放在云端100进行,不必限制为在终端201-1上进行。
4)后处理模块204可以包括去重、重排、截断这三个功能。其中,去重是指在精排模块203输出的资源项列表中有重复资源项的情况下,去除重复的资源项。
重排可以是根据用户的隐私标签(或者用户隐私数据)和人工指定规则,将去重后的资源项列表进行重排序(即得到第三排序结果),如用户隐私数据中包括“运动状态–跑步”且人工指定规则为“跑步时将适合跑步节奏的歌曲排在最前”,去重后的资源项列表中有三首关于运动的歌曲,其中歌曲A的资源属性标签为则调整音乐列表顺序为把带有“运动状态-跑步”标签的音乐排在最前面。可以理解,人工指定规则是指预先规定好的排序规则,例如,对于某些无法根据用户隐私数据排序的资源项,在总结规律后可以人为设定排序规则。
截断可以是在重排序后的资源项列表超出预设的条数时,将多出的条目删除掉。例如,如果重排后的音乐列表长度超过设置返回资源项条数,则对冗余条目进行截断,如经去重、重排的音乐列表为15首歌,一次音乐推荐需返回给用户10首歌,则丢弃后5首歌曲。
5)端侧推荐理由生成模块205可以根据终端200-1上存储的隐私标签,对后处理模块处理过的资源项进行推荐理由生成,比如音乐《Runaway Baby》对应的年代标签为“跑步”,则该模块对其生成的推荐理由为“推荐理由–运动状态–跑步”;如新闻《深圳房价走势》对应的城市标签为“深圳”,则该模块对这则新闻生成的推荐理由为“推荐理由–城市–深圳”。
6)播报显示模块206可以将后处理输出的资源项列表反馈给用户,反馈方式可以包括语音播报和显示,其中显示可以显示一个资源项,隐藏列表中的其他资源项,也可将资源项列表全部显示出来。播报会选择排序第一的资源项推荐理由进行话术配置与语音播放,如“夜深了,请让这首动听的《红豆》伴您入睡。”
可以理解,播报显示模块206还可以具有其他的反馈方式,不限于此,例如,震动加语音播报。
下面以音乐应用中的音乐推荐为例,说明基于图2所示的结构,实现对用户的智能化和个性化推荐的过程。具体地,该过程包括:
1)用户发起与推荐业务相关的请求,终端200-1的用户隐私数据模块201和用户非隐私数据模块202分别上传用户非隐私标签及用户隐私概化标签。例如,在一些场景下,用户通过终端200-1的语音助手发起音乐推荐请求:“我的助手,给我放首歌”。终端200-1上传用户非隐私标签的内容及隐私概化标签到云端100,其中,用户非隐私标签的内容包括:“歌手–周杰伦”,“年代-80后”,隐私概化标签包括:“运动状态”、“作息时间”。
可以理解,在本申请的其他实施例中,也可以是终端200-1主动发起推荐业务,并不是由用户发起,故在此不做限制。
此外,可以理解,在本申请的其他实施例中,有些场景下,终端200-1也可以只上传用户的隐私概化标签,而不同时上传非隐私标签。
2)云端100的搜索模块101可以接收终端200-1发送的用户非隐私标签,并根据非隐私标签与资源属性标签的匹配程度对资源属性模块103中的资源项进行搜索,云侧推荐理由生成模块102对利用用户非隐私标签搜索到的资源项生成相对应的推荐理由。
例如,如果云端100的搜索模块101接收到的用户非隐私标签为“歌手–周杰伦”,“年代-80后”,则在资源属性模块103的音乐库中按照这两个非隐私标签进行搜索,得到搜索结果为两首歌:《东风破》,《忘情水》,并带有以下信息:
songId_1:歌名=忘情水,歌手=刘德华,年代=80后;
songId_2:歌名=东风破,歌手=周杰伦,年代=80后;
songId_3:歌名=忘情水_演唱会版,歌手=刘德华,年代=80后。
可以理解,如果在一些实施例中,终端200-1只上传用户的隐私概化标签,而未上传非隐私标签,则该功能可以省略。
