一种基于EEG数据的物体识别方法
文献发布时间:2023-06-19 11:14:36
技术领域
本发明属于EEG信号识别技术领域,具体涉及一种基于EEG信号的场景识别系统。
背景技术
当前,人类对于场景分类的能力要比计算机强的多。尽管近几年的深度学习算法能够达到一个非常好的场景识别的正确率,深度学习算法仍然无法超越人类的识别正确率。相较于计算机视觉的方法直接提取图像的可区分特征来做识别,人脑的视觉识别过程还包含了知觉过程和识别理论,例如,物体的颜色和形状等对人类大脑的刺激,人类大脑皮层对这些刺激做出的反应。一些在神经科学领域的研究指出,人类的大脑活动,对于特定类别的物体会有特定的大脑活动模式。人类大脑对于同一种类别物体的识别是基于同一种模式的,并且识别速度非常快,时间尺度在几毫秒左右。所以,可以先把物体的图片展示给被试,然后记录下被试的EEG数据,利用EEG数据非常高的时间维度的分辨率,可以很好地从EEG数据中提取出可用来进行识别的特征。如果人类对于物体的感知和识别过程能够被提炼并应用在计算机视觉中,那么计算机能够自动去模拟人类的物体识别过程。
解码视觉相关的人类大脑活动具有很大意义,不仅能够给科研人员提供一个全新的角度去研究视觉认知过程,还能增强人机交互系统的性能。利用人脑的EEG数据进行物体识别,不仅能够改变传统的物体识别方法,还能够提供一个新颖的给未标注的图像数据打标签的方法。借鉴人类视觉系统的模式去做计算机视觉任务一直是一个比较困难的方向,然而,深度学习的兴起使得科研人员能够更加深入地研究 EEG数据和神经科学。就目前我们所知,有一些研究直接利用EEG信号来做物体识别任务。例如,Kapoor A等人提出了一种利用EEG数据去做物体识别的方法,他们把图像分成三种类别(动物、人脸、非生命物体)。Rouby等人利用EEG数据去做物体识别任务。他们利用 256导的EEG数据采集系统采集了一个包含400张图像和对应EEG数据的数据集。他们的平均正确率为82.70%。Viral等人提出了一个基于EEG数据的图像标注系统。他们利用2500张图像作为训练集,并且F1分数达到了0.88。上述这些研究表明了利用EEG数据进行物体识别任务是可行的。2017年,Perceive实验室放出了一个目前最大的物体识别EEG数据集。并且他们构建了一系列的基于循环神经网络的EEG识别模型。他们最好的识别准确率为82.9%。虽然目前这些方法已经取得了非常不错的效果,但是在识别的精度上,仍然有很大提升空间,主要原因是网络仍然需要进行改进,其次是图像的数据较少,给深度学习模型去学习可区分的特征带来了困难。
发明内容
本发明要解决的技术问题是,提供一种基于EEG数据的物体识别方法。首先利用数据增强、提取技术,对数据进行扩容。然后用 ResBlock作为基础结构,构建全新的二维卷积神经网络,把网络的前三层用空洞卷积去代替普通的卷积,利用PReLU作为网络的激活函数,利用Focalloss作为模型的损失函数。使用Perceive实验室在 2017年放出的EEG数据物体识别数据集进行模型训练。
本发明面提出的基于EEG的物体识别方法。在数据预处理阶段,利用数据增强技术,对原始EEG数据做随机置0处理和随机翻转数据的操作,达到对原始数据集进行扩容的目的。然后随机地把数据分成等量的五个部分,进行5折的训练。数据增强可以使得小数据集的数据得到充分的利用。加之采用较深的网络模型,较少的网络参数,尽管数据集中的EEG数据数量较少,也可以尽可能地学习到EEG数据中的能用来识别的特征,因此可以高效、准确地实现对物体的识别任务。