推荐理由生成模块102对以上两首歌,根据其搜索时用到的非隐私标签生成对应的推荐理由(即第二推荐理由),结果如下:
songId_1:歌名=忘情水,歌手=刘德华,年代=80后,推荐理由={年代=80后};
songId_2:歌名=东风破,歌手=周杰伦,年代=80后,推荐理由={歌手=周杰伦、年代=80后};
songId_3:歌名=忘情水_演唱会版,歌手=刘德华,年代=80后,推荐理由={年代=80后}。
可以理解,如果在一些实施例中,终端200-1只上传用户的隐私概化标签,而未上传非隐私标签,则该功能可以省略。
3)云端100的搜索模块101可以在接收到隐私概化标签后,搜索资源属性模块103有对应资源属性标签的资源项。
例如,对于上述音乐推荐,搜索模块101接收到的隐私概化标签包括:“运动状态”,“作息时间”。搜索模块101搜索资源属性模块103中的音乐库,搜索结果为:
songId_4:歌名=奔跑,歌手=羽泉,运动状态=跑步;
songId_5:歌名=沙漠骆驼,歌手=展展与罗罗,运动状态=骑车;
songId_6:歌名=红豆,歌手=王菲,作息时间=睡前;
songId_7:歌名=Malaysia Chabor,歌手=四叶草,作息时间=早起。
4)搜索模块101可以将2)和4)搜到的资源项列表,以及2)中生成的推荐理由做融合,返回给云端。
具体地,继续上面的例子,搜索模块101返回下面内容给终端200-1:
songId_1:歌名=忘情水,歌手=刘德华,年代=80后,推荐理由={年代=80后};
songId_2:歌名=东风破,歌手=周杰伦,年代=80后,推荐理由={歌手=周杰伦、年代=80后};
songId_3:歌名=忘情水_演唱会版,歌手=刘德华,年代=80后,推荐理由={年代=80后};
songId_4:歌名=奔跑,歌手=羽泉,运动状态=跑步;
songId_5:歌名=沙漠骆驼,歌手=展展与罗罗,运动状态=骑车;
songId_6:歌名=红豆,歌手=王菲,作息时间=睡前;
songId_7:歌名=Malaysia Chabor,歌手=四叶草,作息时间=早起;
5)终端200-1的精排模块203可以接收云端100的搜索模块101返回的资源项列表和推荐理由(即包含多个资源项和第二推荐理由),并根据用户的非隐私标签进行相似度匹配排序,与用户的非隐私标签内容相似度高的资源项排在前面。
具体地,对于上述例子,精排模块203根据终端200-1上存储的用户的非隐私标签(“歌手–周杰伦”,“年代-80后”)进行相似度匹配排序,与用户的非隐私标签内容相似度高的资源项排在前面,其中,songId2匹配度最高,则songId2排在最前面,songId1与songId3次之,其余歌曲排在最后,结果如下:
songId_2:歌名=东风破,歌手=周杰伦,年代=80后,推荐理由={歌手=周杰伦、年代=80后};
songId_1:歌名=忘情水,歌手=刘德华,年代=80后,推荐理由={年代=80后};
songId_3:歌名=忘情水_演唱会版,歌手=刘德华,年代=80后,推荐理由={年代=80后};
songId_4:歌名=奔跑,歌手=羽泉,运动状态=跑步;
songId_5:歌名=沙漠骆驼,歌手=展展与罗罗,运动状态=骑车;
songId_6:歌名=红豆,歌手=王菲,作息时间=睡前;
songId_7:歌名=Malaysia Chabor,歌手=四叶草,作息时间=早起;
6)后处理模块204可以接收精排模块203精排后的资源项列表,如果列表中的资源项有重复,则后处理模块204将去除重复的资源项。
具体地,对于上述例子,后处理模块204接收到精排后的下列资源项列表后,发现songId_1和songId_3的音乐均为刘德华的《忘情水》,则对列表进行去重操作,只保留songId_1,结果如下:
songId_2:歌名=东风破,歌手=周杰伦,年代=80后,推荐理由={歌手=周杰伦、年代=80后};
songId_1:歌名=忘情水,歌手=刘德华,年代=80后,推荐理由={年代=80后};
songId_4:歌名=奔跑,歌手=羽泉,运动状态=跑步;
songId_5:歌名=沙漠骆驼,歌手=展展与罗罗,运动状态=骑车;
songId_6:歌名=红豆,歌手=王菲,作息时间=睡前;
songId_7:歌名=Malaysia Chabor,歌手=四叶草,作息时间=早起。
7)后处理模块204还可以对去重后的资源项列表进行重排序,重排依据是隐私标签与人工设置规则的匹配程度,匹配程度高的资源项排在前面。
具体地,对于上述例子,后处理模块204对去重后的资源项列表进行重排序,重排依据是隐私标签的内容与人工设置规则的匹配程度,这里假设用户当前正在跑步(即隐私标签为“运动状态=跑步”)且人工设置规则为“‘运动状态=跑步’时,歌曲排在首位,其余歌曲排在非隐私标签的资源项之后”,则匹配重排后的结果如下;
songId_4:歌名=奔跑,歌手=羽泉,运动状态=跑步;
songId_2:歌名=东风破,歌手=周杰伦,年代=80后,推荐理由={歌手=周杰伦、年代=80后};
songId_1:歌名=忘情水,歌手=刘德华,年代=80后,推荐理由={年代=80后};
songId_5:歌名=沙漠骆驼,歌手=展展与罗罗,运动状态=骑车;
songId_6:歌名=红豆,歌手=王菲,作息时间=睡前;
songId_7:歌名=Malaysia Chabor,歌手=四叶草,作息时间=早起。
8)端侧推荐理由生成模块205可以根据隐私标签生成对应的推荐理由赋予云端100根据隐私概化标签搜索到的资源项。
具体地,对于上述例子,端侧推荐理由生成模块205可以根据隐私标签“运动状态=跑步”生成对应的推荐理由“推荐理由={运动状态=跑步}”赋予给songId4,结果如下:
songId_4:歌名=奔跑,歌手=羽泉,运动状态=跑步,推荐理由={运动状态=跑步};
songId_2:歌名=东风破,歌手=周杰伦,年代=80后,推荐理由={歌手=周杰伦、年代=80后};
songId_1:歌名=忘情水,歌手=刘德华,年代=80后,推荐理由={年代=80后};
songId_5:歌名=沙漠骆驼,歌手=展展与罗罗,运动状态=骑车;
songId_6:歌名=红豆,歌手=王菲,作息时间=睡前;
songId_7:歌名=Malaysia Chabor,歌手=四叶草,作息时间=早起;
9)后处理模块204在重排序后的资源项列表中资源项的个数超过了一次业务请求需要返回的资源项数目的情况下,对重排后的资源项列表进行截断,去除排在后面超出数目的资源项。
具体地,对于上述例子,终端200-1的后处理模块204对去重和重排后的资源项列表进行截断,假设一次业务请求需要返回给用户3首歌曲,那么后处理模块204对列表中第3首之后的歌曲进行截断,结果如下:
songId_4:歌名=奔跑,歌手=羽泉,运动状态=跑步,推荐理由={运动状态=跑步};
songId_2:歌名=东风破,歌手=周杰伦,年代=80后,推荐理由={歌手=周杰伦、年代=80后};
songId_1:歌名=忘情水,歌手=刘德华,年代=80后,推荐理由={年代=80后}。
10)播报显示模块206将终端侧的后处理模块204输出的资源项列表反馈给用户,反馈方式可以包括语音播报和显示,其中显示可以显示一个资源项,隐藏列表中的其他资源项,也可将资源项列表全部显示出来;播报会选择排序第一的资源项推荐理由进行话术配置与语音播放。
例如,对于上述例子,如图3所示,终端侧的播报显示模块206将终端侧的后处理模块204输出的资源项列表反馈给用户,显示第一首歌的歌名《奔跑》,并为之配以话术:“看样子您正在跑步,来体验一下动感的节奏吧”,在显示的同时语音助手对话术进行播报,从而完成对用户请求的反馈。