为了实现上述目的,本发明采用了以下技术方案:
首选Python语言作为基础。在数据增强上,使用numpy库对原始图像数据进行随机置0的操作和随机翻转操作,然后输出数据增强后的数据集。并在此基础上,随机把EEG数据分成等量的5份,用于 5折训练。然后使用开源深度学习框架PyTorch,实现网络模型,完成模型的搭建。通过对数据集进行5折训练,每一折都选取出在验证集上最优的模型,对选出的五个模型进行模型融合,以得到最终的结果。
一种基于EEG的物体识别方法包括以下步骤:
步骤1、获取EEG物体识别数据集,并对获得的原始图像数据集进行清洗。
所述的EEG物体识别数据集包括从被试上采集的EEG数据以及每一个被试在采集数据过程中观看物体的标签。
步骤2、利用数据增强技术对清洗后的EEG物体识别数据集进行增强处理,增加样本的数量。
步骤3、将经过步骤2处理后的EEG物体识别数据集进行随机划分,分成等量的5份数据集。
步骤4、搭建识别网络模型,利用ResBlock作为基础模块,将识别网络模型前三层的ResBlock层采用空洞卷积,网络中的激活函数采用PReLU激活函数,PReLU激活函数的公式如下,
x
识别网络模型采用FocalLoss作为损失函数,FocalLoss损失函数的公式如下,
Loss=-α(1-y′)
公式中,α和γ是两个超参数,分别用来解决数据的不均衡问题和提高难分样本的分类性能问题。y′是识别网络模型的输出。
步骤5、根据步骤3得到的5份数据集,对识别网络模型进行五折训练,并把每折训练得到的最优模型进行融合。
进一步的,步骤2具体包括以下步骤:
步骤2.1、数据随机置0:针对EEG物体识别数据集中的EEG数据,每个EEG数据的128个通道随机取1个到10个通道,随机取时间维度上长5到15个数据点,把这些数据点全部置为0。
步骤2.2、数据随机翻转:对EEG数据做时间维度或者通道维度的翻转操作。
步骤4具体包括以下步骤:
步骤4.1、基于EEG的物体识别网络模型,整体采用ResBlock 作为基础结构,将识别网络模型前三层的ResBlock层采用空洞卷积,通过空洞卷积预编码EEG数据,三个ResBlock内置的空洞卷积空洞率分别设置为1、10和21。
所述的空洞卷积能够使物体识别网络模型在初期获得更大的感受野,有利于提取EEG数据跨通道,跨大时间尺度间的信息。
步骤4.2、将MaxPool(最大池化)和ResBlock叠加得到的模块作为物体识别网络模型的基本模块;三层采用空洞卷积的ResBlock 层后连接同样结构的5个基本模块,构成物体识别网络模型;
前2个基本模块中的MaxPool层的步长在EEG数据时间维度上设置为2,在EEG数据通道维度上设置为1,使得特征图在时间维度和通道维度尺寸接近;后3个基本模块中的MaxPool操作在两个通道的步长都设置为2,即在两个维度上共同进行下采样操作。物体识别网络模型中所有的ResBlock,激活函数采用PReLU激活函数。最后采用FocalLoss作为损失函数。
所述的物体识别网络模型先采用只在时间维度进行下采样是因为EEG数据一般在时间维度上具有更高的分辨率,先在时间维度下采样使得通道维度和时间维度接近,特征图接近于一个正方形,使得接下来的卷积能够更好地提取特征。采用PReLU激活函数,使得网络每一层可以利用反向传播去学习对应于该层来说最好的激活函数。采用 Focalloss使得网络的学习能够偏向难分样本的学习。