此外,对于后处理模块204输出的资源项列表中的歌曲《东方破》,在向用户推荐时,如图4所示,显示歌名《东风破》,并为之配以话术:“你最近比较喜欢听周杰伦的歌,来试试这首《东风破》吧”,在显示的同时语音助手对话术进行播报,从而完成对用户请求的反馈。
可以理解,本申请的推荐方法适用于各种资源库内容的推荐,并不限于上述实施例所举到音乐推荐的例子。
基于上面的描述,下面具体介绍在系统10中各设备的主要工作流程。
根据本申请的一些实施例,结合上述对系统10的描述,对系统10中的终端的工作流程进行说明,上述描述中的具体细节在此处依然适用,在此不再赘述。图5示出了系统10中终端100-1至100-n中的任意一个的工作流程图,具体地,以终端100-1为例,如图5所示,包括:
1)终端200-1可以根据用户发起的与推荐业务相关的请求,上传用户非隐私标签及用户隐私概化标签(500)。
可以理解,在其他实施例中,终端200-1也可以根据场景主动发起推荐业务,在此不做限制。
2)终端200-1可以判断是否接收到云端100返回的资源项列表和推荐理由(502),并在判断结果为是后,根据用户的非隐私标签对资源项列表中的资源项进行相似度匹配排序,与用户的非隐私标签内容相似度高的资源项排在前面(504)。
3)终端200-1可以在排序的资源项列表中判断是否有重复资源项(506),在判断结果为是时,去除列表中重复的资源项(508)。
4)终端200-1可以对去除了重复资源项的资源项列表依据隐私标签和人工设置规则进行重排序(510),其中,匹配程度高的资源项排在前面。
5)终端200-1可以根据隐私标签生成对应的推荐理由赋予云端100根据隐私概化标签搜索到的资源项(512)。
6)终端200-1可以判断重排序后资源项列表中资源项的个数是否超过了一次业务请求需要返回的资源项的项数(514),在判断结果为是的情况下,对重排后的资源项列表进行截断,去除排在后面超出项数的资源项(516)。
7)终端200-1将资源项列表反馈给用户,反馈方式可以包括语音播报和显示(518)。
根据本申请的一些实施例,结合上述对系统10的描述,对系统10中的云端100的工作流程进行说明,上述描述中的具体细节在此处依然适用,在此不再赘述。图6示出了系统10中云端10的工作流程图,具体地,如图6所示,包括:
1)云端100可以接收终端200-1发送的用户的非隐私标签和隐私概化标签,并分别根据非隐私标签和隐私概化标签与资源属性标签的匹配程度对资源库中的资源项进行搜索(600)。
2)云端100对利用用户非隐私标签搜索到的资源项生成相对应的推荐理由(602)。
3)云端100向终端200-1发送搜索到的资源项的资源项列表和利用用户非隐私标签搜索到的资源项的推荐理由(603)。
根据本申请的一些实施例,图7示出了一种推荐装置的结构示意图。具体地,如图7所示,该推荐装置包括:
第一发送模块700,用于向云端发送用户偏好标签,其中,用户偏好标签包括对基于用户的隐私数据生成的第一标签进行概化后的第一概化标签;
第一接收模块702,用于接收云端返回的基于用户偏好标签从资源库中搜索到的多个资源项;
选择模块704,用于从多个资源项中选择出推荐的资源项。
此外,可以理解,在一些实施例中,选择模块704还可以用于基于用户的至少一个第一标签对多个资源项进行排序,生成第一排序结果;将第一排序结果中的前预定数目的资源项作为推荐的资源项。
此外,可以理解,在一些实施例中,用户标签还包括基于用户的非隐私数据生成的第二标签,其中,用户的非隐私数据为对用户进行描述的数据中除用户的隐私数据外的全部数据;并且,云端返回的多个资源项还包括云端基于第二标签搜索到的第二资源项。云端除了返回的多个资源项,还返回对应第二资源项的第二推荐理由,其中,第二推荐理由与搜索到第二资源项时所使用的第二标签相关。并且,显示播报模块,还用于在推荐的资源项包括第二资源项的情况下,在屏幕上显示第二资源项和第二推荐理由。
此外,可以理解,在一些实施例中,选择模块704还可以用于基于至少一个第二标签对多个资源项进行排序,生成第二排序结果;确定第二排序结果中是否存在重复的资源项;在确定存在重复的资源项的情况下,删除重复的资源项;基于第一标签对第二排序结果进行排序,生成第三排序结果;将第三排序结果中的前预定数目的资源项作为推荐的资源项。
此外,可以理解,在一些实施例中,多个资源项包括云端基于第一概化标签搜索到的第一资源项,并且该推荐装置还包括端侧推荐理由生成模块,用于根据检索到第一资源项时用到的第一概化标签所对应的第一标签生成的第一资源项的第一推荐理由。
此外,可以理解,在一些实施例中,该推荐装置还包括显示播报模块,用于在推荐的资源项包括第一资源项的情况下,在屏幕上显示第一资源项和对应第一资源项的第一推荐理由,或者语音播报第一资源项的第一推荐理由,其中,第一推荐理由是根据检索到第一资源项时用到的第一概化标签所对应的第一标签生成的,第一资源项是云端基于第一概化标签搜索到的。
根据本申请的一些实施例,图8示出了一种推荐装置的结构示意图。具体地,如图8所示,该推荐装置包括:
第二接收模块800,用于从终端接收用户偏好标签,其中,用户偏好标签包括对基于用户的隐私数据生成的第一标签进行概化后的第一概化标签;
搜索模块802,用于基于接收到的用户偏好标签,从资源库中搜索与用户偏好标签匹配的资源项;
第二发送模块804,用于在搜索到与用户偏好标签匹配的资源项的情况下,将搜索到的资源项发送给终端。
此外,可以理解,在一些实施例中,用户标签还包括基于用户的非隐私数据生成的第二标签,其中,用户的非隐私数据为对用户进行描述的数据中除用户的隐私数据外的全部数据;并且多个资源项还包括云端基于第二标签搜索到的第二资源项。
此外,可以理解,在一些实施例中,该推荐装置还包括:
云侧推荐理由生成模块,基于第二标签生成对应第二资源项的第二推荐理由。
此外,可以理解,在一些实施例中,该推荐装置还包括:
云侧后处理单元,用于基于第二标签对向终端发送的资源项进行排序,生成第二排序结果;确定第二排序结果中是否存在重复的资源项;在确定存在重复的资源项的情况下,删除重复的资源项。
此外,可以理解,在一些实施例中,资源项包括云端基于第一概化标签搜索到的第一资源项。
现在参考图9,所示为根据本申请的一个实施例的系统900的框图。图9示意性地示出了根据多个实施例的示例系统900。在一个实施例中,系统900可以包括一个或多个处理器904,与处理器904中的至少一个连接的系统控制逻辑908,与系统控制逻辑908连接的系统内存912,与系统控制逻辑908连接的非易失性存储器(NVM)916,以及与系统控制逻辑908连接的网络接口920。
在一些实施例中,处理器904可以包括一个或多个单核或多核处理器。在一些实施例中,处理器904可以包括通用处理器和专用处理器(例如,图形处理器,应用处理器,基带处理器等)的任意组合。在系统900采用eNB(Evolved Node B,增强型基站)101或RAN(RadioAccess Network,无线接入网)控制器102的实施例中,处理器904可以被配置为执行各种符合的实施例,例如,如图1-4所示的多个实施例中的一个或多个。
在一些实施例中,系统控制逻辑908可以包括任意合适的接口控制器,以向处理器904中的至少一个和/或与系统控制逻辑908通信的任意合适的设备或组件提供任意合适的接口。
在一些实施例中,系统控制逻辑908可以包括一个或多个存储器控制器,以提供连接到系统内存912的接口。系统内存912可以用于加载以及存储数据和/或指令。在一些实施例中系统900的内存912可以包括任意合适的易失性存储器,例如合适的动态随机存取存储器(DRAM)。