与现有技术相对,本发明具有以下明显优势:
深度学习模型一般需要大量的数据集去训练,以此来寻求最佳模型,而EEG数据集相对自然图像而言,由于获取的难度大,成本高,使得数据集规模较小。本模型利用了FocalLoss使得模型泛化能力得到加强,使模型的学习能更加注重难分样本的学习。同时,网络前三层采用带不同空洞率的ResBlock,使得网络在预编码的时候能够获取更大感受野,融合得更大时间尺度上的信息。物体识别网络模型采用先对时间尺度进行下采样,使得特征图在时间尺度和通道尺度上的分辨率接近之后,再在两个尺度上同时进行下采样操作,这样的好处在于卷积操作时,卷积核一般采用正方形,所以把特征图变成正方形便于卷积核提取特征。
附图说明
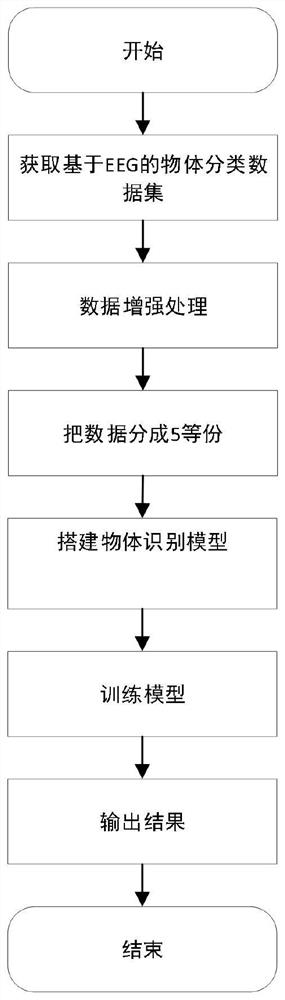
图1为本发明所涉及方法的流程图;
图2为本发明所涉及的EEG物体识别网络总体结构图;
图3是本发明的网络结构图。
图4是本发明的ResBlock结构。
具体实施方式
以下结合具体实施,并参照附图,对本发明进一步详细说明。
本发明所用到的硬件设备有PC机一台、1080ti显卡一张;
如图1所示,本发明提供一种基于深度学习的EEG物体识别方法,具体包括以下步骤:
步骤1、获取相关领域的基于EEG的物体识别数据集,并对获得的原始图像数据集进行清洗(例如,删除脏数据)。
所述的基于EEG的物体识别数据集包括EEG数据以及采集EEG数据时,被试正在观看的物体的种类标签;
步骤2、利用图像增强技术对清洗后的EEG数据集进行增强处理,增加样本的数量并丰富数据内容。
步骤3、将经过步骤2处理后的图像数据集进行随机划分,分成等量的5份数据集。
步骤4、搭建物体识别模型,利用ResBlock作为基础结构,在网络中加入空洞卷积,激活函数采用PReLU激活函数,最后损失函数采用FocalLoss作为损失函数。
如图2所示,是整个基于EEG的物体识别模型的整体结构图。
如图3所示,是本发明的详细模型结构图。
步骤4.1、构建利用ResBlock作为基础模块的模型,如图4所示,是本发明的2DResBlock结构。
步骤4.2、在模型的前三个ResBlock层中,用空洞卷积去代替常规的卷积。
步骤4.3、把模型的前两个最大池化层的步长改成在EEG数据的时间尺度上为2,在EEG数据的通道尺度上为1。
步骤4.4、模型中加入PReLU激活函数,PReLU激活函数的公式如下,
x
步骤4.5、用FocalLoss作为模型的损失函数。FocalLoss损失函数的公式如下,
Loss=-α(1-y′)
公式中,α和γ是两个超参数,分别用来解决数据的不均衡问题和提高难分样本的分类性能问题。
步骤5、根据步骤3得到的5份数据集,对物体识别模型进行五折训练,并把每折训练得到的最优模型进行融合。具体的模型融合方法是每一个模型的输出归一化之后求均值。
经过实验测试,本物体识别模型在测试集上最大正确率达到了 93.2%,2017年Perceive实验室提出模型正确率为82.9%,本模型正确率相较于其模型提升了10.3%,2019年Pranay Mukherjee等人提出的知识蒸馏模型正确率为89.6%,本模型相较于其模型提升了3.6%。
- 一种基于EEG数据的物体识别方法
- 一种基于深度自编码神经网络的脑电信号EEG身份识别方法