NVM/存储器916可以包括用于存储数据和/或指令的一个或多个有形的、非暂时性的计算机可读介质。在一些实施例中,NVM/存储器916可以包括闪存等任意合适的非易失性存储器和/或任意合适的非易失性存储设备,例如HDD(Hard Disk Drive,硬盘驱动器),CD(Compact Disc,光盘)驱动器,DVD(Digital Versatile Disc,数字通用光盘)驱动器中的至少一个。
NVM/存储器916可以包括安装系统900的装置上的一部分存储资源,或者它可以由设备访问,但不一定是设备的一部分。例如,可以经由网络接口920通过网络访问NVM/存储916。
特别地,系统内存912和NVM/存储器916可以分别包括:指令924的暂时副本和永久副本。指令924可以包括:由处理器904中的至少一个执行时导致系统900实施如图3-4所示的方法的指令。在一些实施例中,指令924、硬件、固件和/或其软件组件可另外地/替代地置于系统控制逻辑908,网络接口920和/或处理器904中。
网络接口920可以包括收发器,用于为系统900提供无线电接口,进而通过一个或多个网络与任意其他合适的设备(如前端模块,天线等)进行通信。在一些实施例中,网络接口920可以集成于系统900的其他组件。例如,网络接口920可以集成于处理器904的,系统内存912,NVM/存储器916,和具有指令的固件设备(未示出)中的至少一种,当处理器904中的至少一个执行所述指令时,系统900实现如图3-4所示的方法。
网络接口920可以进一步包括任意合适的硬件和/或固件,以提供多输入多输出无线电接口。例如,网络接口920可以是网络适配器,无线网络适配器,电话调制解调器和/或无线调制解调器。
在一个实施例中,处理器904中的至少一个可以与用于系统控制逻辑908的一个或多个控制器的逻辑封装在一起,以形成系统封装(SiP)。在一个实施例中,处理器904中的至少一个可以与用于系统控制逻辑908的一个或多个控制器的逻辑集成在同一管芯上,以形成片上系统(SoC)。
系统900可以进一步包括:输入/输出(I/O)设备932。I/O设备932可以包括用户界面,使得用户能够与系统900进行交互;外围组件接口的设计使得外围组件也能够与系统900交互。在一些实施例中,系统900还包括传感器,用于确定与系统900相关的环境条件和位置信息的至少一种。
在一些实施例中,用户界面可包括但不限于显示器(例如,液晶显示器,触摸屏显示器等),扬声器,麦克风,一个或多个相机(例如,静止图像照相机和/或摄像机),手电筒(例如,发光二极管闪光灯)和键盘。
在一些实施例中,外围组件接口可以包括但不限于非易失性存储器端口、音频插孔和电源接口。
在一些实施例中,传感器可包括但不限于陀螺仪传感器,加速度计,近程传感器,环境光线传感器和定位单元。定位单元还可以是网络接口920的一部分或与网络接口920交互,以与定位网络的组件(例如,全球定位系统(GPS)卫星)进行通信。
根据本申请的实施例,图10示出了一种SoC(System on Chip,片上系统)1000的框图。在图10中,相似的部件具有同样的附图标记。另外,虚线框是更先进的SoC的可选特征。在图10中,SoC 1000包括:互连单元1050,其被耦合至应用处理器1010;系统代理单元1070;总线控制器单元1080;集成存储器控制器单元1040;一组或一个或多个协处理器1020,其可包括集成图形逻辑、图像处理器、音频处理器和视频处理器;静态随机存取存储器(SRAM)单元1030;直接存储器存取(DMA)单元1060。在一个实施例中,协处理器1020包括专用处理器,诸如例如网络或通信处理器、压缩引擎、GPGPU、高吞吐量MIC处理器、或嵌入式处理器等等。
本申请公开的机制的各实施例可以被实现在硬件、软件、固件或这些实现方法的组合中。本申请的实施例可实现为在可编程系统上执行的计算机程序或程序代码,该可编程系统包括至少一个处理器、存储系统(包括易失性和非易失性存储器和/或存储元件)、至少一个输入设备以及至少一个输出设备。
可将程序代码应用于输入指令,以执行本申请描述的各功能并生成输出信息。可以按已知方式将输出信息应用于一个或多个输出设备。为了本申请的目的,处理系统包括具有诸如例如数字信号处理器(DSP)、微控制器、专用集成电路(ASIC)或微处理器之类的处理器的任何系统。
程序代码可以用高级程序化语言或面向对象的编程语言来实现,以便与处理系统通信。在需要时,也可用汇编语言或机器语言来实现程序代码。事实上,本申请中描述的机制不限于任何特定编程语言的范围。在任一情形下,该语言可以是编译语言或解释语言。
在一些情况下,所公开的实施例可以以硬件、固件、软件或其任何组合来实现。所公开的实施例还可以被实现为由一个或多个暂时或非暂时性机器可读(例如,计算机可读)存储介质承载或存储在其上的指令,其可以由一个或多个处理器读取和执行。例如,指令可以通过网络或通过其他计算机可读介质分发。因此,机器可读介质可以包括用于以机器(例如,计算机)可读的形式存储或传输信息的任何机制,包括但不限于,软盘、光盘、光碟、只读存储器(CD-ROMs)、磁光盘、只读存储器(ROM)、随机存取存储器(RAM)、可擦除可编程只读存储器(EPROM)、电可擦除可编程只读存储器(EEPROM)、磁卡或光卡、闪存、或用于利用因特网以电、光、声或其他形式的传播信号来传输信息(例如,载波、红外信号数字信号等)的有形的机器可读存储器。因此,机器可读介质包括适合于以机器(例如,计算机)可读的形式存储或传输电子指令或信息的任何类型的机器可读介质。
在附图中,可以以特定布置和/或顺序示出一些结构或方法特征。然而,应该理解,可能不需要这样的特定布置和/或排序。而且,在一些实施例中,这些特征可以以不同于说明性附图中所示的方式和/或顺序来布置。另外,在特定图中包括结构或方法特征并不意味着暗示在所有实施例中都需要这样的特征,并且在一些实施例中,可以不包括这些特征或者可以与其他特征组合。
需要说明的是,本申请各设备实施例中提到的各单元/模块都是逻辑单元/模块,在物理上,一个逻辑单元/模块可以是一个物理单元/模块,也可以是一个物理单元/模块的一部分,还可以以多个物理单元/模块的组合实现,这些逻辑单元/模块本身的物理实现方式并不是最重要的,这些逻辑单元/模块所实现的功能的组合才是解决本申请所提出的技术问题的关键。此外,为了突出本申请的创新部分,本申请上述各设备实施例并没有将与解决本申请所提出的技术问题关系不太密切的单元/模块引入,这并不表明上述设备实施例并不存在其它的单元/模块。
需要说明的是,在本专利的示例和说明书中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、资源项或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、资源项或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个”限定的要素,并不排除在包括所述要素的过程、方法、资源项或者设备中还存在另外的相同要素。
虽然通过参照本申请的某些优选实施例,已经对本申请进行了图示和描述,但本领域的普通技术人员应该明白,可以在形式上和细节上对其作各种改变,而不偏离本申请的精神和范围。
- 基于用户隐私数据的推荐方法及其装置、介质和系统
- 一种基于用户行为序列的个性化推荐系统召回方法、系统、装置及存储介质